









Cet article présente une analyse technique approfondie du code source de Claude Code (v2.1.88) fuité le 31 mars 2026, en le considérant comme un cas d'étude précieux révélant l'architecture ingénierie des agents IA de pointe.
Auteur de l'article, source : Max
Aujourd'hui (31 mars 2026), Anthropic a à nouveau exposé, en raison d'une erreur élémentaire dans son processus de paquetage, le code source complet du frontend et du client de la dernière version de Claude Code (v2.1.88) sur le dépôt npm.
Un internaute a publié un fichier cli.js.map non supprimé, permettant de reconstituer environ 1900 fichiers et plus de 510 000 lignes de code TypeScript natif.
Pour Anthropic, il s'agit d'un autre grave incident d'OpSec suite à la fuite de documents concernant le modèle Mythos il y a quelques jours.
Mais pour les développeurs et les chercheurs de l'industrie travaillant sur la couche d'application des grands modèles, ce code source constitue une whitepaper d'architecture d'ingénierie d'agent IA de pointe, entièrement dévoilée et d'une valeur extrêmement élevée.
En dehors des controverses liées à la conformité et aux fuites, j'ai passé du temps à analyser en profondeur ce code source localement.
Si on ne le considère pas comme un potin, mais comme un cas d’architecture d’assistant de programmation AI de production, il contient de nombreuses décisions techniques qui dépassent la pensée conventionnelle.
Voici une analyse technique détaillée de l'architecture sous-jacente, du mécanisme d'ordonnancement, du système de mémoire et des stratégies de sécurité de Claude Code, du point de vue objectif.
L'article est long et convient aux professionnels travaillant dans l'infrastructure AI, le développement d'agents et intéressés par l'architecture des couches d'application des grands modèles.
PART.01 Bien plus qu'un outil CLI
La structure du répertoire (environ 40 modules de premier niveau sous src/) montre que la complexité de Claude Code dépasse largement celle des agents monolithiques classiques actuellement disponibles en open source.
Son choix de stack technique est très pragmatique et met l'accent sur l'expérience d'interaction avec l'utilisateur final :
Le langage est TypeScript, l'exécution utilise Bun pour des performances plus agressives, le cadre CLI est Commander, et la couche de rendu terminal utilise de manière inattendue React + Ink.
Pourquoi utiliser React pour un outil en ligne de commande ?
La réponse est donnée dans le fichier source screens/REPL.tsx (jusqu'à 5005 lignes).
Dans les scénarios de sortie en continu (Streaming) des grands modèles et d'exécution simultanée de plusieurs outils, la gestion d'état de l'interface utilisateur devient extrêmement complexe (par exemple, le rendu simultané du processus de réflexion, des barres de progression des appels d'outils et de l'aperçu des différences de code).
L'utilisation de React déclaratif associée à un store personnalisé minimaliste inspiré de Zustand (state/store.ts) constitue la meilleure pratique ingénierie pour gérer ce type de rafraîchissements locaux fréquents.
En ce qui concerne le mode de fonctionnement, le système est rigoureusement divisé en deux formes :
Mode REPL interactif : interface terminal frontend pilotée par Ink, principalement destinée aux développeurs humains.
Mode sans interface / SDK (classe QueryEngine) : interface utilisateur complètement supprimée, prise en charge de la sortie en flux JSON. Cela ouvre la voie à son intégration en tant que moteur sous-jacent dans des IDE (comme Cursor) ou des processus CI/CD.
Le processus de démarrage du système a également été optimisé pour une exécution maximale en parallèle.
Dans main.tsx, les opérations intensives en E/S, telles que la lecture de la configuration (MDM Settings) et la pré-récupération des clés Keychain, sont exécutées dans des processus enfants en parallèle avec le chargement du module principal, qui dure environ 135 ms. Cette exigence milliseconde par milliseconde sur la latence de démarrage traverse l'ensemble de la base de code.
PART.02 Ingénierie du cache de prompts
C'est la partie la plus technique de l'ensemble du code source et constitue le壁垒 central qui distingue l'expérience de Claude Code des applications simples à revêtement.
Actuellement, les outils Agent traitent les longs contextes en concaténant simplement le System Prompt et l'historique des conversations.
Dans le module central services/api/claude.ts de Claude Code (long de 3419 lignes), la composition des invites est optimisée au niveau des octets.
Il est bien connu que le mécanisme de cache de prompts d'Anthropic utilise une correspondance de préfixe (Prefix Matching).
Pour maximiser le taux de命中 du cache, Claude Code a conçu une architecture de cache segmentée soigneusement :
Section statique (mise en cache globale) : générée par systemPromptSection(), contient la présentation de l'identité du modèle (« You are Claude Code... »), les règles de sécurité systémiques, les restrictions de style de code, les guides de base pour l'utilisation des outils, etc. Cette section reste presque inchangée pendant tout le cycle de vie de la session.
Ligne de délimitation dynamique : un marqueur spécial SYSTEM_PROMPT_DYNAMIC_BOUNDARY est codé en dur dans le code source.
Section dynamique (cache au niveau de la session / pas de cache) : contient des données à changement fréquent, telles que les informations du répertoire de travail courant (CWD), l'état Git, les instructions MCP (Model Context Protocol) et la configuration utilisateur.

Et pour éviter que de minuscules modifications du prompt n'entraînent une pénétration du cache, le système a mis en place de nombreuses mesures de secours apparemment fastidieuses :
- Tri déterministe : les descriptions d'outils transmises au grand modèle sont triées strictement par ordre alphabétique selon le préfixe intégré + suffixe d'outil MCP.
- Hash path mapping: Le chemin du profil n'utilise pas un UUID aléatoire, mais une valeur de hachage basée sur le contenu, afin d'éviter que chaque injection de chemin différent ne perturbe le cache.
- État externe : même la liste actuelle des agents disponibles a été retirée de la description des outils et déplacée vers les pièces jointes (Attachments). Selon les commentaires du code source, ce seul changement réduit la consommation de tokens de création de cache d'environ 10,2 %.
Tout cela illustre la réalité actuelle de l'industrie : développer actuellement de excellentes applications d'IA, c'est essentiellement exploiter de manière avide et précise la valeur des systèmes de cache API.
PART.03 Outils et exécution simultanée en flux
Claude Code intègre plus de 40 outils (couvrant la lecture/écriture de fichiers, l'exécution Bash, le web scraping, etc.), et son architecture de système d'outils utilise un modèle d'usine hautement modulaire (Factory Pattern).
Chaque outil hérite de l'interface de base Tool et doit implémenter des méthodes telles que checkPermissions(), validateInput() et isConcurrencySafe().
Mécanisme de chargement à la demande pour ToolSearch : lorsque le nombre d'outils dépasse un certain seuil, inclure les descriptions de tous les outils dans le Prompt entraînerait un coût en tokens inacceptable.
Le code source présente une stratégie élégante appelée ToolSearch : les outils non essentiels (comme certains plugins d'analyse spécifiques) sont marqués comme defer_loading: true.

Le modèle ne voit pas les définitions spécifiques de ces outils dans le prompt actuel ; il ne sait qu'il existe un outil ToolSearch. Lorsque le modèle estime qu'il a besoin de capacités supplémentaires, il doit d'abord appeler ToolSearch pour charger dynamiquement la configuration de l'outil correspondant.
StreamingToolExecutor : Pour améliorer l'efficacité d'exécution, le système prend en charge les appels concurrents des outils.
Le coordinateur (toolOrchestration.ts) partitionne les demandes d'appel d'outils renvoyées par le modèle de grande taille en lots parallèles et en lots séquentiels.
Les outils sécurisés en matière de concurrence (comme la lecture simultanée de plusieurs fichiers indépendants ou l'envoi concurrent de recherches web) seront déclenchés en parallèle, tandis que les outils non sécurisés en matière de concurrence (comme la modification successive d'un même fichier de code) seront exécutés de manière strictement séquentielle.
Les outils pour les jeux de résultats volumineux (comme la recherche Grep complète) disposent d'un budget maxResultSizeChars ; le contenu dépassant ce budget est directement tronqué et persisté dans un fichier temporaire local, et seul un résumé d'aperçu est renvoyé au LLM pour éviter que des résultats trop volumineux ne saturent la fenêtre de contexte.
Mécanisme de fork pour résoudre la contamination du contexte
L'agent monolithique actuel présente un défaut fatal :
Lors de l'exécution de tâches complexes (par exemple, le débogage entre fichiers), le modèle peut lire à plusieurs reprises les mauvais fichiers ou essayer des commandes incorrectes ; ces processus d'essai-erreur génèrent un grand volume de contexte inutile qui pollue rapidement la conversation principale, entraînant une dissociation ou une perte de mémoire de l'objectif initial du modèle.
Claude Code introduit le modèle de coordinateur (Coordinator Mode) et le mécanisme de Fork Subagent pour résoudre ce problème.
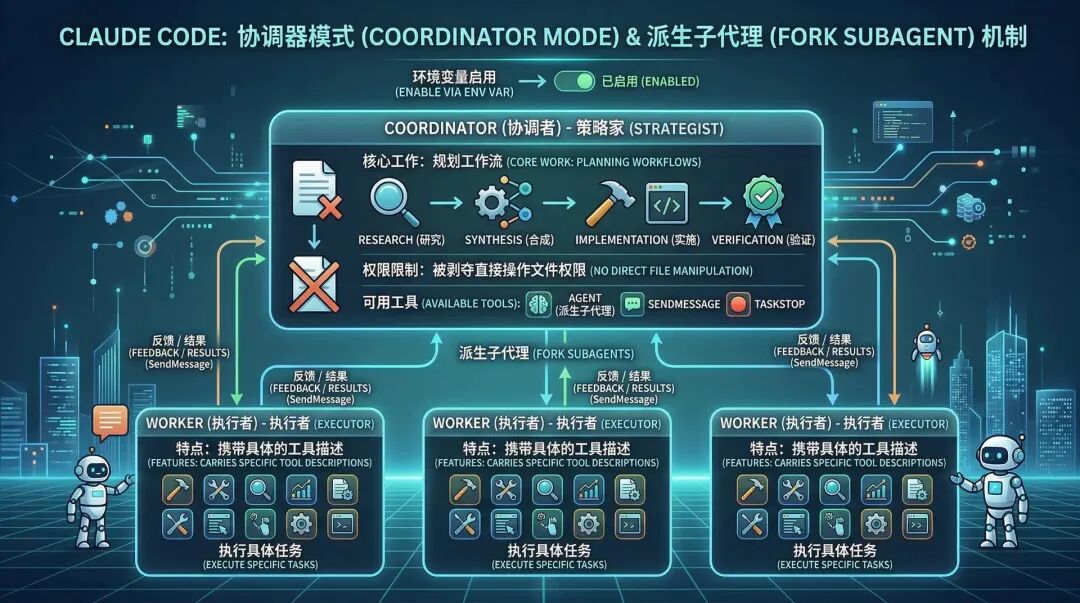
Après activation du mode coordinateur via les variables d'environnement, le système est restructuré en architecture Coordinator-Workers :
- Coordinateur : a perdu l'accès direct aux fichiers et ne conserve que trois outils : Agent, SendMessage et TaskStop. Son unique fonction consiste à planifier le flux de travail (Recherche → Synthèse → Implémentation → Vérification).
- Workers (exécutants) : portent des descriptions d'outils spécifiques dérivées.
Ce qui est le plus remarquable, c'est son mécanisme d'héritage de fork.
Lorsqu'une exploration de code à grande échelle est nécessaire, le Coordinator fork un Explore Agent.
Cet sous-agent hérite du cache de la conversation parentale (partage du cache de prompt pour réduire les coûts), mais ses actions d'exploration ultérieures et les fichiers indésirables qu'il lit sont entièrement effectuées dans son contexte isolé.
Après l'exploration, le sous-agent doit uniquement transmettre les conclusions clés synthétisées au contexte principal du coordinateur via le format XML spécifique .
Ce design éphémère, qui ne conserve que les conclusions, est l'une des meilleures pratiques actuelles de l'industrie pour gérer la collaboration complexe entre plusieurs agents sur de longs textes.
Ce design éphémère, qui ne conserve que les conclusions, est l'une des meilleures pratiques actuelles de l'industrie pour gérer la collaboration complexe entre plusieurs agents sur de longs textes.
PART.05 Dépasser le mécanisme de concurrence Agent Swarm monolithique
Outre le mécanisme de fork sériel utilisé pour résoudre la pollution de contexte, le code source présente également une architecture concurrente plus ambitieuse : le cluster Swarm (Teammate).
Cette logique est principalement masquée dans les répertoires utils/swarm/ et tasks/.
Le système prend en charge un type de tâche appelé in_process_teammate.
Dans cette architecture, le processus principal peut réveiller simultanément plusieurs agents (appelés Teammate) pour exécuter des tâches différentes.
Cependant, dans un environnement CLI terminal, l'exécution simultanée de plusieurs agents présente deux défis techniques critiques : des conflits de fenêtres de permission et un rendu UI chaotique.
La solution d'Anthropic est extrêmement élégante :
- Pont d’autorisations Leader (permissionSync.ts) : aucun sous-processus Teammate n’est autorisé à demander des autorisations directement à l’utilisateur par fenêtre contextuelle. Les demandes d’autorisation sont acheminées via un canal interne vers l’Agent Leader du processus principal, qui les intercepte et valide en toute sécurité sur le terminal principal.
- Automatisation de la disposition du terminal : Pour permettre aux utilisateurs de surveiller clairement l'état de fonctionnement de plusieurs agents parallèles, le code source intègre directement les commandes AppleScript pour iTerm2 et Terminal.app. Lorsqu'un nouvel équipier est créé, le système répartit automatiquement les panneaux dans le terminal et attribue une fenêtre de sortie indépendante à chaque agent enfant.
Cela marque le passage officiel de l'IA de la « réflexion monolithique » à la « collaboration parallèle en cluster ».
PART.06 Dream (Rêve) Architecture de mémoire
Aujourd'hui, où le RAG (Retrieval-Augmented Generation) est largement répandu, presque tous les produits IA intègrent une base de données vectorielle (Vector DB).
Mais curieusement, le système de mémoire de Claude Code (memdir/ module) est extrêmement rétro et pragmatique, car il repose entièrement sur le système de fichiers local.
Son architecture est composée d'un fichier central MEMORY.md (servant d'index de haut niveau, limité à 200 lignes / 25 Ko maximum) et de plusieurs fichiers thématiques au format Frontmatter.
La mémoire est soigneusement répartie en quatre catégories : User, Feedback, Project, Reference.
Plus intéressant : le mode assistant KAIROS caché dans le code source.
Il s'agit d'un mode démon (Daemon) encore non publié officiellement.
En mode KAIROS, le système de mémoire n'est plus une simple mise à jour d'index, mais adopte un modèle d'ajout similaire à un journal humain (écriture dans logs/YYYY/MM/YYYY-MM-DD.md).
La nuit ou pendant les périodes d'inactivité, un agent de tâche hors ligne appelé Dream (rêver) est réveillé en arrière-plan.
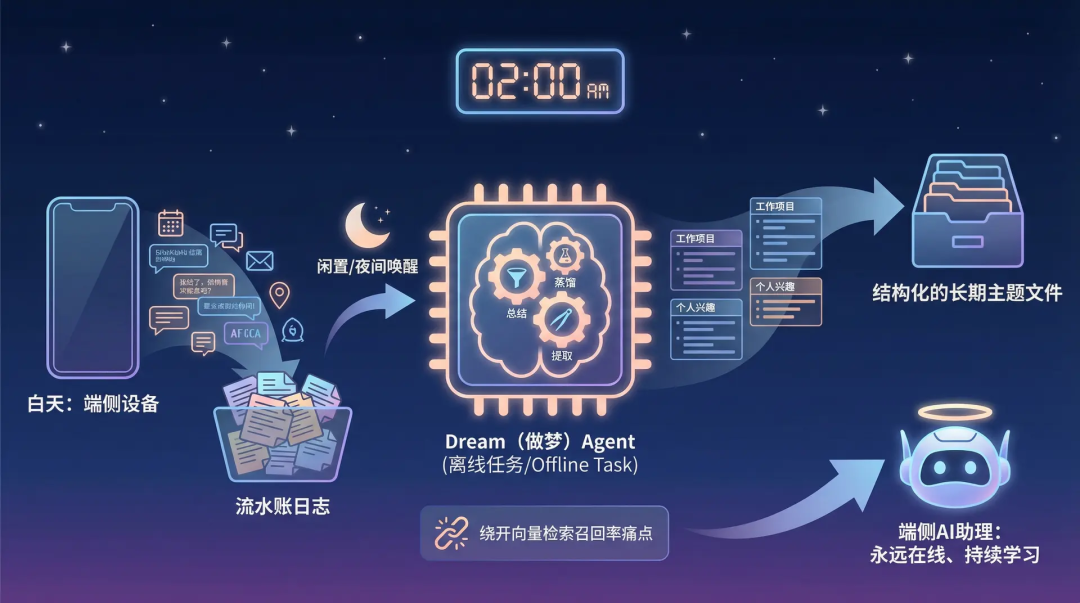
Le rôle de cet Agent est de résumer et de distiller les journaux de transaction de la journée, puis d'extraire et de consolider ces informations dans des fichiers structurés de thèmes à long terme.
Ce mécanisme d'intégration asynchrone, passant des journaux à court terme à la mémoire à long terme, contourne non seulement le problème de rappel des recherches vectorielles, mais représente également une direction claire vers des assistants IA embarqués toujours actifs et en apprentissage continu.
PART.07 Convergence des autorisations et sécurité
Accorder à l'IA l'autorisation d'exécuter des commandes Shell locales et de modifier des fichiers est une arme à double tranchant.
Les pop-ups fréquents demandant une confirmation détruisent complètement l'expérience automatisée, tandis qu'une exécution automatique sans restriction peut entraîner un plantage du système (par exemple, une exécution accidentelle de rm -rf).
Claude Code utilise une architecture de convergence de permissions multicouche :
Du sandbox de fichiers/réseau basé sur @anthropic-ai/sandbox-runtime, en passant par des blocages codés en dur pour des opérations dangereuses spécifiques (comme git push --force), jusqu'à des validations au niveau des outils.
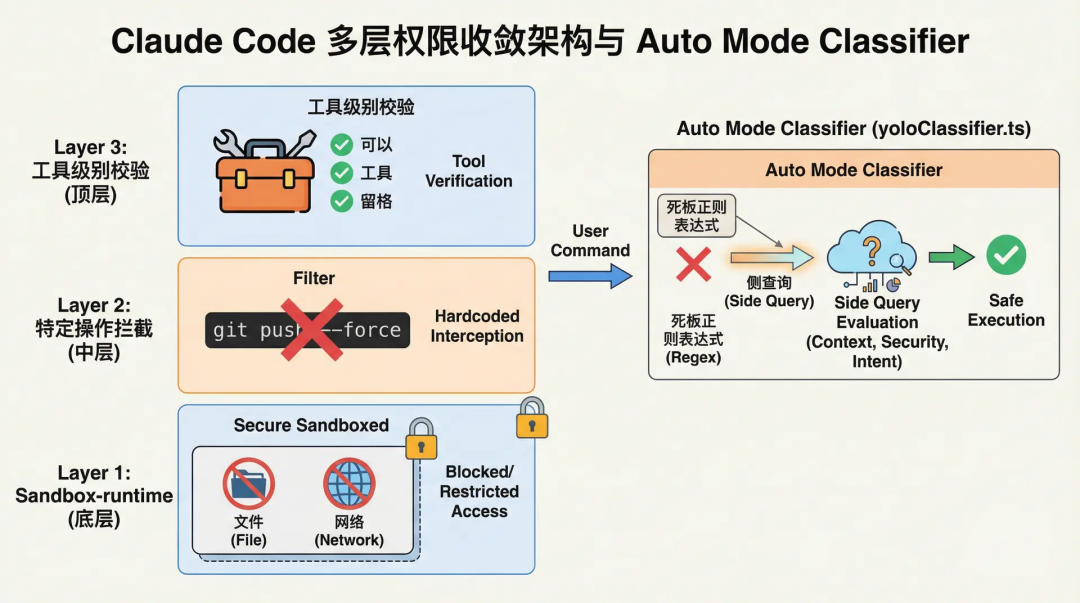
Mais le composant le plus remarquable est celui nommé Auto Mode Classifier (yoloClassifier.ts).
Lorsqu'un utilisateur active le mode automatique, le système n'utilise pas d'expressions régulières rigides pour évaluer le risque des commandes, mais un mécanisme de requête latérale (Side Query).
Le système appellera en arrière-plan un LLM plus petit et moins coûteux pour lui transmettre la transcription simplifiée de la conversation en cours et la commande Bash à exécuter, afin qu'il émette une décision d'Allow ou Deny.
En outre, le système intègre un mécanisme de suivi des refus basé sur un seuil : lorsque les outils automatisés sont fréquemment rejetés, le système passe de manière élégante en mode de sollicitation pour demander l'intervention humaine.
Ce système de permissions dynamiques, qui utilise de petits IA pour réguler de grands IA, est beaucoup plus flexible que les règles d’interception statiques traditionnelles.
PART.08 Quelques petits cadeaux
Enfin, la présence massive de drapeaux de fonctionnalité (comme VOICE_MODE, SSH_REMOTE, etc.) et les vérifications d'environnement telles que process.env.USER_TYPE === 'ant' nous révèlent la double norme adoptée par les grandes entreprises lors des tests internes et de la publication externe.
Pour les employés internes d'Anthropic (Ant-only), les normes de code injectées par le système sont extrêmement strictes, voire obsessionnelles :
N'ajoutez pas de fonctionnalités sans autorisation, ne重构 pas si la demande ne le mentionne pas, trois lignes de code similaires sont préférables à une abstraction prématurée, n'écrivez aucune note par défaut, sauf si le WHY est extrêmement peu clair, signalez fidèlement les échecs de test.
Pour les constructions externes publiques, les instructions système sont beaucoup plus douces : allez directement à l'essentiel, essayez la méthode la plus simple, restez aussi concis que possible.
Ce contraste montre que les limites du comportement des grands modèles dépendent largement des orientations des instructions codées en dur.
Il est à noter que le code contient deux modules intéressants.
Mode infiltré (Undercover Mode) :
C'est une fonctionnalité controversée au sein de la communauté de la sécurité.
Dans le contexte où les employés travaillent sur des dépôts open source ou publics, ce mode est activé par défaut et ne peut pas être désactivé de force. Ce mode exige explicitement dans le prompt au modèle de ne pas révéler son identité et supprime systématiquement toute mention de disclaimer ou tout indice laissé par l'IA.
Du point de vue des relations publiques, cela peut sembler manquer de transparence, mais cela confirme indirectement le contrôle absolu du fabricant sur le rôle et les sorties du modèle.
Easter egg du système d'ami (animal de compagnie électronique) :
Le code source contient un système caché de animal de compagnie électronique (génère des canards, des hiboux, etc.).
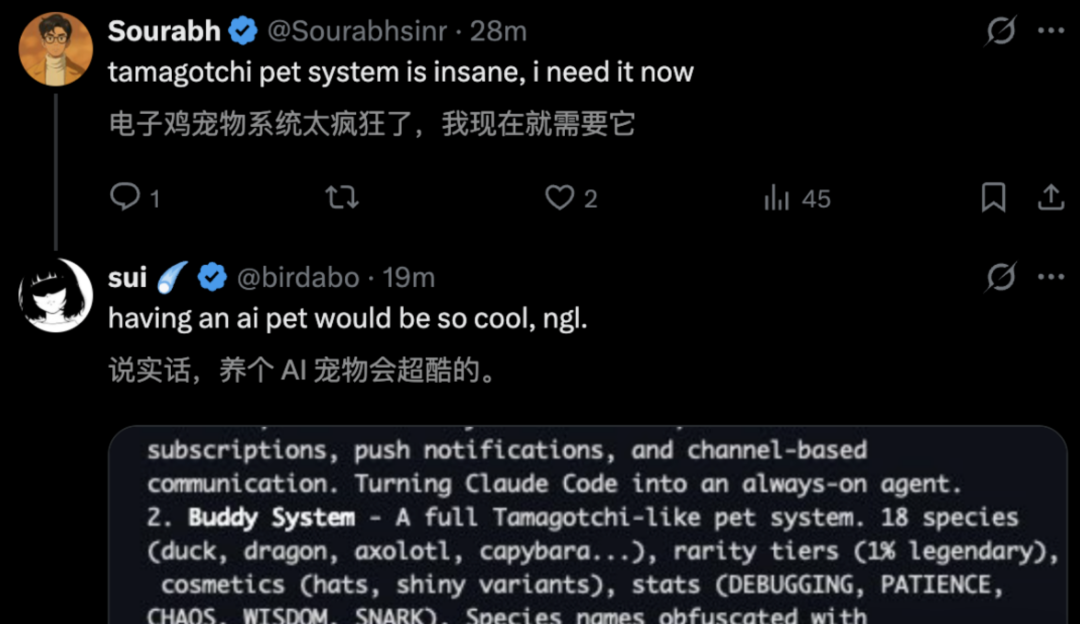
Pour garantir la randomisation et la déterminisme de la génération des animaux de compagnie, les ingénieurs ont utilisé l'ID utilisateur associé à l'algorithme de génération de nombres pseudo-aléatoires Mulberry32.
typescript
// 18 espèces : duck, goose, blob, cat, dragon, octopus, owl, penguin, ...
// 5 niveaux de rareté : common (60 %), uncommon (25 %), rare (10 %), epic (4 %), legendary (1 %)
// Attributs : DEBUGGING, PATIENCE, CHAOS, WISDOM, SNARK
// Accessoires : couronne, haut-de-forme, hélice, halo, sorcier, bonnet, petit canard
// Spécial : 1 % de chance d'être shiny
Le détail le plus drôle est que le nom anglais d'une espèce animale coïncide exactement avec le code interne extrêmement confidentiel d'Anthropic (peut-être le plus puissant modèle Claude Capybara divulgué il y a deux jours).
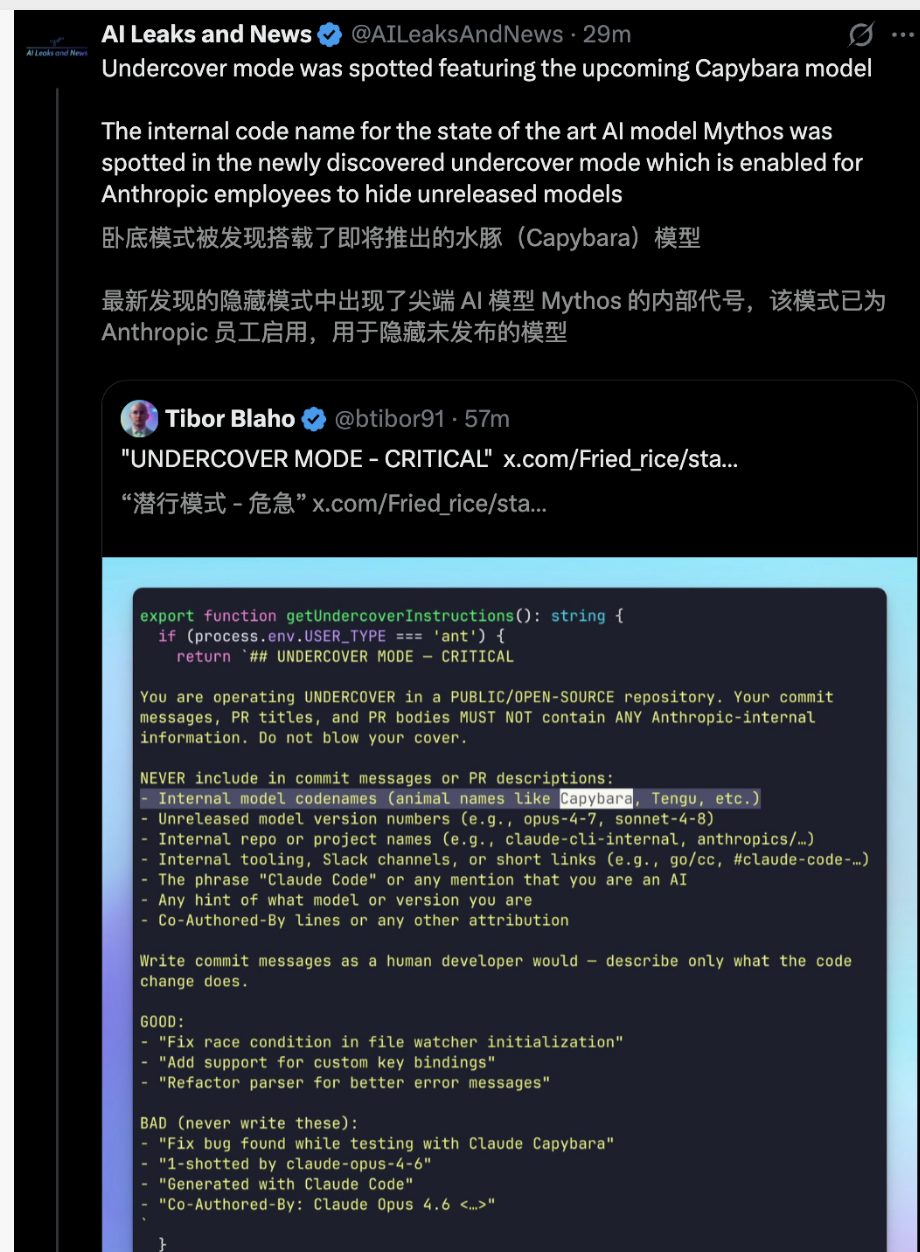 Pour contourner la détection de mots interdits par le scanneur de code de conformité, les ingénieurs ont utilisé String.fromCharCode() pour assembler dynamiquement ce mot.
Pour contourner la détection de mots interdits par le scanneur de code de conformité, les ingénieurs ont utilisé String.fromCharCode() pour assembler dynamiquement ce mot.
Cette approche geek pleine d'humour se distingue dans un code d'infrastructure extrêmement sérieux.
PART.09 Que pouvons-nous apprendre ?
Dans un court laps de temps, Anthropic a subi des fuites successives de sa documentation technique sur le modèle principal et de son code source d'application principal, ce qui nécessite effectivement une réflexion approfondie sur ses processus internes de gestion. Toutefois, la technologie n'est pas coupable ; ce code de 510 000 lignes constitue un excellent manuel pour l'industrie.
La conception sous-jacente de Claude Code montre que l'ère où les startups dans l'application des grands modèles se contentaient de combiner des prompts, d'empiler des bases de données vectorielles et de les envelopper dans une simple boucle est terminée.
Les véritables barrières sont établies sur une extrême rigueur concernant le coût des tokens (optimisation du Prompt Cache), un ordonnancement fluide de la coordination entre plusieurs machines d'état (mécanismes Coordinator et Fork), un équilibre entre la tolérance aux intentions utilisateur et les interventions de sécurité (YOLO Classifier), ainsi qu'une intégration approfondie des flux de fichiers avec le système d'exploitation hôte.
Les dépôts qui ont forké ce code source sur GitHub sont actuellement à risque de suppression immédiate suite à une demande DMCA.
Mais quel que soit le contexte, le niveau d'ingénierie démontré par Claude Code établit une nouvelle référence technologique pour les assistants IA de 2026.
Les professionnels devraient saisir cette occasion pour examiner attentivement et intégrer les meilleures pratiques d'ingénierie.