









Alors que les particuliers s'efforcent encore de maîtriser les « incantations de prompts les plus puissantes », les laboratoires de pointe de la Silicon Valley ont transformé l'infrastructure IA en une chaîne de production.
Auteur et source de l'article : XinZhiYuan
Vous êtes encore en train de répéter les prompts dans la fenêtre de discussion de ChatGPT ?
Récemment, un utilisateur X a publié un tweet commençant par une exclamation : Le modèle de projet Claude Code utilisé en secret par les géants du secteur a été divulgué !
Ce n'est plus de l'écriture de prompts. C'est l'infrastructure d'ingénierie de l'IA.

L'ensemble de la stratégie est basé sur un fichier « CLAUDE.md », dont les principes fondamentaux ne sont que trois :
Chaque fois que Claude fait une erreur → vous ajoutez une règle ; chaque fois que vous vous répétez → vous ajoutez un flux de travail ; chaque fois qu'un bug apparaît → vous ajoutez une barrière de sécurité.

Faire cela permet de transformer l'expérience du projet en un contexte persistant et des contraintes automatisées que le système lit à chaque démarrage.
L'architecture entière, comme la structure des postes dans une entreprise d'IA : CLAUDE.md est le manuel d'intégration, skills/ est le SOP opérationnel, hooks/ est le département de conformité, docs/ est les statuts de l'entreprise, tools/ est l'équipe logistique, src/ est le département opérationnel véritablement productif.

Vous n'êtes plus en train de discuter avec une IA, mais en train de construire une IA qui comprend votre dépôt de code.
La partie la plus folle est que vous n'avez besoin de le configurer qu'une seule fois ; Claude examinera automatiquement le code, le restructurera selon les instructions, appliquera les règles d'architecture, rédigera les notes de version, exécutera des workflows à partir des compétences et se souviendra des erreurs passées.
Et il deviendra de plus en plus intelligent avec l'usage.
La plupart des gens ouvrent ChatGPT, écrivent un prompt, copient-collent, et répètent ; avec cette approche, vous n'avez qu'à ouvrir le terminal et exécuter un code skill déjà livré.
C'est comme avoir une équipe de collègues IA dans votre propre bibliothèque de code.
Derrière ce tweet se cache un petit signe que cette ère est en train de tourner la page, un changement dont la plupart des gens ne se sont pas encore rendu compte.
Une « capture d’écran fuitée » qui n’est pas vraiment une fuite dévoile une vérité
La capture d'écran présentée par @ai_rohitt est le modèle standard recommandé publiquement dans la documentation officielle d'Anthropic pour Claude Code.
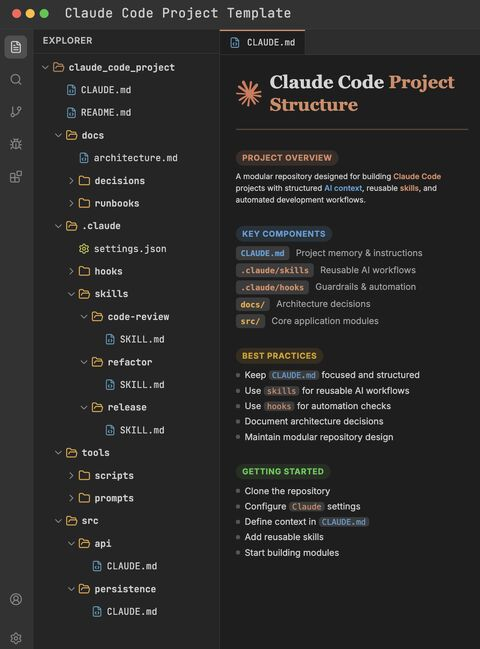
CLAUDE.md est le fichier de mémoire du projet lu automatiquement par Claude Code au début de chaque session.
.claude/skills/ et .claude/hooks/ sont des mécanismes d'extension pris en charge officiellement.
Ce sont des pratiques publiques déjà discutées par la communauté depuis plusieurs mois, et non un « modèle interne » volé par quelqu'un.
Mais le fait qu'il ait été partagé activement par certains développeurs chevronnés indique qu'il a reçu l'approbation de développeurs qui utilisent Claude quotidiennement.
Une bonne partie d'entre eux n'ont peut-être réalisé ces derniers jours qu'il pouvait être utilisé de cette manière.
Et l'équipe de premier plan de la Silicon Valley a déjà transformé cela en une chaîne de production.
Le premier exemple est l'équipe OpenAI Frontier.
Dans les expériences du groupe Frontier divulguées par OpenAI, une version bêta interne démarrant à partir d'un dépôt vide a généré environ 1 million de lignes de code et environ 1 500 demandes de tirage (PR) en environ cinq mois par Codex ; l'équipe est passée de 3 à 7 personnes, sans écriture directe de code par des humains.
Ryan Lopopolo, le chef de l'équipe, a ajouté lors d'un entretien ultérieur que ce flux de travail approchait la forme limite de « 0 code manuel, 0 revue manuelle ».
Il pense qu'il vaut mieux exploiter la capacité de parallélisme extrêmement élevée et le coût extrêmement faible du modèle que de chercher à économiser des tokens, afin de remplacer l'attention synchrone limitée et coûteuse des humains.
Le deuxième exemple est le système d'agent d'automatisation interne de Stripe, Minions.
Les Minions au sein de Stripe génèrent et poussent plus de 1 300 PR par semaine, entièrement créés par l'IA, mais toujours soumis à une revue humaine.
Voici une autre paire de données : 1,6 % contre 98,4 %, issue d’un article publié par le VILA-Lab de l’Université Mohamed bin Zayed pour l’IA.

https://arxiv.org/pdf/2604.14228
Les chercheurs ont analysé de manière systématique les 512 000 lignes de code source TypeScript de la version Claude Code v2.1.88 et ont conclu que seuls 1,6 % correspondaient à la logique de décision de l'IA, les 98,4 % restants étant des infrastructures logicielles déterministes.
Plus précisément, il s'agit de quatre catégories : passerelle d'autorisation, gestion du contexte, routage des outils et récupération d'erreurs.
Ces chiffres ne signifient pas que le modèle ne contribue que 1,6 % de capacité, mais qu’en tant que produit, Claude Code présente une grande partie de sa complexité non pas dans le modèle lui-même, mais dans les infrastructures d’ingénierie déterministes telles que les autorisations, le contexte, le routage des outils et les mécanismes de récupération.
La structure CLAUDE.md/skills/hooks sur cette image constitue une « infrastructure de base pour débutants » que n'importe quel développeur peut mettre en place ; elle suit le même modèle que l'architecture de production d'OpenAI et de Stripe, mais à une échelle bien plus réduite.
Les secrets révélés par CLAUDE.md
Au cours des trois dernières années, tout le monde se demandait : « Quand GPT deviendra-t-il plus intelligent ? » et « Quand sortira la nouvelle version de Claude ? »
Mais les équipes qui mettent réellement en production la programmation par IA s’intéressent probablement bien moins à cela, et se concentrent plutôt sur la manière d’aider l’IA à se souvenir des erreurs passées, à consulter les contraintes d’architecture du projet avant de commencer, et à ce que les erreurs de l’IA soient bloquées automatiquement par les outils.
CLAUDE.md est le support exact de tout cela.
La définition officielle d'Anthropic ne comporte qu'une seule phrase :
Un fichier Markdown placé à la racine du projet, lu automatiquement par Claude Code au début de chaque session.

https://code.claude.com/docs/en/memory
Cela semble simple, mais ce sont les plusieurs couches qui l'entourent qui en font sa véritable force.
CLAUDE.md est le cerveau du projet.
Décisions d’architecture, conventions de nommage, exigences de test, les pièges récurrents — tout est regroupé ici. C’est le « manuel de l’employé » que l’IA voit en premier à chaque démarrage.
.claude/skills/ sont des flux de travail réutilisables.
Boris Cherny, le créateur de Claude Code, répète régulièrement dans la communauté : « Si vous faites quelque chose plus d'une fois par jour, transformez-le en compétence ou en commande. »
Une skill est une méthode exécutable. Le code review, la génération de messages de commit et la rédaction de notes de version ne devraient pas être des tâches effectuées à la main chaque jour avec des prompts, mais plutôt des actions déclenchées par une skill pour obtenir des résultats immédiats.
.claude/hooks/ est une barrière automatique.
C'est la partie la plus cruciale. Il ne repose pas sur le jugement autonome de l'IA, mais sur un code déterministe qui bloque l'IA avant qu'elle ne commette une erreur. C'est pourquoi on peut laisser l'IA fonctionner « sans supervision » : les limites d'erreur sont bloquées par des hooks.
docs/decisions/ est un enregistrement des décisions d'architecture.
Faites en sorte que l'IA ne se contente pas de savoir ce que le code « est », mais aussi pourquoi il est « comme ça ».
C'est le point le plus souvent négligé, mais aussi le levier le plus puissant de la collaboration avec l'IA.
tools/ et src/ sont des couches d'exécution.
Ce qui est vraiment remarquable dans cette architecture, ce n'est pas qu'un développeur ait créé un répertoire élégant, mais que de plus en plus d'équipes indépendantes convergent vers la même approche : intégrer les modèles dans un cadre composé de contexte, d'outils, de permissions, d'évaluations et de boucles de rétroaction.
On peut déjà voir de nombreux projets similaires sur GitHub :
awesome-claude-code-toolkit de rohitg00, claude-code-infrastructure-showcase de diet103 et everything-claude-code d'affaan-m construisent tous un environnement de travail engineering pour Claude Code autour des composants agents, skills, hooks, rules et MCP configs.
Cela signifie qu'un flux de travail d'ingénierie IA véritablement mature ne repose pas uniquement sur un modèle plus puissant, ni uniquement sur une invite plus longue, mais intègre le modèle dans un système d'ingénierie réutilisable, contrôlable, réversible et auditables.
En ce qui concerne la structure des répertoires exacte, les implémentations varient selon les entreprises.
L'expérience limite du laboratoire OpenAI
Le 11 février 2026, le blog officiel d'OpenAI a publié un article : « Harness engineering: leveraging Codex in an agent-first world ».

https://openai.com/index/harness-engineering/
Anthropic a révisé l'architecture de Claude Code autour de ce concept ; le site de Martin Fowler l'a résumé dans une formule : « Agent = Model + Harness. »
Le mot "harness" provient de l'équitation. Il désigne l'ensemble de l'attelage d'un cheval : les rênes, le mors, la selle, la bride.
Un cheval peut courir vite et avec force, mais il ne sait pas où aller : tout l'attelage détermine sa direction.
Comparaison avec la programmation IA : le modèle lui-même est très puissant, mais il ne sait pas où aller dans votre base de code. Harness est le volant, les freins et le système de navigation que vous lui avez créés.
L'expérience de l'équipe Frontier d'OpenAI, « 1 million de lignes sans intervention humaine », revient fondamentalement à pousser Harness à son extrême.
Leurs pratiques d'ingénierie clés incluent les éléments suivants.
Contrainte forte de l'architecture hiérarchique.
De Types à Config, puis à Repo, Service, Runtime et UI, les dépendances circulent dans un seul sens, et cette règle est appliquée par un linter au niveau CI. Si un agent écrit du code violant la hiérarchie, la construction échoue directement.
Les messages d'erreur de linter sont eux-mêmes des instructions de correction, ce qui est le détail le plus contre-intuitif.
Les erreurs de lint des projets ordinaires sont « violation detected », destinées aux humains ; les erreurs de lint d'OpenAI Frontier sont « utilisez logger.info({event: 'name', …data}) au lieu de console.log », des instructions destinées aux agents, directement lisibles et réparables.
Le document sert de source unique de vérité. Tous les schémas d'architecture, les plans d'exécution et les spécifications de conception se trouvent dans le répertoire docs/ du dépôt. L'agent n'a besoin d'aucune base de connaissances externe ; tout est dans le dépôt.
À quel point ce système est-il efficace ?
Le modèle n'a pas changé, mais LangChain a ajusté le harnais, incluant les invites système, les outils, le middleware et le mode d'inférence, augmentant ainsi le score Terminal Bench 2.0 de 52,8 à 66,5.
Ce que vous pouvez faire aujourd'hui
Créer un cerveau de projet pour l'IA
La question revient aux développeurs ordinaires : si le paradigme a déjà changé, qu’est-ce qu’un ingénieur ordinaire peut faire dès aujourd’hui ?
La première chose à faire est de créer un fichier CLAUDE.md dans le répertoire racine de votre projet le plus important.
Pas besoin d’être parfait ni long. Écrivez les règles d’architecture de votre équipe, les conventions de nommage, les exigences de test, les erreurs récurrentes — une version fonctionnelle en 10 minutes.
La prochaine fois que l'IA fait une erreur, ne corrigez pas manuellement, mais demandez-vous : qu'est-ce qui manque dans CLAUDE.md ?
Deuxièmement, transformez les tâches répétées quotidiennement en compétences.
Faites attention à la citation de Boris Cherny : « Si vous faites quelque chose plus d'une fois par jour, transformez-le en compétence ou en commande. »
La revue de code, la génération de messages de commit, la rédaction de notes de version, la correction de bugs répétitifs : ce sont des compétences, pas des instructions à taper manuellement chaque jour.
Troisième chose, ajoutez un hook aux endroits où il est facile de tomber dans un piège.
Hook est la partie la plus levée des 98,4 %. Il ne dépend pas de l'IA pour devenir intelligent ; il repose sur du code déterministe pour imposer des vérifications. C'est le processus de traduction du jugement des ingénieurs humains en contraintes lisibles par la machine.
L'essentiel de cette affaire n'est pas d'écrire du code, mais de rédiger des règles.
La phrase de Karpathy partagée largement sur Twitter en janvier de cette année : « J'ai passé de 80 % de code écrit à la main à 80 % délégué aux agents. »
Au cours des cinq prochaines années, la courbe des compétences des ingénieurs évolue de « combien de lignes de code puis-je écrire » vers « à quel point je peux concevoir un environnement de travail rigoureux pour l’IA ».
Le travail de programmation est en cours d'assumption par des agents.
Mais concevoir le monde dans lequel l'agent peut écrire un bon code, c'est encore le travail de l'homme. Et c'est plus difficile, plus important et plus intéressant qu'avant.