
Alam mo ba kung aling malaking modelo ang tunay na pinakamalakas sa OpenClaw real-world agent tasks?
Ginawa ng MyToken isang transparente na benchmark na nakatuon sa pagtataya ng aktwal na kakayahan ng AI coding agents, batay sa mga resulta mula sa mga website ng pagtataya; tanging ang tagumpay rate ang pinag-uusapan bilang pangunahing dimensyon (ang bilis at gastos ay iba pang mga hiwalay na dimensyon na aaralin nang hiwalay sa hinaharap). Buong pampubliko at maaaring i-replicate, nagpapakita lamang ng maingat na pamantayan sa pagtataya + pinakabagong Top 10 listahan ng tagumpay rate.
I. Mga Aspeto ng Pagsusuri: Success Rate
Tiyak na pamantayan: Ang porsyento ng bilang ng mga gawain na natapos nang buo at tama ng AI agent. Bawat gawain ay ginagamit ang isang napakatipid na proseso:
Accurate user prompt
Ibinigay sa agent ang buong liham upang masimulang totoo ang sitwasyon ng user
Inaasahang pag-uugali (Expected Behavior)
Nakapagpapaliwanag ng mga tanggap na paraan at mga mahahalagang puntos sa paggawa ng desisyon
Mga pamantayan sa pagsusuri (checklist)
Itala ang listahan ng mga atomikong kriteryo para sa pagtukoy ng tagumpay na maaaring isa-isang i-verify
Dalawa: Tatlong paraan ng pagmamarka
Ang pagtataya na ito ay pangunahing gumagamit ng 3 uri ng pagmamarka
Automated check: Direktang pagsusuri ng nilalaman ng file, mga rekord ng pagpapatupad, at mga pagtawag sa kasangkapan ng Python script
LLM malaking modelo na hurado: Claude Opus ay nagbibigay ng puntos ayon sa detalyadong iskala (kalidad ng laman, angkop, kahusayan, atbp.)
Hybrid mode: Pagsasama ng automated at obhetibong pagsusuri + LLM judge para sa kwalitatibong pagtataya
Lahat ng mga depinisyon ng gawain, Prompt, at lohika ng pagsusuri ay ipinapahayag upang maaaring i-retest at i-verify.
Tatlo: Mga gawain para sa pagtataya
Ang mga pagsusulit na ito ay sumasaklaw sa 23 iba’t ibang kategorya ng mga gawain. Kasama ang mga pangunahing interaksyon, pagpapatakbo ng mga file/code, paggawa ng nilalaman, pagsusuri at pananaliksik, pagtawag sa mga sistema at kasangkapan, at pagpapanatili ng memorya, na malapit sa mga karaniwang sitwasyon ng mga developer habang gumagamit ng OpenClaw:
Sanity Check (automated) — magproseso ng simpleng utos at tumugon nang tama sa pagbati
Paglikha ng Event sa Kalendaryo (awtomatiko) — Natural Language Generation ng standard na ICS calendar file
Pananaliksik sa Presyo ng Stock (awtomatiko) — Tumatanggap ng real-time na impormasyon sa presyo ng stock at naglalabas ng formatted na ulat
Blog Post Writing (LLM Judge) — Isulat ang isang structured Markdown blog post na may halos 500 salita
Pagbuo ng Weather Script (awtomatiko) — Sumulat ng Python script para sa Weather API na may error handling
Pagsasalin ng Dokumento (LLM Judge) — Tatlóng bahagi na maikling buod ng pangunahing paksa
Pananaliksik sa Konperensya sa Teknolohiya (LLM Judge) —— Pag-aaral at pagpupulong ng impormasyon sa 5 tunay na konperensya sa teknolohiya (pangalan, petsa, lokasyon, link)
Paggawa ng Propesyonal na Liham sa Email (LLM Judge) — Pagsang-ayon nang maayos sa pagkakataon at pagproponga ng alternatibong solusyon
Memory Retrieval from Context (Automation) — Tumpok nang tumpok ang petsa, miyembro, teknikal na stack, atbp. mula sa mga tala ng proyekto
Paglikha ng File Structure (awtomatiko) — awtomatikong paglikha ng standard na project directory, README, .gitignore
Multi-step API Workflow (hybrid) — basahin ang konfigurasyon → isulat ang script ng pagtawag → buong dokumentasyon
I-install ang ClawdHub Skill (automatization) — i-install at i-verify ang availability mula sa skill repository
Maghanap at I-install ang Skill (automatization) — hanapin at i-install nang tama ang skill para sa panahon
AI Image Generation (Mixed) — Gumawa at i-save ang larawan ayon sa deskripsyon
Humanize AI-Generated Blog (LLM Judge) — Gawing natural at salitang pambuhay ang mga nilalaman na may machine vibe
Daily Research Summary (LLM Judge) — Pagkakaisa ng maraming dokumento upang makabuo ng malinaw na araw-araw na buod
Email Inbox Triage (Mixed) — Analisis ng maraming email at pag-ayos ng ulat ayon sa antas ng kahalagahan
Paghahanap at Pagsasummary ng Email (Mixed) — Hanapin ang mga arkibong email at i-highlight ang mga mahahalagang impormasyon
Kompetitibong Pananaliksik sa Pamilihan (Hibrida) — Pag-aaral ng mga kalaban sa larangan ng Enterprise APM
CSV at Excel Summarization (Mixed) — Analisahin ang mga file ng talahanayan at maglabas ng mga insigh
ELI5 PDF Summarization (LLM Judge) — Ipaliwanag ang teknikal na PDF gamit ang wika na maintindihan ng 5-taong-gulang
Pagsusuri sa Report ng OpenClaw (automatizado) — Tumpak na sagutin ang mga partikular na tanong mula sa PDF ng研究报告
Second Brain Knowledge Persistence (hybrid) — Pag-iimbak at tumpak na pag-alala ng impormasyon sa pagitan ng sesyon
apat: Pangunahing Konklusyon: Top 10 Mga Modelong may Pinakamataas na Pagkakatagumpay (Pinakamataas na %/Average %)
Updated data as of April 7, 2026
Ang pinakamataas na % ay ang pinakamataas na tagumpay sa isang pagkakataon, habang ang average % ay ang average na tagumpay sa maraming pagkakataon, na mas nagpapakita ng katatagan
Narito ang top 10 na mga modelo na may pinakamataas na antas ng tagumpay
anthropic/claude-opus-4.6 (Anthropic) —— 93.3% / 82.0%
arcee-ai/trinity-large-thinking (Arcee AI) — 91.9% / 91.9%
openai/gpt-5.4 (OpenAI) —— 90.5% / 81.7%
qwen/qwen3.5-27b (Qwen) —— 90.0% / 78.5%
minimax/minimax-m2.7 (MiniMax) —— 89.8% / 83.2%
anthropic/claude-haiku-4.5 (Anthropic) —— 89.5% / 78.1%
qwen/qwen3.5-397b-a17b (Qwen) —— 89.1% / 80.4%
xiaomi/mimo-v2-flash (Xiaomi) —— 88.8% / 70.2%
qwen/qwen3.6-plus-preview (Qwen) — 88.6% / 84.0%
nvidia/nemotron-3-super-120b-a12b (NVIDIA) —— 88.6% / 75.5%
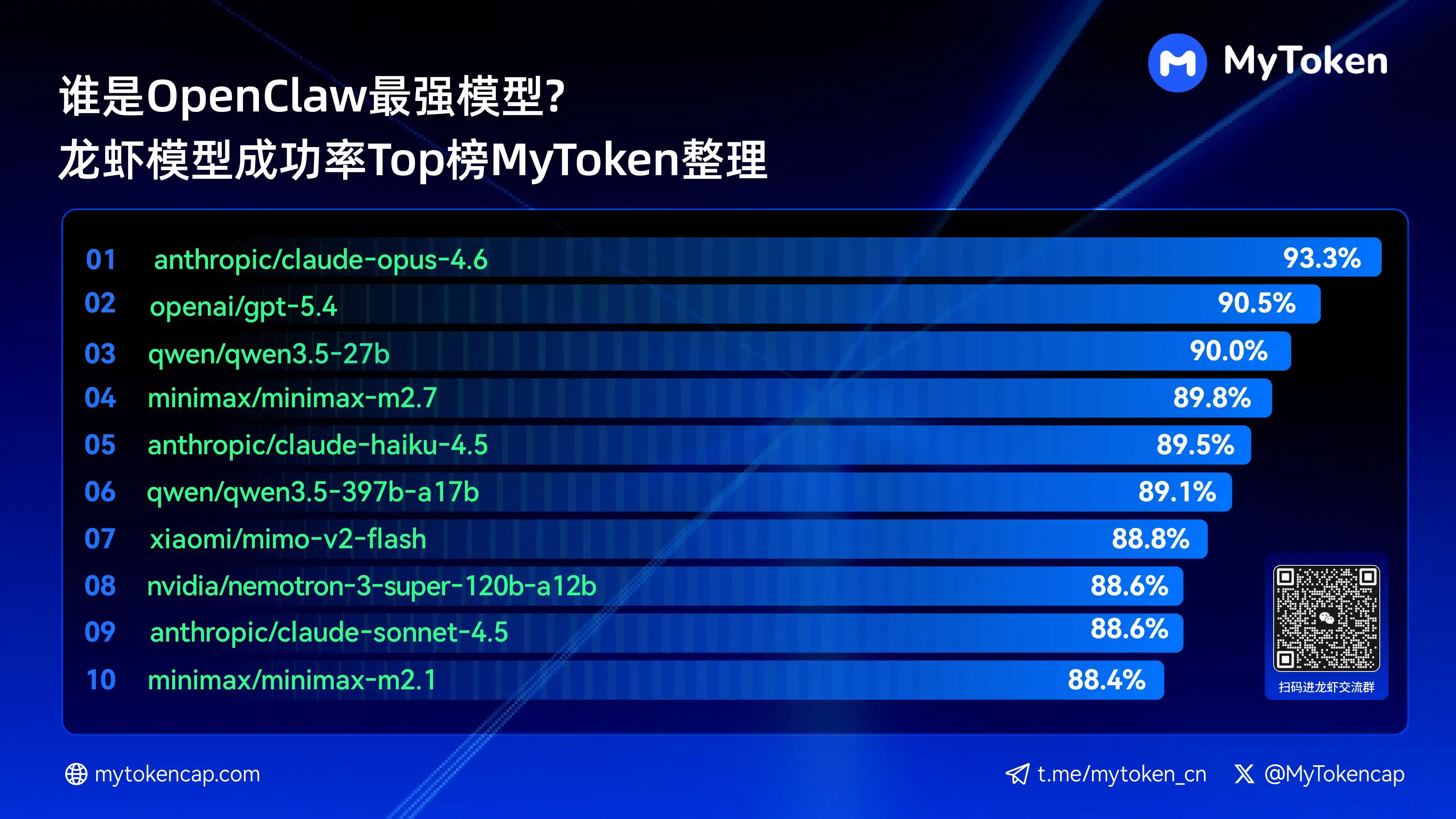
Ang Claude Opus 4.6 ay nangunguna sa pinakamataas na tagumpay na rate na 93.3%, ngunit ang Trinity ni Arcee ay nakikita ang malaking pagkakatipid sa average stability, habang may ilang modelo sa Qwen series na nasa top ten, na nagpapakita ng malakas na potensyal sa value for money. Ang tagumpay na rate ay ang pangunahing hangganan, ngunit ang bilis at gastos ay magiging mas mahalaga sa susunod na pagtataya ng actual na karanasan.
Ang 23-task benchmark na ito ay lubos na transparent, at mabigat na inirerekomenda na subukan ninyo ito batay sa inyong sariling sitwasyon. Hhintayin ninyo ang darating na feature ng MyToken na Agent Ranking para sa karagdagang rankings ng mga model.
(Data mula sa pinagmumulan ng PinchBench na pampublikong OpenClaw agent benchmark, patuloy na ina-update.)