









क्या रोबोट सपने देखते हैं? अगर वे सपने देखते हैं, तो क्या वे इलेक्ट्रॉनिक भेड़ों के सपने देखते हैं?

फिल्म ब्लेड रनर की स्क्रीनशॉट
1968 में, विज्ञान कथा फिल्म ब्लेड रनर के मूल उपन्यास के लेखक फिलिप के. डिक ने टाइपराइटर के सामने इस अमूर्त और अग्रदूत सवाल को टाइप किया, लेकिन उन्हें शायद यह नहीं पता था कि आधे शताब्दी बाद, सिलिकॉन वैली के टेक दिग्गज इसका गंभीरता से जवाब देंगे।
हाँ, वे केवल इलेक्ट्रॉनिक भेड़ों का सपना देखते हैं, बल्कि उन सपनों को दृश्यमान भी बना सकते हैं।
कल, Anthropic ने सैन फ्रांसिस्को में डेवलपर कॉन्फ्रेंस में Managed Agents के लिए नई सुविधाएँ लॉन्च कीं: मेमोरी एक्सटेंशन, रिजल्ट आउटपुट, मल्टी-एजेंट सहयोग, और 'ड्रीमिंग'।
एंथ्रोपिक के अपने शब्दों में, "मेमोरी और ड्रीमिंग मिलकर एक मजबूत, स्व-सुधार करने वाले एजेंट मेमोरी सिस्टम का निर्माण करते हैं।"

फिर से सपना, फिर से यादें, AI क्षेत्र में ध्यान न देने वाले दोस्त शायद पूरी तरह से उलझ जाएंगे—ये मानवीय शब्द कब से AI पर इतने आसानी से लागू होने लगे।
2024 में OpenAI ने o1 श्रृंखला लॉन्च की थी, 'एक ऐसी AI मॉडल श्रृंखला जिसे जवाब देने से पहले अधिक समय तक सोचने के लिए डिज़ाइन किया गया था', 'सोच' शब्द का उपयोग इतना प्राकृतिक था कि किसी ने भी यह पूछने का रुकने का प्रयास नहीं किया कि एक सांख्यिकीय भविष्यवाणी करने वाला प्रोग्राम, जो अगला token प्रेडिक्ट करता है, इसे सोच क्यों कहा जा रहा है?
इसके बाद reasoning (तर्क), memory (स्मृति), reflection (प्रतिबिंब), Imagining (कल्पना) आदि मानवीय क्षमताओं को एक-एक करके उत्पाद प्रकाशन पर लाया जाता है।

फिल्म द ड्रीम के स्क्रीनशॉट, रेड पिलोट
"सोचना" को रूपक के रूप में समझा जा सकता है, "याददाश्त" को भी तकनीकी शब्दावली का विस्तार माना जा सकता है, लेकिन "सपने देखना" तो वास्तव में बहुत अधिक है। प्राचीन काल से लेकर आज तक, साहित्य, इतिहास और दर्शन ने हजारों वर्षों तक इसे समझने में असमर्थता का सामना किया है, और फिर भी AI कंपनियाँ सीधे कहती हैं: हमने केवल सोचने वाली मशीनें ही नहीं, बल्कि सपने देखने वाली मशीनें भी बना ली हैं।
सपना देखना क्या है, इस घटना का सटीक वर्णन करने के लिए क्या कोई भी इंजीनियरिंग शब्द नहीं मिलता?
AI को सपने देखने के लिए भी पैसे खर्च करने पड़ते हैं
क्लॉड कोड लीक होने के समय, नेटिज़न्स ने देखा कि एंथ्रोपिक एक फीचर "ऑटो ड्रीमिंग" की तैयारी कर रहा है। तब सभी सोच रहे थे कि क्या AI भी हम मनुष्यों की तरह सोने की आवश्यकता रखता है, ताकि पर्याप्त आराम के बाद यह अधिक ध्यान केंद्रित और बुद्धिमान बन सके?
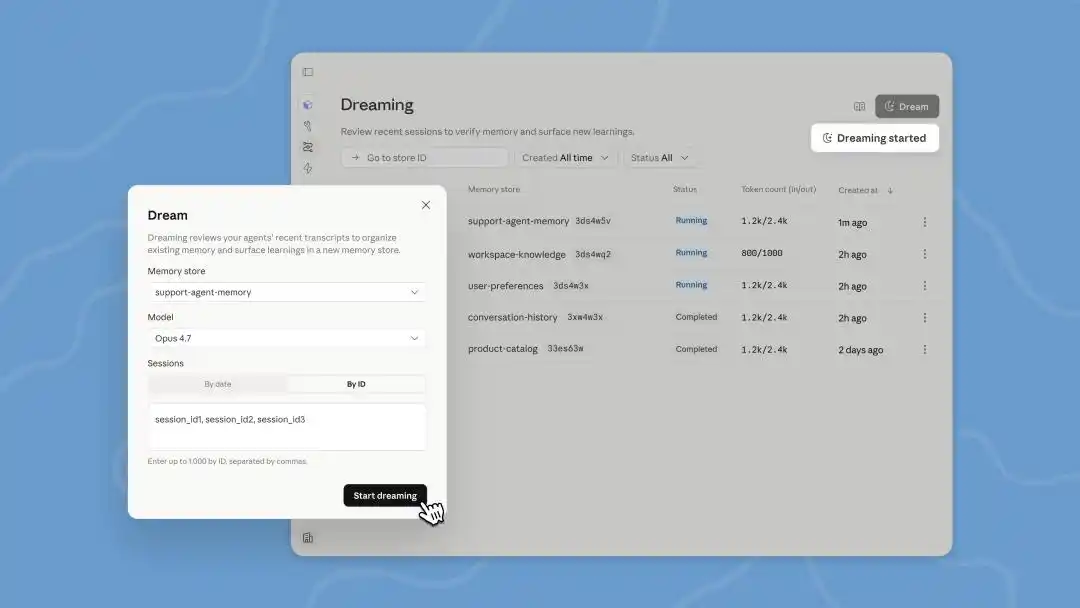
लेकिन जब आप वर्तमान AI एजेंट के कार्य के सिद्धांत को समझते हैं, तो पता चलता है कि जिसे "सपने देखना" कहा जाता है, वह मूल रूप से एक स्वचालित ऑफलाइन लॉग बैच प्रोसेसिंग है।
AI एजेंट अब लंबी और जटिल कार्यों को पूरा करने में कुशल हो गए हैं। उदाहरण के लिए, "मुझे इन पांच प्रतिद्वंद्वी कंपनियों के नवीनतम वार्षिक वित्तीय विवरण का सर्वेक्षण करके एक तालिका में संगठित करें।" इस प्रक्रिया में, एजेंट को विभिन्न वेबसाइटों के बीच स्विच करना पड़ता है, कई दस्तावेज़ पढ़ने पड़ते हैं, विभिन्न उपकरणों का उपयोग करना पड़ता है, और संभवतः एंटी-स्क्रैपिंग मैकेनिज़म के कारण असफल होकर पुनः प्रयास करना पड़ता है।
जब इस लंबी ऑनलाइन कार्यश्रृंखला का अंत हो जाए, तो एजेंट के बैकग्राउंड में विशाल मात्रा में रनलॉग बच जाते हैं।
चित्र AI द्वारा उत्पन्न
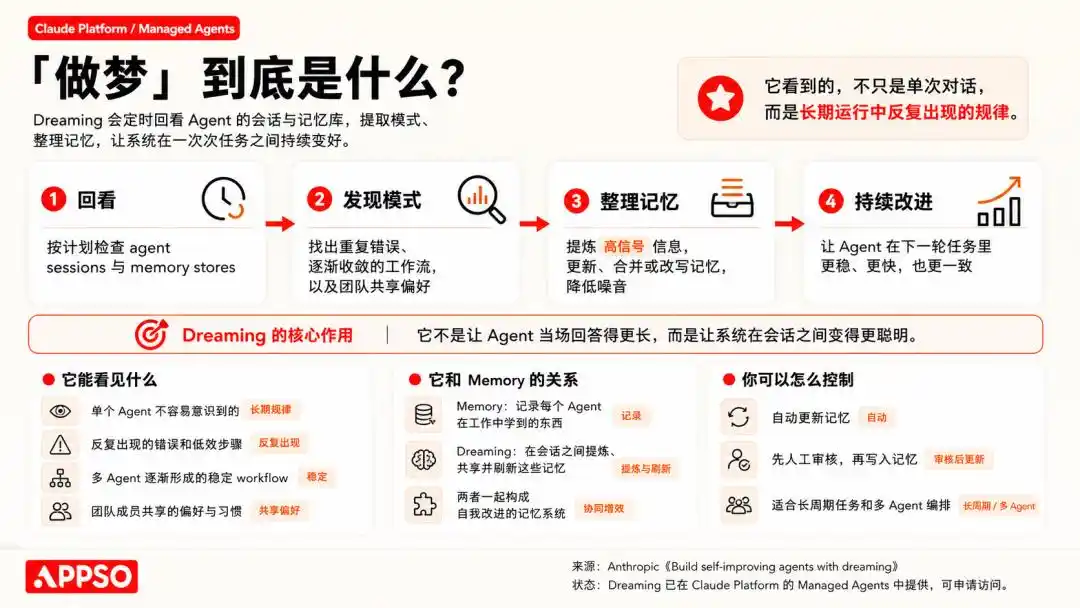
Anthropic का "सपना देखने" फीचर, जिसमें एजेंट अपने निष्क्रिय समय के दौरान इन इतिहास के रिकॉर्ड्स को फिर से संशोधित करता है। यह इनमें पैटर्न ढूंढता है, जैसे कि "हर बार ऐसा पॉप-अप आए, तो ऊपर दाएं कोने पर क्लिक करके इसे बंद किया जा सकता है", और इस प्रकार अगले कार्रवाई के मार्ग को अनुकूलित करता है।
「मेमोरी」 कार्य के दौरान सीखे गए चीजों को कैप्चर करती है, जबकि «सपना» संवादों के बीच इन स्मृतियों को संशोधित करता है और विभिन्न एजेंट्स के बीच साझा करता है।
In simple terms, this is a reinforcement learning and self-correction mechanism based on historical data.

ड्रीम्स का परिचय: https://platform.claude.com/docs/en/managed-agents/dreams
इस डेवलपर कॉन्फ्रेंस में, Managed Agents में Dreams को अपडेट किया गया है, जो एक बैकग्राउंड प्रोसेसिंग टास्क है, जिसे हमें मैन्युअल रूप से ट्रिगर करना होगा। Claude एक बार में अधिकतम 100 सेशन के डायलॉग हिस्ट्री को पढ़ सकता है और फिर हमारे समीक्षा के लिए एक नया memory तैयार करता है, जिसके बाद हम इसे उपयोग करने का फैसला करते हैं।
और पहले Claude Code में चुपचाप लॉन्च किया गया AutoDream, हर एजेंट के साथ एक चक्र बातचीत के बाद, Claude Code पृष्ठभूमि में जांच करता है कि "क्या सपना देखना चाहिए", डिफ़ॉल्ट रूप से 24 घंटे में एक बार।
जैसे सपने देखने की सुविधा, हरमेस एजेंट के पास भी है। हरमेस एजेंट की मुख्य विशेषता यह है कि यह स्वयं सीख सकता है और विकसित हो सकता है, यह केवल अतीत के कार्यों से अनुभव सारांशित करने के लिए समर्थ है और उन्हें स्मृति फ़ाइल में संग्रहित करता है।

इनमें से एक क्यूरेटर नामक सुविधा, इन निकाले गए ऑपरेशन गाइड्स को स्वचालित रूप से स्किल में व्यवस्थित कर सकती है।
इन स्किल्स को अंक दिए जाएंगे, दोहराव वाले एक साथ मर्ज कर दिए जाएंगे, लंबे समय तक उपयोग न किए गए स्वचालित रूप से आर्काइव कर दिए जाएंगे, और इनके पास active, stale, archived जैसे जीवनचक्र भी होंगे। हम महत्वपूर्ण स्किल्स को पिन भी कर सकते हैं ताकि सिस्टम इन्हें स्वचालित रूप से हटा न दे।
OpenClaw ने हाल के कुछ अपडेट्स में क्रॉस-डायलॉग पर्सिस्टेंट मेमोरी, टाइमर-बेस्ड टास्क स्केड्यूलिंग, सब-एजेंट आइसोलेशन एक्जीक्यूशन, और ड्रीमिंग नामक सीधा सपना देखने की सुविधा जोड़ी है।
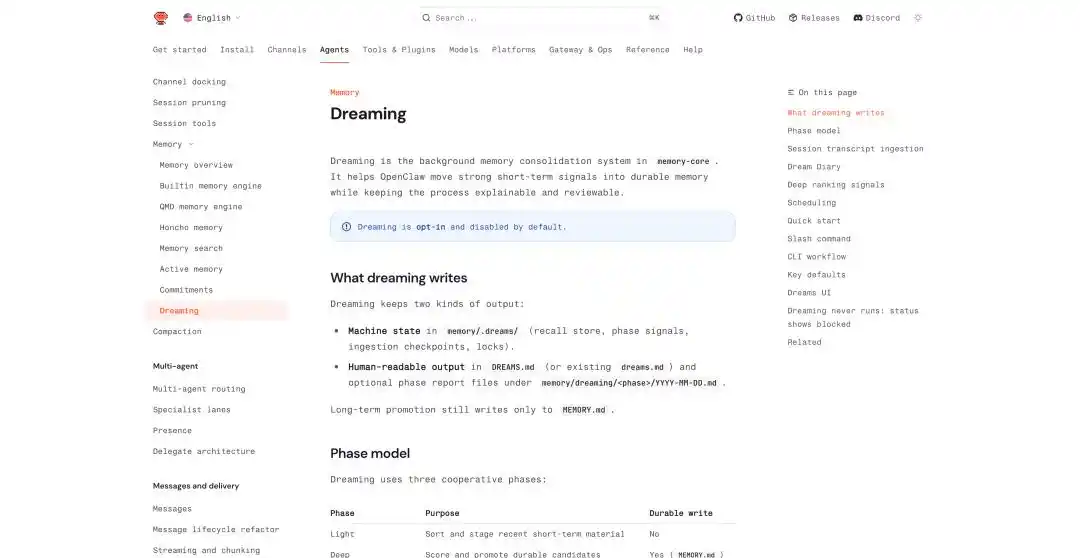
OpenClaw का सपना: https://docs.openclaw.ai/concepts/dreaming
OpenClaw के सपने के तंत्र में, यह सपनों की यात्रा को तीन चरणों में संक्षिप्त करता है: light, REM, deep। पहले दो चरण संगठन, प्रतिबिंब और विषय सारांश के लिए जिम्मेदार हैं, जबकि deep ही वास्तव में सामग्री को लंबे समय तक की स्मृति MEMORY.md में लिखता है।
गहरी नींद के चरण में स्थिरीकरण, लंबे समय तक की याददाश्त में लिखने की आवश्यकता को छह भारित संकेतों द्वारा निर्धारित किया जाएगा: आवृत्ति, संबंधितता, क्वेरी विविधता, समयोचितता, बहुदिनीय दोहराव और अवधारणात्मक समृद्धि।

चित्र AI द्वारा उत्पन्न
लंबे समय तक की याददाश्त में लिखने से दो फाइलें बनती हैं: एक मशीन के लिए स्थिति फाइल, जो memory/.dreams/ में संग्रहित होती है; और एक उपयोगकर्ता के लिए पठनीय रिकॉर्ड, जो DREAMS.md और चरणबद्ध रिपोर्ट में लिखा जाता है।
इसके अलावा, ड्रीमिंग स्वचालित रूप से निर्धारित समय पर चल सकता है, जिसमें डिफ़ॉल्ट रूप से प्रतिदिन रात 3 बजे एक पूर्ण प्रक्रिया चलती है, जिसका क्रम light → REM → deep है।
सपनों के आउटपुट के अलावा, OpenClaw एक 'ड्रीम डायरी' नामक दस्तावेज़ भी बनाए रखता है, जिसमें सिस्टम एक कहानी के रूप में स्मृति संगठन प्रक्रिया को रिकॉर्ड करता है, जिसमें ब्लैक बॉक्स डेटाबेस के बजाय व्याख्यायोग्य और समीक्षायोग्य बनाए रखने पर जोर दिया जाता है।
न्यूरोसाइंस में एक बहुत ही क्लासिक समझ है: मानव दिन के दौरान प्राप्त जानकारी पहले अस्थायी स्टोरेज सिस्टम में जाती है; और नींद के दौरान, दिमाग इन जानकारियों को पुनः चलाता है, मजबूत करता है और साफ करता है, महत्वपूर्ण को बरकरार रखता है और अनावश्यक को हटा देता है।
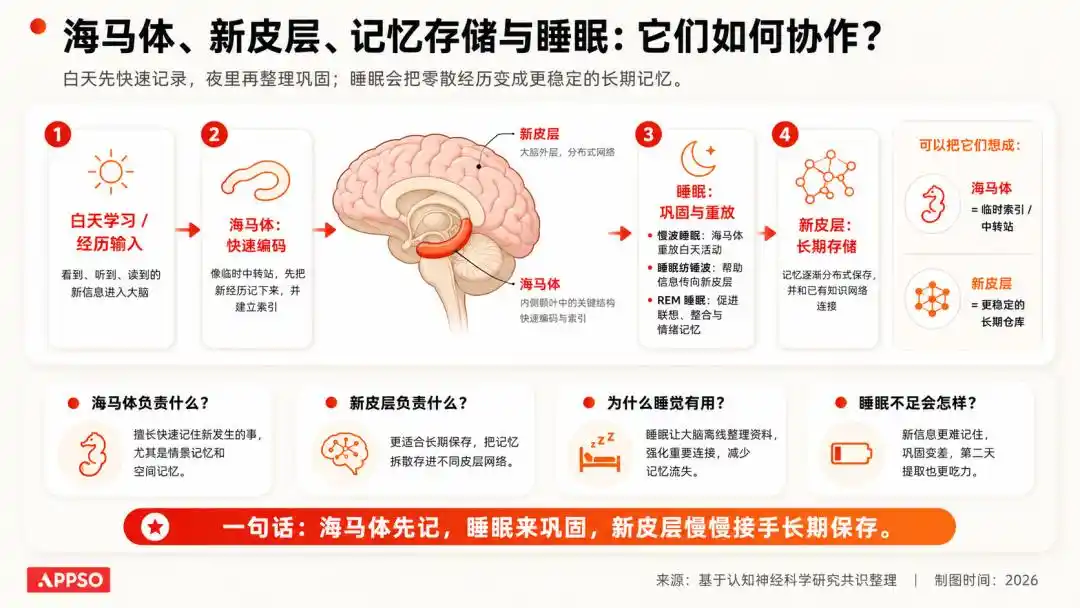
चित्र AI द्वारा उत्पन्न
हम कल काम के रास्ते में हर गाड़ी के रंग को याद नहीं रखेंगे, लेकिन कंपनी तक पहुँचने का तरीका याद रखेंगे।
ये सपने, हमारे इंसानों के सपनों की तरह ही लगते हैं, अगर कोई अंतर ढूंढना है, तो शायद यही कि क्लॉड सपने देखते समय हमारे टोकन का उपयोग कर रहा होता है।
लेकिन Anthropic और OpenClaw ने इसे 'सेशन-आधारित अनुकूलन (session-based optimization)' या 'कार्य के बाद ट्यूनिंग (post-task tuning)' जैसे इंजीनियरिंग-ओरिएंटेड नाम नहीं रखा।
अंततः, जब उन जटिल नामों को सीधे 「सपना देखना」 में बदल दिया जाता है, तो हमें महसूस होता है कि यह कोई सॉफ्टवेयर फ़ंक्शन नहीं, बल्कि एक 「अंतःक्रियाशील डिजिटल जीव」 है।
AI की याददाश्त, छोटे-मोटे संदर्भ हैं
चूंकि "सपना" का उल्लेख किया गया है, इसलिए इसकी पूर्वशर्त, स्मृति (Memory) का उल्लेख करना अनिवार्य है।
पिछले कुछ समय से, AI दुनिया में सबसे लोकप्रिय शब्द प्रॉम्प्ट इंजीनियरिंग से बदलकर कॉन्टेक्स्ट इंजीनियरिंग, स्किल इंजीनियरिंग और हार्नेस इंजीनियरिंग हो गया है, लेकिन जितना भी बदलाव हो रहा है, वर्तमान में सबसे अधिक मूल्यवान अभी भी कॉन्टेक्स्ट इंजीनियरिंग ही है।
सिस्टम प्रॉम्प्ट, उपयोगकर्ता इनपुट, अल्पकालिक बातचीत, दीर्घकालिक स्मृति, पुनः प्राप्त दस्तावेज, उपकरण और कौशल कॉल के आउटपुट, वर्तमान उपयोगकर्ता स्थिति, ये स्तर एक साथ मिलकर एजेंट द्वारा वास्तव में उपयोग किया जाने वाला 'संदर्भ' होते हैं।
लंबे समय तक, एजेंट को अधिक याद रखने और अधिक उपयोगी जानकारी नोट करने की समस्या रही है।
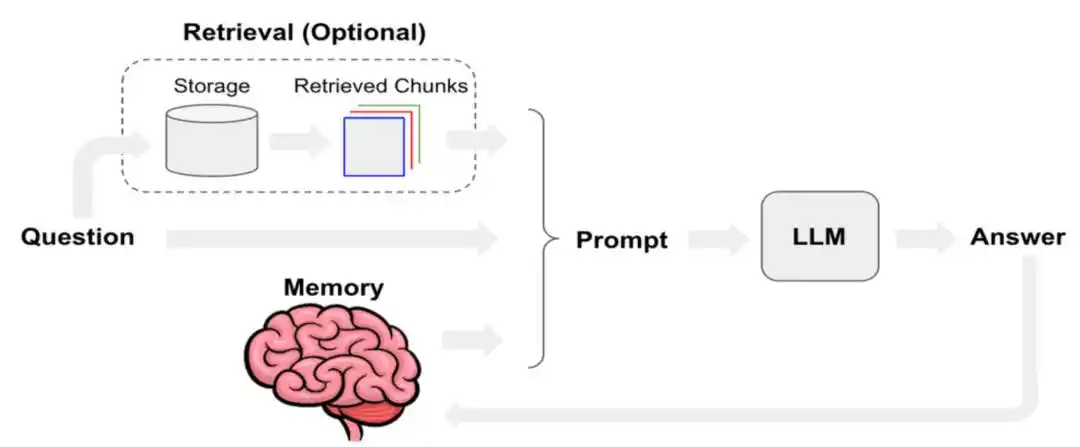
मैनस ने पिछले साल एक तकनीकी ब्लॉग पोस्ट लिखी, जिसमें मैनस कैसे संदर्भ इंजीनियरिंग को अनुकूलित करता है, इसकी विस्तृत चर्चा की गई। इसमें KV-कैश कैश हिट रेट को उत्पादन पर्यावरण में AI एजेंट के सबसे महत्वपूर्ण एकल सूचकों में से एक के रूप में परिभाषित किया गया है। साथ ही, टूल कॉलिंग स्तर पर, "हटाने" के बजाय "छिपाने" को प्राथमिकता दी गई है; और फाइल सिस्टम को अंतिम संदर्भ के रूप में उपयोग किया गया है।
KV कैश (की-वैल्यू कैश) को समझने के लिए, हम बड़े मॉडल को एक अत्यधिक अनुशासनप्रिय व्यक्ति के रूप में कल्पना कर सकते हैं जो केवल एक अक्षर एक समय में पढ़ सकता है।
जब यह एक वाक्य को प्रोसेस करता है, तो प्रत्येक जेनरेट किए गए टोकन के लिए यह एक Key (कुंजी) और एक Value (मान) वेक्टर निकालता है। हर बार पुनः गणना करने से बचने के लिए, यह (K, V) की-वैल्यू जोड़े को स्टोर कर लेता है, जिसे KV Cache कहते हैं।
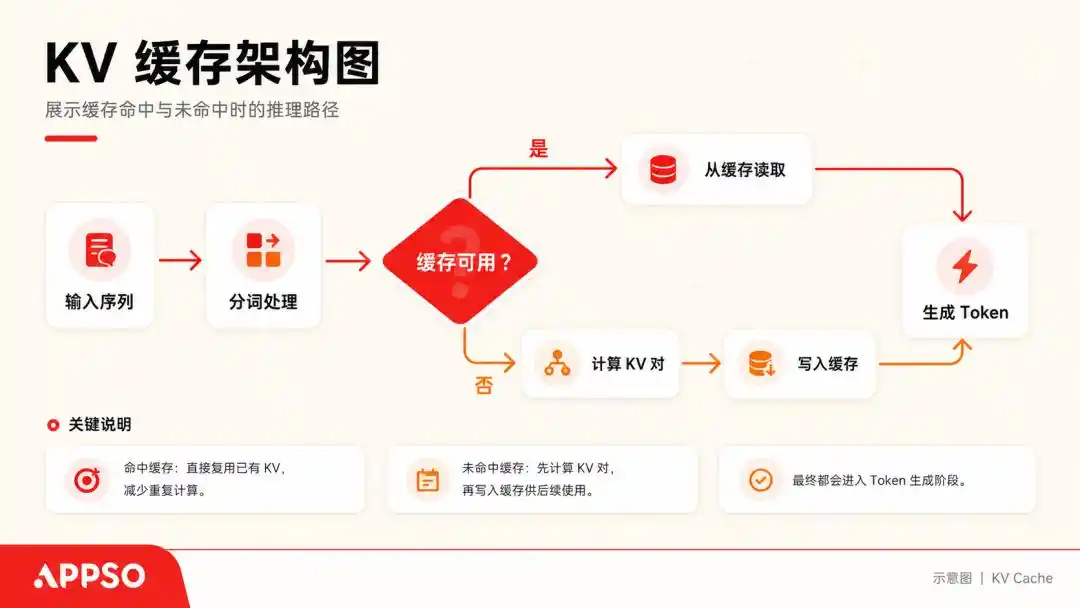
KV कैश (की-वैल्यू कैश) एक निचले स्तर की त्वरण तकनीक है जिसका उपयोग बड़े मॉडल द्वारा पाठ उत्पन्न करते समय "स्थान के लिए समय" के लिए किया जाता है। कैश के कारण, मॉडल को अगले शब्द की भविष्यवाणी करते समय पिछले सभी शब्दों को पुनः गणना करने की आवश्यकता नहीं होती है। चित्र AI द्वारा उत्पन्न।
जब तक बातचीत जारी रहती है, KV Cache लगातार सहेजा जाता रहता है। सामान्यतः, 128k कॉन्टेक्स्ट वाले बड़े मॉडल के सामने, एक 70B पैरामीटर मॉडल 128k कॉन्टेक्स्ट को पूरा करने पर, केवल KV Cache ही 64 GB वीडियो मेमोरी को एक बार में खा जाता है।
इसीलिए अधिकांश मॉडल की संदर्भ खिड़की वर्तमान में केवल लाखों स्तर तक है।
कल, 29 मिलियन डॉलर के बीज फंडिंग से सुसज्जित नई कंपनी Subquadratic ने X पर SubQ नया मॉडल लॉन्च किया, जो लंबे कंटेक्स्ट पर ध्यान केंद्रित करता है।

SubQ दावा करता है कि यह 1200 लाख टोकन तक के कॉन्टेक्स्ट विंडो का समर्थन करता है, जो वर्तमान में सभी बड़े मॉडल्स में सबसे बड़ा कॉन्टेक्स्ट विंडो है।
हालांकि अभी तक कोई तकनीकी पेपर या मॉडल डॉक्यूमेंटेशन उपलब्ध नहीं है, लेकिन प्रस्तुति वीडियो में बताया गया है कि SubQ की केंद्रीय तकनीकी दिशा पारंपरिक Transformer के 'घने ध्यान' से 'अर्ध-वर्ग / रैखिक विस्तार' आर्किटेक्चर की ओर जा रही है, जिसमें विरल ध्यान शामिल है। नया आर्किटेक्चर लंबे संदर्भ के साथ कैलकुलेशन लागत में विस्फोट की समस्या को हल करने की उम्मीद करता है।

दिए गए परीक्षण परिणाम भी काफी आक्रामक हैं: 100 लाख टोकन पर, गति में 50 गुना से अधिक की वृद्धि हुई और लागत में 50 गुना से अधिक की कमी हुई; 1200 लाख टोकन पर, कैलकुलेशन की आवश्यकता प्रगतिशील मॉडलों की तुलना में लगभग 1000 गुना कम हो गई।
RULER 128K लंबे संदर्भ बेंचमार्क पर, Subquadratic ने दावा किया कि SubQ 95% सटीकता और 8 डॉलर की लागत के साथ काम करता है, जबकि Claude Opus की सटीकता 94% और लगभग 2600 डॉलर की लागत है, जिससे लागत में लगभग 300 गुना कमी हुई है।
या तो संदर्भ विंडो को बढ़ाएं, या मॉडल को सपने देखना सिखाएं और खुद कुछ चीजें छोड़ दें।
इसीलिए Anthropic जैसे एजेंट उत्पादों को अब Dreaming लॉन्च करना आवश्यक है। संदर्भ विंडो की सीमा के कारण, अधिक बुद्धिमान AI को बस अधिक सामग्री भरने के बजाय, लक्षित तरीके से काम करना होगा।
स्वीकार करना कि मशीनें केवल मशीनें हैं, जितना सोचा जाता है उससे कठिन है
AI के सपने और स्मृति तंत्र को समझने के बाद, हम शायद इसके मानव गतिविधियों के साथ संबंध को जान पाएं।
लेकिन इन सभी AI कंपनियों द्वारा मशीनों के लिए बनाए गए शब्दों को एक साथ रखें, OpenAI का thinking (विचार), उद्योग-सामान्य memory (स्मृति) और hallucination (भ्रम), Anthropic का इस बार का dreaming (सपना देखना), और Anthropic की संविधान में वर्णित गुण और बुद्धिमत्ता।
हम देख सकते हैं कि AI कंपनियाँ केवल उत्पाद बेचने तक सीमित नहीं हैं, वे "मनुष्य" शब्द के अर्थों के स्वामित्व को पुनर्वितरित कर रही हैं। प्रत्येक शब्द के अपहरण से मशीन और मनुष्य के बीच की सीमा एक कदम और धुंधली हो जाती है।

भाषा अपेक्षाओं को आकार देती है, अपेक्षाएँ सहनशीलता को आकार देती हैं, और सहनशीलता यह निर्धारित करती है कि हम इसे कितना दे देने को तैयार हैं। यह एक लंबी श्रृंखला है, लेकिन शुरुआत प्रेस कॉन्फ्रेंस में उन निर्दोष शब्दों से होती है।
एक अधिक गुप्त प्रभाव जिम्मेदारी का वितरण है। जब उपकरणों को 'सोचने', 'याद रखने', 'मूल्यों' वाले इकाइयों के रूप में वर्णित किया जाता है, तो जब इनमें समस्या आती है, तो हम स्वाभाविक रूप से इसे एक स्वतंत्र 'कार्यकर्ता' के रूप में जिम्मेदार ठहराते हैं, और मानते हैं कि इस AI को 'शिक्षित', 'डीबग' और 'कैलिब्रेट' किया जाना चाहिए।
वास्तव में जिस कंपनी ने इस प्रोग्राम को हमारे कार्य प्रवाह में डिप्लॉय किया है, और जिस उत्पाद टीम ने "dreaming" शब्द लिखा है, उन्हें ही पूछना चाहिए। शब्द बदलते ही, "अभियुक्त की मेज" पर बैठने वाला व्यक्ति भी बदल जाता है।
और जब हम एक ऐसी मशीन को देखते हैं जो "सोचती" है, "याद रखती" है, और अब "सपने देखती" है, तो हम अनजाने में यह मानने लगते हैं कि इसके अंदर कुछ है। क्योंकि इसे सिर्फ एक मशीन मान लेना, उस "मैं एक सोचने वाले अस्तित्व से बात कर रहा हूँ" के अनुभव को खत्म कर देता है, और हम वापस ठंडे-ठंडे उपकरण के संबंध में आ जाते हैं।

व्हाइट ड्रीम फीचर परिचय | चित्र AI द्वारा उत्पन्न
मैंने सोचा था, Dreaming अतीत की चीजों को संभालता है, अगला AI कंपनी Daydreaming, दिन का सपना, जो भविष्य का अभ्यास करेगा।
इसका अर्थ है कि दिनभर के सपने या ध्यान भटकने से Agent, अपनी सक्रिय अवस्था में, वर्तमान में चल रहे प्रोजेक्ट के साथ-साथ, थोड़ी अतिरिक्त कैलकुलेशन क्षमता का उपयोग करके, भविष्य के संभावित कार्यों के लिए खोजी उत्पादन कर सकता है।
यह लेख वेचेन ग्रुप "APPSO" से आया है, लेखक: APPSO जो भविष्य के उत्पादों की खोज करता है।