










लेखक: हमेशा रास्ते में Max, 01Founder
अगर ओपनएआई के 2025 के लिए एक अंतरिम समीक्षा लिखनी हो, तो कई लोग इसे साधारण या यहां तक कि थोड़ा निष्क्रिय कहेंगे।
पिछले एक से अधिक वर्षों में, उन्होंने वास्तव में तर्क के मार्ग को सफलतापूर्वक लागू किया, o3pro से लेकर o4mini तक के निष्कर्षण मॉडल का घना प्रकाशन किया, और GPT-4.5 और GPT-5 जैसे नए आधार मॉडल भी लॉन्च किए।
लेकिन सामान्य उपयोगकर्ताओं के लिए सबसे आसानी से अनुभव किए जाने वाले और स्वयंसेवी प्रसार के लिए सबसे अधिक उपयुक्त दृश्य उत्पादन क्षेत्र में, उनकी उपस्थिति धीरे-धीरे कम हो रही है।
सोरा के शुरुआती हैरानी के बाद, ओपनएआई इस प्रतियोगिता में लंबे समय तक चुप रही प्रतीत होती है।
Meanwhile, the other players at the table were not idle.
ओपन सोर्स इकोसिस्टम में, फ्लक्स जैसे मॉडल ने उच्च गुणवत्ता वाली स्थानीय छवि उत्पादन की बाधाओं को पूरी तरह से तोड़ दिया है;
व्यावसायिक दृष्टिकोण से, केवल पुराने प्रतिद्वंद्वी ही उच्चतम सौंदर्य बाधाओं को नियंत्रित नहीं करते, बल्कि नैनो-बनाना जैसे ऑनलाइन खोज सुविधा से लैस नए प्रतियोगी भी उभरे हैं।
इसके विपरीत, OpenAI का पिछला प्रमुख इमेज जनरेशन मॉडल GPT-Image-1.5 पहले से ही पुराना प्रतीत हो रहा है:
गुणवत्ता खराब है, लेआउट कठोर है, और जटिल पाठ के सामने अक्सर क्रैश हो जाता है।
धीरे-धीरे, उद्योग में एक सहमति बन गई:
OpenAI विजुअल जनरेशन में तकनीकी बाधा का सामना कर रहा है और विभिन्न प्रतिद्वंद्वियों के घेराबंदी में अब इसे संभालना कठिन हो रहा है।
कुछ हफ्तों पहले तक, मोड़ बहुत गुप्त तरीके से आया।
प्रसिद्ध ब्लाइंड टेस्टिंग प्लेटफॉर्म LM Arena पर, एक रहस्यमय इमेज मॉडल, जिसका कोडनाम Duct Tape है, चुपचाप शामिल हो गया।
अंधे परीक्षण में भाग लेने वाले उपयोगकर्ताओं ने जल्द ही महसूस किया कि कुछ गलत है:
यह मॉडल न केवल चरम अनुपातों को अत्यधिक सटीकता से नियंत्रित करता है, बल्कि बहुभाषी पाठ के साथ बिल्कुल बिना दोष के लेआउट पोस्टर भी उत्पन्न करता है, और शायद चित्र बनाने से पहले एक अदृश्य तार्किक योजना प्रक्रिया होती है।
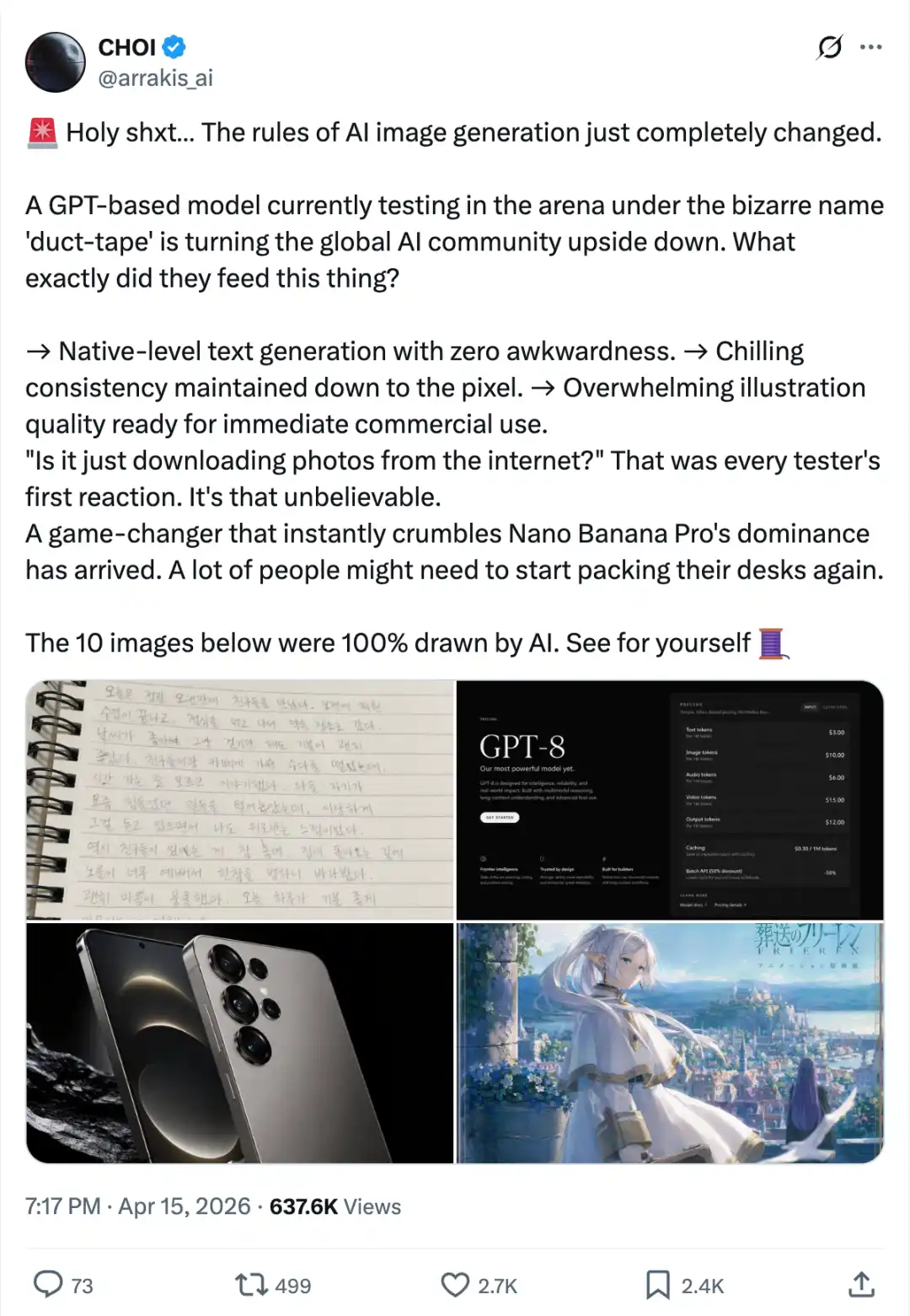
एक समय के लिए, विभिन्न तकनीकी समुदायों ने अनुमान लगाया कि यह किसकी गुप्त रूप से लॉन्च की गई बड़ी चाल है, लेकिन OpenAI ने हमेशा चुप रहा।
The boots finally dropped this morning.
कोई लंबी प्रेस कॉन्फ्रेंस, कोई व्यापक मार्केटिंग प्रचार नहीं, OpenAI ने इस गुप्त नाम वाले मॉडल को आधिकारिक रूप से ChatGPT GPT-Image-2 नाम दिया और इसे पूरी तरह से बाजार में लॉन्च कर दिया।
इसके साथ ही एक ऐसा टेक्स्ट-टू-इमेज प्रतियोगिता रैंकिंग लिस्ट भी जारी किया गया जो कुछ हद तक दम घुटने वाला है।
GPT-Image-2 ने 1512 के अत्यधिक उच्च स्कोर के साथ सीधे शीर्ष स्थान पर कब्जा कर लिया, जो दूसरे स्थान पर (जो इंटरनेट सर्च सुविधा वाला Nano-banana-2 है) से 242 अंकों से आगे है।
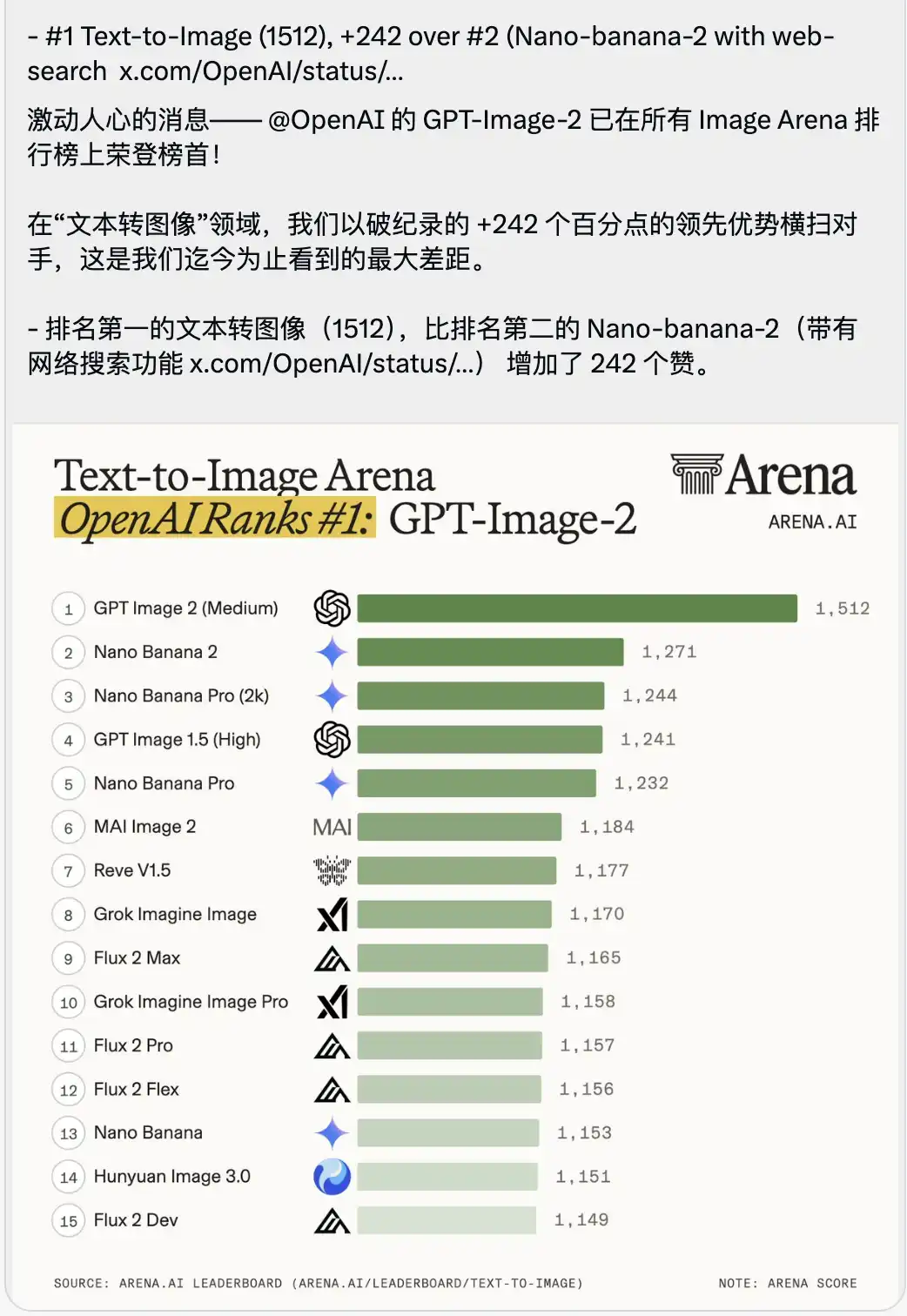
बड़े मॉडल के स्कोरिंग के संदर्भ में, लोग आमतौर पर दशमलव के बाद के अंक या इकाई के स्कोर में अंतर को बहुत बड़े पैमाने पर उठाते हैं, क्योंकि शीर्ष मॉडल्स के बीच स्कोर बहुत करीब होते हैं।
242 का अंतर, प्रतियोगिता के इतिहास में अभूतपूर्व है।
यह कोई छोटा वर्जन अपडेट नहीं है, यह एक क्रूर जनरेशनल ओवरवेल्मेंट है।
मैंने इसकी सभी सीमाएँ और नवीनतम API दस्तावेज़ को ध्यान से पढ़ने में आधा दिन बिता दिया।
एकमात्र सबसे बड़ी भावना है:
OpenAI वही OpenAI है।
जब यह अपनी जमीन वापस पाने का फैसला करता है, तो यह पुरानी कार्ड टेबल को उलट देता है।
इस मॉडल के सामने, जिन विजुअल डिज़ाइन कार्यों को हम सोचते थे कि वे एआई द्वारा पूरी तरह से प्रतिस्थापित होने में अभी दो या तीन साल लगेंगे, आज लगभग पूरी तरह समाप्त हो चुके हैं।
भाग.01 छवि उत्पादन: मॉडल से विजुअल एजेंट तक
GPT-Image-2 द्वारा इतना बड़ा स्कोर अंतर कैसे पैदा हुआ, यह समझने के लिए आपको पाठ से छवि बनाने वाले मॉडल के पुराने धारणाओं को भूलना होगा।
पहले हम AI का उपयोग चित्र बनाने के लिए करते थे, जो मूल रूप से एक ब्लाइंड बॉक्स खींचना था, कुछ प्रॉम्प्ट शब्द डालकर इंतजार करना कि यह पिक्सेल को आपकी इच्छा के अनुसार व्यवस्थित कर दे।
लेकिन GPT-Image-2 एक ऐसा एजेंट की तरह है जिसमें विजुअल इंजन एम्बेडेड है।
सबसे स्पष्ट परिवर्तन यह है कि इसने विधि में सीधे दो पूर्णतः अलग मोड अलग कर दिए हैं।
एक तत्काल मोड (Instant Mode) है जो सभी उपयोगकर्ताओं के लिए उपलब्ध है।
यह मॉडल त्वरित प्रतिक्रिया और जीवन और कार्य प्रवाह के बिना रुके समाहितीकरण पर केंद्रित है।
जैसे कि आप अपने फोन पर इसे एक निर्देश भेजें, तो यह कुछ सेकंड में एक संरचित चित्र दे देगा।
इसकी निहित दृश्य बुद्धिमत्ता अत्यंत शक्तिशाली है, लेकिन यह मुख्य रूप से उच्च आवृत्ति वाली, एकल-बार की दृश्य रूपांतरण आवश्यकताओं को हल करती है।
और भुगतान किए गए उपयोगकर्ताओं के लिए उपलब्ध विचार अवस्था (Thinking Mode)।
इसके एक भी पिक्सेल को रेंडर करने से पहले, यह कुछ दशकों के लॉजिकल रीजनिंग और ऑनलाइन सर्च में जाता है।
यही पैटर्न है, जो एक अत्यंत मूलभूत लेकिन अत्यंत कठिन प्रश्न को हल करता है:
The model knew for the first time what it was supposed to draw.
सबसे सीधा उदाहरण दें।
आप चैट बॉक्स में टाइप करें:
डक टेप इस रहस्यमय मॉडल के बारे में ऑनलाइन लोगों के मूल्यांकन ढूंढें और चैटजीपीटी का क्वार्ट कोड जोड़ें।

अगर पुराने मॉडल का उपयोग किया जाए, तो यह नहीं जानता कि नेटिजन्स ने क्या कहा है, यह केवल एक पोस्टर बनाएगा जिसमें अर्थहीन अक्षर होंगे, और क्वार्ट कोड भी एक झूठी छवि होगी जिसे स्कैन नहीं किया जा सकता।
लेकिन सोचने की मोड में, इसका कार्यप्रवाह ऐसा है:
यह पहले ड्रॉइंग को रोक देगा, इंटरनेट सर्च टूल को शुरू करेगा, और Reddit, Threads या LinkedIn पर उपयोगकर्ताओं के वास्तविक रिव्यूज़ को स्क्रैप करेगा;
फिर, यह पोस्टर के लेआउट, खाली स्थान और फ़ॉन्ट हाइरार्की की योजना बनाना शुरू करता है;
अंत में, यह एक वास्तविक, उपयोगयोग्य क्वार्ट कोड बनाता है जिसे सीधे स्कैन करके जा सकता है, और पूरी छवि को रेंडर करता है।

यह अब केवल चित्र बनाने की बात नहीं है, यह वास्तव में स्वयं अनुसंधान, योजना बनाने, कॉपी निकालने और लेआउट डिज़ाइन करने का एकल प्रक्रिया है।
यहाँ एक समानांतर तुलना करने की आवश्यकता है।
जो लोग बड़े मॉडल समुदाय का अनुसरण करते हैं, वे जानते हैं कि इंटरनेट और खोज क्षमता वाले इमेज जनरेशन मॉडल को OpenAI ने पहली बार नहीं बनाया था।
दूसरे स्थान पर रहे Nano-banana में पहले से ही यह तंत्र था।
लेकिन नैनो-बनाना का वास्तविक उपयोग करते समय, आप देखेंगे कि यह कई जगहों पर थोड़ा बेवकूफ लगता है।
नैनो-बनाना का विचार अक्सर एक यांत्रिक संयोजन तर्क होता है।
जैसे आप उसे एक पोस्टर बनाने के लिए एक उद्योग के रुझान ढूंढने के लिए कहें, तो वह वास्तव में ढूंढता है, लेकिन आमतौर पर यह केवल विकिपीडिया के वाक्यों को कठोरता से काटकर सीधे छवि पर चिपका देता है।
जब किसी अमूर्त व्यावसायिक आवश्यकताओं को समझने के लिए निर्देश दिए जाते हैं, तो यह आसानी से भ्रमित हो जाता है।

वह महसूस करना, जैसे एक ऐसा इंटर्न जो बात समझता है, लेकिन बिल्कुल भी अनुभव नहीं रखता, कार्यों को समझता है, लेकिन रणनीति को पूरी तरह से नहीं समझता।
लेकिन GPT-Image-2 का इस क्षेत्र में प्रदर्शन अतिशयोक्ति से भी अधिक है।
इसका विचार केवल एक रूटीन के रूप में नहीं है, बल्कि पीछे के सांस्कृतिक संदर्भ और व्यावसायिक इरादों को वास्तव में समझता है।
मैंने टेस्ट के दौरान एक अत्यंत सरल चीनी निर्देश दिया: मुझे एक स्क्रीनशॉट बनाएं जिसमें मस्क डायंगशो में डोउबाओ की बिक्री कर रहा हो।
पिछले चित्रण मॉडल का उपयोग करने पर, आपको एक सफेद व्यक्ति की तस्वीर बनाई जाएगी जो मस्क की तरह दिखता है, जिसके हाथ में एक बाओज़ि है, पृष्ठभूमि अस्पष्ट है, और यहां तक कि डायनामिक टिकटॉक कैसा दिखता है, इसका पता भी नहीं है।
लेकिन थिंकिंग मोड में, GPT-Image-2 द्वारा दिए गए परिणाम थोड़े डरावने लगते हैं।
यह केवल तत्वों को जोड़ने के बजाय, चीनी इंटरनेट की समझ को स्वयं सक्रिय करते हुए, डायन्सी लाइवस्ट्रीम यूआई स्क्रीनशॉट का पिक्सेल-लेवल प्रतिकृति बनाता है।
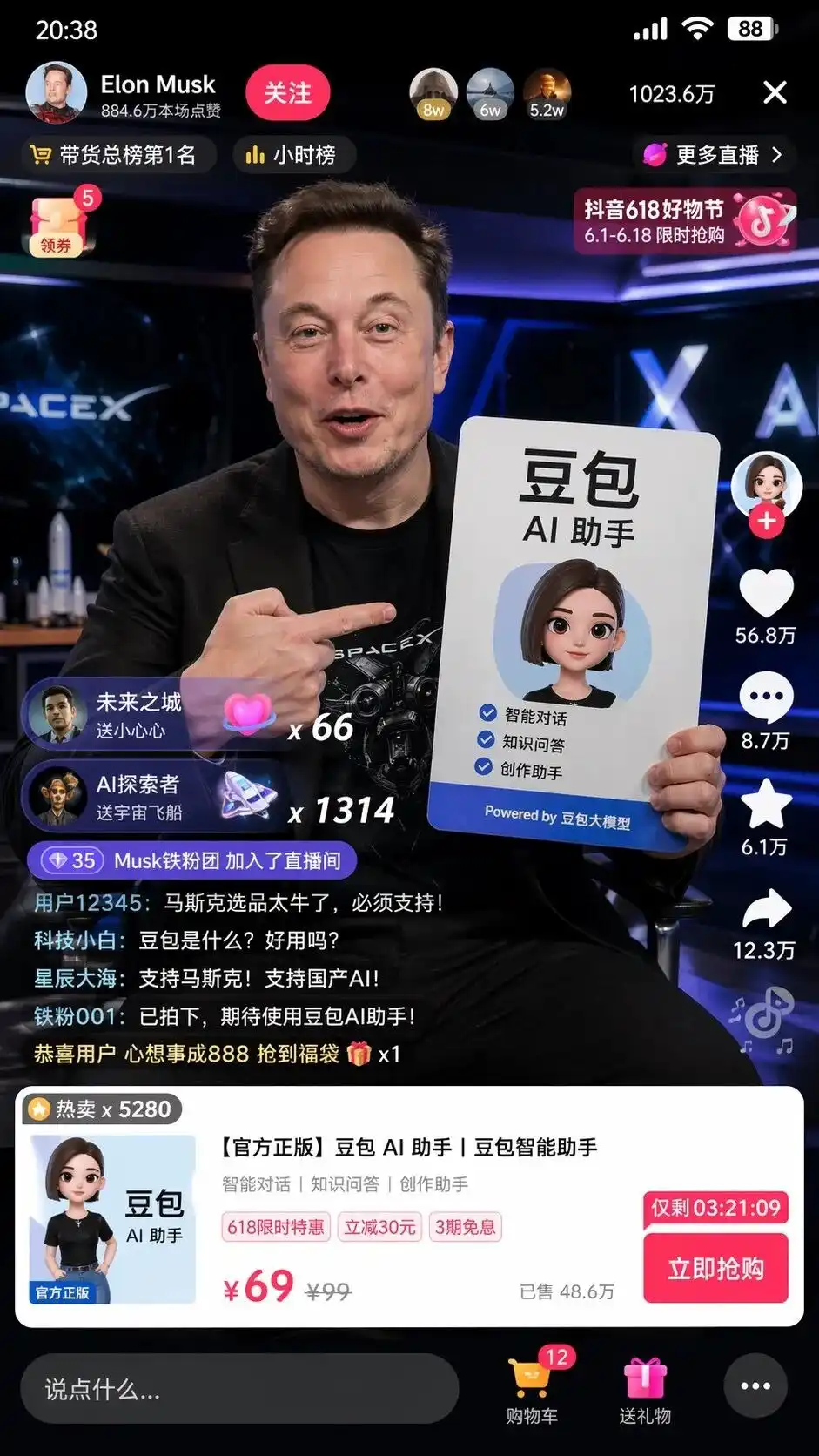
स्क्रीन पर केवल एक वास्तविकता जैसा मस्क ही नहीं, बल्कि परफेक्ट टाइपोग्राफी वाले डोउबाओ AI असिस्टेंट के विज्ञापन प्लैकार्ड को उठाए हुए हैं, और यह भी डरावना है कि उन विस्तारों को जो प्रॉम्प्ट में शामिल नहीं थे:
बाएं ऊपरी कोने में फॉलो बटन और घंटे की सूची, दाएं ऊपरी कोने में 1023.6 लाख ऑनलाइन उपयोगकर्ता, नीचे स्क्रीन पर पॉप अप होने वाला मानक प्रोडक्ट कार्ड, और क्रॉस आउट कीमत 99, ऑफर कीमत 69 और गिनती के साथ तुरंत खरीदें बटन दिखाया गया है।
नीचे बाएँ कोने में बहुत वास्तविक दिखने वाले नेटिज़न्स के कमेंट्स स्क्रॉल हो रहे हैं:
टेक नोविस: डोबाओ क्या है? क्या यह उपयोगी है?
स्टार ओशन: मस्क का समर्थन करें! घरेलू AI का समर्थन करें!
किसी ने उसे नहीं बताया कि चैट बॉक्स में क्या लिखना है, प्रोडक्ट यूआई कैसा दिखना चाहिए, और कीमत कैसे तय करनी है।
यह मॉडल ने डोउयिन शॉपिंग और डोबाओ बड़ा मॉडल इन दो टैग्स के विश्लेषण के बाद मानवीय दिमाग के लिए पूर्ण व्यावसायिक UI डिज़ाइन और ऑपरेशन प्लानिंग को कल्पना करके और निष्पादित किया है।
अब चित्र उत्पादन पर बड़े मॉडल के मूल्यांकन के मापदंड बस यह देखने तक सीमित नहीं रह गए हैं कि यह सुंदर बना सकता है या नहीं, बल्कि यह भी देखा जा रहा है कि यह रणनीति और लेआउट तर्क को समझता है या नहीं।
PART.02 वास्तविक परीक्षण में मूल क्षमताएँ
इसकी सीमा जानने के लिए, मैंने व्यावसायिक डिज़ाइन के मानकों के अनुसार कुछ अक्सर आने वाले और जटिल परिदृश्यों का परीक्षण किया।
यह पाया गया कि इसकी समस्या हल करने की निर्णय बिंदु की सूक्ष्मता भयानक रूप से सूक्ष्म है।
पहला सीन: विजुअल अवबोध और बिजनेस साइकिल (मॉडल को कपड़े पहनाना)
पारंपरिक ई-कॉमर्स विज़ुअल या फैशन प्लानिंग में, एक आइडिया से लेकर उसे पहने हुए देखने तक के बीच का निष्पादन लागत बहुत अधिक होती है।
आप मॉडल ढूंढ रहे हैं, कपड़े उधार ले रहे हैं, स्टूडियो सेट कर रहे हैं, और पोस्ट-प्रोडक्शन में सुधार कर रहे हैं।
बाद में AI आया, और लोगों ने व्यक्ति के चेहरे को स्थिर करने के लिए LoRA मॉडल ट्रेन करना शुरू कर दिया, लेकिन इसके लिए अभी भी कई दर्जन तस्वीरों की आवश्यकता होती है और सीखने की काफी लागत होती है।
GPT-Image-2 में, इस प्रक्रिया को अत्यधिक संकुचित कर दिया गया है।
मैंने अपनी एक दैनिक सेल्फी अपलोड की और उसे बताया कि मैं अगले महीने एक द्वीप छुट्टी पर जा रहा हूँ, और मुझे कुछ आउटफिट्स सुझाएं।
इसने पहले मुझे 8 अलग-अलग स्टाइल के ग्रीष्मकालीन कपड़ों का एक एल्बम दिया, जिसकी व्यवस्था पेशेवर ई-कॉमर्स लुकबुक की तरह थी, और प्रत्येक वस्तु के बगल में सही टेक्स्ट लेबल भी थे।
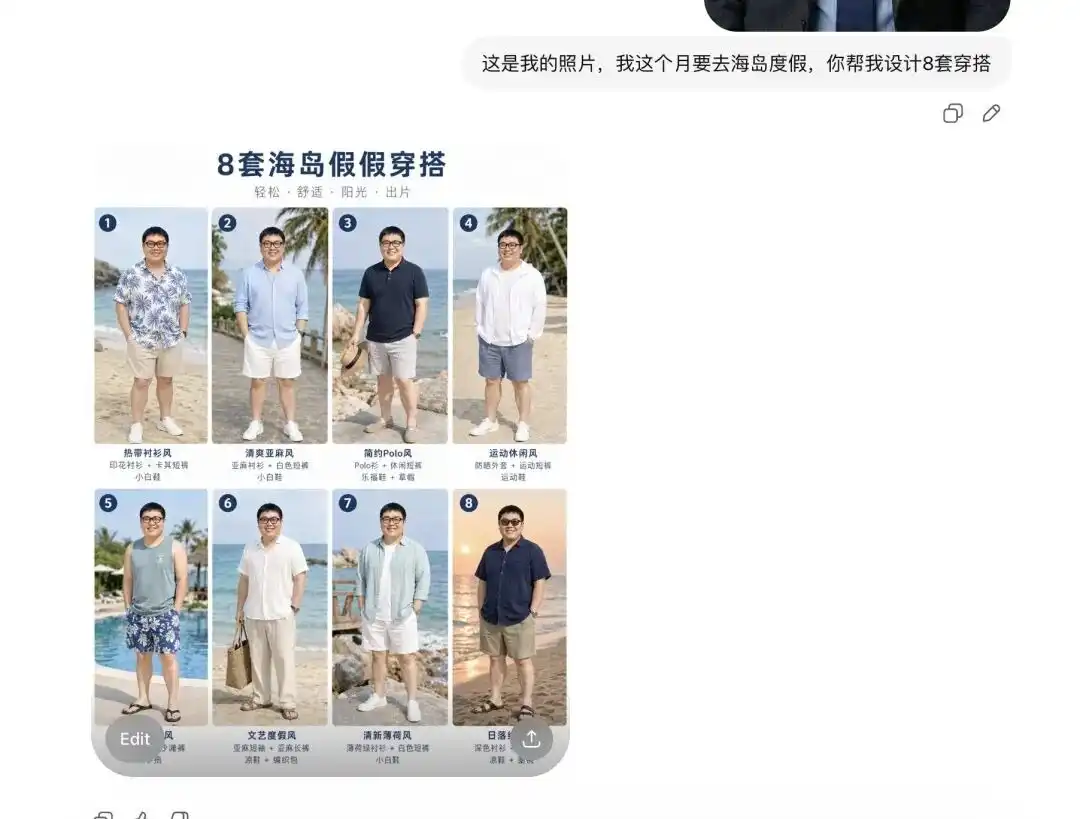
अधिक महत्वपूर्ण बात यह है कि इस क्षण में ही यह मेरे चेहरे के लक्षणों और शरीर के अनुपात को सटीकता से विश्लेषित कर चुका है।
जब मैंने उससे कहा कि मैं पहले सेट को पहने हुए देखना चाहता हूँ और कुछ अलग-अलग कोणों से डिटेल इमेज चाहता हूँ, तो उसने सीधे मेरी उस खुद की तस्वीर से व्यक्ति को निकाल दिया, उस पर गर्मियों का कपड़ा पहना दिया, और पार्श्व, अर्ध-शरीर आदि विभिन्न कोणों से चित्र उत्पन्न कर दिए।

यह मोड़ बहुत चिकना है। इसका मतलब है कि प्रारंभिक कपड़ों की रेंडरिंग, या उन बाहरी नियुक्तियों को जिनमें मॉडल्स द्वारा कपड़े पहनने का काम होता है, उनकी प्रतिस्पर्धी बाधा पूरी तरह से कट गई है।
दूसरा परिदृश्य: सुसंगठितता और निरंतर कथानक को हल करना (एक वाक्य में कॉमिक बनाएं)
AI इमेज बनाने वाले सभी जानते हैं कि AI को एक सुंदर तस्वीर बनाना आसान है, लेकिन एक ही व्यक्ति की दस तस्वीरें बनाना और उनकी गतिविधियों और दृष्टिकोण को संगठित रखना कठिन है।
यही समानता (Consistency) की समस्या कहलाती है।
लेकिन इस वास्तविक परीक्षण में, मैंने एक ऐसा मामला देखा जो पिछले अनुभव के विपरीत था।
आप केवल कल अपने दोस्त के साथ एक फोटो अपलोड कर सकते हैं, और एक बहुत ही सरल प्रॉम्प्ट टाइप कर सकते हैं:
हम दोनों को मुख्य पात्र बनाएं, तीन जापानी कॉमिक्स पृष्ठ बनाएं, जिसकी कहानी आप तय करें।
कुछ ही सेकंड में, यह एक मानक शॉट लिस्ट के साथ तीन पृष्ठों की ब्लैक एंड व्हाइट कॉमिक्स आउटपुट करता है।
सबसे डरावनी बात यह है कि इन दोनों वास्तविक व्यक्तियों से बनाए गए कार्टून किरदार तीन पृष्ठों के अलग-अलग शॉट्स में हैं।

निकट के शॉट, दूर के दृश्य, पीछे का दृश्य, या उनके चेहरे के विशेष लक्षण, बालों के विस्तारित विवरण और कपड़ों के झुर्रियाँ, सभी पूर्ण समानता के साथ बनाए गए हैं।
अधिक विस्मयकारी बात यह है कि कॉमिक की कहानी पूरी तरह से सुसंगठित है, और यहां तक कि डायलॉग बॉक्स में लिखा गया पाठ भी पूर्ण कहानी तर्क को बनाए रखता है।

समय और स्थान की समानता को सुनिश्चित करना दर्शाता है कि यह एकल छवि उत्पादन के क्षेत्र से बाहर निकल गया है और लगातार कथानक के निर्देशन की क्षमता रखता है।
तीसरा परिदृश्य: टेक्स्ट रेंडरिंग की अंतिम सीमा पार करना (बहुभाषी टाइपोग्राफी)
अगर सुसंगठितता कहानी की समस्या को हल करती है, तो बहुभाषी पाठ का सटीक रेंडरिंग वास्तव में ग्राफिक डिजाइनर को कोने में धकेल देता है।
पहले जब भी चित्र में कुछ पाठ होता था, तो बड़े मॉडल अजीब चित्र बनाने लगते थे।
क्योंकि मॉडल द्वारा समझी जाने वाली टेक्स्ट टोकन (अर्थपूर्ण ब्लॉक) होती है, जबकि उत्पन्न छवियाँ पिक्सेल बिंदु होती हैं, जो पहले अलग-अलग थीं।
GPT-Image-2 ने इस समस्या को पूरी तरह से हल कर दिया।
मैंने एक फ्रेंच फैशन मैगजीन कवर बनाया, एक जापानी रेस्तरां का मेनू जिसमें पूर्ण हिरागाना और कैनजी हैं, और यहां तक कि रूसी टिप्पणियों का अत्यधिक सघन टाइपोग्राफी भी आजमाया।

The result is one-time成型, zero spelling errors.
सबसे निराशाजनक बात यह है कि यह केवल शब्दों को सही तरीके से लिखता है, बल्कि भाषा के अनुसार स्थानीय सांस्कृतिक सौंदर्य और फ़ॉन्ट डिज़ाइन के साथ मेल भी खाता है।
उदाहरण के लिए, जापानी प्रचार पत्रक में हनजी का उपयोग बहुत स्थानीय जापानी पुरानी कलात्मक फॉन्ट में किया गया है, और हिरागाना की व्यवस्था जापानी के ऊर्ध्वाधर पठन की परंपरा के अनुसार है।
लेआउट डिजाइन पहले ग्राफिक डिजाइनरों की अपनी जमीन थी।
अक्षर अंतराल कैसे समायोजित करें, प्राथमिकता कैसे निर्धारित करें, और पाठ और बैकग्राउंड के बीच दृश्य संतुलन कैसे प्राप्त करें — इसके लिए बहुत सारी अभ्यास की आवश्यकता होती है।
लेकिन जब AI इतनी सारी भाषाओं को शून्य त्रुटि के साथ संभाल सकता है और उसमें उन्नत टाइपोग्राफी की सुंदरता भी होती है, तो दैनिक पोस्टर, प्रचार पुस्तिकाएँ और फीड विज्ञापनों के लिए अब मैनुअल रेखाएँ संरेखित करने की आवश्यकता नहीं है।
चौथा सीन: विकृत अनुपात और चरम सूक्ष्म नियंत्रण (चावल के दाने पर उकेरा गया अक्षर)
अंत में, इसकी अनुपालन क्षमता कितनी भयावह है, यह देखने के लिए, मैंने इसे कुछ बहुत कठिन निर्देश दिए।
मैंने पहले इसकी चरम पहलू का परीक्षण किया।
पारंपरिक डिफ्यूजन मॉडल अनुकूलित अनुपात से बहुत डरते हैं।
पहले थोड़ा चित्र खींचने पर, चित्र में दो सिर निकल आते थे।
लेकिन मैंने Images 2.0 से 3:1 की अत्यधिक चौड़ी और 1:3 की लंबी तस्वीरें बनाने का अनुरोध किया, और यह न केवल बिगड़ा नहीं, बल्कि शुरुआत और अंत को जोड़कर एक तार्किक रूप से बंद 360 डिग्री पैनोरमिक छवि भी बनाई।
2015 के एक बार के उपयोग वाले कैमरे से ली गई फोटो के बाद, पुराने लेंस का विकृति और फ्लैश की दीवार पर कमजोर प्रतिबिंब दोनों को स्पष्ट रूप से दोहराया गया।
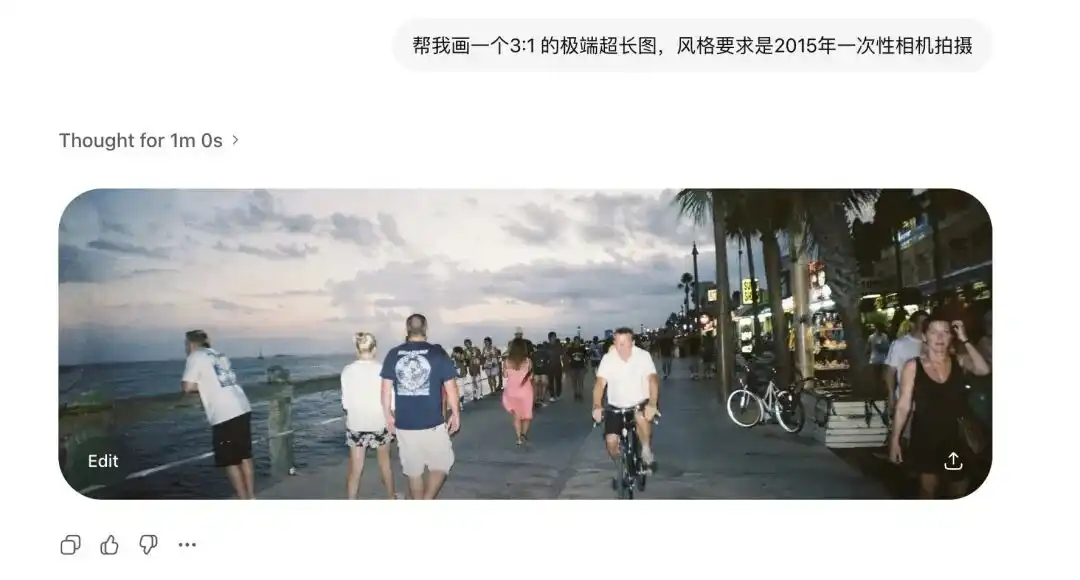
और इसकी सूक्ष्म नियंत्रण क्षमता को और अधिक दर्शाने वाला, प्रेस कॉन्फ्रेंस में प्रदर्शित एक थोड़ा पागलपन भरा चावल का परीक्षण है।
शोधकर्ताओं ने वर्तमान में आंतरिक परीक्षण के चरण में रहने वाले प्रयोगात्मक 4K API को कॉल किया, उन्होंने मैक्रो फोटोग्राफी, 8K अल्ट्रा-हाई डेफिनिशन जैसे किसी भी शब्द का उपयोग नहीं किया, बस एक अत्यंत अमूर्त साधारण निर्देश दिया:
एक ढेर चावल। इस ढेर के एक अनाज पर GPT Image 2 लिखा हुआ है।
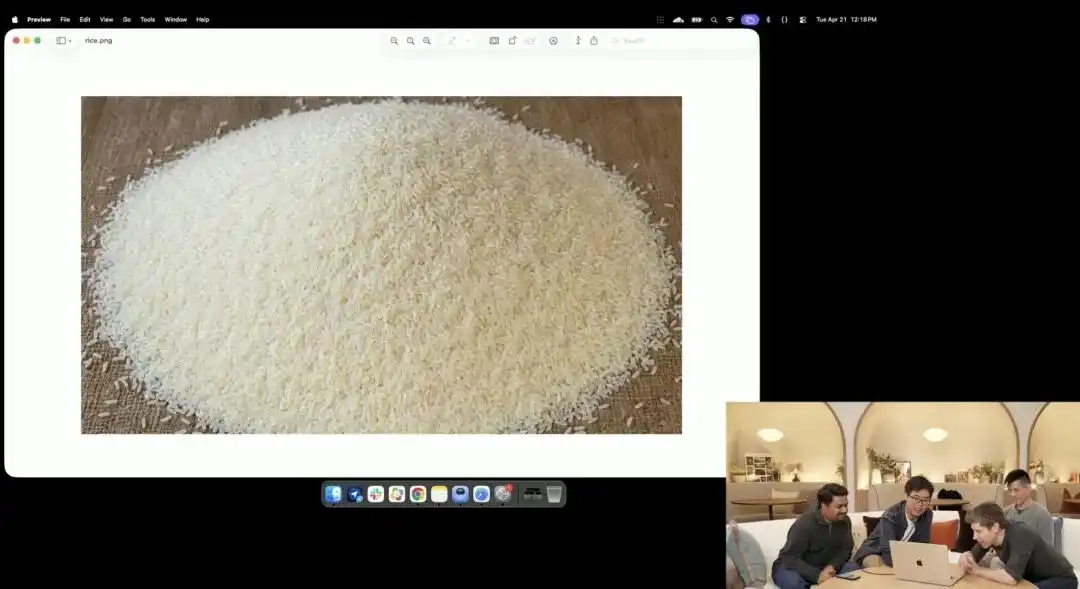
जब स्क्रीन पर चित्र को दहाई गुना तक बड़ा किया जाता है और पिक्सेल के कण दिखाई देने लगते हैं, तो क्या आप सचमुच एक ढेर चावल में से एक अक्षर खुदे हुए सूक्ष्म कण को ढूंढ पाएंगे?
This rice still conforms to the laws of physics, with the text precisely embedded along the subtle curvature of the grain.
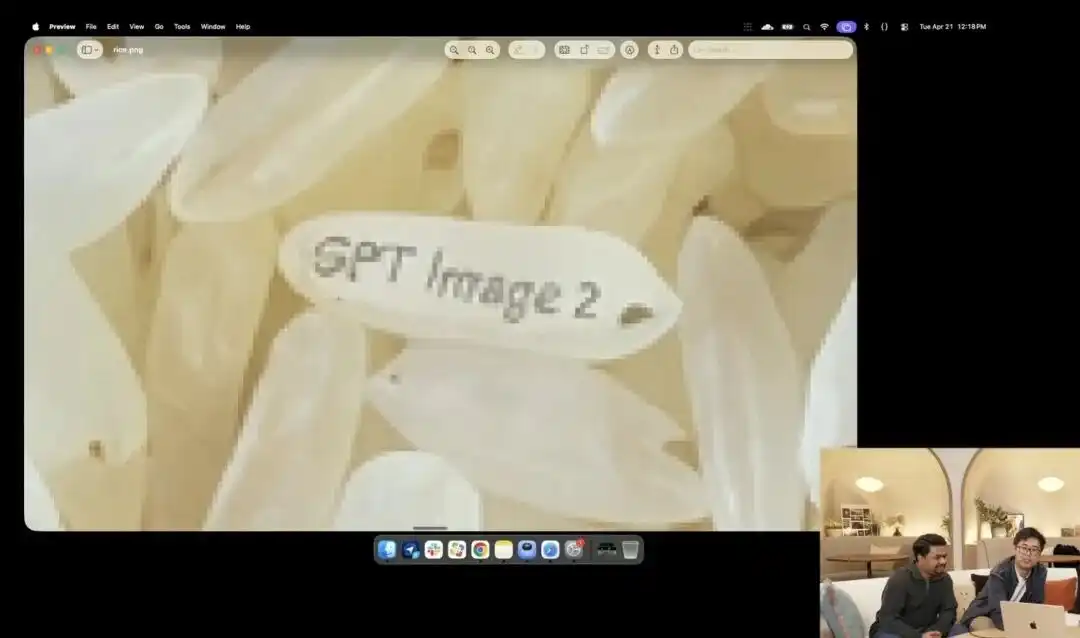
शेष सभी कार्य—मैक्रो व्यू को कॉल करना, डीप्थ ऑफ फील्ड की गणना करना, लेटेंट स्पेस में उस एक चावल के भौतिक निर्देशांक को ढूंढना और उस पर अक्षर छापना—सभी बड़े मॉडल द्वारा विचार अवस्था में स्वयं ही सोचे गए और पूरे किए गए।
यह मामला स्पष्ट रूप से दर्शाता है कि मॉडल की अंतरिक्ष स्थिति की समझ पिक्सेल-स्तरीय शल्य चिकित्सा सटीकता तक पहुँच गई है।
इसका अर्थ है कि अब आप वास्तविक कार्य में डिज़ाइन के किसी भी छोटे हिस्से को सटीकता से संशोधित कर सकते हैं, जहाँ चाहें वहीं संशोधन कर सकते हैं, जबकि पहले आप गले को बदलना चाहते थे, तो पूरी छवि बदल जाती थी।
भाग.03 कुछ तकनीकी विवरण
इस चरम नियंत्रण और रणनीतिक बुद्धिमत्ता को बस बेकार की गणना क्षमता के ढेर से नहीं बनाया जा सकता।
इसकी असली क्षमताओं को समझने के लिए, मैंने GPT-Image-2 के लिए कुछ प्रोब टेस्ट किए।
एक बहुत दिलचस्प बात सामने आई।
हालांकि आधिकारिक दस्तावेज़ में GPT-Image-2 के कुल ज्ञान आधार की समाप्ति तिथि अपडेट करके दिसंबर 2025 बताई गई है, लेकिन मेरे वास्तविक परीक्षण में।
इंस्टेंट मोड के ट्रेनिंग डेटा की अंतिम तारीख अभी भी 2024 की मई के अंत तक है;

और उस लंबे विचार की आवश्यकता वाली विचार अवस्था (Thinking Mode) का मूल ज्ञान-भंडार लगभग जून 2024 तक का है (लेकिन वास्तविक समय में इंटरनेट से जुड़कर वर्तमान सटीक तारीख प्राप्त की जा सकती है)।

इन दो समय बिंदुओं के आधार पर, पूरे GPT-Image-2 की नींव के बारे में कुछ निशान दिखाई देते हैं।
सबसे पहले उच्च आवृत्ति चित्रण पर ध्यान केंद्रित करने वाले तत्काल मोड की बात करते हैं।
2024 की मई की सीमा का अर्थ है कि यह अधिक संभावना है कि o4-mini का सीधा उपयोग किया गया है, या GPT-5 परिवार का हल्का संस्करण (GPT-5 mini या अत्यंत न्यून पैरामीटर वाला GPT-5 nano) है।
क्योंकि इस हल्के आधार के पास पहले से ही अत्यधिक क्षमता है कि वह स्थान योजना बना सके और जटिल निर्देशों को समझ सके, ऊपरी चित्र उत्पादन स्थिर रह सकता है और अव्यवस्थित नहीं हो सकता।
और वह अत्यंत बुद्धिमान, व्यापारिक रणनीति को समझने वाला विचारधारा, उसका आधार GPT-5 मॉडल नहीं हो सकता।
क्योंकि GPT-5 की बेसिक ज्ञान बेस की समाप्ति तिथि सितंबर 2024 है।
थिंकिंग मोड अधिक संभावना है कि बैकग्राउंड में निरंतर अपडेट हो रहे O सीरीज़ इन्फरेंस मॉडल (जैसे o4 या अपडेटेड o3) से जुड़ा हुआ है।
बड़े मॉडल पहले O सीरीज के विशिष्ट लंबे विचार तंत्र का उपयोग करते हुए, लेटेंट स्पेस में व्यावसायिक तर्क, दर्शक मनोविज्ञान और लेआउट निर्देशांक सभी को स्पष्ट रूप से कैलकुलेट करते हैं, और फिर अंतिम पिक्सेल रेंडरिंग के लिए विजुअल मॉड्यूल को सौंप देते हैं।
हालांकि, एक अन्य संभावित मार्ग भी है:
OpenAI के अत्यंत सूक्ष्म कैलकुलेशन रिसोर्स अलॉकेशन मैकेनिज्म के तहत, फास्ट मोड संभवतः GPT-5 nano का उपयोग करता है, जबकि थिंकिंग मोड GPT-5 mini और बाहरी उपकरणों का संयोजन उपयोग करता है।
लेकिन चाहे कोई भी बेस कॉम्बिनेशन हो, अगर आप OpenAI के API इकोसिस्टम पर लगातार नजर रखते हैं, तो आप देखेंगे कि इसकी नींव की जनरेशन लॉजिक पहले से ही Midjourney से पूरी तरह अलग लेवल पर है।
भाग 04 सबसे अधिक चर्चित मूल्य निर्धारण
लेकिन बेस का अनुमान लगाने के बजाय, वास्तविक रूप से इसे अपने कार्यप्रवाह में जोड़ने वाले डेवलपर्स और उद्यमों के लिए, अधिक महत्वपूर्ण है वह अत्यंत वास्तविक और अप्रत्यक्ष API मूल्य निर्धारण सारणी।
पहले DALL-E 3 को प्रति छवि के आधार पर शुल्क देना पड़ता था (जैसे 0.04 डॉलर प्रति छवि)।
लेकिन पहली पीढ़ी GPT-Image-1 से ही, OpenAI ने इसे टोकन-आधारित बिलिंग फ्रेमवर्क में पूरी तरह से बदल दिया है।
GPT-Image-2 इस मानक को फिर से जारी रखता है, और इसके अलावा, यह एक बेहतर ऑफर के साथ आया है।
ऑफिशियल द्वारा हाल ही में जारी की गई कीमत सूची के अनुसार, प्रति मिलियन टोकन की कीमत निम्नलिखित है।
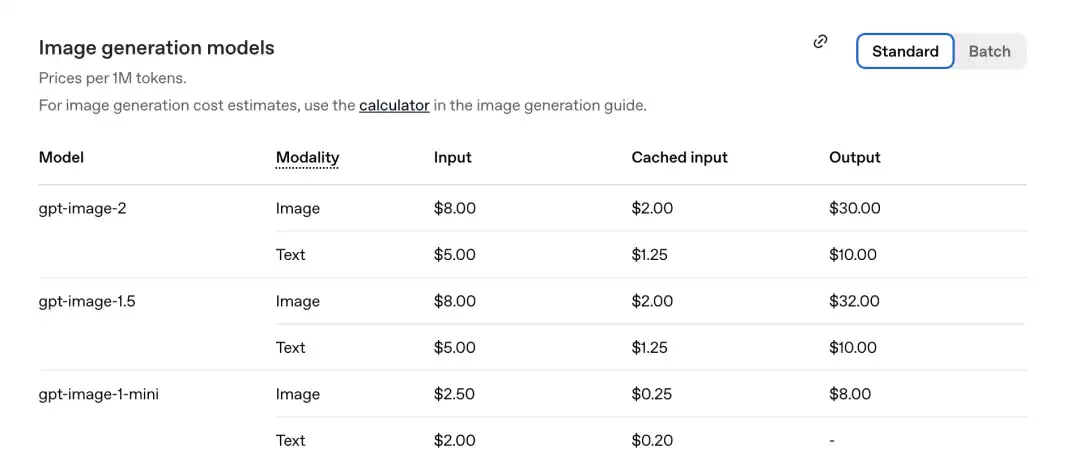
GPT-Image-2 छवि भाग: इनपुट 8.00, कैश्ड इनपुट (Cachedinputs) 2.00, आउटपुट $30.00।
पिछली पीढ़ी gpt-image-1.5 की तुलना में: आउटपुट $32.00 है।
नया मॉडल अब अधिक सस्ता है।
चलिए एक गणना करते हैं।
पिछले मॉडल में, एक उच्च गुणवत्ता वाली छवि बनाने के लिए लगभग 1000 से 1500 आउटपुट टोकन की खपत होती थी।
प्रति मिलियन आउटपुट टोकन 30 डॉलर की कीमत के अनुसार, एक चित्र बनाने की वास्तविक लागत लगभग 0.03 से 0.045 डॉलर के बीच होती है (लगभग 2 से 3 माओ चीनी युआन)।
अगर आपको तुरंत जवाब की आवश्यकता नहीं है और आप औपचारिक रूप से प्रदान किए गए Batch (बैच) API मोड का उपयोग करते हैं, तो इस कीमत में सीधे 50% की कमी हो जाएगी (आउटपुट सीधे $15.00 तक घट जाएगा)।
इसके अनुसार, एक चित्र बनाने की न्यूनतम लागत केवल 10 पैसे से थोड़ी अधिक है।
इस एकल कीमत में पहले से ही काफी बेहतर मूल्य है, लेकिन इसकी असली कुंजी, मूल्य सारणी में उपलब्ध कैश्ड इनपुट (Cached inputs) है।
पहले कॉमिक बुक या सीरीज के पोस्टर डिज़ाइन बनाते समय, हर बार नया जनरेट करने के लिए आपको बहुत सारी किरदार रेफरेंस इमेजेस, पिछली स्थिति और लंबे प्रॉम्प्ट्स फिर से अपलोड करने पड़ते थे, जिससे इनपुट लागत बहुत अधिक होती थी।
लेकिन वर्तमान टोकन बिलिंग मॉडल के तहत, जब आप एक साथ 8 लगातार कॉमिक्स जेनरेट करते हैं, तो पहली छवि के विजुअल तत्वों को सीधे कॉन्टेक्स्ट कैश में सहेजा जाता है।
दूसरी तस्वीर से शुरू करते हुए, इमेज की इनपुट लागत सीधे $8.00 से गिरकर $2.00 हो गई (यानी केवल 25% का शुल्क लिया जा रहा है)।
इसका अर्थ है कि बड़े पैमाने पर व्यावसायिक बैच इमेज जनरेशन या अत्यधिक किरदार समानता की आवश्यकता वाले लगातार जनरेशन के दौरान, इसकी सीमांत लागत सीधे गिरती है।
जितना अधिक बुद्धिमान और अधिक चित्र बनाने वाला मॉडल, उतना कम होता है प्रति चित्र की औसत लागत।
यह औद्योगिक बिलिंग तर्क ही वास्तव में लाइन आउट आर्टिस्ट को कोने में दबा देता है।
PART.05 पृष्ठभूमि टीम का अनावरण
अंत में, हम इस लाइव ब्रीफिंग में प्रस्तुत किए गए OpenAI की आंतरिक विजुअल स्वप्न टीम पर वापस जाते हैं, जिससे पहले जो फ़ंक्शन अतिशयोक्तिपूर्ण लगते थे, वे पूरी तरह समझ में आ जाते हैं।
उदाहरण के लिए, यह बहुभाषी जटिल लेआउट और अर्थहीन लिखावट की समस्याओं को कैसे हल करता है।
इसके लिए टीम के वरिष्ठ वैज्ञानिक गैब्रिएल गोह का योगदान अपरिहार्य है।

In this academic circle, he is most renowned as the core author of the groundbreaking multimodal model CLIP.
CLIP ने आधुनिक AI को यह समझने का आधार दिया कि मानव भाषा और चित्र पिक्सेल कैसे संबंधित होते हैं।
इस बहुमोडल सेमेंटिक मैपिंग के विद्वान के नेतृत्व में, GPT-Image-2 अब बस टेक्स्ट के आकार का अनुमान लगाने की बजाय, पिक्सेल स्तर पर वास्तव में लिख रहा है।
इसी तरह, यह त्रिआयामी स्थानिक संबंधों को कैसे समझता है, चरम लंबाई-चौड़ाई अनुपात वाली 360 डिग्री पैनोरमिक छवियाँ बना सकता है, और चावल के दाने पर माइक्रो-दूरी के प्रकाश और छाया को समझ सकता है।
यह दूसरे कोर सदस्य एलेक्स यू के श्रेय को जाता है।

उससे पहले कि वह OpenAI में शामिल हुआ, वह 3D जनरेशन के क्षेत्र में प्रसिद्ध स्टार्टअप Luma AI के सह-संस्थापक और पूर्व CTO थे, और 3D न्यूरल रेंडरिंग (NeRF आदि) पर विशेष रूप से काम करने वाले शीर्ष शोधकर्ता थे।
उसकी उपस्थिति में, GPT-Image-2 वास्तव में पारंपरिक 2D पिक्सेल पेंटिंग से आगे निकल गया है।
यह शायद मन में पहले एक त्रिआयामी दृश्य बनाता है, प्रकाश को सेट करता है, और फिर आपको एक सटीक 2D काट देता है।
वह अत्यंत भयानक बहु-पृष्ठीय कॉमिक की सुसंगठितता कैसे प्राप्त की गई।
यह मैसाचुसेट्स इंस्टीट्यूट ऑफ टेक्नोलॉजी (MIT CSAIL) से हाल ही में स्नातक हुए युवा जोड़े के लिए है:
बोयुआन चेन (बाएं) और किवहान सॉन्ग (दाएं)।
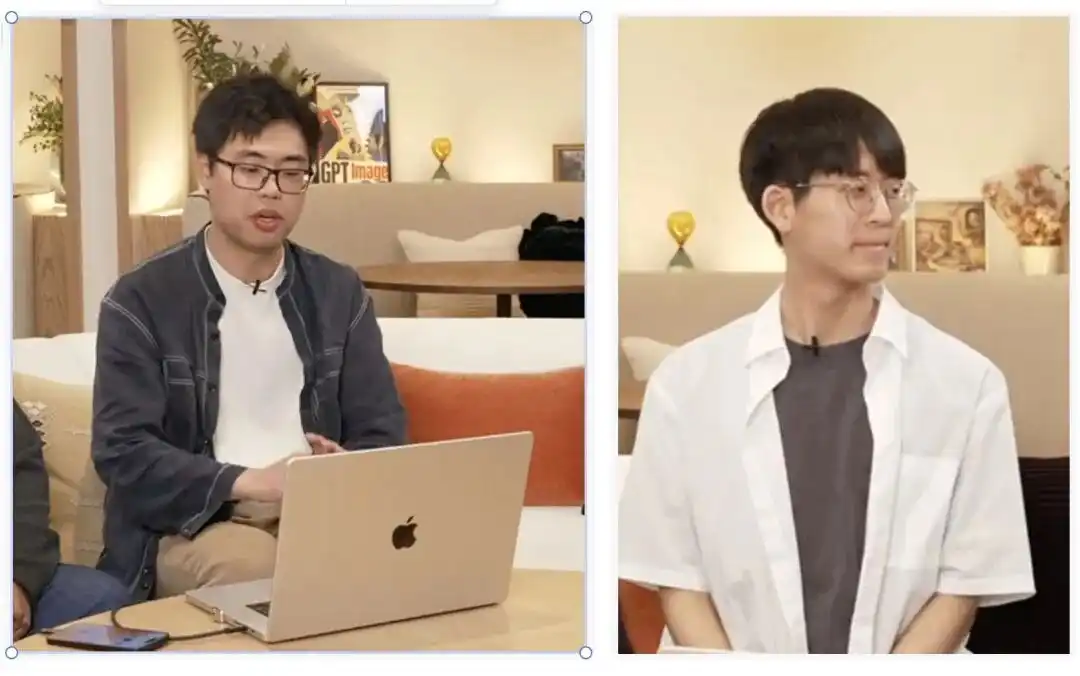
उनकी शैक्षणिक समुदाय में मुख्य दिशाएँ वर्ल्ड मॉडल्स और एम्बॉडिड इंटेलिजेंस हैं।
सीखने के लिए मशीन को भौतिक दुनिया के काम करने का तरीका समझना है, ताकि किरदार विभिन्न समय और स्थान के शॉट्स में पूरी तरह से समान रहें और विकृत न हों, यही उन दोनों विद्वानों का वह प्रश्न है जिसे वे हल करने की कोशिश कर रहे हैं।
अंत में, निथांथ कुडिगे (बाएं, O सीरीज इन्फरेंस मॉडल के महत्वपूर्ण लेखक) और केनजी हाता (दाएं, पूर्व गूगल रिसर्चर, स्टैनफोर्ड विजुअल लैब से स्नातक) को शामिल किया गया है, जो इन्फरेंस बड़े मॉडल और विजुअल बेसिक लॉजिक के बीच की खाई को पार करने के लिए सदैव समर्पित रहे हैं।

जब यह लोग एक साथ आते हैं, तो नीचली तर्कसंगतता, 3D स्थान रेंडरिंग, ग्राफिक्स और पाठ की अत्यधिक संरेखण, और भौतिक दुनिया के नियमों को एक ही मॉडल में स्वाभाविक रूप से जोड़ दिया जाता है।
भाग.06 GPT-Image-2 की सीमाएँ
किसी भी मॉडल की सीमाएँ होती हैं।
The official also admits that it still struggles in the face of certain extreme situations.
जैसे कि कागज़ के तह के निर्देश, रूबिक्स क्यूब को हल करना, या अत्यधिक सघन रेत के कणों जैसी अत्यधिक दोहराव वाली विस्तारित विवरण, अभी भी इसकी क्षमता की सीमा को छूते हैं।
लेकिन व्यावसायिक अनुप्रयोग के संदर्भ में, यह अत्यंत नगण्य दोष है।
पूरे डिजाइन उद्योग के लिए, हमें चिंता का व्यापार नहीं करना चाहिए, यह सौंदर्य के अंत का प्रतिनिधित्व नहीं करता है।
स्वाद, व्यावसायिक दृष्टिकोण और रणनीति को समझने वाले लोग अभी भी इससे बेहतरीन चीजें बना सकते हैं।
लेकिन वास्तविक तथ्य यह है कि डिज़ाइनर के रूप में एक पेशे की सुरक्षा वाली दीवार को वास्तव में तोड़ दिया गया है।
पहले, डिज़ाइन सॉफ्टवेयर की शॉर्टकट कुंजियों को याद करने, फॉन्ट को सीधा और समानांतर बनाने, भाषा के अनुसार टेक्स्ट को व्यवस्थित करने, और सूक्ष्म फोटो संपादन और बैकग्राउंड हटाने के कौशल से जीवित रहना पड़ता था।
लेकिन अब यह मुश्किल हो जाएगा, क्योंकि जो कौशल पहले स्पष्ट मूल्य के साथ व्यापार के लिए उपलब्ध थे, अब कोई भी व्यक्ति एक वाक्य से मुफ्त में उन्हें निर्देशित कर सकता है।
एक लंबे समय तक चुप रहने के बाद, OpenAI ने एक बहुत ही शांत, लेकिन अत्यंत घातक तरीके से साबित कर दिया कि इस टेबल पर किसके पास वास्तव में अंतिम पत्ते हैं।
पुराना निष्पादन उपकरण श्रृंखला टूट रहा है, और उद्योग के लिए अब प्रश्न यह नहीं है कि AI क्या हमें प्रतिस्थापित करेगा, बल्कि हमें इस नई उत्पादन लाइन के साथ कैसे अनुकूलित किया जाए।