










इस स्थिति की कल्पना करें:
आपने AI एजेंट को एक कोड बग ठीक करने के लिए कहा। इसने प्रोजेक्ट खोला, 20 फाइलें पढ़ीं, कुछ बदला, टेस्ट चलाया, फेल हो गया, फिर बदला, फिर चलाया, फिर भी फेल हो गया… कई चक्रों के बाद, अंततः—अभी भी ठीक नहीं हुआ।
आपने कंप्यूटर बंद किया और आराम की सांस ली। फिर आपको API बिल मिला।
ऊपर के अंक आपको सांस रोक देंगे—AI एजेंट द्वारा विदेशी ऑफिशियल API पर स्वयं बग ठीक करने पर, एक बार का अनुत्तरित कार्य अक्सर लाखों टोकन खर्च कर देता है, जिसकी लागत दर्जनों से एक सौ डॉलर तक हो सकती है।
अप्रैल 2026 में, स्टैनफोर्ड, MIT, मिशिगन विश्वविद्यालय आदि द्वारा संयुक्त रूप से प्रकाशित एक शोध पत्र ने AI एजेंट के कोड कार्यों में "खपत के काला बॉक्स" को पहली बार प्रणालीगत रूप से खोला—पैसा कहाँ खर्च हो रहा है, क्या यह खर्च उचित है, और क्या इसे पहले से अनुमानित किया जा सकता है, उत्तर आश्चर्यजनक हैं।
खोज 1: एजेंट द्वारा कोड लिखने की खर्चीली दर, सामान्य AI बातचीत की तुलना में 1000 गुना है
लोगों को लग सकता है कि AI को आपके लिए कोड लिखवाना और AI के साथ कोड पर बात करना, दोनों में खर्च लगभग समान होना चाहिए।
पेपर में दिए गए तुलनात्मक परिणाम दर्शाते हैं:
एजेंटिक कोडिंग टास्क के लिए टोकन खपत, सामान्य कोड प्रश्नोत्तर और कोड निष्कर्षण कार्यों की तुलना में लगभग 1000 गुना है।
पूरी तरह से तीन घातांक अंतर है।
ऐसा क्यों हो रहा है? पेपर एक तथ्य बताता है—पैसा “कोड लिखने” पर नहीं, बल्कि “कोड पढ़ने” पर खर्च होता है।
यहाँ "पढ़ना" का अर्थ मानव द्वारा कोड पढ़ना नहीं है, बल्कि एजेंट कार्य करते समय पूरे प्रोजेक्ट के कॉन्टेक्स्ट, इतिहास की ऑपरेशन रिकॉर्ड, एरर सूचनाएँ और फाइल कंटेंट को एक साथ मॉडल को "फीड" करता है। प्रत्येक अतिरिक्त डायलॉग राउंड के साथ, यह कॉन्टेक्स्ट एक और राउंड लंबा हो जाता है; और मॉडल की लागत Token संख्या के आधार पर होती है—आप जितना अधिक फीड करते हैं, उतना ही अधिक भुगतान करते हैं।
एक उदाहरण दें: यह ऐसा है जैसे आपने एक मरम्मतकर्ता को बुलाया है, जो हर वर्ग को घुमाने से पहले आपसे पूरी इमारत के नक्शे को शुरू से अंत तक पढ़ने को कहता है—नक्शे पढ़ने का खर्च, स्क्रू को घुमाने के खर्च से कहीं अधिक है।
पेपर इस घटना को एक वाक्य में सारांशित करता है: एजेंट लागत को आउटपुट टोकन के बजाय इनपुट टोकन के घातीय वृद्धि द्वारा चलाया जाता है।
दूसरी खोज: एक ही बग को दो बार चलाने पर लागत दोगुनी हो सकती है—और जितना महंगा बग, उतना अस्थिर
अधिक परेशानी की बात यह है कि यह यादृच्छिक है।
शोधकर्ताओं ने एक ही एजेंट को एक ही कार्य पर 4 बार चलाया, और पाया कि:
- अलग-अलग कार्यों के बीच, सबसे महंगा कार्य सबसे सस्ते कार्य की तुलना में लगभग 70 लाख टोकन जलाता है (चित्र 2a)
- एक ही मॉडल और एक ही कार्य के कई चलाने में, सबसे महंगा लगता लगभग सबसे सस्ते का दोगुना है (चित्र 2b)
- और यदि एक ही कार्य की तुलना विभिन्न मॉडलों के बीच की जाए, तो अधिकतम और न्यूनतम खपत के बीच 30 गुना का अंतर हो सकता है।
अंतिम संख्या विशेष रूप से ध्यान देने योग्य है: इसका अर्थ है कि सही मॉडल और गलत मॉडल के बीच लागत का अंतर केवल "थोड़ा महंगा" नहीं, बल्कि "एक क्रम का अंतर" है।
और यह भी दर्दनाक है—ज्यादा खर्च करना, अच्छा काम करने का मतलब नहीं है।
अध्ययन ने एक "उल्टा U आकार का वक्र" पाया:
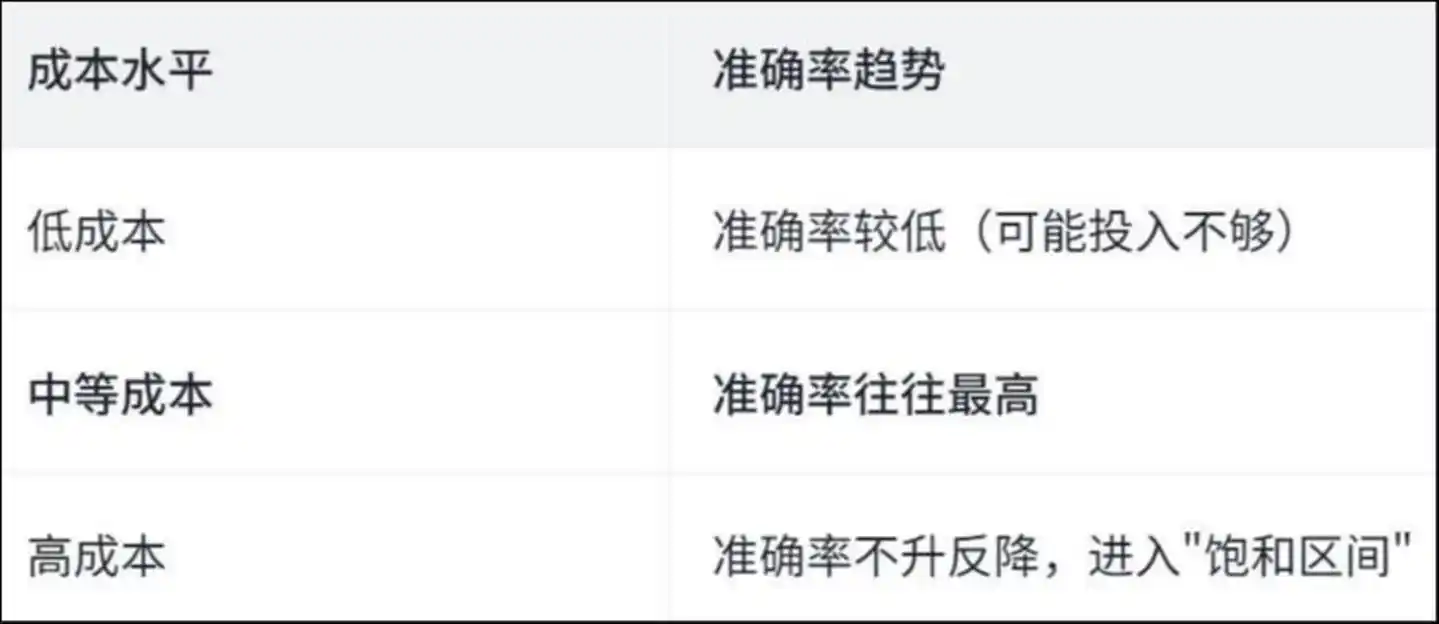
लागत स्तर की सटीकता का रुझान: कम लागत पर सटीकता कम (संभवतः निवेश कम है), मध्यम लागत पर सटीकता अक्सर सबसे अधिक होती है, उच्च लागत पर सटीकता नहीं बढ़ती बल्कि घटती है, "संतृप्त अंतराल" में प्रवेश किया जाता है
ऐसा क्यों हो रहा है? पेपर एजेंट के विशिष्ट कार्यों के विश्लेषण द्वारा उत्तर देता है—
उच्च लागत के संचालन में, एजेंट ने "दोहराई गई श्रम" पर बहुत समय बर्बाद किया।
अध्ययन में पाया गया कि उच्च लागत वाले ऑपरेशन में, लगभग 50% फाइल देखने और फाइल संशोधन के कार्य दोहराए जाते हैं—यानी, एजेंट एक ही फाइल को बार-बार पढ़ रहा है और एक ही कोड लाइन को बार-बार बदल रहा है, जैसे कोई व्यक्ति कमरे में घूम रहा हो, जिससे उसे घूमने लगता है, और जितना घूमता है, उतना ही उलझता जाता है।
पैसा समस्या के समाधान पर नहीं, बल्कि "भटकने" पर खर्च हुआ।
पाया गया तीसरा बिंदु: मॉडलों के बीच "कार्यक्षमता अनुपात" में भारी अंतर—GPT-5 सबसे कम ऊर्जा खर्च करता है, कुछ मॉडल 1.5 मिलियन टोकन अतिरिक्त खर्च करते हैं
एक अध्ययन ने SWE-bench Verified (500 वास्तविक GitHub इशू) पर 8 अग्रणी बड़े मॉडल्स के एजेंट प्रदर्शन का परीक्षण किया। डॉलर में बदलने पर, टोकन दक्ष मॉडल प्रति कार्य के लिए कुछ दर्जन डॉलर अधिक खर्च कर सकते हैं। उद्योग-स्तरीय अनुप्रयोगों में—जहां एक दिन में सैकड़ों कार्य चलते हैं—यह अंतर सच्चे सोने के सिक्कों का अंतर होता है।
एक और दिलचस्प खोज यह है कि टोकन की दक्षता मॉडल की "अंतर्निहित प्रकृति" है, न कि कार्य के कारण।
शोधकर्ताओं ने सभी मॉडल द्वारा सफलतापूर्वक हल किए गए कार्यों (230) और सभी मॉडल द्वारा असफल रहे कार्यों (100) की तुलना की, जिससे पता चला कि मॉडलों का सापेक्ष क्रमांकन लगभग अपरिवर्तित रहा।
यह बताता है: कुछ मॉडल स्वभाव से ही "बातूनी" होते हैं, और यह कार्य की कठिनाई से ज्यादा संबंधित नहीं है।
एक और गहरा अवलोकन: मॉडल में "स्टॉप लॉस जागरूकता" की कमी है।
जब सभी मॉडल एक कठिन कार्य को हल नहीं कर सकते, तो आदर्श एजेंट को बर्बाद होने से पहले जल्दी से छोड़ देना चाहिए। लेकिन वास्तविकता यह है कि मॉडल सामान्यतः असफल कार्यों पर अधिक टोकन खर्च करते हैं—वे “हार मानते” नहीं, बल्कि जारी रखते हैं: खोजना, पुनः प्रयास करना, संदर्भ को पुनः पढ़ना, जैसे कोई ऐसी कार जिसमें ईंधन सूचक लैम्प न हो, और वह कार तब तक चलती है जब तक यह ठहर न जाए।
अवलोकन 4: जिसे मनुष्य कठिन समझते हैं, उसे एजेंट जरूरी नहीं कि महंगा समझे—कठिनाई की अनुभूति पूरी तरह से गलत है
आप सोच सकते हैं: कम से कम क्या मैं कार्य की कठिनाई के आधार पर लागत का अनुमान लगा सकता हूँ?
एक अनुसंधान टीम ने मानव विशेषज्ञों को आमंत्रित किया ताकि 500 कार्यों की कठिनाई का मूल्यांकन किया जा सके और फिर इसे एजेंट के वास्तविक टोकन खपत के साथ तुलना की गई—
Result: There is only a weak correlation between the two.
जो काम इंसान के लिए बहुत मुश्किल और महंगा लगता है, उसे एजेंट आसानी से और कम खर्च में पूरा कर सकता है; जबकि जो काम इंसान के लिए बहुत आसान लगता है, उसे एजेंट के लिए इतना मुश्किल बन सकता है कि वह खुद को समझने लगे।
क्योंकि इंसान और AI द्वारा “देखी” गई कठिनाई पूरी तरह से अलग है:
- मनुष्य देखते हैं: लॉजिकल कॉम्प्लेक्सिटी, एल्गोरिथम डिफिकल्टी, बिजनेस अंडरस्टैंडिंग बैरियर
- एजेंट देख रहा है: प्रोजेक्ट कितना बड़ा है, कितने फाइलों को पढ़ना है, एक्सप्लोरेशन पाथ कितना लंबा है, क्या एक ही फाइल को बार-बार मॉडिफाई किया जाएगा
एक मानव विशेषज्ञ को लगता है कि "केवल एक पंक्ति बदलनी है" वाली बग, एजेंट को उस पंक्ति को ढूंढने के लिए पूरे कोडबेस की संरचना को समझना पड़ सकता है—बस "पढ़ने" में ही बहुत सारे टोकन खर्च हो जाते हैं। और एक मानव विशेषज्ञ को लगता है कि "तर्क बहुत जटिल है" वाली एल्गोरिथम समस्या, एजेंट को शायद मानक समाधान पता हो, जिसे वह तुरंत हल कर देता है।
इससे एक अजीब सच्चाई उभरती है: डेवलपर्स के लिए एजेंट की चलाने की लागत का अनुमान लगाना लगभग असंभव है।
पांचवां खोज: मॉडल खुद भी अपने खर्च की गणना नहीं कर सकता
चूंकि इंसान अनुमान लगाने में असमर्थ है, तो AI को खुद भविष्यवाणी करने के लिए क्यों नहीं दिया जाए?
शोधकर्ताओं ने एक चतुर प्रयोग डिज़ाइन किया: एजेंट को वास्तविक रूप से बग को ठीक करने से पहले, कोडबेस की "जांच" करनी चाहिए और अपने द्वारा कितने टोकन की आवश्यकता होगी, उसका अनुमान लगाना चाहिए—लेकिन ठीक करने का वास्तविक संचालन नहीं करना चाहिए।
What was the result?
All models, completely wiped out.
सर्वश्रेष्ठ परिणाम Claude Sonnet-4.5 द्वारा आउटपुट टोकन की भविष्यवाणी संबंधितता है—0.39 (1.0 के पूर्ण अंक)। अधिकांश मॉडल की भविष्यवाणी संबंधितता केवल 0.05 से 0.34 के बीच है, जिसमें Gemini-3-Pro सबसे कम है, केवल 0.04—जो लगभग अनुमान लगाने के बराबर है।
और यह भी अजीब है: सभी मॉडल अपने टोकन खपत का व्यवस्थित रूप से कम आकलन करते हैं। चित्र 11 के बिखरे हुए आरेख में, लगभग सभी डेटा बिंदु “परफेक्ट प्रेडिक्शन लाइन” के नीचे आते हैं—मॉडल को लगता है कि “उन्हें इतना खर्च नहीं करना पड़ेगा”, लेकिन वास्तव में वे अधिक खर्च करते हैं। और यह कम आकलन का विचलन उदाहरण प्रदान न किए जाने पर अधिक गंभीर होता है।
अधिक विरोधाभासी बात यह है कि भविष्यवाणी करने के लिए भी पैसा खर्च करना पड़ता है।
Claude Sonnet-3.7 और Sonnet-4 की भविष्यवाणी लागत अक्सर कार्य की लागत से दोगुनी से अधिक होती है। यानी, उन्हें पहले "कीमत अनुमानित" करने के लिए कहना, सीधे काम करने से अधिक महंगा है।
पेपर का निष्कर्ष सीधा है:
वर्तमान में, अग्रणी मॉडल अपने टोकन उपयोग का सटीक अनुमान नहीं लगा सकते। "एजेंट चलाएं" पर क्लिक करना एक ब्लाइंड बॉक्स खोलने जैसा है—बिल आने तक पता नहीं चलता कि कितना खर्च हुआ।
इस "भ्रमित खाते" के पीछे एक बड़ी उद्योग समस्या छिपी है
पढ़ने के बाद, आप पूछ सकते हैं: इन खोजों का व्यवसायों के लिए क्या अर्थ है?
"मासिक सदस्यता" की कीमत व्यवस्था को एजेंट द्वारा दरार डाली जा रही है
अध्ययन बताता है कि ChatGPT Plus जैसे सब्सक्रिप्शन मॉडल तब तक काम करते हैं जब तक सामान्य बातचीत के लिए टोकन खपत नियंत्रित और भविष्यवाणीय होती है। लेकिन एजेंट कार्य इस मान्यता को पूरी तरह से तोड़ देते हैं—एक कार्य एजेंट के चक्र में फंस जाने के कारण विशाल मात्रा में टोकन खर्च कर सकता है।
इसका अर्थ है कि एजेंट स्थितियों के लिए केवल सदस्यता आधारित मूल्य निर्धारण अस्थायी नहीं हो सकता, और भुगतान-जितना-उपयोग करना (Pay-as-you-go) काफी समय तक सबसे वास्तविक विकल्प बना रहेगा। लेकिन भुगतान-जितना-उपयोग करने की समस्या यह है—उपयोग स्वयं अप्रत्याशित होता है।
2. टोकन की दक्षता को मॉडल चुनने का "तीसरा सूचक" बनना चाहिए
पारंपरिक रूप से, व्यवसाय मॉडल का चयन दो आयामों पर करते हैं: क्षमता (क्या यह कर सकता है) और गति (यह कितनी तेजी से करता है)। इस पेपर ने तीसरा, समान रूप से महत्वपूर्ण आयाम प्रस्तुत किया है: ऊर्जा कुशलता (कितना खर्च करके यह किया जा सकता है)।
एक थोड़ा कम क्षमता वाला लेकिन 3 गुना अधिक कुशल मॉडल, स्केलिंग स्थितियों में "सबसे शक्तिशाली लेकिन सबसे महंगे" मॉडल की तुलना में अधिक आर्थिक मूल्य रख सकता है।
3. एजेंट को "ऑयल गेज" और "ब्रेक" की आवश्यकता है
पेपर में एक महत्वपूर्ण भविष्य की दिशा का उल्लेख किया गया है—बजट-जागरूक टूल-उपयोग नीतियाँ। सरल शब्दों में, इसका मतलब है कि एजेंट को एक "ईंधन मीटर" लगाएँ: जब टोकन का उपयोग बजट के करीब पहुँच जाए, तो इसे अनावश्यक खोज करने से रोक दें, बजाय इसके कि यह पूरी तरह से बर्बाद हो जाए।
वर्तमान में, लगभग सभी प्रमुख एजेंट फ्रेमवर्क में ऐसा तंत्र नहीं है।
एजेंट की "पैसा जलाने की समस्या", बग नहीं, बल्कि उद्योग का अनिवार्य दर्द है
यह अध्ययन किसी मॉडल की कमी नहीं, बल्कि एजेंट पैराडाइम की संरचनात्मक चुनौती को उजागर करता है—जब AI "एक प्रश्न, एक उत्तर" से आगे बढ़कर "स्वतंत्र योजना बनाने, बहु-चरणीय निष्पादन, और बार-बार डीबग करने" की ओर विकसित होता है, तो Token की खपत की अप्रत्याशितता लगभग अनिवार्य है।
अच्छी खबर यह है कि यह पहली बार है जब किसी ने इस भ्रमित खाते को व्यवस्थित रूप से बाहर निकालकर गणना की है। इस डेटा के साथ, डेवलपर्स मॉडल चुनने, बजट सेट करने और स्टॉप-लॉस मैकेनिज्म डिज़ाइन करने के लिए अधिक समझदारी से निर्णय ले सकते हैं; मॉडल निर्माताओं के लिए एक नया अनुकूलन दिशा भी है—केवल अधिक शक्तिशाली बनने के बजाय, अधिक कुशल बनना।
अंततः, AI एजेंट वास्तविक उत्पादन परिवेश में सभी क्षेत्रों में प्रवेश करने से पहले, हर रुपया स्पष्ट रूप से खर्च करना, हर पंक्ति कोड को सुंदर ढंग से लिखने से अधिक महत्वपूर्ण है। (यह लेख पहली बार टाइमेडिया ऐप पर प्रकाशित हुआ, लेखक | सिलिकॉन वैली टेक न्यूज़, संपादक | ज़होंग होंगयू)
नोट: यह लेख arXiv पर 24 अप्रैल, 2026 को प्रकाशित प्रिंटप्रीन्ट पेपर *How Do AI Agents Spend Your Money? Analyzing and Predicting Token Consumption in Agentic Coding Tasks* (Bai, Huang, Wang, Sun, Mihalcea, Brynjolfsson, Pentland, Pei) पर आधारित है। लेखक वर्जीनिया विश्वविद्यालय, स्टैनफोर्ड विश्वविद्यालय, MIT, मिशिगन विश्वविद्यालय आदि संस्थानों से हैं। यह अध्ययन अभी तक समीक्षा के माध्यम से पारित नहीं हुआ है।