










लेखक: KarenZ, Foresight News
20 मार्च, 2026 को, ऑल-इन वेंचर पॉडकास्ट में एक असामान्य बातचीत थी।
वेंचर कैपिटलिस्ट चमथ पलिहापिटिया ने निवेदन निवेदित किया कि बिटटेंसर पर एक प्रोजेक्ट ने एक काफी पागलपन भरी तकनीकी उपलब्धि पूरी की है, जिसने इंटरनेट पर वितरित कंप्यूटिंग पावर का उपयोग करके एक बड़ा भाषा मॉडल ट्रेन किया है, जिसकी प्रक्रिया पूरी तरह से डिसेंट्रलाइज्ड है और किसी भी केंद्रीकृत डेटासेंटर की सहायता के बिना हुई है।
हुआंग रेन्शुन ने इससे बचने की कोशिश नहीं की। उन्होंने इसे 'Folding@home' के आधुनिक संस्करण के रूप में समानांतर रखा, जो 2000 के दशक में सामान्य उपयोगकर्ताओं को अपनी अव्यस्त कंप्यूटिंग शक्ति योगदान देने के लिए प्रोत्साहित करता था और प्रोटीन फोल्डिंग की समस्या का सामना करने के लिए साझा किया जाता था।
4 दिन पहले, 16 मार्च को, एंथ्रोपिक के सह-संस्थापक जैक क्लार्क ने एआई शोध प्रगति की एक रिपोर्ट में इस उपलब्धि को विस्तार से प्रस्तुत और संदर्भित किया: बिटटेंसर पारिस्थितिकी नेटवर्क टेम्पलर (SN3) ने 720 अरब पैरामीटर के बड़े मॉडल (कोवेनेंट 72B) का वितरित प्रशिक्षण पूरा कर लिया है, जिसका प्रदर्शन मेटा द्वारा 2023 में जारी LLaMA-2 के समान है।
जैक क्लार्क ने इस अध्याय का नाम "डिस्ट्रीब्यूटेड ट्रेनिंग के माध्यम से AI राजनीतिक अर्थशास्त्र को चुनौती देना" रखा है, और अपने विश्लेषण में जोर दिया है कि यह एक ऐसी तकनीक है जिसका लगातार अनुसरण किया जाना चाहिए—वह एक भविष्य की कल्पना कर सकते हैं जहां डिवाइस-पर AI, डिसेंट्रलाइज्ड ट्रेनिंग से उत्पन्न मॉडल्स का व्यापक रूप से उपयोग करेगा, जबकि क्लाउड-आधारित AI निजी बड़े मॉडल्स को चलाता रहेगा।
बाजार की प्रतिक्रिया थोड़ी देर से आई, लेकिन बहुत तीव्र रही: SN3 पिछले महीने 440% से अधिक बढ़ा, पिछले दो हफ्तों में 340% से अधिक बढ़ा, और इसका बाजार पूंजीकरण 130 मिलियन डॉलर हो गया। सबनेट की कहानी का विस्फोट, TAO पर क्रय दबाव के रूप में सीधे प्रतिबिंबित होगा। इसलिए, TAO तेजी से बढ़ा, जिसने एक बार 377 डॉलर तक पहुँचा, पिछले महीने दोगुना हो गया, और FDV लगभग 75 अरब डॉलर हो गया।
सवाल यह है: SN3 ने वास्तव में क्या किया? इसे प्रकाश स्थान पर क्यों लाया गया? वितरित प्रशिक्षण और डिसेंट्रलाइज्ड AI की मूल्य कहानी आगे कैसे विकसित होगी?
वह 72B मॉडल
इस प्रश्न का उत्तर देने के लिए, SN3 द्वारा प्रस्तुत परिणामों को स्पष्ट रूप से देखना आवश्यक है।
10 मार्च, 2026 को, Covenant AI टीम ने arXiv पर एक तकनीकी रिपोर्ट प्रकाशित की, जिसमें Covenant-72B की प्रशिक्षण पूर्णता की औपचारिक घोषणा की गई। यह एक 720 अरब पैरामीटर का बड़ा भाषा मॉडल है, जिसे लगभग 1.1 ट्रिलियन टोकन के कॉर्पस पर 70 से अधिक स्वतंत्र नोड्स पीयर्स (प्रति चक्र लगभग 20 नोड्स समन्वयित, प्रत्येक नोड पर 8 B200 GPU) के साथ प्रशिक्षित किया गया।
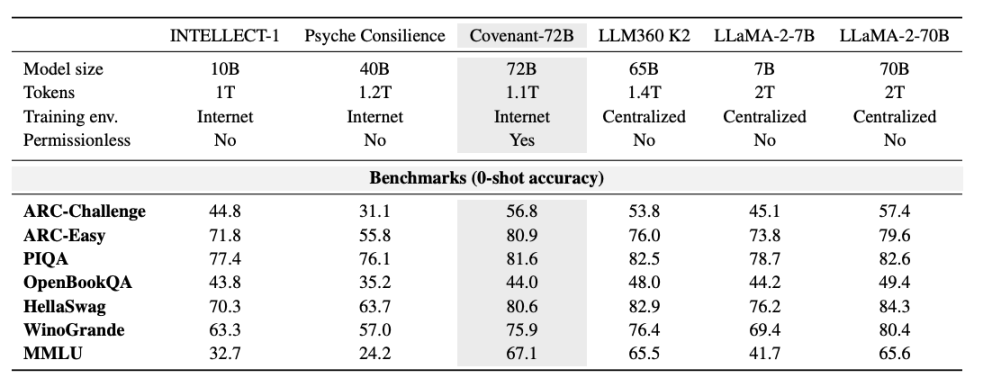
टेम्पलर ने बेंचमार्क के संदर्भ में कुछ डेटा प्रदान किया, जिसमें तुलना 2023 में मेटा द्वारा जारी LLaMA-2-70B के साथ की गई है। जैसा कि Anthropic के सह-संस्थापक जैक क्लार्क ने कहा, Covenant-72B 2026 में कुछ पुराना हो सकता है। MMLU पर Covenant-72B का 67.1 स्कोर, मेटा द्वारा 2023 में जारी LLaMA-2-70B (65.6 स्कोर) के लगभग समान है।
और 2026 के अग्रणी मॉडल—चाहे GPT श्रृंखला, Claude हो या Gemini—पहले ही लाखों GPU पर 100 अरब से अधिक पैरामीटर के साथ प्रशिक्षित हो चुके हैं, और निष्कर्षण, कोडिंग और गणित क्षमता में अंतर प्रतिशत नहीं, बल्कि क्रम का है। इस वास्तविक अंतर को बाजार के भावनात्मक प्रभाव से ढका नहीं जाना चाहिए।
लेकिन इस आधार पर कि "खुले इंटरनेट पर वितरित कंप्यूटिंग पावर का उपयोग करके प्रशिक्षित", इसका अर्थ बिल्कुल अलग हो जाता है।
तुलना करें: एक ही डिसेंट्रलाइज्ड ट्रेनिंग के तहत INTELLECT-1 (Prime Intellect टीम द्वारा, 10 बिलियन पैरामीटर) का MMLU स्कोर 32.7 है; दूसरा, व्हाइटलिस्टेड पार्टिसिपेंट्स में डिस्ट्रीब्यूटेड ट्रेनिंग किया गया Psyche Consilience (40 बिलियन पैरामीटर) का स्कोर 24.2 है। Covenant-72B, जिसका आकार 72B है और MMLU स्कोर 67.1 है, डिसेंट्रलाइज्ड ट्रेनिंग में एक उल्लेखनीय संख्या है।
अधिक महत्वपूर्ण बात यह है कि यह प्रशिक्षण «अनुमति-रहित» है। कोई भी बिना पूर्व समीक्षा या व्हाइटलिस्ट के प्रशिक्षण में भाग लेने के लिए नोड बन सकता है। 70 से अधिक स्वतंत्र नोड्स ने विश्वभर से कनेक्ट होकर कंप्यूटिंग पावर का योगदान दिया।
हुआंग रेन勛 ने क्या कहा, क्या नहीं कहा
उस पॉडकास्ट बातचीत के विवरण को दोहराने से इस «समर्थन» की बाहरी व्याख्या को सुधारने में मदद मिलेगी।
चमथ पलिहापिटिया ने बातचीत में बिटटेंसर की तकनीकी उपलब्धि को हुआंग रेन्क्सन के सामने प्रस्तुत किया और इसे एक डिस्ट्रीब्यूटेड कंप्यूटिंग पावर के साथ एक Llama मॉडल को ट्रेन करने के रूप में वर्णित किया, जिसकी प्रक्रिया "पूरी तरह से डिस्ट्रीब्यूटेड है, जबकि स्टेट को बनाए रखा जाता है"। हुआंग रेन्क्सन की प्रतिक्रिया इसे "मॉडर्न वर्जन ऑफ़ Folding@home" के रूप में तुलना करना और ओपन सोर्स और प्राइवेट मॉडल्स के समानांतर सहअस्तित्व की आवश्यकता पर चर्चा करना था।
ध्यान देने योग्य बात यह है कि हुआंग रेन्शुन ने बिटटेंसर के टोकन या किसी निवेश संबंधी अर्थ का सीधे उल्लेख नहीं किया, और डिसेंट्रलाइज्ड एआई ट्रेनिंग पर आगे चर्चा भी नहीं की।
Bittensor सबनेट और SN3 को समझें
SN3 के ब्रेकआउट को समझने के लिए, सबसे पहले बिटटेंसर और उसके सबनेट्स के कार्यप्रणाली को समझना आवश्यक है। सरल शब्दों में, बिटटेंसर को एक AI पब्लिक चेन और प्लेटफॉर्म के रूप में देखा जा सकता है, और प्रत्येक सबनेट एक स्वतंत्र "AI उत्पादन लाइन" के समान है, जिसका अपना स्पष्ट मुख्य कार्य और प्रोत्साहन तंत्र होता है, जो मिलकर एक डिसेंट्रलाइज्ड AI इकोसिस्टम का निर्माण करते हैं।
इसकी कार्यप्रणाली स्पष्ट और डिसेंट्रलाइज्ड है: सबनेट मालिक सबनेट लक्ष्य निर्धारित करते हैं और प्रोत्साहन मॉडल लिखते हैं; माइनर सबनेट में कंप्यूटिंग पावर प्रदान करते हैं और AI-संबंधित कार्य (जैसे इन्फरेंस, ट्रेनिंग, स्टोरेज आदि) पूरा करते हैं; वेरिफायर माइनर के योगदान का मूल्यांकन करते हैं और इस स्कोर को Bittensor कंसेंसस लेयर पर अपलोड करते हैं; अंततः, Bittensor का Yuma कंसेंसस एल्गोरिथम प्रत्येक सबनेट में जमा हुए पुरस्कार के आधार पर सबनेट प्रतिभागियों को संबंधित लाभ वितरित करता है।
वर्तमान में बिटटेंसर पर 128 सबनेट्स हैं, जो निष्कर्षण, सर्वरहीन AI क्लाउड सेवाएँ, चित्र, डेटा लेबलिंग, रिइनफोर्समेंट लर्निंग, स्टोरेज, कॉम्प्यूटेशन आदि विभिन्न AI कार्यों को कवर करते हैं।
और SN3 इनमें से एक सबनेट है। यह एप्लिकेशन लेयर का कोई ओवरले नहीं बनाता, न ही यह तैयार बड़े मॉडल API किराए पर लेता है, बल्कि यह AI उद्योग श्रृंखला के सबसे महंगे और सबसे बंद केंद्रीय पहलुओं में से एक: बड़े मॉडल प्री-ट्रेनिंग पर सीधे ध्यान केंद्रित करता है।
SN3 बिटटेंसर नेटवर्क का उपयोग विषम कंप्यूटिंग संसाधनों के वितरित प्रशिक्षण को समन्वित करने के लिए करना चाहता है, जिससे प्रेरित वितरित बड़े मॉडल प्रशिक्षण के माध्यम से साबित होता है कि महंगे केंद्रीकृत सुपरकंप्यूटर क्लस्टर के बिना भी शक्तिशाली आधार मॉडल प्रशिक्षित किए जा सकते हैं। मुख्य आकर्षण 'समानता' में है—केंद्रीकृत प्रशिक्षण के संसाधनों के एकाधिकार को तोड़ना, जिससे सामान्य व्यक्ति या छोटे-मध्यम संगठन भी बड़े मॉडल प्रशिक्षण में भाग ले सकें, और वितरित कंप्यूटिंग शक्ति के माध्यम से प्रशिक्षण लागत को कम किया जा सके।
SN3 के विकास की केंद्रीय शक्ति Templar है, जिसके पीछे अनुसंधान टीम Covenant Labs है। यह टीम एक साथ दो अन्य सबनेट्स भी संचालित करती है: Basilica (SN39, कंप्यूटिंग सेवाओं पर केंद्रित) और Grail (SN81, RL फाइन-ट्यूनिंग और मॉडल आकलन पर केंद्रित)। तीनों सबनेट्स एक ऊर्ध्वाधर एकीकरण बनाते हैं, जो बड़े मॉडल के प्री-ट्रेनिंग से लेकर अलाइनमेंट ऑप्टिमाइज़ेशन तक की पूरी प्रक्रिया को कवर करता है, और डिसेंट्रलाइज्ड बड़े मॉडल ट्रेनिंग का एक पूर्ण पारिस्थितिकी तंत्र बनाता है।
विशेष रूप से, माइनर्स कंप्यूटिंग रिसोर्सेज का योगदान देते हैं और ग्रेडिएंट अपडेट (मॉडल पैरामीटर्स की दिशा और तीव्रता) को नेटवर्क पर अपलोड करते हैं; वेरिफायर्स प्रत्येक माइनर के योगदान की गुणवत्ता का मूल्यांकन करते हैं और त्रुटि में सुधार के स्तर के आधार पर चेन पर स्कोर देते हैं। परिणाम रिवॉर्ड वजन निर्धारित करते हैं, जो स्वचालित रूप से आवंटित होते हैं और किसी तीसरे पक्ष पर भरोसा की आवश्यकता नहीं होती।
इन्सेंटिव डिज़ाइन की कुंजी यह है कि पुरस्कार सीधे आपके योगदान से जुड़ा होगा कि आपने मॉडल को कितना बेहतर बनाया, न कि केवल कैलकुलेशन क्षमता की उपस्थिति से। इससे डिसेंट्रलाइज्ड स्थिति में सबसे कठिन समस्या का मूल स्तर पर हल निकल जाता है: माइनर्स को आलस करने से कैसे रोका जाए।
Covenant-72B कैसे संचार की दक्षता और प्रेरणात्मक संगति की समस्याओं को हल करता है?
अलग-अलग विश्वास न किए गए, अलग-अलग हार्डवेयर और असमान नेटवर्क क्वालिटी वाले दर्जनों नोड्स को एक ही मॉडल के लिए सहयोगी रूप से प्रशिक्षित करना दो चुनौतियों का सामना करता है: पहली, संचार की दक्षता, मानक वितरित प्रशिक्षण योजनाएँ नोड्स के बीच उच्च बैंडविड्थ और कम लेटेंसी की आवश्यकता रखती हैं; दूसरी, प्रेरणा का संगति, कैसे दुर्भावनापूर्ण नोड्स को गलत ग्रेडिएंट सबमिट करने से रोका जाए? कैसे सुनिश्चित किया जाए कि प्रत्येक प्रतिभागी सचमुच प्रशिक्षण कर रहा है, और किसी और के परिणामों की नकल नहीं कर रहा है?
SN3 इन दो समस्याओं को SparseLoCo और Gauntlet के दो मुख्य घटकों से हल करता है।
SparseLoCo संचार की दक्षता की समस्या का समाधान करता है। पारंपरिक वितरित प्रशिक्षण में प्रत्येक चरण में पूर्ण ग्रेडिएंट को सिंक्रनाइज़ किया जाता है, जिससे डेटा की मात्रा बहुत अधिक हो जाती है। SparseLoCo का दृष्टिकोण है: प्रत्येक नोड स्थानीय रूप से 30 चरणों के आंतरिक अनुकूलन (AdamW) को पूरा करता है, और फिर उत्पन्न "प्सीडो-ग्रेडिएंट" को संपीड़ित करके अन्य नोड्स को अपलोड करता है। संपीड़न विधि में Top-k स्पार्सिफिकेशन (केवल सबसे महत्वपूर्ण ग्रेडिएंट घटकों को बरकरार रखना), त्रुटि प्रतिक्रिया (हटाए गए भागों को संग्रहीत करके अगले चक्र में जमा करना), और 2-बिट क्वांटाइज़ेशन शामिल हैं। अंतिम संपीड़न अनुपात 146 गुना से अधिक है।
दूसरे शब्दों में, जिस चीज को पहले 100MB ट्रांसमिट करने की आवश्यकता थी, अब उसके लिए 1MB से कम काफी है।
इससे सिस्टम सामान्य इंटरनेट (अपलिंक 110 मेगाबिट प्रति सेकंड, डाउनलिंक 500 मेगाबिट प्रति सेकंड) के बैंडविड्थ सीमा के अंतर्गत गणना उपयोग को लगभग 94.5% पर बनाए रखता है—20 नोड्स, प्रति नोड 8 B200, प्रति संचार चक्र केवल 70 सेकंड का समय लगता है।
Gauntlet इन्सेंटिव कॉम्पैटिबिलिटी समस्या को हल करता है। यह Bittensor ब्लॉकचेन (Subnet 3) पर चलता है और प्रत्येक नोड द्वारा सबमिट किए गए प्सीडो-ग्रेडिएंट की गुणवत्ता की पुष्टि करता है। इसका तरीका यह है: एक छोटे डेटा बैच का उपयोग करके यह जांचता है कि "इस नोड के ग्रेडिएंट का उपयोग करने से मॉडल की हानि कितनी कम हुई", जिसे LossScore कहा जाता है। साथ ही, सिस्टम यह भी जांचता है कि क्या नोड अपने आवंटित डेटा पर प्रशिक्षण दे रहा है—अगर कोई नोड अपने आवंटित डेटा की तुलना में यादृच्छिक डेटा पर अधिक हानि में सुधार करता है, तो उसे नकारात्मक अंक मिलते हैं।
अंततः, प्रत्येक ट्रेनिंग राउंड में केवल सर्वोच्च अंक प्राप्त नोड के ग्रेडिएंट को ही एग्रीगेशन में शामिल किया जाता है, शेष नोड्स इस राउंड से बाहर हो जाते हैं। अतिरिक्त प्रतिभागी समय-समय पर स्थान भरने के लिए जोड़े जाते हैं, ताकि प्रणाली स्थिर बनी रहे। पूरी ट्रेनिंग प्रक्रिया के दौरान, प्रति राउंड औसतन 16.9 नोड्स के ग्रेडिएंट एग्रीगेशन में शामिल किए गए, और कुल मिलाकर 70 से अधिक अद्वितीय नोड ID ने भाग लिया।
डिसेंट्रलाइज्ड एआई की मूल्य कहानी में मौलिक परिवर्तन हो रहा है
इस बात को तकनीकी और उद्योग के दृष्टिकोण से देखें, तो Covenant-72B द्वारा अपनाए जा रहे मार्ग के कुछ वास्तविक महत्व हैं।
पहला, "वितरित प्रशिक्षण केवल छोटे मॉडल के लिए उपयुक्त है" यह पूर्वधारणा को तोड़ दिया गया। हालाँकि इसकी तुलना अग्रणी मॉडल्स से अभी बहुत दूर है, लेकिन इस दिशा की स्केलेबिलिटी को साबित किया गया है।
दूसरा, बिना अनुमति के भागीदारी वास्तविक और संभव है। इस बात का कम मूल्यांकन किया गया है। पिछले वितरित प्रशिक्षण प्रोजेक्ट्स व्हाइटलिस्ट पर निर्भर करते थे—केवल सत्यापित भागीदार ही कंप्यूटिंग पावर योगदान दे सकते थे। SN3 के इस प्रशिक्षण में, कोई भी व्यक्ति जिसके पास पर्याप्त कंप्यूटिंग पावर है, जुड़ सकता है, और प्रमाणीकरण प्रणाली दुरुपयोगी योगदानों को फिल्टर करती है। यह 'वास्तविक डिसेंट्रलाइजेशन' की ओर एक व्यावहारिक कदम है।
तीसरा, बिटटेंसर का dTAO तंत्र उपनेट के मूल्य की बाजार खोज को संभव बनाता है। dTAO प्रत्येक उपनेट को अपना अल्फा टोकन जारी करने की अनुमति देता है, जिससे AMM तंत्र के माध्यम से बाजार यह निर्धारित कर सके कि कौन से उपनेट को अधिक TAO वितरण प्राप्त हो। इससे SN3 जैसे विशिष्ट परिणाम प्राप्त करने वाले उपनेट के लिए एक कच्ची लेकिन प्रभावी मूल्य पकड़ने की प्रणाली प्रदान होती है। हालाँकि, यह प्रणाली कथाओं और भावनाओं से प्रभावित होने की संभावना रखती है, क्योंकि LLM प्रशिक्षण परिणामों की गुणवत्ता का सामान्य बाजार प्रतिभागी स्वतंत्र रूप से मूल्यांकन करने में सक्षम नहीं होता।
चौथा, डिसेंट्रलाइज्ड एआई ट्रेनिंग के राजनीतिक-आर्थिक अर्थ। जैक क्लार्क ने Import AI में इस समस्या को "एआई का भविष्य किसके पास है" इस स्तर तक उठा दिया है। वर्तमान में अग्रणी मॉडल ट्रेनिंग को कुछ ही बड़े डेटासेंटर वाले संस्थानों द्वारा एकाधिकार में रखा गया है, जो केवल व्यावसायिक समस्या ही नहीं, बल्कि शक्ति संरचना की समस्या भी है। यदि वितरित ट्रेनिंग तकनीकी प्रगति जारी रखती है, तो कुछ मॉडल प्रकारों (जैसे विशिष्ट क्षेत्रों के छोटे अग्रणी मॉडल) पर वास्तविक डिसेंट्रलाइज्ड विकास पारिस्थिति का निर्माण संभव हो सकता है। हालाँकि, यह कल्पना अभी बहुत दूर है।
सारांश: एक वास्तविक मील का पत्थर, और कई वास्तविक समस्याएँ
हुआ रेन्युन ने कहा कि यह "आधुनिक Folding@home" की तरह है। Folding@home ने अणु सिमुलेशन के क्षेत्र में वास्तविक योगदान दिया है, लेकिन इसने बड़ी फार्मास्यूटिकल कंपनियों की कोर अनुसंधान स्थिति को खतरे में नहीं डाला है। यह तुलना बहुत सटीक है।
SN3 ने प्रोटोकॉल को सफलतापूर्वक लागू किया और वितरित प्रशिक्षण की संभावित दिशा की पुष्टि की। लेकिन तकनीकी और उद्योग के दृष्टिकोण से, इसके प्रदर्शन के पीछे कई ऐसे मुद्दे मौजूद हैं जिनकी बहुत कम लोग गंभीरता से चर्चा करना चाहते हैं:
MMLU खुद शैक्षणिक समुदाय में एक विवादास्पद सूचकांक है, जिसमें खुले बेंचमार्क के प्रश्न और उत्तर ट्रेनिंग सेट में रिसाव का खतरा है। अधिक महत्वपूर्ण बात यह है कि तुलनात्मक आधार का चयन: पेपर में LLaMA-2-70B और LLM360 K2 के साथ तुलना की गई है, जो 2023 से 2024 के पुराने मॉडल हैं, जबकि उसी समय अवधि में 65 से 70 के स्कोर, Grok और DouBao के संदर्भ में मध्यम से नीचे और प्रारंभिक स्तर के रूप में वर्गीकृत किए जाते हैं, और Claude के अनुसार यह गंभीर रूप से पिछड़ा हुआ है। यदि इसे डायनामिक अपडेट होने वाली सूची या प्रदूषण-विरोधी डिज़ाइन वाले नवीनतम बेंचमार्क पर स्थापित किया जाए, तो निष्कर्ष अधिक सच्चे हो सकते हैं।
अधिक महत्वपूर्ण बात यह है कि मॉडल की क्षमता की सीमा निर्धारित करने वाले उच्च गुणवत्ता वाले डेटा—संवाद, कोड, गणितीय निष्कर्ष, वैज्ञानिक पत्र—संभवतः बड़ी कंपनियों, प्रकाशन संस्थानों और शैक्षणिक डेटाबेस के पास हैं। कैलकुलेशन क्षमता लोकतांत्रिक हो गई है, लेकिन डेटा का पक्ष अभी भी अल्पसंख्यक संरचना है, और इस विरोधाभास को कभी चर्चा नहीं की गई है।
सुरक्षा के संदर्भ में, अनुमति के बिना भागीदारी का अर्थ है कि आपको नहीं पता कि उन 70 से अधिक नोड्स के पीछे कौन है, और वे किस डेटा का उपयोग करके प्रशिक्षण दे रहे हैं। गॉंटलेट ज्ञात असामान्य ग्रेडिएंट्स को फिल्टर कर सकता है, लेकिन सूक्ष्म डेटा पॉइजनिंग से बचाव नहीं कर सकता—अगर कोई नोड समय-समय पर किसी विशिष्ट हानिकारक सामग्री की ओर अधिक प्रशिक्षण चक्र दे रहा है, तो उत्पन्न ग्रेडिएंट परिवर्तन इतने सूक्ष्म होते हैं कि वे हानि स्कोरिंग से गुजर जाते हैं, लेकिन मॉडल के व्यवहार में संचयी विस्थापन पैदा करते हैं। अंतिम प्रश्न यह है: वित्त, स्वास्थ्य, कानून जैसे उच्च-अनुपालन और सुरक्षा-आधारित परिदृश्यों में, कुछ अज्ञात नोड्स द्वारा प्रशिक्षित और डेटा स्रोतों का पता लगाने में अपूर्ण मॉडल का उपयोग करने से क्या खतरे हो सकते हैं?
एक और संरचनात्मक समस्या को सीधे कहना चाहिए: Covenant-72B खुद Apache 2.0 लाइसेंस के तहत ओपन सोर्स है और SN3 टोकन का उपयोग नहीं करता है। SN3 टोकन रखने से, आप इस सबनेट द्वारा भविष्य में नए मॉडल के निरंतर उत्पादन से उत्पन्न होने वाले उत्सर्जन लाभ को साझा करते हैं, न कि मॉडल के उपयोग से कोई सीधा लाभ। यह मूल्य श्रृंखला, निरंतर प्रशिक्षण उत्पादन और Bittensor की समग्र नेटवर्क उत्सर्जन प्रणाली के स्वस्थ संचालन पर निर्भर करती है। यदि भविष्य में प्रशिक्षण रुक जाए या नए प्रशिक्षण परिणामों की गुणवत्ता अपेक्षित स्तर पर नहीं है, तो टोकन के मूल्यांकन का तर्क कमजोर हो जाएगा।
इन सवालों को उठाने का मकसद Covenant-72B के महत्व को नकारना नहीं है। यह तथ्य कि एक ऐसी चीज जिसे पहले असंभव माना जाता था, वह संभव हो गई, वह कभी नहीं गायब होगा। लेकिन कर पाना और इसका क्या मतलब है, ये दो अलग बातें हैं।
SN3 टोकन पिछले महीने 440% बढ़ा है। इस बीच की दूरी, सिर्फ एक बुलिश अफवाह नहीं हो सकती, बल्कि कहानी की गति हमेशा वास्तविकता की गति से तेज होती है। यह दूरी अंततः वास्तविकता द्वारा भर दी जाएगी या बाजार द्वारा समायोजित कर ली जाएगी, यह Covenant AI टीम आगे क्या प्रस्तुत करती है, इस पर निर्भर करता है।
ध्यान देने योग्य बात यह है कि ग्रे स्केल के पास जनवरी 2026 में TAO ETF के लिए आवेदन दायर किया गया है, जो संस्थागत पूंजी के इस क्षेत्र में प्रवेश के संकेत की ओर इशारा करता है। इसके अलावा, दिसंबर 2025 में Bittensor ने दैनिक TAO उत्पादन को आधा कर दिया है, जिससे आपूर्ति की ओर से संरचनात्मक संकुचन अभी भी जारी है।
रेफरेंस लिंक:
https://arxiv.org/pdf/2603.08163
https://importai.substack.com/p/importai-449-llms-training-other
https://docs.tplr.ai/
https://systems-analysis.ru/int/MMLU_Benchmark_%E2%80%94_MMLU_%E5%9F%BA%E5%87%86%E6%B5%8B%E8%AF%95