









Auteur : Shenchao TechFlow
Un article de recherche prétendant « réduire la consommation de mémoire de l'IA à 1/6 » a provoqué la semaine dernière une perte de plus de 90 milliards de dollars de capitalisation boursière pour les actions mondiales de puces de stockage telles que Micron et SanDisk.
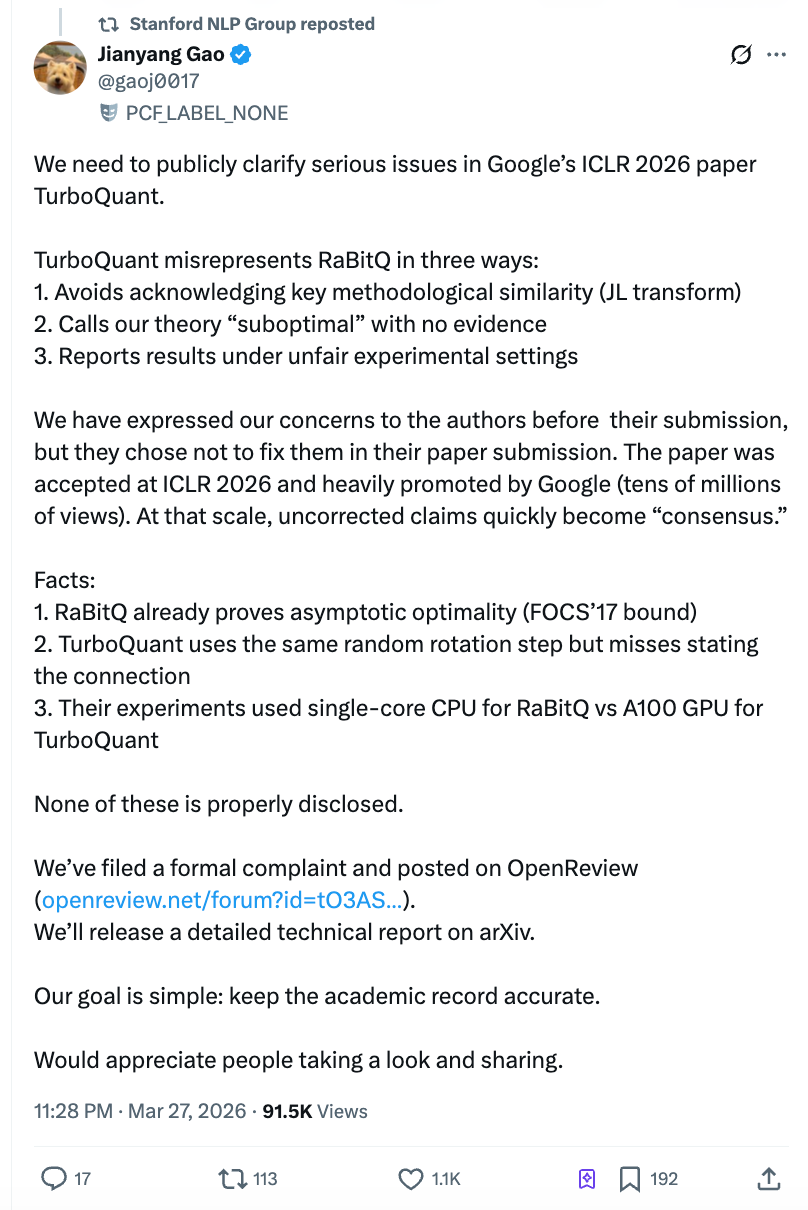
Cependant, seulement deux jours après la publication de l'article, Gao Jianyang, post-doctorant à l'École polytechnique fédérale de Zurich, a publié une lettre ouverte de dix mille caractères accusant l'équipe de Google d'avoir testé son concurrent avec un script Python sur un seul cœur CPU, tout en utilisant une GPU A100 pour ses propres tests, et d'avoir refusé de corriger le problème malgré avoir été informé avant soumission. La lecture sur Zhihu a rapidement dépassé 4 millions, et le compte officiel Stanford NLP a partagé l'article, provoquant une réaction simultanée dans le monde académique et sur le marché.
(Lecture de référence : un article scientifique qui a fait chuter les actions de stockage)
La question centrale de ce débat n'est pas compliquée : un article de conférence IA, largement promu par Google et ayant directement déclenché une vente massivement paniquée sur le secteur des puces, a-t-il systématiquement déformé un travail antérieur déjà publié, en créant délibérément des expériences inéquitables pour établir un récit de supériorité de performance factice ?
Ce que TurboQuant a fait : réduire le « brouillon » de l'IA à un sixième de sa taille d'origine
Lors de la génération de réponses, les grands modèles linguistiques doivent constamment revenir en arrière pour consulter les contenus précédemment calculés. Ces résultats intermédiaires sont temporairement stockés dans la mémoire vidéo, ce qu'on appelle dans l'industrie le « KV Cache » (cache clé-valeur). Plus la conversation est longue, plus ce « brouillon » devient épais, ce qui augmente la consommation de mémoire vidéo et les coûts associés.
L'algorithme TurboQuant, développé par l'équipe de recherche de Google, se distingue en compressant ce brouillon à 1/6 de sa taille originale, tout en affirmant une perte de précision nulle et une accélération de l'inférence jusqu'à 8 fois. L'article a été publié pour la première fois sur la plateforme de prépublications académiques arXiv en avril 2025, accepté en janvier 2026 par la conférence de pointe en intelligence artificielle ICLR 2026, puis relancé par le blog officiel de Google le 24 mars.
Sur le plan technique, l'approche de TurboQuant peut être simplifiée ainsi : d'abord, une transformation mathématique est utilisée pour « nettoyer » les données désordonnées et les convertir en un format uniforme, puis un tableau de compression optimal pré-calculé est appliqué pour compresser chaque élément, enfin, un mécanisme de correction d'erreurs sur 1 bit corrige les biais de calcul introduits par la compression. Une implémentation indépendante par la communauté a confirmé que l'efficacité de compression est essentiellement réelle, et la contribution mathématique de l'algorithme est authentique.
Le débat ne porte pas sur la faisabilité de TurboQuant, mais sur ce que Google a fait pour prouver qu'il « dépasse largement ses concurrents ».
Lettre ouverte de Gao Jianyang : trois allégations, chacune touchant au cœur du problème
Le 27 mars à 22 h, Gao Jianyang a publié un long article sur Zhihu et a soumis un commentaire officiel sur la plateforme d'évaluation d'ICLR, OpenReview. Gao Jianyang est le premier auteur de l'algorithme RaBitQ, publié en 2024 dans la conférence de pointe en base de données SIGMOD, qui traite le même type de problème — la compression efficace de vecteurs de haute dimension.
Ses allégations sont divisées en trois points, chacun étayé par des enregistrements d'e-mails et une chronologie.
Allégation 1 : Utilisation de la méthode principale d'autrui sans mention dans le texte.
Une étape clé commune aux noyaux techniques de TurboQuant et de RaBitQ consiste à effectuer une « rotation aléatoire » des données avant compression. Cette opération transforme des données initialement distribuées de manière irrégulière en une distribution uniforme prévisible, réduisant ainsi considérablement la complexité de la compression. Il s'agit de la partie la plus centrale et la plus similaire entre les deux algorithmes.
L'auteur de TurboQuant a lui-même reconnu cela dans sa réponse aux relecteurs, mais n'a jamais explicitement mentionné ce lien avec RaBitQ dans le corps complet de l'article. Le contexte encore plus crucial est que Majid Daliri, le deuxième auteur de TurboQuant, a contacté activement l'équipe de Gao Jianyang en janvier 2025 pour demander de l'aide afin de déboguer sa version Python modifiée à partir du code source de RaBitQ. L'e-mail décrivait en détail les étapes de reproduction et les messages d'erreur — autrement dit, l'équipe de TurboQuant possédait une connaissance approfondie des détails techniques de RaBitQ.
Un relecteur anonyme de ICLR a également souligné indépendamment que les deux utilisent la même technologie, exigeant une discussion approfondie. Toutefois, dans la version finale de l'article, l'équipe TurboQuant n'a pas ajouté de discussion, mais a plutôt déplacé la description (déjà incomplète) de RaBitQ du corps principal vers l'annexe.
Allégation deux : affirmer sans preuve que la théorie de l'autre est « sous-optimale ».
Le papier de TurboQuant étiquette directement RaBitQ comme « sous-optimal » en raison d'une analyse mathématique « grossière ». Toutefois, Gao Jianyang souligne que la version étendue de RaBitQ a rigoureusement démontré que son erreur de compression atteint la borne optimale mathématique — une conclusion publiée dans une conférence de premier plan en informatique théorique.
En mai 2025, l'équipe de Gao Jianyang a expliqué en détail, à travers plusieurs échanges par courriel, l'optimalité de la théorie RaBitQ. Daliri, deuxième auteur de TurboQuant, a confirmé avoir informé tous les auteurs. Toutefois, la version finale de l'article a conservé la formulation « sous-optimale », sans fournir aucune contre-argumentation.
Allégation 3 : Dans la comparaison expérimentale, « la main gauche lie la personne, la main droite tient le couteau ».
C'est la plus percutante de toutes les affirmations. Gao Jianyang souligne que l'article de TurboQuant a ajouté deux conditions inéquitables lors des expériences de comparaison de vitesse :
Premièrement, RaBitQ offre officiellement du code C++ optimisé (avec prise en charge par défaut du parallélisme multithread), mais l'équipe TurboQuant ne l'a pas utilisé, préférant tester RaBitQ avec sa propre version traduite en Python. Deuxièmement, les tests de RaBitQ ont été effectués sur un CPU mono-cœur avec le multithread désactivé, tandis que TurboQuant a utilisé une GPU NVIDIA A100.
L'effet combiné de ces deux conditions est que le lecteur conclut que « RaBitQ est plusieurs ordres de grandeur plus lent que TurboQuant », sans être informé que cette conclusion repose sur le fait que l'équipe Google avait lié les mains de son adversaire avant de courir. Les différences entre ces conditions expérimentales ne sont pas suffisamment divulguées dans l'article.
La réponse de Google : « La rotation aléatoire est une technique générale, il est impossible de citer chaque article. »
Selon Gao Jianyang, l'équipe TurboQuant a répondu dans un e-mail en mars 2026 : « L'utilisation de la rotation aléatoire et de la transformation Johnson-Lindenstrauss est déjà une technique standard dans ce domaine, et il est impossible de citer chaque article utilisant ces méthodes. »
L'équipe de Gao Jianyang considère qu'il s'agit d'un changement de concept : la question n'est pas de citer tous les articles ayant utilisé la rotation aléatoire, mais que RaBitQ est le premier travail à combiner cette méthode avec la compression vectorielle et à prouver son optimalité dans le même cadre de problème, ce que le papier TurboQuant devrait décrire avec précision.
Le compte officiel X du Stanford NLP Group a partagé la déclaration de Gao Jianyang. L'équipe de Gao Jianyang a publié un commentaire public sur la plateforme ICLR OpenReview et a déposé une plainte formelle auprès du président de la conférence ICLR et du comité d'éthique ; un rapport technique détaillé sera par la suite publié sur arXiv.
Le blogueur technique indépendant Dario Salvati a fourni une évaluation relativement neutre dans son analyse : TurboQuant apporte effectivement une contribution réelle sur le plan mathématique, mais sa relation avec RaBitQ est bien plus étroite que ce que les articles indiquent.
90 milliards de dollars de capitalisation boursière évaporés : polémique autour d’un article scientifique combinée à la panique sur le marché
Le moment de ce débat académique est extrêmement délicat. Après que Google ait publié TurboQuant sur son blog officiel le 24 mars, le secteur mondial des puces de stockage a subi une vente massive. Selon plusieurs médias, dont CNBC, Micron Technology a chuté pendant six jours consécutifs, avec une baisse cumulée de plus de 20 % ; SanDisk a perdu 11 % en une seule journée ; SK Hynix en Corée du Sud a reculé d’environ 6 %, Samsung Electronics de près de 5 %, et Kioxia au Japon d’environ 6 %. La logique de panique sur le marché est simple et directe : la compression logicielle peut réduire la demande mémoire pour l’inférence IA jusqu’à six fois, ce qui entraînera une révision structurelle à la baisse des perspectives de demande pour les puces de stockage.
L'analyste de Morgan Stanley, Joseph Moore, a réfuté ce raisonnement dans un rapport du 26 mars, maintenant les notes « Acheté » pour Micron et SanDisk. Moore a souligné que TurboQuant ne compresse que le cache KV, un type spécifique de mémoire tampon, et non l'utilisation globale de la mémoire, le qualifiant de « simple amélioration de productivité ». L'analyste d'Wells Fargo, Andrew Rocha, a également invoqué le paradoxe de Jevons, affirmant qu'une augmentation de l'efficacité réduisant les coûts pourrait en réalité stimuler un déploiement plus vaste de l'IA, augmentant ainsi la demande en mémoire.
Anciens articles, nouvel emballage : risques de transmission de la recherche en IA aux récits de marché
Selon l'analyse du blogueur technique Ben Pouladian, le papier de TurboQuant a été publié publiquement en avril 2025 et n'est pas une nouvelle recherche. Le 24 mars, Google l'a relancé via son blog officiel, mais le marché l'a traité comme une avancée révolutionnaire en le valorisant ainsi. Cette stratégie de communication « ancien papier, nouvelle publication », combinée à d'éventuels biais expérimentaux dans le papier, révèle les risques systémiques dans la chaîne de transmission entre la recherche en IA et les récits du marché.
Pour les investisseurs dans les infrastructures d'IA, lorsqu'un article affirme avoir réalisé une amélioration de performance de « plusieurs ordres de grandeur », il faut d'abord se demander si les conditions de comparaison du benchmark sont équitables.
L'équipe de Gao Jianyang a clairement indiqué qu'elle continuerait de promouvoir la résolution formelle du problème. Google n'a pas encore répondu officiellement aux allégations spécifiques de la lettre ouverte.