










May-akda: Max, laging nasa daan, 01Founder
Kung sasabihin ang isang intermediate summary para sa OpenAI noong 2025, marami ang magiging malakas o kahit paano ay pasibo.
Sa nakalipas na higit sa isang taon, talagang sinunod nila ang logika ng pag-iisip at malakas na ipinakilala ang mga inference model mula sa o3pro hanggang o4mini, at ipinakilala rin ang mga bagong base model tulad ng GPT-4.5 at GPT-5.
Ngunit sa larangan ng visual generation kung saan ang karaniwang gumagamit ay mas madaling makita at maaaring magpalaganap nang walang pagsisikap, ang kanilang pagkakaroon ay nagsisimulang mawala.
Pagkatapos ng unang pagkakaakit ng Sora, tila nasa mahabang pagtigil ang OpenAI sa larangan na ito.
Samantala, hindi nagpapahinga ang ibang mga lalaro sa mesa.
Sa open-source ecosystem, ang mga modelo tulad ng Flux ay lubos na pinababa ang hadlang para sa mataas na kalidad na lokal na paggawa ng imahe;
Sa komersyal na sektor, hindi lamang may mga dating kalaban na nangangasiwa sa isang ekstremong hadlang sa estetika, kundi lumitaw din ang mga bagong kalahati tulad ng Nano-banana na may built-in na function para sa paghahanap sa internet.
Kumpara sa kanya, ang dating pangunahing model ng OpenAI para sa paggawa ng imahe, GPT-Image-1.5, ay naging lumang-luma na:
Hindi lamang mababa ang kalidad ng imahe at pagsasayos, kundi madalas ring mabagsak sa mga kumplikadong teksto.
Dahan-dahan, nabuo ang isang pagkakasunduan sa industriya:
Nakakaranas ang OpenAI ng teknikal na hadlang sa larangan ng visual generation at nagiging mahirap na sumabay sa pagkakaroon ng iba't ibang kalaban.
Hanggang sa mga nakaraang linggo, ang punto ng pagbabago ay lumabas sa isang napakalalim na paraan.
Sa kilalang platform ng blind test para sa malalaking modelo, ang LM Arena, isang misteryosong image model na may code name na Duct Tape ay nagsisilip nang tahimik.
Mabilis na napansin ng mga user na sumali sa blind test na may kakaibang bagay:
Hindi lamang napakatumpak ng modelo sa pagkontrol sa mga ekstremong aspeto, kundi nakakapag-output rin ito ng mga poster na may malaking dami ng maraming wika nang walang anumang kamalian, kahit na may isang nakatago na proseso ng pagpaplano bago ang paggawa ng imahe.
Sa isang panahon, ang iba’t ibang teknikal na komunidad ay nagtatantya kung sino ang naglulunsad ng lihim na panao, ngunit patuloy na nanatiling tahimik ang OpenAI.
Sa gabi ngayon, final na ang pagkakaroon ng sapatos.
Walang mahabang pagpapakilala, walang malawakang pagpapromosyon, diretso ng OpenAI ang ipinangalan sa modelong may code name na “tape” bilang ChatGPT GPT-Image-2 at isinampa ito sa merkado.
Kasama rin sa pagpapalabas ay isang listahan ng leaderboard sa Text-to-Image arena na nagdudulot ng pagkakaroon ng pakiramdam na hirap huminga.
Ang GPT-Image-2 ay direktang nakapasok sa unang puwesto ng may mataas na marka na 1512, na may labis na 242 puntos sa ikalawang puwesto (na ang Nano-banana-2 na may function ng paghahanap online).
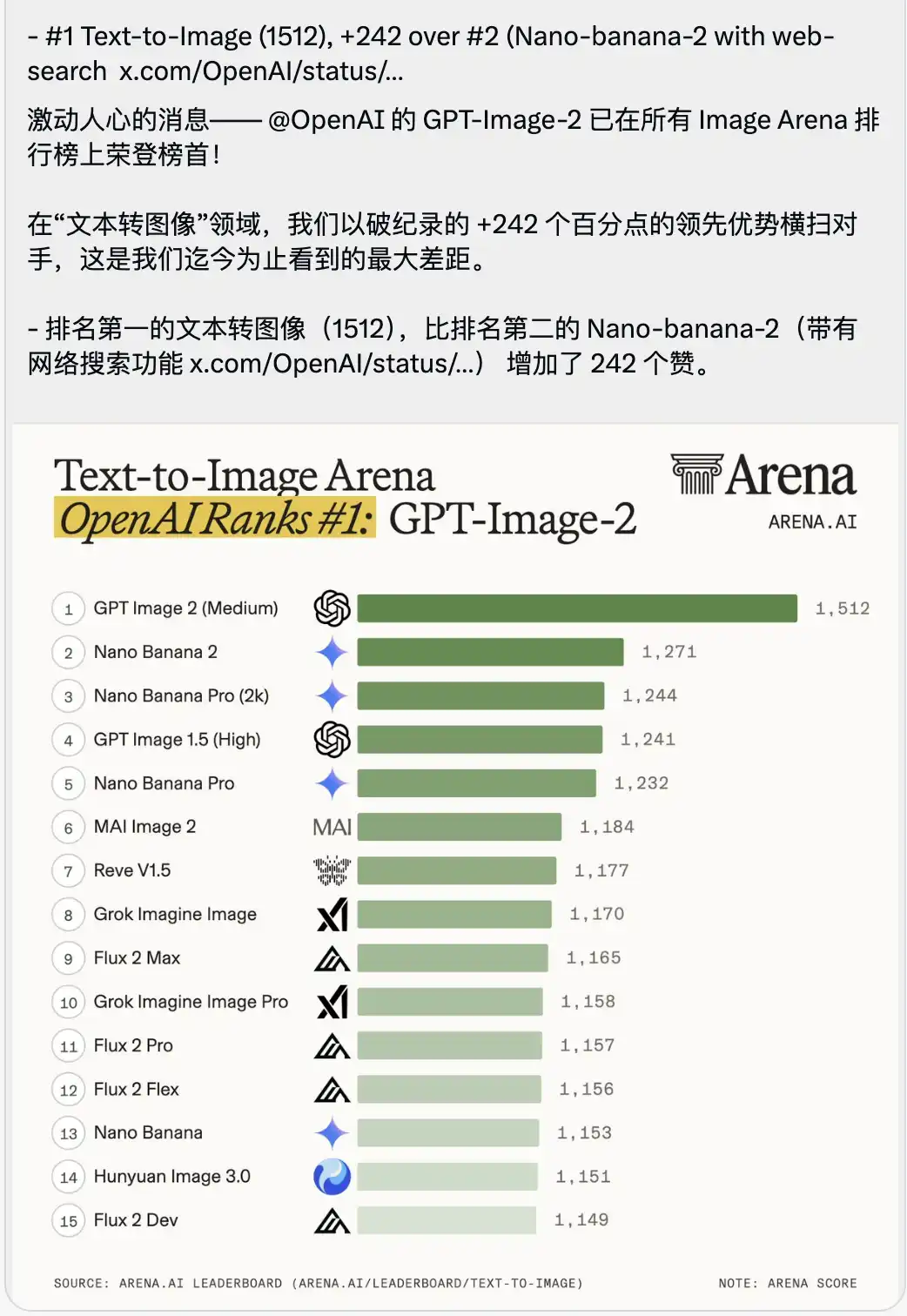
Sa konteksto ng pag-scor ng malalaking modelo, karaniwang ipinapakita nang malaki ang paglabas ng mga bahagdan na kalahati o isang digit, dahil ang mga score ng mga lider ay napakalapit.
Isang lagay na 242 puntos, walang katulad sa kasaysayan ng arena.
Hindi ito simpleng maliit na pag-update ng bersyon, ito ay isang pangangalap na pagkakaiba ng henerasyon.
Nag-antay ako ng kalahating araw para masuri nang mabuti ang lahat ng kanyang mga limitadong kakayahan at ang pinakabagong API documentation.
Ang pinakamalaking pakiramdam ay isa lang:
OpenAI ay ang parehong OpenAI.
Kapag nagsipagpasya ito na muling kunin ang mga nawalang lupain, ang paraan nito ay direktang pagbubuwal sa lumang mesa ng mga kard.
Sa harap ng modelo na ito, ang mga gawain sa visual design na akala nating kailangan pa ng dalawa o tatlong taon bago ganap na palitan ng AI, ngayon ay praktikal na natapos na.
PART.01 Pagbuo ng imahe mula sa modelo hanggang sa visual agent
Upang maunawaan kung bakit kayang magkaroon ng ganoon kalaking pagkakaiba ng puntos ang GPT-Image-2, kailangan mong tanggalin ang mga nakakabit na pananaw sa mga modelo ng text-to-image.
dati, ginagamit natin ang AI para gumawa ng mga larawan, at sa本质上 ay parang pagpapakita ng isang black box; ilalagay mo ang ilang mga prompt, tapos hinihintay mo na i-arrange nito ang mga pixel ayon sa iyong nais.
Ngunit ang GPT-Image-2 ay mas katulad ng isang agent na may nakabuilt-in na visual engine.
Ang pinakamalaking pagbabago ay ang direkta nitong paghihiwalay sa dalawang ganap na iba’t ibang mode sa mekanismo.
Isang instant mode na bukas para sa lahat ng mga user.
Ang modelo na ito ay nakatuon sa mabilis na pagtugon at walang hangganan na pagpapalakas sa mga proseso ng pang-araw-araw at trabaho.
Halimbawa, kung ipapadala mo sa iyo ang isang utos sa iyong mobile phone, maaari itong magbigay sa iyo ng isang kompletong estruktural na larawan sa loob ng ilang segundo.
Ang kanyang malakas na kakayahan sa pag-unawa sa visual ay nakatuon sa mga pangangailangan sa visual conversion na madalas at isang beses.
Ang Thinking Mode na available para sa mga bayad na user.
Bago ito mag-render ng anumang pixel, una itong papasok sa isang mahabang 10+ segundo na proseso ng lohikal na pag-iisip at paghahanap sa internet.
Tama ang pattern na ito, na naglutas sa isang napakaseryoso at napakahirap na paksang:
Alam ng modelo kung ano ang dapat niyang ilarawan para sa unang beses.
Isang pinakamadaling maintindihang halimbawa.
Itype mo sa chat box:
Gumawa ng isang poster, maghanap sa internet ng mga puna tungkol sa misteryosong modelo na Duct Tape, at isama ang QR code ng ChatGPT.

Kung gagamitin ang dating model, hindi ito alam kung ano ang sinabi ng netizens, at magpapakita lang ng isang poster na may mga random at maliit na titik, at ang QR code ay isang fake image na hindi maaaring i-scan.
Ngunit sa mode ng pag-iisip, ang kanyang workflow ay ganito:
Iiwasan muna ang pagguhit, iuunlad ang tool para sa paghahanap sa internet, at i-scraper ang mga totoong puna ng mga netizen mula sa Reddit, Threads, o LinkedIn;
Pagkatapos, itinakda nito ang layout ng poster, ang mga espasyo, at ang hierarchy ng mga font;
Sa huli, ito ay naglalikha ng isang totoong gumagana at direktang scan at i-redirect na QR code, at isinasaayos ang buong imahe.

Hindi na ito pagguhit, ito ay talagang pagkumpleto ng buong proseso ng pag-aaral, pagpaplano, pagkuha ng teksto, at disenyo ng layout.
Kailangan ng parallel na paghahambing dito.
Alam ng lahat sa komunidad ng malalaking modelo na ang mga modelo sa paggawa ng imahe na may kakayahang makikonekta at maghanap ay hindi nilikha ng OpenAI.
Ang Nano-banana sa pangalawang lugar sa leaderboard ay may机制 na ito mula pa noong una.
Ngunit habang gumagamit ka ng Nano-banana, makikita mong maliit ang kanyang kahusayan sa maraming lugar.
Ang pag-iisip ng Nano-banana ay madalas isang mekanikal na pagkakabit ng lohika.
Halimbawa, ipinapagawa mo sa kanya na maghanap ng trend ng industriya para sa poster, at talagang naghanap siya, ngunit karaniwan ay kinukuha niya nang walang pagbabago ang mga pangungusap mula sa Wikipedia at pinipilit na i-post sa larawan.
Madaling magsawa kapag kinakailangan ng pagpapaliwanag sa abstraktong mga pangangailangan ng negosyo.

Ang damdamin ay parang isang intern na nakakaintindi ng mga utos, ngunit walang anumang karanasan sa trabaho, nakakaalam ng pagpapatupad, ngunit ganap na walang pag-unawa sa estratehiya.
Ngunit ang pagganap ng GPT-Image-2 sa aspetong ito ay maaaring ilarawan bilang labis.
Hindi ito isang pagsasagawa ng porma, kundi tunay na pag-unawa sa likod na kultural na konteksto at negosyong intensyon.
Nag-input ako ng isang sobrang simpleng Chinese command habang nagtatasa: Tulongan mo akong gumawa ng screenshot ni Musk habang naglalabas ng DouBao sa livestream sa TikTok.
Kung gagamitin ang dating model sa pagguhit, malaki ang posibilidad na ipapakita nito ang isang puting tao na may anyo ni Musk, habang hawak ang bao, na may malabo na background, at kahit hindi alam kung paano ang tampok ng TikTok.
Ngunit sa mode ng pag-iisip, ang mga resulta ng GPT-Image-2 ay nagdudulot ng ilang pagkakalito.
Hindi ito simpleng pinagsama-samang mga elemento, kundi itinawag nito nang sarili nito ang pag-unawa sa Chinese internet at ginawa ang isang screen capture ng UI ng TikTok live stream na parang pixel-perfect na kopya.
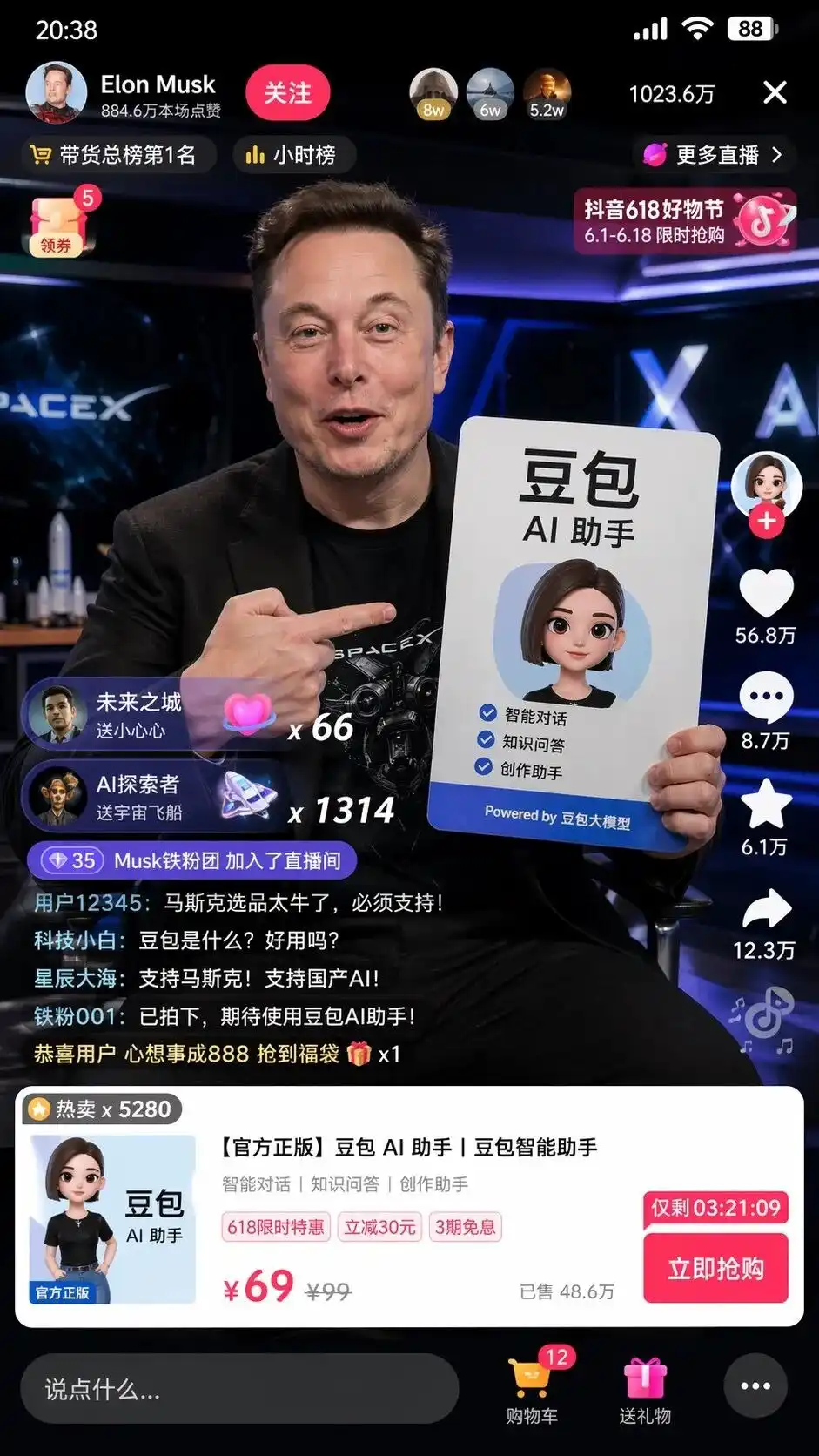
Hindi lang may makatotohanang imahe ni Musk na humahawak ng banner ng ad para sa AI assistant na DouBao na may perpektong pagkakalagay, mas nakakatakot ang mga detalyeng hindi nabanggit sa prompt:
Ang button na pinagmamasdan sa kaliwang itaas, ang listahan ng oras, ang 10.23 milyong online users sa kanang itaas, ang standard product card na lumabas sa ibaba, at kahit ang nakalagay na regular na presyo na 99, special price na 69, at ang button na “Bili Agad” na may countdown.
Ang pinakamakakatakot ay ang mga komento ng netizens na tumatakbo nang napakatotoo sa kaliwang ibaba:
Tech newbie: Ano ang Doudou? Mabuti ba ito?
Saan pa ba ang kalawakan: Suportahan si Musk! Suportahan ang lokal na AI!
Walang sinoman ang sinabi kung ano ang dapat isulat sa comment, paano dapat magmukha ang UI ng produkto, o paano dapat tatakasan ang presyo.
Ito ang kompletong disenyo ng UI at plano sa operasyon na isinagawa ng modelo pagkatapos suriin ang mga label na TikTok Commerce at Doubao Large Model.
Ang mga pamantayan sa pagtataya ng malalaking modelo sa paggawa ng imahe ay sa pitak na ito ay lumampas na sa simpleng kahalagahan kung kaya nitong gawin ang magandang larawan, at pumunta sa pag-unawa sa mga estratehiya at lohika ng pagkakasunod-sunod.
PART.02 Pagsusuri ng Pangunahing Kakayahan
Upang subukan ang kanyang hangganan, sinubukan ko ito gamit ang ilang karaniwan at kumplikadong mga skenaryo batay sa mga pamantayan ng komersyal na disenyo.
Nakita na ang antas ng detalye kung paano ito sinosolusyon, napakadetalye hanggang sa maging nakakatakot.
Unang eksena: Pagsusuri ng biswal at pagsasara ng negosyo (pagsuot ng damit sa modelo)
Sa tradisyonal na e-commerce visual o fashion planning, ang gastos sa pagpapatupad mula sa isang ideya hanggang sa makita ang epekto sa katawan ay napakataas.
Kailangan mo ng model, pagpapahiram ng damit, paghahanda ng studio, at pag-edit ng post-production.
Pagkatapos ay dumating ang AI, at nagsimula ang mga tao na i-train ang mga LoRA model para i-fixed ang anyo ng mukha ng isang tao, ngunit kailangan pa rin ito ng ilang dekada ng mga larawan at malaking gastos sa pag-aaral.
Sa GPT-Image-2, ang proseso ay na-compress nang lubos.
Sinubukan kong i-upload ang isang sariling selfie ko, sinabi kong papunta ako sa isla para sa bakasyon sa susunod na buwan, at hiningi kong tulungan akong piliin ang ilang set ng damit.
Una niyang ibinigay sa akin ang 8 set ng catalog ng summer wear na iba-iba ang estilo, ang layout ay parang propesyonal na电商 Lookbook, at may tamang label sa tabi ng bawat item.
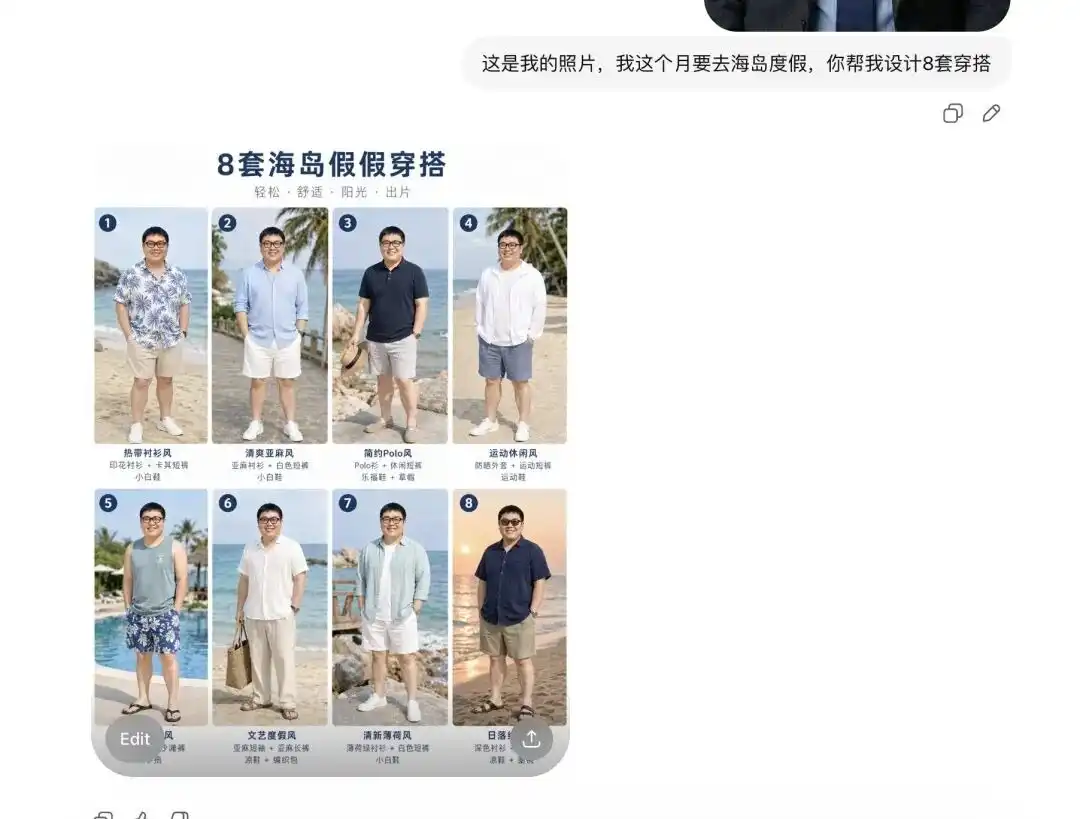
Mas mahalaga pa, sinuri nito nang tama ang aking mga tampok sa mukha at proporsyon ng katawan sa sandaling iyon.
Nang sabihin ko sa ito na gusto kong makita ang epekto ng unang set sa aking katawan at ibigay sa akin ang ilang detalye ng mga larawan mula sa iba’t ibang panig, agad niyang inilabas ang aking sariling litrato, pinalitan ang tao doon ng summer outfit, at inilabas ang mga larawan mula sa iba’t ibang panig tulad ng side view at half-body view.

Sobrang smooth ang pagbabalik na ito. Ibig sabihin nito, ang mga pangunahing pag-render ng pagkakasuot ng damit o ang mga gawain na ibinibigay sa mga modelo para subukan ang damit, ang kanilang malalim na kahon ay lubos na tinanggal.
Ikalawang skena: Lutasin ang pagkakatugma at patuloy na istorya (pagbuo ng komiks sa isang pangungusap)
Alam ng lahat ng nagawa ng AI art na ang paggawa ng isang magandang larawan ay hindi mahirap, ang hirap ay paggawa ng sampung larawan ng iisang tao na may magkakaugnay na galaw at pananaw.
Ito ang tinatawag na problema ng konsistensya (Consistency).
Ngunit sa pagsusuri na ito, nakita ko ang isang kaso na lubos na lumalabag sa nakaraang karanasan.
Maaari mong i-upload ang isang larawan mo at ng iyong kaibigan kahapon, at pagsunod sa isang napakasimpleng prompt:
Iwan mo na lang ang pagiging pangunahing tauhan natin, gumawa ng tatlong pahina ng Japanese-style comic, at i-design mo na ang kuwento.
Sa ilang segundo, itinampok nito nang direkta ang tatlong pahina ng black-and-white comic strip na may standard storyboard.
Ang pinakamakakatakot ay ang dalawang karakter sa komiks na gawa sa totoong tao, na nasa iba’t ibang panel sa tatlong pahina.

Kahit close-up, distant running, o back view, kahit ang kanilang mga katangian sa mukha, detalye ng buhok, at mga plis sa damit, lahat ay nanatiling perpektong magkakatulad.
Mas kahanga-hanga pa, ang kuwento ng komiks ay ganap na magkakaugnay, kahit ang mga teksto sa mga balloon ay bumubuo rin ng isang buong lohikal na kuwento.

Ang kakayahang magkaroon ng pagkakasunod-sunod sa panahon at espasyo ay nagpapakita na ito ay nasa labas na ng saklaw ng paggawa ng isang iisang imahe, at may kakayahang magdirekta ng isang tuloy-tuloy na kuwento.
Ikatlong skena: Paglilipas sa huling hadlang sa pag-render ng teksto (multilingual typesetting)
Kung ang pagkakatulad ang naglutas sa problema ng istorya, ang tumpak na pagpapakita ng maraming wika ang talagang nagpilit sa mga designer sa pader.
dati, kung may teksto sa larawan, ang malalaking modelo ay nagsisimula na mag-guho.
Dahil ang mga salitang nauunawaan ng modelo ay mga Token (mga semantikong bloke), habang ang mga nilalabas na imahe ay mga pixel, ang dalawa ay dating hiwalay.
GPT-Image-2 ay lubos na nalutas ang tanong na ito.
Ginawa kong isang cover ng isang French fashion magazine, isang menu ng isang Hapon na restawran na may buong set ng hiragana at kanji, at kahit isang malalim na pagkakasunod-sunod ng mga Russian na komento.

Ang resulta ay isang pagkakagawa, walang mga pagkakamali sa pagbabaybay.
Ang pinakamalungkot ay hindi lang ito nagpapakita ng tamang pagsulat ng mga titik, kundi alam rin nito na mag-match sa lokal na kultura at disenyo ng font ayon sa wika.
Halimbawa, ang mga karakter na Tsino sa flyer sa Japanese, ginamit ang napakatotoong Japanese vintage calligraphy, at ang pagkakasunod-sunod ng hiragana ay sumusunod sa tradisyonal na pahalang na pagbasa ng Japanese.
Ang layout design ay dating isang sariling teritoryo ng mga graphic designer.
Kailangan ng maraming pagsasanay ang pag-adjust ng spacing ng mga titik, pagkakaiba ng pangunahin at pangalawang elemento, at pagkakaroon ng visual balance sa pagitan ng teksto at background.
Ngunit kapag ang AI ay kayang mag-handle ng maraming wika nang walang anumang pagkakamali, kasama na ang advanced na pagkakasunod-sunod ng disenyo, ang mga karaniwang poster, brochure, at ads sa feed ay hindi na kailangang gawin ng tao nang manual na pag-ayos ng mga linya.
Ikaapat na eksena: Deformed aspect ratio at extremo ng mikro kontrol (pagsusulat sa isang grains ng bigas)
Sa huli, upang makita kung gaano kahigpit ito sa pagtupad, ibinigay ko sa ito ang ilang napakahirap na utos.
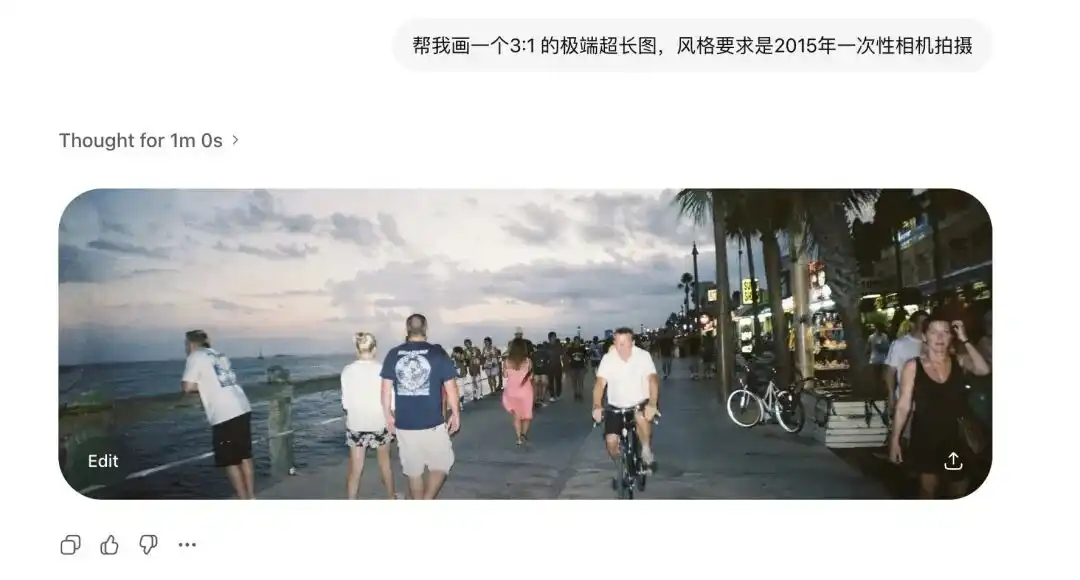
Una kong sinubukan ang extreme aspect ratio nito.
Ang mga tradisyonal na diffusion models ay lubos na takot sa mga hindi standard na proporsyon.
Kahit kaunti lang i-extends ang larawan, lumalabas ang dalawang ulo.
Ngunit hiningi ko sa Images 2.0 na lumikha ng super-widescreen na 3:1 at vertical na 1:3 na mga imahe, at hindi lamang ito ay hindi nasira, kundi lumikha ito ng 360-degree panoramic image na may magkakasambalat at lohikal na pagsasara sa simula at dulo.
Pagkatapos ay idinagdag ang mga term mula sa isang-use camera noong 2015, kahit ang distorsyon ng lumang lens at ang mahinang refleksyon ng flash sa pader ay nailalarawan nang malinaw.
At ang isa pang mas nagpapakita ng kanyang mikro kontrol, ay ang isang kaunting gawain sa bigas na ipinakita ng opisyal sa pagpapahayag.
Kinabisan ng researcher ang eksperimental na 4K API na kasalukuyang nasa internal testing; hindi nila ginamit ang anumang mga termino tulad ng macro photography o 8K ultra HD, kundi nagbigay lang ng isang napakakaraniwang, abstraktong utos:
Isang puno ng bigas. Sa isang hiwa ng bigas sa puno na ito, nakasulat ang GPT Image 2.
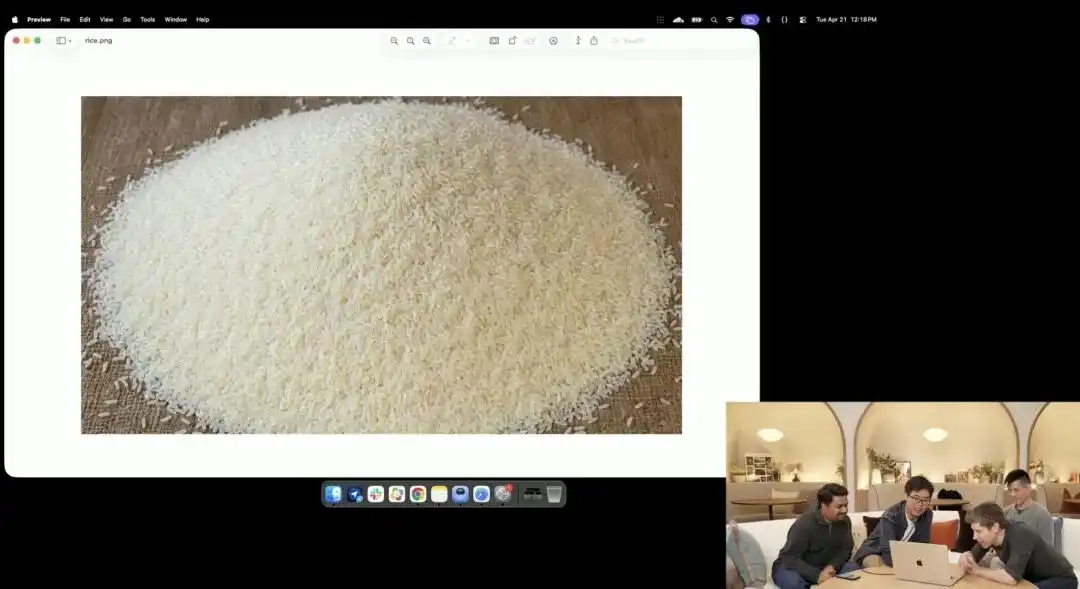
Kapag pinapalaki ang screen ng higit sa sampu-sampu o kaya’y lumalabas na mga pixel, talagang makakahanap ka ng isang maliit na butil na may nakasulat na titik sa gitna ng isang malaking bao ng bigas.
Ang tekstura ng bigas ay patuloy na sumusunod sa mga batas ng pisika, at ang teksto ay tumpak na nakapaloob sa maliit na kurba ng bawat butil ng bigas.
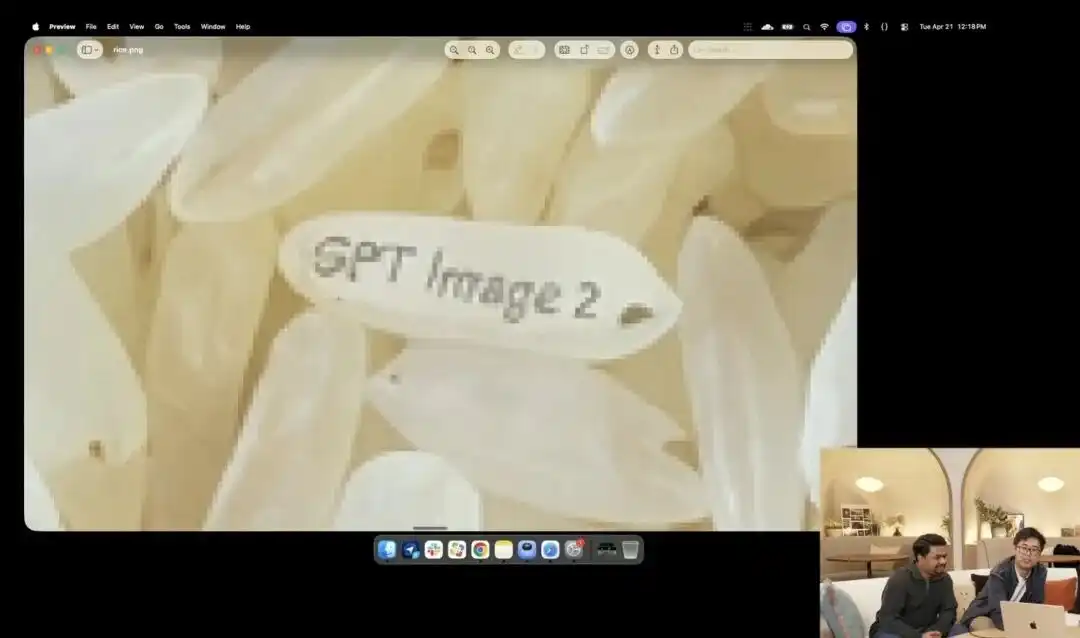
Ang lahat ng natitirang trabaho—pagpapagana ng macro view, pagkalkula ng depth of field, paghahanap sa latent space ng pisikal na koordinado ng isang grains of rice, at pagpapalabas ng text—ay awtomatikong isinagawa ng malaking modelo sa pamamagitan ng pag-iisip.
Nakikita nang malinaw sa kasong ito na ang modelo ay nakamit ang precision ng isang scalpel sa antas ng pixel sa pag-unawa sa spatial position.
Ito ay nangangahulugan na sa mga darating na proyekto, maaari mong mabago nang tumpak ang anumang maliit na bahagi ng design, kung saan mo ito tukuyin, at hindi na tulad ng dati kung saan kapag gusto mong baguhin ang collar, bumabago ang buong larawan.
PART.03 Ilang teknikal na detalye
Hindi ito maaaring makamit lamang sa pamamagitan ng pagpapalaki ng computing power nang walang malinaw na estratehiya.
Upang malaman kung ano talaga ang kanyang mga kartang nakatago, gumawa ako ng ilang pagsubok sa GPT-Image-2.
Nakita ang isang napakaganda't interesanteng punto.
Bagaman ang opisyal na dokumentasyon ay nagpapahayag na ang kabuuang kaalaman ng GPT-Image-2 ay na-update hanggang Disyembre 2025, sa aking sariling pagsubok.
Ang petsa ng pagtatapos ng mga datos para sa Instant Mode ay nananatili pa rin sa huling bahagi ng Mayo 2024;

Ang mode ng pag-iisip (Thinking Mode) na nangangailangan ng mahabang pag-iisip ay may native knowledge base na naka-stay sa Hunyo 2024 (ngunit maaaring makakuha ng kasalukuyang tamang petsa sa pamamagitan ng real-time online connection).

Sa pamamagitan ng pagkalkula mula sa dalawang punto sa oras, tila may mga patunay sa ilalim ng buong GPT-Image-2.
Una, ang immediate mode na nakatuon sa madalas na paggawa ng imahe.
Ang deadline noong Mayo 2024 ay nangangahulugan na ito ay malamang na direktang ginamit ang o4-mini, o isang lightweight na bersyon sa pamilya ng GPT-5 (tulad ng GPT-5 mini o kaya ay napakaliit na parametrong GPT-5 nano).
Dahil sa mga magkakaibang base na ito ay may kakayahang magplano ng espasyo at maintindihan ang mga kumplikadong utos, ang pagbuo ng imahe sa itaas ay nakakapanatili ng kalmado at hindi nagkakaroon ng kalituhan.
At ang napakatalino at nakakaunawa sa mga estratehiya sa negosyo na paraan ng pag-iisip, ang batayan nito ay hindi maaaring ang pangunahing modelo ng GPT-5.
Dahil ang batayang database ng GPT-5 ay nagtatapos sa Setyembre 2024.
Ang mode ng pag-iisip ay malamang na nakakonekta sa patuloy na ina-update na O-series na inference model (tulad ng o4 o ang updated na o3).
Ang malaking modelo ay unang gumagamit ng eksklusibong mekanismo ng mahabang pag-iisip ng serie O, kung saan ito ay kumikalkula nang malinaw ang mga negosyong lohika, psikolohiya ng target na audience, at mga koordinadong pagkakasunod-sunod sa latent space, bago isumite sa visual module para sa huling pixel rendering.
Kasama rin ang ibang posibleng landas:
Sa ilalim ng napakatumpak na mekanismo ng pagkakasunod-sunod ng computing power sa loob ng OpenAI, ang fast mode ay maaaring direktang gumamit ng GPT-5 nano bilang baseline, habang ang thought mode ay gumagamit ng kaunting mas malaking GPT-5 mini kasama ang mga panlabas na kasangkapan.
Ngunit anumang kombinasyon ng base, kung patuloy mong sinusubaybayan ang OpenAI API ecosystem, makikita mo na ang kanilang pondo sa pagbuo ay nasa ibang antas na kumpara sa Midjourney.
PART.04 Ang pinakamalaking pag-aalala ng lahat tungkol sa pagtatakda ng presyo
Ngunit higit pa sa paghula sa base, mas mahalaga para sa mga developer at negosyo na talagang gustong i-integrate ito sa kanilang workflow ay ang napakatotoo at kabaligtaran sa intuisyon na tala ng presyo ng API.
Noong una, ang DALL-E 3 ay binabayaran batay sa bilang (halimbawa, $0.04 bawat imahe).
Ngunit mula sa unang henerasyon ng GPT-Image-1, ang OpenAI ay nagbago na ito sa isang framework na batay sa pagkalkula ng Token.
Ang GPT-Image-2 na ito ay patuloy na sumusunod sa istandart na ito, at higit pa rito, ito ay nag-aalok ng mas maraming functionality sa mas mababang presyo.
Ayon sa bagong ipinahayag na presyo mula sa opisyal, ang bawat milyong Token ay may presyo na sumusunod.
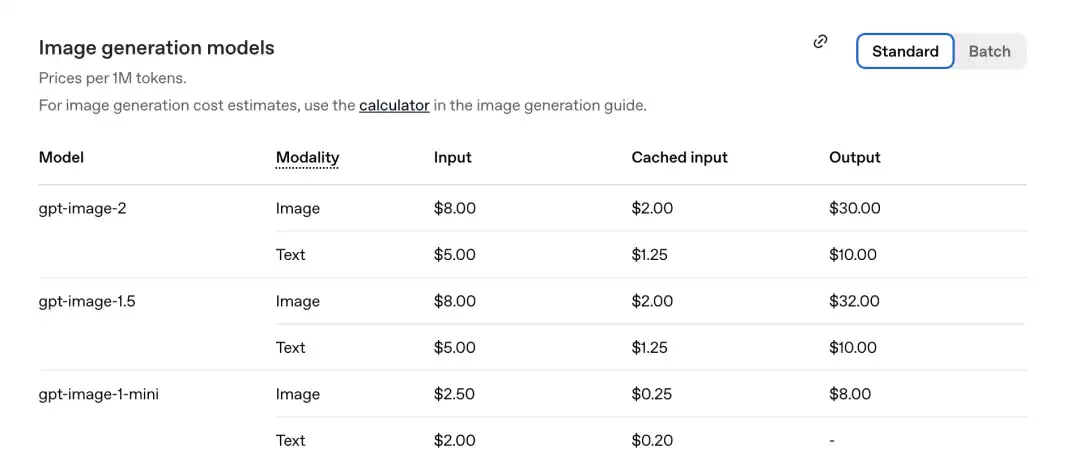
GPT-Image-2 Bahagi ng imahe: Ipasok ang 8.00, cached inputs 2.00, output $30.00.
Kumpara sa nakaraang henerasyon ng gpt-image-1.5: ang output ay $32.00.
Mas mura naman ang bagong modelo.
Magkano ang kalkulasyon natin.
Sa nakaraang modelo, ang pagbuo ng isang mataas na kalidad na imahe ay kumakatawan sa paggamit ng humigit-kumulang 1,000 hanggang 1,500 na output token.
Batay sa presyo ng $30 bawat milyong output na token, ang tunay na gastos sa pagbuo ng isang imahe ay nasa pagitan ng $0.03 hanggang $0.045 (katumbas ng halos ¥2 hanggang ¥3).
Kung hindi mo kailangan ang real-time response, kundi gamitin ang Batch API mode na ibinibigay ng opisyal, bababa pa ang presyo nito ng kalahati (ang output ay bababa agad sa $15.00).
Sa pagkalkula, ang pinakamababang gastos para sa pagbuo ng isang imahe ay lamang ng higit sa 10 sentimos.
Sapat na ang presyo ng isang single na ito para sa halaga, ngunit ang totoong panao nito ay ang cached inputs sa price list.
Kahit na nagpapagawa ka ng komiks o disenyo ng poster sa isang serye, bawat pag-generate muli, kailangan mong i-upload muli ang malaking bilang ng mga reference ng karakter, maikling pagsisimula, at mahabang prompt, kaya mataas ang input cost.
Ngunit sa kasalukuyang token-based billing system, kapag ipinapagawa mo ang paggawa ng 8 magkakasunod na komiks nang isang beses, ang mga visual element ng unang imahe ay diretso nang i-cached bilang konteksto.
Mula sa ikalawang larawan, ang gastos sa pag-input ng imahe ay bumagsak nang direkta mula sa $8.00 patungo sa $2.00 (o kaya'y tanging 25% ang kinukuha).
Ibig sabihin nito, sa paggawa ng malalaking komersyal na batch ng mga imahe, o sa paghingi ng napakataas na pagkakatulad ng mga karakter sa patuloy na pagbuo, ang marginal na gastos nito ay lalabas nang mabilis.
Mas maliit ang gastos kada imahe habang mas matalino ang modelo at mas maraming imahe ang nililikha.
Ang industrialisadong sistema ng pagbabayad ay ang tunay na bagay na magpapabagsak sa mga manggagawa sa produksyon.
PART.05 Paglilinaw sa Likod ng Team
Sa huli, balik tayong tingnan ang OpenAI’s internal visual dream team na nagpakita sa live launch event—maraming mga function na dati ay tila hindi makatotohanan, ngayon ay ganap nang naiintindihan.
Halimbawa, paano ito lutasin ang mga komplikadong layout sa maraming wika at mga suliranin sa pagkakasulat.
Hindi ito posible nang walang si Gabriel Goh, ang karanasan na siyentipiko sa timbang.

Sa larangan ng akademya, ang kanyang pinakakilala na papel ay bilang pangunahing may-akda ng revolutionary na multimodal na modelo na CLIP.
Ang CLIP ay nagtatag ng pundasyon para sa modernong AI na maunawaan kung paano nakakatugma ang mga pixel ng imahe sa human language.
Sa pamumuno ng isang eksperto sa cross-modal semantic mapping, ang GPT-Image-2 ay hindi na nagtatantiya ng anyo ng teksto, kundi talagang sumusulat sa antas ng pixel.
Halimbawa, paano ito nakakaintindi ng mga ugnayang tatlong dimensyon, kahit na makagawa ng 360-degree panoramic images na may extremo na aspect ratio, at nakakaintindi pa ng mga detalyeng mikro ng liwanag at anino sa isang butil ng bigas.
Ito ay dahil sa isa pang pangunahing miyembro, Alex Yu.

Bago siya sumali sa OpenAI, siya ay co-founder at dating CTO ng star startup sa larangan ng 3D generation, ang Luma AI, at isang lider na scholar na nakatuon sa 3D neural rendering (tulad ng NeRF).
May kanya, ang GPT-Image-2 ay talagang lumampas sa tradisyonal na pagpinta ng 2D pixel.
Malamang ay unang nilikha niya ang isang 3D na eksena sa isip, inayos ang ilaw, at pagkatapos ay inirender ang isang akurat na 2D na slice para sa iyo.
Paano natutupad ang napakakatakot na pagkakatugma ng maraming pahina sa komiks.
Ito ay tumutukoy sa bagong magkakapatid na nagtapos mula sa Massachusetts Institute of Technology (MIT CSAIL):
Boyuan Chen (kaliwa) at Kiwhan Song (kanan).
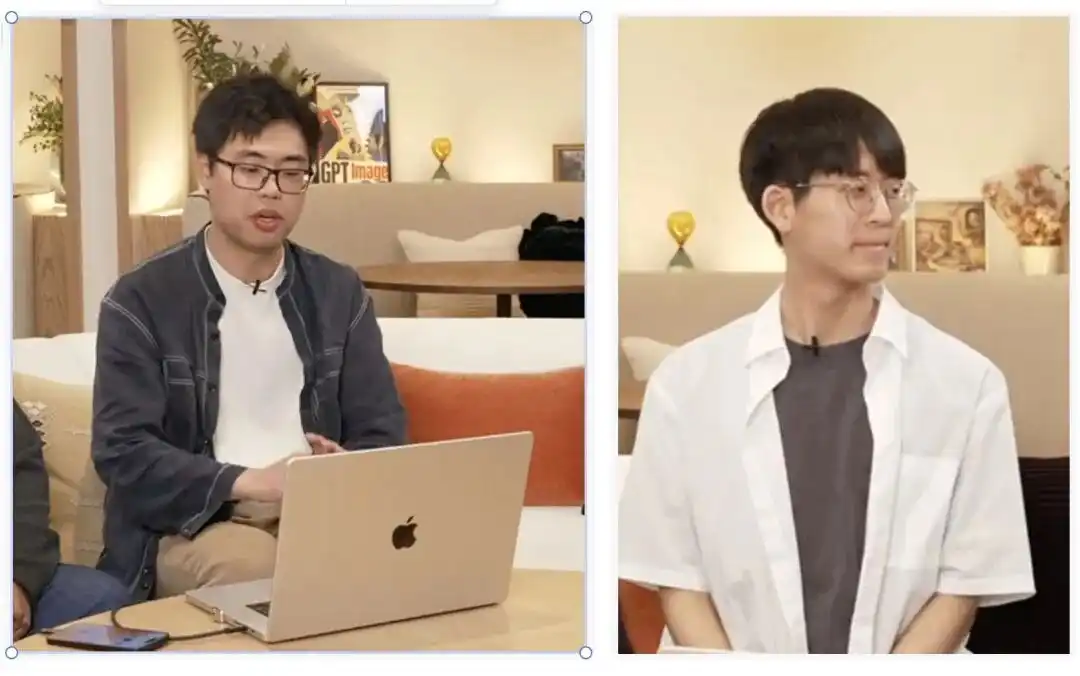
Ang kanilang pangunahang direksyon sa akademya ay ang World Models at embodied intelligence.
Ang pagtuturo sa mga makina kung paano gumagana ang pisikal na mundo, upang panatilihin ang mga karakter na may parehong mga katangian at walang pagbabago sa anyo sa iba’t ibang panahon at espasyo, ay eksaktong ang problema na sinusubukan nilang lutasin ng dalawang propesor.
Huling hinihingi, idagdag ang Nithanth Kudige (kaliwa, mahalagang may-akda ng O-series inference model) at Kenji Hata (kanan, dating researcher sa Google, graduate ng Stanford Vision Lab), na patuloy na nagtatrabaho upang i-connect ang mga malaking inference model sa mga pangunahing lohika ng visual.

Kapag nagkakasama ang grupo na ito, ang pangunahing lohika, ang 3D space rendering, ang perpektong pagkakasunod-sunod ng teksto at imahe, at ang mga batas ng pisikal na mundo, ay natutuloy na isinama sa isang parehong modelo.
PART.06 Ang hangganan ng GPT-Image-2
May hangganan ang anumang modelo.
Admitido rin ng opisyal na nagkakaroon pa rin ito ng mga problema sa pagharap sa ilang ekstremong sitwasyon.
Halimbawa, ang mga gabay sa pagpapalipat ng papel na nangangailangan ng malalim na pagbabalik-tanaw sa pisikal na espasyo, paglutas ng Rubik’s Cube, o mga detalye na may mataas na pag-uulit tulad ng napakadikit-dikit na buhangin, ay patuloy na makakatagpo ng mga limitasyon nito.
Ngunit sa konteksto ng komersyal na aplikasyon, ito ay isang napakaliit na kamalian.
Para sa buong industriya ng disenyo, hindi natin kailangang magbenta ng pagkatakot; ito ay hindi nagpapakita ng pagkawala ng pagkamalikhain.
Ang mga taong may galing, may pananaw sa negosyo, at nakakaunawa sa estratehiya, ay patuloy na makakagawa ng napakagandang mga bagay dito.
Ngunit ang obhetibong katotohanan ay ang pagiging isang propesyon ng designer ay na-degrade nang malalim.
Noong nakaraan, nakabatay sa pagkakaroon ng memorya sa mga shortcut ng design software, pag-unawa kung paano i-align nang patayong at pahalang ang mga font, pag-unawa kung paano i-layout ayon sa wika, at pagkakaroon ng kasanayan sa detalyadong pag-edit at pag-aalis ng background.
Ngayon naman, mas mahirap na, dahil ang mga kasanayan na dati ay maaaring ibenta nang malinaw para sa pagtinda, ay naging mga pangunahing utos na maaaring i-call ng sinuman nang libre sa pamamagitan ng isang pangungusap.
Matapos ang isang panahon ng pagkakasunog, ginamit ng OpenAI ang isang napakapayat, ngunit napakalakas na paraan upang muli itong patunayan na siya ang may tunay na mga card sa mesa.
Ang lumang chain ng mga kasangkapan sa pagpapatupad ay nagsisira na; ang tanong na natitira sa industriya ay hindi na kung gagawin ba ng AI ang pagpapalit sa atin, kundi kung paano natin aangkop ang bagong linya ng produksyon.