










Auteur : Max, toujours en route, 01Founder
Si l'on devait établir un bilan intermédiaire pour OpenAI en 2025, beaucoup le décriraient comme plat, voire légèrement passif.
Au cours de la dernière année, ils ont effectivement suivi une démarche méthodique pour mettre en œuvre la chaîne de raisonnement, publiant intensément des modèles d'inférence allant de o3pro à o4mini, tout en lançant de nouveaux modèles de base tels que GPT-4.5 et GPT-5.
Mais dans le domaine de la génération visuelle, le plus facilement perceptible par les utilisateurs ordinaires et le plus propice à la propagation spontanée, leur présence s'affaiblit progressivement.
Après l'effet de surprise initial de Sora, OpenAI semble entrer dans une longue période de silence sur ce créneau.
En attendant, les autres joueurs à la table n'ont pas été inactifs.
Dans l'écosystème open source, des modèles comme Flux ont complètement aboli les barrières à la génération d'images locales de haute qualité ;
Sur le plan professionnel, non seulement les anciens concurrents maintiennent des barrières esthétiques extrêmes, mais de nouveaux acteurs comme Nano-banana, dotés d'une fonction de recherche en ligne intégrée, émergent également.
En comparaison, le précédent modèle principal d'OpenAI pour la génération d'images, GPT-Image-1.5, semble déjà dépassé :
La qualité d'image est médiocre, la mise en page rigide, et le système plante fréquemment face à des textes complexes.
Progressivement, un consensus s'est établi dans l'industrie :
OpenAI rencontre un obstacle technique dans le domaine de la génération visuelle et semble de plus en plus dépassée face à la concurrence.
Jusqu'à ces dernières semaines, le point de retournement est apparu de manière très discrète.
Sur la plateforme d'évaluation aveugle de grands modèles renommée LM Arena, un modèle d'image mystérieux portant le code Duct Tape s'est glissé discrètement.
Les utilisateurs participant à l'essai aveugle ont rapidement remarqué que quelque chose n'allait pas :
Ce modèle maîtrise avec une précision extrême les formats extrêmes et génère sans défaut des affiches comportant un grand nombre de textes multilingues, comme s'il existait un processus de planification logique invisible avant la génération de l'image.
Pendant un moment, les différentes communautés techniques ont spéculé sur quelle entreprise avait secrètement lancé cette fonctionnalité, mais OpenAI est resté silencieux.
Ce matin, la botte est enfin tombée.
Pas de présentation longue, pas de campagne de marketing massive : OpenAI a officiellement nommé le modèle codé « Gaffer Tape » ChatGPT GPT-Image-2 et l’a lancé sur le marché.
Avec cela, un classement de l'arène Text-to-Image, quelque peu étouffant, a également été publié.
GPT-Image-2 obtient un score record de 1512 et prend directement la première place, devançant le deuxième (le Nano-banana-2 avec fonction de recherche en ligne) de 242 points.
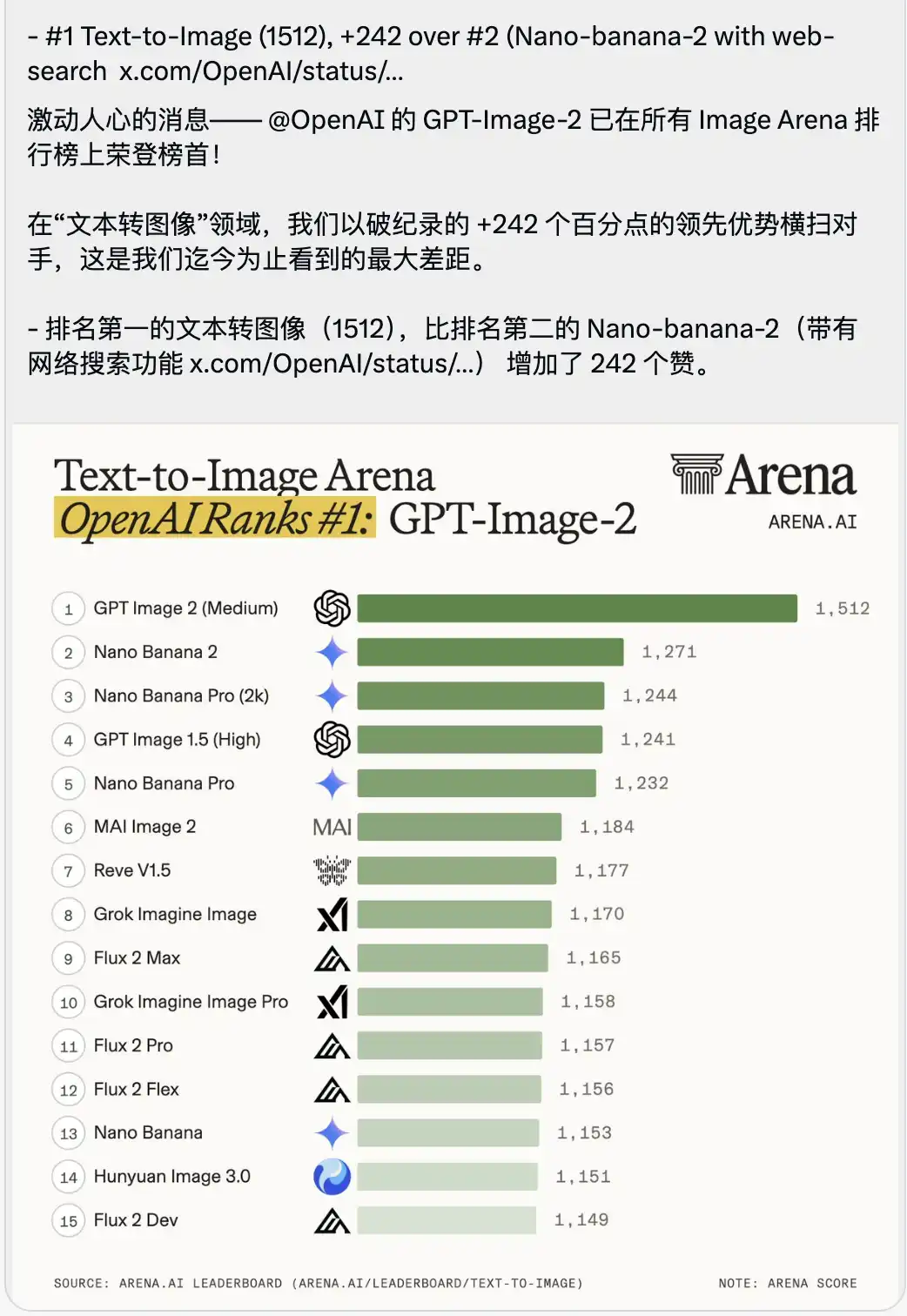
Dans le contexte des benchmarks de grands modèles, les gens mettent souvent en avant des dépassements de quelques dixièmes ou unités, les modèles leaders étant extrêmement proches en termes de scores.
Un écart de 242 points est sans précédent dans l'histoire de l'arène.
Ce n'est pas du tout une petite mise à jour de version, c'est une écrasement brutal de génération.
J'ai passé une bonne partie de la journée à examiner en détail ses différentes capacités极限 et la dernière documentation de l'API.
La sensation la plus forte est une seule :
OpenAI reste le même OpenAI.
Lorsqu'il a décidé de reprendre ce qu'il avait perdu, il l'a fait en renversant directement l'ancienne table de jeu.
Devant ce modèle, les tâches de conception visuelle que nous pensions encore nécessiter deux à trois ans avant d’être entièrement remplacées par l’IA sont aujourd’hui essentiellement terminées.
PART.01 Génération d'images, du modèle à l'agent visuel
Pour comprendre pourquoi GPT-Image-2 peut obtenir un écart de score aussi impressionnant, il faut d'abord abandonner les idées reçues sur les modèles de génération d'images à partir de texte.
Avant, lorsque nous utilisions l'IA pour créer des images, c'était essentiellement comme tirer une loterie : nous entrions quelques mots-clés et attendions qu'elle arrange les pixels selon ce que nous voulions.
Mais GPT-Image-2 ressemble davantage à un agent intégrant un moteur visuel.
Le changement le plus évident est qu'il distingue directement deux modes complètement différents au niveau du mécanisme.
Un mode instantané ouvert à tous les utilisateurs.
Ce modèle met l'accent sur une réponse ultra-rapide et une intégration fluide dans les flux de travail et de vie.
Par exemple, si vous lui envoyez une commande depuis votre téléphone, il peut vous fournir en quelques secondes une image structurée et complète.
Ses capacités de compréhension visuelle sous-jacentes sont extrêmement puissantes, mais elle répond principalement à des besoins de conversion visuelle fréquents et ponctuels.
Le mode réflexion (Thinking Mode) accessible aux utilisateurs payants.
Avant même de commencer à rendre un seul pixel, il effectue d'abord une série de raisonnements logiques et de recherches en ligne d'une durée de plusieurs secondes.
C'est précisément ce modèle qui résout une proposition extrêmement centrale mais également extrêmement difficile :
Le modèle a su pour la première fois ce qu'il devait dessiner.
Voici un exemple le plus direct.
Tapez dans la boîte de dialogue :
Créez une affiche : recherchez en ligne les avis des utilisateurs sur le modèle mystérieux Duct Tape, et incluez le code QR de ChatGPT.

Avec le modèle précédent, il ne comprenait pas du tout ce que les internautes avaient dit ; il ne faisait que générer une affiche avec des caractères aléatoires et un code QR qui était une fausse image non scannable.
Mais en mode réflexion, son flux de travail est le suivant :
Il suspendra d'abord le dessin, lancera un outil de recherche en ligne pour récupérer les avis réels des internautes sur Reddit, Threads ou LinkedIn ;
Ensuite, il a commencé à planifier la mise en page, les espaces blancs et la hiérarchie typographique de l'affiche ;
Enfin, il génère un code QR réel et fonctionnel, directement scannable pour un accès instantané, et rend l’image complète.

Ce n'est plus seulement une question de dessin, c'est en réalité un travail complet qui inclut la recherche autonome, la planification, l'extraction de texte et la conception de mise en page.
Un comparatif parallèle est nécessaire ici.
Tous ceux qui suivent la communauté des grands modèles savent que les modèles de génération d'images avec capacité de connexion et de recherche ne sont pas une首创 d'OpenAI.
Le Nano-banana en deuxième position du classement possédait déjà ce mécanisme.
Mais lors de l'utilisation réelle de Nano-banana, vous constaterez qu'il semble un peu lourd à de nombreux endroits.
La réflexion de Nano-banana est souvent une logique mécanique de assemblage.
Par exemple, si vous lui demandez de rechercher une tendance sectorielle pour créer une affiche, il effectue effectivement la recherche, mais il se contente généralement de copier littéralement des phrases de Wikipédia et de les coller artificiellement sur l’image.
Il panique facilement lorsqu'il est confronté à des instructions nécessitant l'interprétation de demandes commerciales abstraites.

C’est comme un stagiaire qui comprend les instructions mais n’a aucune expérience pratique, qui sait exécuter mais ne comprend absolument pas la stratégie.
Mais la performance de GPT-Image-2 dans ce domaine ne peut être décrite que comme exagérée.
Sa réflexion ne se limite pas à une formalité, mais comprend véritablement le contexte culturel et les intentions commerciales sous-jacents.
During testing, I entered a minimal Chinese instruction: Help me take a screenshot of Musk live-streaming on TikTok to sell Doubao.
Avec les modèles de génération d'images précédents, il est très probable que vous obtiendriez une image d'un homme blanc ressemblant à Musk tenant un baozi, avec un arrière-plan flou, voire sans aucune idée de ce à quoi ressemble TikTok.
Mais en mode réflexion, les résultats de GPT-Image-2 sont un peu inquiétants.
Il n'a pas simplement assemblé des éléments, mais a automatiquement mobilisé sa compréhension de l'internet chinois pour générer une capture d'écran de l'interface d'une salle de diffusion Douyin, parfaitement reproduite au niveau des pixels.
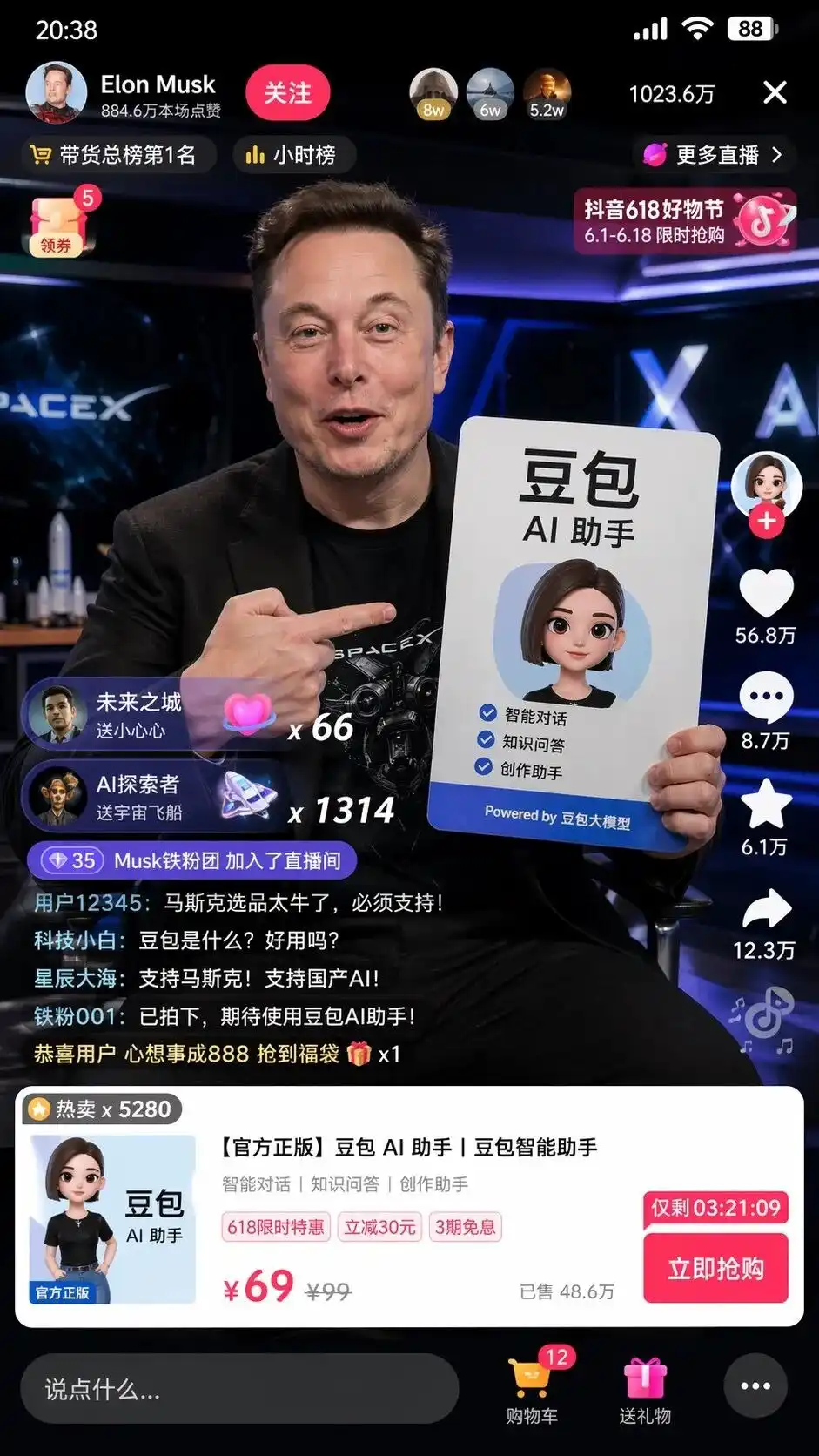
L’écran montre non seulement un Musk réaliste tenant une pancarte publicitaire pour l’assistant AI DouBao avec une mise en page parfaite, mais aussi des détails encore plus effrayants qui n’étaient pas mentionnés dans le prompt :
Le bouton d'abonnement en haut à gauche, le classement horaire, les 10,236 millions d'utilisateurs en ligne en haut à droite, la carte produit déroulante en bas, ainsi que le prix barré à 99, le prix promo à 69 et le bouton d'achat immédiat avec compteur à rebours.
Ce qui est le plus glaçant, c’est le fil de commentaires en bas à gauche, extrêmement réaliste :
Novice en technologie : Qu'est-ce que DouBao ? Est-ce utile ?
Étoiles et mers lointaines : soutenons Musk ! Soutenons l'IA nationale !
Personne ne lui a dit quoi écrire dans les commentaires, à quoi devait ressembler l’interface produit, ou comment fixer les prix.
Ceci est la conception d'interface utilisateur et la stratégie opérationnelle complètes, imaginées et exécutées par le modèle après analyse des tags « vente sur Douyin » et « grand modèle DouBao ».
Les critères d'évaluation des grands modèles en génération d'images franchissent à présent le cap de la simple capacité à produire des images esthétiques pour atteindre la compréhension des stratégies et de la logique de mise en page.
PART.02 Capacités principales testées en conditions réelles
Pour en tester les limites, j'ai utilisé plusieurs scénarios fréquents et complexes selon les normes de conception commerciale.
Il s'est avéré que la granularité avec laquelle il résout les problèmes est allée jusqu'à un niveau effrayant.
Premier scénario : compréhension visuelle et boucle métier (habiller le mannequin)
Dans les visuels traditionnels de commerce électronique ou la planification mode, le coût d'exécution entre l'idée et la visualisation sur le corps est très élevé.
Vous cherchez un mannequin, à emprunter des vêtements, à monter un studio photo et à faire une retouche photo professionnelle.
Ensuite, avec l'arrivée de l'IA, les gens ont commencé à entraîner des modèles LoRA pour stabiliser les traits du visage, mais cela nécessitait toujours des dizaines d'images comme support et un coût d'apprentissage important.
Dans GPT-Image-2, ce processus a été extrêmement optimisé.
J'ai essayé de télécharger une de mes photos de tous les jours, en lui disant que je partais en vacances à l'île le mois prochain, pour qu'il m'aide à choisir quelques tenues.
Il m'a d'abord présenté 8 séries de catalogues de vêtements d'été, chacune dans un style totalement différent, avec une mise en page qui ressemble à un lookbook professionnel, et chaque pièce est accompagnée d'une étiquette textuelle correcte.
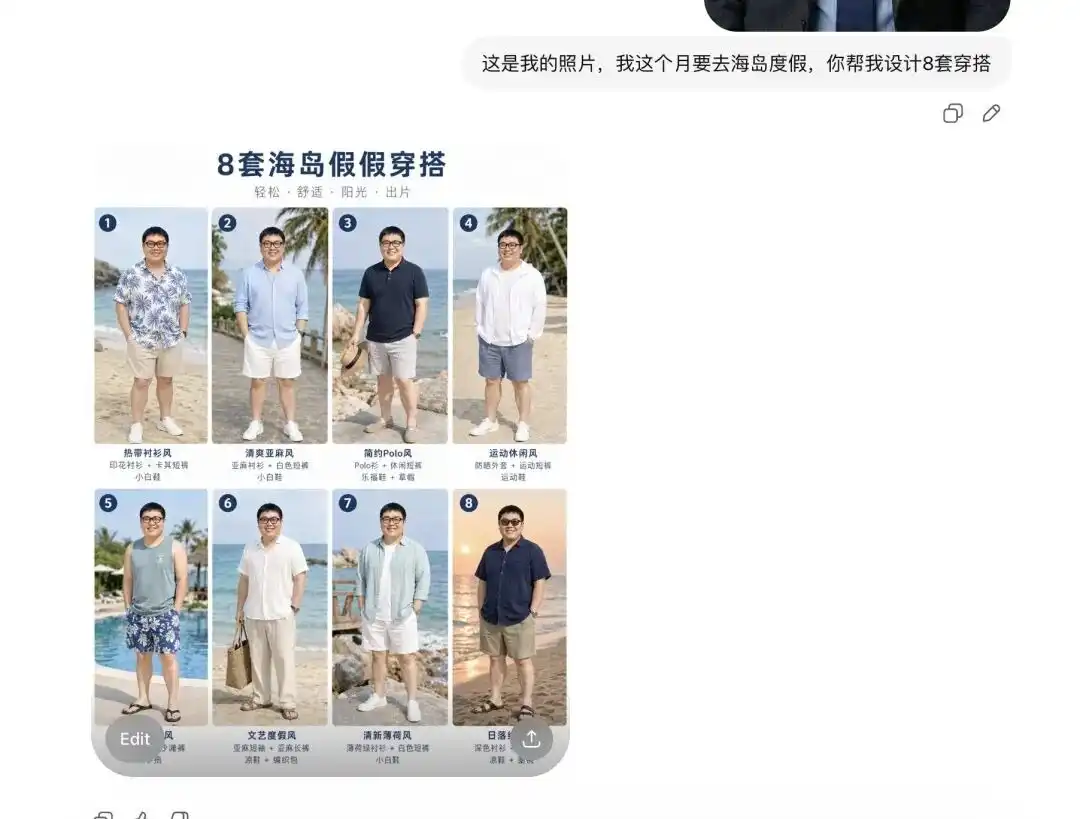
Plus important encore, il a immédiatement analysé avec précision mes traits du visage et mes proportions corporelles.
Lorsque je lui ai dit que je voulais voir à quoi ressemblait la première tenue sur moi et lui demander plusieurs images détaillées sous différents angles, il a directement extrait la personne sur ma photo personnelle, lui a remplacé les vêtements par cette tenue d'été, et a généré des images sous différents angles, comme de côté et à mi-corps.

Cette transition est extrêmement fluide. Cela signifie que le fossé protecteur des rendus de tenues de base ou des travaux externalisés de essayage avec des mannequins a été complètement éliminé.
Deuxième scénario : résoudre la cohérence et la narration continue (génération d'une bande dessinée en une phrase)
Ceux qui ont déjà utilisé la génération d'images par IA savent qu'il n'est pas difficile de faire dessiner à l'IA une belle image, mais il est difficile de lui faire produire dix images de la même personne avec des mouvements et des angles de vue cohérents.
C'est ce qu'on appelle le problème de la cohérence (Consistency).
Mais lors de ce test pratique, j'ai observé un cas extrêmement contraire à mon expérience passée.
Vous pouvez télécharger une seule photo prise hier avec un ami, puis saisir un prompt extrêmement simple :
Transformez-nous en personnages principaux, dessinez trois bandes dessinées japonaises de trois pages chacune, avec un scénario de votre choix.
Quelques secondes plus tard, il a directement généré trois pages de bande dessinée en noir et blanc avec des planches standards.
L'endroit le plus effrayant est que ces deux personnages de bande dessinée générés à partir de personnes réelles apparaissent dans des plans différents sur trois pages.

Que ce soit un plan rapproché, une course en plan large, ou un dos, même les traits du visage, les détails des cheveux et les plis des vêtements, tout reste parfaitement cohérent.
Plus encore, l'intrigue de la bande dessinée est complètement cohérente, et même les textes dans les bulles forment une logique narrative complète.

La capacité à assurer la cohérence dans le temps et l'espace indique qu'elle a dépassé le cadre de la génération d'images individuelles et possède désormais les compétences d'un réalisateur capable de raconter une histoire continue.
Troisième scénario : franchir le dernier seuil du rendu textuel (mise en page multilingue)
Si la cohérence résout le problème narratif, alors la rendu précis du texte multilingue pousse les graphistes à bout.
Avant, dès que le graphique contenait un peu de texte, le grand modèle se mettait à dessiner des tracés absurdes.
Parce que le modèle comprend le texte sous forme de jetons (blocs sémantiques), tandis que les images générées sont composées de pixels, ces deux éléments étaient autrefois séparés.
GPT-Image-2 a résolu définitivement cette question.
J'ai généré une couverture de magazine de mode en français, une carte de restaurant japonais remplie de kana hiragana et de kanji, et même des annotations russes avec une densité de mise en page extrêmement élevée.

Le résultat est une production unique, sans aucune erreur d'orthographe.
Ce qui est le plus désespérant, c’est qu’il non seulement écrit correctement les caractères, mais qu’il sait également adapter la esthétique culturelle locale et la conception typographique en fonction de la langue.
Par exemple, les idéogrammes dans la brochure japonaise utilisent une police artistique rétro typiquement japonaise, et la disposition des kana hiragana respecte la lecture verticale traditionnelle du japonais.
La mise en page était autrefois un domaine réservé aux graphistes.
Ajuster l’espacement des lettres, déterminer les hiérarchies visuelles et établir un équilibre entre le texte et l’arrière-plan nécessitent beaucoup de pratique.
Mais lorsque l'IA peut traiter autant de langues sans aucune erreur, tout en intégrant une esthétique de mise en page avancée, les affiches quotidiennes, les dépliants et les publicités en flux d'information n'auront plus besoin d'être alignées manuellement avec des lignes de référence.
Quatrième scénario : Format déformé et contrôle microscopique extrême (gravure sur un grain de riz)
Enfin, pour voir à quel point son obéissance était impressionnante, je lui ai donné plusieurs instructions très exigeantes.
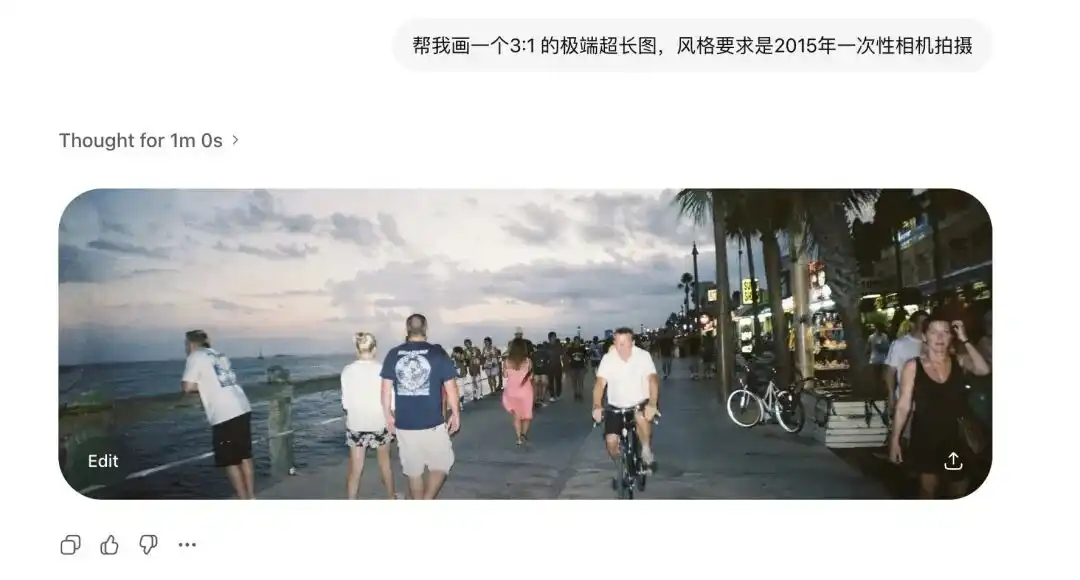
J'ai d'abord testé son format extrême.
Les modèles de diffusion traditionnels craignent extrêmement les proportions non standard.
Avant, quand on étirait légèrement l'image, deux têtes apparaissaient à l'écran.
Mais j'ai demandé à Images 2.0 de générer des images ultra-larges 3:1 et des images verticales longues 1:3 ; non seulement elles n'ont pas été déformées, mais elles ont même produit une image panoramique 360 degrés avec une boucle logique reliant les extrémités.
Après avoir ajouté les termes issus des appareils photo jetables de 2015, même les distorsions des anciens objectifs et les réflexions de mauvaise qualité de l'éclairage sur le mur sont fidèlement reproduites.
Un autre exemple qui illustre mieux son contrôle microscopique est le test de grain de riz légèrement fou présenté par l'entreprise lors de la conférence de lancement.
Les chercheurs ont appelé l'API expérimentale 4K encore en test interne, sans ajouter de termes comme photographie macro ou ultra-haute définition 8K, se contentant d'une instruction extrêmement abstraite en langage simple :
Un tas de riz. Sur un seul grain de riz de ce tas, il est écrit GPT Image 2.
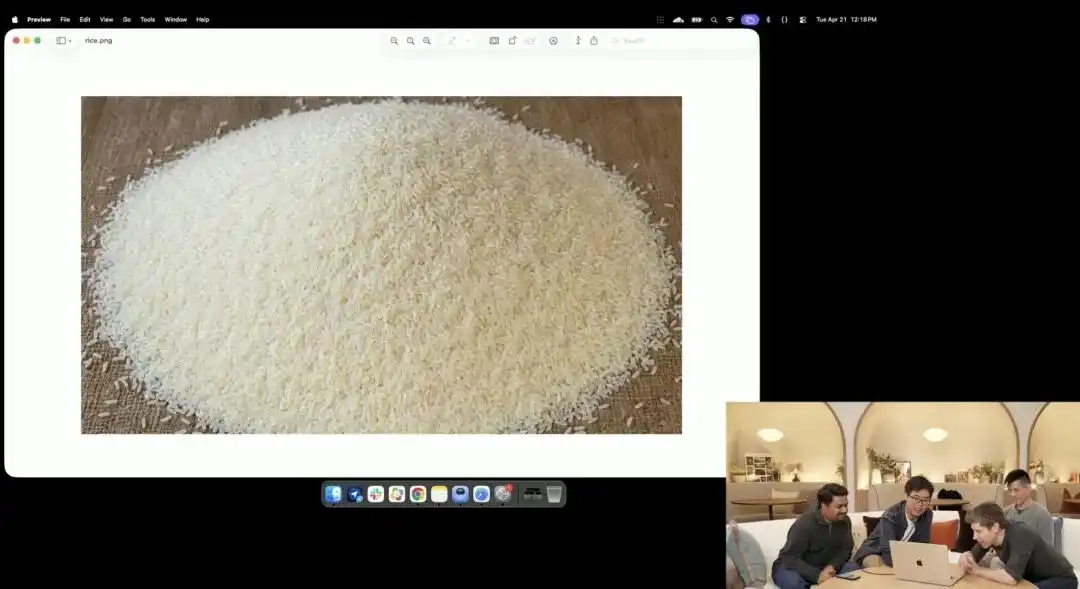
Lorsque l'image est agrandie des dizaines de fois sur l'écran, voire devient pixelisée, pouvez-vous vraiment trouver ce grain microscopique gravé parmi une montagne de riz ?
La texture de ce riz respecte toujours les lois physiques, et le texte est précisément incrusté le long des courbes minuscules des grains.
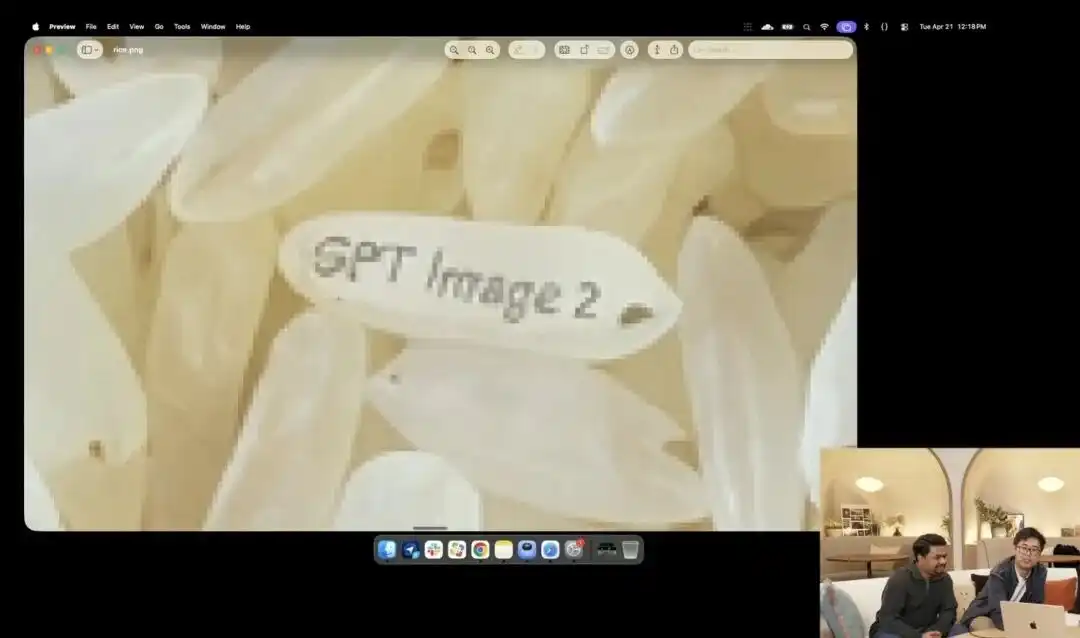
Tout le reste du travail — appeler le point de vue macro, calculer la profondeur de champ, trouver les coordonnées physiques du grain de riz dans l'espace latent et y imprimer les caractères — a été automatiquement imaginé et accompli par le grand modèle en mode réflexion.
Ce cas illustre de manière intuitive que le modèle comprend la position spatiale avec une précision chirurgicale au niveau du pixel.
Cela signifie que, dans le travail pratique à l'avenir, vous pourrez modifier avec précision n'importe quelle petite partie du design, cibler exactement ce que vous voulez modifier, au lieu de devoir, comme auparavant, modifier un col et se retrouver avec l'ensemble de l'image qui change.
PART.03 Quelques détails techniques
Ce niveau extrême de contrôle et d'intelligence stratégique ne peut certainement pas être obtenu simplement en accumulant aveuglément de la puissance de calcul.
Pour comprendre quelles sont ses cartes maîtresses, j'ai effectué quelques tests de sonde sur GPT-Image-2.
Un point très intéressant a été découvert.
Bien que la documentation officielle affirme que la date de référence de la base de connaissances globale de GPT-Image-2 a été mise à jour à décembre 2025, lors de mes tests pratiques.
La date de fin des données d'entraînement du mode instantané (Instant Mode) reste au fin mai 2024 ;

Le mode de réflexion (Thinking Mode), qui nécessite une réflexion approfondie, dispose d'une base de connaissances native datant environ de juin 2024 (mais peut obtenir la date actuelle grâce à une connexion en temps réel).

En remontant à ces deux points dans le temps, il semble y avoir des indices sur la base de GPT-Image-2.
Commencez par le mode instantané, axé sur la production fréquente d'images.
La date limite de mai 2024 suggère qu'il s'agit probablement d'une utilisation directe de o4-mini, ou d'une version légère de la famille GPT-5 (GPT-5 mini ou même une version aux paramètres extrêmement réduits, GPT-5 nano).
C’est précisément parce que ces fondations légeres possèdent déjà une excellente capacité de planification spatiale et de compréhension d’instructions complexes que la génération d’images en couche supérieure peut rester stable et ne pas se désorganiser.
Et ce mode de pensée extrêmement intelligent, axé sur la stratégie commerciale, ne peut pas être fondé sur le modèle principal GPT-5.
La base de connaissances de base de GPT-5 est mise à jour jusqu'en septembre 2024.
Le mode réflexion est très probablement connecté au modèle d'inférence de la série O en itération constante en arrière-plan (par exemple, o4 ou une version mise à jour de o3).
Le grand modèle utilise d'abord le mécanisme de réflexion prolongée spécifique à la série O, calculant précisément dans l'espace latent la logique commerciale, la psychologie du public cible et les coordonnées de mise en page, avant de transmettre le tout au module visuel pour le rendu final des pixels.
Bien sûr, il existe également un autre chemin possible :
Sous le mécanisme de répartition extrêmement précis des ressources de calcul au sein d'OpenAI, le mode rapide pourrait utiliser directement GPT-5 nano comme solution de secours, tandis que le mode réflexion utilise un GPT-5 mini légèrement plus puissant associé à des outils externes.
Mais quel que soit le combo de base, si vous suivez l'écosystème API d'OpenAI, vous constaterez que sa logique de génération sous-jacente n'est plus du tout au même niveau que celle de Midjourney.
PART.04 Le prix qui intéresse le plus les gens
Mais plutôt que de deviner le prix de base, ce qui intéresse davantage les développeurs et les entreprises qui souhaitent réellement l’intégrer à leur flux de travail, c’est la table de tarification API extrêmement réaliste et contre-intuitive.
Auparavant, DALL-E 3 était facturé à l'unité (par exemple, 0,04 $ par image).
Mais depuis la première génération GPT-Image-1, OpenAI l'a complètement transformé en un modèle de facturation par Token.
GPT-Image-2 maintient toujours cette norme, et en plus, il propose une offre améliorée à prix réduit.
Selon le tableau de prix publié récemment par l'officiel, le prix par million de tokens est le suivant.
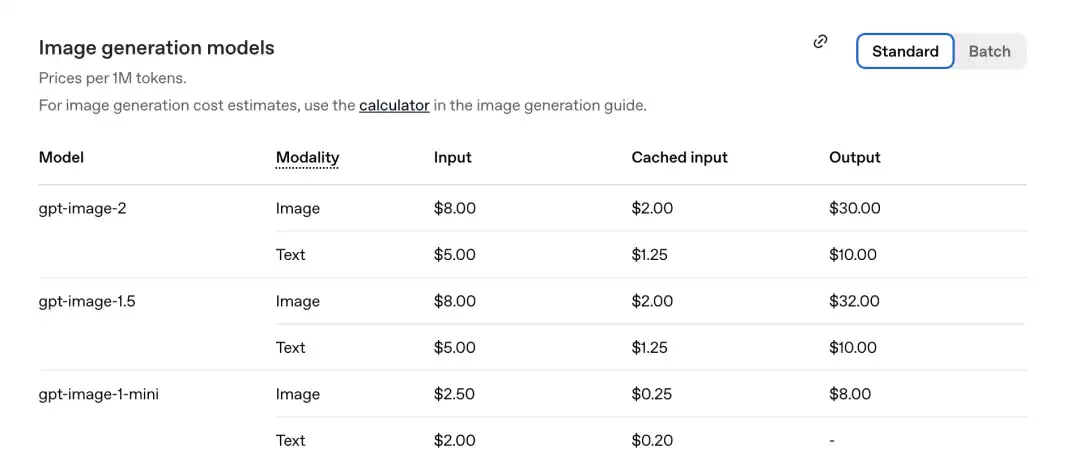
GPT-Image-2 Section image : entrée 8,00, entrées en cache (Cachedinputs) 2,00, sortie 30,00 $
Comparé à la génération précédente gpt-image-1.5 : le coût est de 32,00 $.
Le nouveau modèle est en fait moins cher.
Calculons cela.
Dans les modèles précédents, générer une image de haute qualité consommait environ 1000 à 1500 tokens de sortie.
À un prix de 30 dollars par million de tokens générés, le coût réel de la création d'une image se situe entre 0,03 et 0,045 dollar (environ 2 à 3 cents de yuan chinois).
Si vous n'avez pas besoin de réponses en temps réel et utilisez plutôt le mode API Batch fourni officiellement, ce prix sera encore divisé par deux (le coût descendra directement à 15,00 $).
Au total, la génération d'une image coûte juste un peu plus de 0,1 yuan.
Ce prix unitaire est déjà très compétitif, mais son véritable atout réside dans l'entrée mise en cache (Cached inputs) du tableau de tarification.
Auparavant, lors de la création de bandes dessinées ou de la conception de posters d'une même série, chaque nouvelle génération nécessitait de télécharger à nouveau de nombreuses images de référence, des résumés précédents et de longs prompts, ce qui impliquait un coût d'entrée très élevé.
Mais dans le modèle de facturation par jeton actuel, lorsque vous lui demandez de générer huit bandes dessinées consécutives en une seule fois, les éléments visuels de la première image sont directement mis en cache comme contexte.
À partir de la deuxième image, le coût d'entrée de l'image est tombé directement de 8,00 $ à 2,00 $ (soit seulement 25 % des frais).
Cela signifie que, lors de la production en gros ou de la génération continue exigeant une très grande cohérence des personnages, son coût marginal diminue considérablement.
Plus le modèle est intelligent et plus il génère d'images, plus le coût moyen par image diminue.
C'est ce type de logique de facturation industrialisée qui pousse véritablement les dessinateurs de chaîne de production à bout.
PART.05 Découverte de l'équipe en coulisses
Enfin, revenons sur l'équipe visuelle de rêve d'OpenAI qui a effectué une démonstration en direct lors de cette conférence de lancement : de nombreuses fonctionnalités que l'on jugeait absurdes deviennent maintenant parfaitement compréhensibles.
Par exemple, comment résout-il précisément les défis complexes de mise en page multilingue et les caractères illisibles ?
Cela ne serait pas possible sans le scientifique chevronné de l'équipe, Gabriel Goh.

Dans ce milieu académique, il est le plus connu comme l'un des auteurs principaux du modèle multimodal révolutionnaire CLIP.
CLIP a posé les fondements de la compréhension contemporaine de la correspondance entre le langage humain et les pixels d'images par l'IA.
Avec ce spécialiste en cartographie sémantique intermodale à la tête du projet, GPT-Image-2 ne devine plus les formes des lettres au hasard, mais écrit véritablement au niveau des pixels.
Par exemple, comment comprend-il les relations spatiales en trois dimensions, peut-il même créer des images panoramiques 360 degrés avec des rapports d'aspect extrêmes, et comprend-il les jeux d'ombre et de lumière en macro sur un grain de riz ?
Cela est dû à un autre membre clé, Alex Yu.

Avant de rejoindre OpenAI, il était cofondateur et ancien CTO de Luma AI, une startup émergente réputée dans le domaine de la génération 3D, ainsi qu'un chercheur de premier plan spécialisé dans le rendu neuronal 3D (comme NeRF).
Avec lui, GPT-Image-2 a déjà dépassé le traditionnel peinture de pixels 2D.
Il a probablement d'abord créé mentalement une scène tridimensionnelle, positionné les lumières, puis vous a rendu une tranche 2D précise.
Comment a-t-on réussi à maintenir une cohérence aussi impressionnante sur une bande dessinée de plusieurs pages ?
Cela correspond à la jeune équipe venant tout juste de terminer ses études à MIT CSAIL :
Boyuan Chen (à gauche) et Kiwhan Song (à droite).
Leur orientation principale dans le milieu académique s'appelle les modèles mondiaux (World Models) et l'intelligence incarnée.
Apprendre à la machine à comprendre comment le monde physique fonctionne, afin que les personnages conservent des caractéristiques parfaitement cohérentes et ne se déforment pas dans des plans à différents moments et espaces, voilà précisément la problématique que ces deux chercheurs tentent de résoudre.
Enfin, ajoutez Nithanth Kudige (à gauche, auteur majeur du modèle d'inférence de la série O), qui s'est toujours consacré à relier les grands modèles d'inférence à la logique sous-jacente de la vision, et Kenji Hata (à droite, ancien chercheur chez Google, diplômé du laboratoire de vision de Stanford).

Lorsque ce groupe se réunit, le raisonnement logique de base, le rendu 3D, l'alignement parfait entre texte et image, ainsi que les lois du monde physique, sont naturellement intégrés dans un même modèle.
PART.06 La limite de GPT-Image-2
Tout modèle a ses limites.
L'entreprise reconnaît également qu'elle éprouve encore des difficultés face à certaines situations extrêmes.
Par exemple, des instructions de pliage de papier nécessitant une inversion physique rigoureuse, la résolution d’un Rubik’s Cube, ou des détails extrêmement répétitifs comme des grains de sable très denses, restent à la limite de ses capacités.
Mais dans un contexte d'application commerciale, il s'agit d'une imperfection extrêmement mineure.
Pour toute l'industrie du design, il n'est pas nécessaire de susciter de l'anxiété ; cela ne signifie absolument pas la disparition de l'esthétique.
Les personnes ayant du goût, une insight commerciale et une compréhension des stratégies peuvent toujours en faire quelque chose d'excellent.
Mais le fait objectif est que le fossé protecteur du métier de designer a été sérieusement érodé.
Avant, on gagnait sa vie en mémorisant les raccourcis des logiciels de conception, en sachant aligner les polices horizontalement et verticalement, en comprenant la mise en page selon les langues, et en effectuant des retouches et des découpes précises.
Mais ça sera plus difficile à l'avenir, car ces compétences qui pouvaient autrefois être clairement tarifées et échangées sont désormais devenues des commandes de base accessibles gratuitement par n'importe qui avec une simple phrase.
Après une période d’inactivité, OpenAI a effectivement prouvé, d’une manière très calme mais extrêmement puissante, qui détient véritablement les meilleures cartes sur ce tableau.
La chaîne d'outils d'exécution ancienne est en train de se rompre ; la question qui reste à l'industrie n'est plus si l'IA nous remplacera, mais comment nous adapter à cette nouvelle chaîne de production.