










Auteur original : KarenZ, Foresight News
Le 20 mars 2026, un échange inhabituel a eu lieu dans le podcast d'All-In Ventures.
L'investisseur institutionnel Chamath Palihapitiya a laissé la parole à Jensen Huang, PDG de NVIDIA, en disant qu'un projet sur Bittensor avait accompli « un exploit technologique assez fou » : entraîner un modèle de langage à grande échelle sur Internet en utilisant une puissance de calcul distribuée, entièrement décentralisée, sans aucune intervention de centres de données centralisés.
Huang Renxun n'a pas évité la question. Il a comparé cela à une version moderne de Folding@home, ce projet distribué des années 2000 qui permettait aux utilisateurs ordinaires de contribuer leur puissance informatique inutilisée pour lutter contre le problème du repliement des protéines.
Quatre jours auparavant, le 16 mars, Jack Clark, cofondateur d'Anthropic, a également consacré de nombreuses pages à cette percée dans un rapport sur les progrès de la recherche en IA : le sous-réseau Bittensor Templar (SN3) a achevé l'entraînement distribué d'un modèle de 72 milliards de paramètres (Covenant 72B), dont les performances sont comparables à celles de LLaMA-2 publié par Meta en 2023.
Jack Clark a intitulé ce chapitre « Défier l'économie politique de l'IA par l'entraînement distribué » et souligne dans son analyse qu'il s'agit d'une technologie méritant une surveillance continue — il imagine un avenir où les modèles issus de l'entraînement décentralisé seront largement adoptés sur les appareils, tandis que l'IA cloud continuera à exécuter des grands modèles propriétaires.
La réaction du marché a été légèrement retardée mais très intense : SN3 a augmenté de plus de 440 % au cours du dernier mois et de plus de 340 % au cours des deux dernières semaines, atteignant une capitalisation boursière de 130 millions de dollars. L'explosion du récit autour du sous-réseau se traduit directement par une pression d'achat sur TAO. En conséquence, TAO a fortement augmenté, atteignant un pic de 377 dollars, doublant sa valeur au cours du dernier mois, avec une FDV d'environ 7,5 milliards de dollars.
La question se pose : qu’a exactement fait SN3 ? Pourquoi a-t-il été mis sous les feux de la rampe ? Comment l’histoire de valeur du traitement distribué et de l’IA décentralisée évoluera-t-elle ?
Ce modèle de 72B
Pour répondre à cette question, il faut d'abord examiner les résultats fournis par SN3.
Le 10 mars 2026, l'équipe Covenant AI a publié un rapport technique sur arXiv, annonçant officiellement la fin de l'entraînement de Covenant-72B. Ce modèle de langage à grande échelle compte 72 milliards de paramètres et a été pré-entraîné sur un corpus d'environ 1,1 billion de tokens, en utilisant plus de 70 nœuds indépendants (environ 20 nœuds synchronisés par cycle, chacun équipé de 8 cartes B200).
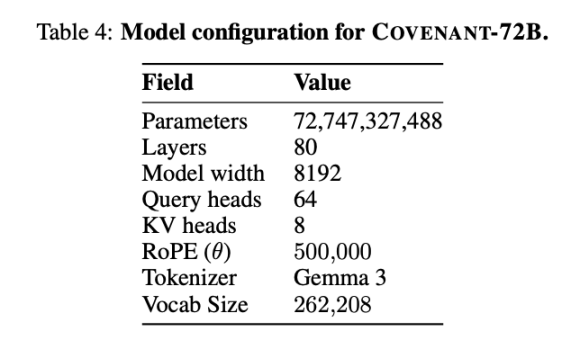
Templar a fourni certaines données sur les tests de référence, avec pour point de comparaison le modèle LLaMA-2-70B publié par Meta en 2023. Comme l'a déclaré Jack Clark, cofondateur d'Anthropic, Covenant-72B pourrait déjà sembler dépassé en 2026. Le score de 67,1 de Covenant-72B sur MMLU correspond approximativement à celui de LLaMA-2-70B de Meta (65,6), publié en 2023.
Les modèles de pointe de 2026 — qu'il s'agisse de la série GPT, Claude ou Gemini — ont déjà été entraînés sur des centaines de milliers de GPU avec un nombre de paramètres bien supérieur à 100 milliards ; les écarts en matière de raisonnement, de codage et de mathématiques sont d'ordre de grandeur, et non de pourcentage. Cette réalité ne doit pas être noyée par l'humeur du marché.
Mais dans le contexte de « l'entraînement à l'aide de la puissance de calcul distribuée sur Internet ouvert », la signification est totalement différente.
Faisons une comparaison : INTELLECT-1 (développé par l'équipe Prime Intellect, 10 milliards de paramètres), formé de manière décentralisée, obtient un score MMLU de 32,7 ; un autre projet de formation distribuée parmi des participants autorisés, Psyche Consilience (40 milliards de paramètres), obtient un score de 24,2. Covenant-72B, avec une taille de 72 milliards de paramètres et un score MMLU de 67,1, représente un chiffre remarquable dans la catégorie de la formation décentralisée.
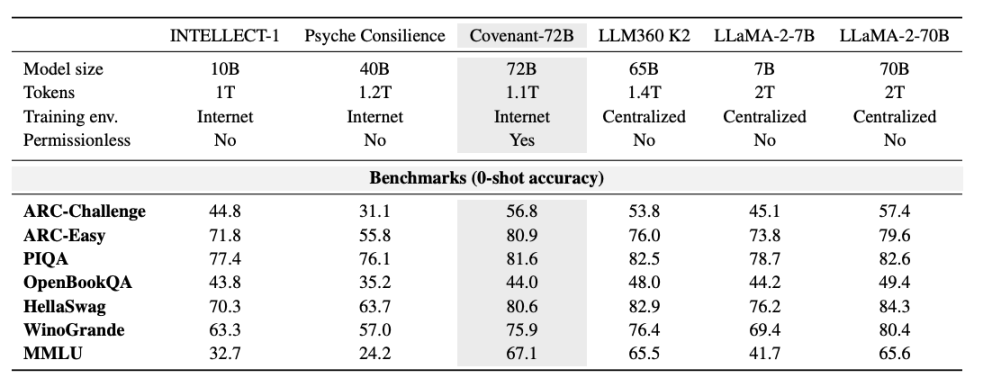
Plus important encore, ce entraînement est « sans autorisation ». Quiconque peut se connecter en tant que nœud participant, sans examen préalable ni liste blanche. Plus de 70 nœuds indépendants ont participé à la mise à jour du modèle, en contribuant des ressources de calcul depuis le monde entier.
Ce que Jensen Huang a dit, et ce qu'il n'a pas dit
Rétablir les détails de la conversation du podcast aidera à corriger les interprétations externes de ce « soutien ».
Chamath Palihapitiya a présenté les réalisations techniques de Bittensor à Jensen Huang lors de la conversation, décrivant comment un modèle Llama avait été formé à l'aide de puissance de calcul distribuée, « entièrement distribuée tout en conservant l'état ». La réponse de Jensen Huang a consisté à comparer cela à une « version moderne de Folding@home », et il a approfondi la discussion sur la nécessité de la coexistence des modèles open source et propriétaires.
Il est à noter que Huang Renxun n'a pas mentionné directement le jeton de Bittensor ni aucune implication d'investissement, ni n'a approfondi la discussion sur l'entraînement décentralisé de l'IA.
Comprendre les sous-réseaux Bittensor et SN3
Pour comprendre la percée de SN3, il faut d'abord saisir le fonctionnement de Bittensor et de ses sous-réseaux. En termes simples, Bittensor peut être vu comme une chaîne et une plateforme AI dédiée, tandis que chaque sous-réseau équivaut à une « ligne de production AI » indépendante, avec une mission centrale bien définie, un mécanisme d'incitation conçu spécifiquement, et qui collabore pour constituer un écosystème AI décentralisé.
Son fonctionnement est clair et décentralisé : les propriétaires de sous-réseaux définissent les objectifs du sous-réseau et conçoivent un modèle d'incitation ; les mineurs fournissent de la puissance de calcul au sein du sous-réseau et accomplissent des tâches liées à l'IA (telles que l'inférence, l'entraînement, le stockage, etc.) ; les validateurs évaluent les contributions des mineurs et téléchargent ces notes sur la couche de consensus de Bittensor ; enfin, l'algorithme de consensus Yuma de Bittensor attribue des récompenses aux participants du sous-réseau en fonction des récompenses accumulées par chaque sous-réseau.
Il existe actuellement 128 sous-réseaux sur Bittensor, couvrant diverses tâches d'IA telles que l'inférence, les services cloud AI sans serveur, l'image, l'étiquetage de données, l'apprentissage par renforcement, le stockage et le calcul.
SN3 est l’un de ces sous-réseaux. Il ne se contente pas de créer une couche application, ni de louer des API de grands modèles existants, mais vise directement l’un des segments les plus coûteux et les plus fermés de la chaîne de valeur de l’IA : la pré-formation des grands modèles eux-mêmes.
SN3 souhaite utiliser le réseau Bittensor pour coordonner l'entraînement distribué de ressources de calcul hétérogènes, prouvant par un entraînement distribué incité de grands modèles qu'il est possible d'entraîner des modèles de base puissants sans recourir à des clusters de supercalculateurs centralisés coûteux. L'atout principal réside dans l'« égalité » — briser le monopole des ressources lié à l'entraînement centralisé et permettre aux particuliers ou aux petites et moyennes institutions de participer à l'entraînement de grands modèles, tout en réduisant les coûts d'entraînement grâce à la puissance de calcul distribuée.
La force motrice derrière le développement de SN3 est Templar, dont l'équipe de recherche sous-jacente est Covenant Labs. Cette équipe gère également deux autres sous-réseaux : Basilica (SN39, axé sur les services de calcul) et Grail (SN81, axé sur le post-entraînement RL et l'évaluation des modèles). Les trois sous-réseaux forment une intégration verticale couvrant l'ensemble du processus, de la pré-formation à l'optimisation d'alignement des grands modèles, constituant ainsi un écosystème complet pour l'entraînement décentralisé des grands modèles.
Plus précisément, les mineurs contribuent des ressources de calcul en téléchargeant les mises à jour de gradient (la direction et l'intensité des ajustements des paramètres du modèle) sur le réseau ; les validateurs évaluent la qualité de la contribution de chaque mineur et attribuent une note sur la chaîne en fonction de l'amélioration de l'erreur. Le résultat détermine le poids des récompenses, qui sont attribuées automatiquement, sans nécessiter de confiance en un tiers.
La clé de la conception du mécanisme d'incitation est de lier les récompenses directement à « la mesure dans laquelle votre contribution a amélioré le modèle », et non simplement à la puissance de calcul fournie. Cela résout fondamentalement le problème le plus difficile dans les scénarios décentralisés : comment empêcher les mineurs de tricher.
Comment Covenant-72B résout-il les problèmes d'efficacité de la communication et de compatibilité des incitations ?
Coordonner des dizaines de nœuds non fiables, aux matériels variés et à des qualités de réseau inégales pour entraîner un même modèle présente deux défis : d’abord, l’efficacité de la communication — les solutions traditionnelles d’entraînement distribué exigent une interconnexion à haut débit et à faible latence entre les nœuds ; ensuite, l’alignement des incitations — comment empêcher les nœuds malveillants de soumettre des gradients erronés ? Comment s’assurer que chaque participant effectue réellement l’entraînement et ne se contente pas de copier les résultats des autres ?
SN3 résout ces deux problèmes avec deux composants principaux : SparseLoCo et Gauntlet.
SparseLoCo résout les problèmes d'efficacité de communication. Les entraînements distribués traditionnels synchronisent les gradients complets à chaque étape, ce qui génère une quantité de données énorme. La solution adoptée par SparseLoCo consiste à faire exécuter à chaque nœud 30 étapes d'optimisation locale (AdamW), puis à compresser les « pseudo-gradients » générés avant de les envoyer aux autres nœuds. La compression inclut la sparsification Top-k (conservation uniquement des composantes de gradient les plus critiques), la rétroaction d'erreur (stockage des composants supprimés pour les accumuler à l'étape suivante) et la quantification sur 2 bits. Le taux de compression final dépasse 146 fois.
En d'autres termes, ce qui nécessitait auparavant de transférer 100 Mo ne nécessite désormais que moins de 1 Mo.
Cela permet au système de maintenir une utilisation du calcul à environ 94,5 % sous les limites de bande passante d'Internet classique (110 Mbps en montée, 500 Mbps en descente) — 20 nœuds, 8 B200 par nœud, chaque cycle de communication ne prenant que 70 secondes.
Gauntlet résout le problème de la compatibilité des incitations. Il s'exécute sur la blockchain Bittensor (Subnet 3) et est chargé de vérifier la qualité des pseudo-gradients soumis par chaque nœud. Le mécanisme consiste à tester, sur un petit ensemble de données, « de combien la perte du modèle diminue lorsqu'on utilise le gradient de ce nœud » ; le résultat est appelé LossScore. Le système vérifie également si le nœud s'entraîne bien sur les données qui lui ont été attribuées — si un nœud obtient une amélioration de la perte sur des données aléatoires supérieure à celle obtenue sur ses propres données attribuées, il se voit attribuer une note négative.
À la fin de chaque itération, seuls les gradients du nœud ayant obtenu la meilleure note sont sélectionnés pour l'agrégation, les autres étant éliminés pour cette itération. Des participants supplémentaires sont ajoutés en temps réel pour maintenir la stabilité du système. Au cours de l'ensemble du processus d'entraînement, en moyenne, les gradients de 16,9 nœuds par itération sont inclus dans l'agrégation, et plus de 70 ID de nœuds uniques ont participé au total.
La narration de valeur de l'IA décentralisée connaît une transformation fondamentale
Du point de vue technique et industriel, la direction représentée par Covenant-72B a plusieurs significations réelles.
Premièrement, il a brisé l'hypothèse selon laquelle l'entraînement distribué ne convient qu'aux petits modèles. Bien qu'il reste encore loin des modèles les plus avancés, il a démontré l'évolutivité de cette approche.
Deuxièmement, la participation sans autorisation est réellement réalisable. Ce point est sous-estimé. Les projets précédents d’entraînement distribué reposaient sur une liste blanche — seuls les participants approuvés pouvaient contribuer leur puissance de calcul. Pour cet entraînement SN3, toute personne disposant d’une puissance de calcul suffisante peut se connecter, tandis que le mécanisme de vérification filtre les contributions malveillantes. Il s’agit d’une étape concrète vers une « décentralisation véritable ».
Troisièmement, le mécanisme dTAO de Bittensor permet la découverte de marché de la valeur des sous-réseaux. dTAO permet à chaque sous-réseau d'émettre son propre token Alpha, permettant au marché de déterminer, via un mécanisme AMM, quels sous-réseaux reçoivent davantage de récompenses TAO. Cela offre aux sous-réseaux ayant produit des résultats concrets, comme SN3, un mécanisme de capture de valeur approximatif mais efficace. Toutefois, ce mécanisme est également vulnérable aux narrations et aux émotions, car la qualité des résultats d'entraînement des LLM est difficile à évaluer indépendamment par les participants ordinaires du marché.
Quatrièmement, les implications politico-économiques de l'entraînement décentralisé de l'IA. Jack Clark, dans Import AI, a élevé cette question au niveau de « qui possède l'avenir de l'IA ». L'entraînement des modèles de pointe actuels est monopolisé par un petit nombre d'institutions possédant de vastes centres de données, ce qui constitue non seulement un problème commercial, mais aussi une question de structure de pouvoir. Si l'entraînement distribué parvient à poursuivre des progrès techniques, il pourrait éventuellement créer un écosystème de développement véritablement décentralisé pour certains types de modèles (comme les petits modèles de pointe dans des domaines spécifiques). Toutefois, cet avenir reste encore très lointain.
Résumé : une véritable étape importante, ainsi qu'une série de problèmes réels
Huang Renxun a déclaré que cela ressemble à une « version moderne de Folding@home ». Folding@home a apporté des contributions réelles dans le domaine de la simulation moléculaire, mais il n'a pas menacé la position centrale des grandes entreprises pharmaceutiques en matière de recherche et développement. Cette analogie est très précise.
SN3 a mis en œuvre le protocole et validé une direction possible pour l'entraînement distribué. Mais du point de vue technique et industriel, derrière ce bilan, il y a encore de nombreux problèmes que peu de gens sont prêts à aborder sérieusement :
MMLU est lui-même un indicateur controversé dans le milieu académique, car les questions et réponses des benchmarks publics risquent d'être leakées dans les ensembles d'entraînement. Ce qui mérite davantage d'attention, c'est le choix des lignes de base : les modèles comparés dans l'article, LLaMA-2-70B et LLM360 K2, sont tous deux des modèles anciens datant de 2023 à 2024, alors que des scores compris entre 65 et 70 points durant la même période sont considérés comme étant de niveau moyen-inférieur ou débutant lorsqu'on les compare à Grok ou DouBao, et comme sérieusement en retard selon Claude. Si ces résultats étaient évalués sur des classements dynamiquement mis à jour ou sur de nouveaux benchmarks conçus pour résister à la contamination, les conclusions seraient probablement plus honnêtes.
Plus important encore, les données de haute qualité qui déterminent la capacité maximale des modèles — données conversationnelles, code, démonstrations mathématiques, publications scientifiques — sont probablement détenues par de grandes entreprises, des éditeurs et des bases de données académiques. Alors que la puissance de calcul est devenue démocratisée, le segment des données reste un oligopole, une contradiction qui n’a jamais été discutée.
En ce qui concerne la sécurité, la participation sans autorisation signifie que vous ne savez pas qui se trouve derrière ces 70 nœuds ni quelles données ils utilisent pour l'entraînement. Gauntlet peut filtrer les gradients manifestement anormaux, mais ne peut pas prévenir l'empoisonnement subtil des données — si un nœud entraîne systématiquement plusieurs itérations supplémentaires sur un type spécifique de contenu nocif, les changements de gradient sont suffisamment subtils pour passer à travers le filtrage basé sur le score de perte, mais provoquent un décalage cumulatif du comportement du modèle. La question finale est : dans des scénarios à forte exigence de conformité et de sécurité tels que la finance, la santé ou le droit, quelles sont les risques associés à l'utilisation d'un modèle entraîné par un petit nombre de nœuds anonymes et dont la provenance des données n'est pas entièrement traçable ?
Il existe également un problème structurel à aborder directement : Covenant-72B est open source sous licence Apache 2.0 et n'utilise pas le jeton SN3. La détention du jeton SN3 vous permet de partager les revenus provenant de l'émission générée par la production continue de nouveaux modèles sur ce sous-réseau, et non des revenus directs liés à l'utilisation du modèle. Cette chaîne de valeur repose sur la production continue d'entraînements et sur le bon fonctionnement du mécanisme d'émission global du réseau Bittensor. Si les entraînements s'arrêtent à l'avenir, ou si la qualité des nouveaux résultats d'entraînement ne répond pas aux attentes, la logique d'évaluation du jeton sera affaiblie.
Lister ces questions ne vise pas à nier l'importance de Covenant-72B. Le fait qu'il ait accompli ce qui était autrefois considéré comme impossible ne disparaîtra pas. Mais accomplir quelque chose, et ce que cela signifie, sont deux choses différentes.
Le token SN3 a augmenté de 440 % au cours du dernier mois. Cette écart pourrait ne pas être dû uniquement à la spéculation, mais plutôt au fait que les récits avancent toujours plus vite que la réalité. Que cet écart soit comblé par la réalité ou absorbé par le marché dépendra de ce que l'équipe de Covenant AI présentera désormais.
Il est à noter que Grayscale a déposé une demande d'ETF TAO en janvier 2026, ce qui indique un signal d'entrée des capitaux institutionnels sur ce segment. De plus, le 25 décembre 2025, Bittensor a réduit de moitié l'émission quotidienne de TAO, ce qui amplifie encore la contraction structurelle de l'offre.
Lien de référence :
https://arxiv.org/pdf/2603.08163
https://importai.substack.com/p/importai-449-llms-training-other
https://docs.tplr.ai/
https://systems-analysis.ru/int/MMLU_Benchmark_%E2%80%94_MMLU_%E5%9F%BA%E5%87%86%E6%B5%8B%E8%AF%95