










Imaginez ce scénario :
Vous avez demandé à un agent IA de corriger un bogue dans votre code. Il a ouvert le projet, lu 20 fichiers, apporté quelques modifications, lancé les tests : échec. Il a modifié à nouveau, relancé les tests : toujours échec… Il a répété cette procédure une dizaine de fois, et finalement — le bogue n’était toujours pas corrigé.
Vous éteignez votre ordinateur et vous soulevez un poids. Ensuite, vous recevez la facture API.
Les chiffres ci-dessus pourraient vous couper le souffle — lorsqu’un Agent IA répare automatiquement des bugs sur l’API officielle à l’étranger, une tâche non résolue peut consommer plus d’un million de tokens, avec des frais pouvant atteindre plusieurs dizaines à plus de cent dollars.
En avril 2026, un article de recherche publié conjointement par Stanford, le MIT, l'Université du Michigan et d'autres institutions a ouvert pour la première fois de manière systématique la « boîte noire » de la consommation des agents IA dans les tâches de codage — où l'argent est dépensé, si cette dépense est justifiée, et s'il est possible de la prévoir à l'avance : les réponses sont stupéfiantes.
Découverte 1 : Le coût de génération de code par l'Agent est 1000 fois supérieur à celui d'une conversation AI classique.
Les gens pourraient penser que faire écrire du code par une IA ou discuter du code avec une IA coûte à peu près le même montant.
L'article présente une comparaison montrant :
La consommation de tokens pour les tâches d'encodage agentic est environ 1000 fois supérieure à celle des tâches classiques de问答 et d'inférence de code.
Trois ordres de grandeur d'écart.
Pourquoi cela ? L'article souligne un fait : l'argent n'est pas dépensé pour « écrire du code », mais pour « lire du code ».
Ici, « lire » ne signifie pas que les humains lisent le code, mais que l’Agent, pendant son fonctionnement, doit constamment « alimenter » le modèle avec l’ensemble du contexte du projet, l’historique des opérations, les messages d’erreur et le contenu des fichiers. À chaque nouvelle conversation, ce contexte devient plus long ; or, le modèle est facturé en fonction du nombre de tokens — plus vous en fournissez, plus vous payez.
Par exemple, c’est comme engager un mécanicien qui, avant chaque mouvement de clé, exige que vous lui lisiez intégralement les plans de tout l’immeuble — le coût de la lecture des plans est bien plus élevé que celui du serrage des vis.
L'article résume ce phénomène en une phrase : le coût des agents est drivé par la croissance exponentielle des tokens d'entrée, et non des tokens de sortie.
Deuxième constat : le même bug, exécuté deux fois, peut coûter deux fois plus cher — et plus le bug est cher, plus il est instable.
Ce qui est encore plus frustrant, c'est la randomisation.
Les chercheurs ont fait exécuter le même agent sur la même tâche quatre fois et ont constaté que :
- Entre les différentes tâches, la tâche la plus coûteuse brûle environ 7 millions de tokens de plus que la moins coûteuse (Figure 2a)
- Sur plusieurs exécutions du même modèle et de la même tâche, la plus coûteuse est environ deux fois plus chère que la moins coûteuse (Figure 2b)
- Cependant, si l'on compare le même task entre différents modèles, la consommation maximale peut être jusqu'à 30 fois supérieure à la consommation minimale.
Le dernier chiffre mérite une attention particulière : cela signifie que l'écart de coût entre choisir le bon modèle et le mauvais modèle n'est pas simplement « un peu plus cher », mais « d'un ordre de grandeur ».
Ce qui est encore plus douloureux — dépenser plus ne signifie pas faire mieux.
L'étude a révélé une courbe en "U inversé" :
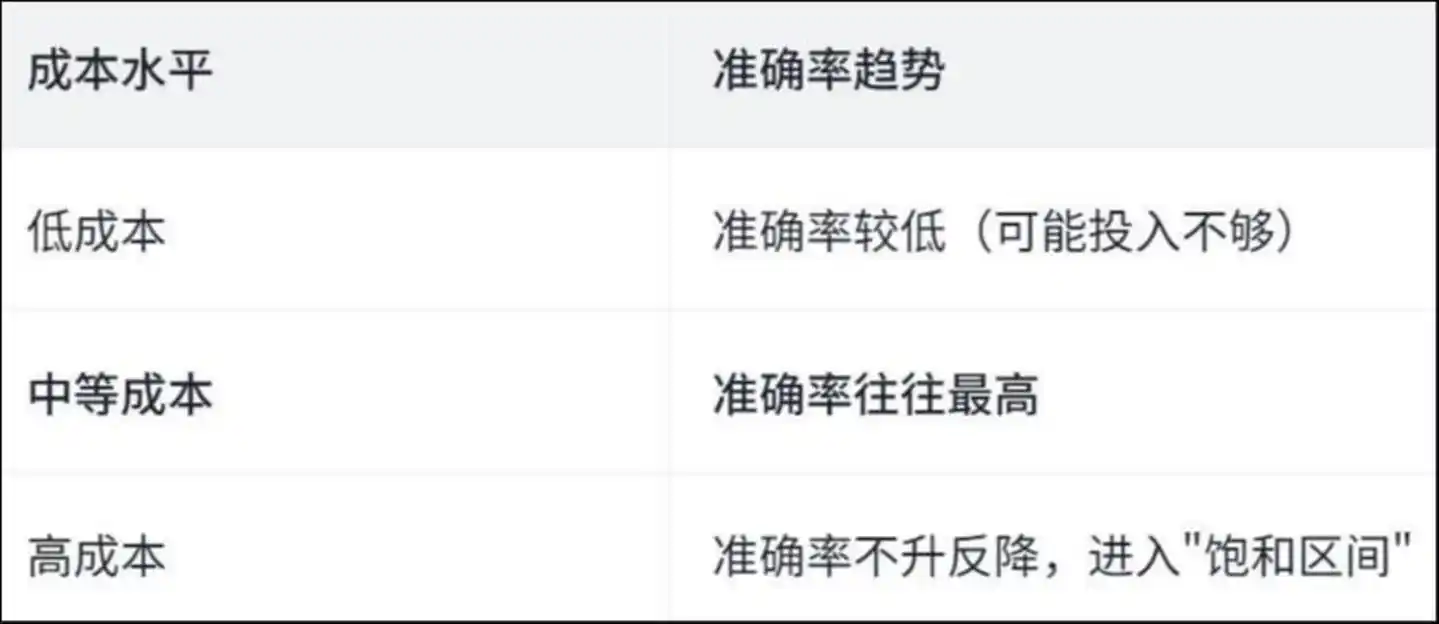
Tendance de précision des niveaux de coût : faible coût, précision faible (peut-être en raison d'un investissement insuffisant) ; coût moyen, précision souvent la plus élevée ; coût élevé, précision ne augmente pas, entre dans la « zone de saturation »
Pourquoi cela se produit-il ? L'article fournit la réponse en analysant les opérations spécifiques de l'Agent —
Dans un contexte de coûts élevés, les agents passent une grande partie de leur temps à effectuer des tâches répétitives.
Des études révèlent que, dans les opérations à haut coût, environ 50 % des actions de consultation et de modification de fichiers sont redondantes — c’est-à-dire que l’agent lit à plusieurs reprises le même fichier et modifie plusieurs fois la même ligne de code, comme une personne qui tourne en rond dans une pièce, de plus en plus étourdie au fur et à mesure qu’elle tourne.
L'argent n'a pas été dépensé pour résoudre le problème, mais pour se perdre.
Découverte trois : les modèles présentent des différences énormes en termes d'efficacité énergétique — GPT-5 est le plus économique, certains modèles consomment jusqu'à 1,5 million de tokens en plus.
Les performances de huit modèles avancés d'agents ont été évaluées sur SWE-bench Verified, un standard industriel basé sur 500 problèmes GitHub réels. En termes de dollars, les modèles les plus efficaces en termes de tokens permettent une différence de plusieurs dizaines de dollars par tâche. Dans un contexte d'application professionnelle — où des centaines de tâches sont exécutées chaque jour — cette différence se traduit par des coûts réels.
Une découverte encore plus intéressante : l'efficacité du token est une « caractéristique intrinsèque » du modèle, et non une conséquence de la tâche.
Les chercheurs ont isolé les tâches résolues par tous les modèles (230) et celles échouées par tous les modèles (100) pour les comparer, et ont constaté que le classement relatif des modèles a à peine changé.
Cela signifie que certains modèles sont naturellement « bavards », peu importe la difficulté de la tâche.
Une autre découverte révélatrice : le modèle manque de « conscience du stop-loss ».
Face aux tâches difficiles que aucun modèle ne peut résoudre, un agent idéal devrait abandonner dès que possible au lieu de continuer à dépenser de l'argent. Mais dans la réalité, les modèles consomment généralement davantage de tokens sur les tâches échouées — ils ne « renoncent » pas, ils continuent à explorer, réessayer, relire le contexte, comme une voiture sans voyant d'avertissement de niveau de carburant qui roule jusqu'à ce qu'elle tombe en panne.
Découverte quatre : Ce qui est difficile pour les humains n'est pas nécessairement coûteux pour l'agent — la perception de la difficulté est complètement décalée
Vous vous demandez peut-être : au moins, puis-je estimer le coût en fonction de la difficulté de la tâche ?
Des experts humains ont évalué la difficulté de 500 tâches, puis ont comparé ces évaluations à la consommation réelle de tokens de l'Agent —
Résultat : seule une faible corrélation existe entre les deux.
Ce qui semble extrêmement difficile pour les humains peut être facilement résolu par un agent à faible coût ; en revanche, ce qui semble trivial pour les humains peut coûter une fortune à un agent.
C'est parce que la difficulté perçue par les humains et par l'IA n'est pas du tout la même :
- Les humains voient : la complexité logique, la difficulté algorithmique, le seuil de compréhension métier
- L'agent examine : la taille du projet, le nombre de fichiers à lire, la longueur du chemin d'exploration et si le même fichier sera modifié plusieurs fois.
Un problème que l'humain juge « il suffit de modifier une ligne » peut obliger l'agent à d'abord comprendre la structure de l'ensemble du codebase pour localiser cette ligne — et simplement « lire » le code consomme une grande quantité de tokens. En revanche, un problème algorithmique que l'humain trouve « logiquement compliqué » peut être résolu en un clin d'œil par l'agent, qui connaît précisément la solution standard.
Cela conduit à une réalité gênante : les développeurs ont presque impossible de prévoir intuitivement le coût d'exécution de l'Agent.
Découverte cinq : Même le modèle ne peut pas prédire avec précision combien il va coûter.
Puisque les humains ne peuvent pas prévoir avec précision, pourquoi ne pas laisser l'IA faire les prédictions elle-même ?
Les chercheurs ont conçu une expérience ingénieuse : faire en sorte que l'Agent « inspecte » d'abord le dépôt de code avant de commencer réellement à corriger les bogues, puis estime le nombre de tokens qu'il consommera — sans effectuer réellement la correction.
How did it go?
Tous les modèles, échec total.
Le meilleur score est la corrélation des prédictions de tokens de Claude Sonnet-4.5 — 0,39 (sur 1,0). La plupart des modèles affichent une corrélation de prévision entre 0,05 et 0,34, avec Gemini-3-Pro au plus bas, à seulement 0,04 — soit presque équivalent à une devinette aléatoire.
Encore plus surprenant : tous les modèles sous-estiment systématiquement leur consommation de jetons. Sur le nuage de points de la Figure 11, presque tous les points se situent en dessous de la « ligne de prédiction parfaite » — les modèles pensent qu’ils n’« utiliseront pas autant », alors qu’ils en consomment davantage. De plus, ce biais de sous-estimation est encore plus prononcé lorsqu’aucun exemple n’est fourni.
Plus ironique encore — faire une prédiction coûte aussi de l'argent.
Le coût de prédiction de Claude Sonnet-3.7 et Sonnet-4 peut dépasser deux fois le coût même de la tâche. Autrement dit, les faire « estimer un prix » coûte plus cher que de procéder directement à l'exécution.
La conclusion de l'article est directe :
À l'heure actuelle, les modèles de pointe ne peuvent pas prédire avec précision leur consommation de jetons. Cliquer sur « Exécuter l'Agent », c'est comme ouvrir une boîte surprise — vous ne connaissez le coût qu'une fois la facture reçue.
Derrière cette « comptabilité confuse » se cache un problème plus vaste pour l'industrie.
À ce stade, vous vous demandez peut-être : que signifient ces découvertes pour les entreprises ?
Le modèle de tarification « abonnement mensuel » est en train d'être fissuré par Agent
L'article souligne que les modèles d'abonnement comme ChatGPT Plus sont viables parce que la consommation de tokens pour des conversations ordinaires est relativement contrôlable et prévisible. Toutefois, les tâches d'agent brisent complètement cette hypothèse — une seule tâche peut consommer une quantité énorme de tokens si l'agent entre en boucle.
Cela signifie que le modèle de tarification par abonnement pur pourrait ne pas être durable pour les scénarios Agent, et que le paiement à l'utilisation (Pay-as-you-go) restera pendant une longue période l'option la plus réaliste. Mais le problème avec le paiement à l'utilisation est que la consommation elle-même est imprévisible.
2. L'efficacité du jeton devrait devenir le « troisième critère » pour choisir un modèle
Traditionnellement, les entreprises évaluent les modèles selon deux dimensions : la capacité (peut-il le faire) et la vitesse (le fait-il rapidement). Cet article introduit une troisième dimension tout aussi importante : l’efficacité énergétique (combien cela coûte-t-il pour y parvenir).
Un modèle légèrement moins performant mais trois fois plus efficace peut avoir une valeur économique supérieure dans des scénarios à grande échelle par rapport au modèle « le plus puissant mais le plus coûteux ».
3. L'agent a besoin d'un "indicateur de carburant" et d'un "frein"
L'article mentionne une direction future à surveiller : les politiques d'utilisation d'outils sensibles au budget. En bref, il s'agit d'équiper l'agent d'un « compteur de carburant » : lorsque la consommation de tokens approche le budget alloué, l'obliger à arrêter les explorations inutiles, au lieu de continuer à dépenser sans limite.
Actuellement, presque tous les cadres d'agents principaux manquent de ce mécanisme.
Le problème de "brûler de l'argent" de l'agent n'est pas un bug, mais une douleur inévitable de l'industrie
Cet article révèle non pas une déficience d'un modèle particulier, mais un défi structurel de l'ensemble du paradigme Agent — lorsque l'IA évolue de la réponse simple à une question vers la planification autonome, l'exécution en plusieurs étapes et les ajustements itératifs, la consommation imprévisible de tokens devient presque inévitable.
La bonne nouvelle est que, pour la première fois, quelqu’un a systématiquement mis à jour et analysé ces comptes confus. Avec ces données, les développeurs peuvent choisir plus intelligemment les modèles, fixer des budgets et concevoir des mécanismes de stop-loss ; les fournisseurs de modèles disposent également d’une nouvelle piste d’optimisation — ne pas seulement rendre les modèles plus puissants, mais aussi plus économes.
Après tout, avant que les agents IA n'entrent véritablement dans les environnements de production de dizaines de secteurs, dépenser chaque dollar de manière transparente est plus important que d'écrire chaque ligne de code de manière élégante. (Cet article est publié en premier sur l'application TiMaiT, auteur | Silicon Valley Tech news, éditeur | Zhao Hongyu)
Remarque : Cet article est basé sur l'article préimprimé publié sur arXiv le 24 avril 2026 intitulé *How Do AI Agents Spend Your Money? Analyzing and Predicting Token Consumption in Agentic Coding Tasks* (Bai, Huang, Wang, Sun, Mihalcea, Brynjolfsson, Pentland, Pei). Les auteurs proviennent d'institutions telles que l'Université de Virginie, Stanford, le MIT et l'Université du Michigan. Cette étude n'a pas encore fait l'objet d'une évaluation par les pairs.