









Auteur :Tina, DongmeiInfoQ
1. Plus de trois ans après, Musk rend à nouveau open source l'algorithme de recommandation de X
À l'instant, l'équipe d'ingénierie de X a publié un message sur X annonçant le lancement officiel de l'algorithme de recommandation de X en open source. Selon les informations fournies, cette bibliothèque open source contient le système de recommandation central qui alimente le fil d'actualité « Pour vous » sur X. Ce système combine le contenu en réseau (provenant des comptes suivis par l'utilisateur) et le contenu hors réseau (découvert via un système de recherche basé sur l'apprentissage automatique), puis classe l'ensemble du contenu à l'aide d'un modèle Transformer basé sur Grok. Cela signifie que cet algorithme utilise la même architecture Transformer que Grok.
Adresse open source : https://x.com/XEng/status/2013471689087086804
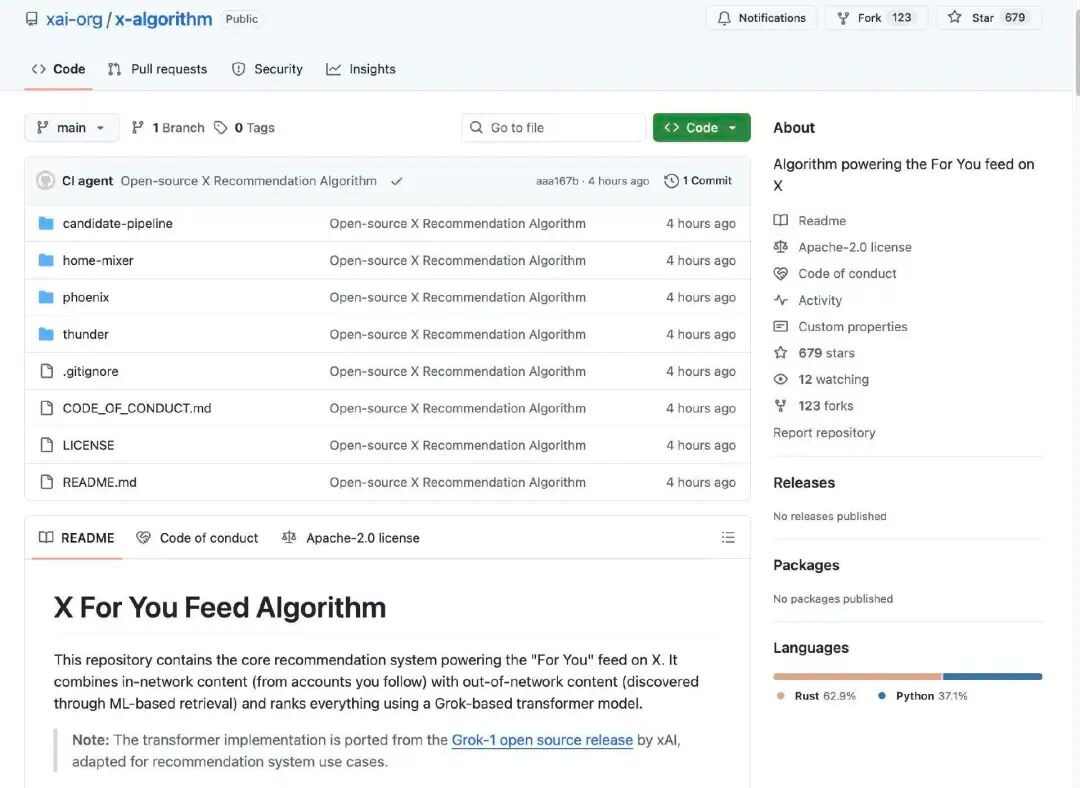
L'algorithme de recommandation de X est chargé de générer le contenu que les utilisateurs voient sur leur page d'accueil.Contenu de la rubrique « Pour vous »Il obtient les publications candidates de deux sources principales :
Le compte auquel vous avez souscrit (In-Network / Thunder)
Autres publications trouvées sur la plateforme (Hors réseau / Phoenix)
Ces contenus candidats sont ensuite traités de manière uniforme, filtrés, puis classés selon leur pertinence.
Alors, quelle est la structure centrale de l'algorithme et sa logique d'exécution ?
L'algorithme commence par récupérer du contenu candidat à partir de deux types de sources :
Contenu des comptes que vous suivez : messages publiés par des comptes que vous suivez activement.
Contenu non suivi : des messages pouvant vous intéresser, trouvés par le système dans l'ensemble de la base de contenus.
L'objectif de cette phase est de "trouver les messages qui pourraient être pertinents".
Le système supprime automatiquement les contenus de mauvaise qualité, en double, illégaux ou inappropriés. Par exemple :
Contenu d'un compte bloqué
Des sujets clairement déclarés comme sans intérêt par l'utilisateur
Messages illégaux, obsolètes ou non valides
Cela garantit que, lors du tri final, seuls les contenus candidats pertinents seront traités.
L'algorithme rendu open source cette fois-ci repose sur un modèle Transformer basé sur Grok (similaire à un grand modèle de langage ou réseau de deep learning), utilisé par le système pour attribuer une note à chaque publication candidate. Le modèle Transformer prédit la probabilité de chaque type d'action (j'aime, réponse, partage, clic, etc.) en se basant sur l'historique des interactions de l'utilisateur. Enfin, ces probabilités d'actions sont combinées de manière pondérée pour former un score global. Les publications ayant un score plus élevé sont plus susceptibles d'être recommandées à l'utilisateur.
Cette conception élimine pratiquement l'extraction manuelle traditionnelle des caractéristiques, en adoptant à la place une approche d'apprentissage bout-en-bout pour prédire les centres d'intérêt des utilisateurs.
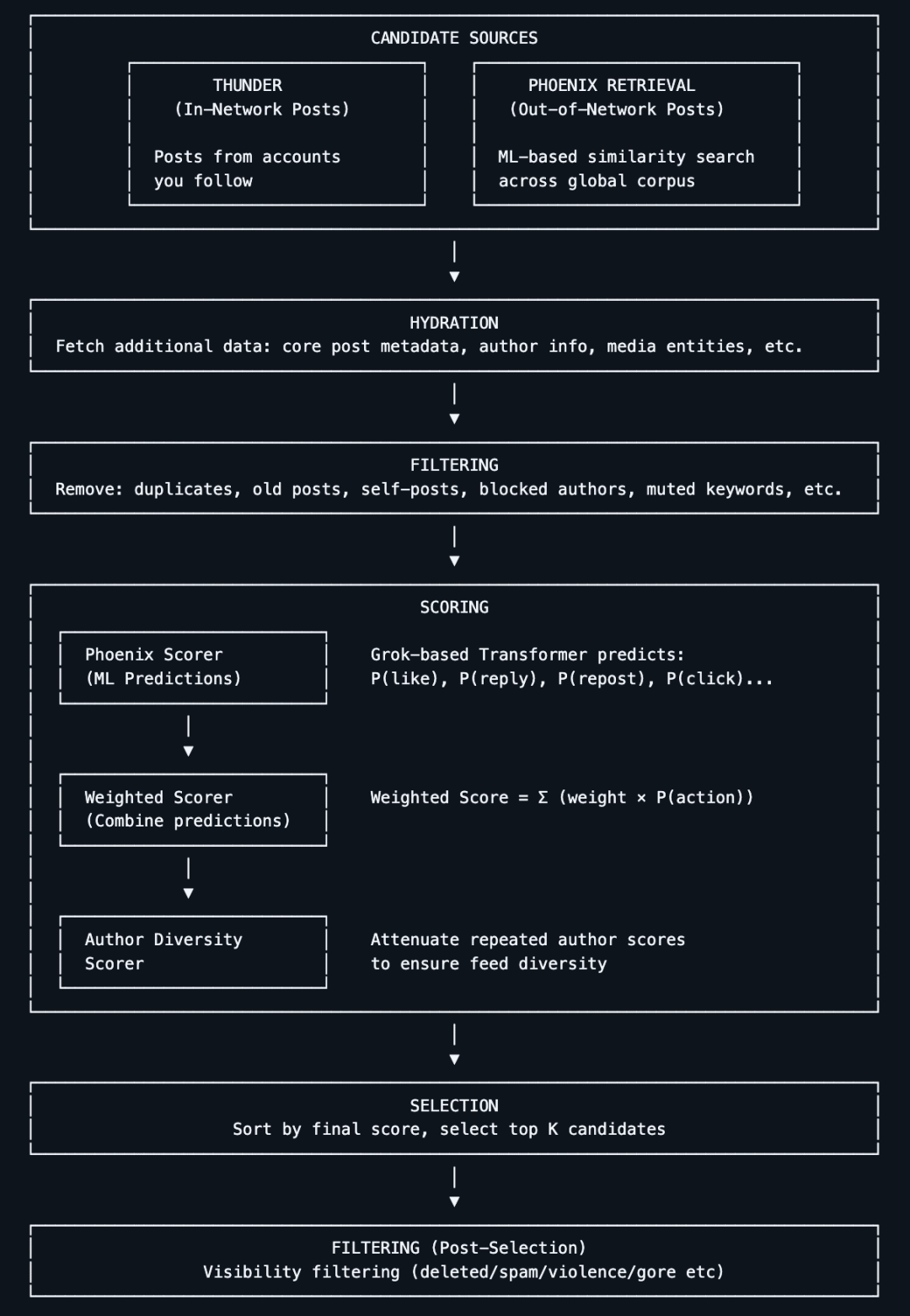
Ce n'est pas la première fois que Musk rend open source l'algorithme de recommandation de X.
Le 31 mars 2023, comme il l'avait promis lorsqu'il avait acquis Twitter, Elon Musk a officiellement rendu open source une partie du code source de Twitter, notamment l'algorithme qui recommande des tweets dans les fils d'actualité des utilisateurs.Le jour de son lancement en open source, le projet a reçu plus de 10 000 étoiles sur GitHub.
À l'époque, Musk avait déclaré sur Twitter que cette publication était« La plupart des algorithmes de recommandation »Les autres algorithmes seront progressivement rendus publics. Il a également précisé qu'il espérait que « des tiers indépendants puissent déterminer avec une précision raisonnable le contenu que Twitter pourrait montrer aux utilisateurs ».
Dans le fil de discussion Space concernant la publication de l'algorithme, il a déclaré que ce plan d'open source visait à rendre Twitter « le système le plus transparent d'Internet » et à le rendre aussi robuste que le projet open source le plus connu et le plus réussi, Linux. « L'objectif global est de permettre aux utilisateurs qui souhaitent continuer à soutenir Twitter d'en tirer le plus grand bénéfice possible. »
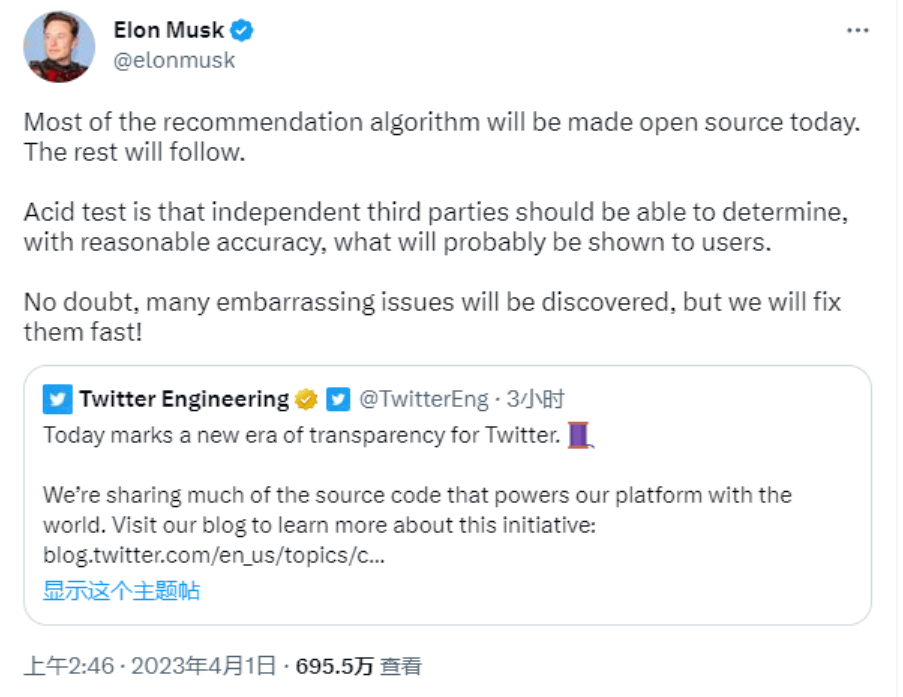
Aujourd'hui, plus de trois ans se sont écoulés depuis que Musk a rendu l'algorithme X open source pour la première fois. En tant que figure incontournable du monde technologique, Musk a depuis longtemps bien fait la promotion de cette initiative open source.
Le 11 janvier, Musk a publié un message sur X, affirmant qu'il rendrait open source l'algorithme X nouveau dans les 7 jours, y compris tout le code utilisé pour déterminer les contenus de recherche naturelle et les publicités recommandés aux utilisateurs.
Ce processus se répétera toutes les 4 semaines, accompagné d'une documentation détaillée pour les développeurs, afin d'aider les utilisateurs à comprendre les changements apportés.
Aujourd'hui, sa promesse s'est à nouveau concrétisée.
2. Pourquoi Musk veut-il open-sourcer ?
Lorsque Elon Musk évoque à nouveau le "logiciel libre", la première réaction de l'extérieur n'est pas l'idéalisme technologique, mais plutôt la pression现实.
Au cours de la dernière année, X a été à plusieurs reprises au cœur de controverses concernant son mécanisme de distribution de contenus. La plateforme a été largement critiquée pour le biais et le soutien systématiques qu'elle accorderait, au niveau de ses algorithmes, aux points de vue de droite. Cette tendance n'est pas perçue comme isolée, mais comme caractéristique d'un système. Un rapport publié l'année dernière a d'ailleurs souligné l'apparition d'un biais politique clairement nouveau dans le système de recommandation de X.
Pendant ce temps, certains cas extrêmes ont encore exacerbé les doutes de l'extérieur. L'année dernière, une vidéo non vérifiée montrant un incident impliquant l'activiste américain de droite Charlie Kirk a été rapidement partagée sur la plateforme X, suscitant un vif émoi public. Les critiques estiment que cela révèle non seulement l'échec des mécanismes de modération de la plateforme, mais souligne aussi une fois de plus le rôle des algorithmes dans le choix de ce qui est amplifié et de ce qui ne l'est pas. Pouvoir implicite.
Dans ce contexte, l'accent soudain mis par Musk sur la transparence des algorithmes est difficile à interpréter simplement comme une décision technique pure.

3. Que pensent les internautes ?
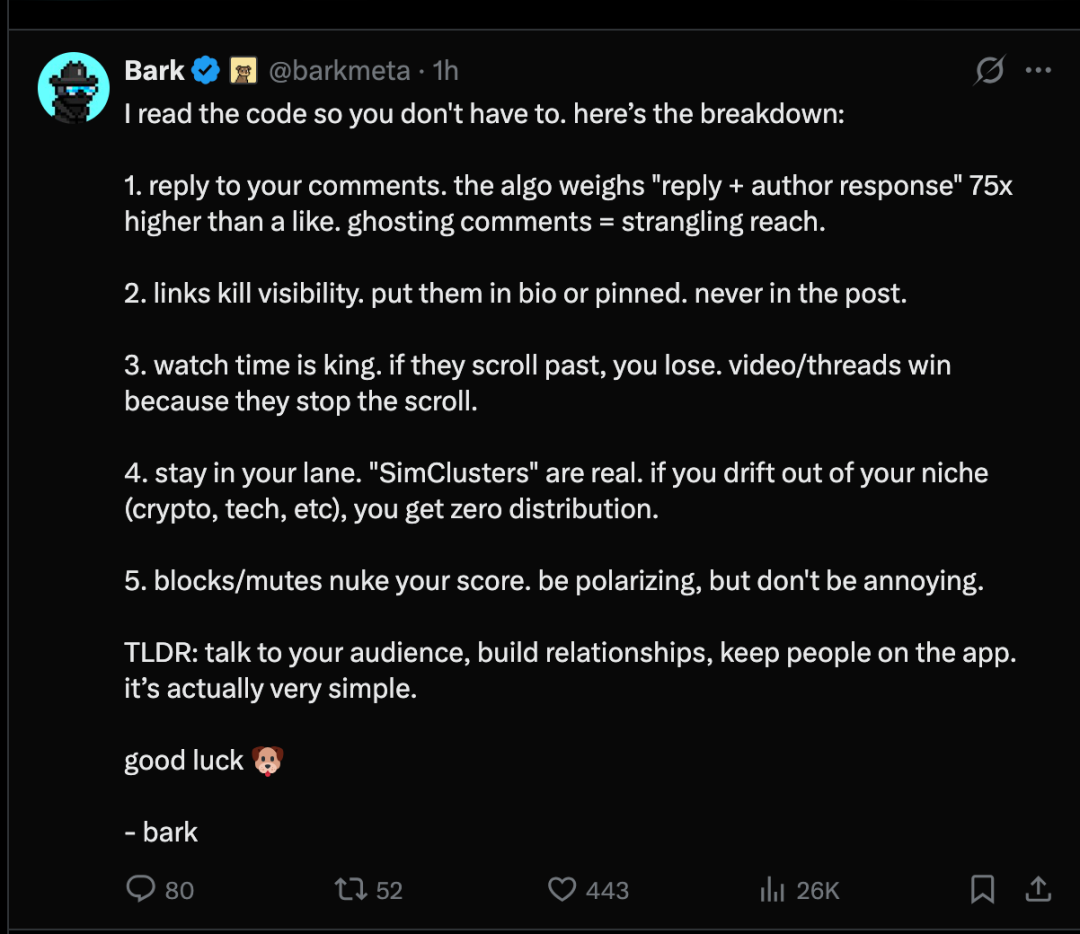
Après que l'algorithme de recommandation de X ait été open source, des utilisateurs sur la plateforme X ont fait les cinq constats suivants concernant le mécanisme d'algorithme de recommandation :
- Répondre à votre commentaireL'algorithme accorde un poids 75 fois plus important à la "réponse + réponse de l'auteur" par rapport aux "j'aime". Ne pas répondre aux commentaires affecte fortement le taux d'exposition.
- Les liens réduisent le taux d'exposition.Mettez le lien dans votre bio ou dans votre publication mise en tête, mais surtout pas dans le corps du message.
- La durée de visionnage est essentielle.Si les utilisateurs font glisser l'écran pour les ignorer, vous ne pourrez pas les attirer. Les vidéos ou les publications obtiennent une grande attention car elles arrêtent l'utilisateur.
- Restez fidèle à votre domaine.« Cluster simulé » existe bel et bien. Si vous sortez de votre domaine spécifique (cryptomonnaies, technologie, etc.), vous ne pourrez obtenir aucun canal de distribution.
- Ignorer ou ne pas répondre réduira considérablement ton score.Quelque chose de controversé, mais pas déplaisant.
En résumé : communiquez avec votre public, établissez des relations et retenez les utilisateurs dans l'application. En fait, c'est assez simple.
D'autres internautes ont remarqué que, bien que l'architecture soit open source, certains éléments ne l'étaient pas encore. Cet internaute a déclaré que cette publication n'était en réalité qu'un cadre, sans moteur. Quels éléments manquaient exactement ?
Paramètre de pondération manquant - Le code confirme l'attribution de points pour les comportements positifs et la déduction de points pour les comportements négatifs, mais contrairement à la version de 2023, les valeurs précises ont été supprimées.
Cacher les poids du modèle - Ne comprenant pas les paramètres internes et les calculs du modèle lui-même.
Données d'entraînement non publiques - Nous n'avons aucune connaissance sur les données utilisées pour entraîner le modèle, la méthode d'échantillonnage des comportements des utilisateurs, ni sur la manière dont les échantillons "bons" et "mauvais" ont été construits.
Pour l'utilisateur X ordinaire, le fait que l'algorithme de X soit open source n'aura probablement pas d'impact majeur. Toutefois, une transparence accrue permettrait d'expliquer pourquoi certains messages obtiennent de l'exposition tandis que d'autres sont ignorés, et permettrait aux chercheurs d'étudier la manière dont la plateforme classe le contenu.
4. Pourquoi le système de recommandation est-il un enjeu stratégique ?
Dans la plupart des discussions techniques,Système de recommandationSouvent considéré comme faisant partie de l'ingénierie en arrière-plan, discret et complexe, mais rarement mis en lumière. Cependant, si l'on examine réellement le fonctionnement commercial des géants d'Internet, on découvre que le système de recommandation n'est pas un module périphérique, mais une « infrastructure fondamentale » qui soutient tout le modèle commercial. C'est pourquoi on peut le qualifier de « géant silencieux » de l'industrie Internet.
Les données publiques ont répétitivement confirmé ce point. Amazon a révélé que près de 35 % des achats sur sa plateforme provenaient directement du système de recommandation ; Netflix est encore plus radical, puisque environ 80 % du temps de visionnage est guidé par l'algorithme de recommandation ; la situation est similaire sur YouTube, où environ 70 % du temps passé à regarder des vidéos provient du système de recommandation, en particulier via le fil d'actualité (feed). Quant à Meta, bien qu'elle n'ait jamais fourni de pourcentage précis, son équipe technique a mentionné qu'environ 80 % des cycles de calcul dans les clusters informatiques internes de l'entreprise sont utilisés pour des tâches liées aux recommandations.
Que signifient ces chiffres ?Si l'on retirait les systèmes de recommandation de ces produits, cela reviendrait à enlever les fondations.Prenons Meta comme exemple : la diffusion de publicités, le temps de connexion des utilisateurs, la transformation en actions commerciales dépendent presque entièrement du système de recommandation. Ce système détermine non seulement ce que les utilisateurs "voient", mais influence aussi directement la manière dont la plateforme "gagne de l'argent".
Cependant, c'est précisément ce système qui détermine la vie ou la mort qui fait face depuis longtemps à des problèmes d'une extrême complexité technique.
Dans l'architecture classique des systèmes de recommandation, il est difficile d'utiliser un seul modèle unifié pour couvrir tous les scénarios. Les systèmes de production réels sont souvent très fragmentés. Prenons par exemple des entreprises comme Meta, LinkedIn ou Netflix : derrière une chaîne complète de recommandation, il est courant que 30 modèles spécialisés, voire plus, soient exécutés simultanément : des modèles de rappel, de tri grossier, de tri fin, de réordonnancement, chacun optimisé pour des fonctions objectif et des indicateurs métier différents. Derrière chaque modèle, il y a souvent un ou plusieurs équipes chargées de l'ingénierie des caractéristiques, de l'entraînement, du réglage des paramètres, du déploiement et de l'itération continue.
Le coût de ce modèle est évident : complexité technique, coûts élevés d'entretien, et difficultés de coordination entre les tâches. Dès qu'une personne suggère l'idée "Est-il possible d'utiliser un seul modèle pour résoudre plusieurs problèmes de recommandation ? ", cela signifie pour l'ensemble du système une réduction exponentielle de la complexité. C'est précisément l'objectif que l'industrie a longtemps souhaité atteindre, mais sans succès jusqu'à présent.
L'émergence des grands modèles linguistiques offre une nouvelle voie potentielle aux systèmes de recommandation.
Les grands modèles linguistiques (LLM) ont déjà démontré, en pratique, qu'ils pouvaient devenir des modèles universels extrêmement puissants : ils présentent une forte capacité de transfert entre différentes tâches, et leurs performances s'améliorent continuellement avec l'augmentation de la quantité de données et de la puissance de calcul. En revanche, les modèles de recommandation traditionnels sont souvent « sur mesure » pour une tâche spécifique, ce qui rend difficile le partage de leurs capacités entre plusieurs scénarios.
Ce qui est encore plus important, un seul grand modèle apporte non seulement une simplification ingénieristique, mais aussi le potentiel d'apprentissage croisé. Lorsqu'un même modèle traite simultanément plusieurs tâches de recommandation, les signaux provenant des différentes tâches peuvent se compléter mutuellement. Avec l'augmentation de l'échelle des données, le modèle évolue plus facilement dans son ensemble. C'est précisément cette caractéristique que les systèmes de recommandation souhaitent depuis longtemps, mais qui est difficile à réaliser par les méthodes traditionnelles.
Les modèles LLM (Large Language Models) ont changé quoi ? En réalité, ils ont changé la donne, passant de l'ingénierie des caractéristiques à la capacité de compréhension.
D'un point de vue méthodologique, la plus grande transformation apportée par les modèles linguistiques de grande taille (LLM) aux systèmes de recommandation se produit au niveau de l'étape centrale de « l'ingénierie des caractéristiques ».
Dans les systèmes de recommandation traditionnels, les ingénieurs doivent d'abord construire manuellement un grand nombre de signaux : historique des clics des utilisateurs, durée de consultation, préférences des utilisateurs similaires, balises du contenu, etc. Ensuite, ils indiquent explicitement au modèle : « Veuillez prendre ces caractéristiques en compte pour faire des jugements ». Le modèle lui-même ne comprend pas le sens sémantique de ces signaux, il apprend simplement des relations d'association dans l'espace numérique.
Après l'utilisation d'un modèle linguistique, ce processus est fortement abstrait. Vous n'avez plus besoin de préciser une à une « regarde ce signal, ignore cet autre signal », mais vous pouvez directement décrire le problème au modèle : « il s'agit d'un utilisateur, il s'agit d'un contenu ; cet utilisateur a aimé des contenus similaires par le passé, d'autres utilisateurs ont également donné des retours positifs sur ce contenu — maintenant, veuillez juger si ce contenu devrait être recommandé à cet utilisateur. »
Le modèle linguistique lui-même possède déjà une capacité de compréhension. Il peut juger par lui-même quels sont les signaux importants et comment les intégrer pour prendre des décisions. En un certain sens, il ne s'agit plus seulement d'appliquer des règles de recommandation, mais plutôt de « comprendre la recommandation elle-même ».
L'origine de cette capacité réside dans le fait que les grands modèles linguistiques (LLM) ont été exposés, lors de leur phase d'entraînement, à d'énormes quantités de données très diversifiées, ce qui leur permet de capturer plus facilement des modèles subtils mais importants. En revanche, les systèmes de recommandation traditionnels doivent compter sur les ingénieurs pour énumérer explicitement ces modèles ; dès qu'un modèle est oublié, le modèle ne peut pas en tenir compte.
Du point de vue du backend, ce genre de changement n'est pas nouveau. Lorsque vous posez une question à GPT, il génère une réponse en se basant sur le contexte ; de la même manière, si vous lui demandez « est-ce que je serais intéressé par ce contenu », il peut également prendre une décision en se fondant sur les informations existantes. En un certain sens, les modèles linguistiques possèdent naturellement déjà la capacité de « recommandation ».