









डीपसीक के इस मूल्य समायोजन ने एक अरैखिक, भारी गिरावट के माध्यम से उद्योग को एक नए लागत युग में जबरदस्ती खींच लिया है।
लेखक, स्रोत: 0x9999in1, ME News
TL;DR
- कीमत निम्न सीमा को तोड़ दी गई: 2026 के अप्रैल के अंत तक, DeepSeek ने सीमित समय की छूट और कैशिंग की कीमत में कमी को जोड़कर अपने V4-Pro मॉडल की आउटपुट कीमत घटाकर 0.878 डॉलर प्रति मिलियन टोकन कर दी, जिससे कैशिंग हिट इनपुट 0.0037 डॉलर (लगभग 0.025 युआन) तक पहुँच गया, जिसने बड़े मॉडल उद्योग के मूल्य निर्धारण के संदर्भ को पूरी तरह से तोड़ दिया।
- चीन और संयुक्त राज्य अमेरिका की कीमत व्यवस्था में “अंतर” है: वैश्विक शीर्ष निर्माताओं की तुलना में, DeepSeek-V4-Pro की API कॉल की समग्र लागत केवल OpenAI GPT-5.5 और Anthropic Claude Opus 4.7 की लगभग तीसवीं हिस्सा है, जिससे अत्यंत स्पष्ट लागत लाभ का कटौती अंतर बनता है।
- घरेलू प्रतिस्पर्धा के दबाव में: डीपसीक के आक्रामक मूल्य निर्धारण के तहत, घरेलू लीडिंग मॉडल्स जैसे ज़हीपु जीएलएम 5.1 और युए किमी K2.6 को व्यावसायिक दबाव का सामना करना पड़ रहा है, जिससे उन्हें मूल्य घटाने के लिए मजबूर होना पड़ सकता है, और उद्योग की साफ़ होने की गति तेज़ हो जाएगी।
- "कैश हिट" को केंद्रीय अर्थव्यवस्था बनाया गया: डीपसीक ने कैश हिट मूल्य को मूल कीमत के 1/10 तक घटा दिया है, जिससे लंबे पाठ संसाधन, RAG (रिट्रीवल-एन्हांस्ड जनरेशन) और एजेंट के लगातार बहु-चरण अंतरक्रिया परिदृश्यों को नींव से बड़ा लाभ मिलता है।
- थिंक टैंक का निष्कर्ष: बेसिक लार्ज मॉडल्स “बुनियादी ढांचे” के रूप में तेजी से विकसित हो रहे हैं, और भविष्य की प्रतिस्पर्धा अब केवल मॉडल पैरामीटर साइज के लिए नहीं, बल्कि इन्फरेंस लागत अनुकूलन क्षमता और डेवलपर इकोसिस्टम के बाजार हिस्से के लिए होगी।
प्रस्तावना: बड़े मॉडल की कैलकुलेशन लागत का "विशेष बिंदु" क्षण
तकनीकी विकास अक्सर लागत के घातांकीय गिरावट के साथ आता है, जो किसी भी विप्लवकारी तकनीक के समग्र ग्रहण की ओर जाने का अनिवार्य मार्ग है। 25-26 अप्रैल, 2026 को, AI उद्योग एक अत्यंत महत्वपूर्ण क्षण को देखने को मिला: शीर्ष बड़े मॉडल निर्माता DeepSeek ने लगातार दो “गहरे पानी के बम” फेंके। पहले DeepSeek-V4-Pro मॉडल API के लिए 2.5 फीसदी की सीमित समय के लिए तेज़ छूट की घोषणा की; तुरंत बाद, सभी API सेवाओं में, इनपुट कैश हिट की कीमत सीधे मूल कीमत के 1/10 तक घटा दी गई।
इन दो चरणों के ओवरलैपिंग मूल्य समायोजन रणनीति के बाद, 5 मई, 2026 तक, DeepSeek-V4-Flash के लिए प्रति एक मिलियन टोकन इनपुट कैश हिट मूल्य अद्भुत 0.0029 डॉलर (लगभग 0.02 युआन) तक गिर चुका है, जबकि वैश्विक शीर्ष स्तर के साथ तुलना के लिए DeepSeek-V4-Pro का इनपुट कैश हिट मूल्य केवल 0.0037 डॉलर (लगभग 0.025 युआन) है।
इससे पहले, उद्योग ने अनुमान लगाया था कि बड़े मॉडल की निष्कर्षण लागत प्रति वर्ष लगभग 50% की दर से घटेगी, लेकिन DeepSeek के इस मूल्य समायोजन ने एक अरैखिक, अचानक गिरावट के साथ उद्योग को एक संपूर्ण नए लागत युग में धकेल दिया है। हम मानते हैं कि यह केवल एक साधारण बाजारकरण गतिविधि या अल्पकालिक "मूल्य युद्ध" नहीं है, बल्कि नींव के एल्गोरिदम आर्किटेक्चर में सुधार (जैसे स्पार्स ध्यान तंत्र, अत्यधिक MoE आर्किटेक्चर का विकास) और कैलकुलेशन क्लस्टर इंजीनियरिंग क्षमता में सुधार के कारण अपरिहार्य परिणाम है। यह रिपोर्ट नवीनतम पूरे उद्योग के मूल्य डेटा के आधार पर DeepSeek के मूल्य में कमी से हुए उद्योग के कंपन का गहन विश्लेषण करेगी, और वैश्विक प्रमुख बड़े मॉडल की व्यावसायिक प्रतिस्पर्धात्मकता की तुलना करेगी, ताकि निर्णय लेने वालों के लिए एक स्पष्ट उद्योग-विकास मार्गदर्शिका प्रस्तुत की जा सके।
मुख्य घटना: DeepSeek-V4 श्रृंखला की कीमत व्यवस्था की सीमा का भेदन
इस कीमत कमी के प्रभाव को समझने के लिए, हमें बड़े मॉडल API शुल्क के तीन मुख्य पहलुओं पर गहराई से विचार करना होगा: इनपुट मूल्य (कैश मिस), इनपुट मूल्य (कैश हिट), और आउटपुट मूल्य। पिछले शुल्क मॉडल अक्सर केवल इनपुट और आउटपुट को अलग करते थे, लेकिन लंबे संदर्भ (Long-Context) तकनीक के परिपक्व होने के साथ, "कैश हिट दर (Cache Hit)" API अर्थशास्त्र को पुनर्परिभाषित करने वाला एक महत्वपूर्ण चर बन रहा है।
प्राइसिंग स्ट्रैटेजी एनालिसिस: छूट का ओवरलैप और कैश्ड लीवरेज
नवीनतम प्रकाशित डेटा के अनुसार, डीपसीक ने "बेंचमार्क कीमत कमी + सीमित समय के लिए छूट + कैशिंग लीवरेज" की तिहाई रणनीति अपनाई है।
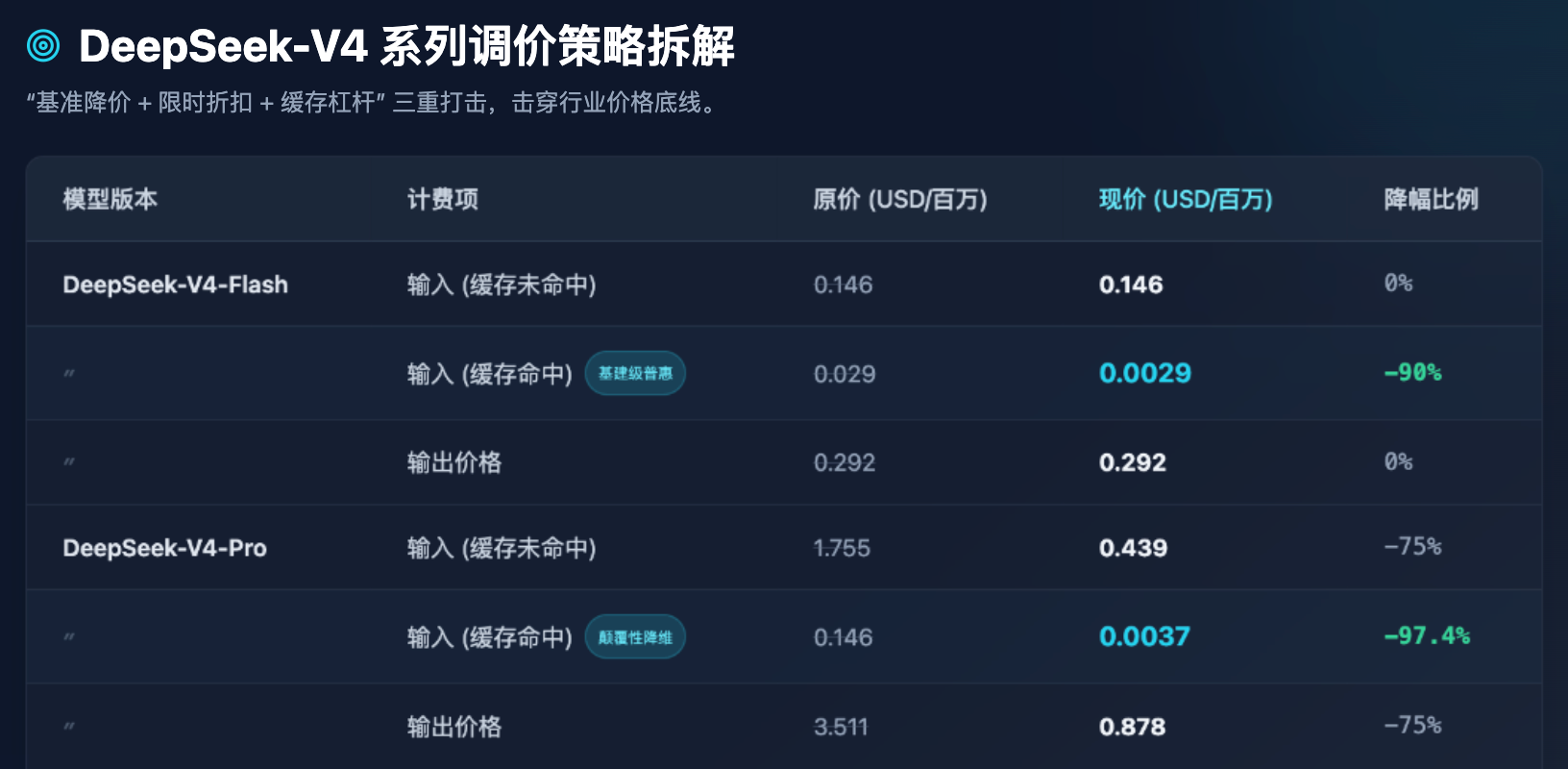
तालिका 1: DeepSeek-V4 श्रृंखला के नवीनतम API मूल्यांकन से पहले और बाद की तुलना (इकाई: डॉलर/मिलियन टोकन)
हम टेबल 1 से कुछ अत्यंत स्पष्ट उद्योग अवलोकन निकाल सकते हैं:
पहला, फ्लैश मॉडल का सार्वभौमिकीकरण सीमा तक पहुंच चुका है। उच्च समानांतरता और निम्न लेटेंसी पर आधारित फ्लैश मॉडल की आउटपुट कीमत 0.292 डॉलर/मिलियन टोकन पर स्थिर है, जो सर्वर की कैलकुलेशन लागत के सीधे लागत के निकटतम सीमा है। डीपसीक ने फ्लैश की मूल कीमत पर कोई अतिरिक्त प्रयास नहीं किया, बल्कि उसने "कैश हिट" कीमत को 90% तक कम कर दिया। इसका अर्थ है कि बड़ी मात्रा में दोहराए जाने वाले सिस्टम प्रॉम्प्ट (System Prompt) या स्थिर दस्तावेज़ प्रश्नोत्तर को संसाधित करते समय, फ्लैश मॉडल की लागत लगभग नगण्य हो जाती है।
दूसरा, Pro मॉडल का डाउनसाइजिंग प्रभाव। V4-Pro, जो वैश्विक शीर्ष स्तर (जैसे GPT-5 स्तर) के लिए एक फ्लैगशिप मॉडल है, उसकी आउटपुट की कीमत 3.511 डॉलर से गिरकर 0.878 डॉलर हो गई है। और अधिक अद्भुत बात यह है कि मूल रूप से 0.146 डॉलर की कैश हिट इनपुट कीमत, सीमित समय के 2.5 फीसदी छूट और 1/10 की कमी के साथ मिलाकर, सीधे 0.0037 डॉलर पर पहुंच गई है। यह एक अत्यंत भयानक संख्या है—इसका मतलब है कि वैश्विक शीर्ष बुद्धि को कॉल करने की लागत को इतना कम कर दिया गया है कि छोटे और मध्यम आकार के उद्यमों और व्यक्तिगत डेवलपर्स भी बिना किसी संकोच के उच्च आवृत्ति पर कॉल कर सकते हैं।
तीसरा, डेवलपर्स को प्रॉम्प्ट इंजीनियरिंग को बेहतर बनाने के लिए विवश करें। कैश मिलने वाली कीमत को कैश न मिलने वाली कीमत का कुछ दशमलव हिस्सा (उदाहरण के लिए, प्रो मॉडल में, 0.0037 डॉलर बनाम 0.439 डॉलर, लगभग 118 गुना का अंतर) रखें, जो केवल मूल्य निर्धारण रणनीति ही नहीं, बल्कि व्यावसायिक तरीके से प्रौद्योगिकी पारिस्थितिकी को दिशा देना है। DeepSeek स्पष्ट रूप से डेवलपर्स को बता रहा है: अगर आपकी आर्किटेक्चर डिज़ाइन सही है (उदाहरण के लिए, स्थिर लंबा कंटेक्स्ट पहले, और परिवर्तनशील छोटे प्रश्न बाद में), तो आप लगभग मुफ्त इनपुट कंप्यूटिंग पाएंगे।
Horizontal comparison: The "gap" contrast in pricing between global and local large models
केवल डीपसीक के अपने मूल्यह्रास की ऊर्ध्वाधर तुलना करके पूरी छवि समझना अपर्याप्त है; जब हम इसे 2026 के वैश्विक बड़े मॉडल बाजार के संदर्भ में रखते हैं, तो इस मूल्य नीति द्वारा उत्पन्न “अंतर” की तीव्रता वास्तव में रीढ़ की हड्डी में सिहरन पैदा कर देती है।
OpenRouter और विभिन्न सार्वजनिक जानकारियों के आधार पर, हमने वर्तमान बाजार में सबसे प्रतिनिधित्वपूर्ण 9 विदेशी और घरेलू बड़े मॉडल के नवीनतम API मूल्य निर्धारण डेटा को संकलित किया है।

सारणी 2: 2026 के लिए वैश्विक प्रमुख भाषा मॉडल API मूल्य निर्धारण की तुलना (इकाई: डॉलर/मिलियन टोकन)
ग्लोबल जायंट्स के खिलाफ: "हाई आईक्यू, हाई प्रीमियम" के मिथक को तोड़ें
पिछले दो वर्षों के AI नैरेटिव में, OpenAI और Anthropic ने एक समझौता बनाए रखा है: सबसे बुद्धिमान मॉडल को सबसे अधिक ग्रॉस मार्जिन मिलना चाहिए। वर्तमान में, GPT-5.5 और Claude Opus 4.7 की आउटपुट कीमत क्रमशः 30 डॉलर और 25 डॉलर/मिलियन टोकन है। ये दोनों सिलिकॉन वैली के विशालकाय अपनी उच्चतम निष्कर्षण क्षमता पर एकाधिकार बनाए रखकर अपनी महंगी कैलकुलेशन टैक्स को बनाए रखने का प्रयास कर रहे हैं।
हालांकि, DeepSeek-V4-Pro के आगमन और उसकी 0.878 डॉलर की आउटपुट कीमत ने सीधे इस कागज को फाड़ दिया। यदि V4-Pro सभी मुख्य बेंचमार्क और वास्तविक अनुभव में GPT-5.5 के स्तर तक पहुंच या उसके करीब पहुंच सकता है, तो इन दोनों के बीच 34 गुना का आउटपुट मूल्य अंतर, विदेशी विशालकायों के B2B बाजार में प्रीमियम तर्क को पूरी तरह से नष्ट कर देगा।
«ME News ज्ञान भंडार» के अनुसार, एक ऐसे विदेशी बाजार पर निर्भर कंपनी के लिए जो AI द्वारा उत्पादित सामग्री पर भारी रूप से निर्भर है, यदि मासिक 10 अरब टोकन आउटपुट का उपयोग होता है, तो GPT-5.5 की कठोर लागत 30,000 डॉलर होगी; जबकि DeepSeek-V4-Pro पर स्विच करने पर यह लागत केवल 878 डॉलर तक घट जाएगी। इस स्तर की लागत का अंतर, एक स्टार्टअप के अस्तित्व को प्रभावित करने के लिए पर्याप्त है। यह दर्शाता है कि चीनी AI कंपनियाँ निम्न स्तरीय मॉडल प्रशिक्षण की दक्षता और निष्कर्षण क्लस्टर अनुकूलन पर, सिलिकॉन वैली से पूरी तरह अलग “बलवान सौंदर्य और अत्यधिक इंजीनियरिंग” के समानांतर मार्ग पर आगे बढ़ रही हैं।
देशी प्रतिद्वंद्वियों का घेराबंदी: उद्योग के बड़े शुद्धीकरण को तेज करें
अगर डीपसीक विदेशी विशालकों के लिए डाइमेंशनल डिस्क्रिमिनेशन है, तो घरेलू प्रतियोगियों के लिए यह एक क्रूर शून्य-योग खेल है।
सारणी 2 से स्पष्ट है कि चीनी शीर्ष निर्माताओं जैसे ज़ही (GLM 5.1, आउटपुट 4.4 डॉलर) और मून ऑफ डार्कनेस (Kimi K2.6, आउटपुट 4 डॉलर) बाजार में एक अजीब स्थिति में हैं। कुछ महीने पहले ये कीमतें "उचित और मूल्य-से-मूल्य" मानी जाती थीं, लेकिन DeepSeek-V4-Pro (आउटपुट 0.878 डॉलर) के सामने, ये सभी कीमत सीमाएँ तुरंत नष्ट हो गईं। यहाँ तक कि हमेशा से ओपन-सोर्स और कम कीमत के लिए जाने जाने वाले अलीबाबा क्लाउड (Qwen3.6 Plus, आउटपुट 1.96 डॉलर) भी "सस्ते" नहीं लगते।
और हल्के Flash मॉडल के क्षेत्र में, लड़ाई भी तीव्र है। Step 3.5 Flash का इनपुट केवल 0.028 डॉलर है और आउटपुट केवल 0.299 डॉलर है, जो DeepSeek-V4-Flash (आउटपुट 0.292 डॉलर) के साथ बहुत करीब है। इससे पता चलता है कि हल्के मॉडल क्षेत्र में, कैलकुलेशन लागत को नैनो स्तर तक कम कर दिया गया है, और सभी कंपनियाँ लागत रेखा के साथ उड़ रही हैं।
समग्र रूप से, डीपसीक वास्तव में प्रो स्तर की क्षमताओं का उपयोग करके घरेलू प्रतिद्वंद्वियों के प्लस या मानक संस्करण की कीमतों को टारगेट कर रहा है; और फ्लैश स्तर की कीमतों का उपयोग करके सभी विशाल, कम मूल्य घनत्व वाले लॉन्ग टेल ट्रैफ़िक को संभाल रहा है। इस “दोनों छोर पर क्लैम्पिंग” रणनीति ने अन्य बड़े मॉडल कंपनियों के जीवन को भारी रूप से संकुचित कर दिया है, और घरेलू AI बड़े मॉडल की निकासी प्रक्रिया इस मूल्य ह्रास के बाद तेज़ हो जाएगी।
गहरा विश्लेषण: अत्यधिक कम कीमत के पीछे की तकनीकी और व्यावसायिक तर्कशक्ति
बुनियादी बातों से दूर निम्न कीमतें टिकाऊ नहीं हैं। डीपसीक ने 2026 में इतनी निर्णायक कीमत कमी की रणनीति अपनाने का साहस क्यों किया, इसके पीछे गहरी तकनीकी समर्थन और अत्यधिक लालची व्यावसायिक योजना है।
तकनीकी तर्क: "शक्तिशाली ईंट उड़ाने" से "संरचना द्वारा विजय" तक
मूल्य में अचानक गिरावट, मूल रूप से तकनीकी ढांचे के विकास के लाभ का विमोचन है।
- MoE (मिक्स्ड एक्सपर्ट) आर्किटेक्चर का गहरा लाभ: OpenAI के प्रारंभिक विशाल सघन मॉडलों से अलग, वर्तमान उन्नत मॉडल सामान्यतः अत्यधिक अनुकूलित MoE आर्किटेक्चर का उपयोग करते हैं। DeepSeek बहुत संभावना है कि V4 आर्किटेक्चर में सक्रिय पैरामीटर के अनुपात को और कम कर देगा। इसका अर्थ है कि भले ही कुल पैरामीटर मात्रा विशाल हो, लेकिन प्रत्येक निष्पादन पर केवल अत्यल्प “एक्सपर्ट” ही सक्रिय होते हैं, जिससे प्रत्येक कॉल की गणना मात्रा (FLOPs) और VRAM बैंडविड्थ का दबाव भारी रूप से कम हो जाता है।
- KV कैश प्रबंधन में क्रांतिकारी क्रांति: इस मूल्य समायोजन का सबसे बड़ा बिंदु "इनपुट कैश हिट 1/10 तक कम हो गया" है। ट्रांसफॉर्मर आर्किटेक्चर में, लंबे टेक्स्ट निष्पादन का सबसे बड़ा बाधक गणना नहीं, बल्कि KV कैश द्वारा लिया गया अधिक मेमोरी है। DeepSeek स्पष्ट रूप से सिस्टम स्तर पर क्रॉस-रिक्वेस्ट, ग्लोबल शेयर्ड KV कैश पूलिंग तकनीक (जैसे RadixAttention तकनीक का अपग्रेड संस्करण) को लागू करता है। जब असंख्य उपयोगकर्ताओं के समानांतर अनुरोधों में समान सिस्टम सेटिंग्स या बैकग्राउंड ज्ञान भंडार होते हैं, तो मॉडल को इन टोकन की पुनः गणना की आवश्यकता नहीं होती, बल्कि यह सीधे मेमोरी या वितरित GPU मेमोरी पूल से पढ़ता है। इससे "लंबे टेक्स्ट इनपुट" की सीमांत लागत शून्य के करीब पहुँच जाती है।
व्यावसायिक तर्क: लाभ के बदले स्थान प्राप्त करें, पारिस्थितिकी तंत्र की रक्षा को पुनर्परिभाषित करें
「ME News ज्ञानकोश」 का मानना है कि डीपसीक की सीमित समय के लिए छूट और न्यूनतम कीमत रणनीति का व्यावसायिक उद्देश्य स्पष्ट और दृढ़ है:
सबसे पहले, "कवर फाइन-ट्यूनिंग" इकोसिस्टम को पूरी तरह से नष्ट कर दें, ताकि AI-नेटिव एप्लिकेशन का विस्फोट हो। जब सबसे शक्तिशाली बेस मॉडल के कॉल की लागत अनंत रूप से मुफ्त के करीब पहुँच जाए, तो उद्यमी अपने उद्योग-विशिष्ट छोटे मॉडल को प्रशिक्षित या फाइन-ट्यून करने के लिए विशाल राशि खर्च करना आर्थिक रूप से अर्थहीन हो जाएगा। DeepSeek, निम्न कीमतों के माध्यम से, समाज के सभी AI डेवलपर्स को अपने API इकोसिस्टम में शामिल करने का प्रयास कर रहा है, ताकि यह अमेज़ॉन AWS, माइक्रोसॉफ्ट Azure की तरह "AI काल की बुनियादी बिजली, पानी और कोयला" बन सके।
दूसरा, एजेंट (इंटेलिजेंट एजेंट) के विस्फोट की सुबह। वास्तविक एजेंटिक अनुप्रयोगों के लिए मॉडल को बड़ी मात्रा में स्वयं के बारे में सोचने, प्रतिबिंबित करने, योजना बनाने और बहु-चक्रीय कॉल (Loop) करने की आवश्यकता होती है। इस प्रक्रिया में, अत्यधिक अदृश्य टोकन खपत होती है। महंगे API एजेंट के प्रसार की सबसे बड़ी बाधा हैं। DeepSeek ने कैश हिट मूल्य को 0.0037 डॉलर तक घटाकर, “AI को एक लाख चक्कर लगाने” के लिए आर्थिक संभावना प्रदान की है। जो सबसे सस्ती प्रयोग लागत प्रदान करता है, वही सबसे महान AI-निर्मित सुपर अनुप्रयोग का जन्म देगा।
उद्योग प्रभाव और रुझान विश्लेषण: "मॉडल युद्ध" से "पारिस्थितिकी युद्ध" तक
इस मूल्य परिवर्तन के प्रभाव को उद्यम स्तरीय निर्णयों पर अधिक स्पष्ट रूप से दर्शाने के लिए, हमने एक उद्यम स्तरीय एप्लिकेशन की लागत प्रतिकृति प्रक्रिया की है।
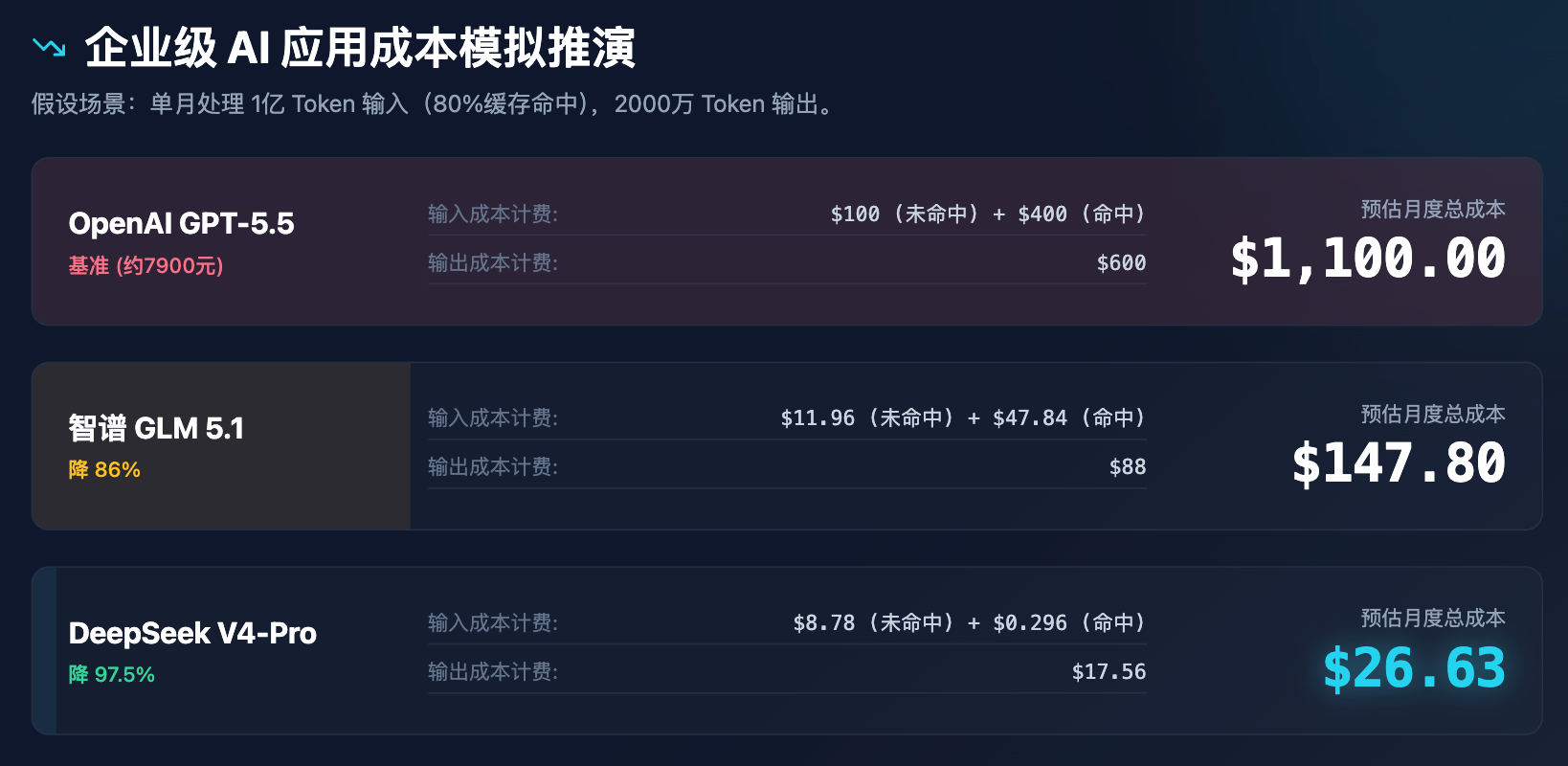
तालिका 3: उद्यम स्तरीय AI अनुप्रयोग लागत प्रतिकृति विश्लेषण (मान लीजिए एक महीने में 1 अरब इनपुट टोकन, 20 मिलियन आउटपुट टोकन प्रसंस्कृत)
उपरोक्त प्रतिरूपण से स्पष्ट है कि डीपसीक की कीमत बस छूट नहीं है, बल्कि लागत मॉडल को पुनर्गठित कर रही है। प्रति महीने 30 डॉलर से कम की लागत से एक मध्यम आकार के व्यवसाय की सभी कस्टमर सपोर्ट असिस्टेंस, दस्तावेज़ विश्लेषण और कोड चेकिंग की आवश्यकताओं को पूरा किया जा सकता है, जिससे एक श्रृंखला प्रतिक्रियाएँ शुरू होंगी:
- AI निवेश तर्क का मूलभूत रूपांतरण: पूंजी “एक सामान्य बड़ा मॉडल फिर से बनाने” के प्रति दृढ़ता से बंद हो जाएगी। अत्यल्प संख्या में राष्ट्रीय टीमों या इंटरनेट महानगरपालिकाओं के अलावा, सामान्य आधारभूत बड़े मॉडल का द्वार बंद हो चुका है। भविष्य का निवेश सम्पूर्ण रूप से अनुप्रयोग स्तर (Application Layer) और बुनियादी ढांचे के मध्यवर्ती सॉफ़्टवेयर (बुनियादी ढांचे के रूटर, AI गेटवे आदि) की ओर बहेगा।
- मल्टी-मॉडल रूटिंग स्ट्रैटेजी (LLM रूटिंग) सामान्य हो गई है: उद्यम अब एकल मॉडल पर अटके नहीं रहेंगे। प्रणाली स्वचालित रूप से कार्य की जटिलता के आधार पर वितरण करेगी। उदाहरण के लिए, 90% दैनिक डेटा क्लीनिंग और सरल वर्गीकरण को DeepSeek-V4-Flash या Step 3.5 Flash के माध्यम से अत्यंत कम लागत पर पूरा किया जाएगा; 10% जटिल तर論की, उच्च प्रबंधन रिपोर्ट जनरेशन के लिए DeepSeek-V4-Pro को या GPT-5.5 को आवश्यकता के अनुसार सक्रिय किया जाएगा।
- लंबे पाठ एप्लिकेशन को वास्तविक व्यावसायिक मोड़ का सामना करना पड़ रहा है: इससे पहले, "मिलियन शब्दों की वार्षिक रिपोर्ट अपलोड करें और AI द्वारा सारांशित करें" अच्छा लगता था, लेकिन प्रत्येक बार कई डॉलर की API लागत के कारण B2B उद्यम इससे दूर रहे। इनपुट कैश हिट मूल्य 0.02 युआन/मिलियन टोकन के स्तर तक घटने के साथ, "पूरी डॉक्यूमेंटेशन लाइब्रेरी पढ़ें और रियल-टाइम इंटरैक्ट करें" सभी उद्यमों के OA सॉफ़्टवेयर और ERP सिस्टम की मानक सुविधा बन जाएगी।
निष्कर्ष और रणनीतिक सुझाव
2026 के अप्रैल में यह कीमत कमी का तूफान, बड़े मॉडल उद्योग को "पैरामीटर और स्कोर की प्रतियोगिता" के क्लासिक रोमांटिक युग से अलग करता है और "लागत, कैलकुलेशन शक्ति और पारिस्थितिकी पर नियंत्रण" के कठोर औद्योगिक युग में प्रवेश कराता है। डीपसीक ने अत्यधिक दबाव वाली मूल्य नीति के माध्यम से न केवल वैश्विक स्तर पर चीनी AI कंपनियों की मॉडल इंजीनियरिंग में गहरी निपुणता को प्रदर्शित किया है, बल्कि AI कैलकुलेशन शक्ति के अतिरिक्त मूल्य के बुलबुले को सक्रिय रूप से फोड़ा है।
इसके लिए, "ME News थिंक टैंक" के तीन सुझाव हैं:
- एप्लिकेशन लेयर डेवलपर्स के लिए: बड़े मॉडल कॉल की लागत के प्रति डर को भूल जाएँ। अभी से अरब पैरामीटर से कम के बेस मॉडल को स्वयं बनाने और फाइन-ट्यून करना बंद कर दें, और सभी रिसर्च और डेवलपमेंट संसाधनों को उत्पाद अनुभव, एंड-पॉइंट अनुकूलन, निजी डेटा बैरियर्स के निर्माण और एजेंट वर्कफ्लो के परिष्करण में लगा दें। इस “सस्ती, उच्च-बुद्धिमत्ता वाली कैलकुलेशन पावर” के लाभ का उपयोग करके, जल्दी से स्थितियों पर कब्जा करें।
- पारंपरिक उद्यमों के CIO/CTO के लिए: अपनी AI-की रणनीति का पुनर्मूल्यांकन करें। पिछले समय में लागत के आधार पर स्थगित किए गए ज्ञान आधारित प्रश्नोत्तर, स्वचालित ग्राहक सेवा और कोड Copilot प्रोजेक्ट्स वर्तमान API मूल्यों के संदर्भ में अब अत्यधिक उच्च ROI (निवेश लाभ) प्रदान करते हैं। एक परिपक्व LLMOps प्लेटफॉर्म शामिल करने, एक उद्यम-स्तरीय AI गेटवे स्थापित करने और वर्तमान में सबसे अधिक लागत-कुशल मॉडल्स को लचीले ढंग से जोड़ने की सलाह दी जाती है।
- बेस मॉडल के प्रतिद्वंद्वी के लिए: अनुसरण रणनीति को त्यागना अनिवार्य है। कीमत के युद्ध के सामने, या तो अधिक उन्नत चिप-फ्रेमवर्क सह-अनुकूलन के माध्यम से लागत को और कम करें, या शरीरिक बुद्धिमत्ता, बहुमॉडल-मूल (वीडियो/3D जनरेशन), ऊर्ध्वाधर उद्योग की मजबूत तर्कशक्ति जैसे भिन्नता के क्षेत्रों में अपरिहार्य तकनीकी बाधाएँ बनाएँ। केवल भाषा के बड़े मॉडल का सामान्यीकरण, अब कोई रास्ता नहीं है।
बड़े मॉडल अब प्रयोगशाला में पूजे जाने वाले देवता नहीं हैं, वे बिना पहले के तेजी से अपने मंदिर से उतर रहे हैं और सब कुछ को स्मार्ट बनाने वाली एक भारी लहर बन रहे हैं। और यह सब सिर्फ शुरुआत है।
स्रोत का उल्लेख:
- OpenRouter. (2026). API मूल्य तुलना डेटाबेस.
- DeepSeek आधिकारिक घोषणा। (2026, 25 अप्रैल)। DeepSeek-V4-Pro API सीमित समय के लिए छूट योजना.
- DeepSeek आधिकारिक घोषणा। (2026, 26 अप्रैल)। बड़े मॉडल युग में सुलभ कैलकुलेशन: API ग्लोबल कैश हिट मूल्य समायोजन योजना.