










स्रोत: CoinW रिसर्च इंस्टीट्यूट
सारांश
Gradients एक डिसेंट्रलाइज्ड AI ट्रेनिंग सबनेट (SN56) है जो Bittensor पर बनाया गया है, जिसका केंद्र “टास्क पोस्टिंग, माइनर प्रतिस्पर्धा, वेरिफिकेशन स्क्रीनिंग” जैसे मैकेनिज़म पर है, जो मॉडल ट्रेनिंग को जटिल तकनीकी प्रक्रिया से बाजार-संचालित नेटवर्क सहयोग में बदलता है। इसकी आर्किटेक्चर में AutoML और डिस्ट्रीब्यूटेड कैलकुलेशन को एक साथ जोड़ा गया है, जो एक प्रेरणा-आधारित ट्रेनिंग मार्केट बनाता है, जो AI के उपयोग की सीमा कम करता है और कैलकुलेशन की दक्षता में सुधार करता है। पारिस्थितिकी और डेटा प्रदर्शन के संदर्भ में, Gradients ने मूल नेटवर्क इंफ्रास्ट्रक्चर पूरा कर लिया है, लेकिन वर्तमान में प्रेरणा भार और निवेश कम हैं। Gradients TAO पारिस्थितिकी में ट्रेनिंग इंफ्रास्ट्रक्चर को पूरा करता है और “बाजार-संचालित AI अनुकूलन” के एक नए पैटर्न का पता लगाता है, जिसकी दीर्घकालिक रूप से डिसेंट्रलाइज्ड AI ट्रेनिंग के महत्वपूर्ण एंट्री पॉइंट के रूप में विकास की संभावना है।
1. Web2 AutoML से शुरू करते हैं: AI प्रशिक्षण की वर्तमान स्थिति और सीमाएँ
1.1 ऑटोएमएल क्या है
पारंपरिक जागरूकता के अनुसार, एक AI मॉडल को प्रशिक्षित करना एक उच्च बाधा वाली प्रक्रिया है, जिसमें इंजीनियर्स को डेटा को संसाधित करना, मॉडल चुनना, पैरामीटर को बार-बार समायोजित करना और प्रभाव का मूल्यांकन करना शामिल होता है, जिससे पूरी प्रक्रिया जटिल और समय लेने वाली हो जाती है। जबकि AutoML (ऑटोमेटेड मशीन लर्निंग) के आगमन से, ये सभी जटिल चरणों को "ऑटोमेटेड पैकेज" के रूप में समझा जा सकता है। इसे एक "ऑटोमैटिक मॉडल बनाने वाला टूल" के रूप में समझा जा सकता है: उपयोगकर्ता केवल डेटा प्रदान करते हैं और सिस्टम को बताते हैं कि वे क्या प्राप्त करना चाहते हैं, जैसे वर्गीकरण, भविष्यवाणी या पहचान, और शेष प्रक्रियाएँ—जैसे मॉडल का चयन, पैरामीटर समायोजन, प्रशिक्षण और अनुकूलन—सिस्टम द्वारा स्वचालित रूप से पूरा कर ली जाती हैं। इससे AI, केवल कुछ पेशेवर इंजीनियरों के लिए एक उपकरण से, सामान्य डेवलपर्स और यहाँ तक कि कंपनियों के लिए एक उपलब्ध क्षमता में परिवर्तित हो गया है, जो AI के सामान्यीकरण की महत्वपूर्ण कदम है।
1.2 पारंपरिक AutoML की मुख्य सीमाएँ
वर्तमान में AutoML के प्रमुख कार्यान्वयन बादल प्रदाताओं के प्लेटफ़ॉर्म पर केंद्रित हैं, जैसे Google Vertex AI और AWS SageMaker, जो "AI प्रशिक्षण एक सेवा के रूप में" प्रदान करते हैं। हालाँकि Web2 AutoML ने AI के उपयोग की बाधाओं को काफी कम कर दिया है, लेकिन इसके नीचे के मॉडल में अभी भी स्पष्ट सीमाएँ मौजूद हैं। पहली सीमा केंद्रीकरण है, जहाँ कंप्यूटिंग शक्ति, मूल्य निर्धारण और नियम सभी प्लेटफ़ॉर्म द्वारा नियंत्रित होते हैं, जिससे उपयोगकर्ता एकल सेवा प्रदाता पर अधिक निर्भर हो जाते हैं और बातचीत की क्षमता कम होती है। दूसरी सीमा लागत की उच्चता और अपारदर्शिता है, क्योंकि AI प्रशिक्षण के लिए आवश्यक GPU संसाधन मुख्य रूप से बादल प्रदाताओं के पास केंद्रित हैं, और मूल्य निर्धारण प्रणाली में बाजार-आधारित प्रतिस्पर्धा की कमी है। अधिक महत्वपूर्ण बात यह है कि अनुकूलन की दक्षता में सीमा है। पारंपरिक AutoML मूल रूप से "एक प्रणाली जो आपके लिए सर्वोत्तम हल ढूंढती है" है, चाहे यह प्रणाली कितनी भी जटिल क्यों न हो, मूलतः यह एकल प्रौद्योगिकी मार्ग के अनुकूलन पर आधारित है। इसका अन्वेषण स्थान सीमित है, और यह एक साथ कई पूरी तरह से अलग-अलग दृष्टिकोणों का प्रयास करने में सक्षम नहीं है। इसलिए, वर्तमान Web2 AI प्रशिक्षण एक "बंद प्रणाली" है, जहाँ मॉडल का प्रशिक्षण, अनुकूलन और संसाधन आवंटन, सभी एकल प्लेटफ़ॉर्म द्वारा नियंत्रित परिवेश में होते हैं। यह मॉडल कुशल है, लेकिन मांग के बढ़ने के साथ, इसकी सीमाएँ धीरे-धीरे स्पष्ट होने लगी हैं।
2. ग्रेडिएंट्स: AI ट्रेनिंग को "नेटवर्क" के साथ पुनर्निर्मित करें
2.1 Gradients क्या है: एक डिसेंट्रलाइज्ड AutoML प्लेटफॉर्म
पिछले अध्याय में हमने उल्लेख किया कि पारंपरिक Web2 AutoML की मुख्य समस्या “बंद प्रणाली” है, जिसमें मॉडल प्रशिक्षण प्लेटफॉर्म पर निर्भर करता है, अनुकूलन के मार्ग सीमित होते हैं और संसाधनों की गतिशीलता सीमित होती है। Gradients इस मॉडल का एक पुनर्निर्माण है। Gradients WanderingWeights द्वारा शुरू किए गए डिसेंट्रलाइज्ड इंजीनियर समुदाय से उत्पन्न हुआ है, जो Bittensor नेटवर्क पर आधारित है और Subnet 56 पर चलने वाला एक AI प्रशिक्षण सबनेट है। पारंपरिक प्लेटफॉर्म के विपरीत, यह केंद्रीकृत सेवाएँ प्रदान नहीं करता, बल्कि प्रशिक्षण प्रक्रिया को विभाजित करके एक खुले नेटवर्क पर सौंप देता है। उपयोगकर्ता केवल अपना कार्य लक्ष्य परिभाषित करते हैं, जैसे मॉडल प्रकार और डेटा, और शेष प्रक्रियाएँ, जिनमें प्रशिक्षण निष्पादन, पैरामीटर अनुकूलन और परिणाम छंटनी शामिल हैं, सभी नेटवर्क द्वारा स्वचालित रूप से पूरा की जाती हैं। इस मॉडल में, AI प्रशिक्षण को जटिल इंजीनियरिंग प्रक्रिया से हटाकर “आवश्यकता सबमिट करें, परिणाम प्राप्त करें” जैसी सरल प्रक्रिया में परिवर्तित कर दिया गया है, जो एक विशेषज्ञता-आधारित प्रौद्योगिकी के स्थान पर एक सामान्य क्षमता के समान है।
2.2 बंद प्रणाली से खुली सहयोग तक: ग्रेडिएंट्स क्या समस्या का समाधान करते हैं
Gradients का मुख्य परिवर्तन यह है कि इसने मूल रूप से एकल प्लेटफॉर्म के भीतर सीमित प्रशिक्षण प्रक्रिया को एक खुली सहयोगात्मक नेटवर्क प्रक्रिया में बदल दिया है। प्रशिक्षण कार्य अब एकल सिस्टम द्वारा पूरा नहीं किए जाते, बल्कि उन्हें कई सहभागियों के बीच वितरित किया जाता है ताकि वे समानांतर रूप से प्रयास कर सकें, और फिर एक समान मूल्यांकन तंत्र के माध्यम से सर्वोत्तम परिणाम चुने जाएँ। इस संरचना से सबसे पहले केंद्रीकृत सेवा प्रदाताओं पर निर्भरता कम होती है, और प्रशिक्षण वितरित कंप्यूटिंग पावर पर स्थापित होता है; साथ ही, विखंडित GPU संसाधनों को एक ही नेटवर्क में एकीकृत किया जाता है, जहाँ प्रतिस्पर्धा के माध्यम से बाजार-आधारित संसाधन आवंटन के करीब पहुँचा जाता है। महत्वपूर्ण बात यह है कि मॉडल अनुकूलन अब एकल मार्ग पर सीमित नहीं है, बल्कि कई विधियों के समानांतर अन्वेषण में लगातार बेहतर समाधान की ओर अग्रसर होता है, जिससे समग्र अनुकूलन सीमा में सुधार होता है।
2.3 मूलभूत परिवर्तन: उपकरण से "प्रशिक्षण बाजार" तक
पारंपरिक AutoML में, प्लेटफॉर्म एक उपकरण की तरह होता है, जो आंतरिक एल्गोरिदम के माध्यम से उपयोगकर्ताओं को आदर्श समाधान ढूंढने में मदद करता है। जबकि Gradients में, यह प्रक्रिया एक निरंतर संचालित "बाजार" के समान है: उपयोगकर्ता आवश्यकताएँ प्रकाशित करते हैं, विभिन्न प्रतिभागी एक ही कार्य के चारों ओर प्रतिस्पर्धा करते हैं, और मूल्यांकन तंत्र के माध्यम से परिणाम छाँटे जाते हैं। इससे, मॉडल प्रदर्शन अब केवल एकल प्रणाली की क्षमता पर निर्भर नहीं होता, बल्कि बहुपक्षीय सहभागिता के तहत निरंतर प्रतिस्पर्धा और पुनरावृत्ति पर निर्भर करता है। AutoML भी एक सापेक्ष बंद तकनीकी अनुकूलन समस्या से एक प्रेरणा-संचालित गतिशील प्रक्रिया में बदल गया है, जिससे अनुकूलन क्षमता प्रतिभागियों की संख्या के साथ विस्तारित हो सकती है। यह परिवर्तन, AI प्रशिक्षण को बाजार की तरह स्वयं को विकसित करने की क्षमता प्रदान करता है।
2.4 TAO इकोसिस्टम में भूमिका: AI ट्रेनिंग इंफ्रास्ट्रक्चर लेयर
बिटटेंसर के सबनेट सिस्टम में, विभिन्न सबनेट निष्पादन, डेटा प्रोसेसिंग और प्रशिक्षण जैसे विभिन्न कार्यों को संभालते हैं, और ग्रेडिएंट्स स्थिति प्रशिक्षण स्तर पर है। यह विखंडित कैलकुलेशन क्षमता को वास्तविक मॉडल आउटपुट में बदलने के लिए जिम्मेदार है और कार्य वितरण और मूल्यांकन तंत्र के माध्यम से इन संसाधनों को निरंतर नियोजित और अनुकूलित करने में सक्षम बनाता है। इसके साथ ही, यह कैलकुलेशन सप्लाई और मॉडल डिमांड के बीच कड़ी बनाता है, जिससे प्रशिक्षण केवल संसाधन खपत की प्रक्रिया से एक संगठित और अनुकूलित नेटवर्क सहयोग प्रक्रिया में परिवर्तित हो जाता है। इस प्रणाली में, ग्रेडिएंट्स एक केंद्रीय घटक की तरह है, जो वितरित संसाधनों को उपयोगयोग्य AI क्षमताओं में परिवर्तित करता है और ऊपरी स्तर के अनुप्रयोगों के विकास का समर्थन करता है।
3. कोर आर्किटेक्चर: AI ट्रेनिंग कैसे नेटवर्क में पूरी की जाती है
पिछले अध्याय में हमने उल्लेख किया था कि Gradients ने AI प्रशिक्षण को "प्लेटफ़ॉर्म के भीतर पूरा करने" से बदलकर "नेटवर्क द्वारा सहयोग से पूरा करने" में बदल दिया है। तो, यह नेटवर्क वास्तव में कैसे काम करता है? इस अध्याय का मुख्य उद्देश्य इस प्रक्रिया को अधिक स्पष्ट तरीके से विघटित करना है।
3.1 वितरित प्रशिक्षण: एक कार्य कैसे "कई लोगों द्वारा पूरा" किया जाता है
Gradients को एक निरंतर चल रहा “ट्रेनिंग सहयोगी नेटवर्क” मान सकते हैं। जब कोई उपयोगकर्ता एक ट्रेनिंग टास्क सबमिट करता है, तो यह टास्क किसी एक सिस्टम को नहीं दिया जाता, बल्कि नेटवर्क के कई सहभागियों को एक साथ भेज दिया जाता है। ये सहभागी एक ही डेटा और लक्ष्य के आधार पर, अलग-अलग ट्रेनिंग विधियों का प्रयास करते हैं और निर्धारित समय के भीतर अपने परिणाम सबमिट करते हैं। इसके बाद, सिस्टम इन परिणामों का एक सामान्य मूल्यांकन करता है और सबसे अच्छा प्रदर्शन करने वाला समाधान चुनता है। अंततः, सर्वश्रेष्ठ परिणाम को पुरस्कार मिलता है, जबकि अन्य समाधानों को अस्वीकार कर दिया जाता है। उपयोगकर्ता के दृष्टिकोण से, इस प्रक्रिया में केवल एक ही टास्क शुरू करना पर्याप्त है, जिससे स्वचालित रूप से कई अलग-अलग अनुकूलन दृष्टिकोणों का “उपयोग” होता है और सर्वोत्तम हल चुना जाता है। इस तरीके की मुख्य बात यह नहीं है कि कोई एकल नोड कितना मजबूत है, बल्कि यह है कि कई लोगों के समानांतर प्रयास + स्वचालित छंटनी के माध्यम से परिणाम सतत सर्वोत्तम की ओर बढ़ते हैं।
इस नेटवर्क में मुख्य रूप से तीन प्रकार के प्रतिभागी होते हैं: उपयोगकर्ता, माइनर और प्रमाणीकर्ता। उपयोगकर्ता ट्रेनिंग की आवश्यकताएँ प्रस्तुत करते हैं; माइनर कंप्यूटिंग पावर प्रदान करते हैं और विभिन्न ट्रेनिंग विधियों का प्रयास करते हैं; प्रमाणीकर्ता परिणामों का मूल्यांकन करते हैं और सर्वोत्तम मॉडल का चयन करते हैं। यह विभाजन ट्रेनिंग प्रक्रिया को निरंतर चलने और बेहतर समाधानों को चयनित करने की अनुमति देता है। समग्र रूप से, यह “आवश्यकता, आपूर्ति, मूल्यांकन” द्वारा संचालित एक सहयोगी नेटवर्क का निर्माण करता है।
3.2 बाजार-संचालित AutoML
पिछले मैकेनिज़म के विश्लेषण से स्पष्ट है कि Gradients ने AutoML को सिर्फ़ ब्लॉकचेन पर लागू नहीं किया है, बल्कि बहुपक्षीय भागीदारी और प्रोत्साहन तंत्र को शामिल करके मॉडल अनुकूलन की मूलभूत तर्कशक्ति को बदल दिया है। पारंपरिक AutoML एकल प्रणाली पर निर्भर करता है, जो सीमित मार्गों में उत्तम समाधान ढूंढती है, जबकि Gradients में यह प्रक्रिया पूरे नेटवर्क तक विस्तारित हो गई है: विभिन्न प्रतिभागी एक ही कार्य के लिए लगातार विभिन्न विधियों का प्रयास करते हैं और एक समान मूल्यांकन के माध्यम से निरंतर छंटनी और पुनरावृत्ति करते हैं। इससे मॉडल अनुकूलन एक एकल-बार की गणना प्रक्रिया नहीं, बल्कि एक पुनरावर्ती रूप से विकसित होने वाली गतिशील प्रक्रिया बन जाती है। इस मैकेनिज़म के तहत, बेहतर प्रदर्शन वाले परिणामों को अधिक लाभ मिलता है, जिससे प्रतिभागी सतत रूप से अपनी रणनीति को अनुकूलित करने के लिए प्रेरित होते हैं, और समग्र प्रदर्शन में सुधार होता है।
4. प्रोत्साहन और प्रतिस्पर्धा तंत्र: AI प्रशिक्षण कैसे "सकारात्मक चक्र" बनाता है
4.1 प्रोत्साहन तंत्र (TAO ड्राइवन): प्रशिक्षण कार्य से आय लाभ तक
ग्रेडिएंट्स के लंबे समय तक संचालन की कुंजी पृष्ठभूमि में उत्तेजना तंत्र है। यह बिटटेंसर द्वारा प्रदान की गई मूल उत्तेजना प्रणाली पर निर्भर करता है। इसमें, TAO बिटटेंसर नेटवर्क का मूल टोकन है, जो पूरे नेटवर्क में “मूल्य वाहक” के रूप में कार्य करता है: एक ओर यह गणना शक्ति और मॉडल योगदान प्रदान करने वालों को पुरस्कृत करने के लिए उपयोग किया जाता है, और दूसरी ओर, इसे क्वेस्टिंग आदि के माध्यम से सबनेट वजन वितरण में शामिल किया जाता है, जिससे संसाधनों का विभिन्न सबनेट्स के बीच प्रवाह प्रभावित होता है।
बिटटेंसर मेननेट निरंतर नए प्रोत्साहन उत्सर्जन (Emission) यानी TAO (वर्तमान में दैनिक उपयुक्त मात्रा लगभग 3600 TAO) उत्पन्न करता रहता है और इसे विभिन्न सबनेट्स के बीच एक निश्चित नियम के अनुसार वितरित किया जाता है। प्रत्येक सबनेट को कितना मिलेगा, यह इस बात पर निर्भर करता है कि वह पूरे नेटवर्क में कितना “प्रदर्शन” कर रहा है, जैसे सक्रियता, योगदान की गुणवत्ता और वित्तीय समर्थन आदि। ग्रेडिएंट्स के सबनेट के लिए, इस वितरित TAO को आंतरिक रूप से प्रतिभागियों के बीच पुनः वितरित किया जाएगा। वितरण का मुख्य आधार यह है कि किसका मॉडल बेहतर है, उसे अधिक लाभ मिलेगा।
विस्तार से देखें, माइनर ट्रेनिंग परिणाम जमा करते हैं, और वेरिफायर इन परिणामों की परीक्षा करते हैं और उन्हें स्कोर देते हैं। सिस्टम स्कोरिंग के आधार पर प्रत्येक भागीदार का "योगदान भार" गणना करता है और फिर इस भार के अनुसार पुरस्कार वितरित करता है। बेहतर प्रदर्शन करने वाले मॉडल (जैसे जो अधिक सामान्यीकरण क्षमता और स्थिर परिणाम प्रदान करते हैं) को अधिक लाभ मिलता है, जबकि वेरिफायर्स को भी अधिक प्रोत्साहन मिलता है यदि वे अधिक सटीक स्कोरिंग करते हैं और वास्तविक गुणवत्ता को बेहतर ढंग से प्रतिबिंबित करते हैं। इस डिज़ाइन से "बेहतर करना" सीधे "अधिक कमाना" से जुड़ा होता है, जिससे भागीदार मॉडल को लगातार अनुकूलित करने के लिए प्रेरित होते हैं।
4.2 सबनेट्स के बीच प्रतिस्पर्धा: केवल आंतरिक प्रतिस्पर्धा ही नहीं, बल्कि बाहरी रैंकिंग भी
ग्रेडिएंट्स को केवल सबनेट के अंदर की प्रतिस्पर्धा ही नहीं, बल्कि बिटटेंसर नेटवर्क के पूरे ढांचे में “क्षैतिज प्रतिस्पर्धा” का सामना करना पड़ता है। चूंकि TAO का वितरण गतिशील है, इसलिए विभिन्न सबनेट्स उच्चतर वजन प्राप्त करने के लिए आपस में प्रतिस्पर्धा करते हैं। केवल वे ही सबनेट्स बड़ा पुरस्कार हिस्सा प्राप्त कर पाते हैं जो लगातार उच्च गुणवत्ता वाले परिणाम प्रदान करते हैं और अधिक सहभागियों को आकर्षित करते हैं। इसलिए, ग्रेडिएंट्स के प्रोत्साहन केवल आंतरिक मॉडल प्रदर्शन पर ही निर्भर नहीं करते, बल्कि इसकी पूरे पारिस्थितिकी तंत्र में सापेक्ष प्रतिस्पर्धात्मकता पर भी निर्भर करते हैं। पूरी प्रणाली एक बहु-स्तरीय चक्र बनाती है: सबनेट के अंदर मॉडलों के बीच प्रतिस्पर्धा होती है; सबनेट्स के बीच समग्र प्रदर्शन की प्रतिस्पर्धा होती है। अंततः, कैलकुलेशन की आपूर्ति, मॉडल प्रभावशीलता और आर्थिक प्रतिफल एक साथ जुड़ जाते हैं, जो एक सतत कार्यरत सकारात्मक प्रतिक्रिया चक्र बनाते हैं।
4.3 ग्रेडिएंट्स 5.0: प्रतिस्पर्धा से “टूर्नामेंट मैकेनिज्म” तक
प्रारंभिक निरंतर प्रतिस्पर्धा के आधार पर, ग्रेडिएंट्स ने एक अधिक संरचित तंत्र, अर्थात् "टूर्नामेंट-आधारित प्रशिक्षण" के रूप में विकास किया। इसे एक नियमित प्रतियोगिता के रूप में समझा जा सकता है: प्रत्येक प्रशिक्षण चक्र में समय खिड़की निर्धारित की जाती है, कई प्रतिभागी एक ही कार्य के लिए प्रतिस्पर्धा करते हैं, और बहु-चरणीय छांटने के माध्यम से क्रमिक रूप से अयोग्य प्रतिभागियों को हटा दिया जाता है, अंततः सर्वोत्तम समाधान का चयन किया जाता है। इस रूप में चरणबद्ध तुलना और केंद्रित मूल्यांकन पर जोर दिया जाता है। एक महत्वपूर्ण परिवर्तन यह है कि माइनर्स अब प्रशिक्षण परिणाम सीधे सबमिट नहीं करते हैं, बल्कि "प्रशिक्षण विधि" (कोड) सबमिट करते हैं, जिसे वेरिफायर नोड्स समेकित रूप से निष्पादित करते हैं। इससे एक ओर समानता में सुधार होता है, क्योंकि विभिन्न कंप्यूटेशनल परिवेशों के कारण होने वाले हस्तक्षेप से बचा जाता है, और दूसरी ओर डेटा और प्रशिक्षण प्रक्रिया की गोपनीयता को बेहतर ढंग से सुरक्षित किया जाता है। इसके अलावा, विजेता समाधान को प्रायः संचित कर लिया जाता है, जो पुनःउपयोगयोग्य विधि के रूप में कार्य करता है, मानो कि "सर्वश्रेष्ठ प्रथाओं" का सतत संचय हो। दीर्घकाल में, यह तंत्र केवल सर्वोत्तम मॉडल का चयन ही नहीं करता, बल्कि सतत विकसित होते हुए प्रशिक्षण विधि संग्रह का निर्माण भी करता है।
5. पारिस्थितिकी की वर्तमान स्थिति
5.1 भागीदार संरचना: आवश्यकता, आपूर्ति और मूल्यांकन से बना सहयोगी नेटवर्क
Gradients इकोसिस्टम तीन प्रकार के केंद्रीय भूमिकाओं से बना है: उपयोगकर्ता (मांग पक्ष), माइनर (आपूर्ति पक्ष) और प्रमाणीकर्ता (मूल्यांकन पक्ष)। उपयोगकर्ता मुख्य रूप से AI डेवलपर, छोटे और मध्यम उद्यम और Web3 बिल्डर हैं, जो आमतौर पर कुछ तकनीकी ज्ञान रखते हैं, लेकिन कम्प्यूटेशनल पावर या पूर्ण मॉडल ट्रेनिंग क्षमता की कमी का सामना करते हैं, इसलिए वे Gradients के माध्यम से कम लागत पर मॉडल बनाने की प्राथमिकता देते हैं। माइनर GPU कम्प्यूटेशनल पावर प्रदान करते हैं और ट्रेनिंग कार्यों के लिए प्रतिस्पर्धा करते हैं, जिनका मुख्य उद्देश्य TAO रिवॉर्ड प्राप्त करना है; प्रमाणीकर्ता ट्रेनिंग परिणामों का मूल्यांकन और क्रमबद्ध करने की जिम्मेदारी रखते हैं, जो मॉडल की गुणवत्ता और प्रणाली के प्रभावी संचालन के लिए महत्वपूर्ण हैं।
अधिक विस्तृत उपयोगकर्ता प्रोफाइल के आधार पर, ग्रेडिएंट्स के वास्तविक उपयोगकर्ता समूह में स्पष्ट "अर्ध-डेवलपर-केंद्रित" विशेषता दिखाई देती है: यह शीर्ष AI प्रयोगशालाओं से अलग है और पूरी तरह से तकनीकी रूप से अनभिज्ञ सामान्य उपयोगकर्ताओं से भी भिन्न है; इसके बजाय, यह कुछ इंजीनियरिंग क्षमता वाले डेवलपर्स और Web3 तकनीकी उपयोगकर्ताओं पर केंद्रित है। यह बात उसकी समुदाय संरचना में भी प्रतिबिंबित होती है, जहां वर्तमान पारिस्थितिकी अंग्रेजी में प्रमुख है, मुख्य उपयोगकर्ता उत्तरी अमेरिका और यूरोप के डेवलपर समुदाय में स्थित हैं, साथ ही कुछ दक्षिण-पूर्वी एशियाई माइनर्स और वैश्विक GPU संसाधन प्रदाताओं को भी कवर करती है। समग्र रूप से, यह एक तकनीक-संचालित डेवलपर समुदाय के समान है।
5.2 इकोसिस्टम की वर्तमान चल रही स्थिति
5 मई को, ग्रेडिएंट्स के एल्फा टोकन की कीमत लगभग 0.0255 TAO थी, जिसमें लगभग 4,890 पते थे, 243 माइनर और 12 प्रमाणीकर्ता थे, और उत्पादन का अनुपात 1.61% था। इसके साथ ही, इसके लिक्विडिटी पूल में TAO का अनुपात 2.19% और Alpha का अनुपात 97.81% था। कीमत और होल्डर संख्या के आधार पर, ग्रेडिएंट्स के पास कुछ उपयोगकर्ता आधार और ध्यान है, लेकिन समग्र रूप से यह अभी प्रारंभिक प्रसार चरण में है। TAO पारिस्थिति के शीर्ष प्रोजेक्ट Chutes की तुलना में, उसी दिन एल्फा टोकन की कीमत 0.0877 TAO थी और होल्डर पते 13,409 थे।
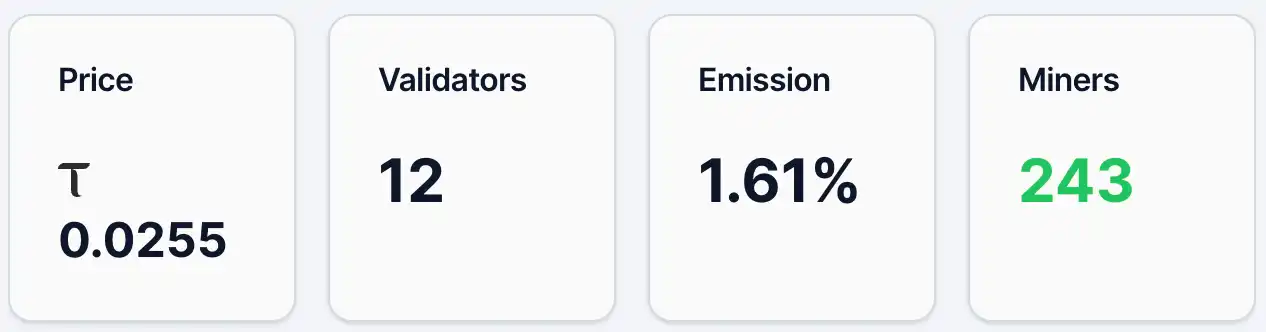
चित्र 1. ग्रेडिएंट्स डेटा।
स्रोत:https://bittensormarketcap.com/subnets/56
दूसरा, इमिशन प्रोत्साहन तंत्र है। बिटटेंसर प्रणाली में, इमिशन का अर्थ है कि उस सबनेट को पूरे नेटवर्क में नए पुरस्कारों में वास्तविक आवंटन भार। बिटटेंसर नेटवर्क लगातार नए TAO उत्पन्न करता है और इन्हें भार के आधार पर विभिन्न सबनेट्स को आवंटित करता है, और ग्रेडिएंट्स का वर्तमान 1.61% का अनुपात इस बात को दर्शाता है कि यह पूरे नेटवर्क के नए प्रोत्साहन में से केवल एक छोटा हिस्सा प्राप्त करता है। यह सूचक मूलतः बाजार द्वारा विभिन्न सबनेट्स के प्रति "मतदान" को दर्शाता है, जिसमें स्टेकिंग जैसी धन प्रवाह शामिल है। इसलिए, 1.61% का स्तर आमतौर पर इस बात को दर्शाता है कि वर्तमान में बाजार स्वीकृति और धन प्रवाह सीमित है, जबकि दूसरी ओर, यह भी संकेत देता है कि भविष्य में इसके भार में वृद्धि का संभावित स्थान है। धन संरचना (लिक्विडिटी पूल) के संदर्भ में, TAO का हिस्सा केवल 2.19% है, जबकि Alpha 97.81% है, जिससे पता चलता है कि बाहरी धन प्रवाह अभी भी सीमित है, और वर्तमान में प्रमुखतः सबनेट के आंतरिक आपूर्ति पर ही निर्भर है। कीमतें नए धन प्रवाह के प्रति संवेदनशील हैं, और यदि TAO का अधिक प्रवाह होता है, तो यह एक स्पष्ट प्रभाव को प्रभावित कर सकता है।
6. प्रतिस्पर्धा का परिदृश्य और शक्तियाँ तथा कमजोरियाँ
6.1 उद्योग स्थिति: डिसेंट्रलाइज्ड AutoML ट्रेनिंग इंफ्रास्ट्रक्चर
Gradients, एक "AI ट्रेनिंग इंफ्रास्ट्रक्चर + डिसेंट्रलाइज्ड AutoML" सब-सेगमेंट में काम करता है। यह मॉडल ट्रेनिंग को सेंट्रलाइज्ड प्लेटफॉर्म से आज़ाद करने का प्रयास करता है और नेटवर्क्ड मैकेनिज़म के माध्यम से अधिक कुशल संसाधन उपयोग और मॉडल अनुकूलन प्राप्त करता है। Web2 प्रणाली में, इस सब-सेगमेंट पहले से ही अपेक्षाकृत परिपक्व है, जिसके प्रमुख प्रतिनिधि Google Vertex AI और AWS SageMaker हैं। ये प्लेटफॉर्म क्लाउड कंप्यूटिंग के माध्यम से डेवलपर्स को एक-स्टॉप मॉडल ट्रेनिंग और डिप्लॉयमेंट सेवाएं प्रदान करते हैं, लेकिन उनकी मूलभूत प्रकृति सेंट्रलाइज्ड आर्किटेक्चर ही है। इसके विपरीत, Gradients का अंतर "अधिक कार्यों" में नहीं, बल्कि नींव के तर्क में है: यह ट्रेनिंग को "प्लेटफॉर्म सेवा" से "नेटवर्क सहयोग" में बदल देता है और प्रतिस्पर्धी मैकेनिज़म के माध्यम से सर्वोत्तम परिणामों का चयन करता है, जिससे यह एक बाज़ार-आधारित ट्रेनिंग सिस्टम के करीब पहुँचता है।
6.2 क्रॉस-कम्पेरिसन: Web2 और Web3 AutoML के बीच अंतर
एक अधिक व्यापक दृष्टिकोण से, Web2 और Web3 के बीच AutoML की दिशा में अंतर, दो अलग-अलग परिप्रेक्ष्यों की तुलना है। Web2 मॉडल कुशलता और स्थिरता पर जोर देता है, केंद्रीकृत संसाधनों और इंजीनियरिंग अनुकूलन के माध्यम से नियंत्रित और परिपक्व सेवा अनुभव प्रदान करता है; जबकि Web3 मॉडल खुलापन और प्रोत्साहन तंत्र पर अधिक ध्यान केंद्रित करता है, जिसमें बहुपक्षीय सहभागिता को शामिल करके मॉडल अनुकूलन को प्रतिस्पर्धा में लगातार विकसित किया जाता है। विशिष्ट रूप से, Web2 AutoML एक “शक्तिशाली उपकरण” की तरह है, जहाँ उपयोगकर्ता कार्य को प्लेटफ़ॉर्म को सौपता है, और प्रणाली आंतरिक रूप से सर्वोत्तम समाधान की खोज करती है; जबकि Gradients जैसे Web3 AutoML, “एक खुला बाज़ार” की तरह है, जहाँ उपयोगकर्ता आवश्यकताएँ प्रकाशित करते हैं, और विभिन्न प्रतिभागी समाधान प्रदान करते हैं, जिन्हें मूल्यांकन प्रक्रिया के माध्यम से छाँटा जाता है। इस अंतर का सीधा प्रभाव यह है: पहला स्थिर और नियंत्रित है, लेकिन अनुकूलन मार्ग सीमित है; दूसरा संभावित स्थान में अधिक खोज करने की क्षमता रखता है, संभावित सीमा अधिक है, लेकिन स्थिरता और परिपक्वता में सुधार की आवश्यकता है।
6.3 Web3 में Gradients का अंतर
वर्तमान Web3 AI क्षेत्र में, अधिकांश प्रोजेक्ट्स अभी भी इन्फरेंस लेयर या AI Agent दिशा पर केंद्रित हैं, जबकि “ट्रेनिंग इंफ्रास्ट्रक्चर” पर ध्यान केंद्रित करने वाले प्रोजेक्ट्स तुलनात्मक रूप से कम हैं। कुछ प्रोजेक्ट्स कैलकुलेशन नेटवर्क या डेटा नेटवर्क को जोड़कर ट्रेनिंग क्षमता प्रदान करने का प्रयास कर रहे हैं, लेकिन समग्र रूप से, अधिकांश अभी भी संसाधन स्केड्यूलिंग या कैलकुलेशन मार्केट स्तर पर ही सीमित हैं। Gradients का अंतर यह है कि यह केवल कैलकुलेशन मैचमेकिंग प्रदान ही नहीं करता, बल्कि “मॉडल ऑप्टिमाइज़ेशन मैकेनिज़म” तक आगे बढ़ता है, जहाँ मूल्यांकन और प्रतिस्पर्धा प्रणाली को शामिल करके ट्रेनिंग प्रक्रिया को सतत विकास की क्षमता प्रदान की जाती है। इसका मतलब है कि यह केवल “कैलकुलेशन कहाँ से आएगा” का समाधान ही नहीं करता, बल्कि “इन कैलकुलेशन का उपयोग कैसे अधिक कुशलता से किया जाए” का भी समाधान करता है। स्थिति के दृष्टिकोण से, Gradients एक “ट्रेनिंग परिणाम-उन्मुख” नेटवर्क के समीप है, जो कि केवल कैलकुलेशन मार्केट या टूल प्लेटफॉर्म नहीं है, और यही इसका Web3 AI प्रोजेक्ट्स के साथ मूलभूत अंतर है।
6.4 मुख्य लाभ: तंत्र-संचालित दक्षता में वृद्धि
समग्र रूप से, Gradients के लाभ मुख्य रूप से उसके मैकेनिज्म डिजाइन में दिखाई देते हैं। सबसे पहले, यह कार्य अमूर्तीकरण के माध्यम से उपयोग करने की बाधा को कम करता है, जिससे उपयोगकर्ता जटिल प्रशिक्षण प्रक्रिया में गहराई से शामिल न होकर भी मॉडल परिणाम प्राप्त कर सकते हैं, जिससे संभावित उपयोगकर्ता समूह बढ़ता है। दूसरे, संसाधन स्तर पर, वितरित कंप्यूटिंग के परिचय से प्रशिक्षण अब एकल क्लाउड प्रदाता पर निर्भर नहीं है, और सिद्धांत रूप से प्रतिस्पर्धा के माध्यम से अधिक लचीली लागत संरचना विकसित की जा सकती है। इससे भी महत्वपूर्ण बात यह है कि इसकी अनुकूलन पद्धति में परिवर्तन हुआ है। बहु-भागीदार समानांतर अन्वेषण और छंटनी मैकेनिज्म के संयोजन के माध्यम से, Gradients एक पारंपरिक एकल-पथ अनुकूलन से भिन्न समाधान प्रदान करता है, जिससे मॉडल को कम समय में बेहतर प्रदर्शन प्राप्त करने का मौका मिलता है। यह “प्रतिस्पर्धा-संचालित अनुकूलन” मॉडल, इसका सबसे मूलभूत लाभ है।
6.5 संभावित चुनौतियाँ
मॉडल की गुणवत्ता में स्थिरता की समस्या हो सकती है। डिसेंट्रलाइज्ड ट्रेनिंग के लिए बहुपक्षीय भागीदारी की आवश्यकता होती है, जो सीमा को बढ़ा सकती है, लेकिन परिणामों में उतार-चढ़ाव भी ला सकती है, जिससे केंद्रीकृत प्रणाली की तुलना में नियंत्रण में कुछ अनिश्चितता आती है। दूसरा, उद्योग-स्तरीय विश्वास की समस्या है। उद्योग उपयोगकर्ताओं के लिए, डेटा सुरक्षा और ट्रेनिंग प्रक्रिया की जांचयोग्यता महत्वपूर्ण है, और डिसेंट्रलाइज्ड परिवेश में डेटा के दुरुपयोग से बचाव और परिणामों की ऑडिट की सुनिश्चितता एक महत्वपूर्ण चुनौती है। अंत में, टोकन अर्थव्यवस्था पर निर्भरता है। Gradients की संचालन प्रणाली प्रेरणा तंत्र पर अत्यधिक निर्भर है; यदि TAO के लाभ का आकर्षण कम हो जाता है, तो माइनरों की सहभागिता और समग्र नेटवर्क सक्रियता प्रभावित हो सकती है। इसलिए, इसकी दीर्घकालिक स्थायित्व कुछ हद तक इस बात पर निर्भर करती है कि आर्थिक मॉडल स्थिर सकारात्मक चक्र का निर्माण कर पाता है या नहीं।
7. भविष्य की दृष्टि: डिसेंट्रलाइज्ड AutoML संभव हो सकता है?
वर्तमान चरण से, ग्रेडिएंट्स अभी शुरुआती चरण में हैं, और उनका भविष्य सफल हो पाएगा या नहीं, कुछ महत्वपूर्ण बिंदुओं पर निर्भर करता है। सबसे मूलभूत बात यह है कि क्या वे बस प्रोत्साहन के चक्र में शामिल होने के बजाय वास्तविक प्रशिक्षण की मांग को लगातार आकर्षित कर पाएंगे; दूसरी बात मॉडल की गुणवत्ता है, कि क्या डिसेंट्रलाइज्ड तरीका स्थिर रूप से उपयोगयोग्य, यहां तक कि बेहतर परिणाम प्रदान कर सकता है; और तीसरी बात आर्थिक मैकेनिज़म है कि क्या यह एक सकारात्मक चक्र बना सकता है, जिससे कैलकुलेशन प्रदान और आय के बीच दीर्घकालिक संतुलन बना रहे।
बड़े उद्योग के संदर्भ में, AI प्रशिक्षण दो मार्गों में विभाजित हो रहा है। एक Web2 मॉडल है, जिसे शीर्ष प्रौद्योगिकी कंपनियाँ नेतृत्व करती हैं और केंद्रीकृत संसाधनों और इंजीनियरिंग क्षमताओं के माध्यम से मॉडल की प्रदर्शन क्षमता को लगातार मजबूत करती हैं, इसका लाभ स्थिरता और परिपक्वता में है; दूसरा Gradients जैसी Web3 पथ है, जो खुले नेटवर्क और प्रोत्साहन तंत्र के माध्यम से अधिक प्रतिभागियों को मॉडल अनुकूलन में सामिल होने के लिए प्रेरित करता है, और प्रतिस्पर्धा में अपनी सीमा को लगातार बढ़ाता है। पहला "अधिक शक्तिशाली प्रणाली बनाना" है, जबकि दूसरा "एक स्वयं-विकसित होने वाले नेटवर्क का निर्माण" जैसा है।
इस दृष्टिकोण से, Gradients की खोज एक नई संभावना को दर्शाती है: AI प्रशिक्षण अब केवल एक तकनीकी समस्या नहीं है, बल्कि “कैलकुलेशन पावर + डेटा + बाजार तंत्र” का संयोजन है। यदि यह मॉडल सफल होता है, तो यह डिसेंट्रलाइज्ड AI के प्रशिक्षण का एक प्रवेश द्वार बन सकता है और Bittensor पारिस्थितिकी में महत्वपूर्ण बुनियादी ढांचे की भूमिका निभा सकता है। निश्चित रूप से, इस दिशा की पुष्टि के लिए अभी समय की आवश्यकता है, लेकिन यह AutoML के लिए पारंपरिक मार्ग से अलग एक विकास की दिशा प्रदान करता है।
संदर्भ
1. बिटटेंसर दस्तावेज़: https://docs.learnbittensor.org
2. ग्रेडिएंट्स वेबसाइट:https://www.gradients.io/
3. ग्रेडिएंट्स:https://bittensormarketcap.com/subnets/56
4. ग्रेडिएंट्स X: https://x.com/gradients_ai
5. टॉसटैट्स:https://taostats.io/subnets/56/chart