









Le modèle est le cerveau d'OpenClaw et influence directement les résultats d'utilisation.
Auteur de l'article : Zhang Haining
Source du texte : Notes de Henry
J'ai récemment essayé plusieurs méthodes d'installation et de déploiement d'OpenClaw : serveurs physiques, machines virtuelles dans le cloud, machines virtuelles, conteneurs, modèles nationaux et internationaux, ainsi que divers réseaux. Dans l'ensemble, cela s'avère assez complexe et comporte de nombreux facteurs à prendre en compte. Je prévois d'écrire un article de synthèse. Celui-ci sert de précurseur et se concentre sur un élément crucial : le choix du modèle.
Le modèle est le cerveau d'OpenClaw et influence directement son efficacité. Actuellement, il est généralement admis que les modèles étrangers sont légèrement plus intelligents que ceux nationaux, mais ils nécessitent un accès Internet avec contournement des restrictions, présentent un coût plus élevé et exigent des moyens de paiement étrangers ; un simple erreur peut entraîner la suspension du compte. Même si des relais offrent des services plus économiques, ils appartiennent à une zone grise et comportent des éléments d'incertitude. Par conséquent, les utilisateurs recherchant une stabilité de service choisissent généralement des modèles nationaux.
Cet article compare l'utilisation et les prix des différents modèles nationaux, et propose quelques recommandations à titre indicatif.
Après que le cadre open source OpenClaw ait connu un succès fulgurant en Chine, il a non seulement provoqué une révolution de la productivité, mais aussi généré des factures choquantes.
Le mode de fonctionnement d'OpenClaw est radicalement différent de celui des IA conversationnelles traditionnelles dans les navigateurs ou les applications. Après qu'un utilisateur ait émis une commande, l'outil déclenche automatiquement des dizaines, voire des centaines, d'appels au modèle pour lire des fichiers, générer du code et déboguer l'exécution, un processus qui consomme des tokens tout au long du parcours.
Une tâche de développement full-stack de complexité moyenne, avec des appels de modèle pouvant s'étendre entre 10 et 40 cycles. En utilisant le modèle phare prenant en charge 200K de contexte, le coût unitaire atteint facilement plusieurs dizaines de yuans.
📊 Calcul du coût réel
À titre d’exemple de tâche de complexité moyenne : OpenClaw déclenche environ 30 conversations, avec une entrée moyenne de 20 000 tokens et une sortie moyenne de 2 000 tokens par conversation, en utilisant un modèle courant (environ 0,005 yuan pour 1 000 tokens d’entrée, 0,02 yuan pour 1 000 tokens de sortie) :
Coût par tâche unique ≈ 30 × (20 000 × 0,005 ÷ 1000 + 2 000 × 0,02 ÷ 1000) = 30 × (0,1 + 0,04) = 4,2 yuans
Les développeurs expérimentés accomplissent 5 à 10 tâches par jour, avec un coût mensuel estimé à 630 à 1 260 yuans. Ce calcul repose sur l'utilisation de modèles de milieu de gamme ; en choisissant un modèle haut de gamme, les frais doubleraient.
Dans ce contexte, les principaux fournisseurs de cloud et entreprises de grands modèles en Chine ont entré sur le marché de manière intensive entre la fin 2025 et mars 2026, en lançant des abonnements « Coding Plan » remplaçant la facturation au token par un forfait mensuel fixe. Ce déclencheur de la guerre des prix a été lancé par Zhipu AI à la fin de 2025 avec le GLM Coding Plan, suivi par Baidu’s BaiLian qui est entré sur le marché avec un seuil extrêmement bas de 7,9 yuans le premier mois, tandis que Tencent Cloud a complété la dernière pièce du puzzle le 5 mars 2026.
Cet article présente une analyse systématique des plans de codage des six principales plateformes nationales, en les comparant selon deux axes : les fournisseurs de cloud (Alibaba Cloud Bailian, Volcano Engine de ByteDance, Tencent Cloud) et les fabricants de modèles (Zhipu GLM, Kimi de Moonshot AI, MiniMax), afin de fournir une référence aux utilisateurs d'OpenClaw.
OpenClaw nécessite d'acheter le plan Coding. Oui, exactement le même modèle d'utilisation que les IDE comme Cursor, Trae, etc., utilisés par les programmeurs, car OpenClaw et Cursor sont fondamentalement des agents. Si vous n'achetez pas le plan Coding (généralement appelé API à l'étranger), l'argent que vous dépensez ne pourra être utilisé que pour accéder aux grands modèles via un navigateur.
(Les modèles étrangers ne sont pas traités dans le présent article)
Fournisseur de services cloud
Les trois grands fournisseurs de cloud : le combat des supermarchés de modèles
La logique centrale du modèle des fournisseurs de cloud est « l'agrégation de plateformes » : regrouper plusieurs modèles de langage open source tels que Qwen, GLM, Kimi et MiniMax dans un même forfait, permettant aux développeurs de basculer librement entre eux avec une seule clé API, sans avoir à recharger séparément sur plusieurs plateformes. Ces forfaits sont facturés en « requêtes » plutôt qu'en prompts, ce qui donne des chiffres apparemment plus élevés, mais doit être interprété en fonction du taux de conversion réel.
Les trois fournisseurs de cloud ont les caractéristiques suivantes :



Fournisseurs de grands modèles
Trois grands fournisseurs de modèles : le choix de la spécialisation en profondeur
Contrairement aux « supermarchés de modèles » des fournisseurs de cloud, le plan modèle original de Coding adopte une approche de « boutique spécialisée » : il ne propose que ses propres modèles, mais ceux-ci ont été profondément optimisés, avec une capacité et une conception de quota plus fines. Ces forfaits utilisent généralement les « Prompts » comme unité de mesure, où 1 Prompt ≈ 15 appels de modèle (selon l'estimation de MiniMax), ce qui donne l'impression de chiffres beaucoup plus faibles, mais permet de gérer un volume de conversation par appel bien plus élevé.



Tableau de comparaison des données principales des plateformes
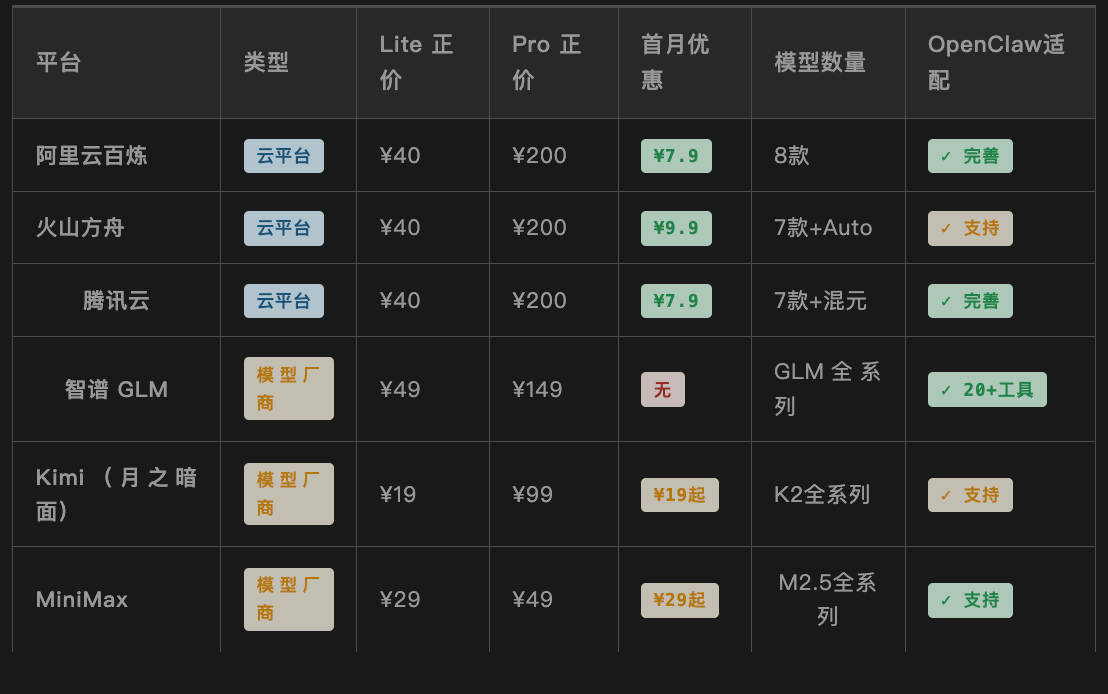
Remarque : Les prix sont basés sur le prix officiel au 31 mars 2026 ; la réduction du premier mois est exclusive aux nouveaux utilisateurs ; les détails sont sujets à la page de commande. Le niveau d'adaptation d'OpenClaw est basé sur l'exhaustivité de la documentation officielle et les retours de la communauté.
Guide pour éviter les pièges
Décryptage de la structure des frais : la vérité derrière les chiffres
Le plus grand obstacle à l'information sur le marché réside dans le fait que chaque plateforme utilise des unités de mesure totalement différentes ; comparer directement les chiffres n'a aucun sens. Cette section présente les trois points clés de facturation pour vous aider à prendre une décision éclairée avant d'acheter.
1. Les unités de mesure ne sont pas uniformes
Sur le marché actuel, deux systèmes coexistent : les fournisseurs de cloud (Alibaba Cloud, Volcano, Tencent) facturent en « requêtes », tandis que les fournisseurs de modèles (Zhipu, MiniMax) facturent en « Prompts ». Le rapport de conversion clé est : 1 Prompt ≈ 15 appels de modèle.
La facturation est basée sur les cycles d'interaction initiés par l'utilisateur : une question, quel que soit le nombre d'appels de modèle effectués en arrière-plan, ne consomme qu'une seule unité. Ce modèle de facturation par nombre d'interactions est typique des fournisseurs de cloud traditionnels, qui facturent selon le nombre d'appels API ; dans ce cas, une question utilisateur déclenchant plusieurs appels de modèle entraînera plusieurs déductions. Le premier modèle est plus favorable aux agents comme OpenClaw, qui effectuent de nombreux appels en arrière-plan, car il permet une prévisibilité des coûts. Le second modèle facture strictement selon le nombre réel de requêtes, ce qui peut entraîner des factures imprévues dues à des appels internes.
Les deux méthodes sont adaptées aux utilisateurs occasionnels d'OpenClaw, car elles ne prennent pas en compte les tokens, ne comptent que le nombre d'occurrences, et sont plafonnées mensuellement, éliminant ainsi l'anxiété liée aux tokens.
2. Exemples de conversion
Le forfait Alibaba Cloud Bailian Pro offre 90 000 requêtes par mois, équivalent à environ 6 000 prompts.
Le forfait ZhiPu GLM Lite offre environ 120 invites toutes les 5 heures, soit environ 1 800 requêtes.
Ainsi, « 90 000 » et « 120 » ne sont pas des chiffres directement comparables.
3. La fenêtre glissante / 5 heures sont le véritable goulot d'étranglement
Presque toutes les plateformes imposent une limite de « 5 heures par période », et ce chiffre est l’indicateur clé déterminant votre capacité à développer intensivement en continu, et non le quota mensuel total. La fenêtre de 5 heures fonctionne selon un mécanisme de récupération décalée (non fixée sur des plages horaires naturelles) : si vous commencez à 14h00 et que votre quota est épuisé à 15h00, vous devrez attendre jusqu’à 19h00 pour récupérer votre premier lot de quota. Il est très facile de atteindre la limite en développant continuellement pendant 2 à 3 heures pendant la période de pointe de l’après-midi.
4. Règles de dévalorisation cachées de Zhipu GLM-5
Le plan de codage GLM de Zhipu contient une règle exclusive : pendant les heures de pointe (14:00 à 18:00 UTC+8), le nombre d'utilisations réelles de GLM-5 n'est que d'un tiers de celui des heures creuses. Aucune autre plateforme n'applique cette règle ; veillez à bien prendre en compte vos heures d'utilisation principales lors de votre achat.
5. Les remboursements et les résiliations ne sont pas autorisés
Toutes ces plateformes stipulent explicitement qu'aucun remboursement ni annulation n'est possible après l'abonnement. Veuillez confirmer vos besoins avant d'acheter. Il est recommandé aux nouveaux utilisateurs de commencer par l'offre à prix réduit du premier mois plutôt que d'opter directement pour un abonnement annuel.
Guide d'achat réservé aux utilisateurs d'OpenClaw
OpenClaw, en tant que cadre d'agent autonome, présente des exigences spécifiques supérieures à celles des plugins IDE classiques pour le Coding Plan : une tolérance élevée aux appels simultanés, une capacité stable de traitement de contextes longs, ainsi qu'une compatibilité native avec le protocole Anthropic (car OpenClaw est conçu sur la base du protocole Claude). Voici des recommandations détaillées classées par scénario d'utilisation.
🌱 Type débutant pour essayer
Recommandé : Alibaba Cloud Bailian Lite au premier mois pour 7,9 ¥ (plus disponible) ou Tencent Cloud au premier mois pour 7,9 ¥
Première expérience avec Coding Plan, souhaitant tester le processus complet d'OpenClaw au moindre coût. La diversité des modèles de Bailian (8 modèles) permet de découvrir en parallèle Qwen, GLM-5 et Kimi dans un seul forfait, facilitant ainsi la construction rapide d'un jugement intuitif. Actuellement, Alibaba Cloud ne propose que le forfait Pro à 200 ¥/mois, tandis que Tencent Cloud propose encore des forfaits Lite à 7,9 ¥ et 40 ¥ ; cependant, les utilisateurs rapportent que les stocks sont épuisés en quelques secondes, et il est probable que seul le forfait à 200 ¥/mois soit facilement accessible.
💼 Développement quotidien
Recommandé : MiniMax Plus à 49 ¥/mois
Des tâches de programmation fixes quotidiennes, mais sans utilisation continue et intensive. Le forfait Starter de MiniMax, avec une réponse ultra-rapide (101 tokens/s) et sans limite hebdomadaire, est idéal pour un rythme de développement fragmenté mais fréquent.
⚡Type continu intensif
Recommandé : Tencent Cloud ou Alibaba Cloud Pro à 200 ¥/mois
Développement continu de plus de 6 heures par jour, nécessitant la gestion d'une grande base de code et de flux de travail Agent complexes. Le quota mensuel de 90 000 utilisations et le quota de 6 000 utilisations par fenêtre de 5 heures de Tencent/Bailian Pro constituent une solution globalement optimale en termes de rapport qualité-prix et de stabilité sur les plateformes cloud.
🎨 Frontend / Multimodal
Recommandé : Kimi Moderato ¥99/mois
Il est fréquemment nécessaire d’importer des captures d’écran de maquettes ou des croquis d’interface utilisateur dans l’IA pour analyser et générer du code. Kimi-K2.5 est le seul forfait d’origine sur le marché Coding Plan à prendre en charge les entrées multimodales par capture d’écran, idéal pour les scénarios frontend et Vibe Coding.
🔬 Ingénierie complexe
Recommandé : ZhiPu GLM Pro à 149 ¥/mois
Gestion de scénarios nécessitant des capacités de modèle de haut niveau, tels que les projets monolithiques volumineux, l'ordonnancement complexe d'agents et les tests automatisés à haute concurrence. Avec une taille de 754 milliards de paramètres, GLM-5 est le modèle open source le plus volumineux en Chine, avec des compétences en codage proches de celles de Claude Opus. Les coûts à long terme peuvent être réduits davantage grâce à un forfait annuel à 30 % de remise.
Summary
Stratégie d'achat
Le marché du Coding Plan en 2026 est entré dans une phase de concurrence acharnée. Les principaux bénéficiaires de la guerre des prix sont les développeurs et les utilisateurs : il est désormais possible d'expérimenter plusieurs des meilleurs modèles pour moins de 10 yuans le premier mois, ce qui était impensable il y a un an.
Cependant, la baisse du seuil d'admission des forfaits ne signifie pas une réduction de la complexité du choix : les différences d'unités de mesure, les règles de plafond cachées et la tendance à la hausse des prix sont des variables à prendre en compte sérieusement.
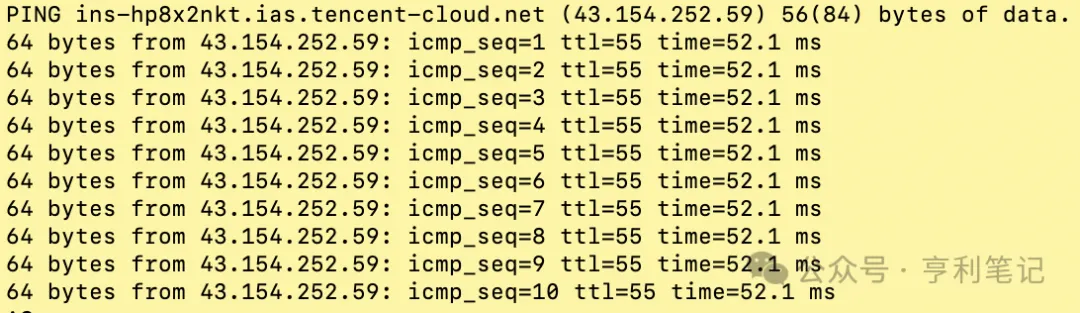
Un autre point important est de vérifier quel service de modèle de grande taille est le plus rapide à atteindre depuis la machine OpenClaw. La méthode la plus simple consiste à utiliser la commande ping sur la machine OpenClaw pour examiner la latence réseau et les pertes de paquets.
Par exemple, il s'agit de vérifier la connectivité réseau entre l'hôte OpenClaw et le point de terminaison Tencent Cloud, en surveillant si des paquets icmp_seq sont perdus et si la latence time est faible :
$ ping api.lkeap.cloud.tencent.com
Selon l'analyse précédente, nous résumons comme suit :

📌 Dernier rappel
Les données du présent document sont à jour au 31 mars 2026. Étant donné que les politiques de prix des différentes plateformes sont fréquemment ajustées (par exemple, Zhipu a augmenté ses prix et Alibaba Cloud Bailian Lite a cessé les nouvelles ventes), veuillez toujours vous référer aux dernières annonces officielles de chaque plateforme avant d'effectuer un achat. Les forfaits ne sont pas remboursables. Il est recommandé de commencer par le forfait à prix réduit du premier mois pour vérifier la compatibilité des outils et vos habitudes d'utilisation avant de planifier un engagement à long terme.
La prochaine fois, nous aborderons les différents compromis à prendre en compte lors du déploiement d'OpenClaw.