









DeepSeek V4 est enfin disponible. C’est un moment attendu depuis près de cinq mois. Le modèle principal MoE de 1T paramètres, accompagné de la version Flash de 285B paramètres, est suivi de la version Pro complète de 1,6T, entièrement open source sur GitHub sous licence Apache 2.0, avec les poids et le code de déploiement publiés simultanément.
Dès la sortie du modèle, les marchés financiers ont répondu par trois moyens indépendants mais interconnectés.
Réactions différentes du marché des capitaux
Presque toutes les actions liées à la chaîne de puissance de calcul ont connu une hausse généralisée. Cambricon a enregistré 11 jours consécutifs de hausse, avec une augmentation journalière de 3,7 % et une hausse cumulative de plus de 60 % ce mois-ci. Higon Information a atteint le plafond de 10 % en séance et a clôturé en hausse de 8,4 %. SMIC a progressé de 4,91 % sur le marché A et de 8,81 % sur le marché des actions de Hong Kong. Hua Hong a atteint un pic de +18 % en séance et a clôturé à +12 %. L'ETF国泰科创芯片 a attiré 2,4 milliards de yuans en une seule journée, atteignant un niveau historique de taille.
Du côté des entreprises de modèles de langage à Hong Kong, c’est une autre couleur. Zhipu (02513.HK) a chuté de 8,07 %, avec un ratio de vente à découvert de 9,9 %. MiniMax (00100.HK) a reculé de 7,40 %, et le ratio de vente à découvert a bondi à 22,87 %. Ce dernier représente la plus forte vente à découvert quotidienne du secteur AI à Hong Kong au cours des trois derniers mois. Ces deux entreprises sont des représentantes de la vague d’IPO AI à Hong Kong prévue au second semestre 2025, et leur prospectus d’IPO mentionne comme compétence clé la même phrase : « modèle de base auto-développé ».
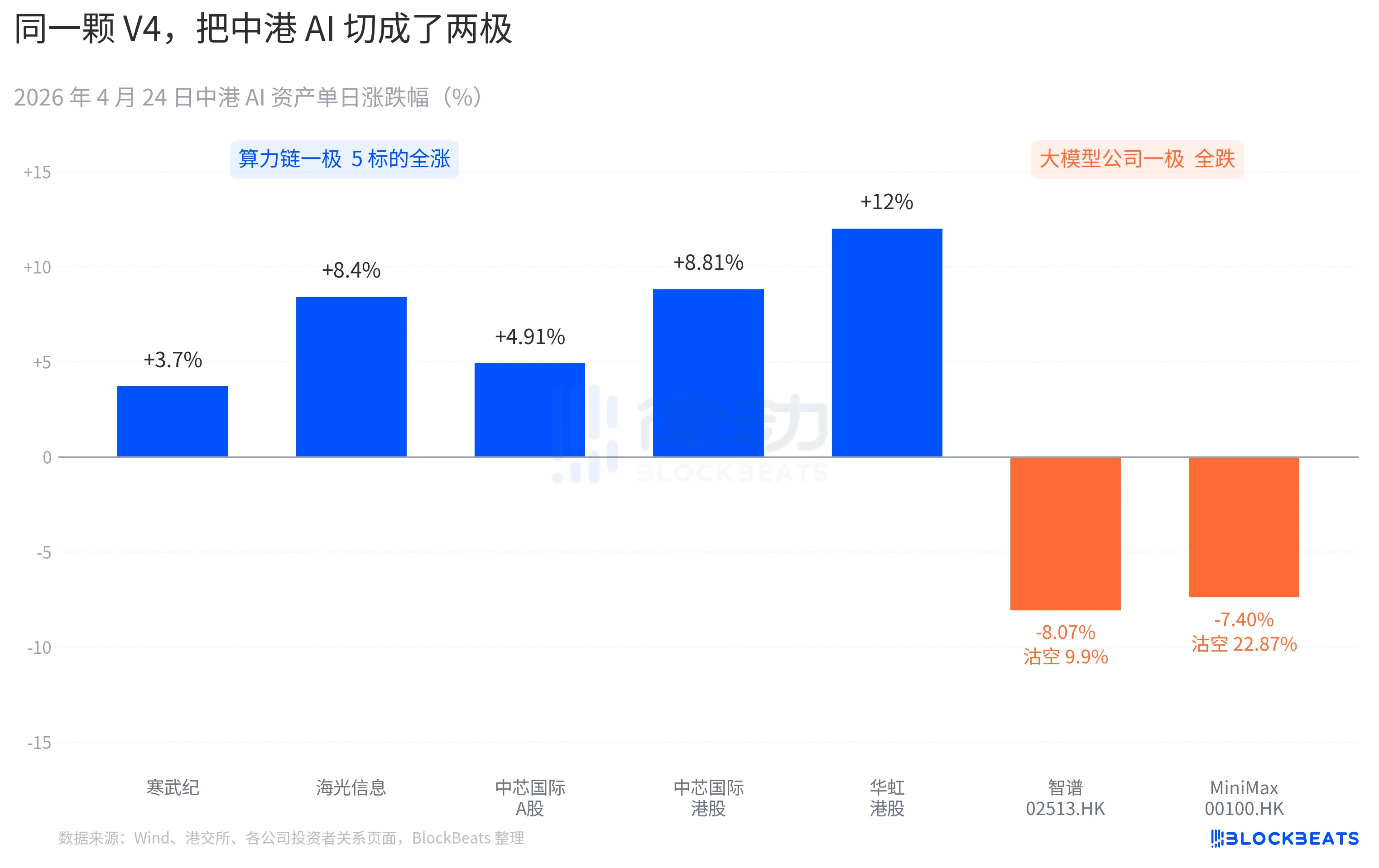
L'autre côté du Pacifique, la réaction a été tout aussi précise. NVIDIA a ouvert en baisse de 1,8 % le 24 avril, ayant touché un plus bas intrajournalier de -2,6 %, avant de clôturer à la même valeur. Bloomberg a comparé ce mouvement de consolidation à la « période DeepSeek V3 » du 27 janvier. La différence réside dans le fait que, en janvier, il s'agissait d'une vente panique ayant fait disparaître 600 milliards de dollars de capitalisation boursière en une journée. Cette fois-ci, il s'agit davantage d'une réévaluation, modérée en volume mais claire dans sa direction. Dans les comptes rendus d'études des institutions acheteuses, une nouvelle formulation est apparue : « La demande chinoise en inférence IA commence à se désynchroniser de la demande nord-américaine en inférence IA. »
Superposez ces trois tableaux, et vous obtenez le premier jugement du marché écrit dans les 24 heures suivant le déploiement de V4. Après la victoire de l’open source, l’argent commence à se réaligner : ce n’est plus le modèle lui-même qui détermine la valeur, mais sur quelle carte il est exécuté et dans quelle chaîne de valeur il est intégré.
30 jours, 11 nouveaux modèles, V4 apporte un coup de pouce à la communauté open source
La fenêtre de publication de V4 est elle-même une partie de la raison pour laquelle cette réaction a été amplifiée.
Ramenez-vous en arrière de 30 jours. Entre le 26 mars et le 24 avril, au moins 11 grands modèles d’importance significative ont été publiés ou mis à jour à l’échelle mondiale, couvrant presque tous les principaux acteurs : Anthropic Opus 4.6, Google Gemini 3.1 Pro, OpenAI GPT-5.5, Mistral Large 3, Meta Llama 4, Moonshot Kimi K2.6, Alibaba Qwen3-Next, ByteDance Doubao 2.5 Pro, Tencent Hunyuan 3.0, Kimi K2.6 Plus, et enfin DeepSeek V4, publié le 23 avril à minuit.
En moyenne, un nouveau modèle est lancé tous les 2,7 jours. C’est une vitesse à laquelle les gestionnaires de fonds n’ont même pas le temps de lire les communiqués. Mais en examinant les graphiques K des actifs IA en Chine et à Hong Kong sur ces 30 derniers jours, un seul nom a laissé une empreinte durable sur le marché : le GPT-5.5 du 8 avril, qui a poussé Nvidia à augmenter de 4,2 % en une journée avant d’atteindre son sommet. Ensuite, le DeepSeek V4 des 23 et 24 avril a propulsé la chaîne de calcul en Chine et à Hong Kong sur une série de sauts consécutifs.
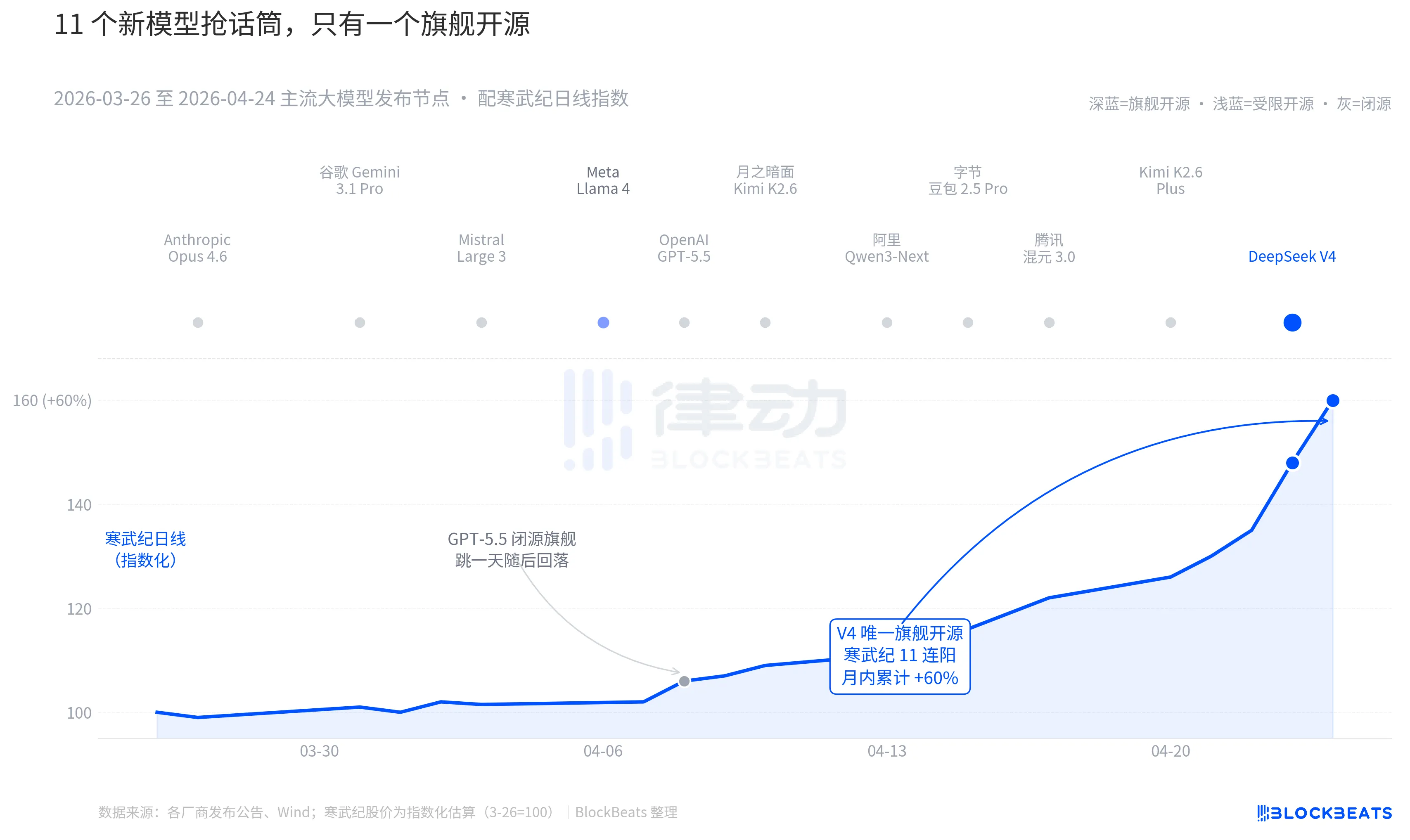
La différence ne réside pas dans les capacités des modèles eux-mêmes. L'écart entre ces 11 modèles sur le classement LMArena est, dans la plupart des cas, inférieur à 50 points, les plaçant dans une bande étroite de « même niveau ». La différence réside dans la combinaison de deux facteurs.
La première chose est l'open source. Parmi les 10 premiers modèles, seul Llama 4 est open source, mais son protocole de poids inclut une longue liste de restrictions commerciales, ce qui a suscité une réaction froide de la part de la communauté des développeurs en Europe et aux États-Unis ; il est tombé hors des dix premiers sur OpenRouter dès le troisième jour. Le protocole de V4 est Apache 2.0, sans restriction d'accès aux poids, sans limitation commerciale, et le code d'inférence est publié simultanément. Il s'agit du premier modèle open source phare des six derniers mois à exercer une pression simultanée sur les acteurs propriétaires en termes de performance, de prix et d'ouverture.
Le deuxième point est le moment. Dans un contexte où les acteurs propriétaires lancent en continu de nouvelles innovations, le récit open source est constamment mis sous pression. Opus 4.6 a porté la tâche de codage SWE-Bench à un nouveau sommet, tandis que GPT-5.5 a fixé le prix à 1,25 dollar par million de tokens comme point d'ancrage inférieur. La question de savoir si l'open source peut rattraper le propriétaire fait débat à Silicon Valley depuis deux ans. Le modèle open source phare V4, avec une estimation de 90 millions d'utilisateurs actifs en un mois, a mis cette discussion en pause.
Selon un grand gestionnaire de fonds national lors d'une présentation, « Avant V4, nous appliquions une remise à la valorisation des grands modèles open source ; après V4, cette remise s'est transformée en prime. »
DeepSeek a changé la table de tarification de la chaîne d'approvisionnement en puissance de calcul
Dans le communiqué de version V4, une phrase n'avait jamais été incluse dans aucun document officiel d'un grand modèle chinois : « Jour 0 : adaptation complète à la Cambricon MLU590 et à l'Ascend 950PR de Huawei, code de déploiement publié en open source. » La portée de cette phrase ne peut être comprise qu'en reliant les trois lignes parallèles qui se sont déroulées au cours des 12 derniers mois : celles concernant le matériel, le logiciel et la réaction de la Silicon Valley.
La première piste se trouve du côté des puces. Le processeur Ascend 950PR de Huawei a été mis en production de masse en décembre 2025, avec une puissance FP4 de 1,56 PFLOPS et une capacité HBM de 112 Go, marquant la première fois qu'une puce IA chinoise égale les spécifications techniques de la série B de NVIDIA. Dans des tâches d'inférence MoE avec 1T de paramètres comme V4, le débit par carte est supérieur de 2,87 fois à celui du H20. La pile logicielle CANN 8.0 optimise les frameworks d'inférence LLM au niveau des opérateurs ; les benchmarks publiés par DeepSeek montrent que la latence d'inférence bout en bout de V4 sur un super-nœud Ascend (8 cartes 950PR) est inférieure de 35 % à celle d'un cluster H100 de taille équivalente. Les données du Cambricon Silan 590 sont encore plus ambitieuses : sa puissance FP8 par puce est comparable à celle du H100, avec un prix inférieur à la moitié.
La deuxième ligne cachée se trouve du côté logiciel. Le 22 avril, vLLM a fusionné la PR pour le backend MLU de Cambricon, marquant la première fois qu’un framework d’inférence open source prend en charge nativement des GPU chinois non NVIDIA. Les DCU de Hygon passent par l’écosystème ROCm sur un autre chemin, mais parviennent à exécuter complètement la couche de routage MoE de V4. Cela signifie que le déploiement de V4 n’est plus « limité à une seule carte chinoise spécifique », mais devient « adaptable entre plusieurs cartes chinoises ». La dépendance de l’écosystème à un fournisseur unique est rompue : c’est un point de bascule crucial pour la production.
Troisième fil rouge provenant de la Silicon Valley. Le 15 avril, Huang Renxun a été pressé par des analystes lors de la conférence de台积电 sur les progrès de la puissance de calcul nationale chinoise ; ses propos, froids et précis, étaient les suivants : « Si ils parviennent vraiment à faire évoluer les LLM en dehors de CUDA, ce serait une catastrophe pour nous ». Neuf jours plus tard, DeepSeek a apporté une réponse avec une annonce Day 0 d'une seule ligne.
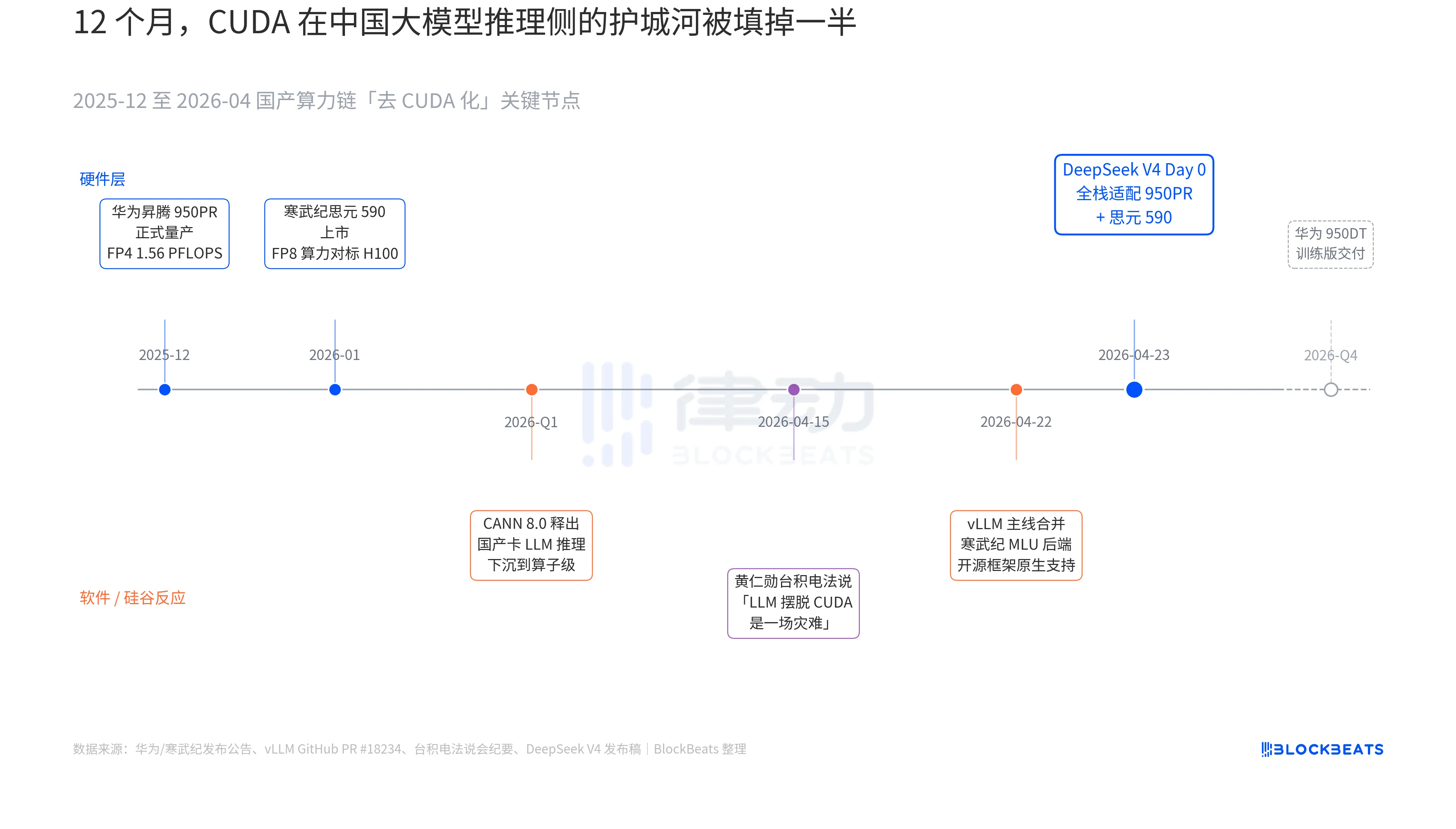
Ces quatre mots « substitution nationale » ont été surutilisés au cours des trois dernières années au point de perdre tout sens. Mais après le 24 avril, pour la première fois, des données concrètes pouvant être valorisées par les marchés financiers sont apparues. Le débit par carte, la latence d’inférence bout en bout, le coût d’inférence et le code de déploiement commercialisable ont silencieusement poussé cette longue bataille rhétorique au seuil de la production.
La logique derrière les 11 hausse consécutives du cours de Cambricon réside ici. Elle n'est plus simplement une « action liée au concept de GPU national », mais un « fournisseur d'infrastructure pour l'inférence DeepSeek V4 ». La même logique explique la hausse de 12 % des actions de Hua Hong en Hong Kong, car elle produit le procédé équivalent 7 nm du 950PR. Chaque token V4 exécuté sur les昇腾 nationaux signifie une partie de la capacité qui aurait autrement été dirigée vers NVIDIA et TSMC, maintenant retenue dans la région du delta de la rivière des Perles.
La prochaine étape est déjà planifiée. Selon la feuille de route d’Huawei, la version d’entraînement 950DT est prévue pour être livrée au quatrième trimestre 2026, avec pour objectif « l’entraînement complet sur une grappe de 10 000 cartes pour des modèles V5 ou de niveau équivalent ». Si ce chemin est emprunté avec succès, le fossé protecteur de CUDA dans l’entraînement de grands modèles en Chine passera de « nécessaire » à « optionnel ».
Source :律动 BlockBeats