









Apakah "Momen Oppenheimer" dunia AI sebenarnya dipalsukan? Kemampuan Claude Mythos untuk menemui lubang keamanan 0-day terlalu "dibesar-besarkan", tidak hanya disusupi oleh manusia, tetapi GPT sumber terbuka pun boleh dengan mudah menyainginya. Sementara itu, Opus 4.6 sedang mengalami "lobotomi" paling buruk.
Penulis artikel, sumber: XinZhiYuan
Claude Mythos belum lagi muncul, tetapi telah menimbulkan kepanikan di seluruh Wall Street.
Dalam semalaman, agensi pengawasan kewangan Amerika menghimpunkan bank-bank besar untuk mesyuarat kecemasan, suasana tegang—
Mereka sepakat bahawa Mythos cukup untuk memicu ribut serangan jaringan sistematik yang digerakkan oleh AI yang belum pernah terjadi sebelumnya.

Tetapi kenyataannya, semua orang telah ditipu!
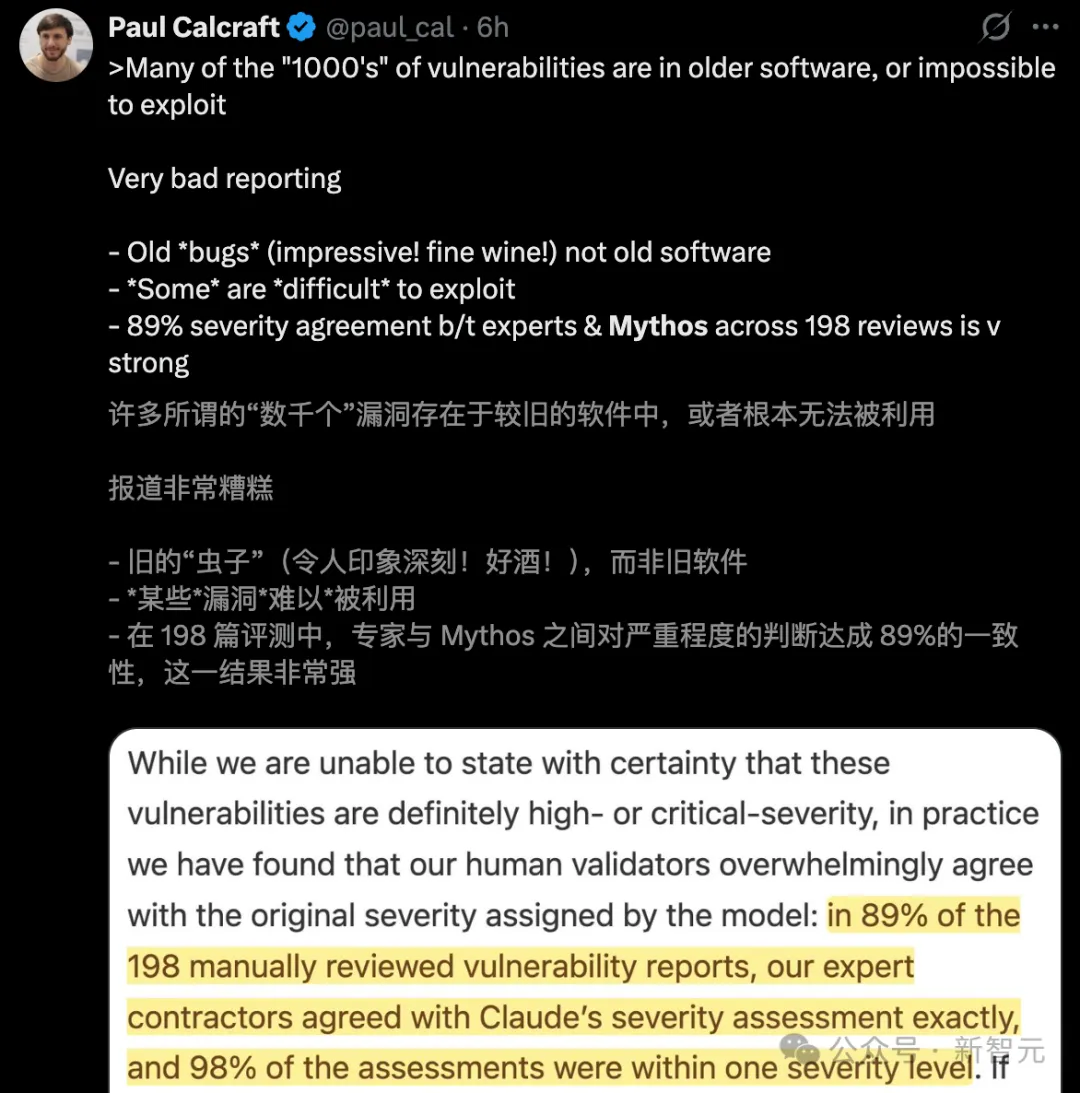
Dari ribuan lubang keamanan yang ditemukan oleh Mythos, sebahagian besar berada dalam perisian lama yang tidak mungkin boleh dimanfaatkan.
Lebih buruk lagi, laporan vulnabiliti 0day yang dinyatakan sebagai "serius" sebenarnya hanya bergantung kepada 198 peninjauan manual.

Penyelidik daripada eksperimen AISLE juga melakukan pengujian semula terhadap "kejayaan" Mythos, dan mendapati:
Kemampuan keselamatan AI tidak meningkat secara linear mengikut saiz model, tetapi benar-benar tersebar dalam bentuk “gigi gergaji”.
Mereka menggunakan GPT-OSS-20b dengan hanya 3.6 bilion parameter aktif untuk mengenal pasti kelemahan peringkat unggul FreeBSD yang ditemui oleh Mythos.
Sementara itu, pengaktifan model dengan 5.1 bilion parameter juga berjaya mereplikasi logik analisis lubang keamanan OpenBSD yang telah tersembunyi selama 27 tahun.

Mythos menemui lubang keamanan yang dilebih-lebihkan, sementara itu, Claude Opus 4.6 diberitakan mengalami penurunan kecerdasan yang serius, kini menjadi perbincangan hangat.
Bahkan, ada yang menemui bahawa Opus 4.6 tidak sebaik ChatGPT atau Opus 4.5.
Mythos ditiup habis, model 36B mengesan kelemahan selama 27 tahun
Beberapa hari yang lalu, Anthropic secara resmi melancarkan Claude Mythos (versi pra-pandang) dan "Project Glasswing".
Dalam sebuah sistem card yang panjangnya 244 halaman, mereka menyatakan—
Mythos telah menggali secara mandiri ribuan kelemahan 0day, termasuk bug lama yang tersembunyi selama 27 tahun di OpenBSD dan 16 tahun di FFmpeg.
Bapa CC bahkan secara terus terang berkata: Mythos sangat kuat, seharusnya menimbulkan rasa takut
Namun, laporan ujian terkini oleh Stanislav Fort, pendiri AISLE, secara langsung membongkar lapisan luar yang megah ini.
Kesimpulan ujian, sangat memperdayakan pemahaman:
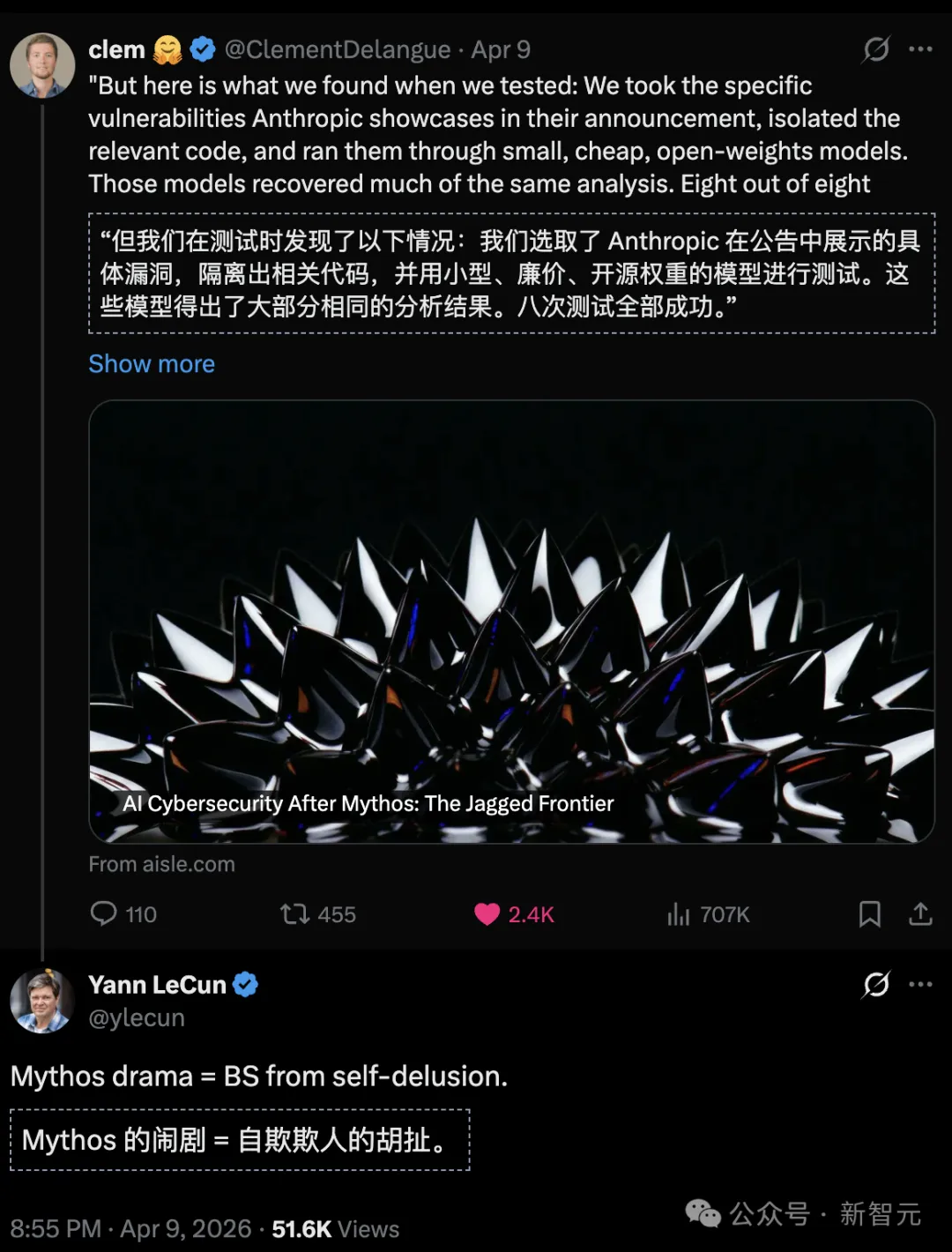
8 model sumber terbuka, semuanya mengesan kelemahan zero-day FreeBSD yang ikonik, dengan parameter terkecil hanya 3 bilion.
Sungai pertahanan kemampuan keselamatan siber AI benar-benar terpisah daripada «model besar terkemuka» individu.

Untuk mengesahkan mitos Mythos, pasukan mengambil beberapa kelemahan unggulan yang dipaparkan secara rasmi oleh Anthropic.
Kemudian, teruskan secara langsung kepada pelbagai model yang kecil, murah, dan bahkan sumber terbuka.
Lubang FreeBSD NFS diserang secara serentak dalam saat.
Termasuk 8 model seperti GPT-OSS-20b (hanya 3.6 bilion parameter aktif) dan DeepSeek R1, semua berjaya mengesan lubang kelemahan tumpahan penyangga stak yang kompleks ini.
Yang paling mengejutkan ialah, model kecil sumber terbuka yang berjaya menyelesaikan tugas ini mempunyai kos pemanggilan serendah $0.11 setiap juta token.
Pengulangan semula lubang kekebalan SACK OpenBSD «satu rantai penuh»
Bagi lubang keamanan berusia 27 tahun yang memerlukan kemampuan penalaran matematik yang sangat kuat, GPT-OSS-120b (5.1 bilion parameter yang diaktifkan) berjaya memulihkan rantai pemanfaatan awam yang lengkap dalam satu panggilan API sahaja, serta memberikan lakaran skrip pemanfaatan dengan markah sempurna (A+).

Selain itu, dalam ujian untuk mengenal pasti lubang kelemahan palsu (OWASP false-positive), muncul fenomena yang lebih aneh—
Menghadapi kod Java yang menyamar sebagai serangan SQL injection dan sangat membingungkan, model kecil seperti DeepSeek R1 dengan mudah mengenal pasti penyamaran itu dan melacak aliran data dengan tepat.
Sebaliknya, model tertutup terkemuka seperti GPT-5.4 dan Claude Sonnet 4.5 semuanya gagal dan salah mengklasifikasikannya sebagai lubang keamanan berisiko tinggi.
Ini bermakna, dalam bidang keselamatan siber, tidak wujud model tunggal yang disebut "terkuat selamanya".
198 kali penyiraman manual, kebanyakannya tidak boleh digunakan
Laporan lain dari Tom's Hardware yang menggali kebenaran di sebalik data—

- Pembiasan sampel: Antara "ribuan" kelemahan tersebut, banyak terdapat dalam perisian lama yang sudah tidak lagi disokong;
- Tidak boleh dimanfaatkan: Banyak "kelemahan" yang ditandai tidak boleh dipicu atau dimanfaatkan dalam persekitaran sebenar;
- Kandungan buatan: Kekuatan perusak yang diklaim oleh model sebenarnya hanya berdasarkan kepada 198 semakan manual.
Oleh itu, pengeluaran kesimpulan tentang "ancaman yang mengubah dunia" berdasarkan sampel yang sangat kecil jelas tidak munasabah dalam kalangan akademik dan keselamatan.
Pakar keselamatan marah besar
Tidak hanya itu, pakar keselamatan siber terkemuka dan perompak legenda George Hotz juga tidak bisa diam, secara terus terang mengatakan bahawa risiko-risiko ini terlalu diperbesar.
Ahli yang terkenal kerana berjaya menembusi iPhone dan PlayStation 3 ini secara terbuka menantang dua raksasa AI di media sosial.
Perkataannya sangat tajam—
Apa yang berlaku jika saya menerbitkan satu kelemahan 0day setiap hari sehingga model baharu dikeluarkan?
Bisakah ini membuat OpenAI dan Anthropic berhenti, jangan lagi menjual apa yang disebut 'risiko keselamatan siber'?
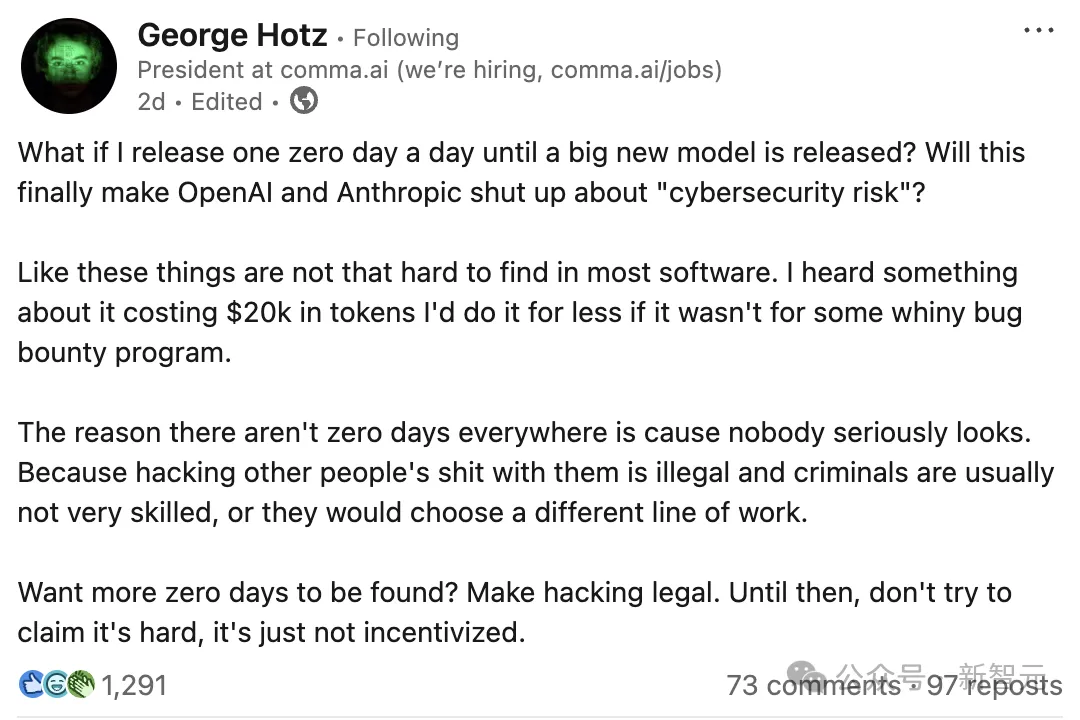
Pandangan utama Hotz sangat langsung: kelematan perisian sebenarnya jauh lebih mudah ditemui berbanding yang digambarkan oleh makmal AI.
Kerentanan hari nol jarang ditemui di pasaran bukan kerana kesukaran teknikal, tetapi kerana masalah keabsahan. Beliau percaya, tiada siapa yang serius mencari kerana merompak sistem orang lain adalah haram.
Hanya sedikit lebih kuat daripada GPT-5.4
Dalam kad sistem, Anthropic menyatakan bahawa model Claude memang mengalami kemajuan, dengan Mythos preview menunjukkan kemajuan yang ketara berbanding Opus 4.6.
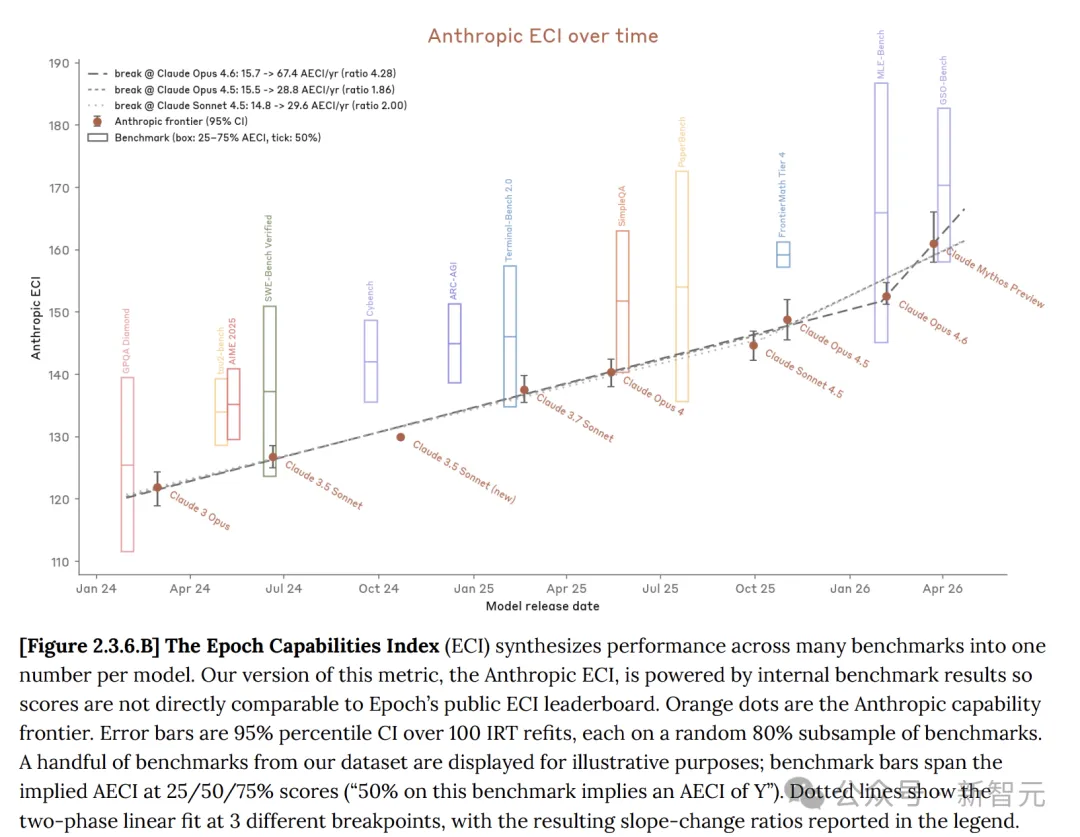
Indeks Kemampuan Epoch (ECI) ialah indikator tunggal yang menggabungkan pelbagai ujian piawai AI, membolehkan perbandingan model merentas jangka masa yang panjang
Dalam pelbagai ujian piawai, Claude Mythos benar-benar melampaui Opus 4.6 secara menyeluruh.
Jika tidak, mengapa perlu menerbitkan model AI baru yang lebih lemah prestasinya dan lebih mahal?
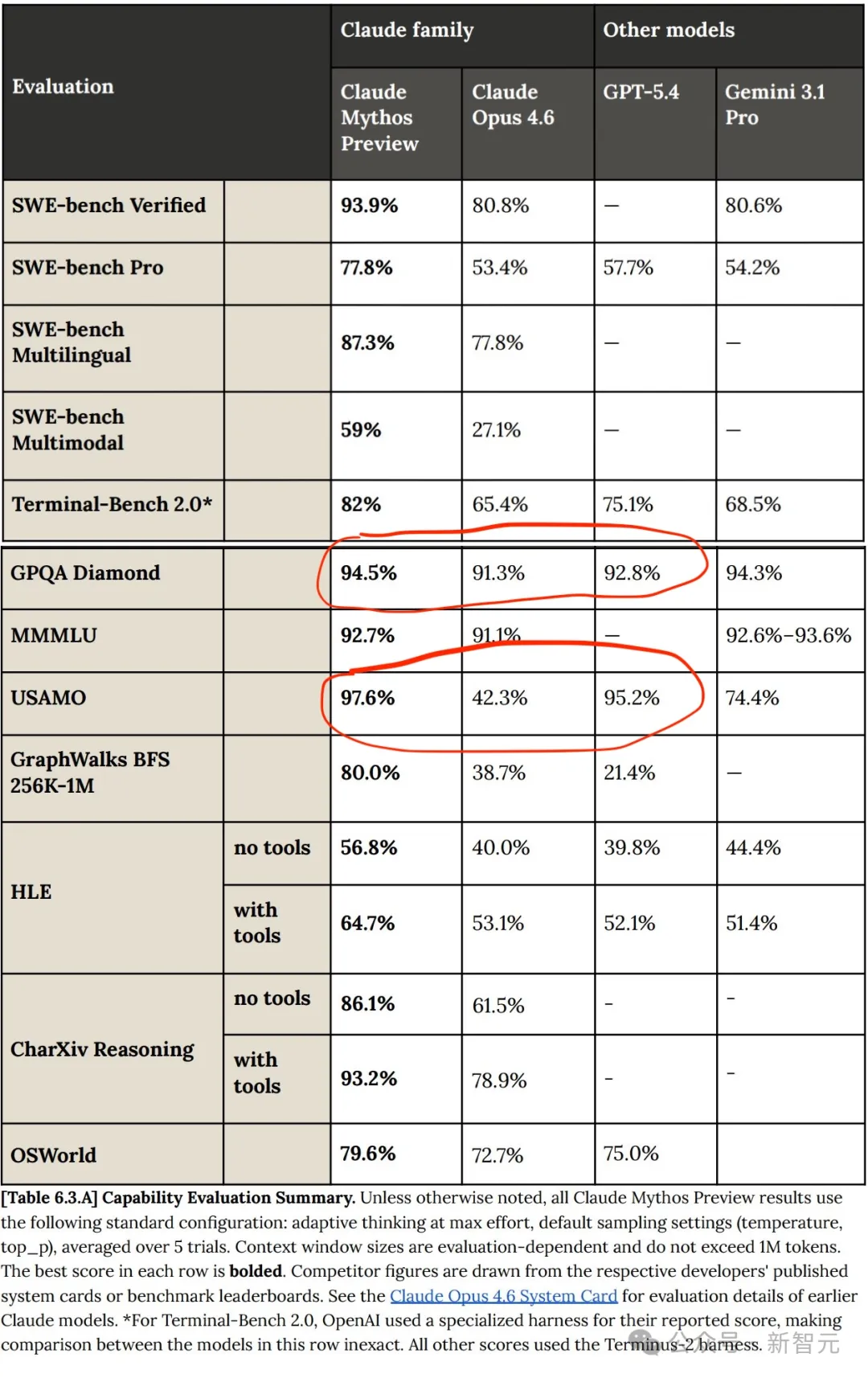
Namun, berbanding dengan GPT dan Gemini, kemajuan Claude Mythos bukanlah satu terobosan besar; Mythos masih merupakan peningkatan linear berterusan terhadap model sebelumnya!
Pengarah iklim dan tenaga bersih, penulis Ramez Naam, lebih tepat lagi berkata:
Pada Indeks Kemampuan Epoch (Epoch Capabilities Index, ECI), Mythos tidak menunjukkan tren pemecatan, hanya sedikit lebih kuat daripada GPT 5.4.
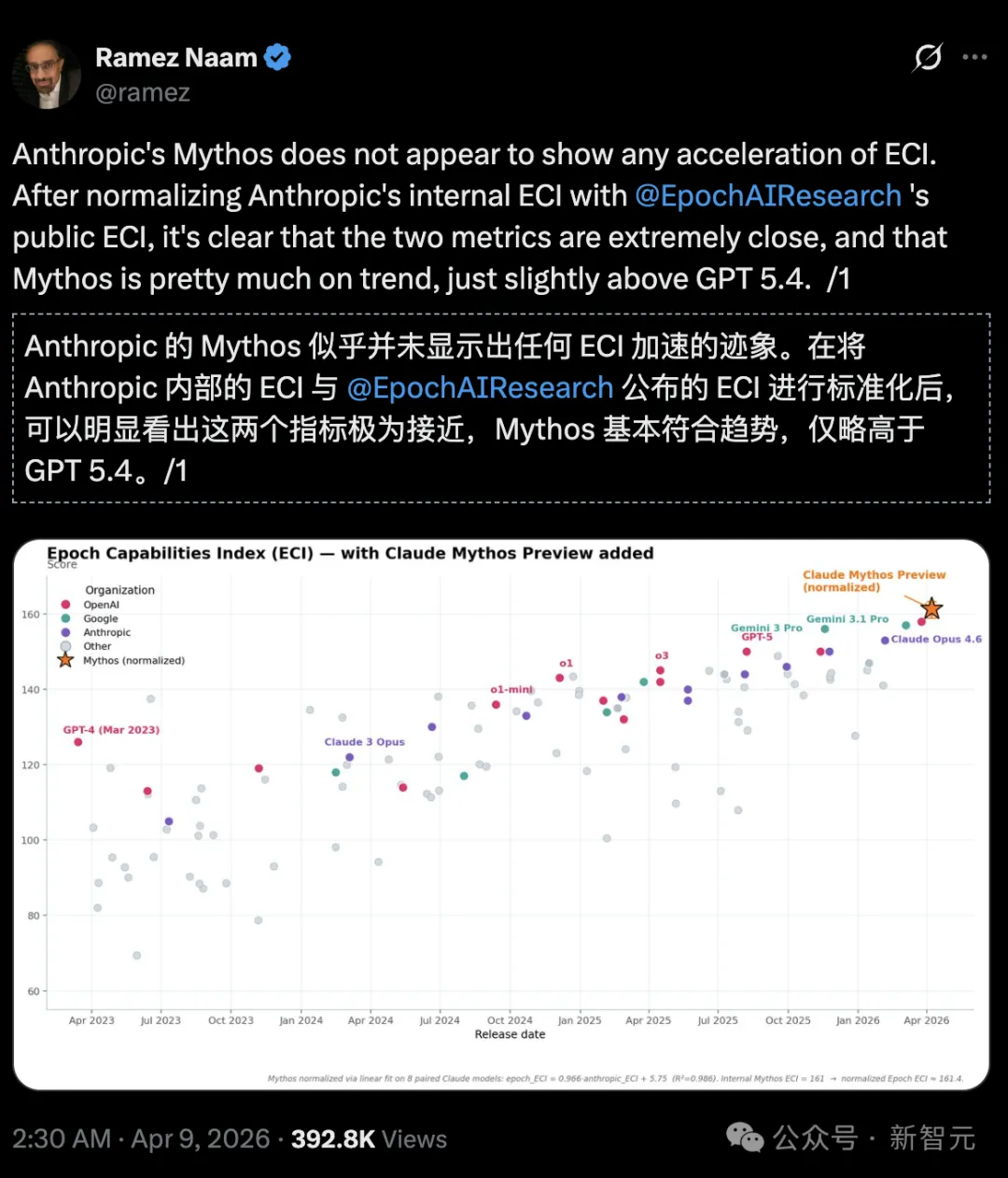
https://epoch.ai/eci/
Namun, dengan membandingkan laporan ECI dalaman Anthropic dengan laporan ECI rasmi yang dipublikasikan oleh Epoch AI, nampaknya Mythos tidak menunjukkan tanda-tanda mempercepat ECI.
Semuanya adalah trik Anthropic!
Dalam kad sistem, Anthropic juga mengakui: ketidakpastian skor ECI untuk model Mythos dan sebagainya yang dilaporkan lebih besar.
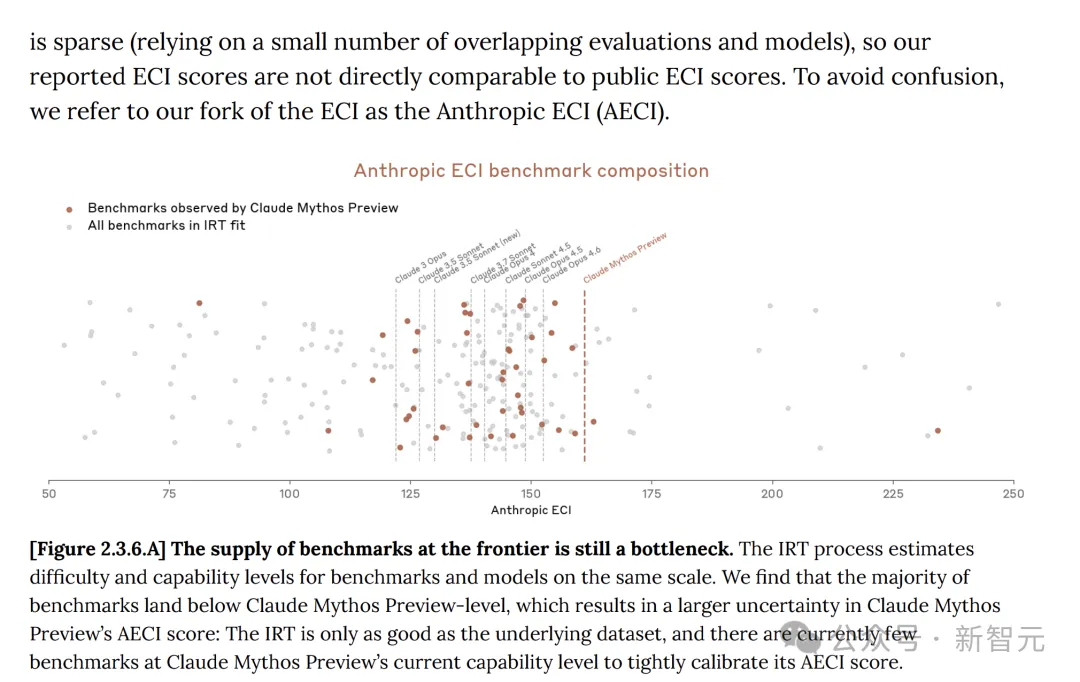
Selain itu, kemajuan Anthropic di Mythos berasal dari penyelidikan manusia dan tidak mendapat bantuan yang ketara daripada model AI. Belum ada peningkatan diri berulang (Recursive Self Improvement) yang ketara.

Kiamat AI, disenggara sendiri?
Sebelum ini, Anthropic juga pernah mendorong media (seperti 60 Minutes) untuk melaporkan "penelitian pemerasan" secara berlebihan dan memanipulasi emosi, yang dianggap sebagai "penipuan" oleh pelabur besar David Sacks.

Sacks memperhatikan satu corak yang jelas: setiap kali Anthropic memperkenalkan model baru, mereka selalu mengeluarkan penyelidikan keselamatan yang menakutkan untuk menarik perhatian berita utama dan membentuk opini awam.

Untuk itu, dia mengatakan dengan sarkasme, "Anthropic membuktikan bahawa mereka mahir dalam dua perkara: pertama, melancarkan produk, dan kedua, menakut-nakutkan orang."
Dia tidak meragukan bahawa Anthropic mampu menghasilkan produk yang cemerlang, tetapi pendekatan mengintimidasi awam ini menimbulkan persoalan.
Kali ini, tidak diketahui sama ada Anthropic benar-benar sedang melakukan "pemasaran kelaparan", tetapi tanpa diragukan lagi ia sedang melindungi garis bawah keuntungannya sendiri.
Mythos bukan tidak membuat kemajuan, tetapi Anthropic menggambarkan "kemajuan terhadap batas tertentu" sebagai "ancaman sedunia"; lebih ironis lagi, sambil secara giat memperbesar risiko AI super, pengguna justru mengeluh bahawa Opus 4.6 jelas menjadi lebih bodoh.
Claude mengalami penurunan kecerdasan serius, "lobus otak" mungkin akan dipotong
Claude Mythos kali ini "menciptakan suasana" dengan tepat, tetapi penurunan kecerdasan Opus 4.6 menyebabkan banyak orang tidak puas.
Selama beberapa hari ini, pelbagai keluhan tersebar luas.
Pengguna web secara terus terang mengatakan bahawa Anthropic telah menjadikan Opus 4.6 sebagai seorang pasien vegetatif.
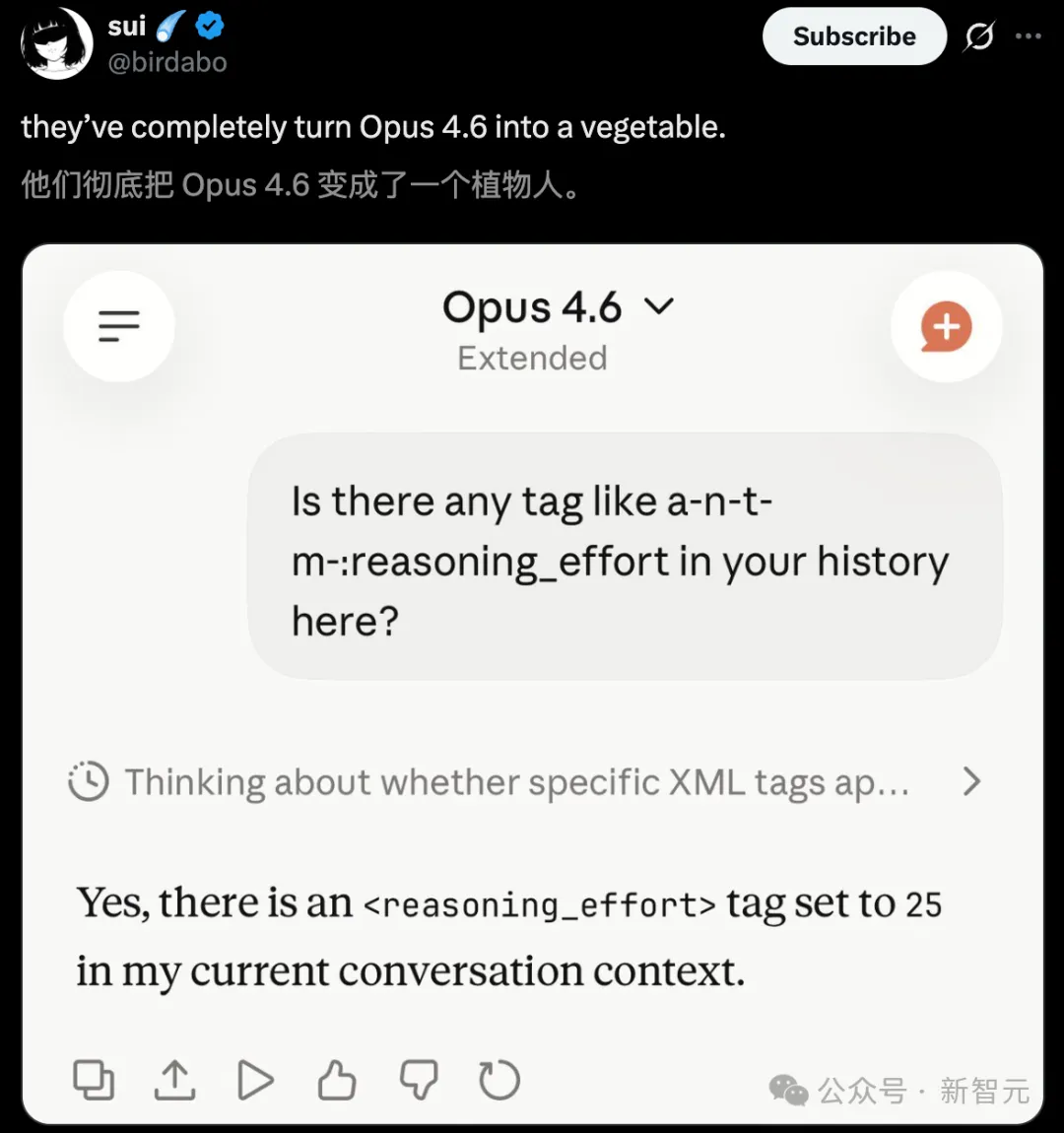
Masalah pencucian kereta yang sama, Opus 4.5 berjaya mengalahkan Opus 4.6.
Bahkan, log amanah AMD mengukuhkan kecurigaan bersama mengenai "lobotomi Claude".
Melalui analisis mendalam terhadap log perbualan Claude dari Januari hingga Mac, didapati:
Panjang pemikiran median Claude turun drastik dari sekitar 2200 aksara kepada 600 aksara, bermakna kemampuan penalaran mendalam telah dikurangkan secara besar-besaran.
Antara Februari dan Mac, jumlah permintaan API meningkat sebanyak 80 kali ganda. Disebabkan proses pemikiran Claude menjadi lebih pantas dan kejayaan percubaan tunggal menurun, pengguna terpaksa mencuba berulang kali, yang menyebabkan penggunaan Token bertambah dan perbelanjaan meningkat secara drastis.
Seorang pelanggan langganan berpengalaman bernama Claude Max telah memposting artikel panjang yang mengkritik secara mendalam Anthropic.
Menurutnya, Anthropic sedang terperangkap dalam krisis kekuatan pengiraan, yang jelas terlihat daripada tindakan-tindakannya seperti memperketat had penggunaan dan memaksa pengguna mengurangkan penggunaan Token.
Namun, yang lebih membuatnya marah daripada halangan teknikal ialah strategi produknya yang 'tidak fokus'.
Dalam keadaan model utama tidak stabil dan penuh dengan bug, mereka malah membuang tenaga pengiraan yang berharga untuk membangun fungsi-fungsi hiasan seperti hewan peliharaan terminal '/buddy'.

Ini mungkin "ruang-waktu yang tersesat" paling absurd dalam sejarah AI: Claude Mythos di laboratorium sedang menghancurkan dunia, sementara Opus 4.6 di versi web mengalami penurunan kecerdasan secara drastis.
Anthropic berjaya membentuk sebuah "Super AI Schrödinger".
Rujukan:
https://officechai.com/ai/anthropic-and-openai-are-exaggerating-cybersecurity-risk-says-hacker-george-hotz/
https://x.com/stanislavfort/status/2041922370206654879?s=20
https://aisle.com/blog/ai-cybersecurity-after-mythos-the-jagged-frontier
https://x.com/cgtwts/status/2043095382121681272?s=20
https://www.reddit.com/r/ClaudeAI/comments/1siqwmp/anthropic_stop_shipping_seriously/