









Ce réajustement de DeepSeek a forcé l'industrie à entrer dans un tout nouvel ère de coûts, avec une chute abrupte et non linéaire.
Auteur et source de l'article : 0x9999in1, ME News
TL;DR
- Prix en dessous du plancher : À la fin d'avril 2026, DeepSeek a réduit le prix de sortie de son modèle V4-Pro à 0,878 $/million de tokens en combinant une réduction temporaire et une baisse des coûts de mise en cache, tandis que les entrées avec hit de cache sont tombées à 0,0037 $ (environ 0,025 yuans chinois), brisant complètement le point de référence tarifaire de l'industrie des grands modèles.
- Un écart de prix entre la Chine et les États-Unis : par rapport aux principaux fabricants mondiaux, le coût total d'appel à l'API de DeepSeek-V4-Pro est environ trentième de celui d'OpenAI GPT-5.5 et d'Anthropic Claude Opus 4.7, créant un écart de coût extrêmement marqué.
- Pression sur le paysage concurrentiel national : sous la stratégie de tarification agressive de DeepSeek, les modèles principaux nationaux tels que Zhipu GLM 5.1 et Moonshot Kimi K2.6 font face à une forte pression commerciale et pourraient être contraints de suivre en réduisant leurs prix, accélérant considérablement le processus d'élimination du secteur.
- « Coup de cache réussi » devient l'économie centrale : DeepSeek réduit le prix du coup de cache réussi à un dixième du prix d'origine, une stratégie qui bénéficie considérablement, à un niveau fondamental, aux scénarios de traitement de textes longs, de RAG (retrieval-augmented generation) et d'interactions multiround continues des agents.
- Les conclusions de l'analyse du think tank : les grands modèles de base accélèrent leur transition vers une infrastructure comparable à l'électricité et à l'eau ; le futur champ de concurrence passera entièrement de la compétition sur la taille des paramètres des modèles à la capacité d'optimisation des coûts d'inférence et à la part de marché des écosystèmes de développeurs.
Introduction : Le moment "singulier" du coût de calcul des grands modèles
Le développement technologique s'accompagne souvent d'une baisse exponentielle des coûts, un parcours incontournable pour toute technologie disruptive afin d'atteindre une adoption généralisée. Du 25 au 26 avril 2026, l'industrie de l'IA a connu un moment hautement symbolique : le principal fabricant de grands modèles, DeepSeek, a lancé deux « bombes sous-marines » successives. D'abord, il a annoncé une réduction exceptionnelle de 75 % pendant une période limitée pour l'API du modèle DeepSeek-V4-Pro ; peu après, il a déclaré que le prix pour les requêtes avec mise en cache d'entrée serait réduit directement à un dixième du prix initial pour toute la gamme d'API.
Après ces deux cycles de stratégie de réajustement des prix, le prix d'entrée pour les hits de cache par million de tokens de DeepSeek-V4-Flash est tombé à un étonnant 0,0029 $ (environ 0,02 ¥) avant le 5 mai 2026, tandis que le prix d'entrée pour les hits de cache de DeepSeek-V4-Pro, en comparaison avec les niveaux mondiaux les plus élevés, n'est que de 0,0037 $ (environ 0,025 ¥).
Avant cela, l'industrie prévoyait généralement que le coût d'inférence des grands modèles diminuerait d'environ 50 % par an, mais le recentrage de prix de DeepSeek a provoqué une chute brutale et non linéaire, forçant l'industrie à entrer dans une nouvelle ère de coûts. Nous estimons que cela ne constitue pas une simple campagne marketing ou une « guerre des prix » à court terme, mais plutôt le résultat inévitable d'optimisations sous-jacentes de l'architecture algorithmique (telles que les mécanismes d'attention clairsemée et l'évolution extrême de l'architecture MoE), ainsi que d'une amélioration des capacités d'ingénierie des clusters de calcul. Ce rapport, basé sur les dernières données de prix de l'ensemble de l'industrie, analysera en profondeur les répercussions de la baisse de prix de DeepSeek et comparera horizontalement la compétitivité commerciale des principaux grands modèles mondiaux, dans le but de fournir aux décideurs une cartographie claire de l'évolution industrielle.
Phénomène central : Percée limite du système de prix de la série DeepSeek-V4
Pour comprendre l'ampleur de cette réduction, nous devons analyser en profondeur les trois dimensions fondamentales de la facturation des API de grands modèles : le prix d'entrée (non mis en cache), le prix d'entrée (mis en cache) et le prix de sortie. Les modèles de facturation antérieurs ne distinguaient généralement que l'entrée et la sortie, mais avec la maturité des technologies de contexte long (Long-Context), le « taux de hit du cache (Cache Hit) » devient une variable clé pour redéfinir l'économie des API.
Analyse de la stratégie de tarification : cumul des remises et levier en cache
Selon les données les plus récentes, DeepSeek a adopté une stratégie en trois volets : réduction de base + réduction limitée dans le temps + levier de mise en cache.
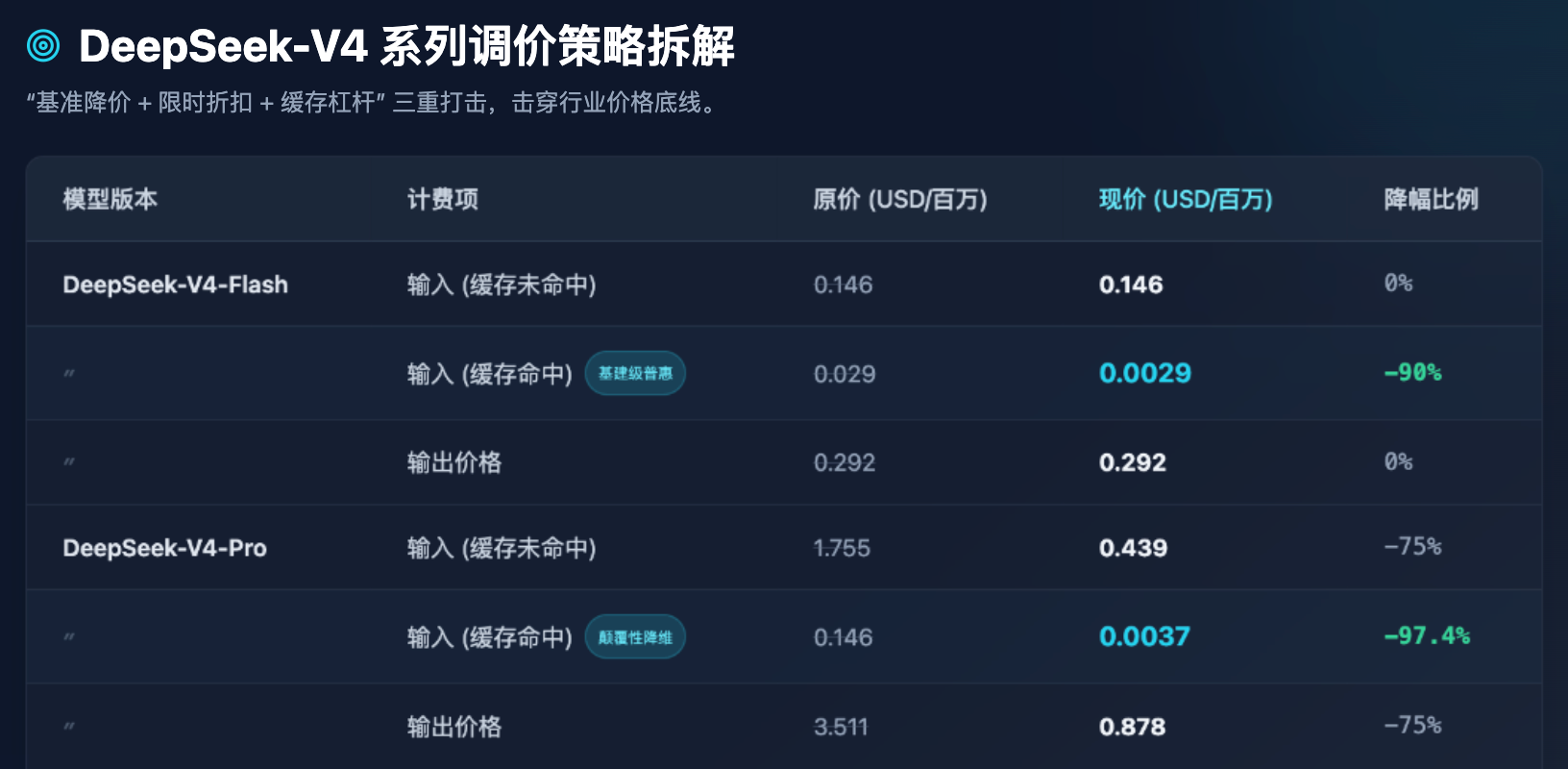
Tableau 1 : Comparaison des prix avant et après la révision des tarifs de l'API DeepSeek-V4 (en dollars par million de tokens)
À partir du Tableau 1, nous pouvons tirer plusieurs observations industrielles extrêmement claires :
Premièrement, la démocratisation du modèle Flash est arrivée à son terme. Pour les modèles Flash axés sur la haute concurrence et la faible latence, le prix de sortie est maintenu à 0,292 dollars par million de tokens, ce qui correspond déjà à la limite inférieure absolue des coûts matériels des serveurs. DeepSeek n'a pas poursuivi la réduction du prix de base du modèle Flash, mais a habilement réduit de 90 % le prix de « hit dans le cache ». Cela signifie que, lors du traitement de grandes quantités de prompts système répétitifs ou de questions-réponses sur des documents fixes, le coût du modèle Flash devient presque négligeable.
Deuxièmement, la réduction de dimension du modèle Pro. En tant que modèle phare conçu pour rivaliser avec les premières équipes mondiales (comme GPT-5), le prix de sortie du V4-Pro est passé de 3,511 dollars à 0,878 dollars. Encore plus impressionnant : le prix d'entrée pour les hits de cache, qui était initialement de 0,146 dollar, est tombé directement à 0,0037 dollar après l'application combinée d'une réduction temporaire de 75 % et d'une réduction supplémentaire de 90 %. C'est un chiffre extrêmement impressionnant — cela signifie que le coût d'appel à l'intelligence de pointe mondiale a été réduit à un niveau tel que même les petites et moyennes entreprises, ainsi que les développeurs individuels, peuvent l'appeler à haute fréquence sans aucune hésitation.
Troisièmement, cela pousse les développeurs à optimiser l'ingénierie des prompts. En fixant le prix lors d'un hit de cache à un vingtième, trentième ou moins du prix en cas de manque de cache (par exemple, dans le modèle Pro : 0,0037 $ contre 0,439 $, soit un écart d'environ 118 fois), il ne s'agit pas seulement d'une stratégie de tarification, mais aussi d'une approche commerciale visant à orienter l'écosystème technologique. DeepSeek indique clairement aux développeurs : si votre architecture est bien conçue (par exemple, en plaçant le contexte long fixe en premier et la question courte variable en dernier), vous pourrez bénéficier d'une puissance d'entrée presque gratuite.
Comparaison horizontale : l'écart marqué entre les prix des grands modèles mondiaux et locaux
Il ne suffit pas de comparer uniquement verticalement la réduction de prix de DeepSeek pour saisir la pleine image ; lorsque nous plaçons cette stratégie de tarification dans le cadre du marché mondial des grands modèles en 2026, le contraste « fracturé » qu'elle crée devient véritablement glaçant.
Sur la base d'OpenRouter et des informations publiques de chaque entreprise, nous avons regroupé les dernières tarifications API des 9 modèles les plus représentatifs sur le marché, nationaux et internationaux.

Tableau 2 : Comparaison des prix des API des grands modèles mondiaux en 2026 (en dollars américains par million de tokens)
Lutter contre les géants mondiaux : briser le mythe du « haut IQ, haute prime »
Au cours des deux dernières années dans le récit de l'IA, OpenAI et Anthropic ont maintenu une entente tacite : les modèles les plus intelligents méritent les marges brutes les plus élevées. Actuellement, les prix de sortie de GPT-5.5 et Claude Opus 4.7 s'élèvent respectivement à 30 $ et 25 $/million de tokens. Ces deux géants de la Silicon Valley tentent de maintenir leur taxe sur la puissance de calcul en monopolisant les capacités d'inférence les plus avancées.
Cependant, l'apparition de DeepSeek-V4-Pro et son prix de sortie de 0,878 $ a directement percé cette fine couche de papier. Supposons que V4-Pro atteigne ou s'approche du niveau de GPT-5.5 dans les principaux tests de référence (Benchmarks) et en expérience réelle, alors cette différence de prix de sortie de 34 fois entre les deux détruira complètement la logique de prime des géants étrangers sur le marché B2B.
Selon les estimations de « ME News Intelligence », pour une entreprise exportatrice fortement dépendante du contenu généré par l'IA, si elle consomme 1 milliard de tokens en sortie par mois, le coût fixe avec GPT-5.5 s'élève à 30 000 dollars américains ; en passant à DeepSeek-V4-Pro, ce coût chute brutalement à 878 dollars. Cette différence de coût à cette échelle peut suffire à déterminer la survie ou l'échec d'une startup. Cela montre que les entreprises chinoises d'IA ont adopté une approche totalement différente de celle de la Silicon Valley, alliant « esthétique de la force » et ingénierie extrême en matière d'efficacité de l'entraînement des modèles de base et d'optimisation des clusters d'inférence.
Éliminer les concurrents nationaux : accélérer le grand nettoyage du secteur
Si DeepSeek représente une attaque à un niveau inférieur pour les géants étrangers, il s'agit pour les concurrents nationaux d'un jeu à somme nulle cruel.
Comme le montre le Tableau 2, les principaux fabricants nationaux, tels que Zhipu (GLM 5.1, sortie à 4,4 $) et Moonshot (Kimi K2.6, sortie à 4 $), se trouvent dans une situation embarrassante en termes de tarification. Ces prix étaient encore considérés comme « raisonnables et performants » il y a quelques mois, mais face à DeepSeek-V4-Pro (sortie à 0,878 $), ils perdent immédiatement toute leur défense tarifaire. Même Alibaba Cloud, connu pour son open source et ses prix bas (Qwen3.6 Plus, sortie à 1,96 $), ne semble plus « bon marché ».
Sur le champ de bataille des modèles légers Flash, la lutte est tout aussi acharnée. Step 3.5 Flash de Jiepao Xingchen affiche un coût d'entrée aussi bas que 0,028 $ et une sortie à seulement 0,299 $, en concurrence étroite avec DeepSeek-V4-Flash (0,292 $ en sortie). Cela montre que dans le domaine des modèles légers, la pression sur les coûts de calcul a atteint un niveau nanométrique, et chaque acteur vole au ras du seuil de coût.
Dans l'ensemble, DeepSeek utilise des capacités de niveau Pro pour concurrencer les prix des versions Plus ou standard des concurrents nationaux, tout en adoptant une tarification de niveau Flash pour capter l'ensemble du trafic de longue traîne, à faible densité de valeur. Cette stratégie de « pincement des deux extrémités » comprime considérablement l'espace de survie des autres entreprises de grands modèles d'IA, et le concours d'élimination des grands modèles d'IA nationaux sera accéléré après cette réduction de prix.
Analyse approfondie : les technologies et la logique commerciale derrière des prix extrêmement bas
Les prix bas sans fondement fondamental ne sont pas durables. DeepSeek ose adopter une stratégie de réduction de prix aussi radicale pour 2026 grâce à un soutien technique solide et à des ambitions commerciales très ambitieuses.
Logique technique : du « force brute » à la « victoire par l'architecture »
La chute brutale des prix est essentiellement la libération des bénéfices issus de l'évolution de l'architecture technique.
- Les avantages profonds de l'architecture MoE (Mixture of Experts) : Contrairement aux grands modèles denses précoces d'OpenAI, les modèles avancés actuels adoptent généralement une architecture MoE hautement optimisée. DeepSeek réduit très probablement encore davantage le ratio de paramètres activés dans l'architecture V4. Cela signifie que, même avec un nombre total de paramètres élevé, seules de très rares « expertises » sont activées lors de chaque inférence, réduisant considérablement la charge de calcul (FLOPs) et la pression sur la bande passante de la mémoire vidéo pour chaque appel.
- Révolution dans la gestion du KV Cache : le point fort de ce ajustement est la réduction du taux de命中 du cache d'entrée à 1/10. Dans l'architecture Transformer, le principal goulot d'étranglement pour l'inférence de textes longs n'est pas le calcul, mais la mémoire vidéo occupée par le KV Cache stockant les informations de contexte. DeepSeek a visiblement mis en œuvre au niveau système une technologie de mise en pool du KV Cache partagé globalement entre requêtes (par exemple, une version améliorée de la technologie RadixAttention). Lorsque de nombreuses requêtes simultanées contiennent les mêmes paramètres système ou base de connaissances contextuelles, le modèle n'a plus besoin de recalculer ces tokens, mais peut les lire directement depuis la mémoire ou même un pool de mémoire vidéo distribuée. Cela fait en sorte que le coût marginal des entrées longues tend vers zéro.
Logique commerciale : échanger les profits contre de l'espace pour redéfinir le fossé écologique
« ME News智库 » estime que la stratégie de réduction temporaire et de prix plancher de DeepSeek a un objectif commercial clair et déterminé :
Premièrement, détruisez complètement l'écosystème des « fine-tunings de conteneurs », forçant l'émergence d'applications natives à l'IA. Lorsque le coût d'appel des modèles de base les plus puissants tend vers zéro, il n'aura plus aucun sens économique pour les entrepreneurs de dépenser des sommes colossales pour entraîner ou affiner leurs propres petits modèles sectoriels. DeepSeek, grâce à ses prix bas, tente d'attirer tous les développeurs d'IA de la société dans son écosystème API, afin d'en faire les « infrastructures de base de l'ère de l'IA », comme Amazon AWS ou Microsoft Azure.
Ensuite, l'aube de l'explosion des agents de positionnement. Les applications agentic véritablement efficaces nécessitent que le modèle effectue une grande quantité de réflexion interne, de rétroaction, de planification et d'appels en boucle multiple. Pendant ce processus, une énorme quantité de tokens implicites est consommée. Les API coûteuses constituent le principal obstacle à la généralisation des agents. DeepSeek, en réduisant le prix de命中 du cache à 0,0037 $, rend en réalité économiquement faisable l'idée de « faire tourner l'IA dix mille fois ». Celui qui offre le coût d'essai-erreur le plus bas sera celui qui favorisera l'émergence de la plus grande application native à l'IA.
Impact et tendances du secteur : du « combat des modèles » au « combat des écosystèmes »
Pour illustrer plus clairement l'impact de ces variations de prix sur les décisions d'entreprise, nous avons réalisé une simulation de coûts pour une application d'entreprise.
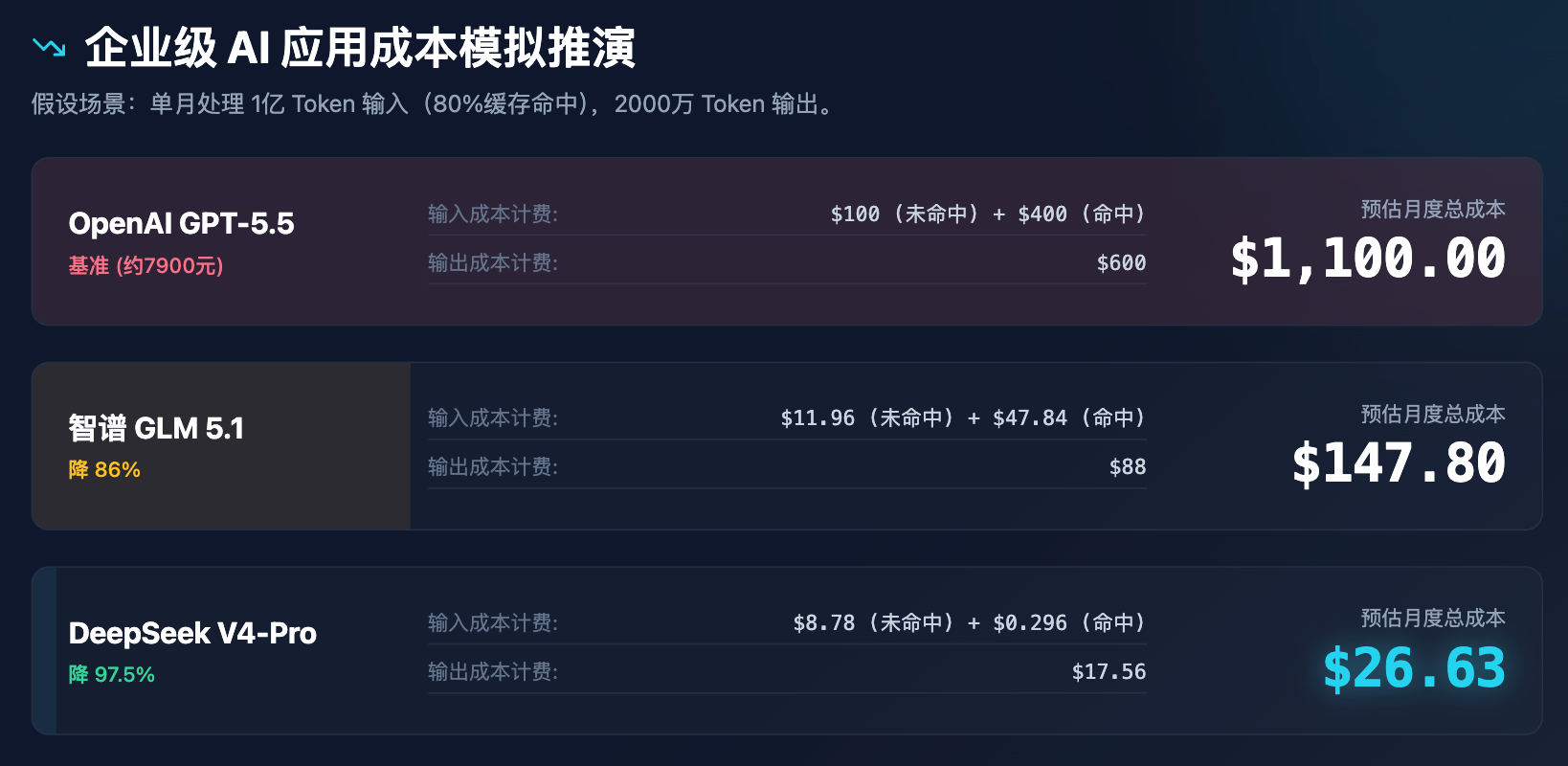
Tableau 3 : Analyse de simulation des coûts des applications AI d'entreprise (hypothèse : 100 millions de tokens d'entrée et 20 millions de tokens de sortie par mois)
À travers la simulation ci-dessus, il est clair que le prix de DeepSeek ne se contente pas de proposer une réduction, mais réstructure entièrement le modèle de coûts. Un coût mensuel inférieur à 30 dollars peut répondre à tous les besoins d'assistance client, de traitement de documents et de vérification de code pour une entreprise de taille moyenne, ce qui déclenchera inévitablement une série de réactions en chaîne :
- Changement fondamental dans la logique d'investissement IA : le capital perdra complètement tout intérêt pour la « création d'un nouveau modèle de grande taille généraliste ». À l'exception de quelques rares entités nationales ou géants d'Internet, la porte des modèles fondamentaux généralistes est désormais soudée. Les investissements futurs s'orienteront intégralement vers la couche application (Application Layer) et les middleware d'infrastructure (routeurs d'infrastructure, passerelles IA, etc.).
- La stratégie de routage multi-modèles (LLM Routing) devient une norme : les entreprises n’opteront plus pour un seul modèle. Le système répartira automatiquement les tâches en fonction de leur complexité. Par exemple, 90 % du nettoyage de données quotidien et de la classification simple seront traités par DeepSeek-V4-Flash ou Step 3.5 Flash à un coût extrêmement faible ; les 10 % restants impliquant un raisonnement logique complexe ou la génération de rapports pour la direction seront gérés par DeepSeek-V4-Pro ou par GPT-5.5 selon les besoins.
- Les applications de longs textes atteignent un véritable tournant commercial : auparavant, « télécharger des rapports financiers de plusieurs centaines de milliers de mots pour obtenir un résumé par IA » semblait idéal, mais le coût de l'API, souvent de plusieurs dollars par utilisation, dissuadait les entreprises B2B. Avec la baisse du prix de命中 du cache d'entrée à 0,02 yuan chinois pour un million de tokens, « lire l'ensemble des documents et interagir en temps réel » deviendra une fonction standard dans tous les logiciels OA et ERP des entreprises.
Conclusion et recommandations stratégiques
La vague de réductions de prix en avril 2026 marque la fin officielle de la période romantique classique du secteur des grands modèles, caractérisée par la compétition sur les paramètres et les scores, pour entrer dans une ère industrielle impitoyable axée sur la maîtrise des coûts, la conquête de la puissance de calcul et la domination des écosystèmes. En adoptant une stratégie de tarification extrêmement agressive, DeepSeek a non seulement démontré au niveau mondial la profonde expertise des entreprises chinoises d'IA en ingénierie de modèles, mais a également activement percé la bulle de survalorisation de la puissance de calcul IA.
À ce sujet, « ME News智库 » propose trois recommandations :
- Pour les développeurs d'applications : abandonnez la peur des coûts d'appel aux grands modèles. Arrêtez immédiatement la création et le fine-tuning de modèles de base de moins de 10 milliards de paramètres, et réorientez toutes vos ressources de développement vers l'amélioration de l'expérience produit, l'adaptation côté terminal, la construction de barrières de données propriétaires et l'affinage des flux de travail Agent. Profitez de cette vague de « puissance de calcul intelligente abordable » pour saisir rapidement les scénarios.
- Pour les CIO/CTO d'entreprises traditionnelles : réévaluez la stratégie d'IA de votre entreprise. Les projets précédemment mis en attente pour des raisons de coûts, tels que les systèmes de问答 de bases de connaissances, les services clients automatisés et les Copilotes de code, présentent désormais un ROI (retour sur investissement) très élevé grâce aux prix actuels des API. Il est recommandé d'adopter une plateforme LLMOps mature et de mettre en place une passerelle IA d'entreprise pour permettre une intégration flexible des modèles les plus rentables actuellement disponibles.
- Pour les concurrents de modèles de base : il faut abandonner la stratégie de suivi. Face à la guerre des prix, il faut soit réduire encore davantage les coûts grâce à une optimisation extrême de la synergie entre puces et frameworks, soit établir des barrières technologiques insurmontables dans des domaines différenciants tels que l’intelligence incarnée, les modèles natifs multimodaux (génération vidéo/3D) ou le raisonnement logique spécialisé par secteur. La banalisation des grands modèles linguistiques purs ne laisse plus aucune issue.
Les grands modèles ne sont plus des divinités enfermées dans des laboratoires ; ils descendent à une vitesse sans précédent de leur piédestal pour devenir un flot puissant qui alimente l'intelligence de tout. Et tout cela vient tout juste de commencer.
Source :
- OpenRouter. (2026). Base de données de comparaison des tarifs API.
- Annonce officielle de DeepSeek. (2026, 25 avril). Plan d'offre limitée pour l'API DeepSeek-V4-Pro.
- Official Announcement from DeepSeek. (2026, April 26).Democratizing Compute Power in the Era of Large Models: Adjustment Plan for API Global Cache Hit Pricing.