









La seconde moitié de la programmation de l'IA ne se joue plus uniquement sur la longueur du contexte, mais sur la décomposition des tâches, la correction d'erreurs et la stabilité d'exécution sur de longues périodes.
Auteur et source de l'article : 0x9999in1, ME News
TL;DR
- La contre-attaque open source : Kimi K2.6 est désormais open source et son API est accessible, brisant directement le monopole des géants propriétaires comme GPT-5.4 et Claude Opus 4.6 dans les tests de référence de programmation essentiels tels que SWE-Bench Pro, et redéfinissant le paysage industriel.
- Force inhumaine : Dépassant les limites « en sprint » de l'IA traditionnelle, K2.6 démontre une capacité d'exécution prolongée de 12 heures, avec plus de 4 000 appels d'outils, permettant à l'IA d'évoluer véritablement d'un « outil de complétion de code » en une « équipe externe indépendante ».
- La montée de l'armée numérique : Agent Swarm bénéficie d'un renforcement épique, capable de planifier 300 agents sous-jacents en parallèle lors d'une seule exécution, facilitant ainsi les tâches de restructuration système à haute concurrence et haute complexité.
- Full-stack and around-the-clock: Address frontend animation gaps, support complex 3D effects; provide 24/7 proactive agent capabilities, marking the beginning of a new era of "human-machine collaboration, machine-led."
- Conclusion claire : La seconde moitié de l'IA de programmation ne se joue plus uniquement sur la longueur du contexte, mais sur la décomposition des tâches, la correction d'erreurs et la stabilité d'exécution sur de longues périodes. K2.6 a obtenu ce billet extrêmement coûteux.
Introduction : Alors que le monde dort, les machines foncent
À trois heures du matin, Zhongguancun est calme, et les immeubles de bureaux de la Silicon Valley le sont aussi.
Les nerfs optiques des programmeurs humains sont secs et douloureux à force de fixer l'écran pendant de longues heures ; l'excitation apportée par la caféine a été engloutie par la fatigue. Ils ferment leur ordinateur et s'endorment profondément.
Mais dans les salles serveurs invisibles, les ventilateurs rugissent.
Des milliers de lignes de code ont été supprimées et réécrites. La compilation a échoué. Débogage. Réécriture à nouveau.
L'outil a été appelé mille fois, deux mille fois, trois mille fois.
Aucune émotion. Aucune plainte. Aucun corps fatigué ayant besoin de vacances.
Ce n'est pas un film de science-fiction. C'est une bombe sous-marine que Moonshot AI vient de lancer dans le monde de la technologie — le nouveau modèle de programmation open source phare, Kimi K2.6.
L'année passée, nous avons été gâtés par les grands modèles. Nous avons pris l'habitude de donner un prompt à l'IA et de la voir produire comme par magie des dizaines de lignes de code Python. Nous appelons cela la « révolution de la productivité ».
Mais est-ce vraiment une révolution ?
Non, ce n’est qu’une machine à écrire un peu plus intelligente.
La vraie programmation est boueuse. Elle exige de plonger dans des centaines de milliers de lignes de code hérité pour démêler des dépendances complexes et inextricables ; elle nécessite de configurer des environnements compliqués et de faire fonctionner des compilateurs pour des langages inconnus ; elle implique de pouvoir itérer et se réparer soi-même face à un bug, et non de croiser les bras en lançant une erreur et en laissant tout à vous.
Kimi K2.6 vous informe que l'ère des machines à écrire est terminée.
L'ère de la conduite entièrement automatisée est officiellement arrivée.
Dominer et s'évader : le « débarquement de Normandie » du camp open source
Le monde souffre depuis longtemps de la fermeture des sources.
Dans les conceptions passées, les modèles se divisaient en deux catégories : d'une part, les modèles propriétaires de pointe comme « GPT-5.4 » ou « Claude Opus », qui étaient considérés comme les sommets de la performance ; d'autre part, les modèles open source, moins coûteux et plus flexibles, mais qui semblaient souvent à la limite face à des problèmes techniques exigeants.
Open source, comme si c'était toujours inférieur.
Jusqu'à ce que K2.6 pose une fiche froide sur la table.
Ce n'est pas seulement une victoire en termes de performance. C'est un tir précis contre le rideau de fer de la source fermée.
Voyons ces données. Sur le classement officiel évaluant la capacité des IA à résoudre des problèmes réels sur GitHub, K2.6 n'a pas joué dans les niches marginales, mais a directement sorti son épée sur le terrain le plus exigeant.
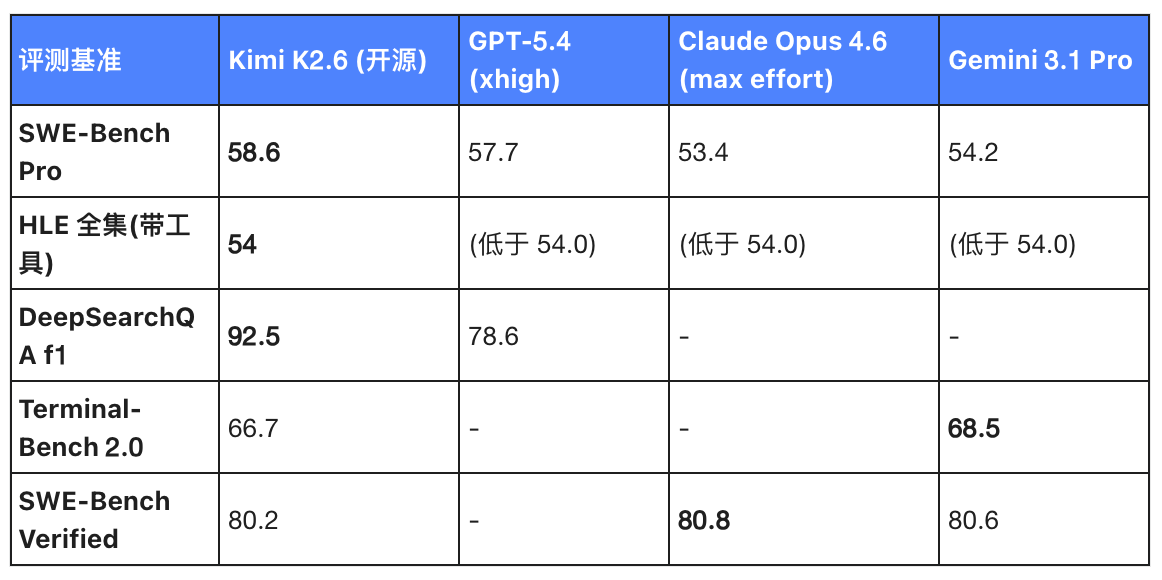
Table 1 : Comparaison des principaux benchmarks de programmation fermés entre Kimi K2.6 et les principaux modèles concurrents
Comprenez-vous ces chiffres ?
Sur SWE-Bench Pro, ce simulateur pratique très prestigieux, K2.6 a obtenu un score de 58,6.
Quel concept ? Il a surpassé les « trois grands » : GPT-5.4, Claude Opus 4.6 et Gemini 3.1 Pro.
Dans le test HLE Full Set (avec outils), K2.6 avec un score de 54.0 domine largement, tandis que les trois géants propriétaires échouent tous.
Pour le DeepSearchQA f1, la note de 92,5 de K2.6 établit un avantage de génération directe sur les 78,6 de GPT-5.4.
Bien que K2.6 ne soit que « au même niveau » que Gemini 3.1 Pro et Opus 4.6, voire légèrement en retard, dans Terminal-Bench 2.0 et SWE-Bench Verified, cela n'a aucune importance.
Pourquoi ? Parce qu'il est open source.
Dans le camp open source, il y avait presque aucune option capable de rivaliser avec les fleurons fermés à ce niveau de performance de programmation. C’est la réalité impitoyable.
Et maintenant, K2.6 est comme le débarquement de Normandie pendant la Seconde Guerre mondiale. Il n'a pas seulement brisé les lignes propriétaires, mais a également établi avec succès une tête de pont. Il dit à tous les développeurs : les compétences de programmation les plus avancées ne sont plus la propriété privée verrouillée dans des coffres-forts API par quelques grandes entreprises.
Adieu le passager, bienvenue au « chef d'entreprise numérique »
Très bon score. Mais un bon score, ça nourrit-il ?
Non.
Ce qui m'a vraiment glacé le sang, ce sont les deux jeux de données de tests « exécution à long terme » publiés de manière superficielle sur le blog officiel de Moonlight.
Les anciennes IA étaient des sprinteurs. Elles avaient une puissance explosive, capables d'écrire de petites fonctions de quelques dizaines de lignes et de faire sensation.
Mais si vous lui demandez de gérer un projet énorme ? Désolé, sa mémoire déclinera, sa logique s’effondrera, il entrera dans une boucle infinie et finira par produire un tas de caractères aléatoires incompréhensibles.
K2.6 ? C'est un marathonien. Et c'est un monstre d'acier qui n'a pas besoin de boire ni de reprendre son souffle.
Douze heures de bataille silencieuse
Voyons le premier cas.
Tâche : Réécrire le code d'inférence de Qwen3.5-0.8B en langage Zig sur Mac localement.
Qu'est-ce que Zig ? Un langage de programmation système extrêmement niche et exigeant. Ce n'est pas un langage simpliste comme Python, qui regorge de bibliothèques prêtes à l'emploi. Écrire un moteur d'inférence en Zig, c'est comme marcher sur une corde raide au bord d'une falaise les yeux bandés.
Un programmeur humain qui prend ce travail doit d'abord apprendre la grammaire pendant une semaine, puis passer quinze jours à régler la mémoire.
Comment fonctionne K2.6 ?
Il a fonctionné en continu pendant 12 heures.
Outil appelé plus de 4 000 fois.
14 rounds of downticks have been conducted.
14 itérations de déclin signifient quoi ? Cela signifie qu'elles testent continuellement des erreurs. Écrire mal, compiler, obtenir une erreur, analyser l'erreur, corriger, puis compiler à nouveau.
Les humains commencent peut-être à frapper sur le clavier lors du troisième message d'erreur.
Les machines ne le font pas. Les machines n'exécutent que froidement la prochaine make.
Et le résultat ? Le débit est passé d’environ 15 tokens/seconde à 193 tokens/seconde, soit environ 20 % plus rapide que LM Studio.
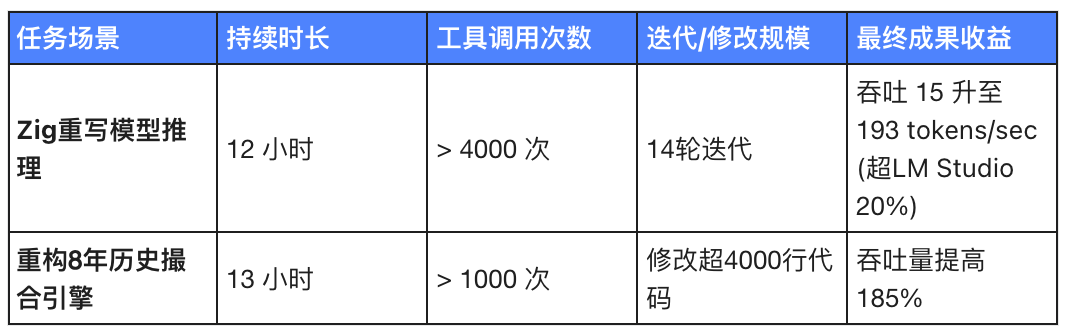
Tableau 2 : Analyse des données de test réelles de l'exécution à long terme de Kimi K2.6
« Chirurgie » du code hérité
Le deuxième cas est encore plus extrême. Prendre en charge un moteur de matching open source âgé de 8 ans exchange-core.
Les programmeurs un peu expérimentés savent ce que cela signifie de reprendre un code open source âgé de 8 ans.
C'est comme reprendre un champ de mines qui peut exploser à tout moment, rempli de correctifs inconnus, de dépendances impossibles à vérifier et de philosophies de conception incompréhensibles.
Face à ce code, les humains n'ont généralement qu'une seule stratégie : « Si ça fonctionne, ne touche à rien. »
K2.6 Ne pas croire aux superstitions.
Il est entré.
A couru pendant 13 heures et appelé des milliers de fois des outils.
Il a agi comme un chirurgien impitoyable, tranchant cet énorme monstre, modifiant plus de 4 000 lignes de code et même reconfigurant la topologie des threads principaux (passant directement de 4ME+2RE à 2ME+1RE).
As a result, throughput increased by 185%.
What does this indicate?
Cela démontre que K2.6 possède une capacité de généralisation extrêmement approfondie à travers plusieurs échelles temporelles, plusieurs langues et plusieurs tâches.
De l'interface utilisateur à DevOps, en passant par l'optimisation des performances et la réécriture de l'architecture centrale. Il n'est plus un jouet avancé capable de simplement afficher « Hello World » ; il possède désormais la capacité de prendre en charge de manière autonome des projets complexes.
It's not your Copilot anymore.
C'est votre Tech Lead, votre équipe externe senior, ce chef de projet numérique qui ne fait jamais planter le système.
De la lutte individuelle à la « nuée numérique » : la réduction de dimension de la puissance de calcul
La puissance du modèle unique n'est qu'une partie de l'histoire.
K2.6 apporte un autre outil redoutable : l'évolution épique d'Agent Swarm (grappe d'agents).

Tableau 3 : Comparaison de l'évolution d'Agent Swarm (K2.5 vs K2.6)
Imaginez que vous devez développer un backend de commerce électronique de taille moyenne.
Autrefois, vous décomposiez les tâches et les attribuiez à 10 programmeurs, organisiez des réunions quotidiennes, coordonniez les interfaces et vous disputiez entre vous.
Maintenant, vous donnez une instruction à K2.6.
En un instant, K2.6 se divise en 300 sous-agent parallèles.
L'agent n°1 rédige les instructions de création de tables pour la base de données ;
L'agent n°2 configure l'environnement Docker ;
L'agent n°3 écrit la logique de connexion utilisateur ;
……
L'agent numéro 300 rédige des tests unitaires.
Single instruction, directly generate over a hundred files.
Ce n'est plus de la programmation, c'est de la « décharge » de code.
L'équipe d'infrastructure RL interne de Lunar Shadow a fait fonctionner un agent de maintenance en autonomie pendant 5 jours avec ce système.
5 jours, 120 heures. Aucune intervention humaine.
Alerte serveur, l'Agent vérifie les journaux lui-même ; débordement de mémoire, l'Agent tue le processus et redémarre le service lui-même.
Quel est ce concept ? Cela signifie que les postes de DevOps de base font face à une véritable crise de survie.
Les machines ne souffrent pas d'insomnie, n'ont pas besoin de boire du café, et ne se réveillent pas en pleine nuit pour maugréer à cause de PagerDuty. Elles traitent simplement silencieusement les pannes, puis inscrivent une ligne froide dans le journal de vérification.
Réveil du frontend et « fantôme » en continu
Si le code arrière-plan ennuyeux constitue la base de K2.6, alors cette amélioration des animations frontales en est la démonstration technique.
Les grands modèles précédents se débrouillaient bien pour écrire du HTML/CSS, mais ils étaient perdus face à des animations complexes.
Mais K2.6 a complètement débloqué l'arbre de compétences frontend : fonds vidéo, shaders WebGL, GSAP/Framer Motion, et même des effets 3D avec Three.js.
Est-ce que cela va aussi briser la cuillère du frontend ?
Peut-être pas encore si vite. Mais imaginez que les designers créent une interaction 3D époustouflante dans Figma, une tâche qui nécessitait auparavant une semaine de travail acharné pour les développeurs front-end avec WebGL. Désormais, K2.6 pourrait construire l'architecture de base en quelques prompts seulement. Cela augmente considérablement la capacité maximale des développeurs indépendants et des petites équipes.
Plus intéressant, c'est son soutien aux « agents actifs ».
K2.6 offre une capacité d'exécution autonome 24/7 pour OpenClaw, Hermes Agent, etc.
En parallèle, la fonction d'aperçu de recherche Claw Groups prend en charge « apporter votre propre agent et commander d'autres agents ».
Cela semble un peu lourd. Traduisez cela :
Les machines commencent à gérer les machines.
En tant qu'humain, vous devenez un « superviseur principal ». Vous émettez des intentions stratégiques, et K2.6 attribue une tâche à un agent superviseur, qui répartit ensuite les tâches à 300 agents ouvriers.
L'humain est passé de « exécutant » à « observateur ».
C'est une nouvelle forme de collaboration homme-machine. Mais dans cette collaboration, le rôle de l'humain devient de plus en plus réduit.
Épilogue : La marée s'est retirée, qui nage à nu ?
La sortie de Kimi K2.6 constitue une ligne de démarcation.
Il a déchiré sans pitié le voile cachant le domaine actuel de la programmation IA.
Alors que vous vous félicitez encore de votre modèle capable de générer du code pour le jeu du serpent, K2.6 approfondit depuis huit ans le moteur de matching open source, effectuant une chirurgie sur son architecture sous-jacente.
Alors que vous hésitez encore à améliorer votre prompt, K2.6 a déjà appelé 4000 fois des outils et achevé une itération en boucle fermée.
Le déploiement complet de K2.6 sur Kimi.com, l'application Kimi, l'API de la plateforme ouverte et Kimi Code signifie que cette productivité extrêmement impressionnante a désormais été mise à la disposition de tous, devenant une infrastructure accessible à tous.
Le mois dernier, il n'était qu'en mode interne sous le nom de code-preview. Aujourd'hui, le géant s'échappe de sa cage.
Nous aimons toujours nous demander : quand l’IA pourra-t-elle vraiment remplacer les programmeurs humains ?
En réalité, c'est une fausse problématique.
Les machines n'ont pas besoin de « remplacer » votre travail. Elles créent simplement une toute nouvelle dimension de productivité. Dans cette dimension, produire cent mille lignes de code de haute qualité, accompagnées de tests et entièrement validées en une seule journée, est devenu une action standard.
Les développeurs qui ne suivent pas cette dimension n'ont pas besoin d'être remplacés ; ils seront naturellement écartés par l'époque.
La première moitié des grands modèles consistait à composer des poèmes, à peindre et à faire des blagues.
La seconde moitié des grands modèles se joue sur la durabilité, la stabilité et l'exécution à long terme.
La face cachée de la lune a prouvé avec K2.6 : après avoir transformé le sable en puces, l'humanité a enfin appris à ces particules de sable à penser et à travailler sans fin.
Et nous, il suffit de boire un café après s'être réveillé pour revisiter les royaumes qu'ils ont conquis.
C'est fou, non ?
But this is the truth.
Source :
- [1] Blog officiel de Moonshot AI. (2026). Kimi K2.6 : Le prochain modèle open-source de codage et d'essaim d'agents. * [2] Contributeurs du projet SWE-Bench. (2026). SWE-Bench Pro Classement & Analyse des performances.
- [3] Notes de version de Kimi Code. (2026). De la prévisualisation du code à la disponibilité générale : la course d'autonomie de 12 heures.