









Managsadula:Tina, Tung Mei,Impormasyon Q
1. Matapos ang higit sa tatlong taon, binuksan ni Musk muli ang algorithm ng X na nagrerekomenda
Kasalukuyan, inanunsiyo ng X engineering team sa pamamagitan ng isang post sa X na pormal na inilabas nila ang X recommendation algorithm sa open source. Ayon sa paliwanag, ang open source library na ito ay naglalaman ng core recommendation system na nagpapatakbo ng "For You" feed sa X. Ito ay nagkukombina ng on-platform content (mula sa mga account na sinusunod ng user) at off-platform content (natuklasan sa pamamagitan ng machine learning-based retrieval), at ginagamit ang Grok-based na Transformer model upang i-rank ang lahat ng content. Ibig sabihin, ang algoritmo ay gumagamit ng parehong Transformer architecture na ginagamit ng Grok.
Open Source Address: https://x.com/XEng/status/2013471689087086804
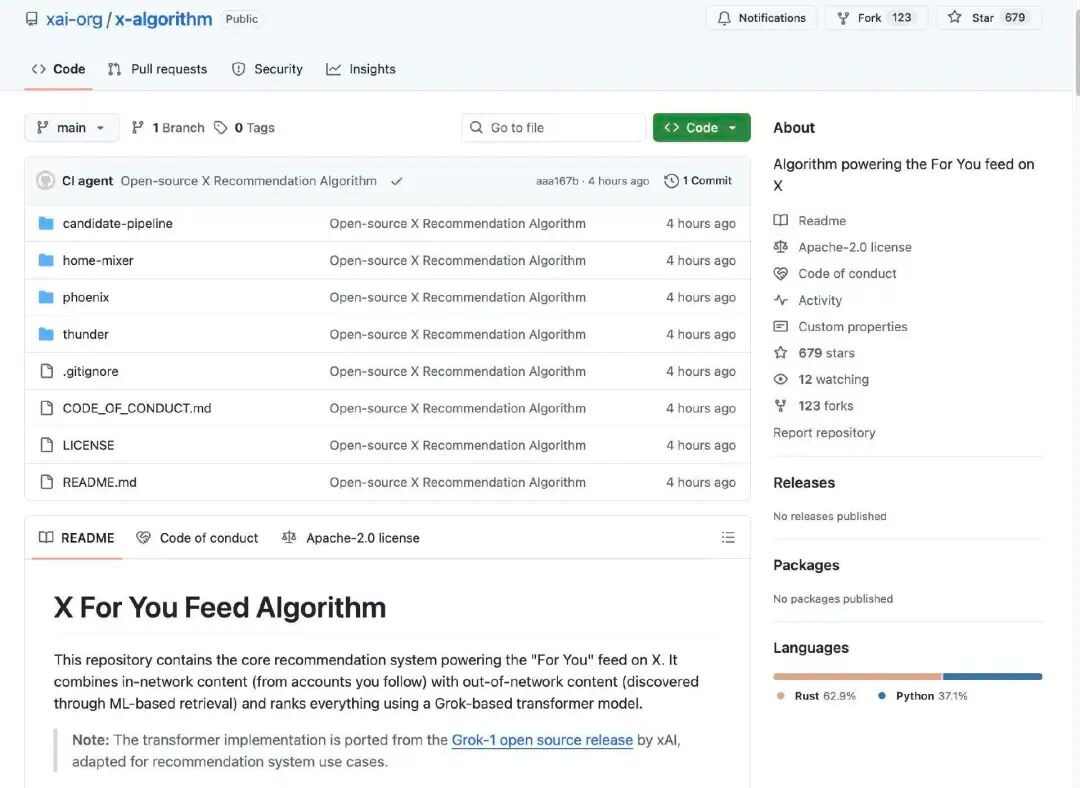
Ang algorithm ng rekomendasyon ng X ang nagpapagawa ng mga bagay na nakikita ng user sa pangunahing pahinaNilalaman ng "For You Feed"Nagmumula ito sa dalawang pangunahing pinagmulan ng mga kandidatong post:
Ang iyong sinusunod na account (In-Network / Thunder)
Mga iba pang post na natagpuan sa platform (Out-of-Network / Phoenix)
Ang mga ito ay pinag-uusapan, inilalagay sa loob ng isang hanay, at inaayos ayon sa kanilang kahalagahan.
Ano ang pangunahing istruktura at lohika ng pagpapatakbo nito?
Una ang algoritmo ay nagsisimula sa pagkuha ng mga potensyal na nilalaman mula sa dalawang uri ng mga pinagmulan:
Nilalaman ng iyong mga sumusunod: mga post na inilathala ng mga account kung saan ikaw ay nagsimulang sumunod.
Nakikitang Nilalaman: Ang mga post na maaaring interesado ka na inilalabas ng sistema mula sa buong database ng nilalaman.
Ang layunin ng yugtong ito ay "hahanapin ang mga post na maaaring kaugnay.
Ang sistema ay awtomatikong alisin ang mga low quality, duplicate, non-compliant, o hindi angkop na nilalaman. Halimbawa:
Nilalayong nilalaman ng account
I-identify ang mga paksa kung saan hindi interesado ang user
Ilegal, lumang o hindi balidong mga post
Ganito ay nagpapagawa ng seguridad na ang pagproseso ng mga halimbawa ng halaga ay nangyayari lamang sa wakas ng pagpapangkat.
Ang pangunahing bahagi ng algoritmo na inilabas na open source ay gumagamit ng isang Transformer model na batay sa Grok (katulad ng isang malaking modelo ng wika o isang network ng malalim na pagkatuto) upang magbigay ng marka sa bawat posibleng post. Ang Transformer model ay nagsusukat ng posibilidad ng bawat uri ng kilos batay sa nakaraang kilos ng user (tulad ng pagsigla, pagsumite ng tugon, pagpapalit ng post, pag-click atbp.). Sa huli, ang mga posibilidad ng kilos ay pinagsasama sa isang komprehensibong marka sa pamamagitan ng pagpapagana ng isang weighted combination. Ang mga post na may mataas na marka ay mas malamang na inirerekomenda sa user.
Ang disenyo na ito ay nagtatapon ng karaniwang paraan ng pagkuha ng mga katangian sa pamamagitan ng kamay, at nagpapalit sa isang paraan ng pag-aaral mula sa simula hanggang sa wakas upang masigla ang mga interes ng user.
Hindi ito ang una niyang ginawa na magbukas ng X recommendation algorithm.
Noong Marso 31, 2023, tulad ng pangako ni Musk nang kumuha siya ng Twitter, opsyonal na inilabas niya ang ilang mga code ng Twitter, kabilang ang algorithm na nagrerekomenda ng mga tweet sa timeline ng userNo opensource ang proyekto, 10k+ na stars ang natanggap nito sa GitHub.
Nangunguna, inilathala ni Musk sa Twitter ang paglabas ngayon ay"Karamihan sa mga rekomendasyon algorithm"Ang iba pang mga algorithm ay mananatili ring magagamit. Ang kanyang nais ay "ang mga third party na independiyente ay maaaring tumpak na masuri kung ano ang maaaring ipakita ng Twitter sa mga user."
Nan sa discussion sa Space tungkol sa paglabas han algorithm, nagsiring hiya nga an layo nga palatuhay amo an paghimo han Twitter nga "pinakatamnip nga system ha internet" ngan himuon ini nga maopay sugad han pinakakilala ngan pinakasikat nga open-source project nga Linux. "An pangunahing layo amo an pag-abiabi han mga user nga magpabilin ha Twitter nga makakabawbaw han pinakadaku nga kasiyahon didto," nagsiring hiya.
Naragaw na napalabas na higit sa tatlong taon kag nagpahayag si Musk ng X algorithm. At bilang isang super KOL sa teknolohiya, nagsimulang magtrabaho na si Musk para sa pagpapalaganap ngayon.
No Nobyembre 11, ginpost ni Musk sa X na babalewaray an bag-o X algorithm (kabahin an tanan code para maitutumbok kon ano nga natural nga mga panikat ngan advertisement an inirekumendar ha mga user) ha 7 ka adlaw.
Ito ay magkakaroon ng paulit-ulit na 4 linggo at may mga detalyadong paliwanag para sa mga developer upang tulungan ang mga user na maintindihan kung ano ang mga nangyari.
Nanampal nga ron an kanyan pangako.
2. Bakit nagmula sa open source ang Tesla?
Ang una'y reaksyon ng mga tao kapag binanggit ni Elon Musk ang "open source" ay hindi ang teknikal na idealismo kundi ang tunay na presyon.
Noong nakaraang taon, madalas na naging kontrobersiya ang X dahil sa kanyang mekanismo ng paghahatid ng nilalaman. Malawak itong kinritiko dahil sa pagmamalasakit at pagpapalakas ng mga kanan-pangunang pananaw sa antas ng algoritmo, at ang ganitong pagmamalasakit ay hindi lamang isang kakaibang kaso kundi itinuturing na mayroong sistema. Ang isang ulat na inilabas noong nakaraang taon ay nagpahayag na mayroon nang malinaw na bagong bias ang sistemang pagsusugan ng X sa paghahatid ng politikal na nilalaman.
Samantala, ang ilang ekstrem na kaso ay nagpapalakas pa ng mga katanungan mula sa labas. Noong nakaraang taon, isang walang pagsusuri na video na kinasasangkutan ng pagpatay kay Charlie Kirk, isang Amerikanong aktibista sa kanan, ay mabilis na umanib sa platform ng X, na nagdulot ng isang malaking alon ng reaksiyon mula sa publiko. Ang mga kritiko ay naniniwala na ito ay hindi lamang nagpapakita ng pagkabigo ng mekanismo ng pagsusuri ng platform, kundi pati na rin nagpapakita muli ng mga algoritmo kung ano ang "pinapalakas at hindi pinapalakas". Panginoon na hindi ipinapakita.
Sa ganitong panimula, mahirap isipin ng madali na ang biglaang pagsisikap ni Musk na magbigay ng kahalagahan sa transparency ng algorithm ay isang teknikal na desisyon lamang.

3. Ano ang opinyon ng iba pang netizen?
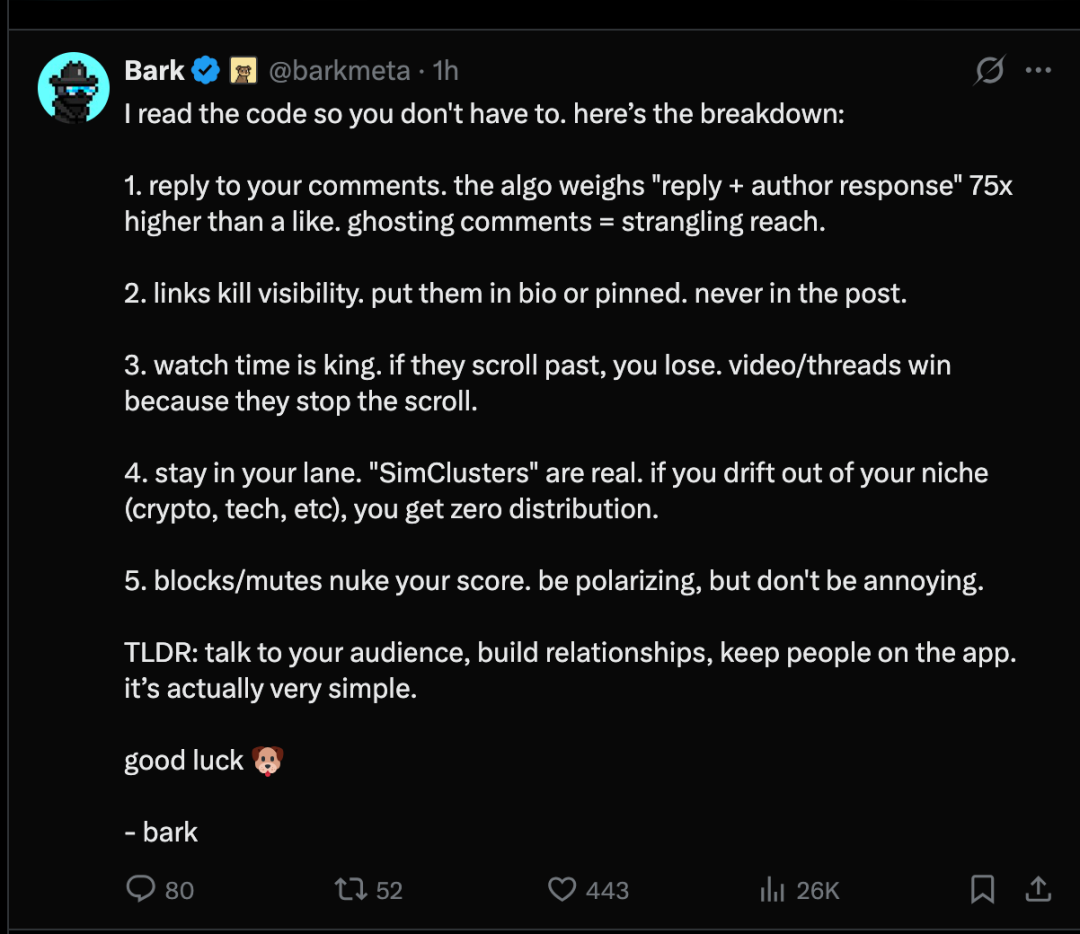
Matapos maging open source ang X recommendation algorithm, may mga user sa X platform na nagawa ang sumusunod na limang pangunahing obserbasyon tungkol sa mekanismo ng recommendation algorithm:
- Sagutin ang iyong komentoAng algorithm ay 75 beses mas mabigat para sa "reply + author response" kumpara sa mga like. Ang hindi pagbibigay ng tugon sa mga komento ay maaaring makasira ng malaki sa exposure.
- Nag-uusad an mga link ha pagbaba han eksponer.Ito ay dapat ilagay sa personal na profile o sa pinakaunang post, huwag maglagay ng link sa loob ng post.
- Mahalaga ang oras ng pagsusuriKung sila ay mag-slide at magbalewala, hindi ka sila makakahawakan. Ang mga video/post ay naging popular dahil sila ay nagpapahinto sa user.
- Panatilihin mo ang iyong teritoryo"Ang 'simulated cluster' ay totoo. Kung umalis ka sa iyong segment (crypto, tech, etc.), hindi ka makakakuha ng anumang channel ng distribusyon."
- Ang pag-block / pagiging tahimik ay maaaring maging sanhi ng malaking pagbagsak ng iyong puntos.Dapat magkaroon ng kontrobersya, ngunit huwag maging mapagmaliwanag.
Sa madaling salita: Mag-ugnay sa iyong mga taga-sakop, magtayo ng ugnayan, at panatilihin ang mga user sa loob ng app. Napakadali pala.
Nakita rin ng ilang netizen na kahit ang arkitektura ay open source, may ilang mga bahagi pa ring hindi open source. Ang netizen ay nagsabi na ang paglilipat na ito ay isang framework lamang at walang engine. Ano ang eksaktong nawawala?
Kulang ang parameter ng timbang Nagkakaroon ng "dagdag puntos para sa positibong gawain" at "bawas puntos para sa negatibong gawain" ang code, subalit sa 2023 na bersyon, ang mga eksaktong bilang ay inalis na.
Iyong mga modelo ng timbang - Ang mga parameter at kompyutasyon sa loob ng modelo ay hindi kasali.
Hindi pa inilabas na datos ng pagsasanay -Hindi namin alam ang tungkol sa data na ginamit para pagsanay sa modelo, ang paraan ng pagsusukat ng mga kilos ng user, at paano nilikha ang "mabuting" at "masamang" mga sample.
Para sa karaniwang mga user ng X, ang pagmamay-ari ng open-source algorithm ng X ay hindi magdudulot ng malaking epekto. Ngunit ang mas mataas na antas ng kahalumigmigan ay maaaring magpaliwanag kung bakit ang ilang mga post ay nakikita ng marami habang ang iba naman ay hindi, at nagbibigay ito ng kakayahang magawa ng mga mananaliksik na suriin kung paano ng platform iniraranggo ang mga nilalaman.
4. Bakit ang rekomendasyon system ay isang lugar ng kompetisyon?
Sa karamihan ng teknikal na talakayan,Rekomendasyon SystemKadalasan ito ay isinasaalang-alang bilang bahagi ng engineering sa likod ng mga proyekto, mababa ang profile, komplikado, at minsan ay hindi nasa ilalim ng ilaw. Ngunit kung talos-talos nating tingnan kung paano talagang gumagana ang negosyo ng mga internet giant, makikita natin na ang sistema ng rekomendasyon ay hindi isang marginal na bahagi, kundi isang "mga batayan ng infrastraktura" na sumusuporta sa buong modelo ng negosyo. Dahil dito, maaari itong tawaging "mangmang na leon" ng industriya ng internet.
Nagawa na ang publiko nga data. Ang Amazon nagsabi nga ang 35% ngadto ha iya plataporma nga mga pagbili diretso nga nangunguna ha rekomendasyon nga system; mas mapaspas an Netflix, 80% han oras han pagbili nga nangunguna ha rekomendasyon nga algoritmo; an sitwasyon han YouTube pareho gihapon, 70% han pagbili nga nangunguna ha rekomendasyon nga system, labi na an impormasyon nga padayon (feed). Kon ha Meta, bisan kon waray pa pirmi nga porsyento, an ira teknikal nga grupo nagsiring nga 80% han ira kompanyya nga kompyuter nga cluster nga mga oras nga ginagamit para ha serbisyo nga rekomendasyon nga mga buluhaton.
Ano ang kahulugan nito mga numero?Ang pagtanggal ng rekomendasyon system mula sa mga produktong ito ay halos katumbas ng pagtanggal ng pundasyon.Ang Meta naman ay isang halimbawa, ang pagpoposisyon ng advertisement, ang oras ng paggamit ng user, at ang komersyal na pagbabago ay halos nakasalalay sa rekomendasyon system. Ang rekomendasyon system ay hindi lamang nagsasaad kung ano ang "mababasa" ng user, kundi mas direktang nagsasaad kung paano "kikita" ang platform.
Ngunit ito man ay isang sistema na may desisyong buhay at kamatayan, na nagmumula sa mahabang panahon ng mga problema ng engineering na may mataas na antas ng kumplikado.
Sa tradisyonal na rekomendasyon system architecture, mahirap i-cover ang lahat ng mga senaryo gamit ang isang unified model. Ang mga aktwal na production system ay kadalasang sobrang fragmented. Gamit ang mga kumpaniya tulad ng Meta, LinkedIn, at Netflix bilang halimbawa, sa likod ng isang kumpletong rekomendasyon pipeline, kadalasang nagsisimula ng 30 o higit pang mga espesyalisadong modelo: retrieval model, coarse-ranking model, fine-ranking model, at reranking model, bawat isa ay ginagamit para sa iba't ibang layunin at business metrics. Sa likod ng bawat modelo, kadalasang mayroon isang o higit pang mga koponan na responsable para sa feature engineering, pagsasanay, parameter tuning, deployment, at patuloy na pagpapabuti.
Ang gastos ng ganitong paraan ay napakalaki: mahirap ang engineering, mataas ang gastos sa pangangalaga, at mahirap ang pagtutulungan sa pagitan ng iba't ibang gawain. Kapag may nagsabi na "Ano kung gagamitin natin ang isang modelo para sa maraming problema sa rekomendasyon?", ito ay nangangahulugan ng isang malaking pagbaba sa kumplikado ng buong sistema. Ito ang layunin ng industriya na nais nila ngunit mahirap sila gawin.
Ang paglitaw ng malalaking modelo ng wika ay nagbibigay ng isang bagong posibleng landas para sa mga system ng rekomendasyon.
Napag-isa na sa praktikal na paggamit ang LLM bilang isang napakalakas at pangkalahatang modelo: mayroon itong malakas na kakayahan sa paglipat mula sa iba't ibang mga gawain, at ang kanyang kahusayan ay patuloy na lumalago kasabay ng pagpapalawak ng data at computing power. Kaugnay nito, ang mga tradisyonal na modelo ng rekomendasyon ay kadalasang "task-specific" at mahirap magbahagi ng kakayahan sa iba't ibang mga senaryo.
Mas mahalaga, ang paggamit ng isang malaking modelo ay hindi lamang nagbibigay ng simpleng pagmamay-ari ng proyekto kundi mayroon din ito ng potensyal na "cross learning". Kapag ang parehong modelo ay nagpoproseso ng maraming mga gawain sa rekomendasyon, maaaring magkaroon ng pagtutuos ang mga signal mula sa iba't ibang gawain, at sa paglaki ng data, mas madali itong magiging buo. Ito ay isang katangian na nais ng mga sistema ng rekomendasyon ngunit mahirap itong makamit sa pamamagitan ng tradisyonal na paraan.
Ano ang binago ng LLM? Ang binago nito ay ang proseso mula sa feature engineering hanggang sa kakayahang maintindihan.
Mula sa pananaw ng metodolohiya, ang pinakamalaking pagbabago na idinulot ng LLM sa mga sistema ng rekomendasyon ay nangyari sa "feature engineering", ang pangunahing bahagi nito.
Sa tradisyonal na mga system ng rekomendasyon, kailangan ng mga engineer na manu-mano na lumikha ng maraming signal bago pa: kasaysayan ng pindot ng user, oras ng paghinto, mga paborito ng mga katulad na user, mga tag ng nilalaman, atbp., at pagkatapos ay bigyan ang modelo ng direktang utos na "piliin ang mga ito bilang batayan ng iyong desisyon". Ang modelo mismo ay hindi naiintindihan ang kahulugan ng mga signal na ito, at nag-aaral lamang ito ng mga relasyon ng pagmamapa sa loob ng isang numerical na espasyo.
Ang proseso ay naging mas abstract pagkatapos ipasok ang mga modelo ng wika. Hindi mo na kailangang magbigay ng mga indibidwal na utos tulad ng "tingnan ito at huwag pansinin ito," kundi maaari ka nang direktang ilarawan ang problema sa modelo: ito ay isang user, ito ay isang nilalaman; ang user na ito ay dati nang nagustuhan ng mga katulad na nilalaman, at ang iba pang mga user ay nagbigay ng positibong feedback sa nilalaman na ito - ngayon, mangyaring suriin kung dapat bang irekomenda ang nilalaman na ito sa user.
Ang mga modelo ng wika ay mayroon nang kakayahang maintindihan. Maaari nitong magawa kung ano ang mga mahahalagang mensahe at kung paano ito gagamitin upang gumawa ng desisyon. Sa ilang paraan, hindi lamang ito nagpapatupad ng mga alituntunin ng rekomendasyon kundi naiintindihan din nito ang "kung ano ang rekomendasyon".
Ang pinagmumulan ng kakayahang ito ay nasa pagkakaroon ng LLM ng access sa malawak at iba't ibang data habang pinapagana ito, kaya't mas madali nitong makuha ang mga subtil ngunit mahahalagang pattern. Kaugnay nito, ang mga tradisyonal na sistema ng rekomendasyon ay kailangang umasa sa mga engineer upang eksplisitong maglista ng mga pattern na ito, at kapag nawala ang isang pattern, hindi na makikilala ng modelo ang pattern na ito.
Mula sa pananaw ng backend, ang pagbabago na ito ay hindi bagong bagay. Tulad ng pagtatanong mo sa GPT, ito ay makagagawa ng isang tugon batay sa impormasyon ng konteksto; sa parehong paraan, kapag tinanong mo ito "sasang-ayon ako sa nilalaman na ito", maaari rin itong gumawa ng isang pagtataya batay sa umiiral na impormasyon. Sa ilang antas, ang kakayahang "irekumenda" ay mayroon nang natural na kakayahan ang modelo ng wika.