









Auteur : XinGPT
Votre assistant de programmation IA, basé sur un modèle chinois que vous n'avez probablement jamais entendu mentionner
De DistillAI, un nouveau média financier à l'ère de l'IA.
Remarque : Nous essayons de créer du contenu entièrement par IA, donc cet article, de son sujet à son rédaction, a été généré par Claude AI.
Vous ouvrez Cursor chaque jour pour écrire du code,重构 des fonctions et demander à l’IA de vous aider à déboguer. Vous pensez utiliser les technologies les plus avancées de la Silicon Valley, car il s’agit d’une entreprise star évaluée à 29,3 milliards de dollars, avec des investisseurs comme Thrive Capital et a16z, et des utilisateurs répartis dans toute la communauté des développeurs mondiaux.

Jusqu'à la semaine dernière, quelqu'un a vu un ID de modèle dans la réponse de l'API de Composer 2 : kimi-k2p5-rl-0317-s515-fast.
Kimi K2.5 — un modèle open source de l'entreprise chinoise Moonshot AI.
Le « cerveau » de votre agent de codage n'est pas celui que vous pensez.
Composer 2 : Une sortie soigneusement préparée
Le 20 mars, Cursor a lancé le nouveau modèle de code Composer 2, utilisant un vocabulaire très fort sur son blog officiel : « frontier-level coding intelligence » — une intelligence de programmation de pointe.
Aucun nom de modèle de base n'est mentionné dans l'annonce. Pas de Kimi, pas de Moonshot, pas de « Chine », pas de « open source ». Tout semble ressembler à un résultat développé en interne par Cursor.
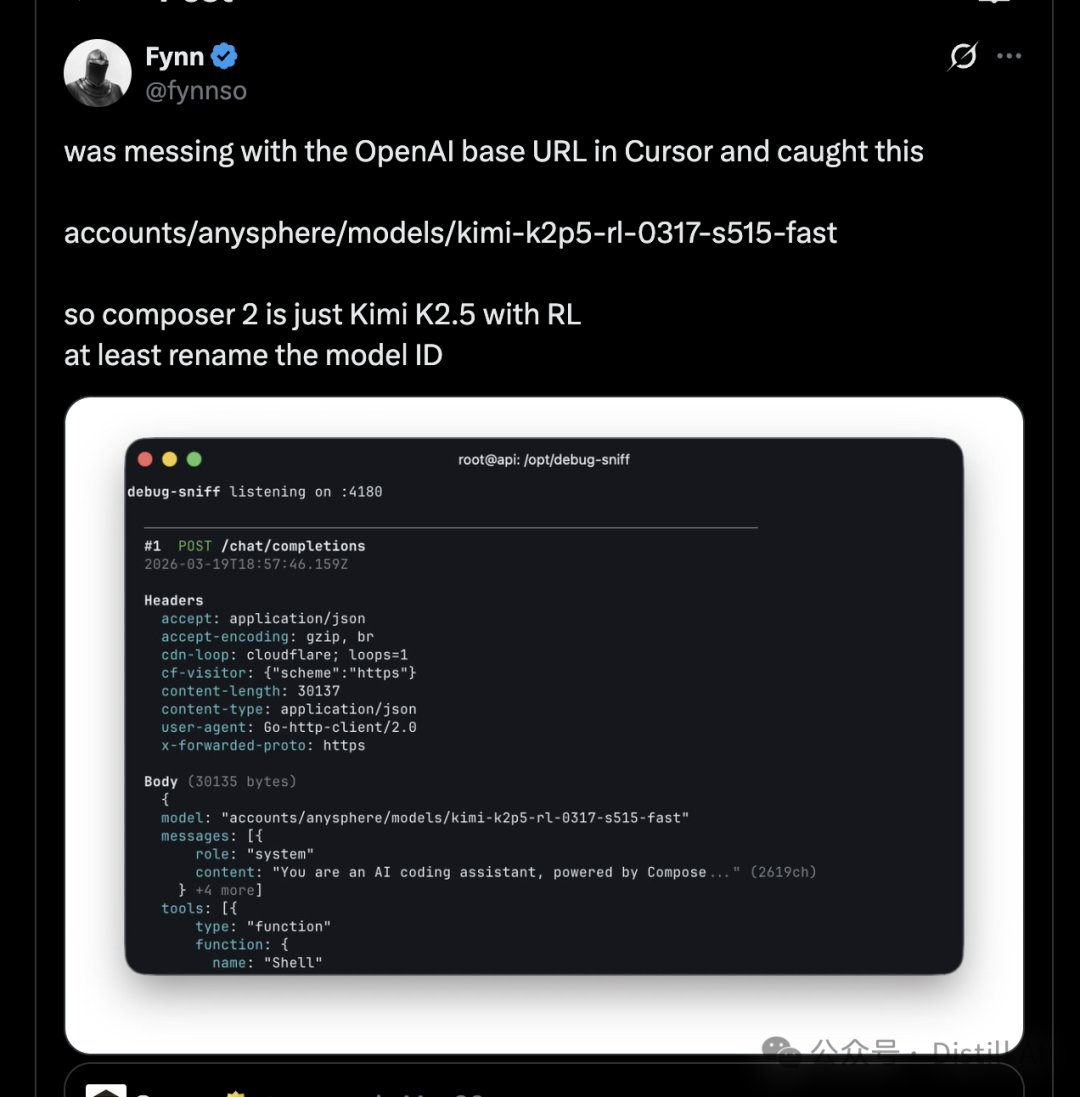
Mais la communauté technique a un nez fin. Le jour de la publication, des développeurs ont remarqué, en appelant l'API de Composer 2, le chemin du modèle retourné : accounts/anysphere/models/kimi-k2p5-rl-0317-s515-fast. Cette chaîne de caractères est presque une présentation d'elle-même — Kimi K2.5, accompagnée d'un fine-tuning RL (apprentissage par renforcement).
Le message s'est répandu rapidement sur les réseaux sociaux. Deux jours plus tard, Lee Robinson, vice-président de l'éducation au développement de Cursor, a répondu publiquement, reconnaissant que Composer 2 est effectivement basé sur Kimi K2.5, mais soulignant que « seuls environ un quart de la puissance de calcul finale proviennent du modèle Kimi, le reste provenant de l'entraînement propre à Cursor ». Il a qualifié l'omission de Kimi dans le blog d'« erreur ».
Si c'était la première « erreur » de Cursor, on pourrait encore la considérer comme une négligence. Mais ce n'est pas le cas.
Lors de la sortie de Composer 1 l'année dernière, certains ont également constaté qu'il utilisait le tokenizer de DeepSeek, sans aucune divulgation sur aucun canal officiel. Une fois, c'est une négligence ; deux fois, il est difficile de ne pas se demander : est-ce une omission, ou une volonté de ne pas le dire ?
Le choix rationnel, la logique silencieuse
Avant de critiquer Cursor, je pense qu'il est nécessaire de comprendre un fait : utiliser Kimi K2.5 comme base est une décision très rationnelle, tant sur le plan technique que commercial.
Kimi K2.5 est un modèle open source publié par Moonshot en janvier de cette année, utilisant une architecture MoE (Mélange d'Experts) et offrant d'excellentes performances dans les tâches de génération de code. Plus important encore, il est open source — ce qui signifie un coût d'accès extrêmement faible. Pour une entreprise comme Cursor, qui doit itérer rapidement et se concentrer sur la couche produit et l'intégration de la chaîne d'outils, utiliser un modèle open source de haute qualité existant comme base, puis le fine-tuner avec ses propres données et l'apprentissage par renforcement, constitue le chemin le plus efficace.
Ce n'est en réalité rien de nouveau.
Le marché des produits IA d'aujourd'hui repose beaucoup plus fréquemment que la plupart des gens ne le pensent sur des modèles open source chinois. DeepSeek, Qwen, Kimi — ces modèles open source développés par des équipes chinoises deviennent la fondation invisible de la pile technologique IA mondiale. Simplement, personne n'aime en parler ouvertement.
La raison n'est pas compliquée. Dans le cadre narratif de la concurrence technologique entre la Chine et les États-Unis, la phrase « notre produit IA repose sur un modèle chinois » n'est pas seulement une révélation technique pour une entreprise américaine, mais aussi une ouverture à un risque de communication. Comment les investisseurs le verront-ils ? Les clients entreprises craindront-ils pour la sécurité des données ? Comment les médias rédigeront-ils leurs titres ?
Le silence est devenu une entente tacite de l'industrie. Tout le monde l'utilise, mais personne n'en parle.
Mais le silence a un coût.
Autorisation réglementaire : la petite ligne ignorée
Le protocole open source de Kimi K2.5 est une licence MIT modifiée ; la plupart des clauses sont très souples, mais une contrainte essentielle existe : si le nombre d'utilisateurs actifs mensuels d'un produit commercial dépasse 100 millions, ou si le chiffre d'affaires mensuel dépasse 20 millions de dollars américains, il faut afficher clairement « Kimi K2.5 » dans l'interface utilisateur.
Les revenus annuels de Cursor s'élèvent à environ 2 milliards de dollars américains, soit environ huit fois ce seuil par mois.
This authorization requirement is clear, enforceable, and clearly ignored.
Je ne suis pas un professionnel du droit et je ne discute pas ici des conséquences juridiques spécifiques. Toutefois, il est à noter que l'industrie du logiciel a mis vingt ans à établir le respect des licences open source — des premiers litiges liés à la GPL jusqu'à l'intégration standard des SBOM (Software Bill of Materials) dans la sécurité de la chaîne d'approvisionnement. La conformité des licences pour les modèles d'IA se trouve probablement au tout début de cette phase sauvage.
Beaucoup pourraient penser que « marquer Kimi K2.5 » n'est pas une grande affaire. Mais le problème est que si une exigence de conformité aussi simple peut être ignorée, qui prend au sérieux des questions plus complexes — le flux de données, l'auditabilité du comportement du modèle, la conformité transfrontalière ?
Taxe de confiance : coût implicite opaque
Quelqu'un a utilisé le terme « Trust Tax » (taxe de confiance) pour décrire le coût de cet événement lié à Cursor, et je trouve ce concept très précis.
Lorsque vos utilisateurs découvrent que le « programmation intelligente de pointe » auquel ils paient 20 $ par mois en abonnement repose en réalité sur un modèle open source gratuit avec un fine-tuning, la confiance se fissure. Le problème n’est pas que Kimi K2.5 ne soit pas bon — il est en effet très bon — mais que les utilisateurs se sentent trompés.
Ce n'est pas la première fois que Cursor fait face à une crise de confiance. Précédemment, la controverse sur le prix du forfait Pro « illimité » a fait découvrir aux utilisateurs qu'ils avaient épuisé leur quota mensuel en seulement trois jours. Ajoutée à la question actuelle concernant l'origine des modèles, la dette de confiance s'accumule.
La question plus profonde est : dans la catégorie des outils d'agent IA, les utilisateurs paient-ils réellement pour quoi ?
Si la réponse est « capacité du modèle », l'utilisateur peut directement appeler l'API de Kimi K2.5, ce qui coûte beaucoup moins cher. Si la réponse est « expérience produit et intégration de la chaîne d'outils », Cursor devrait clairement expliquer où réside exactement sa valeur, au lieu d'impliquer vaguement que tout est développé en interne.
L'industrie mobile a déjà résolu ce problème. Personne ne se sent trompé parce que l'iPhone utilise des puces fabriquées par TSMC, car Apple n'a jamais prétendu posséder des usines de puces. La transparence et la valeur commerciale ne sont pas contradictoires.
L'ère du « fondement invisible » open source en Chine
Au-delà du cas spécifique de Cursor, la tendance structurelle plus importante est que les modèles open source chinois deviennent l'infrastructure de base des applications IA mondiales.
Clément Delangue, PDG de Hugging Face, a déclaré à ce sujet que l'open source en Chine est « la force la plus importante qui façonne la pile technologique mondiale de l'IA ». Ce n'est pas une simple formule de politesse.
La valorisation de Moonshot a quadruplé en trois mois, atteignant environ 18 milliards de dollars américains. L'événement Cursor a, d'une certaine manière, servi de validation mondiale pour Kimi auprès des développeurs : l'outil de programmation AI le plus valorisé au monde a choisi votre modèle comme base, ce qui est bien plus convaincant que n'importe quel benchmark.
Cette tendance ne se limite pas à des discussions géopolitiques. Pour les utilisateurs professionnels, une question pratique se pose : vos codes sont traités par des modèles dont vous ne connaissez pas la source.
Dans les secteurs réglementés (finance, santé, gouvernement), la souveraineté des données et la conformité transfrontalière sont des exigences obligatoires. Si vos développeurs utilisent un outil d'IA dont l'origine du modèle n'est pas transparente, votre équipe de conformité ne sait peut-être même pas quels risques elle court. Ce n'est pas un scénario hypothétique, c'est ce qui se passe actuellement.
Certains appellent ce type de risque « Shadow AI », analogue au concept de Shadow IT d'autrefois. Les développeurs ont intégré des modèles d'IA dans leurs IDE et leurs chaînes CI/CD, sans que les équipes de sécurité et juridiques en soient informées.
Étape suivante : AI-BOM et transparence de la chaîne d'approvisionnement
Après des incidents de sécurité de la chaîne d'approvisionnement tels que Log4j, l'industrie du logiciel a progressivement adopté le concept de SBOM (Software Bill of Materials) — une liste claire qui indique quels composants, quelles versions et quelles vulnérabilités connues sont utilisés dans votre logiciel.
Les modèles d'IA ont besoin des mêmes choses.
Le concept d'AI-BOM (AI Bill of Materials) commence à être discuté dans la communauté de la sécurité. La liste des composants d'un produit IA devrait inclure : le modèle de base utilisé, l'origine et le traitement des données d'entraînement, les méthodes de fine-tuning, ainsi que le déploiement du modèle et le flux des données.
Pour les développeurs, cela signifie qu'il faut commencer à examiner l'origine des modèles aussi soigneusement qu'on vérifie la licence des dépendances. `npm audit` et `pip check` sont déjà des opérations quotidiennes ; à l'avenir, `model audit` pourrait devenir une pratique standard.
Pour les fabricants d'outils IA, divulguer activement l'origine des modèles n'est pas un signe de faiblesse, mais un investissement dans la confiance à long terme. La première entreprise à intégrer l'AI-BOM comme configuration standard pourrait gagner une prime de confiance sur le marché.
Pour l'ensemble de l'industrie, la transparence de la chaîne d'approvisionnement des modèles passe de « nice to have » à « must have ». Ce changement n'aura peut-être pas besoin d'un événement de niveau Log4j pour être déclenché — l'histoire de Cursor est déjà un avertissement suffisamment fort.
Revenons à la scène initiale. Votre Cursor fonctionne toujours bien, Kimi K2.5 reste un modèle excellent. Les compétences techniques de Moonshot sont méritent respect, et l'accumulation de Cursor au niveau du produit et de la chaîne d'outils est réelle.
La question n'est jamais « d'avoir utilisé un modèle chinois » — dans un écosystème open source mondialisé, une bonne technologie ne devrait pas avoir d'étiquette nationale. La question, c'est « de ne pas vous l'avoir dit ».
Aujourd'hui, alors que les agents IA s'intègrent de plus en plus profondément dans les flux de travail, nous confions de plus en plus de code, de données et de décisions à ces outils. Nous devrions au moins savoir qui est le « cerveau » se trouvant derrière ces outils.
Transparency is not a technical detail; it is the infrastructure of trust.