









लेखक:टिना, दोंगमेईइन्फोक्यू
1. तीन साल बाद, मस्क ने फिर से X के अनुशंसा एल्गोरिथ्म को ओपन सोर्स कर दिया।
अभी-अभी, X इंजीनियरिंग टीम ने X पर एक पोस्ट के माध्यम से घोषणा की कि X अनुशंसा एल्गोरिथ्म को आधिकारिक तौर पर ओपन सोर्स कर दिया गया है। जानकारी के अनुसार, यह ओपन सोर्स लाइब्रेरी X पर "अनुशंसित" फीड के लिए समर्थन प्रदान करने वाली मुख्य अनुशंसा प्रणाली को शामिल करती है। यह नेटवर्क के भीतर के सामग्री (उपयोगकर्ता द्वारा अनुसरण किए गए खातों से) और नेटवर्क के बाहर के सामग्री (मशीन लर्निंग आधारित खोज के माध्यम से खोजे गए) को जोड़ती है, और सभी सामग्री को रैंक करने के लिए Grok आधारित Transformer मॉडल का उपयोग करती है। अर्थात, यह एल्गोरिथ्म Grok के समान Transformer आर्किटेक्चर का उपयोग करता है।
खुला स्रोत लिंक: https://x.com/XEng/status/2013471689087086804
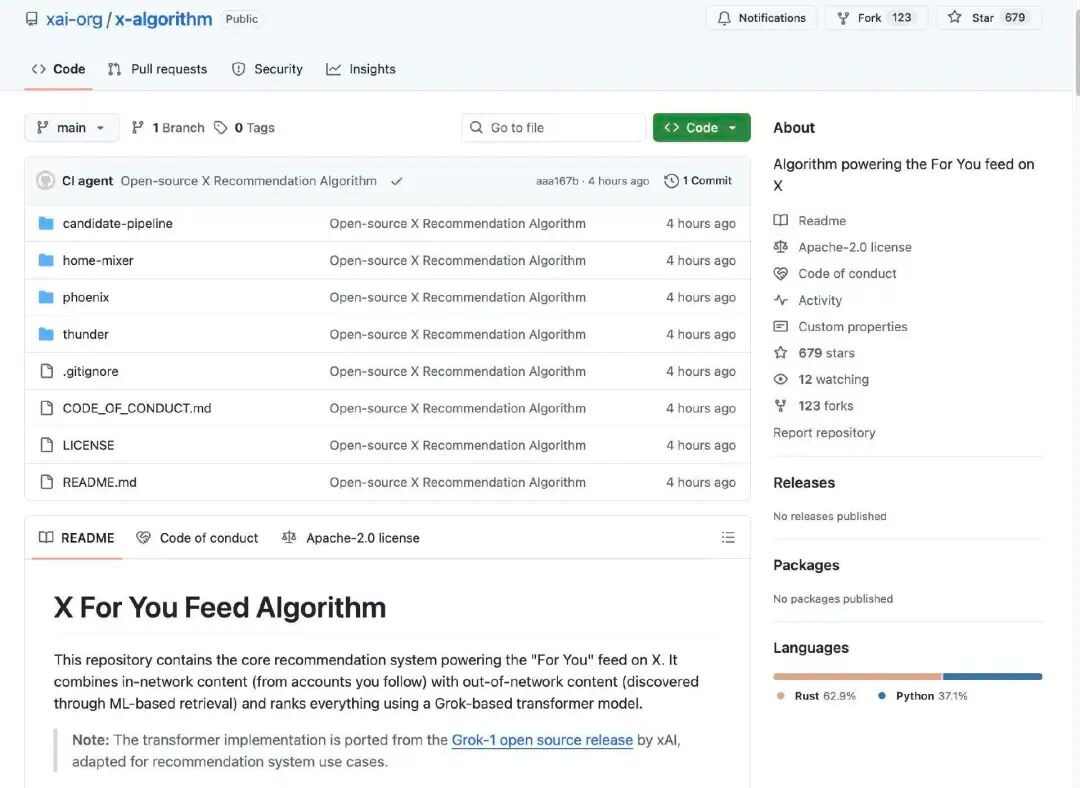
X का अनुशंसा एल्गोरिदम मुख्य रूप से उपयोगकर्ता के मुख्य पृष्ठ पर �"आपके लिए अनुशंसित" (For You Feed) सामग्रीयह दो मुख्य स्रोतों से उम्मीदवार पोस्ट प्राप्त करता है:
आपका ट्रैक किया गया अकाउंट (इन-नेटवर्क / तूफान)
नेटवर्क से बाहर/फिनिक्स के अन्य पोस्ट (Out-of-Network / Phoenix)
इन प्रस्तावित सामग्रियों का बाद में एकीकृत रूप से उपचार किया जाता है, फ़िल्टर किय
तो, एल्गोरिथ्म के मुख्य ढांचा और ऑपरेशन तर्क क्या है?
एल्गोरिदम पहले दो प्रकार के स्रोतों से उम्मीदवार सामग्री को �
अपने संबंधों में: आपके द्वारा सक्रिय रूप से अपने संबंधों में रखे गए खात
अनुसंधान विषय: सम्पूर्ण सामग्री भंडार में प्रणाली द्वारा खोजे गए, आपके द्वारा रुचि रखे जाने की संभावना
इस चरण का लक्ष्य "संभावित रूप से संबंधित पोस्ट ढूंढना" है।
प्रणाली स्वतः निम्न गुणवत्ता वाले, दोहराव, अवैध या अनुपयुक्त सामग्री को हटा देत
अवरुद्ध खाते की सामग्री
उपयोगकर्ता के स्पष्ट रूप से अनुच
अवैध, पुराने या अमान्य पोस्ट
इस प्रकार सुनिश्चित करें कि अंतिम रूप से केवल मूल्यवान उम्मीद
इस बार खुला स्रोत एल्गोरिदम के कोर में सिस्टम एक ग्रोक-बेस्ड ट्रांसफॉर्मर मॉडल (लार्ज लैंग्वेज मॉडल / डीप लर्निंग नेटवर्क के समान) का उपयोग करता है, जो प्रत्येक उम्मीदवार पोस्ट का अंकन करता है। ट्रांसफॉर्मर मॉडल उपयोगकर्ता के अतीत के व्यवहार (लाइक, जवाब, शेयर, क्लिक आदि) के आधार पर प्रत्येक व्यवहार की संभावना का अनुमान लगाता है। अंत में, इन व्यवहार संभावनाओं को एक संयुक्त स्कोर में वजन द्वारा संयोजित किया जाता है, जिसमें उच्च स्कोर वाले पोस्ट उपयोगकर्ता के लिए अधिक
इस डिज़ाइन ने पारंपरिक हाथ से विशेषताओं को निकाले जाने के तरीके को लगभग खत्म कर दिया है और उपयोगकर्ता रुचि के भविष्य की भवि�
यह मस्क की पहली बार नहीं है जब उन्होंने X के सिफ़ारिश एल्गोरिथ्म क
2023 के मार्च 31 को, जैसा कि मस्क ने ट्विटर के अधिग्रहण के समय वादा किया था, उन्होंने ट्विटर के कुछ स्रोत कोड को आधिकारिक तौर पर ओपन सोर्स कर दिया, जिसमें उपयोगकर्ता के टाइमलाइन में ट्वीट की सिफारिश करने वाले एल्गोरिथम को शामिल किया गया।खुले स्रोत के दिन, परियोजना को GitHub पर 10k + स्टार मिल चुके हैं।
उस समय ट्विटर पर मस्क ने कहा था कि यह जारी करना है"अधिकांश सिफ़ारिश एल्गोरि�अन्य एल्गोरिदम भी आने वाले समय में उपलब्ध करा दिए जाएंगे। उन्होंने यह भी कहा कि वे उम्मीद करते हैं कि "स्वतंत्र तीसरे पक्ष ट्विटर के द्वारा उपयोगकर्ता के लिए प्रस्त
स्पेस चर्चा में एल्गोरिथ्म के जारी करे जाने के बारे में उन्होंने कहा कि इस ओपन सोर्स योजना का उद्देश्य ट्विटर को "इंटरनेट पर सबसे अधिक पारदर्शी प्रणाली" बनाना है और इसे लिनक्स जैसे सबसे ज्यादा प्रसिद्ध और सफल ओपन सोर्स प्रोजेक्ट की तरह मजबूत बनाना है। "मुख्य लक्ष्य यह है कि ट्विटर का समर्थन जारी रखने वाले उपयोगकर्ता अधिक
मस्क द्वारा X एल्गोरिथ्म को पहली बार ओपन सोर्स करने से अब लगभग तीन साल हो गए हैं। तकनीकी दुनिया में एक सुपर के.ओ.एल. के रूप में, मस्क ने पहले ही इस ओपन सोर्स करने के लिए पर्याप्त प्रचार कर लिया है।
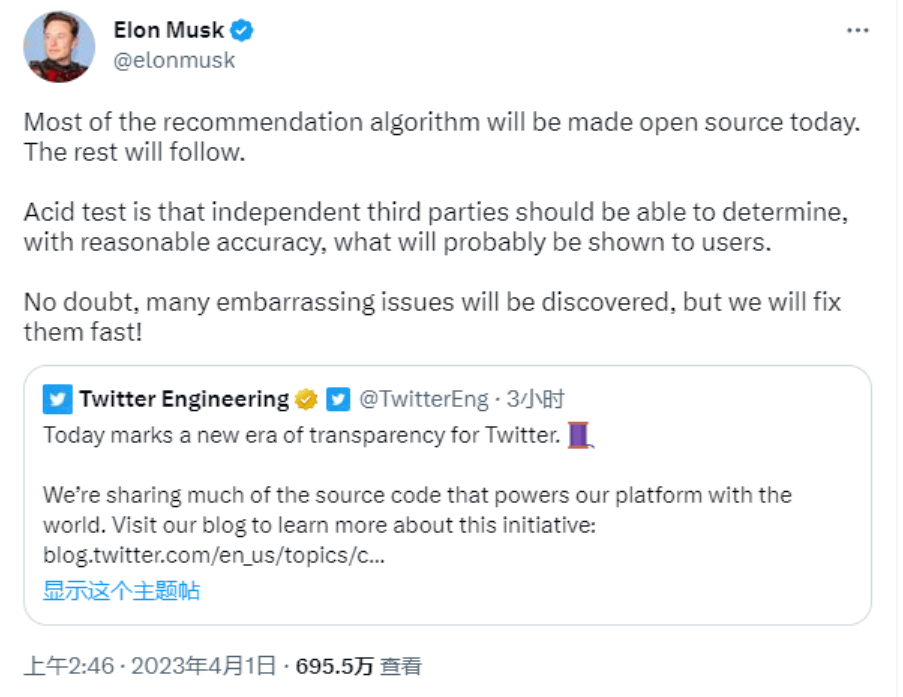
11 जनवरी को, मस्क ने X पर ट्वीट किया कि वे 7 दिनों के भीतर एक्स एल्गोरिथ्म को ओपन सोर्स कर देंगे, जिसमें उपयोगकर्ताओं को कौन सा प्राकृतिक खोज सामग्री और विज्ञापन सामग्री सिफारिश करने के लिए उपयोग किया जाने वाला सभी कोड शामिल है।
इस प्रक्रिया को प्रत्येक 4 सप्ताह में दोहराया जाएगा, जिसमें विस्तृत विकसक टिप्पणियां शामिल होंगी, जो उपयोगकर्ताओं को यह समझने में मदद करेंगी कि क
आज उसका वादा फिर से पूरा हो गया।
2. मस्क को ओपन सोर्स क्यों करने की आवश्यकता है?
जब एलन मस्क फिर से "ओपन सोर्स" का उल्लेख करते हैं, तो बाहरी दुनिया की पहली प्रतिक्रिया तकनीकी आदर्शवाद नहीं, बल्कि वास्तविक दबाव है।
पिछले एक वर्ष में, X अक्सर अपने सामग्री वितरण तंत्र के कारण विवादों में घिरा रहा है। इस प्लेटफॉर्म की आलोचना व्यापक रूप से इसके एल्गोरिदम में दाहिने पक्ष के विचारों के प्रति झुकाव और उनके प्रचार के लिए की गई है, जिसे एक व्यापक विशेषता के रूप में माना जाता है, जबकि इसके बारे में अकेले उदाहरण नहीं माना जाता है। पिछले वर्ष प्रकाशित एक शोध रिपोर्ट में यह बात उजागर की गई कि X की सिफारिश प्रण
इस बीच, कुछ चरम उदाहरणों ने बाहरी संदेह को और अधिक बढ़ा दिया। पिछले वर्ष, एक अप्रमाणित वीडियो, जिसमें अमेरिकी दक्षिणपंथी गतिविधिकर्ता चार्ली कर्क की हत्या के बारे में बात की गई थी, ने X प्लेटफॉर्म पर तेजी से फैलकर लोकमत में हलचल पैदा कर दी। आलोचकों का मानना है कि यह न केवल प्लेटफॉर्म के समीक्षा तंत्र के विफल होने को दर्शाता है, बल्कि एल्गोरिथ्म के "क्या बड़ा करना है और क्या नहीं" के चुनाव को � अदिखा सत्ता।
ऐसे संदर्भ में, मस्क की अचानक एल्गोरिथ्म पारदर्शिता पर बल देना आसानी से एक शुद्ध तकनीकी निर्णय के रूप में समझा नहीं जा सकता ह�

3. इंटरनेट उपयोगकर्ता क्या सोचते हैं?
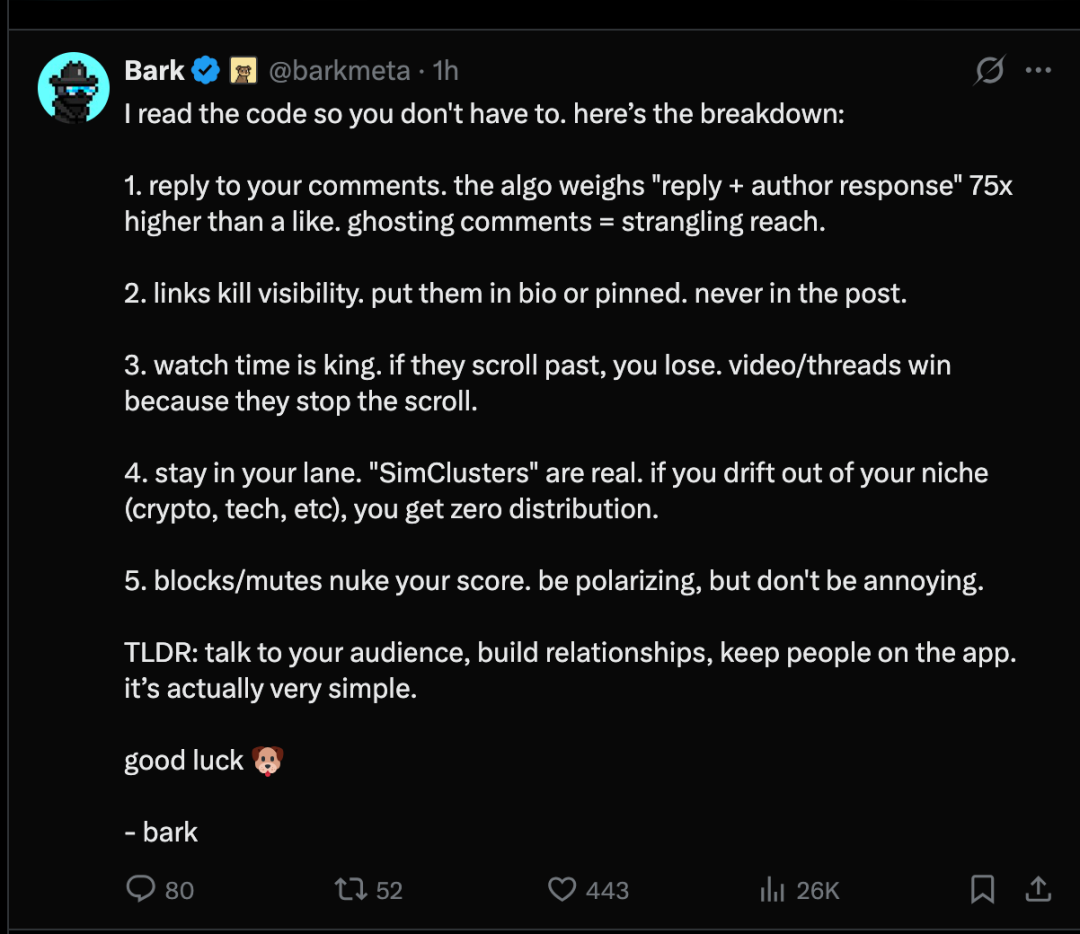
X के सिफ़ारिश एल्गोरिथ्म के स्रोत खुले होने के बाद, X प्लेटफॉर्म पर उपयोगकर्ता द्वारा सिफ़ारिश एल्गोरिथ्म के तंत्र के बारे में निम्नलिखित 5 बिंदुओं
- अपने टिप्पणी का �"टिप्पणी + लेखक का जवाब" के लिए एल्गोरिदम का भार उसके लाइक का 75 गुना होता है। टिप्पणियों का जवाब ना देना प्रदर्शन को बुरी तरह से प्रभावित कर सकता है।
- लिंक दिखाई देने की संभावना कलिंक को अपने प्रोफ़ाइल या शीर्ष स्थित पोस्ट में रखें, अवश्य ही पोस्ट के मुख्य भाग में नहीं।
- दृश्यमान समय बहुत महतअगर वे स्क्रीन को स्वाइप करके उसे छोड़ देते हैं, तो आप उन्हें आकर्षित नहीं कर पाएंगे। वीडियो / पोस्ट जो अधिक ध्यान आकर्षित करते हैं, वे उपयोगकर्ता को रोकने में सक्षम होते है
- अपने क्षेत्र का नि�"सिमुलेटेड क्लस्टर" वास्तविक है। अगर आप अपने निश्चित क्षेत्र (क्रिप्टोकरेंसी, टेक्नोलॉजी आदि) से बाहर निकल जाते हैं, तो आपको कोई भी डिस्ट्रीब्यूशन चैन
- अगर आप अपने आप को ब्लॉक करते हैं / चुप रहते हैं तो आपके स्कोर मे�विवादास्पद होना चाहिए, लेकिन अप्रिय नहीं।
सारांश में: अपने दर्शकों के साथ संचार करें, संबंध बनाएं और उपयोगकर्ता एप्लिकेशन में बने रहे। वास्तव में यह ब
एक अन्य नेटिजन ने भी ध्यान दिया कि यहां तक़ कि आर्किटेक्चर ओपन सोर्स है, लेकिन कुछ अभी भी ओपन सोर्स नहीं है। उस नेटिजन का कहना है कि इस जारीकरण का आधार एक फ्रेमवर्क है, इंजन नहीं।
भार पैरामीटर की क - कोड में "सकारात्मक व्यवहार के अंक जोड़े जाएंगे" और "नकारात्मक व्यवहार के अंक काटे जाएंगे" की पुष्टि की गई है, लेकिन 2023 के संस्करण से अलग, विशिष्ट मूल्य हटा दिए गए हैं।
छिपाए गए मॉडल व - मॉडल के स्वयं के आंतरिक पैरामीटर और गणना को शामिल नह
अप्रकाशित प्रशिक्षण डेटा - हम अपने मॉडल के लिए प्रशिक्षण डेटा, उपयोगकर्ता व्यवहार के नमूना लेने के तरीके, और "अच्छे" और "खराब" नमूनों को कैसे बनाया जाए इस बारे में कुछ भी नहीं जानते हैं।
सामान्य एक्स उपयोगकर्ता के लिए, एक्स के एल्गोरिदम के ओपन सोर्स होने से बहुत अधिक प्रभाव नहीं पड़ेगा। लेकिन अधिक जांच क्यों कुछ पोस्ट दिखाई देते हैं जबकि अन्य नहीं, और शोधकर्ता इस बात की जांच कर सकते हैं कि प्लेटफॉर्म कंटेंट को कैसे रैंक करता है।
4. क्यों अनुशंसा प्रणाली एक आवश्यक लड़ाई का क्षेत्र है?
अधिकांश तकनीकी चर्चाओं में,अनुशंसा प्रणयह प्रायः पीछे के इंजीनियरिंग के हिस्से के रूप में देखा जाता है, जो कि नीचे से जटिल और शांतिपूर्ण होता है, लेकिन धूप में खड़ा नहीं होता है। लेकिन अगर आप वास्तव में इंटरनेट के दिग्गजों के व्यावसायिक संचालन को तोड़कर देखें, तो आप पाएंगे कि अनुशंसा प्रणाली केवल एक किनारे का मॉड्यूल नहीं है, बल्कि पूरे व्यावसायिक मॉडल का स
सार्वजनिक डेटा इस बात को बार-बार साबित करता है। अमेज़न ने खुलासा किया है कि लगभग 35% खरीदारी अपने प्लेटफॉर्म पर सिर्फ रिकॉमेंडेशन सिस्टम से होती है; नेटफ्लिक्स इस मामले में और भी आगे है, जहां लगभग 80% देखे गए समय के पीछे रिकॉमेंडेशन एल्गोरिदम है; यूट्यूब की स्थिति भी इसी तरह है, जहां लगभग 70% देखे गए समय के पीछे रिकॉमेंडेशन सिस्टम है, खासकर फीड (feed) के माध्यम से। मेटा के बारे में तो यहां तक कि कोई निश्चित अनुपात भी नहीं दिया गया है, लेकिन उनकी तकनीकी टीम ने बताया है कि कंपनी के आंतरिक कंप्यूटिंग क्लस्टर में लगभग 80% कंप्यूटेशनल साइकिल रिकॉमेंडेशन से संबंधित कार्यों के
ये संख्याएँ क्या दर्शाती ह�यदि आप इन उत्पादों से अनुशंसा प्रणाली को हटा दें, तो यह लगभग भूमि के आधार को खींच लेने के बराबर है।मेटा के मामले में, विज्ञापन, उपयोगकर्ता के समय की अवधि, व्यावसायिक रूपांतरण, लगभग सभी अनुशंसा प्रणाली पर आधारित हैं। अनुशंसा प्रणाली न केवल यह निर्धारित करती है कि उपयोगकर्ता "क्या देखे", बल्कि सीधे तौर पर यह भी निर्धारित करती है कि "प्लेटफ
हालांकि, ऐसी एक जीवन और मृत्यु के निर्णय लेने वाली प्रणाली, लंबे समय तक इंजीनियरिंग की जटिलता के
पारंपरिक अनुशंसा प्रणाली वास्तुकला में, एक ऐसे एकीकृत मॉडल को बनाना कठिन होता है जो सभी परिदृश्यों को कवर कर सके। वास्तविक उत्पादन प्रणालियाँ अक्सर अत्यधिक टुकड़ों में बंटी रहती हैं। मेटा, लिंक्डइन, नेटफ्लिक्स जैसी कंपनियों के उदाहरण लें, एक पूर्ण अनुशंसा श्रृंखला के पीछे, अक्सर 30 या अधिक विशिष्ट मॉडल एक साथ चल रहे होते हैं: फिल्टरिंग मॉडल, कूर मॉडल, फाइन मॉडल, री-रैंकिंग मॉडल, जो अलग-अलग लक्ष्य फंक्शन और व्यावसायिक मापदंडों के लिए अनुकूलित होते हैं। प्रत्येक मॉडल के पीछे, अक्सर एक या अधिक टीमें होती हैं, जो विशेषता इंजीनियरिंग, प्रशिक्षण, पैरामीटर ट्यूनिंग, लॉन
इस पैटर्न की कीमत स्पष्ट है: इंजीनियरिंग जटिल, रखरखाव लागत अधिक, और कार्यों के बीच सहयोग करना कठिन। जैसे ही कोई व्यक्ति "क्या एक मॉडल के साथ कई रिकॉमेंडेशन समस्याओं को हल किया जा सकता है" प्रस्तावित करता है, पूरे सिस्टम के लिए इसका अर्थ जटिलता के आदेश का गिरावट होता है। यही उद्योग के लंबे समय से इच्छित लेकिन प्राप्त नह
बड़े भाषा मॉडल के उभरने ने अनुशंसा प्रणाली में एक नई संभावित राह खोली है।
प्रथक के रूप में, LLM ने अपनी शक्तिशाली सामान्य ताकत का प्रमाण दिया है: यह अलग-अलग कार्यों के बीच मजबूत स्थानांतरण कर सकता है, और डेटा पैमाने और कम्प्यूटिंग शक्ति के विस्तार के साथ, प्रदर्शन लगातार बेहतर होता जाता है। इसकी तुलना में, पारंपरिक रूप से अनुशंसा मॉडल अक्सर "कार्य विशिष्ट" होते हैं, जो कई परिदृश्य
अधिक महत्वपूर्ण बात यह है कि एकल बड़े मॉडल के साथ न केवल इंजीनियरिंग की सरलता बल्कि "पारस्परिक अध्ययन" की क्षमता भी आती है। जब एक ही मॉडल एक साथ कई अनुशंसा कार्यों को संसोधित करता है, तो अलग-अलग कार्यों के बीच संकेत एक-दूसरे को पूरक बन सकते हैं, डेटा के पैमाने के बढ़ने के साथ मॉडल को समग्र रूप से विकसित होने में आसानी होती है। यही विशेष
LLM ने क्या बदल दिया? वास्तव में विशेषता इंजीनियरिंग से समझ की क्षमता तक कुछ बदल गया है।
विधि के स्तर पर, LLM का अनुशंसा प्रणाली पर सबसे बड़ा प्रभाव "लक्षण इंजीनियरिंग" नामक मुख्य चरण पर पड़ा है।
पारंपरिक सिफारिश प्रणालियों में, इंजीनियरों को पहले बड़ी संख्या में संकेतों का निर्माण करना पड़ता है: उपयोगकर्ता के क्लिक इतिहास, रुके रहने का समय, समान उपयोगकर्ता पसंद, सामग्री टैग आदि, फिर मॉडल को स्पष्ट रूप से बताना होता है "कृपया इन विशेषताओं के आधार पर निर्णय लें"। मॉडल खुद इन संकेतों के अर्थ को समझता नहीं है, बल्कि मात्रात्मक स्थान
भाषा मॉडल के परिचय के बाद, यह प्रक्रिया अत्यधिक अमूर्त हो गई है। अब आपको एक-एक करके "इस संकेत को देखें, उस संकेत को नज़रअंदाज़ करें" जैसे निर्देश देने की आवश्यकता नहीं है, बल्कि आप सीधे मॉडल को समस्या का वर्णन कर सकते हैं: यह एक उपयोगकर्ता है, यह एक सामग्रि है; इस उपयोगकर्ता ने पहले इस तरह की सामग्रि पसंद की है, अन्य उपयोगकर्ता इस सामग्रि के प्रति सकारात्मक प्रतिक्रिया दे चुके हैं - अब कृपया �
भाषा मॉडल के पास स्वयं अर्थ की अपेक्षा है, यह स्वतंत्र रूप से निर्धारित कर सकता है कि कौन सी जानकारी महत्वपूर्ण संकेत है और इन संकेतों को कैसे संयोजित करके निर्णय लिया जाए। किसी अर्थ में, यह केवल अनुशंसा नियमों का कार्यान्वयन
इस क्षमता का स्रोत इस तथ्य में है कि LLM प्रशिक्षण चरण में बड़ी मात्रा में विविध डेटा से संपर्क करता है, जिससे अप्रत्यक्ष लेकिन महत्वपूर्ण पैटर्न को पकड़ना आसान हो जाता है। इसके विपरीत, पारंपरिक रूप से अनुशंसा प्रणाली को इंजीनियरों द्वारा इन पैटर्न को स्पष्ट रूप से बनाए रखने
पीछे की ओर से देखें तो, ऐसा बदलाव अजनबी नहीं है। जैसे कि आप GPT से प्रश्न पूछते हैं, तो यह संदर्भ के आधार पर उत्तर उत्पन्न करता है; ठीक उसी तरह, जब आप इससे पूछते हैं कि "क्या मुझे इस सामग्री में रुचि होगी", तो यह उपलब्ध जानकारी के आधार पर निर्णय ले सकता है। कुछ हद तक, भाषा मॉडल के पास स्वाभाविक रूप से "अनुशंसा" करने की क्षमता हो चुकी है।