










Isipin ang isang skena:
Inilabas mo ang AI Agent para tulungan kang ayusin ang isang bug sa code. Binuksan nito ang project, binasa ang 20 na file, ginawa ang ilang pagbabago, pinagana ang mga pagsubok, hindi nakapasa, muli itong inayos, muli itong pinagana—patuloy na isinagawa ang mga ito sa higit sa sampung beses, at sa wakas—hindi pa rin ito naayos.
Ipinatong mo ang computer at huminga ng malalim. Pagkatapos, natanggap mo ang API na taksil.
Ang mga numero sa itaas ay maaaring magdulot ng paghinga ng malalim—ang pag-ayos ng bug ng AI Agent sa ilalim ng opisyal na API sa abroad, karaniwang nagpapalabas ng higit sa isang milyong Token sa bawat hindi nalulutas na gawain, na maaaring magkakahalaga ng sampu hanggang sa isang daan dolyar.
Sa Abril 2026, isang pananaliksik na isinulong ng Stanford, MIT, at University of Michigan ay unang sistematikong inilantad ang “black box” ng pagkonsumo sa mga gawain sa code ng AI Agent—saan talaga napupunta ang pera, kung worth it ito, at kung maaari itong ma-predict sa harap—at ang sagot ay nakakalito.
Pagkakita 1: Ang bilis ng paggastos ng Agent sa paggawa ng code ay 1,000 beses ang dami ng karaniwang AI na pag-uusap.
Maaaring isipin ng mga tao na ang pagpapalit ng AI para sumulat ng code at ang pag-uusap sa AI tungkol sa code ay magkakasalungat sa gastos.
Ang papel ay nagbibigay ng komparasyon:
Ang paggamit ng token sa agentic coding task ay humigit-kumulang 1,000 beses ang dami ng paggamit sa karaniwang code Q&A at code reasoning tasks.
Nagkakaiba ng tatlong antas ng lakas.
Bakit ganito? Ang papel ay nagtuturo ng isang katotohanan—hindi ginagastusan ang pera sa “pagsusulat ng code”, kundi sa “pagbabasa ng code”.
Dito, ang “pagbasa” ay hindi tumutukoy sa pagbasa ng code ng tao, kundi sa pagkakaroon ng Agent na kailangang magbigay nang patuloy ng buong konteksto ng proyekto, kasaysayan ng mga aksyon, mga error message, at nilalaman ng file sa modelo. Bawat dagdag na round ng usapan ay nagdudulot ng mas mahabang konteksto; at ang modelo ay binabayaran batay sa bilang ng Token—mas marami kang ibinibigay, mas marami kang binabayaran.
Halimbawa: Parang hinihingi mong pumunta ang isang tekniko, ngunit bawat beses na gagamitin niya ang wrench, kailangan mong basahin sa kanya ang lahat ng mga plano ng gusali mula sa simula—ang bayad para sa pagbabasa ng mga plano ay mas mataas kaysa sa bayad para sa pagpapakilos ng bulb.
Isinummary ng papel ang fenomenong ito sa isang pangungusap: Ang nagpapadali sa gastos ng Agent ay ang eksponensyal na pagtaas ng input Token, hindi ang output Token.
Pagkakatuklas 2: Parehong bug, dalawang beses na pina-run, nagkakahalaga ng dalawang beses—at mas mahal ang bug, mas hindi stably
Mas nakakapagod ang pagkakasundo.
Inilapat ng mga mananaliksik ang parehong Agent sa parehong gawain ng apat na beses, at natuklasan nila:
- Sa pagitan ng iba’t ibang gawain, ang pinakamahal na gawain ay bumubulok ng higit sa 7 milyong Token kaysa sa pinakamura (Figure 2a)
- Sa maraming pagpapatakbo sa parehong modelo at parehong gawain, ang pinakamahal ay halos dalawang beses ang halaga ng pinakamura (Figure 2b)
- Kung ihahambing ang parehong gawain sa iba’t ibang modelo, maaaring magkakaiba ng hanggang 30 beses ang pinakamataas at pinakamababang paggamit.
Ang huling numero ay lalo na dapat pansinin: ibig sabihin nito, ang pagkakaiba sa gastos sa pagpili ng tamang modelo at maling modelo ay hindi “mas mahal kaunti,” kundi “mas mahal ng isang ordeng-pamamaraan.”
Mas nakakasakit pa—ang paggastos ng marami ay hindi nangangahulugan na mas mabuti ang gawin.
Nakakita ang pananaliksik ng isang "inverse U-shaped" curve:
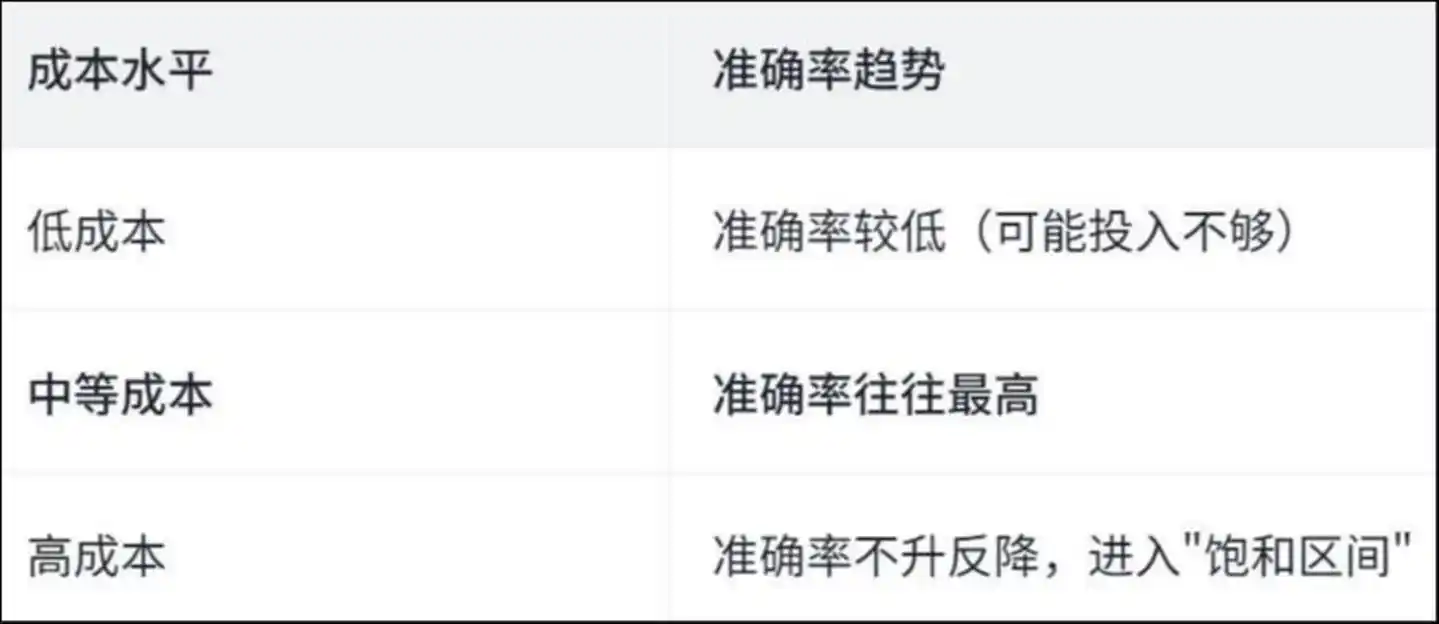
Trend ng pagkakatumpak ng antas ng gastos: Mababang gastos — mababang pagkakatumpak (posibleng kulang ang investasyon); Katamtamang gastos — karaniwang pinakamataas na pagkakatumpak; Mataas na gastos — hindi tumataas ang pagkakatumpak, pumasok sa "saturation zone"
Bakit ganito? Ang papel ay nagbibigay ng sagot sa pamamagitan ng pagsusuri sa mga partikular na aksyon ng Agent—
Sa mataas na gastos sa operasyon, ang Agent ay nagugugol ng maraming oras sa “muling paggawa.”
Ayon sa pag-aaral, sa mga operasyon na may mataas na gastos, halos 50% ng mga operasyon sa pagtingin at pagbabago ng file ay paulit-ulit—ibig sabihin, ang Agent ay paulit-ulit na bumabasa sa parehong file at paulit-ulit na nagbabago sa parehong linya ng code, tulad ng isang tao na umiikot sa loob ng isang silid, mas umiikot, mas nalulunod.
Hindi ginastusan ang pera para solusyunan ang problema, kundi para sa “pagkawala ng daan”.
Natuklasan 3: Malaking pagkakaiba sa “efficiency ratio” sa pagitan ng mga modelo—ang GPT-5 ang pinakamababang paggamit, habang ang ilang modelo ay nagpapalabas ng 1.5 milyong token pa more
Sinubok ng papel ang pagganap ng 8 na mga advanced na malaking modelo na Agent sa SWE-bench Verified, na may istandar ng industriya (500 totoong GitHub Issue). Sa pagsasalin sa dolyar, ang mga modelo na may mataas na efisyensiya ng token ay maaaring magkarga ng ilang sampu ng dolyar pa bawat gawain. Sa mga aplikasyon sa antas ng negosyo—na nagpapatakbo ng maraming daan ng gawain araw-araw—ang pagkakaiba ay direktang pera.
Isang mas interesanteng natuklasan ay: ang efficiency ng token ay ang "naka-impluwensya na pagkakakilanlan" ng modelo, hindi ang gawain.
Ipinagkumpara ng mga mananaliksik ang lahat ng mga gawain na nalutas ng lahat ng modelo (230) at ang lahat ng mga gawain na nabigo ang lahat ng modelo (100), at natuklasan na halos walang pagbabago sa relatibong pagkakaroon ng puwesto ng mga modelo.
Ito ay nagpapakita: may ilang modelong likas na “maraming sinasabi,” at hindi ito malalayon sa kalalabasan ng gawain.
Isang iba pang malalim na pagkakakilanlan: kulang ang modelo sa “pagkakaunawa sa stop-loss”.
Sa pagharap sa mga mahirap na gawain na hindi kayang lutasin ng anumang modelo, ang ideal na Agent ay dapat magpapahinto nang maaga kaysa magpatuloy na magastos. Ngunit ang katotohanan ay, ang mga modelo ay karaniwang naglalabas ng mas maraming Token sa mga nabigong gawain—hindi sila “sumusuko,” kundi patuloy na nag-aaral, nagrere-try, at nagbabasa ulit ng konteksto, tulad ng isang kotse na walang ilaw ng alerto sa petrolyo, at patuloy na nagmamadali hanggang mabigla.
Pagkakamali 4: Ang mga bagay na mahirap para sa tao ay hindi kailangang mahal para sa Agent—ang pagkakaintindi sa kahirapan ay lubos na mali.
Maaari mong isipin: Kung kaya ko bang i-predict ang gastos batay sa kalakasan ng gawain?
Kinuha ng papel ang mga eksperto mula sa tao upang magbigay ng评分 sa kahirapan ng 500 na gawain, at pagkatapos ay ihambing ito sa aktwal na Token consumption ng Agent—
Result: May mahinang kaugnayan lamang sa pagitan ng dalawa.
Sa madaling salita: ang mga gawain na tila imposible para sa tao, maaaring madali at mura para sa Agent; samantala, ang mga simpleng gawain para sa tao, maaaring magdulot ng malaking gastos para sa Agent.
Dahil ang pagkakakilala ng hirap ng tao at ng AI ay hindi magkakatulad:
- Ang tinitingnan ng tao ay: kahalagahan ng lohika, kahirapan ng algoritmo, at antas ng pag-unawa sa negosyo
- Tinataya ng agent: gaano kalaki ang proyekto, ilang file ang kailangang basahin, gaano kalalim ang pag-aaral ng path, at kung babaguhin muli ang parehong file
Isang tao ay maaaring isipin na “sapat na magbago ng isang linya” ang bug, ngunit ang isang agent ay maaaring kailanganin munang maintindihan ang buong istruktura ng codebase upang makahanap ng linya na iyon—ang pagbasa lang ay maaaring mag消耗 ng malaking halaga ng Token. Samantala, ang isang problema sa algoritmo na itinuturing ng tao bilang “magulo ang lohika” ay maaaring alam nang eksakto ng agent ang standard na solusyon, at matapos lang nito ay masosolusyunan ito nang mabilis.
Nagresulta ito sa isang kahiyain na katotohanan: halos imposible para sa mga developer na maunawaan ang gastos sa pagpapatakbo ng Agent sa pamamagitan ng intuisyon.
Discovery Five: Even the model can't accurately calculate how much it will cost itself.
Kung hindi makakalkula ng tama ang tao, ano kaya kung papayagan natin ang AI na mag-predict nang sarili nito?
Nilikha ng mga mananaliksik ang isang masusing eksperimento: pinayagan ang Agent na unang “inspect” ang codebase bago magsimula sa pag-ayos ng bug, at tantiyahin kung gaano karaming Token ang kailangan nito—ngunit hindi pa ginagawa ang pag-ayos.
Paano ang resulta?
All models, completely wiped out.
Ang pinakamataas na resulta ay ang Claude Sonnet-4.5 sa paghuhula ng kakaibang kinalabasan ng Token—0.39 (sa maximum na 1.0). Ang karamihan sa mga modelo ay may paghuhula na kakaibang kinalabasan na nasa pagitan ng 0.05 hanggang 0.34, at ang Gemini-3-Pro ay ang pinakamababa, na lamang 0.04—tulad ng paghuhula nang walang batayan.
Mas kakaibang bagay: lahat ng modelo ay sistematikong nag-underestimate ng kanilang paggamit ng Token. Sa scatter plot ng Figure 11, halos lahat ng puntos ay nasa ilalim ng “perpektong pagpapahula line”—ang modelo ay naniniwala na “hindi sila gagastusin ang marami,” ngunit sa katotohanan, mas marami ang ginastos. At mas malaki ang bias na ito sa pag-underestimate kapag walang ibinigay na halimbawa.
Mas nakakatooto—ang pagbibilang mismo ay kailangang magbayad.
Ang pagkalkula ng gastos para sa Claude Sonnet-3.7 at Sonnet-4 ay maaaring umabot sa higit sa dalawang beses ang gastos ng sariling gawain. Ibig sabihin, mas mahal ang pagpapahalaga nila muna kaysa direktang paggawa.
Ang konklusyon ng papel ay direktang:
Sa kasalukuyan, ang mga pinakamoderno na modelo ay hindi kayang makapag-predict nang tama ang kanilang sariling paggamit ng Token. Pindutin ang “Run Agent”, tulad ng pagbukas ng surprise box—kailangan mong maghintay hanggang lumabas ang bill para malaman kung magkano ang ginastos.
Sa likod ng “nakakalito na aklat” na ito, nakatago ang isang mas malaking problema sa industriya
Nakakabasa ka nito, maaaring magtanong ka: Ano ang kahulugan ng mga natuklasang ito para sa mga negosyo?
Ang pricing model na “monthly subscription” ay pinapagkamali ng Agent
Ang papel ay nagpapakita na ang mga subscription tulad ng ChatGPT Plus ay maaaring magtrabaho dahil ang paggamit ng token sa karaniwang pag-uusap ay relatibong kontrolado at maipapalagay. Ngunit ang mga gawain ng Agent ay lubos na nagbago sa ipinapalagay na ito—isang gawain ay maaaring magbunsod ng malaking dami ng paggamit ng token dahil sa pagkabigo ng Agent sa isang loop.
Ibig sabihin nito, ang pure subscription pricing ay maaaring hindi mapanatili para sa Agent scenarios, at ang pay-as-you-go ay nananatiling pinakamakatotohanang opsyon sa mahabang panahon. Ngunit ang problema sa pay-as-you-go ay—ang paggamit mismo ay hindi maipapalagay.
2. Ang efficiency ng token ay dapat maging "ikatlong indikador" sa pagpili ng modelo
Tradisyonal, ang mga negosyo ay tumitingin sa dalawang dimensyon kapag pumipili ng modelo: kakayahan (kaya ba itong gawin) at bilis (mabilis ba itong gawin). Ang papel na ito ay nagbigay ng ikatlong dimensyon na magkakaparehong kahalagahan: efisiyensiya sa enerhiya (gaano karaming gastos ang kailangan upang matapos ito).
Isang modelo na may kaunting mas mababang kakayahan ngunit 3 beses na mas epektibo ay maaaring magkaroon ng mas malaking ekonomikong halaga sa mga iskala ng pagpapalawak kaysa sa “pinakamalakas ngunit pinakamahal” na modelo.
3. Kailangan ng agent ang “fuel gauge” at “brake”
Ang papel ay binanggit ang isang makabuluhang direksyon para sa hinaharap—mga patakaran sa paggamit ng kasangkapan na may pag-unawa sa budget: Sa simpleng salita, ibibigay ang isang "mga sukat ng gasolina" sa Agent: kapag ang paggamit ng Token ay malapit na sa budget, ipipigil ito nang pilit mula sa walang kwentang pagpapalawak, at hindi ipapagpatuloy ang pagkawala nito hanggang sa wala nang natitira.
Sa kasalukuyan, kawalan ng mekanismong ito ay naroroon sa halos lahat ng pangunahing Agent framework.
Ang "problemang pagpapalabas ng pera" ng agent ay hindi bug, kundi karanasan na kailangang dumaan ng industriya
Ang papel na ito ay hindi nagpapakita ng isang kahinaan ng isang modelo, kundi ang struktural na hamon ng buong Agent paradigm—kapag ang AI ay umunlad mula sa “isang tanong, isang sagot” patungo sa “pagpaplano nang sarili, marami-hakbang na pagsasagawa, at paulit-ulit na pagpapabuti,” ang hindi makikita na pagkawala ng Token ay halos isang kakaibang katotohanan.
Ang magandang balita ay ang unang pagkakataon na sinistemang inilabas at kinalkula ang gulo na ito. Sa pamamagitan ng data na ito, maaaring magdesisyon nang mas matalino ang mga developer tungkol sa pagpili ng modelo, pagtatakda ng budget, at pagdidisenyo ng mekanismo para sa stop-loss; samantala, mayroon ding bagong direksyon para sa mga tagapagbigay ng modelo—hindi lamang gawing mas malakas, kundi gawing mas mura rin.
Sa wakas, bago ang AI Agent ay makapasok sa mga produksyon na kalakalan, mas mahalaga ang paggastus ng bawat piso nang maayos kaysa sa paggawa ng bawat linya ng code nang maganda. (Ang artikulong ito ay unang ipinakilala sa Titanium Media APP, may-akda | Silicon Valley Tech news, editor | Zhao Hongyu)
Tanda: Ang artikulong ito ay batay sa preprint na papel na may pamagat na *How Do AI Agents Spend Your Money? Analyzing and Predicting Token Consumption in Agentic Coding Tasks* (Bai, Huang, Wang, Sun, Mihalcea, Brynjolfsson, Pentland, Pei), na ipinahayag noong Abril 24, 2026 sa arXiv. Ang mga may-akda ay mula sa mga institusyon tulad ng University of Virginia, Stanford University, MIT, at University of Michigan. Ang pag-aaral na ito ay hindi pa pinagsurihan ng mga kapwa eksperto.