









Auteur original : David, DeepTide TechFlow
Le 20 janvier, X a open-sourcé un nouveau algorithme de recommandation.
La réponse de Musk est assez intéressante : « Nous savons que cet algorithme est nul et qu'il a besoin d'être entièrement révisé, mais au moins tu peux voir que nous luttions en temps réel pour l'améliorer. Aucune autre plateforme sociale n'oserait faire ça. »
Ces paroles ont deux significations.D'une part, admettre que les algorithmes posent problème, et d'autre part, présenter la « transparence » comme un atout.
Il s'agit de la deuxième fois que X rend son algorithme open source. La version du code publiée en 2023 n'avait pas été mise à jour depuis trois ans et était depuis longtemps déconnectée du système réel. Cette fois-ci, il s'agit d'une refonte complète, et le modèle central a été remplacé du machine learning traditionnel par le Grok transformer. Selon le communiqué officiel, cela permettrait d'« éliminer complètement l'ingénierie manuelle des caractéristiques ».
Auparavant, les algorithmes dépendaient des ingénieurs pour ajuster manuellement les paramètres, mais maintenant, l'IA examine directement votre historique d'interactions pour décider s'il faut ou non recommander votre contenu.
Pour les créateurs de contenu, cela signifie que les anciennes méthodes empiriques telles que « à quelle heure poster est le mieux » ou « quels tags utiliser pour gagner des abonnés » pourraient ne plus fonctionner.
Nous avons également consulté des dépôts GitHub open source et, avec l'aide de l'IA, nous avons découvert qu'il y avait effectivement quelques logiques figées cachées dans le code, qui valent le coup d'être analysées.
Changements dans la logique des algorithmes : du défi manuel à la détection automatique par l'IA
Clarifions d'abord les différences entre les anciennes et nouvelles versions, sinon les discussions suivantes risquent de devenir confuses.
En 2023, la version open source de Twitter s'appelait Heavy Ranker, qui n'était en réalité qu'un apprentissage automatique traditionnel. Les ingénieurs devaient définir manuellement plusieurs centaines de « caractéristiques » : si le tweet contient une image, combien de followers a le compte, depuis combien de temps le tweet a été publié, s'il contient un lien...
Ensuite, on attribue un poids à chaque caractéristique, on les ajuste, et on regarde quelle combinaison donne de meilleurs résultats.
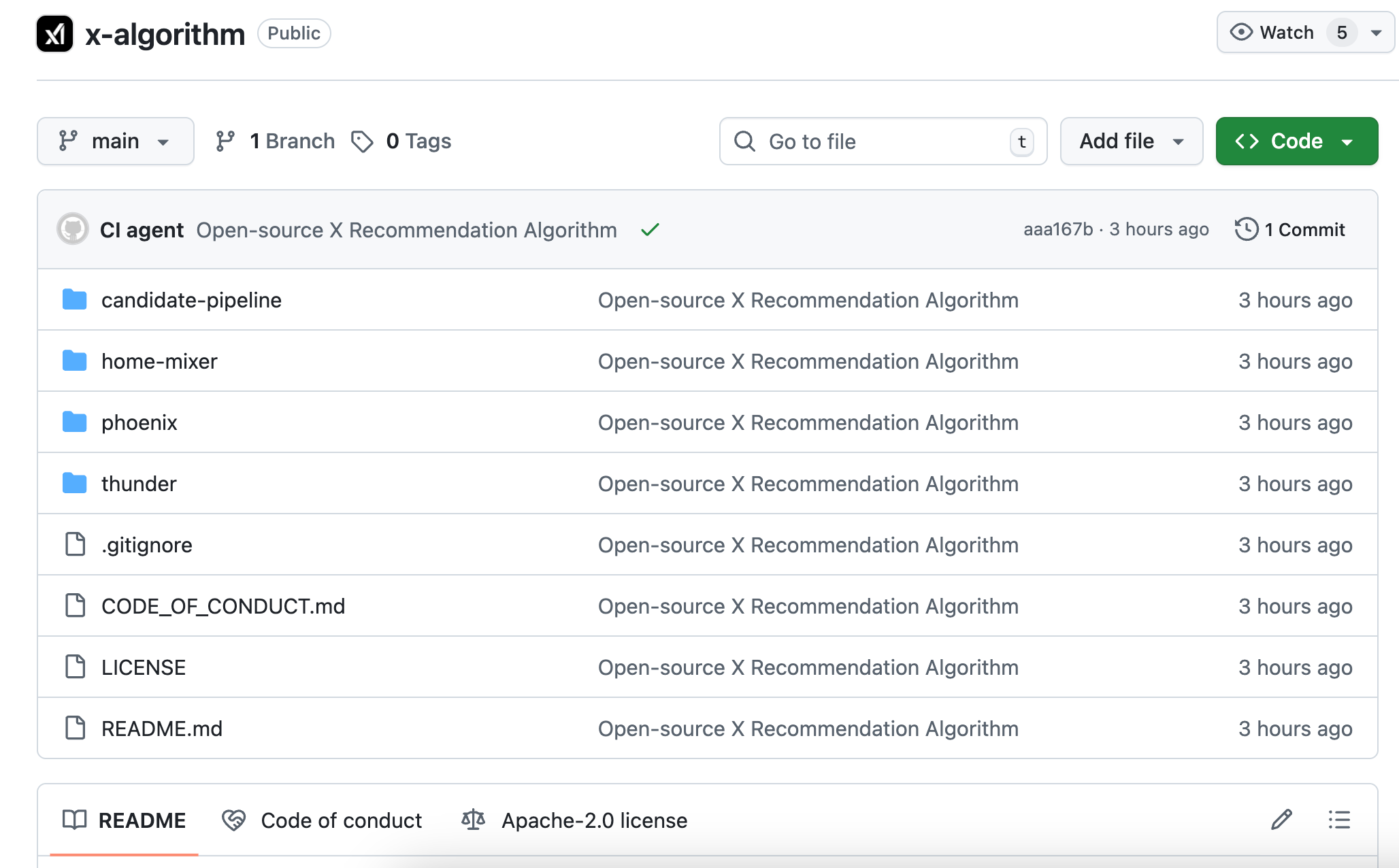
La nouvelle version open source s'appelle Phoenix, son architecture est complètement différente. Tu peux la comprendre comme un algorithme qui dépend davantage des grands modèles d'IA. Son noyau utilise le modèle transformer de Grok, la même technologie que ChatGPT et Claude.
Le document README officiel est très clair : « Nous avons éliminé chaque caractéristique conçue manuellement. »
Toutes les règles traditionnelles qui dépendaient de l'extraction manuelle des caractéristiques du contenu ont été abandonnées, sans exception.
Maintenant, sur quoi cet algorithme se base-t-il pour déterminer si un contenu est bon ou non ?
La réponse dépend de toi.Séquence d'actionsVous avez aimé quoi par le passé, répondu à qui, passé plus de deux minutes sur quels posts, et bloqué quels types de comptes. Phoenix alimente ces comportements au modèle transformer, afin qu'il découvre lui-même les tendances et les synthétise.
Par analogie : l'ancien algorithme ressemble à un tableau de notation manuellement rédigé, où chaque case cochée correspond à un certain nombre de points ;
Le nouvel algorithme ressemble à un IA qui aurait consulté l'historique de toutes vos visites sur le web,Devinez directementQue voudrais-tu regarder à la seconde suivante ?
Pour les créateurs, cela signifie deux choses :
Premièrement, les astuces précédentes telles que les « meilleurs moments pour poster » ou les « balises d'or » ont perdu de leur valeur.Puisque le modèle n'analyse plus ces caractéristiques fixes, il se concentre désormais sur les préférences personnelles de chaque utilisateur.
Deuxièmement, la capacité de votre contenu à être diffusé dépend de plus en plus de la réaction des personnes qui le voient.Cette réaction a été quantifiée en 15 prédictions comportementales, que nous détaillerons au chapitre suivant.
Les algorithmes prédisent vos 15 réactions
Après avoir récupéré un article à recommander, Phoenix prédit 15 comportements possibles que l'utilisateur actuel pourrait avoir face à ce contenu :
- Comportement positif: comme les j'aime, les réponses, les partages, les retransmissions avec citation, les clics sur les publications, les clics sur la page d'accueil de l'auteur, la visualisation de plus de la moitié d'une vidéo, le développement des images, le partage, le temps passé à regarder au-delà d'une certaine durée, l'abonnement à l'auteur
- Comportement négatif: comme cliquer sur « Pas intéressé », bloquer l'auteur, muter l'auteur, signaler
Chaque action correspond à une probabilité prédite. Par exemple, le modèle évalue à 60 % la probabilité que vous appuyiez sur le bouton « J'aime » pour cette publication, à 5 % la probabilité que vous bloquiez l'auteur, etc.
Ensuite, l'algorithme fait quelque chose d'assez simple : il multiplie ces probabilités par leurs poids respectifs, les additionne, et obtient ainsi un score total.
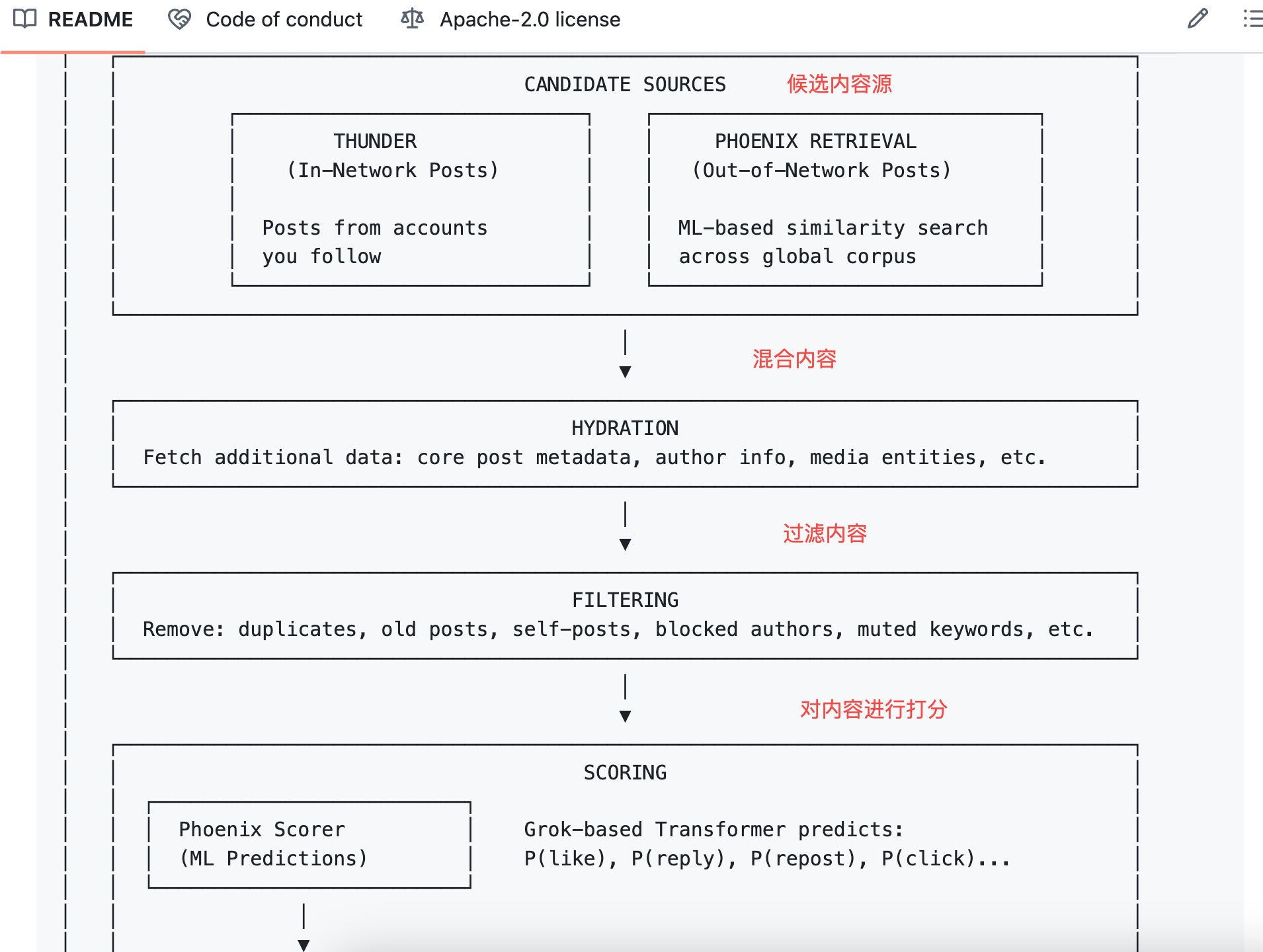
La formule ressemble à ceci :
Score final = Σ ( poids × P(action) )
Les poids des comportements positifs sont des nombres positifs, et les poids des comportements négatifs sont des nombres négatifs.
Les messages avec un score total élevé apparaîtront en premier, tandis que ceux avec un score faible descendront.
En sortant de la formule, disons clairement que :
Aujourd'hui, la qualité d'un contenu n'est plus vraiment déterminée par la qualité du contenu lui-même (bien que la lisibilité et l'utilité soient des bases essentielles pour sa diffusion) ; elle dépend davantage de « la réaction que ce contenu va provoquer chez vous ». L'algorithme ne s'intéresse pas à la qualité intrinsèque du post, mais uniquement à vos actions.
En suivant cette logique, dans des cas extrêmes, une publication vulgaire mais qui incite les gens à y répondre avec des commentaires critiques pourrait obtenir un score plus élevé qu'une publication de qualité mais sans aucune interaction. Le principe fondamental de ce système pourrait bien être ainsi.
Cependant, l'algorithme de la nouvelle version open source ne révèle pas les valeurs numériques spécifiques des pondérations des comportements, contrairement à celle de 2023 qui les avait publiées.
Référence ancienne : 1 signalement = 738 j'aime
Nous pouvons maintenant analyser les données de l'année 2023, même si elles sont un peu anciennes, elles vous aideront à comprendre la différence de « valeur » que l'algorithme accorde à divers comportements.
Le 5 avril 2023, X a effectivement publié un ensemble de poids sur GitHub.
Directement les chiffres :
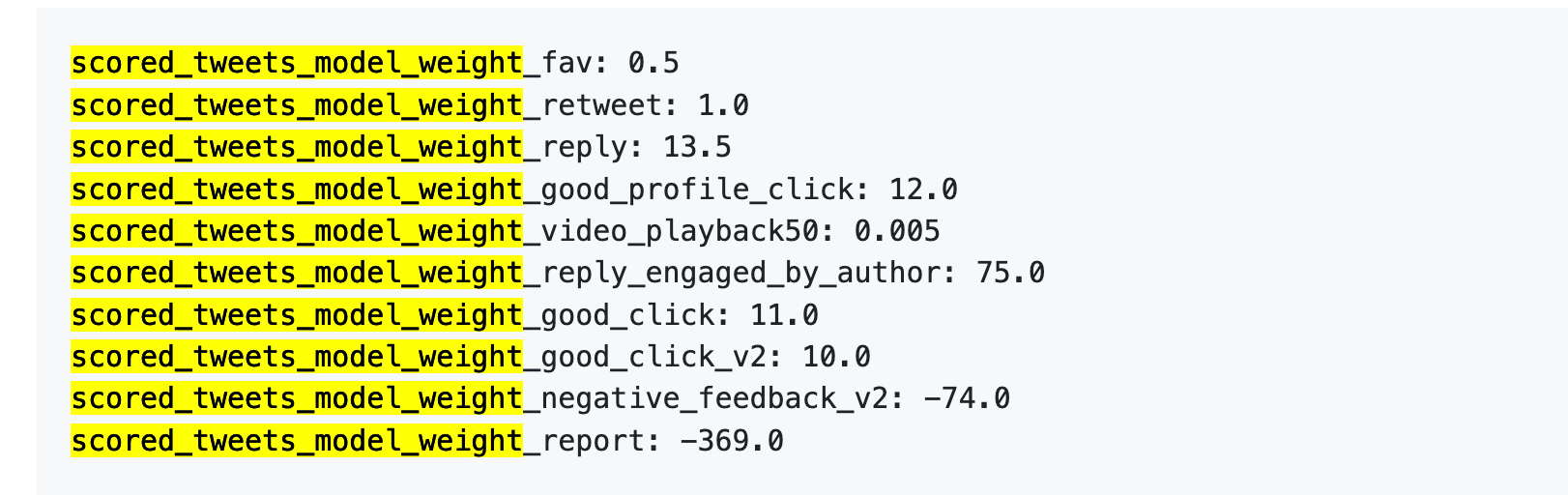
Traduis plus littéralement :
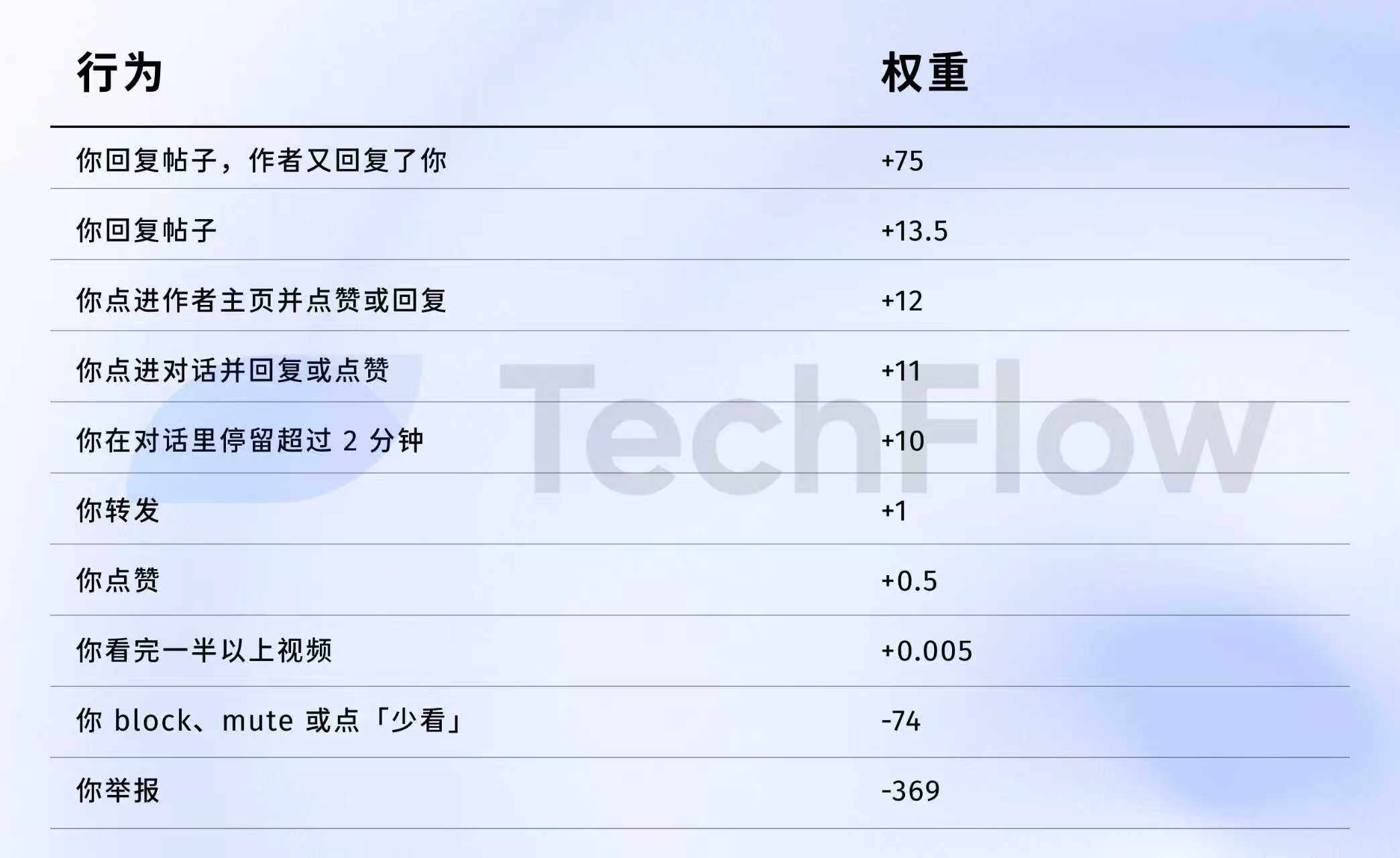
Source des données : version précédente Dépôt GitHub twitter/the-algorithm-ml, cliquez pour voir l'algorithme d'origine
Quelques chiffres méritent une attention particulière.
Premièrement, les "j'aime" sont presque sans valeur. Son poids n'est que de 0,5, le plus faible parmi tous les comportements positifs. Aux yeux de l'algorithme, la valeur d'un like est à peu près équivalente à zéro.
Deuxièmement, l'interaction dialoguée est véritablement la monnaie d'échange. Le poids d'une réponse mutuelle, où l'auteur répond à votre commentaire, est de 75, soit 150 fois celui d'un simple like. L'algorithme privilégie avant tout les échanges dialogués plutôt que les likes unidirectionnels.
Troisièmement, le coût des retours négatifs est extrêmement élevé. Un bloc ou un bannissement (-74) nécessite 148 "j'aime" pour être compensé. Une dénonciation (-369) nécessite 738 "j'aime". De plus, ces points négatifs s'accumulent dans le score de confiance de votre compte et affectent la distribution de tous vos futurs messages.
Quatrièmement, le poids du taux de visionnage des vidéos est ridiculement faible. Il n'y a que 0,005, presque négligeable. Cela contraste fortement avec TikTok et Douyin, où le taux de visionnage complet est considéré comme un indicateur clé.
Dans le même document, il est également indiqué : « Les poids exacts contenus dans le fichier peuvent être ajustés à tout moment... Depuis cette date, nous ajustons périodiquement ces poids afin d'optimiser les indicateurs de la plateforme. »
Les poids peuvent être ajustés à tout moment, et ils l'ont effectivement été.
La nouvelle version ne publie pas les valeurs exactes, mais le cadre logique indiqué dans le README est identique : ajout de points positifs, retrait de points négatifs, somme pondérée.
Les chiffres précis peuvent avoir changé, mais les relations d'ordre sont probablement restées les mêmes. Répondre à un commentaire d'un autre utilisateur est probablement plus utile que d'obtenir 100 « j'aime ». Faire en sorte qu'on veuille te bloquer est pire qu'un total d'absence d'interaction.
Sachant tout cela, que pouvons-nous faire, nous les créateurs ?
Après avoir analysé les anciens et nouveaux algorithmes de Twitter, en les combinant et en les réfléchissant, voici quelques conclusions opérationnelles.
1. Répondez à vos commentateurs. Dans le tableau des pondérations, « la réponse de l'auteur à un commentateur » est l'élément le plus valorisé (+75), soit trois fois plus que le simple fait d'obtenir un like unilatéral d'un utilisateur. Ce n'est pas une invitation à quémander des commentaires, mais à répondre lorsqu'on en reçoit un. Même une simple réponse telle que « merci » sera prise en compte par l'algorithme.
2. Ne laissez personne faire défiler. Un seul bloc nécessite 148 « j'aime » pour être compensé. Le contenu controversé attire effectivement l'interaction, mais si cette interaction prend la forme de « ce type m'énerve, je le bloque », votre score de réputation d'utilisateur continuera de se dégrader, affectant ainsi la distribution de tous vos futurs posts. Le trafic controversé est un couteau à double tranchant : avant de blesser les autres, réfléchissez à ce que vous feriez à votre propre égard.
3. Mettez les liens externes dans la section des commentaires.L'algorithme ne souhaite pas diriger les utilisateurs vers l'extérieur du site. Le texte contenant des liens subira une diminution de son poids.C'est d'ailleurs ce que Musk a lui-même déclaré publiquement. Si tu veux rediriger le trafic, écris le contenu principal dans le corps du message, et place le lien en premier commentaire.
4. Ne spammez pas l'écran. La nouvelle version du code contient un « Author Diversity Scorer », dont le rôle est d'appliquer un coefficient de pénalité aux publications consécutives provenant d'un même auteur. L'intention est de rendre le fil d'actualité de l'utilisateur plus varié. Effet secondaire : poster dix fois de suite est moins efficace que poster une seule fois de manière soignée.
6. Il n'y a plus de « meilleur moment pour poster ». L'algorithme ancien disposait d'une caractéristique manuelle : l'« heure de publication », mais cette version a été supprimée sans préavis. Phoenix ne prend en compte que la séquence des comportements des utilisateurs, et ignore l'heure à laquelle un message a été publié. Les conseils tels que « il est meilleur de poster à 15 heures un mardi après-midi » deviennent de moins en moins pertinents.
Ce qui précède est ce que l'on peut lire au niveau du code.
Certains éléments de pondération supplémentaires proviennent des documents publics de X, et ne se trouvent pas dans le dépôt open source actuel : l'obtention du label bleu apporte un avantage, l'utilisation de majuscules partout réduit l'impact, et le contenu sensible déclenche une diminution de 80 % du taux de couverture. Ces règles ne sont pas open source, nous n'entrerons donc pas dans les détails.
En résumé, ce qui a été open source cette fois-ci est assez solide.
L'architecture système complète, la logique de rappel du contenu candidat, le processus de classement et d'évaluation, ainsi que la mise en œuvre de divers filtres. Le code est principalement écrit en Rust et Python, avec une structure claire. Le fichier README est plus détaillé que celui de nombreux projets commerciaux.
Mais quelques éléments clés n'ont pas été divulgués.
1. Les paramètres de pondération ne sont pas publiés. Le code ne précise que « ajouter des points pour les comportements positifs, retirer des points pour les comportements négatifs », mais ne précise pas combien de points sont ajoutés pour un like, ni combien sont retirés pour un blocage. La version de 2023 au moins affichait les chiffres, cette fois-ci, on ne donne qu'un cadre de formule.
2. Les poids du modèle ne sont pas publiés. Phoenix utilise le modèle Grok, mais les paramètres du modèle lui-même ne sont pas fournis. Vous pouvez voir comment le modèle est appelé, mais pas comment les calculs s'effectuent à l'intérieur du modèle.
3. Les données d'entraînement ne sont pas publiques. Rien n'a été dit sur les données utilisées pour l'entraînement du modèle, la manière dont les comportements des utilisateurs sont échantillonnés, ni la façon dont les échantillons positifs et négatifs sont construits.
Pour faire une comparaison, cette fois-ci, l'ouverture du code source revient à vous dire : « nous utilisons une somme pondérée pour calculer le score total », mais sans vous indiquer les pondérations ; à vous dire : « nous utilisons un transformer pour prédire la probabilité d'action », mais sans vous dire à quoi ressemble ce transformer en interne.
En comparaison transversale, TikTok et Instagram n'ont même jamais rendu publics ces informations. Cette fois-ci, la quantité d'informations rendue publique par X est effectivement plus importante que celle des autres plateformes majeures. Cependant, elle reste encore éloignée d'une « transparence totale ».
Cela ne signifie pas que le logiciel libre n'apporte aucune valeur. Pour les créateurs et les chercheurs, il vaut toujours mieux avoir accès au code que de ne pas l'avoir.