









Article | Sleepy.txt
Il y a huit ans, ZTE a connu un arrêt cardiaque.
Le 16 avril 2018, une ordonnance de l'Bureau de l'industrie et de la sécurité du Département américain du Commerce a paralysé ZTE, le quatrième plus grand fabricant mondial d'équipements de communication, comptant 80 000 employés et un chiffre d'affaires annuel dépassant mille milliards, en une seule nuit. L'ordonnance stipulait simplement qu'aucune entreprise américaine ne pouvait vendre à ZTE des composants, produits, logiciels ou technologies pendant les sept années à venir.
Sans les puces de Qualcomm, les stations de base ont été arrêtées. Sans la licence Android de Google, les téléphones n'ont plus de système exploitable. 23 jours plus tard, ZTE a publié un communiqué indiquant que ses activités principales ne pouvaient plus être menées.
Mais ZTE a fini par survivre, au prix de 1,4 milliard de dollars.
Amende de 1 milliard de dollars à payer en une seule fois ; 400 millions de dollars de garantie déposés sur un compte de dépôt dans une banque américaine. En outre, remplacement complet de la direction supérieure et installation d'une équipe de surveillance de la conformité américaine. Pour l'année 2018, ZTE a enregistré une perte nette de 7 milliards de yuans, avec une chute de 21,4 % de son chiffre d'affaires par rapport à l'année précédente.
Le président de ZTE, Yin Yimin, a écrit dans une lettre interne : « Nous évoluons dans un secteur complexe, fortement dépendant des chaînes d'approvisionnement mondiales. » À l'époque, cette phrase semblait à la fois une réflexion et une expression de résignation.
Huit ans plus tard, le 26 février 2026, la licorne chinoise de l'IA DeepSeek annonce que son prochain modèle multimodal V4 établira une collaboration approfondie avec des fabricants nationaux de puces, réalisant pour la première fois une solution entièrement non NVIDIA, du pré-entraînement à l'ajustement fin.
Nous n'utilisons plus NVIDIA.
Dès l'annonce, la première réaction du marché a été de remettre cela en question. NVIDIA détient plus de 90 % du marché mondial des puces d'entraînement AI ; renoncer à elle, est-ce commercialement raisonnable ?
Mais derrière le choix de DeepSeek se cache une question plus grande que la logique commerciale : quelle indépendance en matière de puissance de calcul l'IA chinoise a-t-elle besoin ?
Qu'est-ce qui est vraiment bloqué ?
Beaucoup pensent que l'embargo sur les puces entrave le matériel. Mais ce qui étouffe véritablement les entreprises chinoises d'IA, c'est une chose appelée CUDA.
CUDA, qui signifie Compute Unified Device Architecture, est une plateforme de calcul parallèle et un modèle de programmation lancés par NVIDIA en 2006. Elle permet aux développeurs d'accéder directement à la puissance de calcul des GPU NVIDIA pour accélérer diverses tâches de calcul complexes.
Avant l'ère de l'IA, il ne s'agissait que d'un outil réservé à quelques geeks. Mais lorsque la vague de l'apprentissage profond a frappé, CUDA est devenu la fondation de toute l'industrie de l'IA.
L'entraînement des grands modèles d'IA repose essentiellement sur d'immenses opérations matricielles, ce qui correspond exactement à ce que les GPU font le mieux.
NVIDIA, grâce à un déploiement anticipé de plus de dix ans, a construit pour les développeurs d'IA du monde entier une chaîne d'outils complète, allant de l'hardware de base aux applications de haut niveau, avec CUDA. Aujourd'hui, tous les principaux frameworks d'IA, de TensorFlow de Google à PyTorch de Meta, sont profondément intégrés à CUDA en couche inférieure.
Un doctorant en intelligence artificielle apprend, programme et effectue des expériences dans un environnement CUDA depuis le premier jour de son inscription. Chaque ligne de code qu'il écrit renforce le fossé compétitif de NVIDIA.

En 2025, l'écosystème CUDA compte plus de 4,5 millions de développeurs, couvre plus de 3 000 applications accélérées par GPU, et est utilisé par plus de 40 000 entreprises dans le monde. Ce chiffre signifie que plus de 90 % des développeurs d'IA dans le monde sont liés à l'écosystème NVIDIA.
La force de CUDA réside dans le fait qu'il s'agit d'une roue d'inertie. Plus de développeurs l'utilisent, plus il génère d'outils, de bibliothèques et de code, et plus l'écosystème prospère ; plus l'écosystème prospère, plus il attire de nouveaux développeurs. Une fois en mouvement, cette roue d'inertie est presque impossible à déstabiliser.
Le résultat, c’est que NVIDIA vous vend la pelle la plus chère et définit la seule posture de minage. Vous voulez une autre pelle ? D’accord. Mais vous devrez réécrire intégralement toutes les expériences, outils et codes accumulés au cours des dernières décennies par des dizaines de milliers des cerveaux les plus brillants du monde dans cette posture.
Qui paie ce coût ?
Ainsi, le 7 octobre 2022, lorsque la première série de restrictions de la BIS est entrée en vigueur, limitant l'exportation vers la Chine des A100 et H100 de NVIDIA, les entreprises chinoises d'IA ont ressenti pour la première fois une sensation d'étouffement similaire à celle vécue par ZTE. NVIDIA a ensuite lancé les versions « spécifiques à la Chine » A800 et H800, réduisant la bande passante d'interconnexion entre les puces, afin de maintenir provisoirement l'approvisionnement.
Mais seulement un an plus tard, le 17 octobre 2023, un second cycle de restrictions a été renforcé, interdisant également les A800 et H800, et ajoutant 13 entreprises chinoises à la liste des entités. NVIDIA a dû à nouveau lancer une version encore plus limitée, l'H20. En décembre 2024, la dernière vague de restrictions sous l'administration Biden est entrée en vigueur, imposant des restrictions strictes à l'exportation de l'H20 lui-même.
Trois niveaux de restrictions, avec des mesures de plus en plus strictes.
Mais cette fois-ci, l'issue de l'histoire est totalement différente de celle de ZTE à l'époque.
Une percée asymétrique
Sous l'interdiction, tout le monde pensait que le rêve chinois des grands modèles d'IA prendrait fin.
Ils se sont tous trompés. Face au blocus, les entreprises chinoises n'ont pas choisi de faire face directement, mais ont entamé une percée. Le premier champ de bataille de cette percée n'est pas la puce, mais l'algorithme.
De la fin de l'année 2024 à 2025, les entreprises chinoises d'IA ont collectivement orienté leurs efforts vers une direction technologique : les modèles d'experts mélangés.
En résumé, il s'agit de diviser un modèle volumineux en plusieurs petits experts, et lors du traitement d'une tâche, n'activer que les quelques plus pertinents, plutôt que de faire fonctionner l'ensemble du modèle.
DeepSeek V3 est un exemple typique de cette approche. Il possède 671 milliards de paramètres, mais n'active que 37 milliards lors de chaque inférence, soit seulement 5,5 % du total. En termes de coût d'entraînement, il a utilisé 2048 GPU NVIDIA H800 pendant 58 jours, pour un coût total de 5,576 millions de dollars. À titre de comparaison, les estimations externes du coût d'entraînement de GPT-4 s'élèvent à environ 78 millions de dollars. Un écart d'un ordre de grandeur.
L'optimisation extrême au niveau algorithmique se reflète directement dans les prix. Le prix de l'API DeepSeek est de 0,028 à 0,28 $ pour 1 million de tokens en entrée et de 0,42 $ en sortie. En comparaison, le prix d'entrée de GPT-4o est de 5 $ et de 15 $ en sortie. Claude Opus est encore plus cher, avec un prix d'entrée de 15 $ et de 75 $ en sortie. En termes de comparaison, DeepSeek est 25 à 75 fois moins cher que Claude.
Cet écart de prix a suscité un énorme écho sur le marché mondial des développeurs. En février 2026, sur OpenRouter, la plus grande plateforme d'agrégation d'API de modèles d'IA au monde, le volume hebdomadaire d'appels des modèles d'IA chinois a augmenté de 127 % en trois semaines, dépassant pour la première fois les États-Unis. Il y a un an, la part des modèles chinois sur OpenRouter était inférieure à 2 %. Un an plus tard, elle a augmenté de 421 %, s'approchant de 60 %.
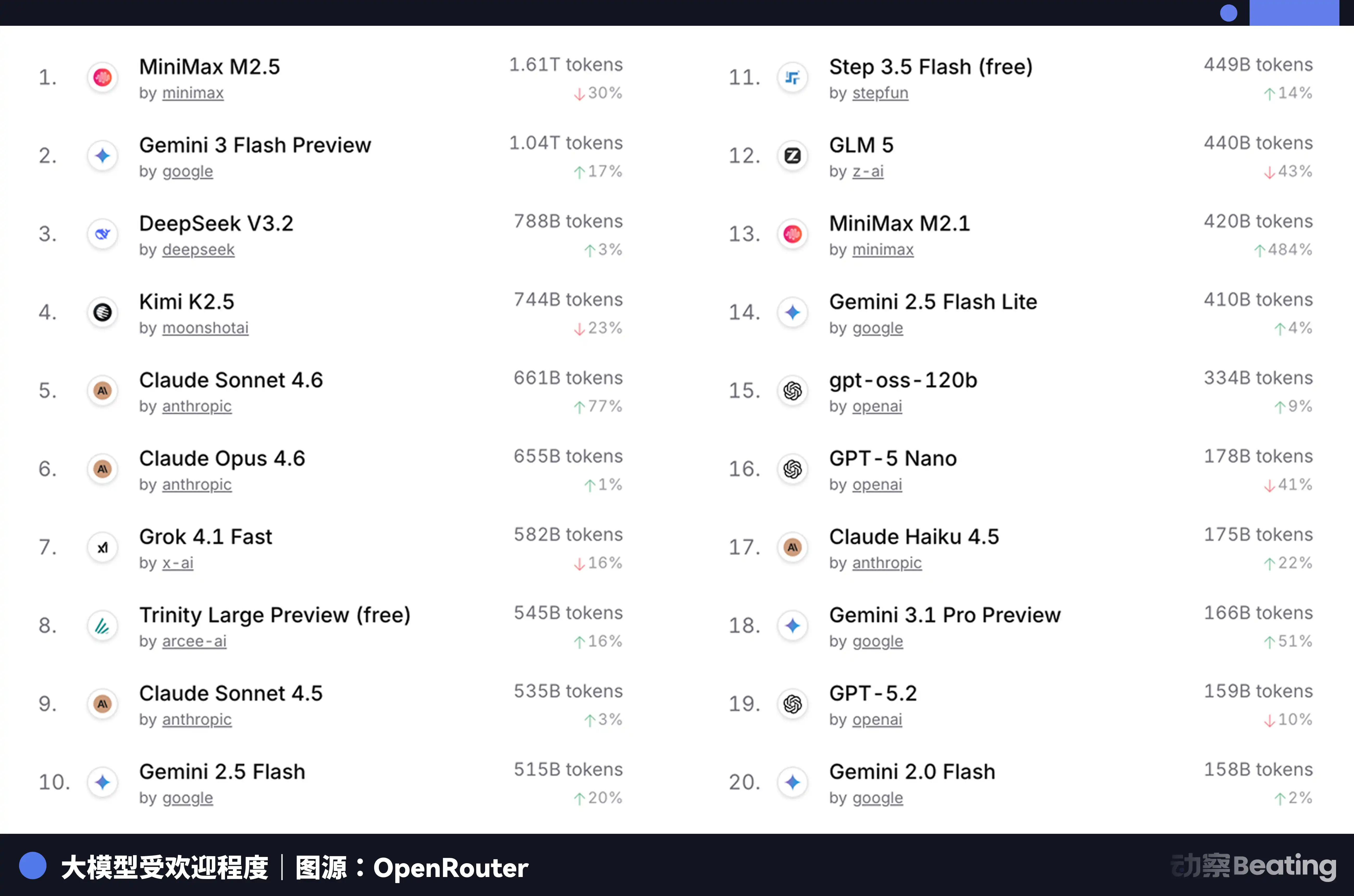
Derrière ces données se cache un changement structurel souvent négligé. À partir du second semestre 2025, les scénarios principaux des applications d'IA passeront du chat à l'Agent. Dans les scénarios d'Agent, la consommation de tokens pour une tâche est de 10 à 100 fois supérieure à celle d'un simple chat. Lorsque la consommation de tokens augmente de manière exponentielle, le prix devient un facteur déterminant. Le rapport qualité-prix extrême des modèles chinois correspond exactement à cette fenêtre.
Mais le problème est que la réduction des coûts d'inférence ne résout pas le problème fondamental de l'entraînement. Un grand modèle dont la capacité à s'entraîner et à itérer continuellement sur les données les plus récentes est limitée voit ses performances se dégrader rapidement. Et l'entraînement reste toujours ce trou noir de puissance de calcul incontournable.
Alors, d'où viennent les « pioches » entraînées ?
Passage de la position de « deuxième choix » à la position officielle
Jiangsu Xinghua, une petite ville du sud du Jiangsu, connue pour son acier inoxydable et ses aliments sains, n'avait auparavant aucun lien avec l'IA. Mais en 2025, une ligne de production nationale de serveurs de calcul d'une longueur de 148 mètres a été construite et mise en service ici, en seulement 180 jours depuis la signature de l'accord.
Le cœur de cette chaîne de production est constitué de deux puces entièrement nationales : le processeur Loongson 3C6000 et la carte d'accélération AI Taichu Yuanqi T100. Le Loongson 3C6000 possède un jeu d'instructions et une micro-architecture entièrement développés en interne. La carte Taichu Yuanqi provient de l'équipe du Centre national de calcul supercalculateur de Wuxi et de l'Université Tsinghua, et utilise une architecture hétérogène multi-cœurs.
Lorsque cette ligne de production fonctionne à pleine capacité, un serveur est produit toutes les 5 minutes. L'investissement total de cette ligne de production s'élève à 1,1 milliard de yuans, avec une production annuelle prévue de 100 000 unités.
Plus important encore, les clusters de dix mille puces basés sur ces puces nationales ont déjà commencé à prendre en charge des tâches d'entraînement de grands modèles réels.
En janvier 2026, Zhipu AI, en collaboration avec Huawei, a lancé GLM-Image, le premier modèle d' génération d'images SOTA entièrement entraîné sur des puces nationales. En février, le modèle de grande taille « Xingchen » de China Telecom a été entièrement entraîné sur le pool de calcul national de dix mille cartes à Shanghai Lingang.

La signification de ces cas réside dans le fait qu'ils démontrent un seul point : les puces nationales sont passées de « capables d'inférence » à « capables d'entraînement ». Il s'agit d'une transformation qualitative. L'inférence ne nécessite que l'exécution de modèles déjà entraînés, ce qui impose des exigences relativement faibles pour les puces ; tandis que l'entraînement exige le traitement de volumes massifs de données, des calculs de gradients complexes et des mises à jour de paramètres, imposant des exigences en termes de puissance de calcul, de bande passante d'interconnexion et d'écosystème logiciel supérieures d'un ordre de grandeur.
La force centrale derrière ces tâches est la série de puces Ascend de Huawei. À la fin de 2025, le nombre de développeurs dans l'écosystème Ascend a dépassé 4 millions, avec plus de 3 000 partenaires, et 43 des principaux modèles d'intelligence artificielle du secteur ont été pré-entraînés sur Ascend, tandis que plus de 200 modèles open source ont été adaptés. Le 2 mars 2026, lors du salon MWC, Huawei a lancé en exclusivité sur les marchés internationaux sa nouvelle infrastructure de calcul SuperPoD.
La puissance de calcul FP16 du Ascend 910B est désormais équivalente à celle de la NVIDIA A100. Bien qu'un écart subsiste, il est passé de non utilisable à utilisable, et continue de s'améliorer vers une utilisation optimale. Le développement de l'écosystème ne peut pas attendre que la puce soit parfaite ; il doit être largement déployé dès la phase où elle est suffisamment performante, en utilisant des besoins commerciaux réels pour pousser l'itération des puces et des logiciels. Les objectifs d'adoption des serveurs de calcul national par ByteDance, Tencent et Baidu devraient doubler en 2026 par rapport à l'année précédente. Selon les données du ministère de l'Industrie et des Technologies de l'information, la capacité de calcul intelligent en Chine atteint déjà 1590 EFLOPS. L'année 2026 devient l'année charnière du déploiement à grande échelle du calcul national.
Pénurie d'électricité aux États-Unis et expansion chinoise à l'étranger
Au début de l'année 2026, la Virginie, qui héberge une grande partie du trafic des centres de données mondiaux, a suspendu l'approbation de nouveaux projets de centres de données. La Géorgie a suivi, prolongeant la suspension des autorisations jusqu'en 2027. L'Illinois et le Michigan ont également adopté des mesures restrictives.
Selon les données de l'Agence internationale de l'énergie, la consommation d'électricité des centres de données aux États-Unis a atteint 183 térawattheures en 2024, soit environ 4 % de la consommation totale du pays. D'ici 2030, ce chiffre devrait doubler pour atteindre 426 TWh, avec une part pouvant dépasser 12 %. Le PDG d'Arm a même prédit qu'en 2030, les centres de données AI consommeront entre 20 % et 25 % de l'électricité aux États-Unis.
Le réseau électrique américain est déjà surchargé. Le réseau PJM, qui couvre 13 États de l'Est des États-Unis, fait face à une pénurie de capacité de 6 GW. D'ici 2033, l'ensemble des États-Unis connaîtra un déficit de capacité électrique de 175 GW, équivalent à la consommation de 130 millions de ménages. Les coûts de l'électricité de gros dans les régions concentrées de centres de données ont augmenté de 267 % par rapport à il y a cinq ans.
La limite de la puissance de calcul est l'énergie. Sur ce plan, l'écart entre la Chine et les États-Unis est plus grand que celui des puces, mais dans la direction inverse.
La production d'électricité annuelle de la Chine est de 10,4 billions de kilowattheures, contre 4,2 billions aux États-Unis, soit 2,5 fois plus. Plus important encore, la consommation d'électricité résidentielle en Chine ne représente que 15 % de la consommation totale, contre 36 % aux États-Unis. Cela signifie que la Chine dispose d'une capacité industrielle bien plus importante que les États-Unis pour dédier à la construction de puissance de calcul.
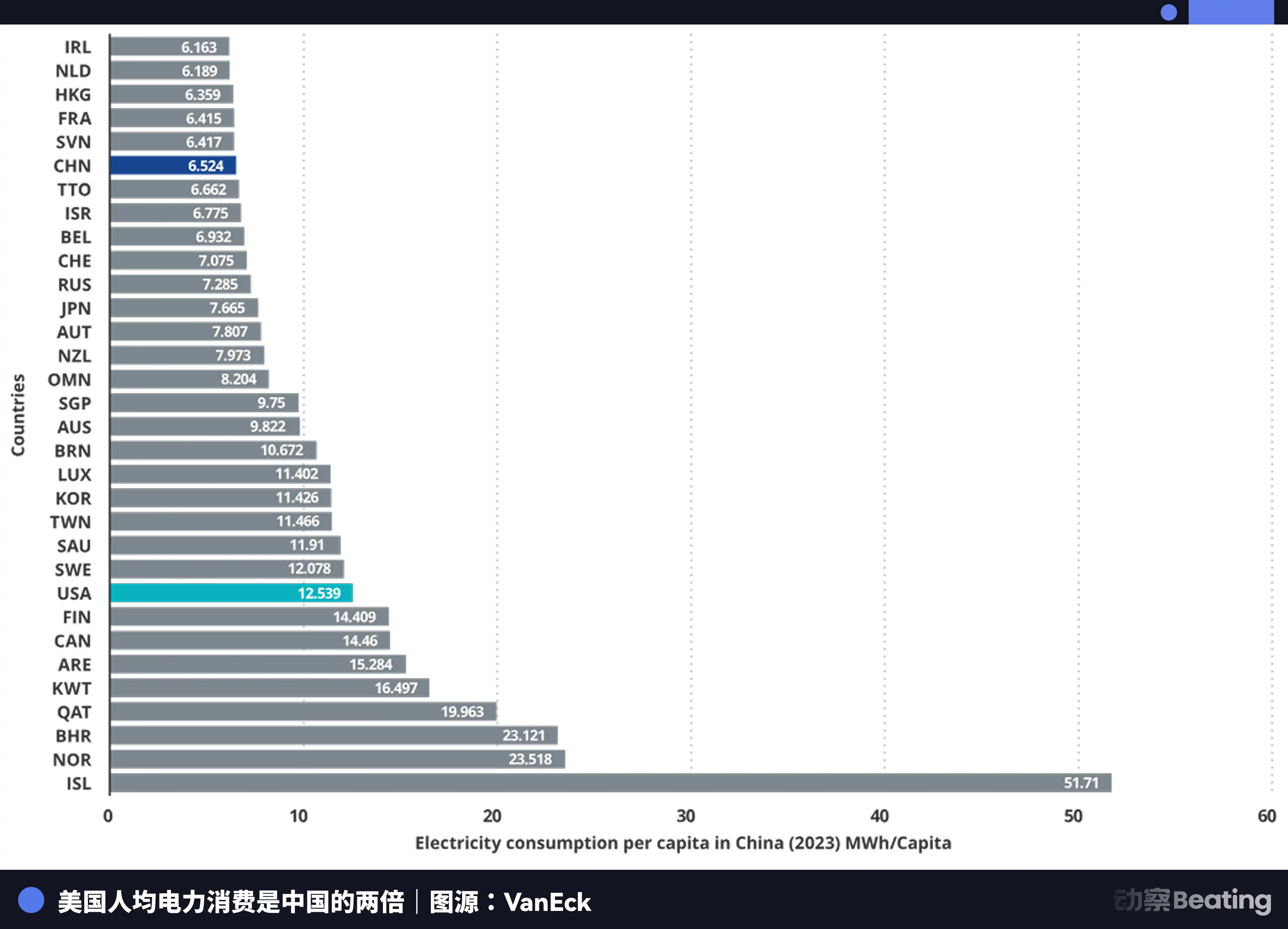
Aux États-Unis, dans les régions où les entreprises d'IA sont regroupées, le prix de l'électricité se situe entre 0,12 et 0,15 dollar par kilowattheure, tandis que le prix industriel de l'électricité dans l'ouest de la Chine est d'environ 0,03 dollar, soit seulement un quart à un cinquième du prix aux États-Unis.
L'augmentation de la production d'électricité en Chine atteint sept fois celle des États-Unis.
Alors que les États-Unis s'interrogent sur l'électricité, l'IA chinoise s'exporte discrètement. Mais cette fois-ci, ce ne sont pas les produits ni les usines qui s'exportent, ce sont les tokens.
Les tokens, unités minimales traitées par les modèles d'IA, deviennent un nouveau bien numérique. Ils sont produits dans les usines de calcul en Chine et acheminés à travers des câbles sous-marins vers le monde entier.
Les données de répartition des utilisateurs de DeepSeek sont très révélatrices : 30,7 % en Chine continentale, 13,6 % en Inde, 6,9 % en Indonésie, 4,3 % aux États-Unis et 3,2 % en France. Il prend en charge 37 langues et est très populaire sur des marchés émergents comme le Brésil. Plus de 26 000 entreprises à travers le monde ont créé un compte, et 3 200 institutions ont déployé la version entreprise.
En 2025, 58 % des nouvelles startups d'IA ont intégré DeepSeek dans leur pile technologique. En Chine, DeepSeek détient 89 % du marché. Dans d'autres pays sous sanctions, la part de marché varie entre 40 % et 60 %.
Cette scène ressemble fortement à une autre guerre sur l'autonomie industrielle il y a quarante ans.
À Tokyo en 1986, sous une forte pression des États-Unis, le gouvernement japonais a signé l'Accord sur les semi-conducteurs entre le Japon et les États-Unis. Les trois clauses principales de l'accord étaient les suivantes : exiger que le Japon ouvre son marché des semi-conducteurs, que la part de marché des puces américaines au Japon dépasse 20 % ; interdire aux semi-conducteurs japonais d'exporter à un prix inférieur à leur coût ; imposer un droit de douane punitif de 100 % sur 300 millions de dollars de puces exportées par le Japon. En outre, les États-Unis ont bloqué la prise de contrôle de Fairchild Semiconductor par Fujitsu.
Cette année-là, l'industrie japonaise des semi-conducteurs était au sommet de sa puissance. En 1988, le Japon contrôlait 51 % du marché mondial des semi-conducteurs, contre 36,8 % pour les États-Unis. Parmi les dix plus grandes entreprises mondiales de semi-conducteurs, six étaient japonaises : NEC en deuxième position, Toshiba en troisième, Hitachi en cinquième, Fujitsu en septième, Mitsubishi en huitième et Panasonic en neuvième. En 1985, Intel a enregistré une perte de 173 millions de dollars américains dans la bataille des semi-conducteurs entre le Japon et les États-Unis, au bord de la faillite.
Mais après la signature de l'accord, tout a changé.
Les États-Unis ont lancé une pression globale contre les entreprises japonaises de semi-conducteurs par le biais d'enquêtes telles que l'enquête 301, tout en soutenant Samsung et SK Hynix en Corée du Sud pour perturber le marché japonais à des prix plus bas. La part du marché japonais en DRAM est tombée de 80 % à 10 %. En 2017, la part de marché japonaise dans les circuits intégrés n'était plus que de 7 %. Les géants autrefois dominants ont été soit scindés, soit rachetés, soit contraints de quitter le marché amidon de pertes continues.
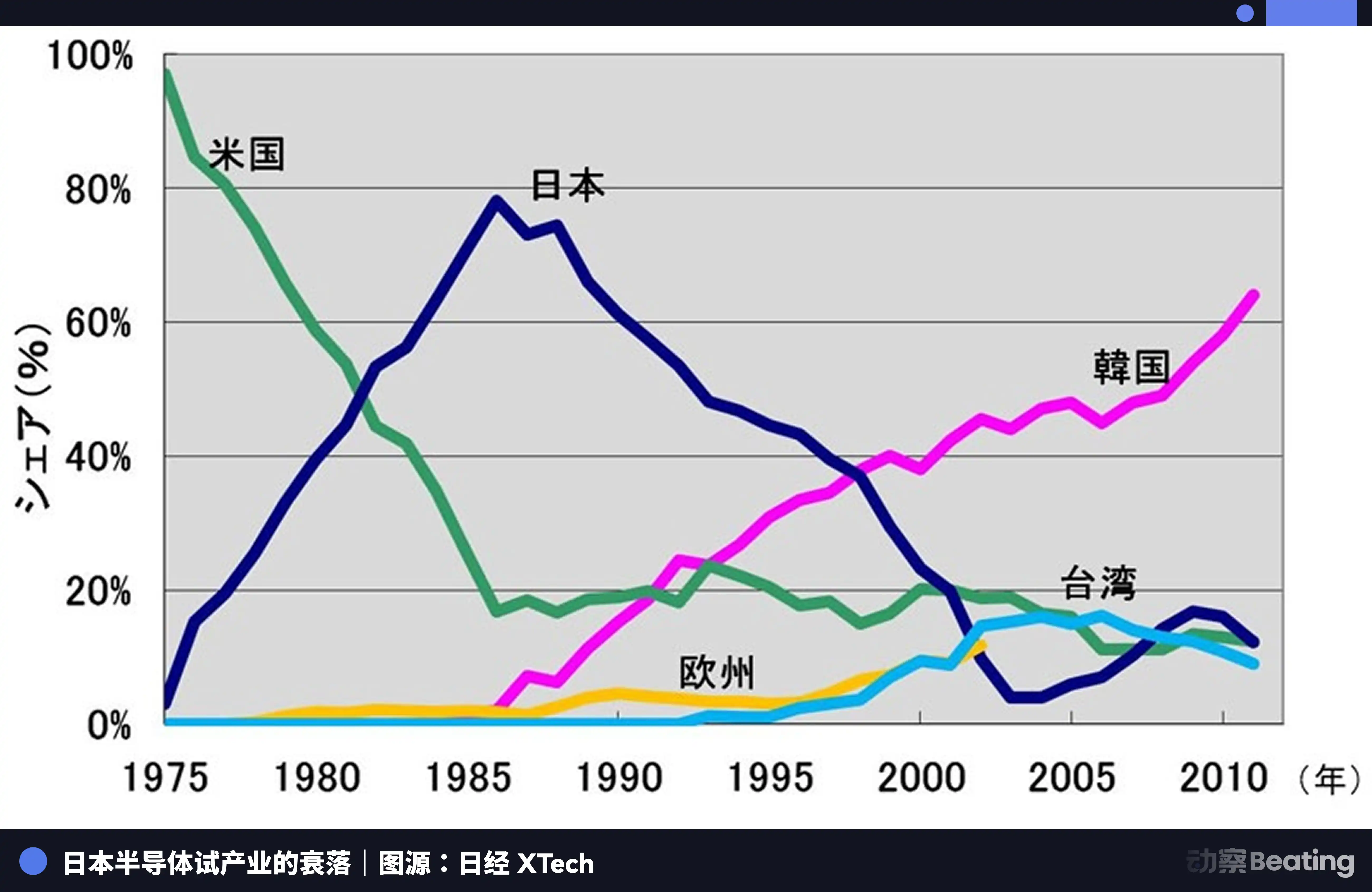
Le drame des semi-conducteurs japonais réside dans le fait qu'ils se sont contentés d'être le meilleur producteur dans un système de division du travail mondial dominé par une seule puissance externe, sans jamais chercher à construire un écosystème propre et indépendant. Lorsque la marée s'est retirée, ils ont réalisé qu'ils ne possédaient rien d'autre que la production elle-même.
L'industrie chinoise de l'IA se trouve aujourd'hui à un carrefour similaire, mais complètement différent.
De même, nous faisons face à une pression externe considérable. Trois rounds de restrictions sur les puces, avec des mesures de plus en plus strictes, et les barrières de l'écosystème CUDA restent élevées.
Contrairement à cela, cette fois-ci, nous avons choisi un chemin plus difficile : de l’optimisation extrême au niveau algorithmique, au passage des puces nationales de l’inférence à l’entraînement, en passant par l’accumulation de 4 millions de développeurs dans l’écosystème Ascend, jusqu’à la pénétration des tokens sur les marchés mondiaux. Chaque étape de ce chemin construit un écosystème industriel indépendant que le Japon n’a jamais possédé.
Épilogue
Le 27 février 2026, trois bulletins de résultats provenant d'entreprises locales de puces IA ont été publiés le même jour.
Cambricon, revenus en hausse de 453 %, réalise pour la première fois un bénéfice annuel. Moore Threads, revenus en hausse de 243 %, mais perte nette de 1 milliard. Moxi, revenus en hausse de 121 %, perte nette de près de 800 millions.
La moitié est feu, l'autre moitié est mer.
La flamme, c’est la soif extrême du marché. Les 95 % de vide laissés par Huang Renxun sont en train d’être remplis peu à peu par les chiffres d’affaires de ces entreprises locales. Quelle que soit la performance, quelle que soit l’écosystème, le marché a besoin d’une deuxième option en dehors de NVIDIA. C’est une opportunité structurelle sans précédent ouverte par la géopolitique.
L'eau de mer représente un coût énorme pour le développement écologique. Chaque perte correspond à des fonds réels investis pour rattraper l'écosystème CUDA : des investissements en R&D, des subventions logicielles, et les coûts humains des ingénieurs déployés sur site pour résoudre un par un les problèmes de compilation. Ces pertes ne résultent pas d'une mauvaise gestion, mais constituent le prix à payer pour construire un écosystème indépendant.
Ces trois rapports financiers ont enregistré avec plus d'honnêteté la réalité de cette guerre de puissance de calcul que n'importe quel rapport sectoriel. Ce n'est pas une victoire triomphante, mais une bataille de position sanglante, menée au prix de pertes tout en avançant.
Mais la nature de la guerre a vraiment changé. Il y a huit ans, nous discutions de la question « pouvons-nous survivre ? ». Aujourd'hui, nous discutons de la question « quel prix devons-nous payer pour survivre ? ».
Le coût lui-même, c'est le progrès.
Cliquez pour découvrir les postes ouverts chez BlockBeats
Rejoignez la communauté officielle de律动 BlockBeats :
Groupe Telegram abonné : https://t.me/theblockbeats
Groupe Telegram : https://t.me/BlockBeats_App
Compte officiel Twitter : https://twitter.com/BlockBeatsAsia