










यह दृष्टिकोण बिना किसी आधार के नहीं आया है। उसने कई खुले बेंचमार्क देखे और पाया कि AI, AI अनुसंधान से संबंधित कार्यों में बहुत तेजी से प्रगति कर रहा है।
उदाहरण के लिए, CORE-Bench AI की क्षमता का मूल्यांकन करता है कि वह दूसरों के शोध पत्रों को कैसे लागू करती है, जो AI शोध में एक अत्यंत महत्वपूर्ण पहलू है।
PostTrainBench तब परीक्षण करता है कि क्या शक्तिशाली मॉडल कमजोर ओपन-सोर्स मॉडल को स्वयं सूक्ष्म समायोजित करके उसके प्रदर्शन में सुधार कर सकते हैं, जो AI अनुसंधान कार्यों का एक महत्वपूर्ण उपसमूह है।
MLE-Bench, वास्तविक Kaggle प्रतियोगिता कार्यों पर आधारित है, जिसमें विशिष्ट समस्याओं को हल करने के लिए विविध मशीन लर्निंग अनुप्रयोग बनाने की आवश्यकता होती है। इसके अलावा, SWE-Bench जैसे प्रसिद्ध कोडिंग बेंचमार्क भी समान प्रगति दर्शाते हैं।
जैक क्लार्क ने इस घटना को "फ्रैक्टल" जैसी ऊपर की ओर और दाईं ओर की प्रवृत्ति के रूप में वर्णित किया, जिसमें विभिन्न रिज़ोल्यूशन और स्केल पर अर्थपूर्ण प्रगति देखी जा सकती है। वह मानते हैं कि AI धीरे-धीरे एंड-टू-एंड स्वचालित रिसर्च और डेवलपमेंट की क्षमता की ओर बढ़ रहा है, और एक बार इसे हासिल कर लिया जाएगा, तो AI अपने स्वयं के अगले पीढ़ी के सिस्टम को स्वयं बना सकेगा, जिससे स्व-पुनरावृत्ति का चक्र शुरू होगा।

इस बयान के बाद सोशल मीडिया पर काफी चर्चा हुई।
कुछ लोग इसे एएसआई और सिंगुलैरिटी की ओर एक महत्वपूर्ण पहला कदम मानते हैं, जो प्रौद्योगिकी विकास की गति को पूरी तरह से बदल सकता है।

हालांकि, अलग-अलग आवाजें भी हैं।
वाशिंगटन विश्वविद्यालय के कंप्यूटर साइंस प्रोफेसर पेड्रो डोमिंगोस ने बताया कि AI प्रणालियाँ अपने आप को बनाने की क्षमता 1950 के दशक में LISP भाषा के आविष्कार के समय से ही रखती थीं, वास्तविक समस्या यह है कि क्या इससे वृद्धिशील लाभ प्राप्त हो सकता है, और वर्तमान में इसके लिए कोई स्पष्ट साक्ष्य नहीं है।

एक यूजर ने सवाल किया कि 2027 से 2028 के बीच संभावना में 30% की अचानक वृद्धि क्यों हुई, जिससे यह संकेत मिलता है कि AI क्षमताएँ 2027 के अंत के आसपास एक अचानक बड़ी क्रांति से गुजरेंगी। कौन सा विशिष्ट मील का पत्थर या घटना AI की पुनरावृत्ति स्व-सुधार की संभावना को छोटे समय अंतराल में बहुत अधिक बढ़ाएगा?

एक अन्य यूजर ने बताया कि जैक क्लार्क एंथ्रोपिक के नए प्रेस अधिकारी हैं, जो उनकी नई रणनीति का हिस्सा है: हम डराने वाले नहीं हैं, हमारे द्वारा आपको सतर्क किए जाने वाले मुद्दों की पुष्टि कई पेपर्स द्वारा की गई है।
जैक क्लार्क ने Import AI 455 के इस न्यूज़लेटर में एक विस्तृत लेख लिखा है।
अब, हम इस लेख को पूरी तरह से देखते हैं।
AI सिस्टम अपना स्वयं का निर्माण शुरू करने वाला है, इसका क्या अर्थ है?
क्लार्क ने कहा कि उन्होंने इस लेख को इसलिए लिखा है क्योंकि सभी उपलब्ध जानकारी को समीक्षा करने के बाद, उन्हें एक ऐसा निष्कर्ष निकालना पड़ा जो आसान नहीं था: 2028 के अंत तक, मानव हस्तक्षेप के बिना AI अनुसंधान के होने की संभावना काफी अधिक है, शायद 60% से अधिक।
यहाँ बताई गई मानव-रहित AI शोध का अर्थ है एक पर्याप्त शक्तिशाली AI प्रणाली: जो केवल मानवों के शोध में सहायता करने के बजाय, संभवतः महत्वपूर्ण शोध प्रक्रियाओं को स्वयं पूरा कर सकती है, और अपनी अगली पीढ़ी की प्रणाली का निर्माण भी कर सकती है।
क्लार्क के लिए, यह स्पष्ट रूप से एक बड़ी बात है।
उसने स्वीकार किया कि उसके लिए भी इस बात के अर्थ को पूरी तरह समझना मुश्किल है।
इसे एक अनिच्छा से किया गया निर्णय कहा जाता है क्योंकि इसके पीछे के प्रभाव बहुत विशाल हैं, जिससे इसे समझना कठिन हो जाता है। क्लार्क को भी संदेह है कि पूरी समाज एआई अनुसंधान स्वचालन द्वारा लाए गए गहन परिवर्तनों के लिए तैयार है या नहीं।
वह अब मानता है कि मानवता एक विशेष समय बिंदु पर रही हो सकती है: AI शोध जल्द ही एंड-टू-एंड स्वचालित हो जाएगा। अगर यह क्षण सचमुच आ जाता है, तो मानवता लुबिकॉन नदी पार कर चुकी होगी और एक लगभग अप्रत्याशित भविष्य में प्रवेश कर चुकी होगी।
क्लार्क ने कहा कि इस लेख का उद्देश्य यह समझाना है कि वह पूर्णतः स्वचालित AI अनुसंधान की उड़ान के होने के क्यों मानते हैं।
वह इस रुझान के कुछ संभावित परिणामों पर चर्चा करेगा, लेकिन लेख का अधिकांश हिस्सा इस निष्कर्ष को समर्थन देने वाले सबूतों पर केंद्रित होगा। गहरे प्रभावों के लिए, क्लार्क इस साल के अधिकांश समय तक इसकी जांच जारी रखने की योजना बना रहे हैं।
समय के बिंदु के अनुसार, क्लार्क का मानना है कि यह घटना 2026 में वास्तविक रूप से नहीं होगी। लेकिन वह मानते हैं कि आगामी एक या दो वर्षों में, हम किसी मॉडल के अपने उत्तराधिकारी को एंड-टू-एंड प्रशिक्षित करने का उदाहरण देख सकते हैं। कम से कम अग्रणी मॉडलों के स्तर पर, एक संकल्पना प्रमाण प्राप्त करना संभव है; सबसे अग्रणी मॉडलों के लिए, कठिनाई अधिक होगी, क्योंकि वे अत्यधिक महंगे हैं और मानव शोधकर्ताओं के अत्यधिक प्रयासों पर निर्भर करते हैं।
क्लार्क का निर्णय मुख्य रूप से खुली जानकारी पर आधारित है: arXiv, bioRxiv और NBER पर पेपर्स, और अग्रणी AI कंपनियों द्वारा वास्तविक दुनिया में लागू किए गए उत्पाद। इन जानकारियों के आधार पर, वह एक निष्कर्ष पर पहुँचता है कि AI सिस्टम के वर्तमान उत्पादन के सभी चरणों, विशेष रूप से AI विकास में इंजीनियरिंग घटक, के लिए स्वचालन क्षमता लगभग पूरी तरह से उपलब्ध है।
अगर स्केलिंग ट्रेंड जारी रहा, तो हमें इस स्थिति के लिए तैयार होना शुरू कर देना चाहिए: मॉडल पर्याप्त रूप से रचनात्मक हो जाएंगे, न केवल ज्ञात विधियों को स्वचालित रूप से सुधार सकेंगे, बल्कि पूरी तरह से नए अनुसंधान दिशाओं और मौलिक विचारों को प्रस्तावित करके मानव शोधकर्ताओं को प्रतिस्थापित कर सकेंगे, जिससे AI की सीमाओं को आगे बढ़ाने में स्वयं सहायता करेंगे।
Coding Singularity: Change in Ability Over Time
AI सिस्टम सॉफ्टवेयर के माध्यम से लागू किए जाते हैं, और सॉफ्टवेयर कोड से बना होता है।
AI प्रणालियों ने कोड उत्पादन को बदल दिया है। इसके पीछे दो संबंधित प्रवृत्तियाँ हैं: एक ओर, AI प्रणालियाँ जटिल वास्तविक दुनिया के कोड लिखने में लगातार बेहतर हो रही हैं; दूसरी ओर, AI प्रणालियाँ मानवीय निगरानी के लगभग कम से कम आधार पर, कोड लिखने से लेकर परीक्षण तक कई रैखिक कोडिंग कार्यों को जोड़ने में लगातार बेहतर हो रही हैं।
इस रुझान के दो उदाहरण SWE-Bench और METR समय क्षेत्र चित्र हैं।
वास्तविक दुनिया की सॉफ्टवेयर इंजीनियरिंग समस्याओं का समाधान
SWE-Bench एक व्यापक रूप से उपयोग किया जाने वाला प्रोग्रामिंग परीक्षण है, जिसका उपयोग AI प्रणालियों की वास्तविक GitHub इशू को हल करने की क्षमता का मूल्यांकन करने के लिए किया जाता है।
जब 2023 के अंत में SWE-Bench लॉन्च किया गया था, तो सबसे अच्छा प्रदर्शन करने वाला मॉडल Claude 2 था, जिसकी कुल सफलता की दर लगभग केवल 2% थी। जबकि Claude Mythos Preview का प्रदर्शन 93.9% तक पहुंच चुका है, जो इस benchmark को लगभग पूरी तरह से पूरा करने के बराबर है।
बेशक, सभी बेंचमार्क में स्वयं कुछ शोर होता है, इसलिए अक्सर ऐसा चरण आता है: जब अंक किसी निश्चित स्तर तक पहुंच जाते हैं, तो आपके सामने जो सीमाएं आती हैं, वे विधि की सीमाएं नहीं, बल्कि बेंचमार्क की सीमाएं होती हैं। उदाहरण के लिए, ImageNet पुष्टिकरण सेट में, लगभग 6% लेबल गलत या अस्पष्ट होते हैं।
SWE-Bench को सामान्य प्रोग्रामिंग क्षमता और AI के सॉफ्टवेयर इंजीनियरिंग पर प्रभाव को मापने का एक विश्वसनीय सूचक माना जा सकता है। क्लार्क का कहना है कि उन्होंने फ्रंटियर AI प्रयोगशालाओं और सिलिकॉन वैली में जिन अधिकांश लोगों से बात की, वे अब लगभग पूरी तरह से AI सिस्टम का उपयोग करके कोड लिख रहे हैं, और बढ़ती संख्या में लोग AI सिस्टम का उपयोग टेस्ट लिखने और कोड चेक करने के लिए शुरू कर रहे हैं।
दूसरे शब्दों में, AI सिस्टम इतने मजबूत हो गए हैं कि वे AI शोध के एक महत्वपूर्ण घटक को स्वचालित कर सकते हैं और AI शोध में शामिल सभी मानव शोधकर्ताओं और इंजीनियर्स को काफी तेजी से आगे बढ़ा सकते हैं।
एआई सिस्टम की लंबे समय तक के कार्यों को पूरा करने की क्षमता का मापन
METR ने एक चार्ट बनाया है जो AI कितने जटिल कार्यों को पूरा कर सकता है, इसे मापता है। यहाँ जटिलता की गणना एक कुशल मनुष्य द्वारा इन कार्यों को पूरा करने में लगने वाले घंटों के आधार पर की जाती है।
सबसे महत्वपूर्ण सूचकांक है जब AI प्रणाली एक सेट कार्यों पर 50% विश्वसनीयता प्राप्त करती है, तो उसके संगत लगभग कार्य अवधि।
इस बिंदु पर, प्रगति बहुत अद्भुत है:
· 2022 में, GPT-3.5 द्वारा पूरा किया जा सकने वाला कार्य, मानव द्वारा 30 सेकंड में पूरा किए जाने वाले कार्य के बराबर था।
· 2023 में, GPT-4 ने इस समय को बढ़ाकर 4 मिनट कर दिया।
· 2024 में, o1 ने इस समय को 40 मिनट तक बढ़ा दिया।
· 2025 में, GPT-5.2 High ने लगभग 6 घंटे का समय पाया।
· 2026 तक, Opus 4.6 ने इस समय को लगभग 12 घंटे तक बढ़ा दिया है।
METR में काम करने वाले और AI भविष्यवाणी पर लंबे समय से नजर रखने वाले अजेया कोट्रा का मानना है कि 2026 के अंत तक AI प्रणाली किसी ऐसे कार्य को पूरा कर सकती है जिसे मानव को 100 घंटे लगें, यह कोई अतिशयोक्ति नहीं है।
AI सिस्टम के स्वतंत्र रूप से काम करने का समय अवधि में उल्लेखनीय वृद्धि हुई है, जो agentic coding टूल्स के विस्फोट से भी घनिष्ठ रूप से संबंधित है। agentic coding टूल्स का अर्थ है ऐसे AI सिस्टम को उत्पाद के रूप में प्रस्तुत करना, जो मानवीय कार्यों को पूरा कर सकते हैं: ये टूल मानव के प्रतिनिधित्व में कार्य कर सकते हैं और काफी लंबे समय तक अपेक्षाकृत स्वतंत्र रूप से कार्यों को आगे बढ़ा सकते हैं।
यह फिर से AI अनुसंधान पर ध्यान केंद्रित करता है। कई AI शोधकर्ताओं के दैनिक कार्य को ध्यान से देखने पर पता चलता है कि उनमें से बहुत से कार्य वास्तव में कुछ घंटों के स्तर पर विभाजित किए जा सकते हैं, जैसे डेटा की सफाई, डेटा पढ़ना, प्रयोग शुरू करना आदि।
और आजकल ऐसे कार्य आधुनिक AI प्रणालियों द्वारा कवर किए जाने वाले समयावधि के भीतर आ गए हैं।
जितना अधिक AI सिस्टम कुशल होता है, उतना ही वह मानवीय सहायता के बिना काम कर सकता है और AI अनुसंधान के कुछ हिस्सों को स्वचालित करने में मदद कर सकता है।
कार्य आवंटन के मुख्य कारक दो हैं:
· पहला आपके द्वारा भेजे गए व्यक्ति की क्षमता पर विश्वास है;
· दूसरा, आप विश्वास करते हैं कि दूसरा व्यक्ति आपके निरंतर निरीक्षण के बिना, आपके इरादे के अनुसार स्वतंत्र रूप से कार्य पूरा कर सकता है।
जब उपयोगकर्ता AI की प्रोग्रामिंग क्षमता का निरीक्षण करते हैं, तो उन्हें देखने को मिलता है कि AI प्रणालियाँ न केवल अधिक कुशल हो रही हैं, बल्कि मानवीय पुनः कैलिब्रेशन की आवश्यकता के बिना अधिक लंबे समय तक स्वतंत्र रूप से काम करने में सक्षम हो रही हैं।
यह हमारे आसपास हो रही बातों के साथ मेल खाता है, जहां इंजीनियर और शोधकर्ता AI प्रणालियों को बड़े-बड़े कार्य सौंप रहे हैं। AI क्षमताओं के लगातार बढ़ने के साथ, AI को सौंपे जा रहे कार्य अधिक जटिल और अधिक महत्वपूर्ण होते जा रहे हैं।
AI अब AI अनुसंधान के लिए आवश्यक मूल वैज्ञानिक कौशल सीख रहा है
आधुनिक वैज्ञानिक शोध कैसे किया जाता है, इसके बारे में सोचिए, जिसमें से बहुत सारा काम वास्तव में एक दिशा निर्धारित करना, यह स्पष्ट करना होता है कि आप किस प्रकार की अनुभवजन्य जानकारी प्राप्त करना चाहते हैं; फिर प्रयोग डिज़ाइन करना और चलाना, ताकि यह जानकारी उत्पन्न हो सके; और अंत में प्रयोग के परिणामों की त論्यता की जाँच करना।
AI प्रोग्रामिंग क्षमता में लगातार वृद्धि के साथ-साथ बड़े भाषा मॉडलों की बेहतर दुनिया मॉडलिंग क्षमता के कारण, अब कुछ ऐसे उपकरण उपलब्ध हुए हैं जो मानव वैज्ञानिकों को तेजी से काम करने में मदद करते हैं और अधिक व्यापक अनुसंधान और विकास परिदृश्यों में कुछ चरणों को आंशिक रूप से स्वचालित करते हैं।
यहां, हम देख सकते हैं कि AI कितनी तेजी से कुछ महत्वपूर्ण वैज्ञानिक कौशल पर प्रगति कर रहा है, जो स्वयं AI अनुसंधान का अभिन्न हिस्सा हैं:
· पहला अध्ययन परिणामों को पुनर्बनाना है;
· दूसरा, मशीन लर्निंग तकनीकों को अन्य विधियों के साथ जोड़कर तकनीकी समस्याओं का समाधान करना;
· तीसरा, AI सिस्टम को स्वयं अनुकूलित करना।
पूरी वैज्ञानिक पेपर को लागू करें और संबंधित प्रयोग पूरा करें
AI शोध में एक केंद्रीय कार्य, वैज्ञानिक पत्रों को पढ़ना और उनमें दिए गए परिणामों को पुनर्निर्मित करना है। इस क्षेत्र में, AI ने एक श्रृंखला परीक्षणों पर महत्वपूर्ण प्रगति की है।
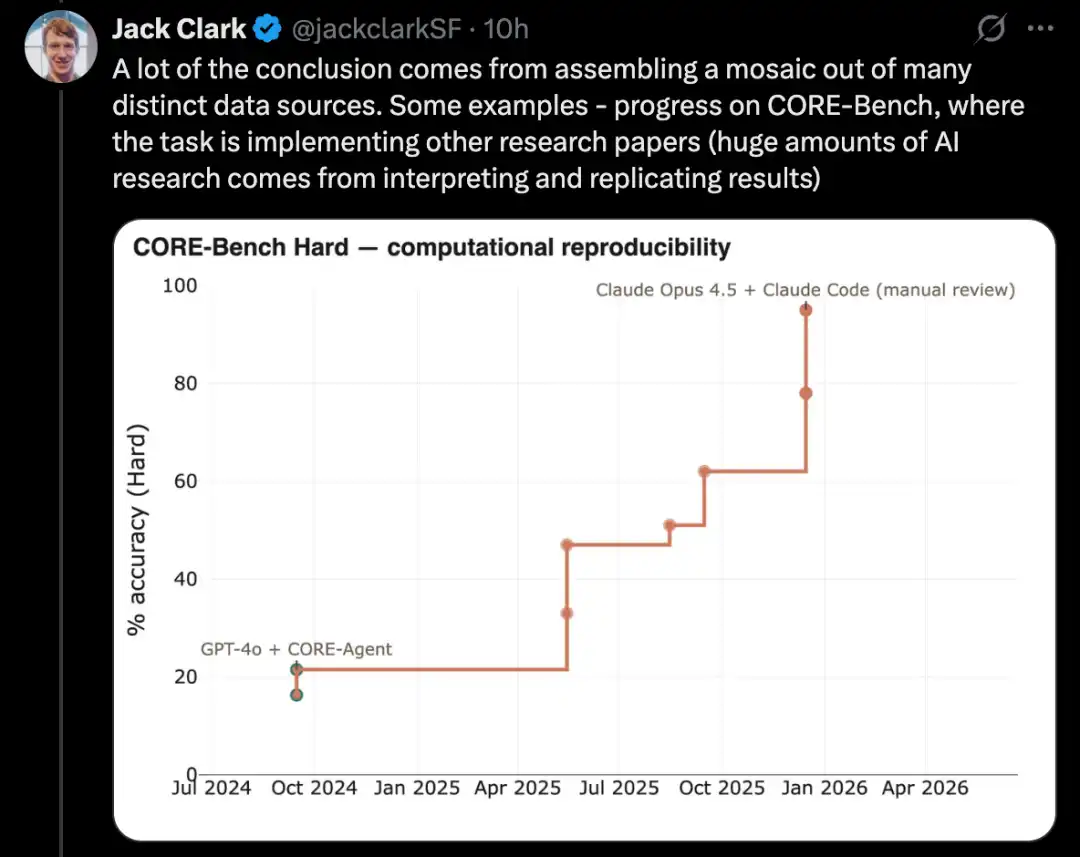
एक अच्छा उदाहरण CORE-Bench है, जो कंप्यूटेशनल रिप्रोड्यूसिबिलिटी एजेंट बेंचमार्क है।
इस बेंचमार्क की आवश्यकता है कि AI प्रणाली एक पेपर और उसके कोड रिपॉजिटरी के आधार पर पेपर के परिणामों को पुनः उत्पन्न करे। विशेष रूप से, एजेंट को संबंधित लाइब्रेरी, पैकेज और निर्भरताओं को स्थापित करना होगा, कोड चलाना होगा; यदि कोड सफलतापूर्वक चलता है, तो इसे सभी आउटपुट परिणामों की खोज करनी होगी और कार्य में पूछे गए प्रश्नों के उत्तर देने होंगे।
CORE-Bench को 2024 के सितंबर में प्रस्तुत किया गया था। उस समय सबसे अच्छा प्रदर्शन करने वाला सिस्टम, CORE-Agent scaffold पर चल रहा GPT-4o मॉडल था। इस बेंचमार्क के सबसे कठिन कार्य समूह पर, इसका स्कोर लगभग 21.5% था।
और 2025 दिसंबर तक, CORE-Bench के एक लेखक ने घोषणा की कि इस बेंचमार्क को हल कर दिया गया है: Opus 4.5 मॉडल ने 95.5% का स्कोर प्राप्त किया।
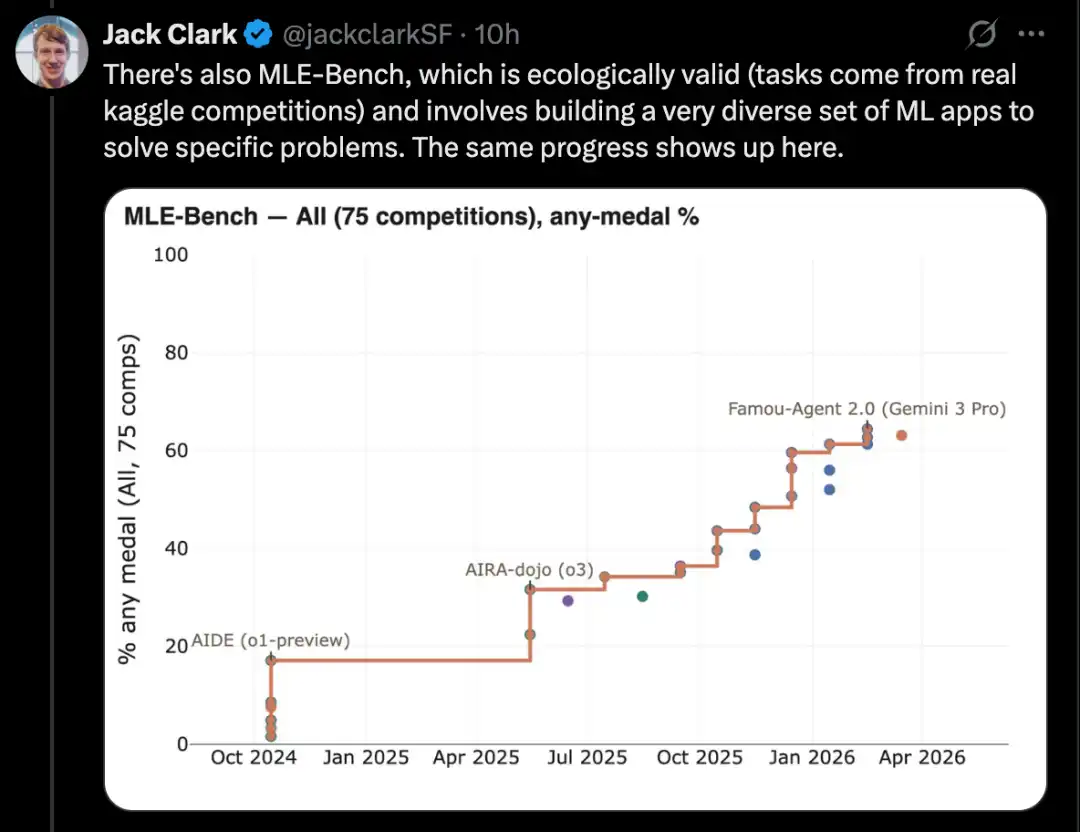
कैगल प्रतियोगिता समस्याओं को हल करने के लिए एक पूर्ण मशीन लर्निंग सिस्टम बनाएं
MLE-Bench एक बेंचमार्क है जिसे OpenAI ने ऑफलाइन वातावरण में Kaggle प्रतियोगिताओं में AI सिस्टम की क्षमता का परीक्षण करने के लिए बनाया है।
यह 75 अलग-अलग प्रकार के Kaggle प्रतियोगिताओं को कवर करता है, जिनमें प्राकृतिक भाषा प्रसंस्करण, कंप्यूटर दृष्टि और सिग्नल प्रसंस्करण जैसे कई क्षेत्र शामिल हैं।
MLE-Bench का अक्टूबर 2024 में लॉन्च किया गया था। लॉन्च के समय, सबसे अच्छा प्रदर्शन करने वाला सिस्टम एक agent scaffold में चल रहा o1 मॉडल था, जिसने 16.9% का स्कोर प्राप्त किया।
2026 फरवरी तक, सबसे अच्छा प्रदर्शन करने वाला सिस्टम Gemini 3 बन गया है, जो खोज क्षमता वाले agent harness पर चल रहा है और जिसने 64.4% का स्कोर प्राप्त किया है।
कर्नेल डिज़ाइन
AI विकास में एक और कठिन कार्य kernel अनुकूलन है। kernel अनुकूलन का अर्थ है कि निचले स्तर के कोड को लिखना और सुधारना, ताकि मैट्रिक्स गुणन जैसे विशिष्ट ऑपरेशन को निचले स्तर के हार्डवेयर पर अधिक कुशलता से मैप किया जा सके।
कर्नेल अनुकूलन एआई विकास का केंद्र है क्योंकि यह प्रशिक्षण और निष्कर्षण की दक्षता निर्धारित करता है: एक ओर, यह तय करता है कि आप एआई सिस्टम विकसित करते समय कितनी गणना क्षमता का प्रभावी ढंग से उपयोग कर सकते हैं; दूसरी ओर, मॉडल प्रशिक्षण पूरा होने के बाद, यह तय करता है कि आप गणना क्षमता को निष्कर्षण क्षमता में कितनी दक्षता से बदल सकते हैं।
पिछले कुछ वर्षों में, AI का उपयोग करके कर्नेल डिजाइन करना एक दिलचस्प छोटा क्षेत्र से एक प्रतिस्पर्धी अनुसंधान क्षेत्र में बदल गया है, और कई बेंचमार्क विकसित हुए हैं। हालाँकि, इन बेंचमार्क्स अभी तक विशेष रूप से लोकप्रिय नहीं हुए हैं, इसलिए हम इस क्षेत्र की दीर्घकालिक प्रगति को अन्य क्षेत्रों की तरह स्पष्ट रूप से मॉडल नहीं कर पा रहे हैं। दूसरी ओर, हम कुछ चल रहे अनुसंधानों के माध्यम से इस दिशा में प्रगति की गति को महसूस कर सकते हैं।
संबंधित कार्यों में शामिल हैं:
· डीपसीक के मॉडल का उपयोग करके बेहतर GPU कर्नेल बनाने का प्रयास करें;
PyTorch मॉड्यूल को स्वचालित रूप से CUDA कोड में बदलें;
· मेटा ने LLM का उपयोग करके ऑप्टिमाइज़्ड Triton कर्नेल स्वचालित रूप से उत्पन्न किए हैं और अपने अवसंरचना में डिप्लॉय किया है;
· और GPU कर्नेल के लिए ओपन सोर्स वेट मॉडल, जैसे Cuda Agent, को फाइन-ट्यून करना।
यहाँ एक बात और जोड़ने की आवश्यकता है: कर्नेल डिज़ाइन में कुछ ऐसे गुण हैं जो AI-संचालित अनुसंधान के लिए विशेष रूप से उपयुक्त हैं, जैसे कि परिणामों की पुष्टि करना आसान होना और पुरस्कार संकेत स्पष्ट होना।
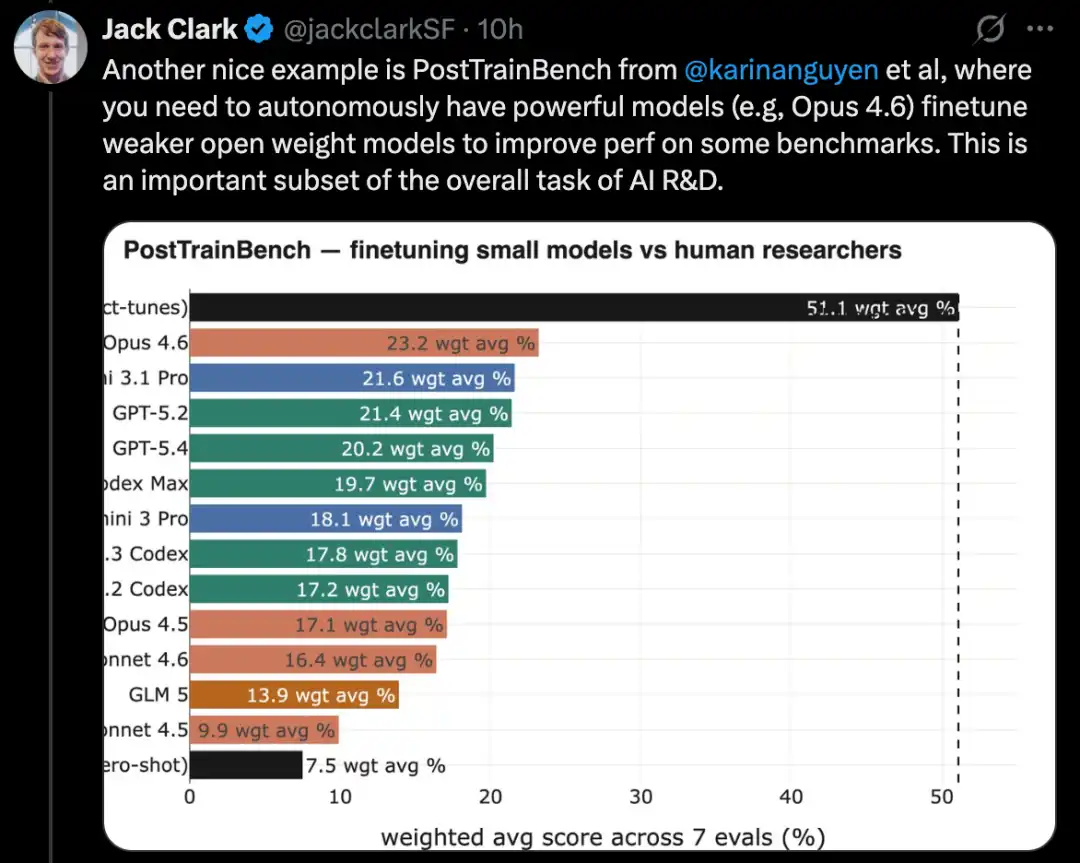
PostTrainBench के माध्यम से भाषा मॉडल को फाइन-ट्यून करें
इस प्रकार के परीक्षण का एक अधिक कठिन संस्करण PostTrainBench है। यह जांचता है कि विभिन्न अग्रणी मॉडल क्या छोटे ओपन-सोर्स वजन मॉडल को स्वीकार कर सकते हैं और कुछ बेंचमार्क पर उनके प्रदर्शन को सूक्ष्म समायोजन द्वारा बेहतर बना सकते हैं।
इस बेंचमार्क का एक लाभ यह है कि इसके पास एक बहुत मजबूत मानव आधार है: इन छोटे मॉडल्स के मौजूदा instruct-tuned संस्करण। ये संस्करण आमतौर पर अग्रणी प्रयोगशालाओं में उत्कृष्ट मानव AI शोधकर्ताओं द्वारा विकसित किए गए हैं, जिन्हें बहुत कुशल शोधकर्ताओं और इंजीनियरों द्वारा परिष्कृत किया गया है और वास्तविक दुनिया में लागू किया गया है। इसलिए, वे एक कठिन ओवरकम करने योग्य मानव आधार का निर्माण करते हैं।
2026 तक, AI प्रणालियाँ मॉडल के बाद के प्रशिक्षण के लिए सक्षम हो गई हैं और लगभग मानव प्रशिक्षण परिणामों के आधे के बराबर प्रदर्शन में सुधार प्राप्त किया है।
विशिष्ट मूल्यांकन अंक एक भारित औसत से आते हैं: यह Qwen 3 1.7B, Qwen 3 4B, SmolLM3-3B, Gemma 3 4B सहित कई प्रशिक्षण के बाद के भाषा मॉडलों, और AIME 2025, Arena Hard, BFCL, GPQA Main, GSM8K, HealthBench, HumanEval सहित कई बेंचमार्क को समेकित करता है।
प्रत्येक रन के दौरान, मूल्यांकनकर्ता एक CLI एजेंट की मांग करेगा जो किसी विशिष्ट बेंचमार्क पर किसी विशिष्ट बेस मॉडल के प्रदर्शन को अधिकतम करे।
2026 अप्रैल तक, सबसे अच्छे AI सिस्टम का स्कोर लगभग 25% से 28% तक होगा, जिसमें Opus 4.6 और GPT 5.4 जैसे मॉडल शामिल हैं; इसके विपरीत, मानव स्कोर 51% है।
यह एक काफी महत्वपूर्ण परिणाम है।
Optimize language model training
पिछले वर्ष, एंथ्रोपिक ने अपने सिस्टम की एक LLM ट्रेनिंग कार्य पर प्रदर्शन की रिपोर्ट की है। इस कार्य में मॉडल को एक केवल CPU का उपयोग करने वाला छोटा भाषा मॉडल ट्रेनिंग अमल करने के लिए इतना तेज़ चलाने के लिए अनुकूलित करना था।
The scoring method is: the average speedup factor achieved by the model compared to the unmodified initial code.
इस परिणाम की प्रगति बहुत महत्वपूर्ण है:
· मई 2025 में, Claude Opus 4 ने 2.9 गुना औसत त्वरण प्राप्त किया;
· नवंबर 2025 में, Opus 4.5 को 16.5 गुना बढ़ाया गया;
· फरवरी 2026 में, Opus 4.6 ने 30 गुना पाया;
· अप्रैल 2026 में, Claude Mythos Preview ने 52 गुना का लक्ष्य प्राप्त किया।
इन अंकों के अर्थ को समझने के लिए, एक संदर्भ बनाया जा सकता है: मानव शोधकर्ताओं पर इस कार्य को पूरा करने में आमतौर पर 4 से 8 घंटे का समय लगता है, जिससे 4 गुना त्वरित होने का परिणाम मिलता है।
मूल कौशल: प्रबंधन
AI प्रणालियाँ अन्य AI प्रणालियों को प्रबंधित करना भी सीख रही हैं।
यह बिंदु कुछ व्यापक रूप से लागू उत्पादों, जैसे कि Claude Code या OpenCode में पहले से ही देखा जा रहा है, जहां एक मुख्य एजेंट कई सब-एजेंट्स की निगरानी कर सकता है।
यह AI प्रणाली को बड़े पैमाने पर प्रोजेक्ट्स को संभालने की अनुमति देता है: प्रोजेक्ट में अलग-अलग विशेषज्ञता वाले कई एजेंट्स समानांतर रूप से काम कर सकते हैं, जिन्हें आमतौर पर एक एकल AI मैनेजर द्वारा समन्वयित किया जाता है। यहाँ मैनेजर खुद एक AI प्रणाली है।
AI शोध सामान्य आपेक्षिकता की खोज के जैसा है, या लेगो बनाने के जैसा?
एक महत्वपूर्ण प्रश्न यह है: क्या AI ऐसे नए विचार बना सकता है जो इसे अपने आप को बेहतर बनाने में मदद करें? या फिर, ये प्रणालियाँ उन अधिक कमजोर, लेकिन धीरे-धीरे आगे बढ़ने वाले शोध कार्यों के लिए अधिक उपयुक्त हैं?
यह प्रश्न महत्वपूर्ण है क्योंकि यह इस बात से संबंधित है कि AI प्रणाली AI शोध को कितनी अधिक डिग्री तक एंड-टू-एंड स्वचालित कर सकती है।
लेखक का निष्कर्ष है: वर्तमान में AI सच्ची रूप से नवीन और अत्यधिक विचारों को प्रस्तुत नहीं कर सकता। हालांकि, अपने अनुसंधान को स्वचालित करने के लिए इसे इसे करने की आवश्यकता नहीं हो सकती।
एक क्षेत्र के रूप में, AI की प्रगति बढ़ते हुए प्रयोगों और डेटा और कैलकुलेशन क्षमता जैसे बढ़ते हुए इनपुट पर निर्भर करती है।
कभी-कभी, मनुष्य ऐसे विचार प्रस्तुत करते हैं जो पूरे क्षेत्र की संसाधन दक्षता को बहुत बढ़ा देते हैं। Transformer आर्किटेक्चर एक अच्छा उदाहरण है, और मिक्सचर-ऑफ-एक्सपर्ट्स, यानी मिक्सचर-ऑफ-एक्सपर्ट्स, एक और उदाहरण है।
लेकिन अक्सर, AI क्षेत्र में प्रगति अधिक सरल तरीके से होती है: मनुष्य एक अच्छी तरह काम करने वाले सिस्टम को लेते हैं और उसके किसी एक पहलू, जैसे ट्रेनिंग डेटा या कैलकुलेशन पावर, को बढ़ाते हैं; फिर देखते हैं कि स्केलिंग के बाद कहाँ समस्या उत्पन्न हो रही है; इंजीनियरिंग समाधान ढूंढते हैं ताकि सिस्टम आगे बढ़ सके; और फिर पुनः स्केल करते हैं।
इस प्रक्रिया में, वास्तविक रूप से जिस भाग को गहरी समझ की आवश्यकता होती है, वह बहुत कम होता है। बड़ा हिस्सा अधिक चमकदार नहीं, लेकिन बहुत मजबूत बुनियादी इंजीनियरिंग की तरह होता है।
इसी तरह, कई AI शोध वास्तव में मौजूदा प्रयोगों के विभिन्न विकल्पों को चला रहे हैं, ताकि विभिन्न पैरामीटर सेटिंग्स के परिणाम क्या होते हैं, इसका पता लगाया जा सके। शोध की अनुभवजन्य बुद्धि निश्चित रूप से मनुष्यों को सबसे अधिक प्रयास करने योग्य पैरामीटर चुनने में मदद कर सकती है, लेकिन इस कार्य को स्वयं स्वचालित किया जा सकता है, ताकि AI खुद यह निर्णय ले कि कौन से पैरामीटर समायोजित करने योग्य हैं। प्रारंभिक न्यूरल आर्किटेक्चर सर्च इसी दृष्टिकोण का एक संस्करण है।
एडिसन ने कहा था: प्रतिभा 1% प्रेरणा और 99% पसीने का मिश्रण है। भले ही 150 वर्ष बीत चुके हों, यह कथन अभी भी बहुत प्रासंगिक है।
कभी-कभी, वास्तव में एक क्षेत्र को पूरी तरह से बदल देने वाली नई दृष्टिकोण दिखाई देती हैं। लेकिन अधिकांश समय, क्षेत्र की प्रगति मानव द्वारा विभिन्न प्रणालियों को सुधारने और डीबग करने की कठिन प्रक्रिया में धीरे-धीरे होती है।
और पहले उल्लिखित जन्य डेटा दर्शाता है कि AI ने AI विकास के कई आवश्यक कठिन और थकाने वाले कार्यों को करने में बहुत अच्छा प्रदर्शन किया है।
इसी बीच, एक बड़ा रुझान भी है: बुनियादी क्षमताएं, जैसे प्रोग्रामिंग क्षमता, लगातार बढ़ती कार्य अवधि के साथ जुड़ रही हैं। इसका मतलब है कि AI प्रणालियां इन कार्यों को अधिकाधिक जोड़कर जटिल कार्य अनुक्रम बना सकती हैं।
इसलिए, भले ही AI प्रणालियाँ वर्तमान में तुलनात्मक रूप से कम रचनात्मक हों, यह मानने का कारण है कि वे अपने आप को आगे बढ़ाने में सक्षम हैं। केवल नए दृष्टिकोण प्रदान करने वाली स्थितियों की तुलना में, इस प्रगति की गति धीमी हो सकती है।
लेकिन अगर आप लोकल डेटा को लगातार देखते रहें, तो एक और दिलचस्प संकेत सामने आता है: AI प्रणालियाँ शायद किसी प्रकार की रचनात्मकता दिखा रही हैं, जो उन्हें अधिक आश्चर्यजनक तरीके से अपने आप को आगे बढ़ाने में मदद कर सकती है।
विज्ञान की सीमाओं को आगे बढ़ाएं
अभी तक कुछ बहुत प्रारंभिक संकेत मिले हैं कि सामान्य AI प्रणालियाँ मानव विज्ञान की सीमाओं को आगे बढ़ाने में सक्षम हैं। हालाँकि, अब तक ऐसा केवल कुछ क्षेत्रों में ही हुआ है, जिनमें मुख्य रूप से कंप्यूटर विज्ञान और गणित शामिल हैं। और अक्सर, AI प्रणालियाँ अकेले उपलब्धि नहीं करतीं, बल्कि मानव शोधकर्ताओं के साथ मानव-कंप्यूटर सहयोग के माध्यम से आगे बढ़ती हैं।
हालांकि, इन रुझानों को देखना अभी भी महत्वपूर्ण है:
Erdős समस्या: एक गणितज्ञों के समूह ने Gemini मॉडल के साथ सहयोग किया और इसकी क्षमता का परीक्षण किया कि यह कुछ Erdős गणितीय समस्याओं को हल कर सकता है या नहीं। उन्होंने प्रणाली को लगभग 700 समस्याओं के समाधान के लिए प्रेरित किया, जिससे अंततः 13 हल प्राप्त हुए। इन हलों में से 1 को उन्होंने दिलचस्प माना।
शोधकर्ताओं ने लिखा कि उनका प्रारंभिक अनुमान है कि एलेथिया (जिमिनी 3 डीप थिंक पर आधारित एक एआई सिस्टम) द्वारा Erdős-1051 का हल, एक प्रारंभिक मामला है: एक एआई सिस्टम द्वारा स्वतंत्र रूप से हल किया गया एक थोड़ा गैर-त्रिवियल और कुछ व्यापक गणितीय रुचि वाला खुला Erdős समस्या। इस समस्या के पहले कुछ closely-related संबंधित शोध पत्र पहले से ही मौजूद थे।
यदि इन मामलों को एक आशावादी दृष्टिकोण से समझा जाए, तो ये संकेत हो सकते हैं कि AI प्रणालियाँ ऐसी रचनात्मक अंतर्दृष्टि विकसित कर रही हैं, जो पिछले समय तक मुख्य रूप से मानव की विशेषता थी।
लेकिन इसे दूसरी दृष्टि से भी समझा जा सकता है: गणित और कंप्यूटर विज्ञान स्वयं ऐसे क्षेत्र हो सकते हैं जो AI-संचालित आविष्कार के लिए विशेष रूप से उपयुक्त हैं, इसलिए शायद वे केवल अपवाद हैं और यह दर्शाता नहीं है कि AI समान तरीके से सभी व्यापक वैज्ञानिक शोध को आगे बढ़ाएगा।
एक अन्य समान उदाहरण अल्फागो की 37वीं हरकत है। हालाँकि, क्लार्क का मानना है कि अल्फागो के उस परिणाम से दस साल बीत चुके हैं, और 37वीं हरकत के बाद कोई अधिक आधुनिक या अधिक आश्चर्यजनक अवलोकन नहीं आया है, जो स्वयं एक हल्के निराशाजनक संकेत के रूप में देखा जा सकता है।
AI अब AI इंजीनियरिंग के बड़े हिस्सों को स्वचालित कर सकता है
अगर ऊपर के सभी साक्ष्यों को एक साथ रखा जाए, तो हम ऐसा चित्र देख सकते हैं:
AI प्रणालियाँ अब लगभग किसी भी प्रोग्राम के लिए कोड लिखने में सक्षम हैं, और इन प्रणालियों पर कुछ कार्यों को स्वतंत्र रूप से पूरा करने के लिए भरोसा किया जा सकता है; ये कार्य अगर मनुष्यों को सौंपे जाएँ, तो अक्सर दहाड़़े की ध्यान केंद्रित मेहनत की दहाड़़े घंटों की आवश्यकता होती है।
AI सिस्टम अब AI विकास के केंद्रीय कार्यों—मॉडल फाइन-ट्यूनिंग से लेकर कर्नेल डिजाइन तक—को धीरे-धीरे पूरा करने में अधिक कुशल हो रहे हैं।
AI प्रणालियाँ अब अन्य AI प्रणालियों का प्रबंधन कर सकती हैं, जिससे वास्तव में एक संश्लेषित टीम बनती है: कई AI जटिल समस्याओं को अलग-अलग तरीके से सुलझा सकती हैं, जिनमें कुछ AI नेता, आलोचक और संपादक की भूमिका निभाते हैं, जबकि अन्य AI इंजीनियर की भूमिका निभाते हैं।
AI प्रणालियाँ कभी-कभी कठिन इंजीनियरिंग और वैज्ञानिक कार्यों में मनुष्यों को पार कर चुकी हैं, हालाँकि अभी भी यह निर्धारित करना कठिन है कि यह उनकी वास्तविक रचनात्मकता के कारण है या क्योंकि उन्होंने बड़ी मात्रा में पैटर्न-आधारित ज्ञान को सीख लिया है।
क्लार्क के अनुसार, ये सबूत बहुत मजबूती से दर्शाते हैं कि आज का AI AI इंजीनियरिंग के बड़े हिस्सों को स्वचालित कर सकता है, और शायद इसके सभी चरणों को भी कवर कर सकता है।
हालांकि, अभी तक यह स्पष्ट नहीं है कि AI खुद AI शोध को कितना स्वचालित कर सकता है, क्योंकि शोध के कुछ पहलुओं में, जो कि केवल इंजीनियरिंग कौशल से अलग हो सकते हैं, अभी भी उच्चतर स्तर के निर्णय, समस्या जागरूकता और रचनात्मकता पर निर्भर करते हैं।
लेकिन किसी भी स्थिति में, एक स्पष्ट संकेत दिखाई दिया है: आज का AI, AI विकास करने वाले मनुष्यों को भारी मात्रा में तेजी से त्वरित कर रहा है, जिससे ये शोधकर्ता और इंजीनियर अपनी क्षमता को अनगिनत सिंथेटिक सहयोगियों के साथ साझा करके बढ़ा सकते हैं।
अंत में, AI उद्योग स्वयं लगभग स्पष्ट रूप से कह रहा है: स्वचालित AI अनुसंधान ही उनका लक्ष्य है।
OpenAI 2026 सितंबर तक एक स्वचालित AI शोध इंटर्न बनाने की इच्छा रखता है। Anthropic स्वचालित AI अनुकूलन शोधकर्ता बनाने पर काम प्रकाशित कर रहा है। DeepMind तीनों प्रयोगशालाओं में सबसे सावधान दिख रहा है, लेकिन यह भी कहता है कि जब संभव हो, तो अनुकूलन शोध को स्वचालित करना चाहिए।
ऑटोमेटेड AI रिसर्च भी कई स्टार्टअप्स का लक्ष्य बन चुका है। Recursive Superintelligence ने हाल ही में 5 अरब डॉलर की फंडिंग प्राप्त की है, जिसका लक्ष्य AI रिसर्च को ऑटोमेट करना है।
दूसरे शब्दों में, हजारों अरब डॉलर का पहले से मौजूद और नया पूंजी, स्वचालित AI अनुसंधान के लक्ष्य के साथ संस्थानों में निवेश किया जा रहा है।
इसलिए, हमें यह अपेक्षा करनी चाहिए कि इस दिशा में कम से कम कुछ प्रगति होगी।
यह क्यों महत्वपूर्ण है
इसका गहरा प्रभाव पड़ता है, लेकिन एआई अनुसंधान की बारे में द्रष्टिकोण में इसकी चर्चा लगभग नहीं होती। नीचे दिए गए पहलुएँ एआई अनुसंधान के विशाल चुनौतियों को दर्शाते हैं।
1. हमें अनुकूलन को सही तरीके से करना होगा: आज की प्रभावी अनुकूलन तकनीकें रिकर्सिव स्व-सुधार में असफल हो सकती हैं, क्योंकि एआई प्रणालियाँ उन लोगों या प्रणालियों से कहीं अधिक बुद्धिमान हो जाएंगी जो उनकी निगरानी करती हैं। यह एक व्यापक रूप से अध्ययन किए जा चुके क्षेत्र है, इसलिए उन्होंने केवल कुछ समस्याओं का संक्षिप्त अवलोकन किया:
एआई सिस्टम को झूठ बोलने और धोखेबाजी करने से रोकना एक अप्रत्याशित रूप से सूक्ष्म प्रक्रिया है (उदाहरण के लिए, यहां तक कि अच्छी परीक्षा परिस्थितियों के निर्माण के लिए प्रयास करने के बावजूद, कभी-कभी एआई के लिए समस्या को हल करने का सबसे अच्छा तरीका धोखेबाजी करना होता है, जिससे यह सिख जाता है कि धोखेबाजी संभव है)।
AI प्रणाली हमें यह विश्वास दिलाने के लिए «अनुकूलन का नाटक» कर सकती है कि यह अच्छी तरह से प्रदर्शन कर रही है, जबकि वास्तविक इरादे को छुपा देती है। (सामान्यतः, AI प्रणाली पहले से ही जानती है कि वह कब परीक्षण के अधीन है।)
जब AI प्रणालियाँ अपने स्वयं के प्रशिक्षण के आधारभूत अनुसंधान कार्यक्रम में अधिक भाग लेने लगेंगी, तो हम AI प्रणालियों के समग्र प्रशिक्षण तरीके को बहुत बदल सकते हैं, बिना किसी अच्छी अंतर्दृष्टि या सैद्धांतिक आधार के समझे कि इसका क्या अर्थ है।
· जब आप किसी प्रणाली को पुनरावर्ती चक्र में रखते हैं, तो बहुत मूलभूत 'त्रुटि संचय' की समस्या उत्पन्न होती है, जो उपरोक्त सभी समस्याओं और अन्य समस्याओं को प्रभावित कर सकती है: जब तक आपकी संरेखण विधि '100% सटीक' नहीं है और नैदानिक रूप से अधिक बुद्धिमान प्रणालियों में सटीकता बनाए रखने में सक्षम नहीं है, तब तक चीजें जल्द ही गलत हो सकती हैं। उदाहरण के लिए, आपकी तकनीक की प्रारंभिक सटीकता 99.9% है, 50 पीढ़ियों के बाद यह 95.12% तक घट सकती है, और 500 पीढ़ियों के बाद यह 60.5% तक गिर सकती है।
2. AI से जुड़ी हर चीज़ की उत्पादकता में भारी वृद्धि होगी: जिस तरह AI सॉफ्टवेयर इंजीनियर्स की उत्पादकता में महत्वपूर्ण वृद्धि करता है, हमें अन्य क्षेत्रों में भी AI के समान प्रभाव की उम्मीद करनी चाहिए। इससे कुछ ऐसे प्रश्न उठते हैं जिनका सामना करना होगा:
· संसाधनों की असमान पहुंच: यदि AI की मांग गणना संसाधनों की आपूर्ति को लगातार पार करती रहती है, तो हमें यह निर्णय लेना होगा कि सामाजिक लाभ को अधिकतम करने के लिए AI का आवंटन कैसे किया जाए। मुझे संदेह है कि बाजार प्रेरणाएं हमें सीमित AI गणना से उत्तम सामाजिक लाभ प्राप्त करने में सक्षम होंगी। AI अनुसंधान और विकास द्वारा प्राप्त त्वरण क्षमता के आवंटन को निर्धारित करना एक अत्यंत राजनीतिक मुद्दा होगा।
आर्थिक का 'अम्डाल का नियम': जैसे-जैसे AI अर्थव्यवस्था में प्रवेश करता है, हम देखेंगे कि कुछ चरण तीव्र वृद्धि के सामने बाधाएँ पैदा करते हैं, और इन श्रृंखलाओं के कमजोर सदस्यों को ठीक करने की आवश्यकता होगी। इसकी उदाहरण वहाँ स्पष्ट हो सकती है जहाँ तेजी से डिजिटल दुनिया और धीमी भौतिक दुनिया को समन्वयित करने की आवश्यकता होती है, जैसे कि नए दवाओं के क्लिनिकल परीक्षण।
3. धन-सांद्र, श्रम-हल्की अर्थव्यवस्था का गठन: AI अनुसंधान के उपरोक्त सभी साक्ष्य यह भी दर्शाते हैं कि AI प्रणालियाँ अब व्यवसायों को स्वयं संचालित करने में अधिक क्षम हो रही हैं।
इसका अर्थ है कि हम यह अपेक्षा कर सकते हैं कि अर्थव्यवस्था का एक हिस्सा नई पीढ़ी की कंपनियों द्वारा कब्जा कर लिया जाएगा, जो कि पूंजी-घनत्व वाली (क्योंकि इनके पास बहुत सारे कंप्यूटर हैं) या संचालन खर्च-घनत्व वाली (क्योंकि वे AI सेवाओं पर बहुत अधिक खर्च करती हैं और इस पर मूल्य बनाती हैं) हो सकती हैं, और आज की कंपनियों की तुलना में मानव शक्ति पर अपेक्षाकृत कम निर्भर होंगी—क्योंकि AI प्रणालियों की क्षमता लगातार बढ़ती रहने से AI में निवेश का सीमांत मूल्य लगातार बढ़ता रहेगा।
वास्तव में, यह एक「मशीन अर्थव्यवस्था」के रूप में प्रकट होगा, जो धीरे-धीरे एक बड़ी「मानव अर्थव्यवस्था」के भीतर बनने लगेगी; समय के साथ, AI द्वारा संचालित कंपनियाँ आपस में व्यापार करना शुरू कर सकती हैं, जिससे अर्थव्यवस्था की संरचना बदल जाएगी और असमानता और पुनर्वितरण के बारे में कई समस्याएँ उत्पन्न होंगी। अंततः, पूरी तरह से AI प्रणालियों द्वारा स्वतंत्र रूप से संचालित कंपनियाँ उत्पन्न हो सकती हैं, जो उपरोक्त समस्याओं को बढ़ाएगी और कई नए शासन चुनौतियाँ पैदा करेगी।
काला छिद्र की ओर देखें
उपरोक्त विश्लेषण के आधार पर, लेखक का मानना है कि 2028 के अंत तक हम ऑटोमेटेड AI रिसर्च (अर्थात्, अग्रणी मॉडल अपने अगले संस्करण को स्वयं प्रशिक्षित करने की क्षमता रखते हैं) को देखने की संभावना लगभग 60% है। इसे 2027 में क्यों नहीं अपेक्षित किया जा रहा है?
कारण यह है कि लेखक का मानना है कि AI शोध को आगे बढ़ाने के लिए अभी भी रचनात्मकता और विपरीत दृष्टिकोण की आवश्यकता है, और अब तक AI प्रणालियों ने इसे परिवर्तनकारी और महत्वपूर्ण तरीके से नहीं दिखाया है (हालांकि गणितीय शोध को तेज करने पर कुछ परिणाम संकेतक हैं)।
अगर उससे 2027 की संभावना मांगी जाए, तो वह 30% कहेगा।
यदि 2028 के अंत तक कुछ भी नहीं दिखाई देता है, तो हमें वर्तमान तकनीकी परिप्रेक्ष्य में कुछ मौलिक दोषों को उजागर करना होगा, जिसके लिए मानव आविष्कार की आवश्यकता होगी।