










Penulis asal: KarenZ, Foresight News
Pada 20 Mac 2026, terdapat satu perbualan yang tidak biasa dalam podcast pelaburan All-In.
Pengusaha modal ventura Chamath Palihapitiya menyerahkan pembicaraan kepada CEO NVIDIA, Jensen Huang, dengan mengatakan bahawa sebuah projek di Bittensor telah "mencapai pencapaian teknikal yang agak gila", melatih model bahasa besar di internet menggunakan kuasa pengiraan terdistribusi, sepenuhnya terdesentralisasi tanpa sebarang pusat data terpusat.
Huang Renxun tidak menghindar. Beliau membandingkan perkara ini dengan "versi moden Folding@home", projek terdistribusi yang pada dekad 2000-an membolehkan pengguna biasa menyumbangkan kuasa komputasi yang tidak digunakan untuk bersama-sama mengatasi masalah pelipatan protein.
Empat hari sebelum ini, pada 16 Mac, Jack Clark, salah seorang penubuh Anthropic, juga menekankan dan merujuk kepada terobosan ini dalam laporan kemajuan penyelidikan AI dengan banyak ruang: Subnet ekosistem Bittensor Templar (SN3) telah menyelesaikan latihan teragih model besar 72 bilion parameter (Covenant 72B), dengan prestasi model yang sepadan dengan LLaMA-2 yang dikeluarkan oleh Meta pada 2023.
Jack Clark menamakan bahagian ini sebagai "Menggugat Politik Ekonomi AI Melalui Pelatihan Terdistribusi", dan dalam analisisnya menekankan bahawa ini adalah teknologi yang patut diperhatikan secara berterusan—dia boleh membayangkan satu masa depan: model yang dihasilkan melalui pelatihan terdesentralisasi digunakan secara meluas di peranti, sementara AI awan terus menjalankan model besar eksklusif.
Tindakan pasaran sedikit lewat tetapi sangat tajam: SN3 meningkat lebih daripada 440% dalam sebulan terakhir, lebih daripada 340% dalam dua minggu terakhir, dengan kapitalisasi pasaran mencapai USD130 juta. Naratif sub-jaringan meletup, yang secara langsung menciptakan tekanan pembelian terhadap TAO. Oleh itu, TAO meningkat dengan cepat, sehingga mencapai USD377 pada satu masa, berlipat ganda dalam sebulan terakhir, dengan FDV mencapai sekitar USD7.5 bilion.
Masalahnya: Apa yang sebenarnya dilakukan oleh SN3? Mengapa ia ditarik ke dalam sorotan? Bagaimana narasi nilai pelatihan terdistribusi dan AI terdesentralisasi akan berkembang?
Model 72B itu
Untuk menjawab soalan ini, perlu diperhatikan dengan teliti pencapaian SN3.
Pada 10 Mac 2026, pasukan Covenant AI menerbitkan laporan teknikal di arXiv, secara rasmi mengumumkan bahawa Covenant-72B telah selesai dilatih. Ini adalah model bahasa besar dengan 72 bilion parameter, yang dilatih secara pra-pelatihan pada korpus sebanyak 1.1 bilion token menggunakan lebih daripada 70 nod berasingan (sekira-kira 20 nod disegerakkan setiap pusingan, setiap nod dilengkapi dengan 8 unit B200).
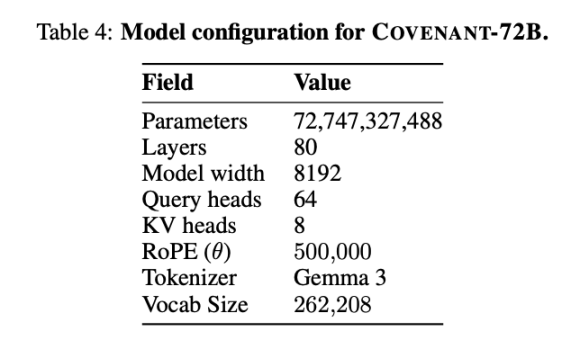
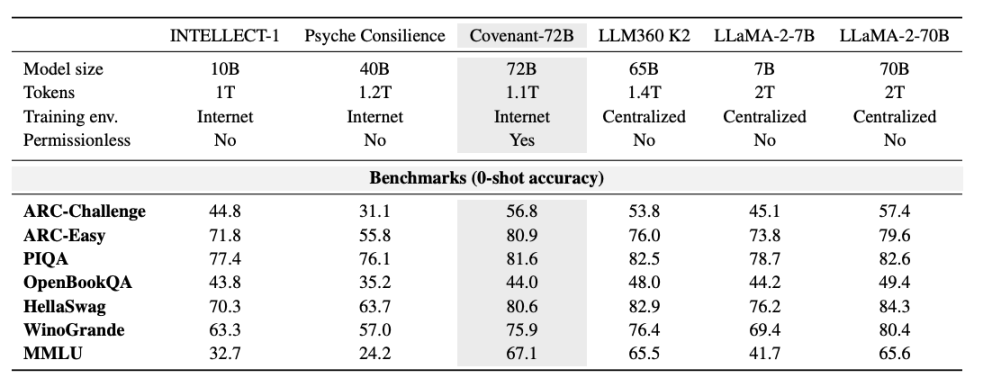
Templar memberikan beberapa data mengenai ujian piawai, dengan LLaMA-2-70B yang dibandingkan merupakan model besar yang dikeluarkan oleh Meta pada tahun 2023. Seperti yang dikatakan oleh salah seorang penemu bersama Anthropic, Jack Clark, Covenant-72B mungkin sudah ketinggalan zaman pada tahun 2026. Skor 67.1 Covenant-72B pada MMLU kira-kira sepadan dengan LLaMA-2-70B yang dikeluarkan oleh Meta pada tahun 2023 (65.6).
Manakala model terkini tahun 2026—sama ada siri GPT, Claude, atau Gemini—telah dilatih pada ratusan ribu GPU dengan parameter yang jauh melebihi 100 bilion, jurang dalam kemampuan inferens, kod, dan matematik adalah masalah peringkat, bukan peratusan. Jurang realiti ini tidak seharusnya ditenggelamkan oleh emosi pasaran.
Tetapi apabila diukur berdasarkan prasyarat "dilatih menggunakan kuasa pengkomputeran teragih di internet terbuka", maknanya menjadi sangat berbeza.
Bandingkan: INTELLECT-1 (dikembangkan oleh pasukan Prime Intellect, 10 miliar parameter) mendapat skor MMLU 32.7; projek latihan terdistribusi lain yang dilakukan di kalangan peserta senarai putih, Psyche Consilience (40 miliar parameter), mendapat skor 24.2. Covenant-72B, dengan ukuran 72B dan skor MMLU 67.1, merupakan angka yang menonjol dalam litar latihan terdesentralisasi.
Yang lebih penting, latihan ini adalah "tanpa kebenaran". Sesiapapun boleh menyambung sebagai nod peserta tanpa semakan sebelumnya atau senarai putih. Lebih daripada 70 nod bebas menyertai kemas kini model, menyumbang kuasa pengiraan dari seluruh dunia.
Apa yang Huang Renxun katakan, dan apa yang tidak dia katakan
Mengembalikan butiran perbincangan podcast itu akan membantu memperbetulkan tafsiran luar terhadap «penyokongan» ini.
Chamath Palihapitiya memaparkan pencapaian teknikal Bittensor kepada Huang Renxun dalam perbincangan itu, menggambarkan ia sebagai pelatihan model Llama menggunakan daya pengiraan teragih, dengan proses yang "sepenuhnya teragih sambil mengekalkan keadaan". Respons Huang Renxun ialah membandingkannya dengan "versi moden Folding@home", serta mengembangkan perbincangan mengenai keperluan kehadiran sejajar antara model sumber terbuka dan propietari.
Perlu diperhatikan bahawa Huang Renxun tidak secara langsung menyebut token Bittensor atau sebarang implikasi pelaburan, dan tidak membincangkan lebih lanjut mengenai latihan AI terpusat.
Memahami subnet Bittensor dan SN3
Untuk memahami tembusan SN3, pertama-tama perlu memahami cara kerja Bittensor dan sub-jaringannya. Secara ringkas, Bittensor boleh dilihat sebagai rantai AI dan platform, sementara setiap sub-jaringan bersifat seperti satu «jalur pengeluaran AI» yang berasingan, masing-masing dengan tugas utama yang jelas dan mekanisme insentif yang direka, bekerjasama membina ekosistem AI terdesentralisasi.
Proses operasinya jelas dan terdesentralisasi: pemilik sub-jaringan menentukan sasaran sub-jaringan dan menulis model insentif; penambang menyediakan daya komputasi dalam sub-jaringan dan menyelesaikan tugas berkaitan AI (seperti inferensi, pelatihan, penyimpanan, dll.); validator memberi skor terhadap sumbangan penambang dan mengunggah skor tersebut ke lapisan konsensus Bittensor; akhirnya, algoritma konsensus Yuma Bittensor akan mengalokasikan keuntungan yang sesuai kepada peserta sub-jaringan berdasarkan hadiah yang terkumpul di setiap sub-jaringan.
Sekarang terdapat 128 sub-jaringan di Bittensor, yang meliputi pelbagai tugas AI seperti inferens, perkhidmatan awan AI tanpa pelayan, imej, penandaan data, pembelajaran penguatan, penyimpanan, dan pengiraan.
SN3 pula merupakan salah satu sub-jaringan. Ia tidak membuat lapisan aplikasi, tidak menyewa API model besar yang sudah ada, tetapi terus menargetkan salah satu peringkat paling mahal dan tertutup dalam keseluruhan industri AI: latihan pra-model besar itu sendiri.
SN3 berhasrat memanfaatkan rangkaian Bittensor untuk mengkoordinasikan latihan terdistribusi sumber daya pengiraan heterogen, membuktikan bahawa model asas yang kuat boleh dilatih tanpa memerlukan kluster superkomputer terpusat yang mahal, melalui latihan model besar terdistribusi yang diinsentif. Tarikan utama terletak pada “kesetaraan” — memecahkan monopoli sumber daya dalam latihan terpusat, membolehkan individu biasa atau institusi kecil dan sederhana menyertai latihan model besar, sambil mengurangkan kos latihan melalui kuasa pengiraan terdistribusi.
Kekuatan utama yang mendorong perkembangan SN3 ialah Templar, dengan pasukan penyelidik di belakangnya ialah Covenant Labs. Pasukan ini juga mengendalikan dua sub-jaringan lain: Basilica (SN39, fokus pada perkhidmatan pengiraan) dan Grail (SN81, fokus pada latihan selepas RL dan penilaian model). Tiga sub-jaringan ini membentuk integrasi menegak, meliputi sepenuhnya keseluruhan proses dari pra-latihan hingga pengoptimuman selarasan model besar, membina ekosistem latihan model besar terdesentralisasi yang lengkap.
Secara khusus, penambang menyumbangkan sumber daya komputasi untuk menghantar kemas kini gradien (arah dan magnitud penyesuaian parameter model) ke rangkaian; penyahsahih menilai kualiti sumbangan setiap penambang dan memberikan penilaian atas rantai berdasarkan tahap peningkatan ralat. Hasilnya menentukan bobot ganjaran, yang dibahagikan secara automatik tanpa perlu mempercayai pihak ketiga mana pun.
Kunci reka bentuk mekanisme insentif ialah hadiah terkait langsung dengan "sejauh mana sumbangan anda membuat model menjadi lebih baik", bukan sekadar kehadiran kuasa pengiraan. Ini menyelesaikan masalah paling sukar dalam skenario terdesentralisasi pada asasnya: bagaimana mencegah penambang bermalas-malasan.
Bagaimana Covenant-72B menyelesaikan masalah kecekapan komunikasi dan kesesuaian insentif?
Mengkoordinasikan puluhan nod yang tidak saling percaya, peranti keras berbeza, dan kualiti rangkaian yang tidak seragam untuk melatih model yang sama, terdapat dua cabaran: pertama, kecekapan komunikasi, skema latihan teragih standard memerlukan sambungan berpemandu tinggi dan latensi rendah antara nod; kedua, keserasian insentif, bagaimana mencegah nod jahat menghantar gradien yang salah? Bagaimana memastikan setiap peserta benar-benar melatih model, bukan menjiplak hasil orang lain?
SN3 menyelesaikan dua masalah ini dengan dua komponen utama: SparseLoCo dan Gauntlet.
SparseLoCo menyelesaikan masalah kecekapan komunikasi. Latihan terdistribusi tradisional memerlukan penyegerakan gradien penuh pada setiap langkah, yang menghasilkan jumlah data yang sangat besar. Pendekatan yang digunakan SparseLoCo ialah: setiap nod menjalankan 30 langkah pengoptimuman tempatan (AdamW), kemudian menghantar "gradien palsu" yang telah dikompresi kepada nod lain. Kaedah kompresi termasuk sparsifikasi Top-k (hanya mengekalkan komponen gradien paling penting), umpan balik ralat (menyimpan bahagian yang dibuang dan mengumpulkannya untuk langkah seterusnya), serta kuantisasi 2 bit. Nisbah kompresi akhir melebihi 146 kali.
Dengan kata lain, apa yang dahulu memerlukan penghantaran 100MB kini cukup dengan kurang daripada 1MB.
Ini memungkinkan sistem untuk mengekalkan penggunaan pengiraan pada sekitar 94.5% di bawah batasan bandwidth internet biasa (hulu 110 Mbps, hilir 500 Mbps) — 20 nod, setiap nod dengan 8 unit B200, dan setiap putaran komunikasi hanya mengambil masa 70 saat.
Gauntlet menyelesaikan masalah kepentingan yang selaras. Ia beroperasi di atas blokchain Bittensor (Subnet 3), bertanggungjawab untuk mengesahkan kualiti pseudo-gradien yang diserahkan oleh setiap nod. Cara spesifiknya ialah: menguji dengan sekumpulan kecil data untuk mengukur "sejauh mana kerugian model berkurang apabila menggunakan gradien nod ini", hasilnya dipanggil LossScore. Sistem juga memeriksa sama ada nod tersebut sedang melatih diri menggunakan data yang telah dialokasikan kepadanya—jika satu nod menunjukkan peningkatan kerugian yang lebih baik pada data rawak berbanding data yang telah dialokasikan kepadanya, ia akan diberi skor negatif.
Pada akhirnya, hanya gradien dari nod dengan skor tertinggi dalam setiap putaran yang dipilih untuk penggabungan, sementara nod-nod lain dikeluarkan dari putaran tersebut. Peserta tambahan akan diisikan secara sewaktu-waktu untuk memastikan sistem tetap stabil. Sepanjang proses pelatihan, purata 16.9 nod per putaran mempunyai gradien yang dimasukkan ke dalam penggabungan, dengan lebih daripada 70 ID nod unik yang telah menyertai.
Narratif nilai AI terdesentralisasi sedang mengalami perubahan mendasar
Dari perspektif teknikal dan industri, arah yang diwakili oleh Covenant-72B mempunyai beberapa makna yang sebenar.
Pertama, mematahkan anggapan bahawa "latihan teragih hanya sesuai untuk model kecil". Walaupun masih jauh dari model terkini, ia membuktikan skalabiliti arah ini.
Kedua, penyertaan tanpa kebenaran adalah praktikal dan boleh dilaksanakan. Ini telah diabaikan. Projek latihan terdistribusi sebelum ini bergantung pada senarai putih—hanya peserta yang telah disahkan yang boleh menyumbang kuasa pengiraan. Dalam latihan SN3 ini, sesiapa sahaja yang memiliki kuasa pengiraan yang mencukupi boleh menyambung, dan mekanisme pengesahan bertanggungjawab untuk menyaring sumbangan jahat. Ini merupakan langkah nyata menuju “pengusangan sejati”.
Ketiga, mekanisme dTAO Bittensor memungkinkan penemuan nilai pasaran untuk sub-jaringan. dTAO membolehkan setiap sub-jaringan mengeluarkan token Alpha sendiri, membolehkan pasaran menentukan sub-jaringan mana yang mendapat lebih banyak pelepasan TAO melalui mekanisme AMM. Ini memberikan mekanisme penangkapan nilai yang kasar tetapi berkesan kepada sub-jaringan seperti SN3 yang telah menghasilkan hasil nyata. Tentu saja, mekanisme ini juga mudah dipengaruhi oleh naratif dan emosi, dan kualiti hasil latihan LLM sukar dinilai secara bebas oleh peserta pasaran biasa.
Keempat, implikasi politik-ekonomi pelatihan AI terdesentralisasi. Jack Clark dalam Import AI meningkatkan isu ini ke tahap “siapa yang memiliki masa depan AI”. Pelatihan model terkini kini dikuasai oleh sedikit institusi yang memiliki pusat data berskala besar, bukan hanya masalah perniagaan, tetapi juga masalah struktur kuasa. Jika pelatihan terdistribusi dapat terus mencapai kemajuan teknikal, ia berpotensi membentuk ekosistem pembangunan yang benar-benar terdesentralisasi untuk beberapa jenis model (seperti model terkini berskala kecil dalam bidang tertentu). Namun, prospek ini masih jauh dari kenyataan pada masa kini.
Ringkasan: Satu tonggak sejarah yang sebenar, serta sekumpulan masalah yang sebenar
Huang Renxun mengatakan ini seperti "Folding@home versi moden". Folding@home telah memberikan sumbangan nyata dalam bidang simulasi molekul, tetapi ia tidak mengancam kedudukan utama perusahaan farmasi besar dalam penyelidikan dan pembangunan. Perbandingan ini sangat tepat.
SN3 telah melaksanakan protokol dan mengesahkan arah yang mungkin untuk latihan terdistribusi. Namun, dari sudut pandang teknikal dan industri, di sebalik pencapaian ini masih terdapat banyak isu yang jarang ada yang bersedia membincangkan secara serius:
MMLU sendiri juga merupakan ukuran yang kontroversial di kalangan akademik, dengan risiko kebocoran soal dan jawapan piawaian terbuka ke dalam set latihan. Lebih penting lagi ialah pemilihan garis dasar perbandingan: model yang dibandingkan dalam kertas ini, LLaMA-2-70B dan LLM360 K2, adalah model lama dari tahun 2023 hingga 2024, manakala skor 65 hingga 70 dalam tempoh yang sama dianggap sebagai tahap menengah ke bawah dan permulaan apabila dibandingkan dengan Grok dan DouBao, serta dianggap sangat tertinggal menurut Claude. Jika diletakkan dalam senarai dinamik atau piawaian generasi baharu yang direka untuk menahan pencemaran, kesimpulannya mungkin akan lebih jujur.
Yang lebih penting, data berkualiti tinggi yang menentukan had kemampuan model—data perbualan, kod, penurunan matematik, dan literatur saintifik—sebahagian besarnya berada di tangan syarikat-syarikat besar, institusi penerbitan, dan pangkalan data akademik. Kuasa pengiraan telah didemokratisasikan, tetapi sisi data masih berstruktur oligopoli, dan kontradiksi ini belum pernah dibincangkan.
Mengenai keselamatan, penyertaan tanpa kebenaran bermaksud anda tidak tahu siapa di sebalik lebih daripada 70 nod tersebut, atau data apa yang mereka gunakan untuk melatih. Gauntlet boleh menyaring gradien yang jelas tidak normal, tetapi tidak mampu menghalang racun data yang halus—jika satu nod secara sistematik melatih lebih banyak pusingan dalam arah kandungan berbahaya tertentu, perubahan gradien yang dihasilkan cukup halus untuk lulus pemeriksaan skor kerugian, tetapi menyebabkan pergeseran berterusan terhadap tingkah laku model. Masalah akhirnya ialah: dalam skenario yang memerlukan kepatuhan dan keselamatan tinggi seperti kewangan, perubatan, dan undang-undang, penggunaan model yang dilatih oleh beberapa nod anonim dengan sumber data yang tidak dapat dilacak akan membawa risiko apa?
Masih ada satu masalah struktural yang perlu dinyatakan secara terus terang: Covenant-72B sendiri adalah sumber terbuka di bawah lesen Apache 2.0 dan tidak menggunakan token SN3. Memegang token SN3 bererti anda berkongsi keuntungan emisi yang dihasilkan secara berterusan daripada model-model baru yang dihasilkan oleh sub-jaringan ini, bukan keuntungan langsung daripada penggunaan model tersebut. Rantai nilai ini bergantung kepada pengeluaran latihan yang berterusan dan kelancaran mekanisme emisi keseluruhan rangkaian Bittensor. Jika latihan di masa depan terhenti, atau kualiti hasil latihan baru tidak memenuhi jangkaan, logik penilaian token akan menjadi lemah.
Senarai soalan-soalan ini bukan untuk menyangkal makna Covenant-72B. Ia membuktikan bahawa sesuatu yang sebelum ini dianggap mustahil boleh dilakukan, dan fakta ini tidak akan hilang. Tetapi, melakukan sesuatu dan maksudnya adalah dua perkara yang berbeza.
Token SN3 meningkat 440% dalam sebulan terakhir. Jarak di antara keduanya mungkin bukan sekadar spekulasi, tetapi lebih kepada kecepatan naratif yang selalu lebih pantas daripada kecepatan realiti. Samada jarak ini akhirnya akan diisi oleh realiti atau diserap melalui penyesuaian pasaran, bergantung kepada apa yang sebenarnya akan diberikan oleh pasukan Covenant AI seterusnya.
Perlu diperhatikan bahawa Grayscale telah mengemukakan permohonan ETF TAO pada Januari 2026, menandakan isyarat masuknya modal institusi ke segmen ini. Selain itu, pada Disember 2025, Bittensor akan mengurangkan pelepasan harian TAO separuhnya, dan pengetatan struktural di sisi bekalan masih berterusan.
Pautan rujukan:
https://arxiv.org/pdf/2603.08163
https://importai.substack.com/p/importai-449-llms-training-other
https://docs.tplr.ai/
https://systems-analysis.ru/int/MMLU_Benchmark_%E2%80%94_MMLU_%E5%9F%BA%E5%87%86%E6%B5%8B%E8%AF%95