










Source : Institut de recherche CoinW
Résumé
Gradients est un sous-réseau décentralisé d'entraînement d'IA construit sur Bittensor (SN56), dont le cœur réside dans la transformation du processus d'entraînement de modèles en une collaboration réseau pilotée par le marché, grâce à des mécanismes tels que la publication de tâches, la concurrence entre mineurs et la vérification sélective. Sur le plan architectural, il combine l'AutoML et les ressources de calcul distribuées pour créer un marché d'entraînement centré sur des mécanismes d'incitation, réduisant ainsi les barrières à l'utilisation de l'IA tout en améliorant l'efficacité de l'utilisation des ressources de calcul. Du point de vue de l'écosystème et des performances des données, Gradients a achevé la construction de son réseau de base, mais les poids d'incitation et les flux de capitaux restent actuellement limités. Gradients complète l'infrastructure d'entraînement au sein de l'écosystème TAO et explore un nouveau paradigme d'optimisation de l'IA pilotée par le marché, avec un potentiel à long terme pour devenir une couche d'entrée majeure pour l'entraînement décentralisé de l'IA.
1. En partant de Web2 AutoML : État actuel et limites de l'entraînement de l'IA
1.1 Qu'est-ce que l'AutoML ?
Dans la perception traditionnelle, entraîner un modèle d'IA était une tâche à haut seuil d'entrée, nécessitant des ingénieurs pour traiter les données, choisir le modèle, ajuster répétitivement les paramètres et évaluer les résultats, un processus complexe et chronophage. L'apparition de l'AutoML (machine learning automatisé) consiste essentiellement à « regrouper et automatiser » ces étapes fastidieuses. On peut le comprendre comme un « outil automatique de création de modèles » : l'utilisateur fournit simplement les données et indique à système l'objectif souhaité — classification, prédiction ou reconnaissance — tandis que le système automatise automatiquement les étapes restantes, y compris le choix du modèle, l'ajustement des paramètres et l'entraînement et l'optimisation. Cela transforme progressivement l'IA d'un outil réservé à quelques ingénieurs spécialisés en une capacité accessible aux développeurs ordinaires et même aux entreprises, constituant une étape cruciale vers la démocratisation de l'IA.
1.2 Limitations fondamentales de l'AutoML traditionnel
Les implémentations dominantes actuelles de l'AutoML se concentrent sur les plateformes des fournisseurs cloud, telles que Google Vertex AI et AWS SageMaker, qui proposent une « formation AI comme service ». Bien que l'AutoML Web2 ait considérablement abaissé les barrières à l'entrée pour l'utilisation de l'IA, ses modèles sous-jacents présentent toujours des limites évidentes. Tout d'abord, il y a un problème de centralisation : les ressources de calcul, les prix et les règles sont entièrement contrôlés par la plateforme, ce qui entraîne une forte dépendance des utilisateurs à un seul fournisseur et une absence de pouvoir de négociation. Ensuite, les coûts sont élevés et manquent de transparence : les ressources GPU nécessaires à la formation de l'IA sont principalement détenues par les fournisseurs cloud, et les mécanismes de tarification souffrent d'un manque de concurrence de marché. Plus crucial encore, l'efficacité d'optimisation atteint une limite. L'AutoML traditionnel reste fondamentalement « un système qui cherche pour vous la meilleure solution » ; peu importe à quel point ce système est complexe, il s'agit toujours d'une optimisation selon une seule voie technologique. Son espace d'exploration est limité, et il est difficile d'essayer simultanément plusieurs approches complètement différentes. Ainsi, la formation AI actuelle dans le Web2 constitue un « système fermé », où l'entraînement, l'optimisation et la planification des ressources se déroulent dans un environnement contrôlé par une seule plateforme. Ce modèle, bien que efficace, commence à révéler ses limites à mesure que la demande augmente.
2. Gradients : Reconstituer l'entraînement de l'IA avec le « réseau »
2.1 Gradients : une plateforme AutoML décentralisée
Dans le chapitre précédent, nous avons mentionné que le problème fondamental des plateformes traditionnelles Web2 d'AutoML réside dans leur « système fermé » : l'entraînement des modèles dépend de la plateforme, les chemins d'optimisation sont limités et le flux de ressources est restreint. Gradients constitue une重构 de ce modèle. Gradients trouve son origine dans une communauté décentralisée d'ingénieurs initiée par WanderingWeights, et est construit sur le réseau Bittensor, en tant que sous-réseau d'entraînement AI opérant sur le Subnet 56. Contrairement aux plateformes traditionnelles, il ne propose pas de services centralisés, mais décompose et externalise l'ensemble du processus d'entraînement à un réseau ouvert. L'utilisateur se contente de définir l'objectif de la tâche — par exemple, le type de modèle et les données — tandis que le réseau gère automatiquement les étapes suivantes : exécution de l'entraînement, optimisation des paramètres et sélection des résultats. Dans ce modèle, l'entraînement AI est abstractisé en un processus simple de « soumission d'une demande et réception d'un résultat », devenant ainsi une capacité universelle plutôt qu'une technologie réservée à des experts.
2.2 De systèmes fermés à la collaboration ouverte : Quels problèmes Gradients résout-il ?
La modification fondamentale de Gradients réside dans la transformation du processus d'entraînement, autrefois confiné à une seule plateforme, en un processus de réseau ouvert et collaboratif. Les tâches d'entraînement ne sont plus accomplies par un seul système, mais réparties entre plusieurs participants qui les exécutent en parallèle, puis évaluées selon un mécanisme unifié pour sélectionner les meilleurs résultats. Cette structure réduit d'abord la dépendance aux fournisseurs centralisés, en fondant l'entraînement sur une puissance de calcul distribuée ; en même temps, les ressources GPU dispersées sont intégrées au même réseau, formant, dans un cadre de concurrence, un mode de allocation des ressources plus proche du marché. Plus important encore, l'optimisation des modèles ne se limite plus à une seule voie, mais progresse constamment vers des solutions optimales grâce à l'exploration parallèle de multiples approches, augmentant ainsi la limite globale d'optimisation.
2.3 Changement fondamental : de l'outil au « marché d'entraînement »
Dans l'AutoML traditionnel, la plateforme agit davantage comme un outil aidant les utilisateurs à trouver la meilleure solution grâce à des algorithmes internes. Dans Gradients, ce processus ressemble plutôt à un « marché » en constante évolution : les utilisateurs publient des besoins, différents participants rivalisent sur la même tâche, et les résultats sont filtrés par un mécanisme d'évaluation. Ainsi, la performance du modèle ne dépend plus uniquement des capacités d'un système unique, mais émerge d'une concurrence et d'une itération continues impliquant de multiples acteurs. L'AutoML passe ainsi d'un problème technique relativement fermé à un processus dynamique guidé par des incitations, permettant à la capacité d'optimisation de s'étendre continuellement avec l'ajout de nouveaux participants. Ce changement confère à l'entraînement de l'IA des caractéristiques d'autorégulation similaires à celles d'un marché.
2.4 Rôle dans l'écosystème TAO : couche d'infrastructure d'entraînement d'IA
Dans le système de sous-réseaux de Bittensor, différents Subnets assument des fonctions variées telles que l'inférence, le traitement des données et l'entraînement, et Gradients se situe au niveau de l'entraînement. Il est chargé de convertir la puissance de calcul dispersée en résultats de modèles concrets, et grâce à des mécanismes de distribution et d'évaluation des tâches, il permet de planifier et d'optimiser continuellement ces ressources. En outre, il relie l'offre de puissance de calcul à la demande de modèles, transformant ainsi l'entraînement d'un simple processus de consommation de ressources en un processus de collaboration réseau organisable et optimisable. Dans ce système, Gradients agit comme un maillon central, transformant les ressources distribuées en capacités d'IA exploitables et soutenant le développement des applications de niveau supérieur.
3. Architecture principale : Comment l'entraînement de l'IA est-il effectué sur le réseau ?
Dans le chapitre précédent, nous avons mentionné que Gradients a transformé l'entraînement de l'IA de « réalisé à l'intérieur de la plateforme » en « réalisé par collaboration réseau ». Comment ce réseau fonctionne-t-il précisément ? Le cœur de ce chapitre consiste à décomposer ce processus de manière plus intuitive.
3.1 Formation distribuée : comment une tâche est-elle « accomplie par plusieurs personnes » ?
Vous pouvez imaginer Gradients comme un réseau de collaboration en continu qui s'exécute en permanence. Lorsqu'un utilisateur soumet une tâche d'entraînement, cette tâche n'est pas confiée à un seul système, mais est simultanément distribuée à plusieurs participants du réseau. Ces participants, en se basant sur les mêmes données et le même objectif, essaient chacun des méthodes d'entraînement différentes et soumettent leurs résultats dans un délai imparti. Le système évalue ensuite uniformément ces résultats et sélectionne la meilleure solution. Les résultats les plus performants reçoivent une récompense, tandis que les autres sont éliminés. Du point de vue de l'utilisateur, ce processus ne nécessite qu'une seule soumission de tâche, équivalente à un « appel » simultané à plusieurs approches d'optimisation différentes, avec sélection automatique de la meilleure solution. L'essentiel de cette méthode ne réside pas dans la puissance individuelle d'un nœud, mais dans la combinaison d'essais parallèles multiples et de la sélection automatique, permettant aux résultats de converger progressivement vers l'optimum.
Sur ce réseau, il existe trois types principaux de participants : les utilisateurs, les mineurs et les validateurs. Les utilisateurs soumettent les demandes d'entraînement ; les mineurs fournissent de la puissance de calcul et testent différentes méthodes d'entraînement ; les validateurs évaluent les résultats et sélectionnent le meilleur modèle. Cette répartition des tâches permet à la procédure d'entraînement de fonctionner en continu et d'identifier progressivement des solutions optimales. Dans l'ensemble, elle constitue un réseau collaboratif piloté par la « demande, l'offre et l'évaluation ».
3.2 AutoML piloté par le marché
Dans l'analyse du mécanisme précédente, on peut voir que Gradients ne se contente pas de transférer simplement l'AutoML sur la chaîne, mais modifie la logique fondamentale de l'optimisation des modèles en introduisant une participation multiple et des mécanismes d'incitation. L'AutoML traditionnel repose sur un système unique cherchant une solution optimale parmi un ensemble limité de chemins, tandis que dans Gradients, ce processus est étendu à l'ensemble du réseau : différents participants expérimentent continuellement diverses approches pour la même tâche et les filtrent et itèrent constamment grâce à une évaluation unifiée. Cela transforme l'optimisation des modèles en un processus dynamique répétitif, et non plus en une simple opération de calcul ponctuelle. Dans ce mécanisme, les résultats les plus performants génèrent des revenus plus élevés, attirant ainsi continuellement des participants à améliorer leurs stratégies et à faire progresser globalement les performances.
4. Mécanismes d'incitation et de compétition : Comment l'entraînement de l'IA crée-t-il un « cercle vertueux » ?
4.1 Mécanisme d'incitation (guidé par TAO) : Du comportement d'entraînement au retour sur investissement
La clé du fonctionnement à long terme de Gradients réside dans son mécanisme d'incitation, qui repose sur le système d'incitation natif fourni par Bittensor. Dans ce cadre, TAO est la crypto-monnaie native du réseau Bittensor et sert de « vecteur de valeur » dans tout le réseau : il récompense les participants qui fournissent de la puissance de calcul et contribuent à des modèles, tout en permettant, par le biais de la mise en gage et d'autres mécanismes, de participer à la répartition des poids des sous-réseaux et d'influencer la manière dont les ressources circulent entre les différents sous-réseaux.
La blockchain principale de Bittensor génère continuellement de nouvelles émissions d'incitation, soit des TAO (actuellement environ 3600 TAO par jour), qui sont réparties selon des règles spécifiques entre les différents sous-réseaux. La quantité attribuée à chaque sous-réseau dépend de son « performance » au sein du réseau global, par exemple son niveau d'activité, la qualité de ses contributions et son soutien financier. Pour le sous-réseau auquel appartient Gradients, cette part de TAO est à nouveau répartie en interne entre les participants. Le critère fondamental de cette répartition est la qualité des modèles contribués : plus le modèle est performant, plus le contributeur reçoit de récompenses.
Plus précisément, les mineurs soumettent les résultats de l'entraînement, tandis que les validateurs sont chargés de tester et d'évaluer ces résultats. Le système calcule le « poids de contribution » de chaque participant en fonction des évaluations, puis répartit les récompenses selon ce poids. Les modèles les plus performants (par exemple, ceux avec une meilleure capacité de généralisation et une stabilité supérieure) obtiennent des rendements plus élevés, tandis que les validateurs dont les évaluations sont plus précises et reflètent mieux la qualité réelle reçoivent également davantage d'incitations. Cette conception fait correspondre directement « faire mieux » à « gagner plus », incitant ainsi les participants à optimiser continuellement leurs modèles.
4.2 Concurrence entre sous-réseaux : pas seulement une concurrence interne, mais aussi un classement externe
En plus de la concurrence interne au sous-réseau, Gradients fait face à une « concurrence horizontale » au sein du réseau Bittensor entier. Étant donné que la répartition de TAO est dynamique, les différents sous-réseaux se disputent des poids plus élevés. Seuls les sous-réseaux qui produisent continuellement des résultats de haute qualité et attirent davantage de participants obtiennent une part plus importante des récompenses. Ainsi, les incitations de Gradients dépendent non seulement de la performance interne des modèles, mais aussi de sa compétitivité relative au sein de l'écosystème global. L'ensemble du système forme un cycle à plusieurs niveaux : une concurrence entre modèles à l'intérieur du sous-réseau, et une concurrence globale entre les sous-réseaux. En fin de compte, les investissements en puissance de calcul, la qualité des modèles et les retours économiques sont liés, créant un mécanisme de rétroaction positive en constante évolution.
4.3 Gradients 5.0 : De la concurrence au « mécanisme de tournoi »
Sur la base de la compétition continue initiale, Gradients a évolué vers un mécanisme plus structuré : le « entraînement par tournoi ». On peut le comprendre comme une compétition périodique : chaque cycle d'entraînement définit une fenêtre temporelle, durant laquelle plusieurs participants concourent sur la même tâche, et sont progressivement éliminés au fil de plusieurs étapes jusqu'à ce que la meilleure solution soit sélectionnée. Ce format met l'accent sur des comparaisons progressives et une évaluation centralisée. Un changement important réside dans le fait que les mineurs ne soumettent plus directement les résultats d'entraînement, mais plutôt les « méthodes d'entraînement » (code), qui sont ensuite exécutées de manière unifiée par les nœuds de validation. Cela améliore la justesse en éliminant les interférences dues à des environnements de calcul différents, tout en protégeant mieux la confidentialité des données et du processus d'entraînement. En outre, les solutions gagnantes sont souvent conservées et deviennent des méthodes réutilisables, semblables à des « meilleures pratiques » en constante accumulation. À long terme, ce mécanisme ne se contente pas de sélectionner les meilleurs modèles, mais construit également une bibliothèque en constante évolution de méthodes d'entraînement.
5. État de l'écosystème
5.1 Structure des participants : un réseau collaboratif composé de la demande, de l'offre et de l'évaluation
L'écosystème Gradients est composé de trois rôles centraux : les utilisateurs (côté demande), les mineurs (côté offre) et les validateurs (côté évaluation). Les utilisateurs comprennent principalement les développeurs d'IA, les petites et moyennes entreprises ainsi que les constructeurs Web3 — des groupes qui possèdent généralement une certaine base technique, mais manquent de puissance de calcul ou de capacités complètes d'entraînement de modèles, et préfèrent donc utiliser Gradients pour construire des modèles à moindre coût. Les mineurs fournissent de la puissance GPU et participent à la compétition pour les tâches d'entraînement, leur motivation principale étant d'obtenir des revenus en TAO. Les validateurs sont chargés d'évaluer et de classer les résultats d'entraînement, jouant un rôle essentiel pour garantir la qualité des modèles et le bon fonctionnement du mécanisme.
Du point de vue des profils d'utilisateurs plus précis, la base d'utilisateurs réels de Gradients présente un caractère nettement « semi-développeur » : elle diffère à la fois des laboratoires d'IA de pointe et des utilisateurs ordinaires sans compétences techniques, en étant principalement composée de développeurs dotés d'une certaine capacité technique et d'utilisateurs de la technologie Web3. Ce constat se reflète également dans la structure de sa communauté : l'écosystème actuel est dominé par l'anglais, avec des utilisateurs clés principalement situés dans les communautés de développeurs d'Amérique du Nord et d'Europe, tout en couvrant également une partie des mineurs d'Asie du Sud-Est et des fournisseurs mondiaux de ressources GPU. Dans l'ensemble, il s'agit d'une communauté de développeurs pilotée par la technologie.
5.2 État actuel de l'écosystème
Au 12 mai, le prix de l'alpha token de Gradients était d'environ 0,0255 TAO, avec environ 4 890 adresses détentrices, 243 mineurs et 12 validateurs, pour une répartition d'émission de 1,61 %. Par ailleurs, dans son pool de liquidité, la part de TAO est de 2,19 % et celle d'Alpha de 97,81 %. En termes de prix et de nombre d'adresses détentrices, Gradients dispose déjà d'une base d'utilisateurs et d'une certaine attention, mais reste globalement en phase de diffusion précoce. À titre de comparaison, le projet leader de l'écosystème TAO, Chutes, affichait ce jour-là un prix d'alpha token de 0,0877 TAO et 13 409 adresses détentrices.
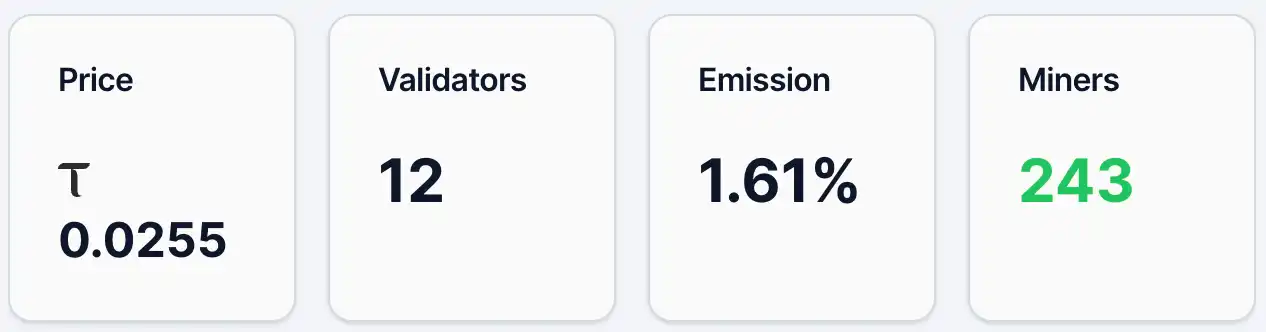
Figure 1. Données de dégradés.
Source :https://bittensormarketcap.com/subnets/56
Ensuite, le mécanisme d'émission. Dans le système Bittensor, l'émission désigne le poids de répartition en temps réel des récompenses nouvelles générées par l'ensemble du réseau à chaque sous-réseau. Le réseau Bittensor génère continuellement de nouveaux TAO et les distribue selon ces poids. Le taux actuel de 1,61 % de Gradients signifie qu'il ne reçoit qu'une petite part des récompenses nouvelles totales du réseau. Ce indicateur reflète essentiellement le « vote » du marché sur différents sous-réseaux, exprimé via les flux de capitaux (comme le staking). Ainsi, un niveau de 1,61 % indique généralement une reconnaissance et une entrée de capitaux limitées actuellement, mais implique également un potentiel de hausse du poids à l'avenir. Du point de vue de la structure des fonds (pools de liquidité), la part de TAO ne représente que 2,19 %, tandis qu'Alpha atteint 97,81 %, ce qui montre que les entrées de capitaux externes restent limitées et que l'offre actuelle est principalement interne au sous-réseau. Le prix est sensible aux nouveaux flux de capitaux ; une augmentation des entrées de TAO pourrait donc générer un effet amplificateur plus marqué.
6. Paysage concurrentiel et avantages/inconvénients
6.1 Positionnement industriel : infrastructure d'entraînement AutoML décentralisée
Gradients opère dans le segment spécialisé de « l'infrastructure d'entraînement IA + l'AutoML décentralisé ». Il vise à libérer l'entraînement de modèles des plateformes centralisées et à réaliser une utilisation plus efficace des ressources et une optimisation des modèles grâce à des mécanismes réseau. Dans l'écosystème Web2, ce segment est déjà relativement mature, avec des représentants typiques tels que Google Vertex AI et AWS SageMaker. Ces plateformes offrent aux développeurs des services intégrés d'entraînement et de déploiement de modèles via le cloud computing, mais leur architecture reste fondamentalement centralisée. En comparaison, la différence de Gradients ne réside pas dans « davantage de fonctionnalités », mais dans une logique sous-jacente différente : il transforme l'entraînement d'un « service de plateforme » en une « collaboration réseau », et utilise un mécanisme de concurrence pour sélectionner les meilleurs résultats, ce qui le rapproche davantage d'un système d'entraînement fonctionnant selon des principes de marché.
6.2 Comparaison horizontale : différences entre Web2 et Web3 AutoML
Du point de vue plus large, la différence entre Web2 et Web3 en matière d'AutoML correspond essentiellement à une comparaison entre deux paradigmes distincts. Le modèle Web2 met l'accent sur l'efficacité et la stabilité, en exploitant des ressources centralisées et des optimisations techniques pour offrir une expérience de service contrôlée et mature ; tandis que le modèle Web3 privilégie l'ouverture et les mécanismes d'incitation, en intégrant plusieurs parties prenantes pour permettre une évolution continue de l'optimisation des modèles par la concurrence. Concrètement, l'AutoML Web2 ressemble davantage à « un outil puissant » : l'utilisateur soumet sa tâche au plateau, qui recherche en interne la solution optimale ; en revanche, l'AutoML Web3, représenté par Gradients, agit comme « un marché ouvert » : l'utilisateur publie ses besoins, et divers participants proposent des solutions, suivies d'un mécanisme d'évaluation pour sélectionner les meilleurs résultats. Cette différence se traduit directement par : le premier modèle est plus stable et contrôlable, mais offre un chemin d'optimisation limité ; le second offre un espace d'exploration plus vaste et un potentiel supérieur, tout en conservant encore des marges d'amélioration en termes de stabilité et de maturité.
6.3 La différenciation de Gradients dans Web3
Dans le secteur actuel Web3 AI, la plupart des projets se concentrent encore sur la couche d'inférence ou les agents IA, tandis que les projets axés sur les « infrastructures d'entraînement » sont relativement rares. Certains projets tentent de combiner des réseaux de puissance de calcul ou de données pour fournir des capacités d'entraînement, mais dans l'ensemble, la plupart restent au niveau du routage des ressources ou du marché de la puissance de calcul. La différence de Gradients réside dans le fait qu'il ne se contente pas de proposer une mise en relation de puissance de calcul, mais s'étend davantage jusqu'au « mécanisme d'optimisation des modèles » lui-même, en introduisant un système d'évaluation et de compétition qui confère à l'entraînement une capacité d'évolution continue. Cela signifie qu'il ne résout pas seulement la question « d'où vient la puissance de calcul », mais aussi « comment l'utiliser de manière plus efficace ». Sur le plan du positionnement, Gradients ressemble davantage à un réseau orienté résultats d'entraînement qu'à un simple marché de puissance de calcul ou une plateforme d'outils — ce qui constitue la distinction fondamentale avec la plupart des projets Web3 AI.
6.4 Avantages clés : amélioration de l'efficacité pilotée par le mécanisme
Dans l'ensemble, les avantages de Gradients résident principalement dans sa conception mécanique. Tout d'abord, il réduit la barrière à l'entrée grâce à une abstraction des tâches, permettant aux utilisateurs d'obtenir des résultats de modèle sans avoir à participer activement à des processus d'entraînement complexes, élargissant ainsi la base potentielle d'utilisateurs. Ensuite, au niveau des ressources, l'introduction d'une puissance de calcul distribuée permet de ne plus dépendre d'un seul fournisseur de cloud ; théoriquement, la concurrence peut créer une structure de coûts plus résiliente. Plus important encore, son approche d'optimisation a changé. En permettant à plusieurs participants d'explorer en parallèle et en combinant un mécanisme de sélection, Gradients propose une solution différente de l'optimisation traditionnelle à chemin unique, offrant aux modèles la possibilité d'atteindre des performances supérieures en un temps plus court. Ce modèle d'optimisation piloté par la concurrence constitue son avantage le plus fondamental.
6.5 Défis potentiels
La qualité du modèle peut présenter des problèmes de stabilité. L'entraînement décentralisé repose sur la participation de plusieurs parties ; bien qu'il puisse augmenter la performance maximale, il peut aussi entraîner des fluctuations dans les résultats, présentant une certaine incertitude en termes de contrôlabilité par rapport aux systèmes centralisés. Ensuite, il y a le problème de la confiance au niveau professionnel. Pour les utilisateurs professionnels, la sécurité des données et la vérifiabilité du processus d'entraînement sont essentielles ; garantir, dans un environnement décentralisé, que les données ne soient pas mal utilisées et que les résultats soient auditables reste un défi majeur. Enfin, il y a la dépendance au modèle économique des jetons. Le fonctionnement de Gradients repose fortement sur des mécanismes d'incitation ; si l'attractivité des revenus TAO diminue, cela pourrait affecter la participation des mineurs et l'activité globale du réseau. Par conséquent, sa durabilité à long terme dépend en partie de la capacité du modèle économique à établir un cercle vertueux stable.
7. Perspectives futures : le AutoML décentralisé peut-il exister ?
À ce stade, Gradients reste en phase précoce ; sa capacité à réussir à long terme dépend de plusieurs points clés. Le plus essentiel est de parvenir à attirer en continu des besoins réels d'entraînement, et non seulement une participation motivée par des incitations. Ensuite, la qualité des modèles : le modèle décentralisé peut-il produire de manière stable des résultats utilisables, voire supérieurs ? Enfin, le mécanisme économique peut-il créer une boucle positive, assurant un équilibre durable entre l'offre de puissance de calcul et les revenus.
Dans un contexte industriel plus large, l'entraînement de l'IA se divise en deux voies. L'une est le modèle Web2, dominé par les grandes entreprises technologiques, qui renforcent continuellement les performances des modèles grâce à des ressources et des compétences techniques centralisées, avec l'avantage de la stabilité et de la maturité ; l'autre est la voie Web3 représentée par Gradients, qui, grâce à un réseau ouvert et à des mécanismes d'incitation, permet à un plus grand nombre de participants de contribuer à l'optimisation des modèles et d'élever constamment leur potentiel dans un contexte concurrentiel. La première consiste à « construire des systèmes plus puissants », tandis que la seconde ressemble davantage à « construire un réseau capable de s'auto-évoluer ».
Du point de vue de cette perspective, l'exploration de Gradients représente une nouvelle possibilité : l'entraînement de l'IA n'est plus seulement une question technique, mais une combinaison de « puissance de calcul + données + mécanismes de marché ». Si ce modèle s'avère viable, il pourrait devenir une porte d'entrée pour l'entraînement de l'IA décentralisée et jouer un rôle d'infrastructure clé au sein de l'écosystème Bittensor. Bien sûr, cette voie nécessite encore du temps pour être validée, mais elle offre déjà à l'AutoML une voie d'évolution différente de celle traditionnelle.
Référence
1. Documentation Bittensor :https://docs.learnbittensor.org
2. Site web Gradients :https://www.gradients.io/
3. Gradients :https://bittensormarketcap.com/subnets/56
4. Gradients X : https://x.com/gradients_ai
5. Taostats : https://taostats.io/subnets/56/chart