










Pandangan ini bukanlah tanpa dasar. Dia melihat sejumlah tolok ukur awam dan mendapati bahawa AI membuat kemajuan pantas dalam tugas-tugas berkaitan penyelidikan AI.
Sebagai contoh, CORE-Bench menilai kemampuan AI untuk melaksanakan kertas penyelidikan orang lain, yang merupakan aspek penting dalam penyelidikan AI.
PostTrainBench menguji sama ada model yang kuat boleh menyesuaikan sendiri model sumber terbuka yang lebih lemah untuk meningkatkan prestasi, yang merupakan subset penting dalam tugas penyelidikan AI.
MLE-Bench berdasarkan tugas pertandingan Kaggle sebenar, yang memerlukan pembinaan aplikasi pembelajaran mesin yang pelbagai untuk menyelesaikan masalah tertentu. Selain itu, benchmark pengkodean terkenal seperti SWE-Bench juga menunjukkan kemajuan serupa.
Jack Clark menggambarkan fenomena ini sebagai tren naik ke kanan bersifat "fraktal", di mana kemajuan bermakna dapat dilihat pada resolusi dan skala yang berbeza. Beliau percaya bahawa AI sedang secara beransur-ansur mendekati kemampuan untuk mengautomasikan pembangunan end-to-end, dan apabila dicapai, AI akan mampu membina sistem penggantinya sendiri, memulakan kitaran peningkatan diri.

Pernyataan ini menimbulkan banyak perbincangan di media sosial.
Sebahagian orang melihatnya sebagai langkah penting menuju ASI dan titik kelainan, yang berpotensi mengubah ritme perkembangan teknologi secara drastis.

Namun, terdapat suara yang berbeza.
Profesor Sains Komputer Universiti Washington, Pedro Domingos, menunjukkan bahawa sistem AI telah memiliki kemampuan untuk "membina diri sendiri" sejak bahasa LISP ditemukan pada dekad 1950-an; masalah sebenarnya ialah sama ada ia boleh mendapat pulangan berterusan, dan sehingga kini tiada bukti jelas yang menyokong perkara ini.

Seorang pengguna bertanya, kebarangkalian meningkat tiba-tiba sebanyak 30% dari tahun 2027 hingga 2028, yang mengisyaratkan bahawa kemampuan AI mungkin mengalami lompatan besar mendadak pada akhir 2027. Apakah tonggak atau peristiwa spesifik yang akan menyebabkan kebarangkalian peningkatan diri berulang AI meningkat secara ketara dalam tempoh singkat?

Pengguna lain juga menyatakan bahawa Jack Clark ialah pengurus hubungan awam baharu Anthropic, yang merupakan sebahagian daripada strategi baharu mereka: Kami bukanlah orang yang menakut-nakutkan; terdapat banyak kertas kerja yang membuktikan perkara-perkara yang selama ini kami beri amaran kepada anda.
Jack Clark menulis artikel panjang yang menjelaskan secara terperinci dalam newsletter Import AI 455.
Seterusnya, kita akan melihat seluruh artikel ini.
Sistem AI akan segera bermula membina dirinya sendiri, apa maksudnya ini?
Clark menyatakan bahawa beliau menulis artikel ini kerana setelah mengkaji semua maklumat awam yang boleh diperoleh, beliau terpaksa membentuk satu penilaian yang tidak mudah: kemungkinan munculnya pembangunan AI tanpa campur tangan manusia sebelum akhir 2028 sudah cukup tinggi, mungkin melebihi 60%.
AI yang dikatakan tanpa campur tangan manusia merujuk kepada sistem AI yang cukup kuat: ia tidak hanya boleh membantu manusia dalam penyelidikan, tetapi juga berpotensi menyelesaikan proses penting pembangunan secara autonomi, bahkan membina sistem generasi seterusnya sendiri.
Dalam pandangan Clark, ini jelas merupakan perkara besar.
Dia mengakui bahawa dirinya juga sukar untuk sepenuhnya memahami makna perkara ini.
Ia disebut sebagai penghakiman yang tidak diingini kerana kesan di sebaliknya terlalu besar, membuatkan dia merasa sukar untuk menguasainya. Clark juga tidak pasti sama ada seluruh masyarakat sudah bersedia untuk menyambut perubahan mendalam yang dibawa oleh pengautomatan pembangunan AI.
Dia kini percaya bahawa manusia mungkin sedang hidup dalam titik masa yang istimewa: penyelidikan AI akan segera diotomatiskan secara end-to-end. Jika saat ini benar-benar tiba, manusia seperti telah melintasi Sungai Rubicon dan memasuki masa depan yang hampir tidak dapat diramalkan.
Clark menyatakan bahawa tujuan artikel ini adalah untuk menjelaskan mengapa dia percaya bahawa ke arah pemulaan pembangunan AI sepenuhnya automatik sedang berlaku.
Dia akan membincangkan beberapa kesan yang mungkin dibawa oleh tren ini, tetapi sebahagian besar artikel akan berfokus pada bukti yang menyokong penilaian ini. Mengenai kesan yang lebih mendalam, Clark merancang untuk terus mengkaji sepanjang sebahagian besar tahun ini.
Dari segi masa, Clark tidak percaya bahawa perkara ini akan benar-benar berlaku pada tahun 2026. Namun, beliau percaya bahawa dalam tempoh satu atau dua tahun ke depan, kita mungkin akan melihat kes di mana suatu model dilatih end-to-end untuk menghasilkan penerusnya sendiri. Sekurang-kurangnya pada aras model bukan terkini, kemungkinan besar akan muncul bukti konsep; manakala pada aras model terkini, kesukarannya akan lebih tinggi kerana kosnya sangat mahal dan bergantung kepada kerja intensif daripada ramai penyelidik manusia.
Penilaian Clark terutama berdasarkan maklumat awam: termasuk kertas kerja di arXiv, bioRxiv, dan NBER, serta produk yang telah diterapkan oleh syarikat AI terkini ke dalam dunia nyata. Berdasarkan maklumat ini, dia menyimpulkan bahawa automatikasi seluruh peringkat yang diperlukan untuk menghasilkan sistem AI semasa ini, terutamanya komponen kejuruteraan dalam pembangunan AI, pada dasarnya sudah tersedia.
Jika tren penskalaan berterusan, kita perlu mula bersiap menghadapi situasi di mana model akan menjadi cukup kreatif, tidak hanya mampu memperbaiki kaedah yang sudah diketahui secara automatik, tetapi juga menggantikan penyelidik manusia dalam mencadangkan arah penyelidikan baru dan idea orisinal, dengan sendirinya mendorong hadapan AI terus maju.
Singularity Encoding: Perubahan Kemampuan Seiring Masa
Sistem AI diwujudkan melalui perisian, dan perisian terdiri daripada kod.
Sistem AI telah mengubah cara penghasilan kod secara radikal. Terdapat dua tren berkaitan di sebaliknya: pada satu sisi, sistem AI semakin mahir dalam menulis kod dunia nyata yang kompleks; pada sisi lain, sistem AI juga semakin mahir dalam menggabungkan banyak tugas pengkodean linear tanpa bergantung banyak pada pengawasan manusia, seperti menulis kod terlebih dahulu, kemudian menguji.
Dua contoh klasik yang menunjukkan tren ini ialah SWE-Bench dan plot jangka masa METR.
Menyelesaikan masalah kejuruteraan perisian dunia nyata
SWE-Bench ialah ujian pemrograman yang digunakan secara meluas untuk menilai kemampuan sistem AI dalam menyelesaikan isu GitHub sebenar.
Apabila SWE-Bench dilancarkan pada akhir 2023, model yang paling cemerlang pada masa itu ialah Claude 2, dengan kejayaan keseluruhan hanya sekitar 2%. Manakala prestasi Claude Mythos Preview telah mencapai 93.9%, hampir mencapai sempurna dalam benchmark ini.
Tentu, semua benchmark itu sendiri pasti mempunyai kebisingan, jadi biasanya terdapat satu peringkat di mana apabila skor mencapai tahap tertentu, apa yang anda hadapi mungkin bukan batasan kaedah itu sendiri, tetapi batasan benchmark itu sendiri. Sebagai contoh, dalam set pengesahan ImageNet, kira-kira 6% daripada label adalah salah atau ambigu.
SWE-Bench boleh dianggap sebagai ukuran yang boleh dipercayai terhadap kemampuan pengaturan perisian umum, serta kesan AI terhadap kejuruteraan perisian. Clark menyatakan bahawa kebanyakan orang yang beliau temui di makmal AI terkini dan Silicon Valley kini hampir semuanya menulis kod sepenuhnya melalui sistem AI, dan semakin ramai yang mula menggunakan sistem AI untuk menulis ujian dan memeriksa kod.
Dengan kata lain, sistem AI sudah cukup kuat untuk mengautomasi satu komponen penting dalam penyelidikan AI dan mempercepat secara ketara semua penyelidik dan jurutera manusia yang terlibat dalam penyelidikan AI.
Mengukur kemampuan sistem AI dalam menyelesaikan tugas jangka panjang
METR telah membuat grafik untuk mengukur seberapa kompleks tugas yang boleh diselesaikan oleh AI. Kompleksiti di sini diukur berdasarkan berapa jam yang diperlukan oleh manusia yang mahir untuk menyelesaikan tugas-tugas tersebut.
Indikator paling penting ialah julat masa tugas yang berkaitan apabila sistem AI mencapai kebolehpercayaan 50% pada satu set tugas.
Pada titik ini, kemajuan sangat mengagumkan:
· Pada tahun 2022, tugas yang boleh diselesaikan oleh GPT-3.5 kira-kira setara dengan tugas yang memerlukan manusia 30 saat untuk menyelesaikannya.
· Pada tahun 2023, GPT-4 meningkatkan masa ini kepada 4 minit.
· Pada tahun 2024, o1 meningkatkan masa ini kepada 40 minit.
· Pada tahun 2025, GPT-5.2 High mencapai sekitar 6 jam.
· Pada tahun 2026, Opus 4.6 telah mendorong masa ini lebih jauh kepada sekitar 12 jam.
Ajeya Cotra, yang bekerja di METR dan telah lama memperhatikan ramalan AI, berpendapat bahawa tidak mustahil untuk sistem AI menyelesaikan tugas yang setara dengan 100 jam usaha manusia pada akhir tahun 2026.
Masa kerja bebas sistem AI telah meningkat secara ketara, dan sangat berkaitan dengan ledakan alat pengkodean agen. Alat pengkodean agen pada dasarnya adalah produkisasi sistem AI yang mampu menyelesaikan tugas menggantikan manusia: alat-alat ini boleh bertindak atas nama manusia dan meneruskan tugas secara relatif bebas dalam jangka masa yang panjang.
Ini juga kembali menunjuk kepada pembangunan AI sendiri. Dengan memerhatikan tugas harian banyak penyelidik AI, banyak tugas sebenarnya boleh dipecahkan menjadi tugas yang mengambil beberapa jam, seperti pembersihan data, membaca data, dan memulakan eksperimen.
Dan jenis pekerjaan ini kini telah jatuh dalam lingkup masa yang boleh dicakup oleh sistem AI moden.
Semakin mahir sistem AI, semakin mampu ia beroperasi secara bebas daripada manusia, dan semakin besar keupayaannya untuk membantu mengautomasi sebahagian kerja dalam pembangunan AI.
Faktor utama dalam penghantaran tugas terutamanya ada dua:
· Pertama, keyakinan anda terhadap kemampuan pihak yang diberi kuasa;
· Kedua, anda percaya bahawa pihak berkenaan mampu menyelesaikan kerja tersebut secara berdiri sendiri mengikut niat anda tanpa bergantung kepada pengawasan berterusan daripada anda.
Apabila pengguna memantau kemampuan AI dalam pemrograman, mereka akan mendapati bahawa sistem AI tidak hanya menjadi semakin mahir, tetapi juga mampu bekerja secara berdikari lebih lama tanpa perlu penyesuaian semula oleh manusia.
Ini juga sejalan dengan apa yang sedang berlaku di sekeliling kita, di mana jurutera dan penyelidik sedang menyerahkan semakin banyak tugas kepada sistem AI. Seiring dengan peningkatan kemampuan AI secara berterusan, tugas yang dipercayakan kepada AI menjadi semakin kompleks dan semakin penting.
AI sedang menguasai kemahiran saintifik penting yang diperlukan untuk pembangunan AI
Pertimbangkan bagaimana penyelidikan saintifik moden dijalankan—sebahagian besar kerja sebenarnya bermula dengan menentukan arah, mengenal pasti jenis maklumat empirikal yang ingin diperolehi; kemudian merekabentuk dan menjalankan eksperimen untuk menghasilkan maklumat tersebut; akhirnya, memeriksa kepatutan keputusan eksperimen.
Dengan kemampuan pengaturan AI yang terus meningkat, ditambah dengan kemampuan pemodelan dunia model bahasa besar yang semakin kuat, kini telah muncul sejumlah alat yang dapat membantu para saintis manusia mempercepat proses dan mengautomasi sebahagian peringkat dalam pelbagai skenario penyelidikan dan pembangunan.
Di sini, kita dapat mengamati kelajuan kemajuan AI dalam beberapa kemahiran saintifik utama, yang mana kemahiran-kemahiran ini sendiri merupakan bahagian penting dalam penyelidikan AI:
· Pertama, mengulangi keputusan penyelidikan;
· Kedua, menggabungkan teknologi pembelajaran mesin dengan kaedah lain untuk menyelesaikan masalah teknikal;
· Ketiga, mengoptimumkan sistem AI itu sendiri.
Mewujudkan seluruh kertas ilmiah dan menyelesaikan eksperimen berkaitan
Satu tugasan utama dalam penyelidikan AI ialah membaca kertas ilmiah dan mengulangi keputusan di dalamnya. Dalam hal ini, AI telah mencapai kemajuan ketara dalam serangkaian benchmark.
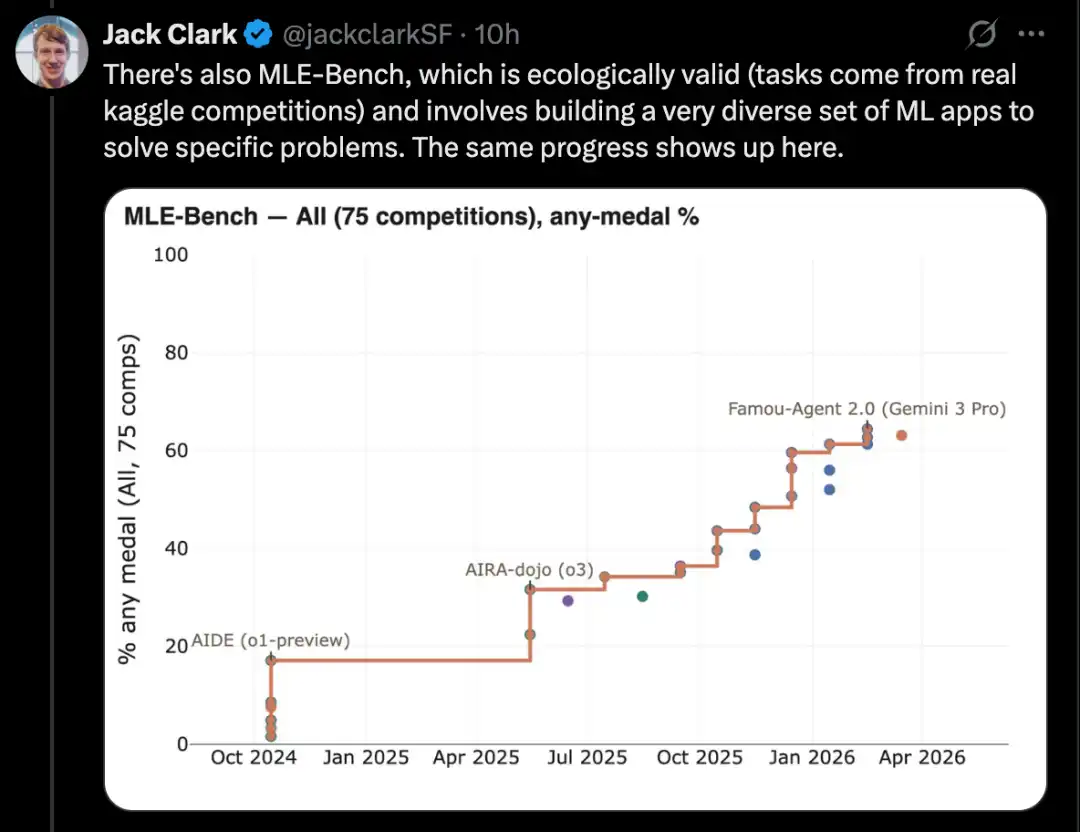
Satu contoh yang baik ialah CORE-Bench, iaitu Computational Reproducibility Agent Benchmark.
Benchmark ini memerlukan sistem AI untuk mereproduksi hasil dalam kertas ilmiah apabila diberikan kertas ilmiah tersebut beserta repositori kodnya. Secara khusus, Agen perlu memasang pustaka, pakej, dan ketergantungan yang berkaitan, menjalankan kod; jika kod berjalan berjaya, ia juga perlu mencari semua hasil output dan menjawab soalan dalam tugas tersebut.
CORE-Bench dicadangkan pada September 2024. Sistem terbaik pada masa itu ialah model GPT-4o yang berjalan di dalam scaffolding CORE-Agent. Pada set tugas paling sukar dalam benchmark ini, skornya kira-kira 21.5%.
Pada Disember 2025, seorang penulis CORE-Bench mengumumkan bahawa benchmark ini telah diselesaikan: model Opus 4.5 mencapai skor 95.5%.
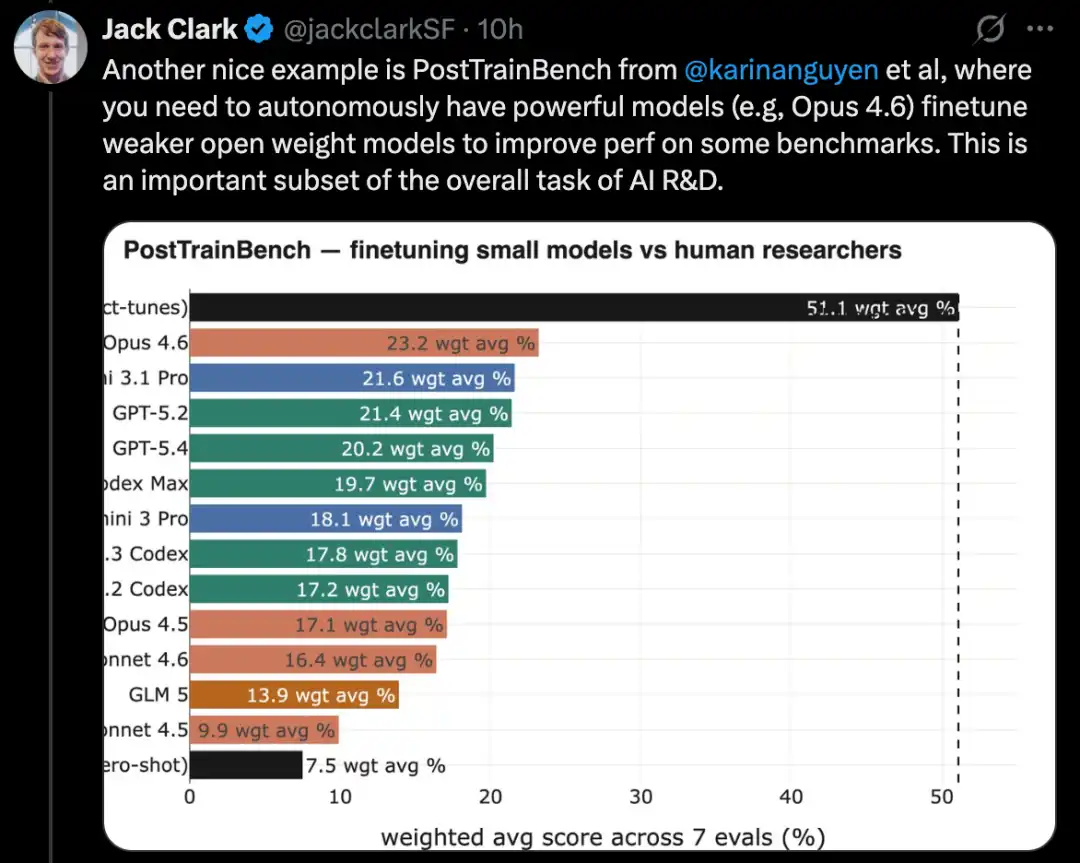
Bina sistem pembelajaran mesin yang lengkap untuk menyelesaikan masalah pertandingan Kaggle
MLE-Bench ialah benchmark yang dibina oleh OpenAI untuk menguji kemampuan sistem AI dalam menyertai pertandingan Kaggle dalam persekitaran luar talian.
Ia meliputi 75 jenis kompetisi Kaggle yang berbeza, yang merangkumi pelbagai bidang seperti pemprosesan bahasa semula jadi, penglihatan komputer, dan pemprosesan isyarat.
MLE-Bench dikeluarkan pada Oktober 2024. Semasa pelancaran, sistem terbaik ialah model o1 yang berjalan dalam agent scaffold, dengan skor 16.9%.
Pada Februari 2026, sistem terbaik telah berubah menjadi Gemini 3 yang berjalan di dalam agent harness dengan kemampuan carian, dengan skor 64.4%.
Reka bentuk Kernel
Tugas yang lebih sukar dalam pembangunan AI ialah pengoptimuman kernel. Pengoptimuman kernel merujuk kepada penulisan dan peningkatan kod aras bawah untuk memetakan operasi tertentu seperti pendaraban matriks ke peranti aras bawah dengan lebih cekap.
Pengoptimuman kernel adalah inti dalam pembangunan AI kerana ia menentukan kecekapan latihan dan inferens: di satu sisi, ia mempengaruhi sejauh mana anda dapat memanfaatkan kuasa pengiraan semasa membangunkan sistem AI; di sisi lain, selepas model selesai dilatih, ia juga menentukan sejauh mana anda boleh menukar kuasa pengiraan menjadi kecekapan inferens.
Dalam beberapa tahun terakhir, penggunaan AI dalam reka bentuk kernel telah berubah daripada satu arah kecil yang menarik kepada satu bidang penyelidikan yang sangat kompetitif, dengan munculnya beberapa benchmark. Namun, benchmark-benchmark ini belum terlalu popular, jadi kami sukar untuk memodelkan kemajuan jangka panjangnya dengan jelas seperti dalam bidang lain. Di sisi lain, kita boleh merasakan kelajuan kemajuan arah ini melalui beberapa penyelidikan yang sedang berlangsung.
Kerja berkaitan termasuk:
· Mencuba membina kernel GPU yang lebih baik menggunakan model DeepSeek;
Mengonversi modul PyTorch secara automatik kepada kod CUDA;
· Meta menggunakan LLM untuk menghasilkan kernel Triton yang dioptimasi secara automatik dan menghantar ke infrastruktur sendiri;
· Serta menyesuaikan model bobot sumber terbuka berdasarkan reka bentuk GPU kernel, contohnya Cuda Agent.
Perlu ditambahkan sedikit: reka bentuk kernel memang memiliki beberapa sifat yang sesuai untuk pembangunan yang didorong AI, seperti hasil yang mudah diverifikasi dan isyarat ganjaran yang lebih jelas.
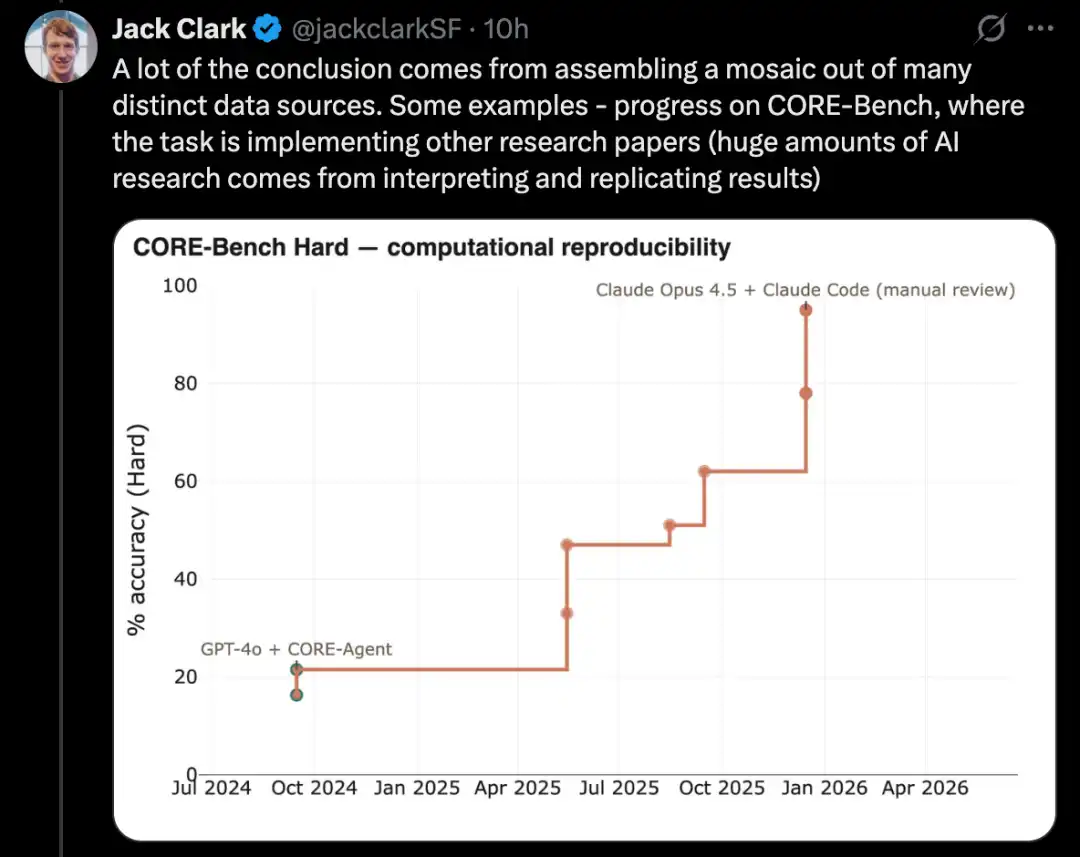
Menyesuaikan model bahasa melalui PostTrainBench
Versi yang lebih sukar bagi ujian semacam ini ialah PostTrainBench. Ia menguji sama ada model terkini yang berbeza boleh mengambil alih model berat sumber terbuka yang lebih kecil dan meningkatkan prestasi mereka pada beberapa benchmark melalui penyesuaian halus.
Salah satu kelebihan benchmark ini ialah ia mempunyai garis dasar manusia yang sangat kuat: versi instruct-tuned yang sedia ada untuk model kecil ini. Versi-versi ini biasanya dibangunkan oleh penyelidik AI manusia yang cemerlang di makmal terkini, telah diasah oleh penyelidik dan jurutera yang sangat berupaya, dan telah dilancarkan ke dunia nyata. Oleh itu, ia membentuk garis dasar manusia yang sukar dilampaui.
Pada Mac 2026, sistem AI telah mampu melakukan pasca-pelatihan model dan mencapai peningkatan prestasi sekitar separuh daripada hasil pelatihan manusia.
Skor penilaian spesifik berasal daripada purata tertimbang: ia menggabungkan beberapa model bahasa besar selepas latihan, termasuk Qwen 3 1.7B, Qwen 3 4B, SmolLM3-3B, Gemma 3 4B, serta beberapa benchmark, termasuk AIME 2025, Arena Hard, BFCL, GPQA Main, GSM8K, HealthBench, HumanEval.
Dalam setiap peneraan, penilai akan meminta agen CLI untuk meningkatkan seberapa baik model asas tertentu berprestasi pada benchmark tertentu.
Pada April 2026, sistem AI dengan skor tertinggi berkisar antara 25% hingga 28%, dengan model perwakilan termasuk Opus 4.6 dan GPT 5.4; sebaliknya, skor manusia adalah 51%.
Ini sudah merupakan hasil yang cukup bermakna.
Mengoptimumkan latihan model bahasa
Dalam setahun terakhir, Anthropic telah melaporkan prestasi sistemnya dalam tugas latihan LLM. Tugas ini memerlukan model untuk mengoptimumkan implementasi latihan model bahasa kecil yang hanya menggunakan CPU, supaya ia berjalan secepat mungkin.
Cara penilaian adalah: ganda purata pecutan yang dicapai oleh model berbanding kod asal yang tidak diubah.
Hasil ini menunjukkan kemajuan yang sangat ketara:
· Pada Mei 2025, Claude Opus 4 mencapai purata percepatan 2.9 kali;
· Pada November 2025, Opus 4.5 dinaikkan kepada 16.5 kali;
· Pada Februari 2026, Opus 4.6 mencapai 30 kali;
· Pada April 2026, Claude Mythos Preview mencapai 52 kali.
Untuk memahami makna nombor-nombor ini, boleh dijadikan perbandingan: tugas ini biasanya memerlukan 4 hingga 8 jam kerja oleh penyelidik manusia untuk mencapai percepatan 4 kali ganda.
Kemahiran asas: Pengurusan
Sistem AI juga sedang belajar bagaimana mengurus sistem AI lain.
Ini sudah dapat dilihat dalam beberapa produk yang telah dilancarkan secara meluas, seperti Claude Code atau OpenCode. Dalam produk-produk ini, satu agen utama boleh mengawasi beberapa agen sub.
Ini membolehkan sistem AI mengendalikan projek berskala lebih besar: projek mungkin memerlukan beberapa agen dengan keahlian berbeza bekerja secara serentak, yang biasanya dikoordinasikan oleh seorang pengurus AI tunggal. Pengurus di sini sendiri merupakan sistem AI.
Penyelidikan AI lebih seperti menemukan teori relativiti umum, atau menyusun lego?
Masalah utama ialah: Adakah AI mampu mencipta idea baru untuk membantunya memperbaiki dirinya sendiri? Ataukah sistem-sistem ini lebih sesuai untuk menjalankan tugas-tugas yang kurang menarik tetapi perlu diperjuangkan langkah demi langkah dalam penyelidikan?
Masalah ini penting kerana ia berkaitan dengan sejauh mana sistem AI boleh mengautomasi sepenuhnya penyelidikan AI itu sendiri.
Penilaian penulis adalah: AI pada masa kini masih tidak mampu menghasilkan idea baru yang benar-benar radikal. Namun, untuk mencapai automatik dalam pembangunan sendiri, ia mungkin tidak perlu mencapai perkara ini.
Sebagai satu bidang, kemajuan AI sebahagian besarnya bergantung kepada eksperimen yang semakin besar dan input yang semakin banyak, seperti data dan kuasa pengiraan.
Sesekali, manusia mengemukakan idea yang mengubah paradigma, meningkatkan kecekapan sumber dalam seluruh bidang. Arsitektur Transformer adalah contoh yang baik, dan model pakar campuran, atau mixture-of-experts, juga merupakan contoh lain.
Namun, lebih sering, kemajuan dalam bidang AI sebenarnya lebih sederhana: manusia akan mengambil sistem yang berprestasi baik, memperbesar salah satu aspeknya, seperti data latihan dan kekuatan komputasi; mengamati di mana masalah muncul setelah skala diperbesar; mencari solusi rekabentuk untuk membolehkan sistem terus berkembang; kemudian memperbesar skala sekali lagi.
Dalam proses ini, bahagian yang benar-benar memerlukan wawasan sebenarnya sangat sedikit. Sebahagian besar kerja lebih seperti kejuruteraan asas yang tidak terlalu menonjol, tetapi sangat kukuh.
Secara serupa, banyak kajian AI sebenarnya menjalankan pelbagai varian eksperimen semasa, mengkaji kesan pelbagai tetapan parameter. Walaupun intuisi kajian boleh membantu manusia memilih parameter yang paling patut dicuba, proses ini sendiri boleh diotomatiskan, membolehkan AI menentukan parameter mana yang perlu disesuaikan. Pencarian arsitektur saraf awal merupakan satu versi idea ini.
Edison pernah berkata: Bakat adalah 1% inspirasi, ditambah 99% peluh. Walaupun telah berlalu 150 tahun, pernyataan ini masih sangat relevan.
Kadang-kadang, memang terdapat wawasan baru yang benar-benar mengubah satu bidang. Tetapi kebanyakannya, kemajuan bidang tersebut dicapai melalui usaha manusia yang gigih dalam memperbaiki dan menguji pelbagai sistem secara perlahan-lahan.
Manakala data awam yang disebutkan sebelumnya menunjukkan bahawa AI telah sangat mahir dalam menjalankan banyak tugas melelahkan yang diperlukan dalam pembangunan AI.
Sambil itu, terdapat satu tren yang lebih besar: kemampuan asas, seperti kemahiran pengaturcaraan, sedang digabungkan dengan jangka masa tugas yang terus membesar. Ini bermaksud sistem AI boleh menghubungkan semakin banyak tugas semacam ini untuk membentuk urutan kerja yang kompleks.
Oleh itu, walaupun sistem AI saat ini relatif kurang kreatif, terdapat alasan untuk percaya bahawa mereka masih mampu mendorong perkembangan diri mereka sendiri. Hanya sahaja, kelajuan kemajuan ini mungkin lebih perlahan berbanding situasi di mana mereka dapat menghasilkan wawasan baru sepenuhnya.
Namun, jika terus memantau data awam, akan ditemui isyarat lain yang menarik: sistem AI mungkin sedang menunjukkan kreativiti tertentu, dan kreativiti ini mungkin membolehkan mereka mendorong kemajuan diri mereka dengan cara yang lebih mengejutkan.
Mendorong sempadan ilmu terus maju
Sudah ada beberapa petanda awal yang menunjukkan bahawa sistem AI generik mampu mendorong sempadan ilmu manusia ke hadapan. Namun, sehingga kini, keadaan ini hanya berlaku dalam beberapa bidang sedikit, terutamanya sains komputer dan matematik. Selain itu, sering kali bukan sistem AI yang mencapai terobosan secara berasingan, tetapi melalui kerjasama manusia-mesin bersama penyelidik manusia.
Walaupun begitu, tren-tren ini masih patut diperhatikan:
Masalah Erdős: Sekumpulan ahli matematik bekerjasama dengan model Gemini untuk menguji prestasinya dalam menyelesaikan beberapa masalah matematik Erdős. Mereka membimbing sistem untuk mencuba sekitar 700 soalan, dan akhirnya mendapat 13 penyelesaian. Di antara penyelesaian-penyelesaian ini, 1 dianggap menarik oleh mereka.
Para penyelidik menulis bahawa mereka menganggap awalnya bahawa Aletheia (sistem AI berdasarkan Gemini 3 Deep Think) dalam menyelesaikan Erdős-1051 mewakili kes awal: satu sistem AI yang menyelesaikan secara autonomi satu masalah Erdős terbuka yang sedikit tidak remeh dan memiliki minat matematik yang lebih luas. Masalah ini sebelum ini telah mempunyai beberapa literatur penyelidikan yang berkaitan rapat.
Jika ditafsirkan secara optimis, kes-kes ini boleh dilihat sebagai isyarat: sistem AI sedang membangunkan intuisi kreatif tertentu yang mampu mendorong hadapan bidang ini, yang sebelum ini terutama dimiliki oleh manusia.
Namun, ia juga boleh ditafsirkan dari sudut lain: matematik dan sains komputer mungkin secara intrinsik sesuai untuk penemuan yang didorong AI, oleh itu ia mungkin hanya pengecualian dan tidak mewakili sains saintifik yang lebih luas yang akan didorong oleh AI dengan cara yang sama.
Contoh serupa ialah langkah ke-37 AlphaGo. Namun, Clark berpendapat bahawa sudah sepuluh tahun berlalu sejak keputusan AlphaGo itu, dan langkah ke-37 tidak digantikan oleh wawasan yang lebih moden atau lebih mengejutkan, yang juga boleh dianggap sebagai isyarat yang sedikit pesimis.
AI kini mampu mengautomasi sebahagian besar kerja dalam kejuruteraan AI
Jika semua bukti di atas digabungkan, kita dapat melihat gambaran berikut:
Sistem AI telah mampu menulis kod untuk hampir semua program, dan sistem-sistem ini sudah boleh dipercayai untuk menyelesaikan beberapa tugas secara berdikari; tugas-tugas ini, jika diberikan kepada manusia, biasanya memerlukan puluhan jam kerja keras yang penuh fokus.
Sistem AI semakin mahir dalam menyelesaikan tugas-tugas utama dalam pembangunan AI, dari penyesuaian model hingga reka bentuk kernel, yang semuanya secara beransur-ansur dicakup.
Sistem AI telah mampu mengurus sistem AI lain, sebenarnya membentuk satu pasukan sintetik: beberapa AI boleh menangani masalah kompleks secara berasingan, di mana beberapa AI berperan sebagai pemimpin, pencritik, dan penyunting, sementara AI lain berperan sebagai jurutera.
Sistem AI kadang-kadang sudah mampu melebihi manusia dalam tugas kejuruteraan dan sains yang sukar, walaupun pada masa ini masih sukar untuk menentukan sama ada ini disebabkan oleh kreativiti sejati mereka, atau kerana mereka telah menguasai sejumlah besar pengetahuan berpola.
Menurut Clark, bukti-bukti ini telah menunjukkan dengan sangat meyakinkan bahawa AI hari ini sudah boleh mengautomasi sebahagian besar kerja dalam kejuruteraan AI, bahkan mungkin merangkumi keseluruhan prosesnya.
Namun, masih tidak jelas sejauh mana AI boleh mengautomasi penyelidikan AI itu sendiri. Kerana beberapa bahagian dalam penyelidikan mungkin berbeza daripada kemahiran kejuruteraan semata-mata, dan masih bergantung kepada penilaian tingkat tinggi, kesedaran masalah, dan kreativiti.
Namun bagaimanapun, isyarat yang jelas telah muncul: AI hari ini sedang mempercepat secara besar-besaran usaha manusia dalam pembangunan AI, membolehkan penyelidik dan jurutera ini memperluaskan kemampuan kerja mereka melalui kerjasama dengan rakan kerja sintetik yang tak terhitung jumlahnya.
Akhirnya, industri AI sendiri hampir secara eksplisit menyatakan: otomatisasi pembangunan AI adalah tujuan mereka.
OpenAI berharap untuk membina seorang pegawai penyelidikan AI automatik sebelum September 2026. Anthropic sedang menerbitkan karya mengenai pembinaan penyelidik keselarasan AI automatik. DeepMind kelihatan paling berhati-hati di antara tiga makmal, tetapi juga menyatakan bahawa penyelidikan automatik keselarasan harus dipromosikan apabila ia munasabah.
Pembangunan AI automatik juga telah menjadi matlamat banyak syarikat rintisan. Recursive Superintelligence baru-baru ini memperoleh pendanaan sebanyak $500 juta, dengan matlamat untuk mengautomatikkan penyelidikan AI.
Dengan kata lain, modal yang sudah ada dan modal baru dalam bilion dolar AS sedang dialirkan kepada sejumlah institusi yang bertujuan untuk mengembangkan AI secara automatik.
Oleh itu, kita tentu harus mengharapkan bahawa arah ini sekurang-kurangnya akan mencapai beberapa kemajuan.
Mengapa ini penting
Impak yang ditimbulkan sangat mendalam, tetapi jarang dibincangkan dalam liputan media arus utama mengenai pembangunan AI. Aspek-aspek berikut boleh mencerminkan cabaran besar yang dibawa oleh pembangunan AI.
1. Kita perlu memastikan keselarasan yang betul: teknik keselarasan yang berkesan hari ini mungkin gagal dalam proses peningkatan diri berulang, kerana sistem AI akan menjadi jauh lebih pintar daripada manusia atau sistem yang mengawasnya. Ini adalah bidang yang telah dikaji secara meluas, jadi beliau hanya memberikan gambaran ringkas tentang beberapa isu:
Melatih sistem kecerdasan buatan agar tidak berbohong atau curang adalah proses yang halus dan mengejutkan (contohnya, walaupun berusaha membina ujian yang baik untuk persekitaran, terkadang cara terbaik bagi kecerdasan buatan untuk menyelesaikan masalah adalah dengan curang, sehingga mengajarinya bahawa curang adalah mungkin).
Sistem AI mungkin menipu kita dengan "berpura-pura selaras", menghasilkan skor yang membuat kita percaya ia berprestasi baik, tetapi sebenarnya menyembunyikan niat sebenarnya. (Secara umum, sistem AI sudah mampu mengesan bila ia sedang diuji.)
· Seiring dengan sistem AI yang mula terlibat lebih banyak dalam agenda penyelidikan asas pelatihan mereka sendiri, kita mungkin mengubah cara keseluruhan pelatihan sistem AI secara besar-besaran, tanpa intuisi atau asas teori yang baik untuk memahami apa maksudnya.
· Apabila anda meletakkan sesuatu sistem ke dalam kitaran rekursif, ia akan menghasilkan masalah "akumulasi ralat" yang sangat asas, yang mungkin mempengaruhi semua isu di atas dan isu-isu lain: selagi kaedah penyelarasan anda tidak "100% tepat" dan secara teori mampu mengekalkan ketepatan tersebut dalam sistem yang lebih cerdas, perkara-perkara boleh cepat menjadi salah. Sebagai contoh, ketepatan awal teknologi anda ialah 99.9%, selepas 50 generasi ia mungkin turun kepada 95.12%, dan selepas 500 generasi ia mungkin turun kepada 60.5%.
2. Setiap perkara yang melibatkan AI akan mendapat peningkatan produktiviti yang besar: seperti AI yang secara signifikan meningkatkan produktiviti jurutera perisian, kita seharusnya mengharapkan bidang-bidang lain yang melibatkan AI juga akan mengalami hal yang sama. Ini membawa beberapa isu yang perlu diatasi:
· Ketidakseimbangan dalam akses sumber daya: Jika permintaan terhadap AI terus melebihi bekalan sumber pengiraan, kita perlu memutuskan bagaimana mengagihkan AI untuk mencapai manfaat sosial maksimum. Saya meragukan bahawa insentif pasaran dapat menjamin kita memperoleh manfaat sosial terbaik daripada pengiraan AI yang terhad. Menentukan cara mengagihkan kemampuan percepatan yang dihasilkan daripada penyelidikan dan pembangunan AI akan menjadi isu yang sangat politikal.
Hukum Amdahl dalam ekonomi: Seiring AI mengalir ke dalam ekonomi, kita akan mendapati beberapa peringkat mengalami bottleneck apabila menghadapi pertumbuhan pesat, dan perlu dicari cara untuk memperbaiki titik lemah dalam rantai ini. Ini mungkin terutama jelas dalam bidang yang memerlukan koordinasi antara dunia digital yang cepat dan dunia fizikal yang perlahan, seperti ujian klinikal ubat baru.
3. Pembentukan ekonomi yang padat modal dan ringan tenaga kerja: Semua bukti mengenai pembangunan AI yang disebutkan di atas juga menunjukkan bahawa sistem AI semakin mampu mengendalikan perniagaan secara autonom.
Ini bermakna kita boleh mengharapkan sebahagian ekonomi akan dikuasai oleh syarikat generasi baru, yang mungkin bersifat padat modal (kerana mereka memiliki komputer dalam jumlah besar) atau padat perbelanjaan operasi (kerana mereka menghabiskan banyak dana untuk perkhidmatan AI dan mencipta nilai berdasarkannya), dengan ketergantungan yang lebih rendah terhadap tenaga kerja berbanding syarikat hari ini—kerana semakin meningkatnya kemampuan sistem AI, nilai marjinal pelaburan dalam AI terus meningkat.
Sebenarnya, ini akan muncul sebagai "ekonomi mesin" yang secara perlahan terbentuk di dalam "ekonomi manusia" yang lebih besar; seiring berjalannya waktu, syarikat yang dioperasikan oleh AI mungkin akan mulai berdagang antara satu sama lain, mengubah struktur ekonomi dan memicu pelbagai isu mengenai ketidaksamaan dan redistribusi. Pada akhirnya, mungkin akan muncul syarikat yang sepenuhnya dioperasikan secara autonom oleh sistem AI, yang akan memperburuk masalah-masalah tersebut sekaligus membawa banyak cabaran tata kelola baru.
Memandang lubang hitam
Berdasarkan analisis di atas, penulis berpendapat bahawa pada akhir 2028, kami melihat kemungkinan sekitar 60% bahawa pengembangan AI automatik (iaitu model terkini mampu melatih versi penerusnya secara bebas) akan berlaku. Mengapa tidak dijangkakan ia muncul pada 2027?
Sebabnya ialah penulis percaya bahawa penyelidikan AI masih memerlukan kreativiti dan pandangan berbeza untuk maju, dan sehingga kini, sistem AI belum menunjukkan ini dengan cara yang transformasional dan signifikan (walaupun beberapa keputusan dalam mempercepat penyelidikan matematik memberi petunjuk).
Jika terpaksa memberikan kebarangkalian untuk tahun 2027, dia akan mengatakan 30%.
Jika tidak muncul pada akhir 2028, kita mungkin akan mengungkapkan beberapa kelemahan mendasar dalam paradigma teknologi semasa, yang memerlukan penemuan manusia untuk mendorong perkembangan lanjutan.