










Managsadula | ZeR0, Smart Things
I-edit | Walang Silbi
Ayon sa report ng Xindongxi sa Las Vegas no Enero 5, kahapon, ginawa ni Jensen Huang, ang co-founder at CEO ng NVIDIA, ang kanyang unang keynote speech para sa CES 2026. Katulad ng dati, nagsuot si Huang ng leather jacket at inilathala ang 8 pangunahing paglulunsad sa loob ng 1.5 oras, mula sa mga chip, rack hanggang sa network design, at nagbigay ng detalyadong paliwanag tungkol sa buong bagong henerasyon ng platform.

Sa larangan ng accelerated computing at AI infrastructure, inilabas ng NVIDIA ang NVIDIA Vera Rubin POD AI supercomputer, ang NVIDIA Spectrum-X Ethernet co-packaged optics, ang NVIDIA Inference Context Memory Storage platform, at ang NVIDIA DGX SuperPOD na batay sa DGX Vera Rubin NVL72.

Ang NVIDIA Vera Rubin POD ay gumagamit ng anim na inilimbag na microchip ng NVIDIA, kabilang ang CPU, GPU, Scale-up, Scale-out, imbakan at kakayahang kumopya, lahat ng mga bahagi ay idinesinyo nang magkasama upang matugunan ang mga pangangailangan ng advanced na modelo at mabawasan ang gastos sa kompyuter.
Ang CPU ng Vera ay gumagamit ng isang custom na arkitektura ng Olympus, habang ang GPU ng Rubin ay may Transformer engine kung saan ang NBFP4 inference performance ay hanggang 50 PFLOPS, may NVLink bandwidth ng hanggang 3.6 TB/s bawat GPU, at sumusuporta sa ikatlong henerasyon ng universal confidential computing (unang rack-level TEE), na nagbibigay ng isang buong trusted execution environment sa pagitan ng CPU at GPU.

Ang lahat ng mga chip ay naipadala na, at na-verify na ng NVIDIA ang buong NVIDIA Vera Rubin NVL72 system, at nagsisimulang gumana ang mga kasosyo sa kanilang sariling AI model at algorithm, at naghahanda na ang buong ecosystem para sa deployment ng Vera Rubin.
Sa iba pang mga paglulunsad, ang NVIDIA Spectrum-X Ethernet na may optical na pagsasama ay nagpapabuti ng kahusayan ng kuryente at oras ng normal na operasyon ng mga aplikasyon; ang NVIDIA Inference Context Memory Storage Platform ay nagbabago ng stack ng imbakan upang bawasan ang redundant na kompyutasyon at palakihin ang kahusayan ng inference; at ang NVIDIA DGX SuperPOD na batay sa DGX Vera Rubin NVL72 ay nagbaba ng gastos sa token ng malalaking MoE modelo hanggang 1/10.

Sa aspeto ng open model, inanunsiyo ng NVIDIA ang pagpapalawig ng kanilang open-source model family, na kabilang ang mga bagong modelo, dataset, at library, tulad ng pagdaragdag ng mga agentic RAG model, seguridad model, at voice model sa NVIDIA Nemotron open-source model series, pati na rin ang paglulunsad ng mga ganap na bagong open model para sa lahat ng uri ng robot. Gayunpaman, hindi personal na inilahad ni Jensen Huang ang mga detalye nito sa kanyang talumpati.
Sa aspeto ng AI,Narating na ang ChatGPT sandali para sa AI na may kinalaman sa pisikaAng NVIDIA full-stack na teknolohiya ay nagbibigay-daan sa pandaigdigang ekosistema upang muling ilarawan ang mga industriya sa pamamagitan ng robotika na idinisenya ng AI; Ang malawak na toolset ng AI ng NVIDIA, kabilang ang bagong pangunguna ng modelo ng Alpamayo, ay nagbibigay-daan sa pandaigdigang industriya ng transportasyon upang mabilis na makamit ang ligtas na pagmamaneho ng L4; Ang NVIDIA DRIVE autonomous na platform ay nasa produksyon na at kasalukuyang inilalagay sa lahat ng bagong Mercedes-Benz CLA para sa L2++ na AI-defined na pagmamaneho.

01. Bagong AI Supercomputer: 6 na custom chip, 3.6 EFLOPS na computing power sa isang server rack
Ayon kay Jensen Huang, ang industriya ng computer ay nagkakaroon ng isang malaking pagbabago bawat 10 hanggang 15 taon, ngunit ngayon, ang dalawang pagbabago sa platform ay nangyayari nang sabay-sabay, mula sa CPU papunta sa GPU, at mula sa "software programming" papunta sa "training software", kung saan ang accelerated computing at AI ay nagbabago ng buong stack ng computing. Ang industriya ng computing na may halaga ng 10 trilyon dolyar sa nakaraang sampung taon ay nasa gitna ng isang modernisasyon.
Samantala, ang pangangailangan para sa computing power ay bumagal din ng mabilis. Ang laki ng mga modelo ay lumalaki ng sampung beses kada taon, ang bilang ng mga token na ginagamit ng mga modelo para sa pag-iisip ay lumalaki ng limang beses kada taon, at ang presyo ng bawat token ay bumaba ng sampung beses kada taon.
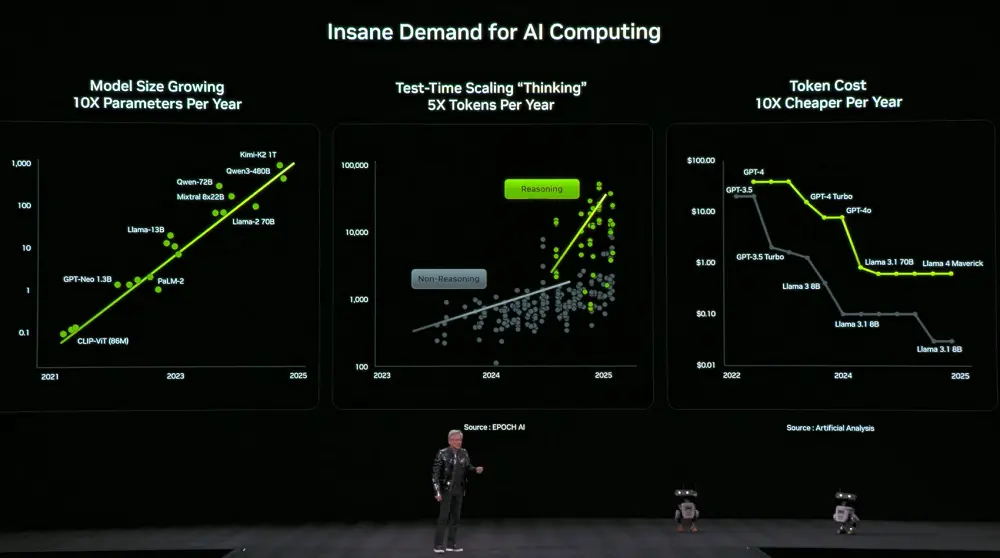
Upang tugunan ang pangangailangan na ito, nagpasya ang NVIDIA na maglabas ng mga bagong kagamitan sa pagkalkula tuwing taon. Inilabas ni Jensen Huang na buksan na ngayon ng Vera Rubin ang buong produksyon.
Ang bagong AI supercomputer ng NVIDIA na NVIDIA Vera Rubin POD ay gumagamit ng anim na sariling ginawa nitong mga chip: Vera CPU, Rubin GPU, NVLink 6 Switch, ConnectX-9 (CX9) smart NIC, BlueField-4 DPU, at Spectrum-X 102.4T CPO.
Vera CPU:Ginawa para sa paggalaw ng data at pagproseso ng mga agent, mayroon itong 88 na Nvidian na custom na Olympus core, 176-thread na Nvidian na spatial multi-threading, 1.8TB/s NVLink-C2C na suporta sa CPU:GPU na pagsasama ng memorya, hanggang 1.5TB na system memory (3 beses na laki ng Grace CPU), 1.2TB/s na SOCAMM LPDDR5X memory bandwidth, at suportado ang rack-level confidential computing, na nagpapalakas ng dalawang beses ng data processing performance.

Rubin GPU:Inilunsad ang Transformer engine, ang NVFP4 inference performance ay umabot sa 50PFLOPS, 5 beses na mas mabilis kumpara sa Blackwell GPU, may backward compatibility, nagpapataas ng BF16/FP4 performance habang nananatiling pareho ang inference accuracy; ang NVFP4 training performance ay umabot sa 35PFLOPS, 3.5 beses na mas mabilis kumpara sa Blackwell.
Ang Rubin ay ang una ring platform na sumusuporta sa HBM4, na may bandwidth na 22TB/s, 2.8 beses mas mataas kaysa sa nakaraang henerasyon, at maaaring magbigay ng kinakailangang performance para sa mga mahigpit na MoE model at AI workload.

NVLink 6 Switch:Ang bawat lane ay mayroon nang 400Gbps throughput, na ginagamit ang SerDes technology para sa mataas na bilis ng signal transmission; Ang bawat GPU ay mayroon 3.6TB/s na buong koneksyon bandwidth, dalawang beses ng nakaraang henerasyon, ang kabuuang bandwidth ay 28.8TB/s, ang in-network computing performance sa FP8 accuracy ay 14.4TFLOPS, at suportado ang 100% liquid cooling.

NVIDIA ConnectX-9 SuperNIC:Ang bawat GPU ay nagbibigay ng 1.6 Tb/s bandwidth, na mayroon optimized para sa malalaking AI, na may ganap na software-defined, programmable, accelerated data path.

NVIDIA BlueField-4:800Gbps DPU para sa mga intelihenteng network adapter at storage processor, may 64-core Grace CPU, na pagsasama ng ConnectX-9 SuperNIC, para sa pag-unload ng mga gawain sa network at storage, habang pinapalakas ang kakayahan sa seguridad ng network, ang kumpletong kumpletong kumpletong kumpletong kumpletong kumpletong kumpletong kumpletong kumpletong kumpletong kumpletong kumpletong kumpletong kumpletong kumpletong kumpletong kumpletong kumpletong kumpletong kumpletong kumpletong kumpletong kumpletong kumpletong kumpletong kumpletong kumpletong kumpletong kumpletong kumpletong kumpletong kumpletong kumpletong kumpletong kumpletong kumpletong kumpletong kumpletong kumpletong kumpletong kumpletong kumpletong kumpletong kumpletong kumpletong kumpletong kumpletong kumpletong kumpletong kumpletong kumpletong kumpletong kumpletong kumpletong kumpletong kumpletong kumpletong kumpletong kumpletong kumpletong kumpletong kumpletong kumpletong kumpletong kumpletong kumpletong kumpletong kumpletong kumpletong kumpletong kumpletong kumplet

NVIDIA Vera Rubin NVL72:Nagawa'y isisipat ang lahat ng mga komponent na ito sa isang system-level na single-rack na system na may 200 bilyon na transistor, 3.6 EFLOPS na NVFP4 inference performance, at 2.5 EFLOPS na NVFP4 training performance.
Ang LPDDR5X memory capacity ng system ay 54TB, 2.5 beses na mas malaki kaysa sa dating. Ang kabuuang HBM4 memory ay 20.7TB, 1.5 beses na mas malaki kaysa sa dating. Ang HBM4 bandwidth ay 1.6PB/s, 2.8 beses na mas malaki kaysa sa dating. Ang kabuuang vertical expansion bandwidth ay 260TB/s, lumampas sa kabuuang bandwidth scale ng pandaigdigang internet.

Ang sistema ay batay sa ika-3 na henerasyon ng disenyo ng MGX rack, kung saan ang mga computasyon na tray ay may modular, walang host, walang kable at walang paliguan. Dahil dito, ang bilis ng pag-aassemble at pagpapanatili ay 18 beses mas mabilis kumpara sa GB200. Ang orihinal na 2 oras ng pag-aassemble ay kaya ngayon gawin sa loob ng 5 minuto. Ang orihinal na sistema ay gumagamit ng 80% na likidong cooling, ngunit ngayon ay 100% na gamit ang likidong cooling. Ang isang solong sistema ay may timbang na 2 tonelada, at kapag idinagdag ang likidong cooling, ito ay 2.5 tonelada.

Ang NVLink Switch tray ay maaaring magawa ang zero downtime maintenance at fault tolerance, kahit na ang tray ay inalis o paunlaping inilalagay, ang rack ay maaari pa ring gumana. Ang pangalawang henerasyon ng RAS engine ay maaaring gawin ang zero downtime health check.
Nagpapataas ang mga katangiang ito ng oras ng pagganap at throughput ng sistema, nagpapababa pa ngunit ng gastos sa pagsasanay at pag-iisip, at nagpapatugon sa mga pangangailangan ng data center para sa mataas na katiyakan at mataas na mapagkukunan.
May higit sa 80 na mga kasunduan ng MGX ang handa nang suportahan ang deployment ng Rubin NVL72 sa mga network ng hyperscale.
02. Malaki ang pagpapabuti ng tatlong bagong produkto sa kahusayan ng AI reasoning: Bagong CPO device, Bagong context storage layer, Bagong DGX SuperPOD
Samantala, inilabas ng NVIDIA ang tatlong pangunahing produkto: ang NVIDIA Spectrum-X Ethernet co-packaged optics, ang NVIDIA Inference Context Memory Storage Platform, at ang NVIDIA DGX SuperPOD na batay sa DGX Vera Rubin NVL72.
1. NVIDIA Spectrum-X Ethernet na may kasamang optik na disenyo
Ang NVIDIA Spectrum-X Ethernet co-packaged optics ay batay sa arkitekturang Spectrum-X, na may disenyo ng dalawang chip, na gumagamit ng 200Gbps SerDes, at bawat ASIC ay maaaring magbigay ng 102.4Tb/s bandwidth.
Ang palitan ay binubuo ng isang 512-port na mataas na density system at ng isang 128-port na kompakto system, at ang bawat port ay may bilis na 800Gb/s.

Ang CPO (Co-Packaged Optics) switching system ay nagbibigay-daan sa 5 beses na pagtaas ng koryenteng kahusayan, 10 beses na pagtaas ng kahusayan ng kasiyahan, at 5 beses na pagtaas ng oras ng normal na operasyon ng application.
Ito ay nangangahulugan ng mas maraming token ang maaaring maproseso araw-araw, na nagpapababa pa ng kabuuang gastos sa pagmamay-ari ng data center (TCO).
2. NVIDIA Inference Context Memory Storage Platform
Ang NVIDIA Inference Context Memory Storage Platform ay isang AI-native storage infrastructure sa antas ng POD na ginagamit para iimbak ang KV Cache, batay sa BlueField-4 at Spectrum-X Ethernet acceleration, na may malapad na ugnayan sa NVIDIA Dynamo at NVLink, na nagpapahintulot sa kooperatibong pagpapatakbo ng memorya, imbakan, at network para sa pagkakasunod-sunod ng konteksto.
Ang platform na ito ay nagtrato ng konteksto bilang unang klase ng data type, na nagbibigay-daan sa 5 beses mas mabilis na pag-iisip, 5 beses mas mahusay na kahusayan.

Mahalaga ito para sa pagpapabuti ng multi-turn na pag-uusap, RAG, agensikong multi-step na pag-iisip at iba pang mga application na may mahabang konteksto, kung saan ang mga gawain ay napapailalim sa kakayahang epektibong iimbak, gamitin muli at ibahagi ang konteksto sa buong sistema.
Nag-e-evolve ang AI mula sa chatbot papunta sa Agentic AI, na kaya mag-reason, mag-call ng mga tool, at pangangalagaan ang estado nang matagalan. Ang mga konteksto ay nadagdagan na hanggang sa milyon-milyon na token. Ang mga konteksto na ito ay naka-store sa KV Cache. Ang bawat hakbang na i-recompute ay isang pag-aaksaya ng oras ng GPU at nagdudulot ng malaking delay, kaya kailangan itong i-store.
Angunit ang GPU memory ay mabilis ngunit limitado, ang tradisyonal na network storage ay masyadong mababa ang kasanayan para sa maikling terminong konteksto. Ang bottleneck ng AI inference ay nagmula sa kompyutasyon papunta sa kontekstong imbakan. Kaya kailangan ng isang bagong uri ng memory layer na nasa pagitan ng GPU at imbakan na espesyal na ginawa para sa inference.

Ang layer na ito ay hindi na isang pagkukusa pagkatapos ng kaganapan, kundi dapat itoy idisenyo nang magkasama sa network storage upang maganap ng paggalaw ng konteksto sa pinakamababang gastos.
Ang NVIDIA Inference Context Memory Storage Platform, isang nagsisimula nang bagong antas ng imbakan, ay hindi direktang matatagpuan sa host system, kundi konektado sa labas ng computing device sa pamamagitan ng BlueField-4. Ang pangunahing bentahe nito ay mas maaasahan at mas mabilis na ma-expand ang scale ng imbakan pool, kaya maiiwasan ang redundant na pagkalkula ng KV Cache.
Nagkakaalo-alo na ang NVIDIA sa kanyang mga kaalyadong nagtataguyod ng imbakan upang mag-introduce ng NVIDIA Inference Context Memory Storage Platform sa Rubin platform, kaya't maaari ngayon ng mga customer itong i-deploy bilang bahagi ng kanilang kumpletong at inilalagay na AI na istruktura.
3. NVIDIA DGX SuperPOD na batay sa Vera Rubin
Sa antas ng sistema, ang NVIDIA DGX SuperPOD ay isang blueprint para sa malawakang AI factory deployment, na gumagamit ng walong (8) unit ng DGX Vera Rubin NVL72 system, na pinalawak nang vertical gamit ang NVLink 6, pinalawak nang horizontal gamit ang Spectrum-X Ethernet, mayroon ding built-in na NVIDIA inference context memory storage platform, at na-verify na sa pamamagitan ng engineering.
Inilulutas ng NVIDIA Mission Control software ang buong sistema para sa maximum na kahusayan. Maaari itong i-deploy bilang isang turnkey platform kung saan maaaring gawin ng mga customer ang kanilang mga gawain sa pagsasanay at pagpapalagay gamit ang kaunting GPU.
Ang Rubin platform ay nagawa nang mabawasan ang gastos sa pagsasanay at pagpapasiya dahil sa perpektong kooperasyon sa disenyo sa lahat ng 6 na chip, tray, rack, Pod, data center, at software. Kumpara sa naging Blackwell, kailangan lamang ng 1/4 na bilang ng GPU para magsanay ng parehong laki ng MoE model. Sa parehong antas ng delay, ang gastos ng token para sa malalaking MoE model ay nabawasan hanggang 1/10.
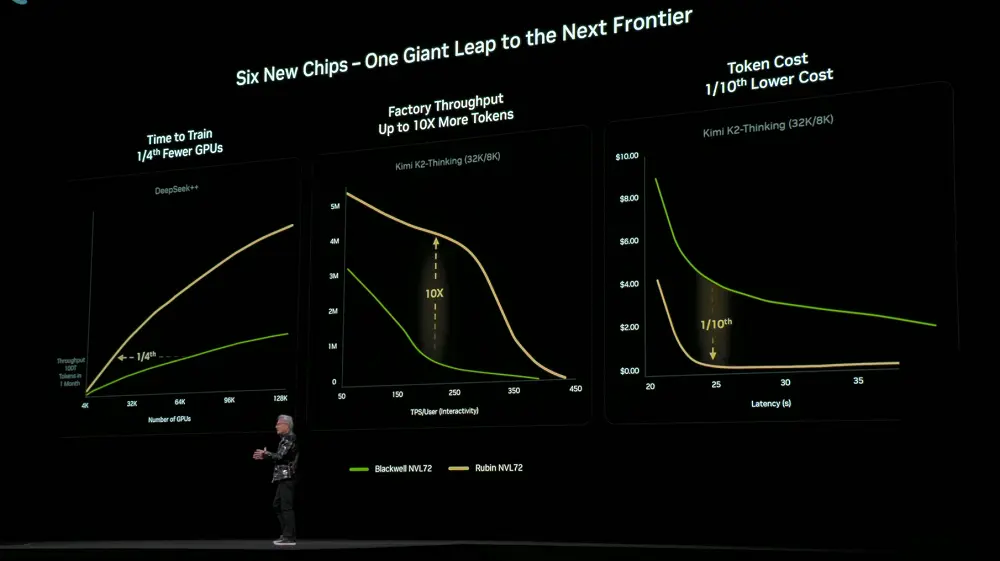
Kasama rin sa paglulunsad ang NVIDIA DGX SuperPOD na mayroong sistema ng DGX Rubin NVL8.
Gamit ang arkitekturang Vera Rubin, nagtatrabaho ang NVIDIA kasama ng kanyang mga kasosyo at customer upang magmungkahi ng pinakamalaking, pinakamoderno, at pinakamura na AI system sa mundo upang mapabilis ang paggamit ng AI.

Sisiglaan ng Rubin ang kanyang infrastructure sa pangalawang kalahati ng taon sa pamamagitan ng mga kumpanya ng cloud service provider at system integrator, kung saan ang Microsoft at iba pa ay maging una sa pag-deploy.
03. Pinalawig ang Open Model Universe: Mga bagong modelo, data, at mahalagang ambag ng open-source ecosystem
Sa antas ng software at modelo, patuloy na tinataguyod ni Nvidia ang pagpapalakas ng open source.
Nagpapakita ang mga pangunahing platform para sa pagbuo tulad ng OpenRouter na noong nakaraang taon, ang paggamit ng AI model ay lumaki ng 20 beses, kung saan ang 1/4 ng token ay galing sa mga open-source model.
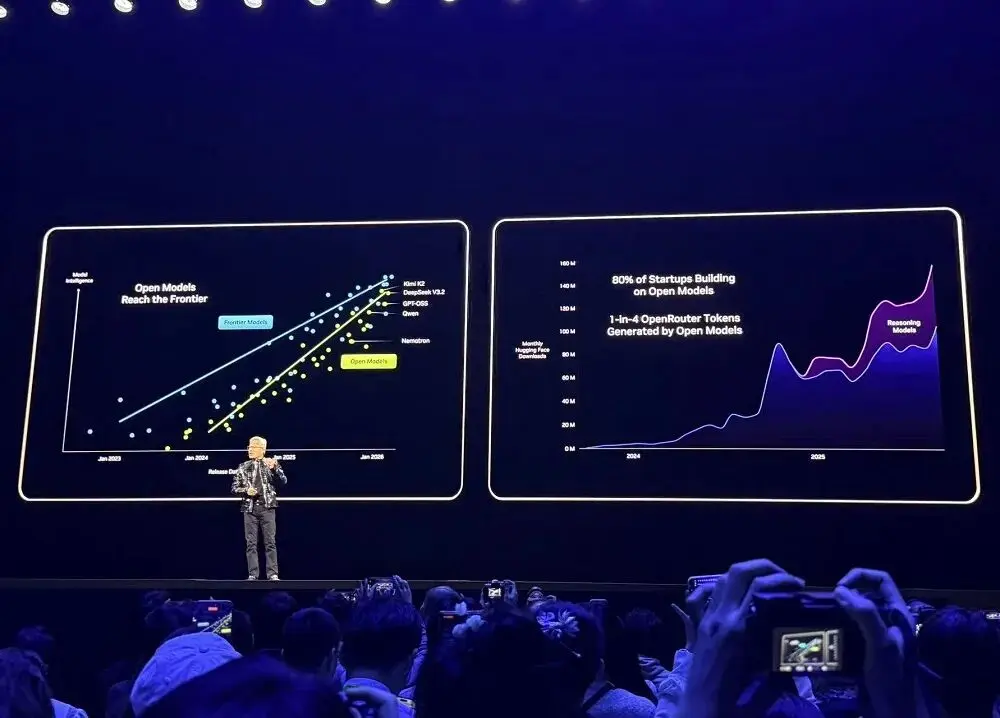
Noong 2025, ang NVIDIA ay naging pinakamalaking ambag ng modelo, data, at reseta sa Hugging Face, na may 650 modelo at 250 dataset na nai-publish.

Nasaunaan sa maraming mga listahan ng ranggo ang open-source na modelo ng NVIDIA. Maaari hindi lamang gamitin ng mga developer ang mga open-source na modelo na ito, kundi maaari silang mag-aral mula rito, magpadaloy ng pagsasanay, palawakin ang dataset, at gumamit ng mga open-source na tool at dokumentadong teknolohiya upang bumuo ng mga sistema ng AI.

Nakita ni Jensen Huang na ang mga Agent ay dapat maging multi-model, multi-cloud, at hybrid cloud, na isang pangunahing arkitektura ng mga agentic AI system, na kung saan ang halos lahat ng startup ay nagsisimula.
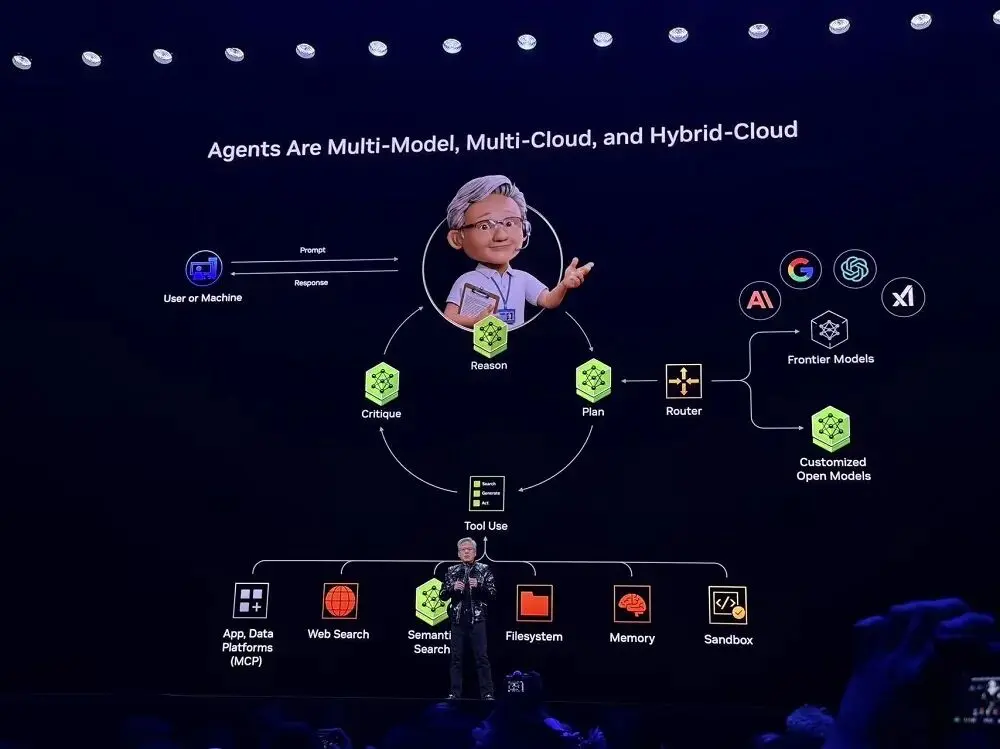
Sa tulong ng mga modelo at tool na open source na inaalok ng NVIDIA, maaari ngayon ang mga developer na i-customize ang mga system ng AI at gamitin ang mga abilidad ng mga modelo na nasa pinakabagong teknolohiya. Ang mga framework na ito ay na-imbento ng NVIDIA bilang "blueprint" at inilagay sa loob ng isang platform ng SaaS. Maaari ng gumamit ng blueprint ang mga user para sa mabilis na deployment.
Sa mga halimbawa ng live demonstration, maaari itong awtomatikong masuri ng system kung ano ang dapat gawin batay sa layunin ng user, kung ano ang gagawin ng lokal na pribadong modelo o ang modelo ng cloud edge, maaari ding i-call ang mga panlabas na tool (halimbawa, email API, robot control interface, kalendaryo service, atbp.), at maaari itong gawin ang multi-modal fusion, at magtrabaho ng magkasamang impormasyon tulad ng teksto, boses, imahe, robot sensing signal, atbp.
Ang mga kumplikadong kakayahan na ito ay dati'y walang masabi, ngunit ngayon ay naging simpleng bagay na. Ang mga katulad na kakayahan ay magagamit na sa mga enterprise platform tulad ng ServiceNow at Snowflake.
04. Ang Open-Source Alpha-Mayo Model, nagbibigay-daan sa mga awtonomong sasakyan upang "mag-isip"
Naniniwala ang NVIDIA na ang AI at robotika ay magiging pinakamalaking segment ng consumer electronics sa buong mundo. Lahat ng mga bagay na makakagalaw ay magiging ganap na awtonomo at idinaraus ng AI.
Narating na ng AI ang mga yugto ng AI sa pagkakilanlan, generative AI, at Agentic AI, at ngayon ay pumasok na ito sa panahon ng Physical AI, kung saan ang katalinuhan ay pumapasok sa tunay na mundo, kung saan ang mga modelo na ito ay maaaring maunawaan ang mga batas ng pisika at magsagawa ng mga aksyon mula sa direktang pagkakilanlan mula sa pisikal na mundo.
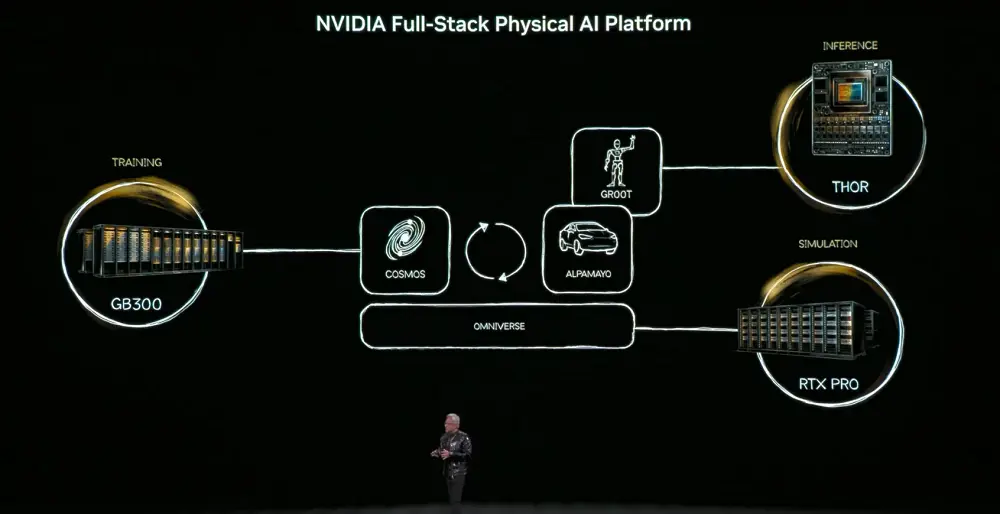
Upang makamit ang layunin na ito, kailangang matutuhan ng physical AI ang karaniwang kaalaman tungkol sa mundo - ang pagkakaroon ng mga bagay, gravity, at friction. Ang pagkuha ng mga kakayahan na ito ay nakasalalay sa tatlong computer: ang training computer (DGX) para sa paggawa ng AI model, ang inference computer (robot/car chip) para sa real-time execution, at ang simulation computer (Omniverse) para sa paggawa ng synthetic data at pagpapatunay ng physical logic.
Ang pangunahing modelo nito ay ang Cosmos World Foundation Model, na pagsasama-sama ng wika, imahe, 3D at mga batas ng pisika, at suporta sa buong link mula sa paglikha ng data ng pagsasanay.
Makikita ang AI sa pisikal sa tatlong uri ng mga bagay: mga gusali (tulad ng mga pabrika at silo), robot, at mga awtonomong sasakyan.
Naniniwala si Jensen Huang na ang autonomous driving ay maging unang malawakang aplikasyon ng AI. Ang mga system na ito ay kailangan mag-unawa sa tunay na mundo, gumawa ng mga desisyon, at isagawa ang mga aksyon, na mayroon mataas na pangangailangan sa seguridad, pag-simulate, at data.
Sa ganap na sistema na ito, inilabas ng NVIDIA ang Alpha-Mayo, isang buong sistema na binubuo ng mga modelo ng open-source, mga tool sa pag-simulate, at dataset ng AI sa pisika, para mapabilis ang seguridad at batay sa reasoning na pag-unlad ng AI sa pisika.
Ang kanyang hanay ng mga produkto ay nagbibigay ng mga batayang bloke para sa pagbuo ng mga sistema ng autonomous na antas ng L4 para sa mga global na automotive company, mga tagapagtustos, mga startup at mga mananaliksik.

Ang Alpha-Mayo ay ang unang totoo modelong nagpapagawa ng "pagnanais" sa mga awtonomong sasakyan, at ang modelong ito ay naging open source na. Ito ay nagawa ito sa pamamagitan ng paghihiwalay ng mga tanong sa mga hakbang, ang pag-iisip ng lahat ng mga posibilidad, at pagpili ng pinakaligtas na landas.

Ang ganitong uri ng modelo ng task-action na may deductive reasoning nagpapahintulot sa autonomous system na harapin ang mga komplikadong edge case na hindi pa nasikap bago, tulad ng pagkabigo ng traffic light sa isang busy na intersection.
Mayo-Alpha ay mayroon 10 bilyon na mga parameter, sapat na malaki upang harapin ang mga gawain ng autonomous driving, at sapat na maliit upang maitaguyod sa mga workstation para sa mga mananaliksik ng autonomous driving.
Nararangalan nito ang teksto, panningin ng kamera, estado ng pagmamaneho ng sasakyan at mga input ng navigasyon, at nagpapahiwatag ng mga trajectory ng sasakyan at proseso ng pag-iisip upang maintindihan ng mga pasahero kung bakit kinukuha ng sasakyan ang isang aksyon.
Sa promosyonal na palabas na ipinapalabas nang live, ang awtonomyong kotse ay maaaring gawin ang pag-iwas sa mga tao, antalaan ang mga sasakyan na tutumbok sa kaliwa at ilipat ang trayektoriya nito upang lumikha ng distansya nang walang anumang interbensyon mula sa Alpha-Mayo.

Aminin ni Jensen Huang na ang Mercedes-Benz CLA na may Alpha-Mayo ay nasa produksyon na, at kamakailan lamang ito pinagpala ng pinakamaligtas na kotse sa mundo ng NCAP. Ang bawat code, chip, at sistema ay sertipikadong ligtas. Magagamit ito sa merkado ng Estados Unidos, at maglalabas ng mas malakas na kakayahan sa pagmamaneho noong huli ng taon, kabilang ang pagmamaneho sa highway nang walang kamay, at end-to-end autonomous driving sa urban na kapaligiran.

Ang NVIDIA ay naglabas din ng ilang dataset para sa pagsasanay ng Alpha-Mayo at ng opensource na framework ng pag-evaluate ng modelo ng reasoning na Alpha-Sim. Ang mga developer ay maaaring gamitin ang kanilang sariling data upang magsagawa ng fine-tuning sa Alpha-Mayo, o maaari silang gumamit ng Cosmos upang makagawa ng synthetic data, at magsanay at subukang gamitin ang mga application ng autonomous driving batay sa kombinasyon ng tunay at synthetic na data. Bukod dito, inanunsiyo ng NVIDIA na ang NVIDIA DRIVE platform ay ngayon nasa production.
Nan-ayad ni NVIDIA nga an mga lider sa robotika sa tibuok kalibotan sugad han Boston Dynamics, Franka Robotics, Surgical Robotics, LG Electronics, NEURA, XRLabs, ug Zhejiang Qianjiang Robotics ay nahimo ha base han NVIDIA Isaac ngan GR00T.

Nagawa ni Huang Renxun ang pormal na pagsasama-sama kasama ang Siemens. Ang Siemens ay nagpapagana ng NVIDIA CUDA-X, mga modelo ng AI, at ang Omniverse sa kanyang mga tool at platform para sa EDA, CAE, at digital twin. Ang AI batay sa pisika ay gagamitin nang malawak mula sa disenyo, pagsusulit, hanggang sa produksyon at operasyon.
05. Pagsusulat ng wakas: Ang kaliwang kamay ay humahawak ng open source, ang kanang kamay ay gumawa ng hardware system hanggang sa maging kapalit.
Nangunguna na ang AI infrastructure mula sa pagsasanay patungo sa malawak na pag-iisip, ang kompetisyon sa platform ay umunlad mula sa isang puntos na kakayahan, patungo sa isang proyektong pang-system na kumakalawang sa mga microchip, rack, network at software, na may layuning magbigay ng pinakamalaking throughput ng pag-iisip sa pinakamababang TCO. Ang AI ay pumasok na sa isang bagong yugto ng "paggawa ng pabrika".
Nakatuon ang NVIDIA sa disenyo ng antas ng sistema, at inilunsad ni Rubin ang pagpapabuti ng kahusayan at ekonomiya sa parehong pagsasanay at pagmamay-ari ng impormasyon, at maaari itong maging isang alternatibong plug-and-play para sa Blackwell, na may walang sawalang paglipat mula sa Blackwell.
Sa pagpili ng platform, nananatiling naniniwala ang NVIDIA na mahalaga ang pagsasanay dahil lamang sa mabilis na pagsasanay ng mga pinaka-advanced na modelo, maaaring makakuha ng tunay na benepisyo ang platform ng pag-iisip, kaya inilabas ang NVFP4 na pagsasanay sa GPU ng Rubin upang paunlarin pa ang kahusayan at bawasan ang TCO.
Samantala, patuloy din na tinatagubilin ng kompanya ng AI computing ang kanilang arkitektura sa parehong vertical at horizontal expansion, at tinatapon ang bottleneck ng konteksto, at nagawa ang kooperatibong disenyo ng storage, network, at computing.
Ang nangungunang estratehiya ng NVIDIA na magbigay ng maraming open-source samantalang ginagawa nila ang hardware, interconection, at disenyo ng system ay "hindi palitan" pa rin, ang patuloy na pagpapalawak ng demand, pagpapalakas ng paggamit ng token, pagpapalawak ng pag-iisip, at pagbibigay ng murang at mahusay na infrastructure ay nagsisimulang maging isang mas matibay na "moat" para sa NVIDIA.