









Article rédigé par Zack Pokorny
Traduction : Chopper, Foresight News
Le déploiement d'agents intelligents sur la blockchain n'a pas été sans difficultés : bien que la blockchain possède des caractéristiques programmables et sans autorisation, elle manque d'abstractions sémantiques et d'une couche de coordination adaptées aux agents. L'organisme de recherche cryptographique Galaxy a publié un rapport indiquant que les agents rencontrent quatre frictions structurelles sur la chaîne : la détection d'opportunités, la vérification fiable, l'accès aux données et les processus d'exécution. Les infrastructures actuelles sont toujours conçues autour des interactions humaines et ne parviennent pas à soutenir la gestion autonome des actifs et l'exécution de stratégies par l'IA, ce qui constitue les principaux freins à l'adoption à grande échelle des agents sur la blockchain. Voici la traduction complète du rapport :
Les scénarios d'application et les capacités des agents IA commencent à évoluer. Ils commencent à exécuter des tâches de manière autonome et sont développés pour détenir et configurer du capital, ainsi que pour identifier des stratégies de trading et de rendement. Bien que cette transition expérimentale soit encore à un stade extrêmement précoce, elle diffère radicalement de l'évolution précédente des agents, qui étaient principalement utilisés comme outils sociaux et analytiques.
La blockchain devient le terrain d'essai naturel de cette évolution. La blockchain est sans autorisation, composable, dispose d'un écosystème d'applications open source, offre un accès équitable aux données à tous les participants, et tous les actifs sur chaîne sont par défaut programmables.
Cela soulève une question structurelle : si la blockchain est programmable et sans autorisation, pourquoi les agents autonomes rencontrent-ils encore des frictions ? La réponse ne réside pas dans la faisabilité de l'exécution, mais dans la charge sémantique et de coordination qui repose au-dessus de l'exécution. La blockchain garantit la correction des transitions d'état, mais ne fournit généralement pas d'abstractions natives au protocole, comme celles nécessaires pour l'interprétation économique, la normalisation de l'identité ou la coordination au niveau des objectifs.
Une partie de la friction provient des défauts d'architecture des systèmes sans autorisation, et une autre partie reflète l'état actuel des outils, de la gestion des contenus et de l'infrastructure du marché. En réalité, de nombreuses fonctions de niveau supérieur dépendent encore de logiciels et de flux de travail qui nécessitent une intervention humaine pour être construits.
Architecture blockchain et agents IA
La conception de la blockchain repose sur la concorde et l'exécution déterministe, et non sur l'interprétation sémantique. Elle expose des primitives sous-jacentes telles que des emplacements de stockage, des journaux d'événements et des traces d'appels, et non des objets économiques standardisés. Par conséquent, des concepts abstraits tels que les positions, les rendements, les coefficients de santé et la profondeur de liquidité doivent généralement être重构 hors chaîne par des indexeurs, des couches d'analyse de données, des interfaces utilisateur et des API, afin de transformer les états spécifiques à chaque protocole en formes plus utilisables.
De nombreuses opérations de finance décentralisée grand public, en particulier celles axées sur les particuliers et les décisions subjectives, reposent toujours sur le modèle où l'utilisateur interagit via une interface frontale et signe chaque transaction individuellement. Ce modèle centré sur l'interface utilisateur s'est étendu avec la popularisation des particuliers, même si une grande partie des activités sur chaîne sont désormais pilotées par des machines. Le modèle dominant d'interaction des particuliers reste le suivant : intention → interface utilisateur → transaction → confirmation. Les opérations automatisées suivent un autre chemin, mais présentent également leurs propres limites : les développeurs choisissent au moment de la conception les contrats et l'ensemble des actifs, puis exécutent des algorithmes dans ce cadre fixe. Aucun de ces deux modèles ne peut s'adapter aux systèmes qui doivent découvrir, évaluer et combiner dynamiquement des opérations pendant l'exécution, en fonction d'objectifs en constante évolution.
Lorsqu’une infrastructure optimisée pour la vérification des transactions est utilisée par des systèmes nécessitant d’interpréter simultanément l’état économique, d’évaluer la crédibilité et d’optimiser les comportements autour d’objectifs précis, des frictions commencent à apparaître. Ces écarts proviennent en partie des caractéristiques de conception sans autorisation et hétérogène de la blockchain, et en partie du fait que les outils d’interaction sont toujours construits autour d’une revue humaine et d’intermédiaires frontaux.
Comparaison entre le processus de comportement des agents et les stratégies d'algorithmes traditionnels
Avant d'explorer l'écart entre les infrastructures blockchain et les systèmes d'agents, il est essentiel de clarifier : quelle est la différence entre des processus comportementaux plus intelligents et autonomes, et les systèmes algorithmiques traditionnels sur chaîne ?
La différence ne réside pas dans le niveau d'automatisation, la complexité, les paramètres configurables, ni même dans la capacité d'adaptation dynamique. Les systèmes d'algorithmes traditionnels peuvent être hautement paramétrisés, détecter automatiquement de nouveaux contrats et de nouveaux tokens, répartir les fonds entre plusieurs types de stratégies et les rééquilibrer en fonction des performances. La vraie différence réside dans la capacité du système à gérer des scénarios non prévus lors de la phase de conception.
Les systèmes d'algorithmes traditionnels, aussi complexes soient-ils, n'exécutent que des logiques prédéfinies sur des modèles prédéfinis. Ils nécessitent des analyseurs d'interfaces prédéfinis pour chaque type de protocole, des logiques d'évaluation prédéfinies pour mapper l'état du contrat en termes économiques, des règles explicites pour juger de la crédibilité et de la normalité, ainsi que des règles codées en dur pour chaque branche de décision. Lorsqu'une situation ne correspond pas à un modèle prédéfini, le système soit l'ignore, soit échoue directement. Il ne peut pas raisonner sur des scénarios inconnus ; il ne peut que déterminer si le scénario actuel correspond à un modèle connu.
Comme ce dispositif mécanique « canard de digestion », capable de simuler des comportements biologiques, mais dont tous les mouvements sont préprogrammés.
Un algorithme traditionnel qui scanne les marchés de prêt DeFi peut identifier de nouveaux contrats déployés émettant des événements familiers ou correspondant à des modèles d'usine connus. Toutefois, si un nouvel élément de base de prêt à l'interface inconnue apparaît, le système ne peut pas l'évaluer. Un humain doit examiner le contrat, comprendre son mécanisme de fonctionnement, déterminer s'il constitue une opportunité exploitable et écrire la logique d'intégration. Seulement après cela, l'algorithme peut interagir avec lui. L'humain interprète, l'algorithme exécute. Les systèmes d'agents basés sur des modèles fondamentaux modifient cette frontière : ils peuvent réaliser des raisonnements appris :
- Interpréter des objectifs vagues ou mal définis. Des instructions telles que « maximiser les rendements tout en évitant un risque excessif » nécessitent une interprétation sémantique. Qu'est-ce qui constitue un risque excessif ? Comment équilibrer rendement et risque ? Les algorithmes traditionnels exigent une définition précise de ces critères à l'avance. En revanche, les agents sont capables d'interpréter l'intention, de prendre des décisions et d'optimiser leur compréhension en fonction des retours.
- Peut généraliser et s'adapter à des interfaces inconnues. L'agent peut lire du code de contrat inconnu, analyser des documents ou examiner des interfaces binaires d'applications auxquelles il n'a jamais été confronté, et en déduire la fonction économique du système. Il n'a pas besoin de pré-construire des parseurs pour chaque type de protocole. Bien que cette capacité ne soit pas encore parfaitement développée et que l'agent puisse mal interpréter ce qu'il voit, il est capable d'interagir avec des systèmes non prévus lors de la phase de construction.
- Raisonner dans un contexte d'incertitude concernant la confiance et la normativité. Lorsque les signaux de crédibilité sont flous ou incomplets, le modèle fondamental peut évaluer probabilistiquement ces signaux, plutôt que d'appliquer simplement des règles binaires. Ce contrat intelligent est-il standard ? Sur la base des preuves disponibles, ce jeton est-il légal ? Les algorithmes traditionnels suivent soit des règles, soit ne peuvent rien faire ; les agents, eux, peuvent raisonner sur le niveau de confiance.
- Expliquez l'erreur et apportez les ajustements nécessaires. En cas de situation imprévue, l'agent peut raisonner sur la cause du problème et décider de la réponse appropriée. À l'inverse, les algorithmes traditionnels se contentent d'exécuter un module de capture d'exceptions, se limitant à transmettre les informations d'erreur sans les interpréter.
Ces capacités existent réellement aujourd'hui, mais elles ne sont pas parfaites. Les modèles de base peuvent générer des hallucinations, mal interpréter le contenu et prendre des décisions erronées avec une apparence de certitude. Dans un environnement adversarial impliquant des capitaux (où le code peut contrôler ou recevoir des actifs), « essayer d'interagir avec des systèmes non prévus » peut signifier une perte de fonds. L'idée centrale de cet article n'est pas que les agents soient désormais capables d'exécuter ces fonctions de manière fiable, mais qu'ils puissent essayer des approches impossibles pour les systèmes traditionnels, et que les infrastructures futures permettront de rendre ces essais plus sûrs et plus fiables.
Cette différence devrait plutôt être considérée comme un continuum, et non comme une limite catégorique absolue. Certains systèmes traditionnels intègrent des formes de raisonnement appris, et certains agents peuvent également dépendre de règles codées en dur sur des chemins critiques. Cette distinction est orientée, et non binaire absolue. Les systèmes d'agents déplacent une plus grande partie de l'interprétation, de l'évaluation et de l'adaptation vers le raisonnement en temps d'exécution, plutôt que vers des règles prédéfinies lors de la phase de construction. Ce point est essentiel pour la discussion sur les frictions, car les systèmes d'agents cherchent à accomplir exactement ce que les algorithmes traditionnels évitent complètement. Les algorithmes traditionnels évitent la découverte de frictions en faisant trier les ensembles de contrats par des humains pendant la phase de construction ; ils évitent les frictions au niveau du contrôle en s'appuyant sur des listes blanches maintenues par des opérateurs ; ils évitent les frictions liées aux données en utilisant des analyseurs préconçus pour des protocoles connus ; et ils évitent les frictions d'exécution en fonctionnant à l'intérieur de limites de sécurité prédéfinies. Les humains accomplissent à l'avance les tâches sémantiques, de crédit et de stratégie, tandis que les algorithmes n'effectuent que des actions dans les limites fixées. Les premiers flux de comportement des agents sur chaîne pourraient suivre ce modèle, mais la valeur fondamentale des agents réside dans le déplacement de la découverte, de l'évaluation du crédit et de la stratégie vers le raisonnement en temps d'exécution, et non vers des préconfigurations lors de la phase de construction.
Ils tenteront de découvrir et d'évaluer des opportunités inconnues, de raisonner sur la standardité sans règles codées en dur, d'interpréter des états hétérogènes sans parseur prédéfini, et d'exécuter des contraintes stratégiques sur des objectifs potentiellement vagues. La présence de frottements ne provient pas du fait que les agents accomplissent les mêmes tâches que les algorithmes, mais avec une difficulté accrue ; elle découle du fait qu'ils tentent des choses radicalement différentes : opérer dans un espace de comportements ouvert et interprété dynamiquement, et non dans un système fermé et pré-intégré.
Friction
Sur le plan structurel, cette contradiction ne provient pas d’un défaut du consensus blockchain, mais du fonctionnement de l’ensemble de la pile d’interactions qui l’entoure.
La blockchain garantit des transitions d'état déterministes, un consensus sur l'état final et la finalité. Elle ne tente pas d'encoder au niveau du protocole des interprétations de significations économiques, la vérification des intentions ou le suivi des objectifs. Ces responsabilités ont toujours été assumées par les interfaces frontales, les portefeuilles, les indexeurs et d'autres couches de coordination hors chaîne, nécessitant toujours une intervention humaine.
Même pour les participants expérimentés, le modèle d'interaction dominant actuel reflète cette conception. Les particuliers interprètent l'état via un tableau de bord, sélectionnent des actions via une interface utilisateur, et signent des transactions via un portefeuille, tout en vérifiant de manière informelle les résultats. Les institutions de trading algorithmique ont automatisé l'exécution, mais dépendent toujours d'opérateurs humains pour filtrer les ensembles de protocoles, détecter les anomalies et mettre à jour la logique d'intégration lors de changements d'interface. Dans les deux cas, le protocole se contente de garantir la correction de l'exécution, tandis que l'interprétation des intentions, la gestion des anomalies et l'adaptation aux nouvelles opportunités restent à la charge de l'humain.
Les systèmes d'agents compressent voire éliminent cette division du travail. Ils doivent restructurer de manière programmatique des états portant une signification économique, évaluer la progression vers les objectifs et valider les résultats de l'exécution, et non se limiter à confirmer la mise sur chaîne des transactions. Sur la blockchain, ces responsabilités sont particulièrement marquées, car les agents opèrent dans un environnement ouvert, adversarial et en constante évolution, où de nouveaux contrats, actifs et chemins d'exécution peuvent apparaître sans examen centralisé. Le protocole garantit uniquement l'exécution correcte des transactions, mais pas la lisibilité des états économiques, la standardisation des contrats, le respect des intentions de l'utilisateur par les chemins d'exécution, ou la possibilité de découvrir de manière programmatique les opportunités associées.
Ci-dessous, nous examinerons étape par étape les friction rencontrées au cours des différentes phases du cycle d'exécution de l'agent : identifier les contrats et opportunités existants, vérifier leur légalité, obtenir des états ayant une signification économique, et exécuter des opérations autour des objectifs.
Découvrir la friction
La friction émerge du fait que l'espace d'activité de la finance décentralisée s'étend librement dans un environnement sans autorisation, tandis que la pertinence et la légitimité sont filtrées par les humains via les couches sociales, de marché et d'outils sur chaîne. De nouveaux protocoles apparaissent par des annonces, puis sont filtrés par des couches telles que l'intégration frontale, la liste des jetons, les plateformes d'analyse de données et la formation de liquidité. Avec le temps, ces signaux tendent à former un critère de jugement viable pour distinguer les parties de l'espace d'activité qui possèdent une valeur économique et une crédibilité suffisante, bien que ce consensus puisse être informel, inégal et partiellement dépendant de filtres tiers et humains.
On peut fournir aux agents des données filtrées et des signaux de confiance, mais ils ne possèdent pas les raccourcis intuitifs que les humains utilisent pour interpréter ces signaux. Du point de vue chain-on, tous les contrats déployés sont également accessibles. Les protocoles légitimes, les forks malveillants, les déploiements de test et les projets abandonnés existent tous sous forme de bytecode appelable. La blockchain elle-même ne code pas la notion de quels contrats sont importants ou sécurisés.
Ainsi, l'agent doit construire son propre mécanisme de découverte : scanner les événements de déploiement, identifier les modèles d'interface, suivre les contrats usine (c'est-à-dire les contrats capables de déployer d'autres contrats de manière programmée) et surveiller la formation de la liquidité afin de déterminer quels contrats doivent être inclus dans la prise de décision. Ce processus ne consiste pas seulement à rechercher des contrats, mais à évaluer s'ils doivent entrer dans l'espace d'action de l'agent.
Identifier les candidats n’est qu’une première étape. Après le filtrage initial par le contrat, ceux-ci doivent encore passer par le processus de vérification de la standardisation et de l’authenticité décrit dans la section suivante. L’agent doit d’abord confirmer que le contrat découvert correspond bien à ce qu’il prétend être, avant de l’inclure dans l’espace de décision.
La détection de friction ne signifie pas détecter de nouveaux comportements déployés. Des systèmes algorithmiques matures sont déjà capables de le faire au sein de leurs propres stratégies. Les chercheurs qui surveillent les événements de l'usine Uniswap et intègrent automatiquement de nouveaux pools de liquidité effectuent une découverte dynamique. La friction apparaît à deux niveaux supérieurs : déterminer si le contrat découvert est légitime, et s'il est lié à des objectifs ouverts, et non simplement correspondant à un type de stratégie prédéfini.
La logique de découverte du chercheur est étroitement liée à sa stratégie. Il sait quelles structures d'interface rechercher, car la stratégie les a définies. En revanche, un agent chargé d'exécuter des instructions plus larges, telles que « configurer les meilleures opportunités ajustées au risque », ne peut pas se contenter de filtres dérivés de la stratégie. Il doit évaluer les nouvelles opportunités rencontrées par rapport aux objectifs eux-mêmes, ce qui exige de comprendre des interfaces inconnues, d'inférer leurs fonctions économiques et de déterminer si ces opportunités doivent être intégrées à l'espace de décision. Cela relève en partie du problème de l'autonomie générale, mais la blockchain aggrave ce problème.
Contrôler la friction
La génération de friction au niveau du contrôle provient du fait que l'identification et la légitimité sont généralement déterminées en dehors du protocole, en s'appuyant sur un ensemble de critères tels que le filtrage, la gouvernance, la documentation, les interfaces et le jugement des opérateurs. Dans de nombreux processus actuels, l'être humain reste une composante essentielle de cette étape de décision. La blockchain garantit l'exécution déterministe et la finalité, mais ne garantit pas que l'appelant interagit avec le contrat cible. Cette détermination de l'intention est externalisée vers des contextes sociaux, des sites web et un filtrage humain.
Dans le processus actuel, les humains utilisent la couche de confiance du site web comme moyen de vérification informel. Ils accèdent au domaine officiel (généralement trouvé via des plateformes agrégatrices comme DeFiLlama ou des comptes sociaux vérifiés du projet) et considèrent ce site comme le support standard de la correspondance entre les concepts humains et les adresses de contrat. Ensuite, l’interface frontale établit un référentiel de confiance opérationnel, identifiant clairement quelles adresses sont officielles, quelles balises de jeton utiliser, et quels points d’entrée sont sécurisés.

Le Turc mécanique de 1789 est une machine à échecs qui semble fonctionner de manière autonome, mais qui repose en réalité sur un opérateur humain caché.
Les agents intelligents ne peuvent pas par défaut interpréter les identités de marque, les signaux d'authentification sociale ou la « légitimité » dans un contexte social. Il est possible de leur fournir des données filtrées issues de ces signaux, mais pour les transformer en hypothèses de confiance machine durables et exploitables, il faut un registre explicite, une stratégie ou une logique de vérification. Il est possible de configurer les agents avec des listes blanches filtrées, des adresses certifiées et des stratégies de confiance fournies par les opérateurs. Le problème n'est pas que le contexte social soit entièrement inaccessibles, mais que le coût opérationnel pour maintenir ces mesures de protection dans un espace comportemental en expansion dynamique soit très élevé, et que, en l'absence ou l'imperfection de ces mesures, les agents manquent de mécanismes de vérification de secours que les humains utilisent par défaut.
Le système piloté par des agents blockchain a déjà entraîné des conséquences concrètes dues à une évaluation de confiance insuffisante. Dans le cas du célèbre blogueur de cryptomonnaies Orangie, un agent aurait déposé des fonds dans un contrat piège. Dans un autre cas, l'agent nommé Lobstar Wilde, en raison d'une défaillance d'état ou de contexte, a mal interprété l'état d'une adresse et a transféré un important solde de jetons à un « mendiant » en ligne. Ces exemples ne constituent pas des arguments centraux, mais suffisent à illustrer comment des erreurs d'évaluation de confiance, d'interprétation d'état et de stratégie d'exécution peuvent entraîner directement une perte de fonds.
Le problème n’est pas que les contrats soient difficiles à trouver, mais que la blockchain ne possède généralement pas de concept natif de « ceci est le contrat officiel de cette application ». Ce manque est en partie une caractéristique des systèmes sans autorisation, et non une erreur de conception, mais il pose néanmoins des défis de coordination pour les systèmes autonomes. Ce problème provient en partie de l’architecture ouverte des systèmes dotés d’identités faiblement standardisées, et en partie du fait que les registres, les normes et les mécanismes de distribution de confiance ne sont pas encore matures. Un agent tentant d’interagir avec Aave v3 doit déterminer quels adresses sont les adresses standard, ainsi que si ces adresses sont immuables, peuvent être mises à jour via un proxy, ou sont actuellement en attente de changement de gouvernance.
Les humains résolvent ce problème à l'aide de documents, d'interfaces frontales et de réseaux sociaux. Les agents doivent déterminer en vérifiant les éléments suivants :
- Modèle d'agent et points clés de mise en œuvre
- Permissions de gestion et verrouillage temporel
- Module de mise à jour des paramètres de gouvernance
- Bytecode / interface binaire d'application correspondant entre déploiements
En l'absence d'un registre standardisé, « l'officialité » devient une question d'inférence. Cela signifie que les agents ne peuvent pas considérer les adresses de contrat comme une configuration statique. Ils doivent soit maintenir une liste blanche filtrée vérifiée en continu, soit recalculer dynamiquement l'officialité à l'exécution via un proxy en vérifiant la gouvernance et la surveillance, soit assumer le risque d'interagir avec des contrats abandonnés, compromis ou contrefaits. Dans les logiciels et infrastructures de marché traditionnels, l'identité des services est généralement ancrée dans des espaces de noms, des certificats et des contrôles d'accès gérés par des institutions. En revanche, sur chaîne, un contrat peut être appelé et fonctionner correctement, mais du point de vue de l'appelant, il n'est pas officiel sur le plan économique ou commercial.
L'authenticité des jetons et les métadonnées constituent le même problème. Les jetons semblent pouvoir se décrire eux-mêmes. Toutefois, les métadonnées des jetons ne sont pas autoritatives ; elles ne sont que des données binaires renvoyées par le code. Un exemple typique est l'Ether encapsulé (WETH). Le code du contrat WETH largement utilisé définit explicitement le nom, le symbole et la précision.
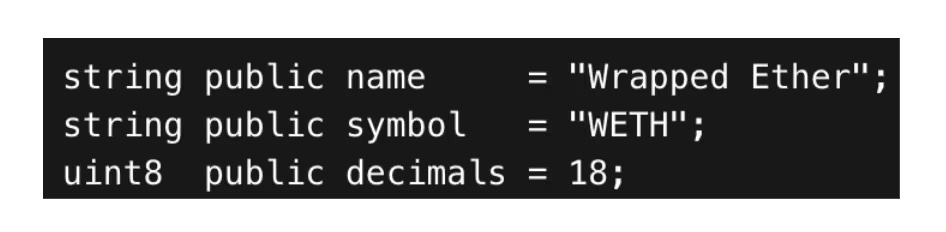
Cela semble être un identifiant, mais ce n'est pas le cas. Tout contrat peut être configuré :
- symbol() = WETH
- décimales() = 18
- name() = Wrapped Ether
Et implémentent la même interface de norme ERC-20. Les fonctions name(), symbol() et decimals() sont simplement des fonctions en lecture seule publiques qui retournent des contenus arbitraires définis par le déploiement. En réalité, sur Ethereum, il existe près de 200 jetons dont le nom est « Wrapped Ether », le symbole est « WETH » et la précision est de 18 décimales. Sans consulter CoinGecko ou Etherscan, pouvez-vous distinguer quel « WETH » est la version standard ?
Les agents font face à cette situation : la blockchain ne vérifie pas l'unicité, ne consulte aucun registre de référence et n'impose aucune restriction. Vous pouvez déployer aujourd'hui 500 contrats, tous renvoyant les mêmes métadonnées. Certaines méthodes expérimentales en ligne permettent de déterminer la légitimité (par exemple, vérifier si le solde Ethereum correspond à la quantité totale en circulation, consulter la profondeur de liquidité sur les échanges décentralisés principaux, ou confirmer s'il est accepté comme collatéral dans des protocoles de prêt), mais aucune ne fournit une preuve absolue. Chaque méthode repose soit sur des hypothèses de seuil, soit sur une vérification récursive de la normalité d'autres contrats.

Comme trouver le chemin « réel » dans un labyrinthe nécessite une orientation externe, il n'existe pas de signal natif sur la chaîne.
C’est pourquoi les listes de jetons et les registres existent en tant que couche de filtrage hors chaîne. Ils offrent un moyen de mapper le concept de « WETH » sur une adresse spécifique, ce qui explique pourquoi les portefeuilles et les interfaces frontales maintiennent des listes blanches ou dépendent de plateformes agrégées de confiance. Pour les agents, la question centrale n’est pas seulement la faible fiabilité des métadonnées, mais aussi le fait que les identités standard sont généralement établies au niveau social ou institutionnel, et non nativement par le protocole. Les identifiants fiables sur chaîne sont les adresses de contrats, mais la correspondance entre l’intention humaine, comme « échanger contre USDC », et l’adresse correcte repose toujours fortement sur des filtres, des registres, des listes blanches ou d’autres couches de confiance non natives au protocole.
Friction des données
Les agents optimisant la répartition entre les protocoles de la finance décentralisée doivent standardiser chaque opportunité en tant qu'objet économique : rendement, profondeur de liquidité, paramètres de risque, structure des frais, sources d'oracle, etc. D'un certain point de vue, il s'agit d'un problème classique d'intégration de systèmes. Toutefois, sur la blockchain, l'hétérogénéité des protocoles, l'exposition directe au capital, la concaténation d'états multi-appels et l'absence d'un modèle économique unifié sous-jacent aggravent cette charge. Or, ces éléments sont précisément les fondements nécessaires pour comparer les opportunités, simuler l'allocation et surveiller les risques.
Les blockchains ne exposent généralement pas d'objets économiques standardisés au niveau du protocole. Elles exposent des emplacements de stockage, des journaux d'événements et des sorties de fonctions, dont les objets économiques doivent être déduits ou重构és. Le protocole garantit uniquement que les appels de contrat retournent les valeurs d'état correctes, mais ne garantit pas que ces valeurs puissent être clairement mappées à des concepts économiques lisibles, ni qu'il soit possible de récupérer les mêmes concepts économiques via une interface cohérente à travers les protocoles.
Ainsi, des concepts abstraits tels que le marché, les positions et le coefficient de santé ne sont pas des primitives du protocole. Ils sont reconstruits hors chaîne par des indexeurs, des plateformes d'analyse de données, des interfaces utilisateur et des API, transformant l'état hétérogène du protocole en abstractions exploitables. Les utilisateurs humains ne voient généralement que ce niveau standardisé. Les agents peuvent également utiliser ce niveau, mais ils héritent alors des modèles, délais et hypothèses de confiance de tiers ; sinon, ils doivent reconstruire ces abstractions eux-mêmes.
Ce problème devient de plus en plus prononcé dans divers protocoles. Les prix des parts de trésorerie, les taux de marge des marchés de prêt, la profondeur de liquidité des pools d'échanges décentralisés et les taux de récompense des contrats de staking sont des composants fondamentaux ayant une signification économique, mais aucun n'offre d'interface standardisée. Chaque type de protocole dispose de ses propres méthodes d'accès, de sa propre structure et de ses propres conventions d'unités. Même au sein d'une même catégorie, les implémentations varient.
Marché de prêt : récupérer des cas typiques fragmentés
Le marché de l'emprunt illustre clairement ce problème. Ses concepts économiques sont universels et globalement uniformes, tels que la liquidité offerte et demandée, les taux d'intérêt, le taux de marge, les plafonds de crédit et les seuils de liquidation, mais les moyens d'y accéder varient considérablement.
Dans Aave v3, l'énumération des marchés et la récupération de l'état des réserves sont deux étapes distinctes. Le processus typique est le suivant :
Listez les actifs de réserve par le biais de la méthode suivante pour retourner un tableau d'adresses de jetons.

Pour chaque actif, obtenez les données de liquidité et de taux d'intérêt à l'aide d'un autre extrait de code,

Cette méthode retourne, via un seul appel, une structure contenant le total de la liquidité, l'indice des taux d'intérêt et les indicateurs de configuration, par exemple :
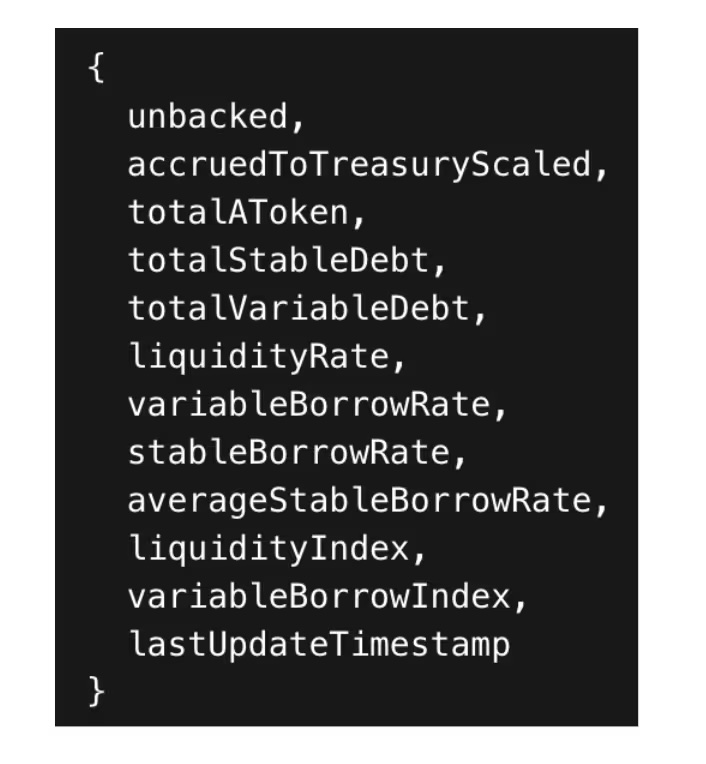
En comparaison, dans Compound v3, chaque déploiement correspond à un seul marché (USDC, USDT, ETH, etc.) et ne possède pas de structure de réserve unifiée. Au contraire, il faut assembler les instantanés de marché via plusieurs appels de fonction :
- Utilisation de base
- Total
- Taux d'intérêt
- Allocation des actifs en garantie
- Paramètres de configuration globaux
Chaque appel ne retourne qu'un sous-ensemble différent de l'état économique. Le « marché » n'est pas un objet de premier niveau, mais une structure déduite assemblée par l'appelant.
Du point de vue des agents, les deux protocoles sont des marchés de prêt-emprunt ; mais du point de vue de l’intégration, ils constituent des systèmes d’obtention structurellement différents. Aucun modèle partagé unifié n’existe. Au contraire, les agents doivent utiliser des méthodes d’énumération d’actifs distinctes pour chaque protocole et assembler l’état via plusieurs appels.
La fragmentation entraîne des retards et des risques de cohérence
Outre l'incohérence structurelle, cette fragmentation introduit des risques de latence et d'incohérence. Étant donné que l'état économique n'est pas exposé sous la forme d'un seul objet de marché atomique, les agents doivent reconstituer des instantanés en effectuant plusieurs appels de procédure distante à travers plusieurs contrats. Chaque appel supplémentaire augmente la latence, le risque de limitation et la probabilité d'incohérence entre les blocs. Dans un environnement volatil, lorsque le calcul du taux d'offre est terminé, le taux peut déjà avoir changé ; sans verrouillage explicite du bloc, les paramètres de configuration peuvent correspondre à une hauteur de bloc différente de celle du total de liquidité. Les utilisateurs comptent sur une couche de cache UI et un backend agrégé pour atténuer indirectement ces problèmes. Les agents qui interagissent directement avec les interfaces RPC brutes doivent gérer explicitement la synchronisation, le regroupement et la cohérence temporelle. Ainsi, la récupération non standardisée entraîne non seulement des difficultés d'intégration, mais limite également les performances, la synchronisation et la correction.
En l'absence d'un schéma normalisé de recherche de données économiques, même si les protocoles implémentent des primitives financières presque identiques, leur exposition d'état dépend des spécificités et de la composition des contrats. Ces différences structurelles constituent un élément fondamental de la friction des données.
Mauvaise correspondance du flux de données potentiel
L'accès à l'état économique sur la blockchain est fondamentalement un modèle de type « pull » ; même si les signaux d'exécution peuvent être diffusés en continu. Les systèmes externes interrogeent les nœuds pour obtenir l'état requis, au lieu de recevoir des mises à jour continues et structurées. Ce modèle reflète la fonctionnalité fondamentale de la blockchain : la vérification à la demande, et non le maintien d'une vue continue de l'état au niveau des applications.
Les primitives push existent. Les abonnements WebSocket permettent de diffuser en temps réel de nouveaux blocs et des journaux d'événements, mais ceux-ci ne contiennent pas l'état de stockage qui porte la majeure partie du sens économique, à moins que le protocole ne choisisse explicitement de le publier en redondance. Les agents ne peuvent pas directement s'abonner aux abonnements chain-on pour connaître l'utilisation du marché de prêt-emprunt, les réserves des pools ou le coefficient de santé des positions. Ces valeurs sont stockées dans le stockage des contrats, et la plupart des protocoles ne fournissent pas de mécanisme natif pour pousser ces informations aux utilisateurs en aval. Le modèle actuel optimal consiste à s'abonner aux en-têtes de nouveaux blocs et à interroger à nouveau chaque bloc. Les journaux ne peuvent qu'indiquer qu'un état pourrait avoir changé, mais ne codent pas l'état économique final ; la reconstruction de cet état nécessite toujours une lecture explicite et un accès à l'état historique.
Les systèmes d'agents pourraient bénéficier d'un processus inversé. Au lieu de sonder les changements d'état de centaines de contrats, les agents peuvent recevoir des mises à jour d'état structurées et pré-calculées, directement poussées vers leur environnement d'exécution. Une architecture de type push réduit les requêtes redondantes, diminue la latence entre les changements d'état et la perception des agents, et permet à la couche intermédiaire d'empaqueter l'état sous forme de mises à jour sémantiquement claires, plutôt que de laisser les agents interpréter le sens à partir du stockage brut.
Ce retournement n'est pas facile. Il nécessite une infrastructure d'abonnement, une logique de filtrage de la pertinence et un modèle pour transformer les changements de stockage en événements économiques exécutables par les agents. Mais à mesure que les agents deviennent des participants continus plutôt que des requérants intermittents, le coût de l'inefficacité du modèle de pull devient de plus en plus élevé. Considérer les agents comme des consommateurs continus, plutôt que comme des clients intermittents, pourrait mieux correspondre au fonctionnement des systèmes autonomes.
La question de savoir si l’infrastructure push est véritablement supérieure reste en suspens. Les changements d’état massifs créent des problèmes de filtrage, et les agents doivent toujours déterminer quels changements sont pertinents, réintroduisant ainsi, à un autre niveau, la sémantique pull. Le problème ne réside pas dans l’architecture pull en soi, mais dans le fait que la conception actuelle ne prend pas en compte des consommateurs d’état persistants ; à mesure que l’échelle d’utilisation des agents augmente, il pourrait être utile d’explorer d’autres modèles alternatifs.
Frottement d'exécution
La friction provient du fait que de nombreuses couches d'interaction actuelles regroupent la conversion d'intention, l'audit des transactions et la vérification des résultats dans des processus conçus autour de l'interface utilisateur, du portefeuille et de la supervision par les opérateurs. Dans les scénarios impliquant des particuliers et des décisions subjectives, cette supervision est généralement effectuée par des humains. Pour les systèmes autonomes, ces fonctions doivent être formalisées et directement codées. La blockchain garantit une exécution déterministe selon la logique du contrat, mais ne garantit pas que les transactions correspondent à l'intention de l'utilisateur, respectent les contraintes de risque ou réalisent les résultats économiques attendus. Dans les processus actuels, l'interface utilisateur et les humains comblent cette lacune.
Séquence d’opérations combinées dans l’interface utilisateur (échange, autorisation, dépôt, emprunt) : le portefeuille fournit le nœud final « Vérifier et envoyer », où l’utilisateur ou l’opérateur effectue généralement une évaluation stratégique informelle à la dernière étape. Ils évaluent souvent la sécurité de la transaction et la faisabilité du résultat de prix sans disposer d’informations complètes. En cas d’échec de la transaction ou de résultat inattendu, les utilisateurs réessayent, ajustent la glisse, modifient le chemin ou abandonnent directement l’opération. Le système d’agent élimine l’humain de ce cycle d’exécution. Cela signifie que le système doit remplacer les trois fonctions humaines par des mécanismes natifs à la machine :
- Intégration des intentions. Les objectifs humains, tels que « transférer mes stablecoins vers un lieu offrant le meilleur rendement ajusté au risque », doivent être intégrés en plans d'action concrets : sélection du protocole, du marché, du chemin de jetons, de la taille, des autorisations, ainsi que de l'ordre d'exécution. Pour les humains, ce processus est accompli implicitement via l'interface utilisateur ; pour les agents intelligents, il doit être réalisé de manière formalisée.
- Exécution de la stratégie. Cliquer sur « Envoyer la transaction » n’est pas seulement une signature, mais aussi une vérification implicite que la transaction respecte les contraintes : tolérance au slippage, limite de levier, coefficient de santé minimal, contrat autorisé dans la liste blanche, ou « contrat non améliorable interdit ». L’agent doit coder les contraintes de stratégie explicites en règles vérifiables par machine :
- Le système d'exécution doit vérifier que le graphe d'appel proposé respecte ces règles avant de le diffuser.
- Vérification des résultats. La transaction sur la chaîne ne signifie pas que la tâche est terminée. Même si la transaction s'exécute avec succès, l'objectif peut ne pas être atteint : le slippage peut dépasser la tolérance acceptable, la taille de la position cible peut ne pas être atteinte en raison de limites de quota, ou les taux d'intérêt peuvent avoir changé entre la simulation et la mise sur chaîne. Les humains vérifient de manière informelle en consultant l'interface utilisateur après coup. Les agents doivent évaluer de manière programmatique les post-conditions.
Cela introduit la nécessité d'une vérification complète, et non seulement d'une simple inclusion de transaction. Une architecture centrée sur l'intention peut partiellement résoudre ce problème en transférant une plus grande partie du fardeau de « comment » exécuter les tâches des agents vers des solveurs spécialisés. En diffusant des intentions signées plutôt que des données d'appel brutes, les agents peuvent spécifier des contraintes basées sur les résultats que les solveurs ou les mécanismes au niveau du protocole doivent satisfaire pour que l'exécution soit acceptable.
Workflow en plusieurs étapes et modes de défaillance
La plupart des opérations exécutées dans la finance décentralisée sont intrinsèquement multisteps. Un ajustement de rendement peut nécessiter d'effectuer les étapes suivantes : autorisation → échange → dépôt → emprunt → mise en gage. Certaines étapes peuvent être des transactions indépendantes, tandis que d'autres peuvent être regroupées via des contrats de multi-appel ou de routage. Les humains tolèrent les processus partiellement accomplis et retournent à l'interface utilisateur pour poursuivre la procédure. Les agents, en revanche, nécessitent une orchestration déterministe des processus : si une étape quelconque échoue, l'agent doit décider de réessayer, de re-router, de revenir en arrière ou de suspendre.
Cela a engendré de nouveaux modes de défaillance largement masqués dans les processus humains :
- Dérive d'état entre la décision et la mise sur chaîne. Entre la simulation et l'exécution, les taux d'intérêt, l'utilisation ou la liquidité peuvent changer. Les humains acceptent cette variabilité ; les agents doivent définir une plage acceptable et l'appliquer.
- Exécution non atomique et成交 partielle. Certaines opérations peuvent s'étaler sur plusieurs transactions ou produire des résultats partiels. L'agent doit suivre l'état intermédiaire et confirmer que l'état final correspond à l'objectif.
- Montant d'autorisation et risque d'approbation. Les humains signent automatiquement une autorisation via l'interface utilisateur ; les agents doivent, quant à eux, intégrer la portée de l'autorisation (montant, utilisateur, durée) comme partie intégrante de leur stratégie de sécurité, et non simplement comme une étape d'interface utilisateur.
- Choix de chemin et coûts d'exécution implicites. Les humains s'appuient sur les contrats de routage et les paramètres par défaut de l'interface utilisateur. Les agents doivent intégrer le slippage, le risque de valeur maximale extraisible, les coûts de gaz et l'impact sur les prix dans leur fonction objectif.
Exécuter : Problème de contrôle natif de la machine
L'argument central sur la friction d'exécution est que la couche d'interaction de la finance décentralisée repose sur la signature du portefeuille humain comme plan de contrôle final. Ce point intègre la vérification de l'intention actuelle, la tolérance au risque et les jugements informels de « raisonnabilité ». En supprimant l'humain, l'exécution devient un problème de contrôle : les agents doivent traduire les objectifs en modèles d'action, appliquer automatiquement des contraintes de stratégie et valider les résultats sous incertitude. Ce défi existe dans de nombreux systèmes autonomes, mais l'environnement blockchain est particulièrement exigeant : l'exécution implique directement des capitaux, des contrats inconnus composables et est exposée à des changements d'état adverses. Les humains prennent des décisions à l'aide d'heuristiques et corrigent les erreurs par essais et erreurs. Les agents doivent accomplir le même travail à la vitesse machine, souvent dans un espace d'action en constante évolution. Ainsi, l'affirmation selon laquelle « l'agent n'a qu'à soumettre une transaction » sous-estime largement la difficulté. Soumettre une transaction est la partie la plus simple.
Conclusion
La conception de la blockchain n'a pas été initialement destinée à fournir nativement les couches sémantiques et de coordination nécessaires aux agents. Son objectif est de garantir l'exécution déterministe et le consensus sur les transitions d'état dans un environnement adversarial. Les couches d'interaction construites sur cette base ont évolué autour du modèle dans lequel les utilisateurs humains interprètent les états via une interface, choisissent des actions via une interface frontale, et valident les résultats par une vérification manuelle.
Les systèmes d'agents bouleversent cette architecture. Ils éliminent les interprètes humains, les approbateurs et les validateurs du cycle, exigeant que ces fonctions soient implémentées de manière native par les machines. Cette transition révèle des frictions structurelles sur quatre dimensions : la découverte, l'évaluation de la crédibilité, l'accès aux données et les processus d'exécution. Ces frictions ne proviennent pas de l'impossibilité d'exécution, mais du fait que, dans la plupart des cas, l'infrastructure autour de la blockchain suppose toujours la présence d'une intervention humaine entre l'interprétation de l'état et la soumission de la transaction.
Pour combler ces lacunes, il faudra probablement construire une nouvelle infrastructure au sein d'une pile technologique multicouche : normaliser les états économiques跨协议 en middleware lisible par machine ; fournir des services d'indexation ou des extensions d'appels distants pour les primitives sémantiques telles que les positions, le coefficient de santé et les ensembles d'opportunités ; établir un registre offrant des cartographies de contrats standard et une vérification de l'authenticité des jetons ; ainsi qu'un cadre d'exécution codifiant les contraintes de stratégie, gérant les flux de travail en plusieurs étapes et vérifiant de manière programmatique l'accomplissement des objectifs. Certaines lacunes proviennent des caractéristiques structurelles des systèmes sans autorisation : déploiement ouvert, identité standard faible, interfaces hétérogènes. D'autres dépendent des outils, normes et conceptions d'incitations actuels ; à mesure que l'échelle d'utilisation des agents augmente et que les protocoles s'efforcent d'optimiser leur compatibilité avec les systèmes autonomes, ces lacunes devraient se réduire.
Alors que les systèmes autonomes commencent à gérer des capitaux, exécuter des stratégies et interagir directement avec les applications sur chaîne, les hypothèses architecturales de la couche d'interaction actuelle deviendront de plus en plus évidentes. La plupart des frictions décrites dans cet article reflètent l'évolution des outils blockchain et des modèles d'interaction autour des flux de travail médiés par l'humain ; certaines frictions proviennent de l'ouverture, de l'hétérogénéité et de l'environnement adversarial des systèmes sans autorisation ; d'autres encore sont des problèmes courants auxquels font face les systèmes autonomes dans des environnements complexes.
Le défi principal n'est pas de faire signer les transactions par l'agent, mais de lui fournir un moyen fiable d'accomplir les tâches d'interprétation sémantique, d'évaluation de crédit et d'exécution de stratégie, qui sont actuellement partagées entre le logiciel et le jugement humain entre l'état de la blockchain et les comportements opérationnels.