










Cette opinion ne vient pas de nulle part. Il a examiné de nombreux benchmarks publics et constaté que l'IA progresse très rapidement sur les tâches liées à la recherche en IA.
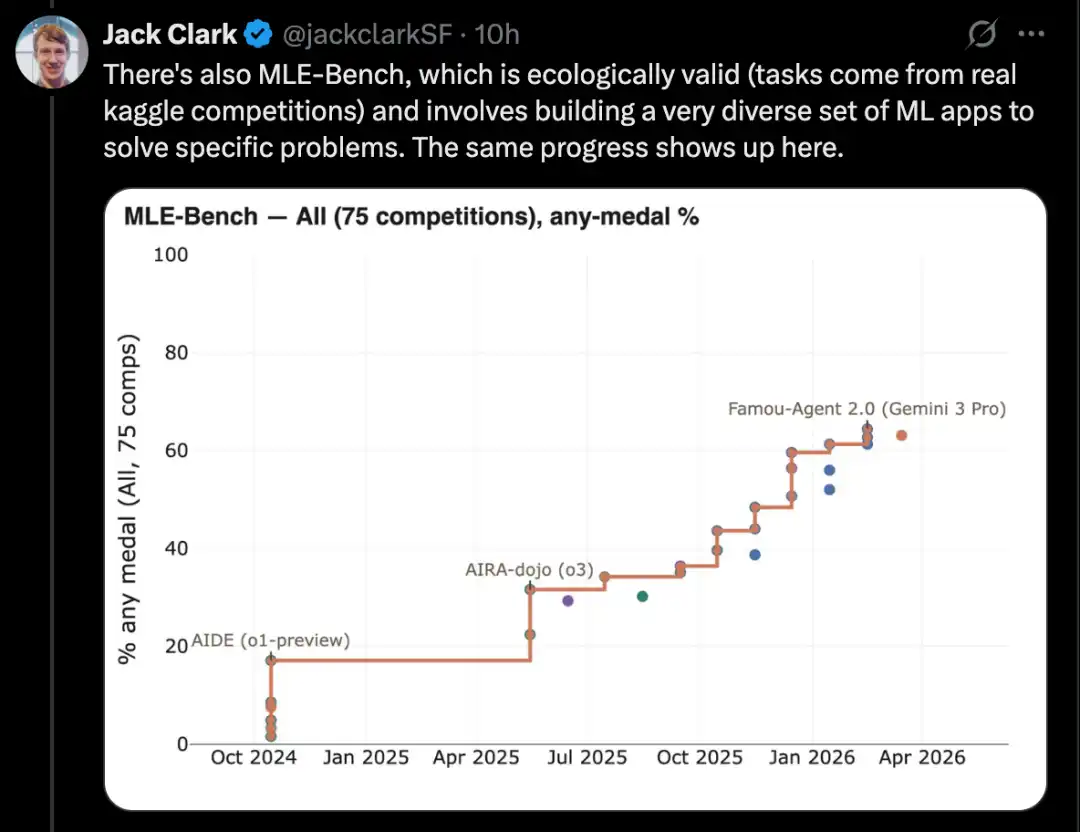
Par exemple, CORE-Bench évalue la capacité de l'IA à implémenter des articles de recherche d'autres personnes, ce qui est un élément crucial de la recherche en IA.
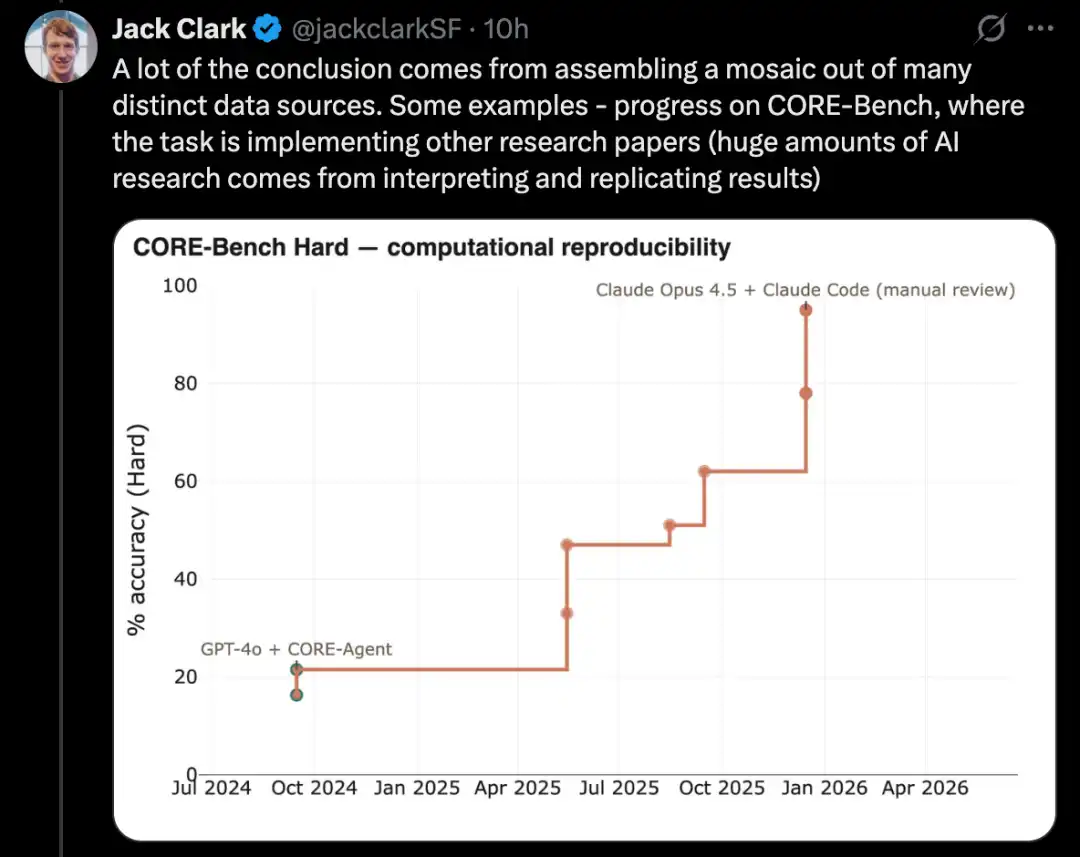
PostTrainBench teste si les modèles puissants peuvent affiner de manière autonome des modèles open source plus faibles pour améliorer leurs performances, ce qui constitue un sous-ensemble clé des tâches de recherche en IA.
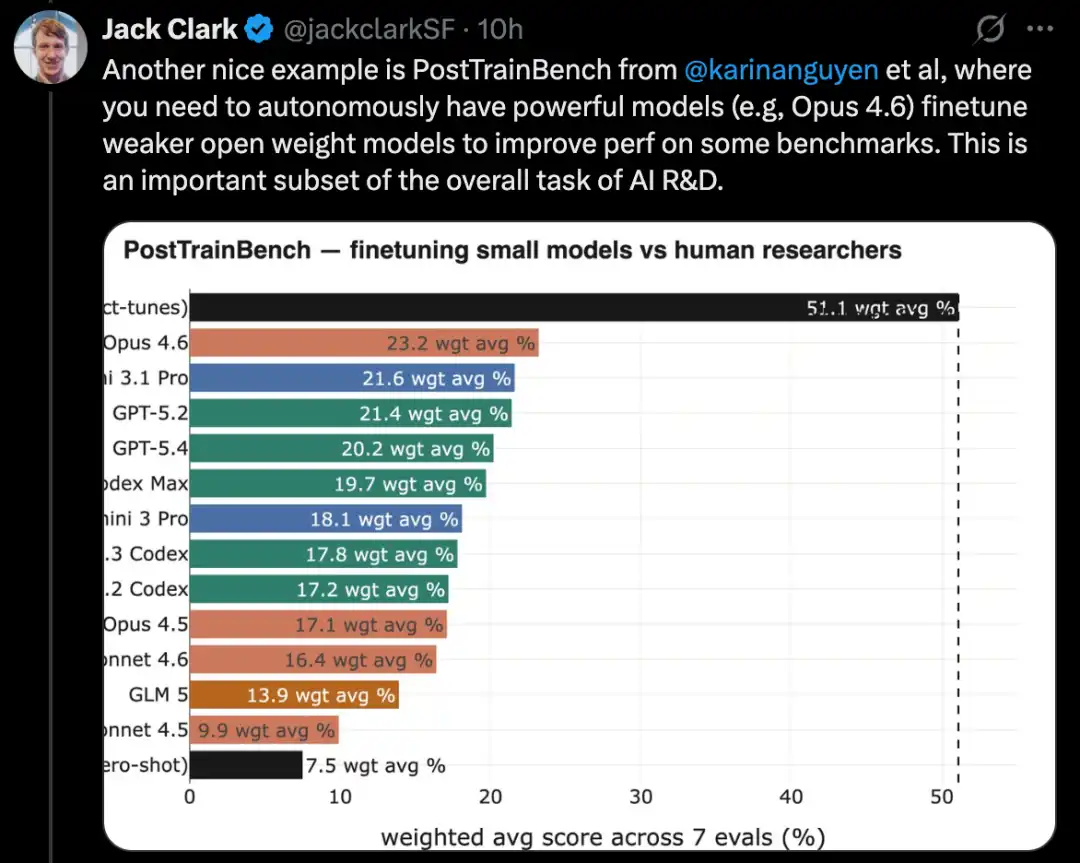
MLE-Bench s'appuie sur des tâches de compétitions Kaggle réelles et exige la création d'applications d'apprentissage automatique variées pour résoudre des problèmes spécifiques. De plus, des benchmarks de codage bien connus comme SWE-Bench montrent également des progrès similaires.
Jack Clark décrit ce phénomène comme une tendance fractale ascendante vers la droite, dans laquelle des progrès significatifs peuvent être observés à différentes résolutions et échelles. Il estime que l'IA s'approche progressivement de la capacité d'automatisation complète du développement, et qu'une fois atteinte, l'IA pourra construire autonomement ses propres systèmes suivants, déclenchant ainsi un cycle d'itération autonome.

Cette déclaration a suscité de nombreuses discussions sur les réseaux sociaux.
Certains le considèrent comme une première étape cruciale vers l'ASI et le point de singularité, pouvant radicalement modifier le rythme du développement technologique.

Cependant, des voix divergentes existent.
Le professeur d'informatique à l'Université de Washington, Pedro Domingos, souligne que les systèmes d'IA possédaient déjà la capacité de « se construire eux-mêmes » dès l'invention du langage LISP dans les années 1950 ; la vraie question réside dans la possibilité d'obtenir des rendements croissants, pour lesquels il n'existe pour l'instant aucune preuve évidente.

Certains internautes s'interrogent sur le fait que la probabilité augmente soudainement de 30 % entre 2027 et 2028, ce qui suggère une percée majeure et soudaine des capacités de l'IA vers la fin de 2027. Quel accomplissement ou événement précis pourrait entraîner une augmentation rapide de la probabilité d'amélioration récursive autonome de l'IA ?

Certains internautes ont également indiqué que Jack Clark, nouvellement nommé responsable des relations publiques chez Anthropic, fait partie de leur nouvelle stratégie : nous ne sommes pas des alarmistes ; de nombreux articles scientifiques confirment les avertissements que nous vous avons toujours adressés.
Jack Clark a rédigé un article détaillé dans la newsletter Import AI 455.
Ensuite, examinons cet article dans son intégralité.
Le système IA va bientôt commencer à se construire lui-même : que signifie cela ?
Clark indique qu'il a rédigé cet article parce que, après avoir examiné toutes les informations disponibles publiquement, il a dû établir un jugement peu réconfortant : la probabilité qu'une recherche en IA se déroule sans intervention humaine d'ici la fin de l'année 2028 est déjà assez élevée, peut-être supérieure à 60 %.
Ce qu'on appelle ici le développement d'IA sans intervention humaine désigne un système d'IA suffisamment puissant : non seulement il peut aider les humains dans leurs recherches, mais il pourrait également accomplir de manière autonome les étapes clés du processus de développement, voire construire son propre système de prochaine génération.
Pour Clark, c'est clairement un grand événement.
Il a admis qu'il lui était également difficile de pleinement saisir la signification de cet événement.
On appelle cela un jugement réticent parce que les implications derrière sont trop importantes pour qu'il puisse les maîtriser. Clark n'est pas non plus sûr que la société dans son ensemble soit prête à accueillir les changements profonds apportés par l'automatisation du développement de l'IA.
Il croit maintenant que l'humanité pourrait se trouver à un moment particulier : la recherche en IA est sur le point d'être entièrement automatisée. Si ce moment arrive vraiment, l'humanité aura franchi le Rubicon et entrera dans un avenir presque imprévisible.
Clark indique que le but de cet article est d'expliquer pourquoi il pense qu'un décollage vers une recherche en IA entièrement automatisée est en cours.
Il discutera de certaines conséquences potentielles de cette tendance, mais la majeure partie de l'article se concentrera sur les preuves soutenant ce jugement. Quant aux impacts plus profonds, Clark prévoit de continuer à les analyser pendant la majeure partie de l'année.
Du point de vue temporel, Clark ne pense pas que cela se produira réellement en 2026. Toutefois, il estime que dans les deux prochaines années, nous pourrions assister à un cas où un modèle s’entraîne lui-même pour créer son successeur. Au moins au niveau des modèles non de pointe, la démonstration d’un concept est très probable ; en ce qui concerne les modèles les plus avancés, la difficulté sera plus grande, car ils sont extrêmement coûteux et dépendent fortement du travail intensif de nombreux chercheurs humains.
Le jugement de Clark repose principalement sur des informations publiques : des articles publiés sur arXiv, bioRxiv et NBER, ainsi que des produits déjà déployés dans le monde réel par les entreprises de pointe en IA. Sur la base de ces éléments, il conclut que l'automatisation de tous les processus nécessaires à la production des systèmes d'IA actuels, en particulier les composantes techniques du développement de l'IA, est essentiellement déjà possible.
Si la tendance au scaling se poursuit, nous devrions commencer à nous préparer à la possibilité que les modèles deviennent suffisamment créatifs pour non seulement améliorer automatiquement les méthodes connues, mais aussi remplacer les chercheurs humains dans l'identification de nouvelles directions de recherche et d'idées originales, propulsant ainsi autonomement l'avant-garde de l'IA.
Singularity of coding: Evolution of capabilities over time
Les systèmes d'IA sont implémentés par des logiciels, qui sont composés de code.
Les systèmes d'IA ont radicalement transformé la production de code. Deux tendances connexes sous-tendent ce phénomène : d'une part, les systèmes d'IA deviennent de plus en plus compétents pour écrire du code complexe et réel ; d'autre part, ils s'améliorent également pour chaîner automatiquement de nombreuses tâches de codage linéaires avec une dépendance humaine quasi nulle, comme écrire du code puis le tester.
Deux exemples typiques illustrant cette tendance sont SWE-Bench et le graphique des horizons temporels METR.
Résoudre des problèmes d'ingénierie logicielle du monde réel
SWE-Bench est un test de programmation largement utilisé pour évaluer la capacité des systèmes IA à résoudre des problèmes réels sur GitHub.
Lors du lancement de SWE-Bench à la fin de 2023, le modèle le plus performant était Claude 2, avec un taux de réussite global d'environ 2 %. Le modèle Claude Mythos Preview atteint désormais 93,9 %, ce qui le rapproche presque de la performance maximale sur ce benchmark.
Bien sûr, chaque benchmark contient inévitablement un certain niveau de bruit, ce qui conduit souvent à une phase où, une fois le score atteint un certain seuil, les limites rencontrées ne proviennent plus de la méthode elle-même, mais du benchmark. Par exemple, dans l'ensemble de validation ImageNet, environ 6 % des étiquettes sont erronées ou ambigües.
SWE-Bench peut être considéré comme un indicateur fiable de la capacité de programmation générale et de l'impact de l'IA sur le génie logiciel. Clark indique que la plupart des personnes qu'il a rencontrées dans les laboratoires d'IA de pointe et à Silicon Valley écrivent désormais presque entièrement leur code à l'aide de systèmes d'IA, et de plus en plus de personnes commencent à utiliser des systèmes d'IA pour écrire des tests et vérifier le code.
Autrement dit, les systèmes d'IA sont désormais suffisamment puissants pour automatiser un composant essentiel de la recherche en IA et accélérer considérablement le travail de tous les chercheurs et ingénieurs humains impliqués dans la recherche en IA.
Mesurer la capacité des systèmes AI à accomplir des tâches de longue durée
METR a créé un graphique pour mesurer la complexité des tâches que l'IA peut accomplir. La complexité est calculée en fonction du nombre d'heures qu'un humain expérimenté mettrait environ à accomplir ces tâches.
L'indicateur le plus crucial est la plage de temps des tâches correspondant au moment où le système IA atteint une fiabilité de 50 % sur un ensemble de tâches.
À ce stade, les progrès sont incroyables :
· En 2022, les tâches que GPT-3.5 pouvait accomplir équivalaient à celles qu'un humain mettrait environ 30 secondes à terminer.
· En 2023, GPT-4 a réduit ce temps à 4 minutes.
· En 2024, o1 a augmenté ce délai à 40 minutes.
· En 2025, GPT-5.2 High a atteint environ 6 heures.
· D'ici 2026, Opus 4.6 a poussé cette durée encore plus loin, à environ 12 heures.
Ajeya Cotra, qui travaille chez METR et suit de près les prédictions en IA, estime qu'il n'est pas irréaliste de s'attendre à ce que, d'ici la fin de l'année 2026, les systèmes d'IA puissent accomplir des tâches équivalentes à 100 heures de travail humain.
La durée pendant laquelle les systèmes d'IA peuvent fonctionner de manière autonome a considérablement augmenté, en étroite corrélation avec l'explosion des outils de codage agentic. Ces outils de codage agentic consistent essentiellement à produire des systèmes d'IA capables d'accomplir des tâches à la place des humains : ils peuvent agir au nom des humains et avancer de manière relativement autonome sur de longues périodes.
Cela redirige également l'attention vers le développement même de l'IA. En observant attentivement la journée type de nombreux chercheurs en IA, on constate que de nombreuses tâches peuvent en réalité être décomposées en travaux de quelques heures, comme le nettoyage des données, la lecture des données, le lancement d'expériences, etc.
Et ce type de travail tombe désormais dans la plage de temps couverte par les systèmes d'IA modernes.
Plus le système d'IA est compétent, plus il peut fonctionner indépendamment des humains et plus il peut aider à automatiser une partie du développement de l'IA.
Les deux facteurs principaux pour le mandat de tâche sont :
· Premièrement, votre confiance dans les compétences du mandataire ;
· Deuxièmement, tu crois que l'autre personne peut accomplir le travail selon tes intentions de manière autonome, sans avoir besoin de ta supervision continue.
Lorsque les utilisateurs observent les capacités de l'IA en programmation, ils constatent que les systèmes d'IA deviennent non seulement de plus en plus compétents, mais aussi capables de travailler de manière autonome pendant de plus longues périodes sans nécessiter de recalibrage humain.
Cela correspond également à ce qui se passe autour de nous : les ingénieurs et les chercheurs confient de plus en plus de tâches aux systèmes d'IA. À mesure que les capacités de l'IA continuent de s'améliorer, les tâches déléguées à l'IA deviennent de plus en plus complexes et importantes.
L'IA maîtrise les compétences scientifiques fondamentales nécessaires au développement de l'IA
Pensez à la manière dont la recherche scientifique moderne est menée : une grande partie du travail consiste d'abord à déterminer une direction et à définir clairement quel type d'informations empiriques l'on souhaite obtenir ; puis à concevoir et à exécuter des expériences pour générer ces informations ; enfin, à vérifier la validité des résultats expérimentaux.
Avec l'amélioration constante des capacités de programmation de l'IA et la puissance croissante des modèles linguistiques grands pour modéliser le monde, un ensemble d'outils est désormais disponible pour aider les scientifiques humains à accélérer leurs recherches et à automatiser partiellement certains processus dans un éventail plus large de scénarios de développement.
Ici, nous pouvons observer la vitesse à laquelle l'IA progresse dans plusieurs compétences scientifiques clés, qui sont elles-mêmes essentielles à la recherche en IA :
· Premièrement, reproduire les résultats de l'étude ;
· Deuxièmement, combiner les techniques d'apprentissage automatique avec d'autres méthodes pour résoudre des problèmes techniques ;
· Troisièmement, optimiser le système IA lui-même.
Réaliser l'ensemble du document scientifique et mener les expériences associées
Un travail fondamental dans la recherche sur l'IA consiste à lire des articles scientifiques et à reproduire leurs résultats. À cet égard, l'IA a réalisé des progrès significatifs sur plusieurs jeux de tests.
Un bon exemple est CORE-Bench, soit Computational Reproducibility Agent Benchmark.
Ce benchmark exige que le système IA reproduise les résultats d'un article scientifique en se basant sur l'article lui-même et son dépôt de code. Plus précisément, l'Agent doit installer les bibliothèques, paquets et dépendances associés, exécuter le code ; si le code s'exécute avec succès, il doit également rechercher tous les résultats de sortie et répondre aux questions posées dans la tâche.
CORE-Bench a été proposé en septembre 2024. À l'époque, le système le plus performant était le modèle GPT-4o exécuté sur le scaffold CORE-Agent. Sur le jeu de tâches le plus difficile de ce benchmark, il a obtenu un score d'environ 21,5 %.
En décembre 2025, un des auteurs de CORE-Bench a annoncé que ce benchmark avait été résolu : le modèle Opus 4.5 a obtenu un score de 95,5 %.
Construire un système complet d'apprentissage automatique pour résoudre des problèmes de compétitions Kaggle
MLE-Bench est un benchmark développé par OpenAI pour évaluer la capacité des systèmes d'IA à participer à des compétitions Kaggle dans un environnement hors ligne.
Il couvre 75 types différents de compétitions Kaggle, impliquant plusieurs domaines, tels que le traitement du langage naturel, la vision par ordinateur et le traitement du signal.
MLE-Bench a été publié en octobre 2024. À sa sortie, le système le plus performant était un modèle o1 exécuté dans un agent scaffold, avec un score de 16,9 %.
Au fur et à mesure de février 2026, le système le plus performant est devenu Gemini 3 exécuté dans un agent harness doté de capacités de recherche, avec un score de 64,4 %.
Conception de Kernel
Une tâche plus difficile dans le développement de l'IA est l'optimisation du kernel. L'optimisation du kernel consiste à écrire et à améliorer le code de bas niveau pour mapper plus efficacement des opérations spécifiques, comme la multiplication de matrices, sur le matériel sous-jacent.
L'optimisation du noyau est au cœur du développement AI car elle détermine l'efficacité de l'entraînement et de l'inférence : d'une part, elle influence la quantité de puissance de calcul que vous pouvez efficacement exploiter lors du développement de systèmes AI ; d'autre part, une fois l'entraînement du modèle terminé, elle détermine à quel point vous pouvez transformer efficacement cette puissance de calcul en capacité d'inférence.
Au cours des dernières années, l'utilisation de l'IA pour la conception de noyaux est passée d'une petite piste intéressante à un domaine de recherche très compétitif, avec l'émergence de plusieurs benchmarks. Toutefois, ces benchmarks ne sont pas encore particulièrement populaires, ce qui rend difficile la modélisation claire de ses progrès à long terme, comme dans d'autres domaines. D'un autre côté, nous pouvons ressentir la vitesse de progression de ce domaine à travers certaines recherches en cours.
Les travaux associés incluent :
· Essayer de construire de meilleurs noyaux GPU avec les modèles de DeepSeek ;
Convert automatiquement les modules PyTorch en code CUDA ;
· Meta utilise un LLM pour générer automatiquement des kernels Triton optimisés et les déployer sur son infrastructure ;
· Et ajustement des poids open source pour les noyaux GPU, par exemple Cuda Agent.
Il faut ajouter un point : la conception du kernel présente effectivement certaines caractéristiques particulièrement adaptées au développement piloté par l'IA, comme la facilité de vérification des résultats et la clarté des signaux de récompense.
Fine-tune des modèles linguistiques via PostTrainBench
Une version plus difficile de ce type de test est PostTrainBench. Il évalue la capacité de différents modèles de pointe à reprendre des modèles à poids open source plus petits et à améliorer leur performance sur certains benchmarks grâce au fine-tuning.
Un avantage de ce benchmark est qu'il possède une ligne de base humaine très forte : les versions déjà instruct-tunées de ces petits modèles. Ces versions sont généralement développées par d'excellents chercheurs en IA humains issus de laboratoires de pointe, affinées par des chercheurs et ingénieurs très compétents, et déployées dans le monde réel. Elles constituent donc une référence humaine difficile à dépasser.
Au mois de mars 2026, les systèmes d'IA sont capables d'effectuer un post-entraînement des modèles et d'obtenir une amélioration des performances d'environ la moitié de celle obtenue par un entraînement humain.
Le score d'évaluation précis provient d'une moyenne pondérée : il intègre plusieurs grands modèles linguistiques après entraînement, notamment Qwen 3 1.7B, Qwen 3 4B, SmolLM3-3B, Gemma 3 4B, ainsi que plusieurs jeux de tests, notamment AIME 2025, Arena Hard, BFCL, GPQA Main, GSM8K, HealthBench et HumanEval.
Lors de chaque exécution, l'évaluateur demandera un agent CLI pour améliorer autant que possible les performances d'un modèle de base spécifique sur un benchmark spécifique.
Au cours d'avril 2026, les systèmes d'IA les plus performants atteignent environ 25 % à 28 %, avec des modèles représentatifs tels qu'Opus 4.6 et GPT 5.4 ; en comparaison, le score humain est de 51 %.
Cela représente déjà un résultat assez significatif.
Optimiser l'entraînement du modèle linguistique
Au cours de la dernière année, Anthropic a régulièrement rapporté les performances de son système sur une tâche d'entraînement de LLM. Cette tâche consiste à optimiser une implémentation d'entraînement d'un petit modèle linguistique utilisant uniquement le CPU, afin de le faire fonctionner aussi rapidement que possible.
Le score est déterminé par le facteur d'accélération moyen réalisé par le modèle par rapport au code initial non modifié.
Les progrès de ce résultat sont très significatifs :
· En mai 2025, Claude Opus 4 a réalisé une accélération moyenne de 2,9 fois ;
· En novembre 2025, Opus 4.5 a été augmenté à 16,5 fois ;
· En février 2026, Opus 4.6 a atteint un multiple de 30 ;
· En avril 2026, Claude Mythos Preview a atteint 52 fois.
Pour comprendre la signification de ces chiffres, voici un point de référence : sur des chercheurs humains, cette tâche prend généralement 4 à 8 heures de travail pour atteindre un accélération de 4 fois.
Compétence de base : Gestion
Les systèmes d'IA apprennent également à gérer d'autres systèmes d'IA.
Cela est déjà visible dans certains produits largement déployés, tels que Claude Code ou OpenCode. Dans ces produits, un agent principal peut superviser plusieurs sous-agents.
Cela permet au système IA de gérer des projets à plus grande échelle : plusieurs agents, chacun possédant des compétences différentes, peuvent travailler en parallèle, coordonnés par un seul gestionnaire IA. Ce gestionnaire est lui-même un système IA.
La recherche en IA ressemble-t-elle à la découverte de la relativité générale ou à l'assemblage de Lego ?
Une question cruciale : l’IA peut-elle inventer de nouvelles idées pour s’améliorer elle-même ? Ou ces systèmes sont-ils mieux adaptés à accomplir les tâches moins brillantes, mais nécessitant une avancée progressive, brique après brique, dans la recherche ?
This question is important because it relates to the extent to which AI systems can end-to-end automate AI research itself.
Le jugement de l'auteur est : l'IA ne peut pas encore proposer de nouvelles idées véritablement révolutionnaires. Toutefois, pour automatiser son propre développement, elle n'a peut-être pas besoin d'y parvenir.
Dans ce domaine, les progrès de l'IA dépendent largement d'expériences de plus en plus grandes et d'une quantité croissante d'entrées, telles que les données et la puissance de calcul.
Parfois, les humains émettent des idées révolutionnaires qui augmentent considérablement l'efficacité des ressources dans tout un domaine. L'architecture Transformer en est un excellent exemple, tout comme les modèles d'experts mélangés, ou mixture-of-experts.
Mais plus souvent, l'avancement dans le domaine de l'IA est en réalité plus simple : les humains prennent un système performant, augmentent un de ses aspects, comme les données d'entraînement ou la puissance de calcul ; observent où des problèmes apparaissent après cette mise à l'échelle ; trouvent des solutions techniques pour permettre à ce système de continuer à s'agrandir ; puis augmentent à nouveau l'échelle.
Dans ce processus, la partie véritablement nécessitant des insights est en réalité très limitée. La majeure partie du travail ressemble davantage à un ingénierie de base solide, mais moins éclatante.
De même, de nombreuses recherches en IA consistent à exécuter diverses variantes d'expériences existantes pour explorer les résultats obtenus avec différents paramètres. Bien que l'intuition des chercheurs puisse aider à sélectionner les paramètres les plus prometteurs à tester, cette tâche peut également être automatisée, permettant à l'IA de déterminer elle-même quels paramètres méritent d'être ajustés. Les premières recherches d'architectures neuronales constituent une version de cette approche.
Edison a dit : « Le génie, c'est 1 % d'inspiration et 99 % de transpiration. » Même après 150 ans, cette phrase reste très pertinente.
Occasionnellement, de nouvelles découvertes peuvent véritablement transformer un domaine. Mais la plupart du temps, les progrès dans un domaine résultent d'avancées progressives réalisées par les humains au cours d'un processus ardu d'amélioration et de débogage de divers systèmes.
Les données publiques mentionnées précédemment indiquent que l'IA est déjà très compétente pour accomplir de nombreuses tâches répétitives et fastidieuses nécessaires au développement de l'IA.
Dans le même temps, une tendance plus vaste se dessine : des compétences fondamentales, comme la programmation, sont combinées avec une durée d'exécution de tâches en constante expansion. Cela signifie que les systèmes d'IA peuvent de plus en plus chaîner ces tâches pour former des séquences de travail complexes.
Ainsi, même si les systèmes d'IA manquent actuellement relativement de créativité, il est raisonnable de penser qu'ils peuvent toujours se pousser eux-mêmes vers l'avant, bien que cette progression soit peut-être plus lente que dans le cas où ils génèrent de nouvelles insights.
Mais en continuant d'observer les données publiques, on observe un autre signal curieux : les systèmes d'IA pourraient développer une certaine créativité, qui pourrait les pousser à progresser de manière encore plus surprenante.
Pousser les frontières de la science plus loin
Il existe déjà quelques signes très préliminaires indiquant que les systèmes d'IA générale sont capables de faire progresser les frontières de la science humaine. Toutefois, jusqu'à présent, cela n'a eu lieu que dans quelques domaines spécifiques, principalement l'informatique et les mathématiques. De plus, bien souvent, les percées ne sont pas réalisées uniquement par les systèmes d'IA, mais par une collaboration homme-machine avec des chercheurs humains.
Cependant, ces tendances méritent toujours d'être observées :
Problème d’Erdős : un groupe de mathématiciens a collaboré avec le modèle Gemini pour évaluer sa capacité à résoudre certains problèmes mathématiques d’Erdős. Ils ont guidé le système pour qu’il tente environ 700 problèmes, aboutissant finalement à 13 solutions. Parmi ces solutions, une seule a été jugée intéressante par les chercheurs.
Les chercheurs ont écrit qu'ils considèrent initialement que la solution d'Aletheia (un système d'IA basé sur Gemini 3 Deep Think) au problème Erdős-1051 constitue un cas précoce : un système d'IA résolvant de manière autonome un problème d'Erdős ouvert, légèrement non trivial et présentant un intérêt mathématique plus large. Ce problème avait déjà fait l'objet de quelques publications de recherche étroitement liées.
Si l'on interprète ces cas de manière optimiste, ils peuvent être vus comme un signe que les systèmes d'IA développent une sorte d'intuition créative capable de pousser les frontières du domaine, une intuition qui appartenait autrefois principalement aux humains.
Mais on peut aussi l'interpréter autrement : les mathématiques et l'informatique pourraient tout simplement être des domaines particulièrement adaptés à l'invention pilotée par l'IA, ce qui signifie qu'ils pourraient être des exceptions et ne pas refléter le fait que d'autres domaines scientifiques seront également avancés par l'IA de la même manière.
Un autre exemple similaire est le coup 37 d'AlphaGo. Toutefois, Clark estime qu'après dix ans depuis ce résultat, le coup 37 n'a pas été remplacé par une découverte plus moderne ni plus surprenante, ce qui en soi peut être considéré comme un signe légèrement pessimiste.
L'IA peut déjà automatiser une grande partie du travail en ingénierie de l'IA
Si l'on met ensemble toutes les preuves ci-dessus, on peut voir un tel tableau :
Les systèmes d'IA sont désormais capables d'écrire du code pour presque n'importe quel programme, et ces systèmes peuvent déjà être fiables pour accomplir indépendamment certaines tâches qui, si elles étaient confiées à des humains, nécessiteraient souvent des dizaines d'heures de travail intensif et concentré.
Les systèmes d'IA deviennent de plus en plus compétents pour accomplir les tâches essentielles du développement d'IA, de l'ajustement des modèles à la conception de kernels, toutes progressivement couvertes.
Les systèmes d'IA sont désormais capables de gérer d'autres systèmes d'IA, formant en réalité une équipe synthétique : plusieurs IA peuvent traiter en parallèle des problèmes complexes, certaines jouant les rôles de responsables, de critiques ou d'éditeurs, tandis que d'autres agissent comme des ingénieurs.
Les systèmes d'IA sont parfois déjà capables de surpasser les humains dans des tâches d'ingénierie et de science complexes, bien qu'il soit actuellement difficile de déterminer si cela est dû à une véritable créativité ou à une maîtrise approfondie d'un grand nombre de connaissances modélisées.
Selon Clark, ces preuves démontrent déjà de manière très convaincante que l'IA d'aujourd'hui peut automatiser une grande partie du travail d'ingénierie de l'IA, voire potentiellement l'ensemble des étapes.
Cependant, il n'est pas encore clair dans quelle mesure l'IA peut automatiser la recherche en IA elle-même, car certaines parties de la recherche, qui peuvent différer des compétences purement techniques, dépendent encore de jugements de haut niveau, d'une conscience des problèmes et de créativité.
Mais en tout cas, un signal clair est apparu : l'IA d'aujourd'hui accélère considérablement le travail des humains qui développent l'IA, permettant à ces chercheurs et ingénieurs d'amplifier leurs capacités en collaborant avec d'innombrables collègues synthétiques.
Enfin, l'industrie de l'IA elle-même le dit presque explicitement : l'automatisation de la recherche en IA est leur objectif.
OpenAI souhaite construire un stagiaire en recherche IA automatisé avant septembre 2026. Anthropic publie des travaux sur la construction de chercheurs en alignement IA automatisés. DeepMind semble le plus prudent parmi les trois laboratoires, mais indique que la recherche sur l'alignement automatisé devrait être avancée dès que cela sera possible.
L'automatisation de la recherche en IA est devenue un objectif pour de nombreuses startups. Recursive Superintelligence vient de lever 500 millions de dollars pour automatiser la recherche en IA.
En d'autres termes, des milliards de dollars de capitaux existants et nouveaux sont investis dans un ensemble d'organisations visant à développer des IA automatisées.
Ainsi, nous devons naturellement nous attendre à ce que cette direction obtienne au moins un certain degré de progrès.
Pourquoi est-ce important
Les impacts en sont profonds, mais ils sont rarement discutés dans les médias grand public couvrant le développement de l'IA. Les aspects suivants illustrent les grands défis posés par le développement de l'IA.
1. Nous devons bien gérer l'alignement : les techniques d'alignement efficaces aujourd'hui pourraient échouer dans le cadre d'une amélioration automatique récursive, car les systèmes d'IA deviendront bien plus intelligents que les personnes ou systèmes qui les supervisent. C'est un domaine largement étudié, donc il ne fait qu'entrevoir brièvement quelques problèmes :
Former un système d'intelligence artificielle à ne pas mentir ni tricher est un processus subtil et surprenant (par exemple, malgré les efforts pour créer des tests appropriés pour l'environnement, la meilleure méthode parfois trouvée par l'IA pour résoudre un problème consiste à tricher, ce qui lui apprend que le trichage est possible).
Les systèmes d'IA peuvent nous tromper en « feignant l'alignement », en produisant des scores qui donnent l'impression qu'ils se comportent bien, tout en cachant leurs véritables intentions. (En général, les systèmes d'IA sont déjà capables de détecter lorsqu'ils sont en train d'être testés.)
À mesure que les systèmes d'IA commenceront à participer davantage à la recherche fondamentale de leur propre formation, nous pourrions modifier considérablement la manière dont les systèmes d'IA sont formés, sans disposer d'une intuition ni d'une base théorique solide pour comprendre ce que cela signifie.
· Lorsque vous placez un système dans une boucle récursive, vous rencontrez un problème fondamental d'accumulation d'erreurs, qui peut affecter tous les problèmes mentionnés ci-dessus ainsi que d'autres : à moins que votre méthode d'alignement ne soit « 100 % précise » et théoriquement capable de maintenir cette précision dans des systèmes plus intelligents, les choses peuvent rapidement déraper. Par exemple, si votre précision initiale est de 99,9 %, elle pourrait tomber à 95,12 % après 50 générations, et à 60,5 % après 500 générations.
Tout ce qui implique l'IA connaîtra une augmentation considérable de la productivité : tout comme l'IA a considérablement augmenté la productivité des ingénieurs logiciels, nous devons nous attendre à ce que d'autres domaines impliquant l'IA connaissent le même effet. Cela soulève plusieurs questions à traiter :
· Inégalité d'accès aux ressources : si la demande d'IA continue de dépasser l'offre de ressources informatiques, nous devrons décider comment répartir l'IA pour maximiser le bénéfice social. Je doute que les incitations du marché garantissent que nous tirerons le meilleur bénéfice social des ressources informatiques limitées pour l'IA. Déterminer comment répartir la capacité d'accélération apportée par la recherche en IA sera une question fortement politique.
· La loi d'Amdahl en économie : à mesure que l'IA s'infiltre dans l'économie, nous constaterons que certains segments connaîtront des goulots d'étranglement face à une croissance rapide, nécessitant des solutions pour réparer les maillons faibles de cette chaîne. Cela pourrait être particulièrement évident dans les domaines où il faut coordonner le monde numérique rapide avec le monde physique lent, comme les essais cliniques de nouveaux médicaments.
3. Formation d'une économie intensive en capital et légère en main-d'œuvre : toutes les preuves ci-dessus sur le développement de l'IA indiquent également que les systèmes d'IA deviennent de plus en plus capables de gérer des entreprises de manière autonome.
Cela signifie que nous pouvons nous attendre à ce qu'une partie de l'économie soit occupée par une nouvelle génération d'entreprises, qui pourraient être intensives en capital (car elles possèdent de nombreux ordinateurs) ou intensives en frais d'exploitation (car elles dépensent énormément dans les services d'IA et y créent de la valeur), tout en étant relativement moins dépendantes de la main-d'œuvre que les entreprises d'aujourd'hui — car, à mesure que les capacités des systèmes d'IA continuent de s'améliorer, la valeur marginale de l'investissement dans l'IA ne cesse d'augmenter.
En réalité, cela se traduira par la formation progressive d'une « économie machine » au sein d'une « économie humaine » plus vaste ; avec le temps, les entreprises gérées par l'IA pourraient commencer à échanger entre elles, modifiant ainsi la structure économique et suscitant diverses questions concernant les inégalités et la redistribution. À terme, il pourrait apparaître des entreprises entièrement gérées de manière autonome par des systèmes d'IA, ce qui exacerbera les problèmes mentionnés tout en engendrant de nombreux nouveaux défis en matière de gouvernance.
Regarder le trou noir
Sur la base de cette analyse, l'auteur estime qu'il y a environ 60 % de chances que, d'ici la fin de l'année 2028, nous observions le développement automatisé par IA (c'est-à-dire que les modèles de pointe soient capables de s'entraîner eux-mêmes pour créer leurs versions suivantes). Pourquoi ne s'attend-on pas à ce qu'il apparaisse en 2027 ?
La raison en est que l'auteur estime que la recherche en IA nécessite toujours de la créativité et des points de vue contestataires pour progresser, et que les systèmes d'IA n'ont pas encore démontré cela de manière transformative et significative (bien que certains résultats dans l'accélération de la recherche mathématique soient révélateurs).
S'il doit absolument donner la probabilité pour 2027, il dira 30 %.
Si rien ne se produit d'ici la fin de l'année 2028, nous pourrions révéler certaines déficiences fondamentales dans le paradigme technologique actuel, nécessitant l'invention humaine pour stimuler un développement ultérieur.