










Pinagmulan: CoinW Research Institute
Buod
Ang Gradients ay isang decentralized AI training subnet (SN56) na binuo sa Bittensor, na nakabatay sa mga mekanismo tulad ng "pagpapalabas ng task, kompetisyon ng miner, at pagpili ng validator" upang isalin ang model training mula sa isang kumplikadong teknikal na proseso sa isang network collaboration na drivern ng merkado. Sa arkitektura, ito ay nagtatagpo ng AutoML at distributed computing upang bumuo ng isang training market na nakabatay sa incentive mechanism, na hindi lamang nababawasan ang hadlang sa paggamit ng AI kundi pati na rin pinapabuti ang efficiency ng computing power. Sa pananaw ng ecosystem at data performance, natapos na ng Gradients ang pagbuo ng base network, ngunit ang current incentive weight at flow ng pondo ay relatibong limitado. Ang Gradients ay nagpapuno sa training infrastructure sa loob ng TAO ecosystem at nag-aaral ng isang bagong paradigm na "market-driven AI optimization", na may potensyal na maging mahalagang entry layer sa decentralized AI training sa mahabang panahon.
1. Magsimula sa Web2 AutoML: Kasalukuyan at mga limitasyon ng AI training
1.1 Ano ang AutoML
Sa tradisyonal na pag-unawa, ang pag-train ng isang AI model ay isang bagay na may mataas na hadlang, kung saan kailangan ng mga inhinyero na gamitin ang data, piliin ang model, paulit-ulit na ayusin ang mga parameter, at suriin ang epekto—ang buong proseso ay kumplikado at nagmumula sa maraming oras. Ang pagkakaroon ng AutoML (automated machine learning) ay nagpapakita ng pagpapakasal sa mga nakakapagod na hakbang na ito. Maaari itong maunawaan bilang isang “automated tool para gumawa ng model”: ang user ay kailangan lang magbigay ng data at sabihin sa sistema kung ano ang kanilang layunin, tulad ng paghahati, pagpapahula, o pagkilala; ang lahat ng natitirang proseso—kabilang ang pagpili ng model, pag-ayos ng parameter, at pag-train at pag-optimize—ay awtomatikong natatapos ng sistema. Ito ay nagpapalit sa AI mula sa isang kasangkapan ng kaunting propesyonal na inhinyero hanggang sa isang kakayahan na maaaring gamitin ng karaniwang developer o kahit mga negosyo, isang mahalagang hakbang patungo sa pagpapalaganap ng AI.
1.2 Ang pangunahing limitasyon ng tradisyonal na AutoML
Ang mga pangunahing implementasyon ng AutoML sa kasalukuyan ay nakatuon sa mga platform ng cloud providers, tulad ng Google Vertex AI at AWS SageMaker, na nag-aalok ng “AI Training as a Service.” Bagaman napababa ng Web2 AutoML ang hadlang sa paggamit ng AI, ang ilalim na modelo nito ay may malinaw na mga limitasyon. Una, ang sentralisasyon — ang computing power, pricing, at mga patakaran ay nasa kontrol ng platform, kaya ang mga user ay malakas na nakadepende sa isang serbisyong nagtataguyod, at walang kakayahang tawaran. Pangalawa, mataas at hindi malinaw ang gastos — ang mga GPU resource na kinakailangan para sa AI training ay pangunahing nasa kamay ng mga cloud provider, at ang mekanismo ng presyo ay kulang sa kompetisyon sa merkado. Mas mahalaga pa, may limitasyon sa efficiency ng pag-optimize. Ang tradisyonal na AutoML ay patuloy na “isang sistema na nagtutulong sa iyo upang makahanap ng pinakamahusay na solusyon,” kahit gaano pa kalaki ang kanyang kumplikado, ito ay isang optimisasyon sa isang solong teknikal na landas. Ang kanyang espasyo para sa pag-aaral ay limitado, at mahirap samantalahin ang maraming ganap na iba’t ibang ideya nang sabay-sabay. Kaya ang kasalukuyang Web2 AI training ay isang “saradong sistema,” kung saan ang pag-train, pag-optimize, at pag-schedule ng mga resource ay nangyayari sa isang kapaligiran na kontrolado ng isang solong platform. Bagaman epektibo ang modelo na ito, habang tumataas ang pangangailangan, ang mga hangganan nito ay unti-unting nagiging malinaw.
2. Gradients: Gamit ang "network" para muli pang-buo ang AI training
2.1 Ano ang Gradients: Isang decentralized na AutoML platform
Sa nakaraang kabanata, binanggit natin na ang pangunahing problema ng tradisyonal na Web2 AutoML ay ang “saradong sistema”, kung saan ang pagtatrain ng model ay nakadepende sa platform, may limitadong mga landas sa pag-optimize, at limitadong paggalaw ng mga yaman. Ang Gradients ay isang pagrereporma sa ganitong modelo. Pinagsimulan ng Gradients ang isang decentralize na komunidad ng mga inhinyero na pinamumunuan ng WanderingWeights, at itinayo sa Bittensor network bilang isang AI training subnet na tumatakbo sa Subnet 56. Sa pagkakaiba sa tradisyonal na mga platform, hindi ito nag-aalok ng sentralisadong serbisyo kundi hinati at isinagawa ang proseso ng pagtatrain sa isang bukas na network. Ang mga user ay kailangan lang magtukoy ng layunin ng gawain, tulad ng uri ng model at data, at ang lahat ng iba pang proseso—kabilang ang pagpapatupad ng pagtatrain, pag-optimize ng mga parameter, at pagpili ng mga resulta—ay awtomatikong isinasagawa ng network. Sa ganitong modelo, ang AI training ay naging isang simpleng proseso ng “pagsumite ng kahilingan, pagkuha ng resulta” mula sa isang kumplikadong inhinyeriyang proseso, at mas malapit sa isang pangkalahatang kakayahan kaysa sa isang teknikal na gawain na may mataas na hadlang.
2.2 Mula sa Isang Saradong Sistem sa Pagsasama-samang Buksan: Ano ang Solusyon ng Gradients
Ang pangunahing pagbabago ng Gradients ay ang pagbabago sa proseso ng pag-train na dating nakaputol sa isang solong platform patungo sa isang bukas at kakaibang network. Ang mga gawain sa pag-train ay hindi na natatapos ng isang solong sistema, kundi hinati sa mga maraming kalahati para sa paralel na pagsubok, at pagkatapos ay pinili ang pinakamahusay na resulta sa pamamagitan ng isang iisang mekanismo ng pag-evaluate. Ang istrukturang ito ay una nang bawasan ang pagkakadepende sa sentralisadong serbisyong nag-aalok, at nagtatayo ng pag-train sa pamamagitan ng distributed computing power; samantala, ang mga dispersed na GPU resources ay isinama sa iisang network, at sa kompetisyon ay bumubuo ng isang paraan ng pagkakabahagi ng mga yunit na mas malapit sa isang market-based approach. Mas mahalaga pa, ang pag-optimize ng model ay hindi na nakalulokal sa isang solong landas, kundi patuloy na lumalapit sa mas mahusay na solusyon sa pamamagitan ng paralel na pagsusuri ng iba’t ibang paraan, na nagpapataas sa pangkabuuang hangganan ng pag-optimize.
2.3 Pangunahing pagbabago: Mula sa kasangkapan patungo sa “pamilihan ng pagtuturo”
Sa tradisyonal na AutoML, ang platform ay mas tulad ng isang kasangkapan na tumutulong sa mga gumagamit na makahanap ng pinakamahusay na solusyon sa pamamagitan ng mga algoritmo sa loob. Sa Gradients, ang proseso ay mas malapit sa isang patuloy na gumagalaw na “market”: ang mga gumagamit ay nagpapahayag ng kanilang pangangailangan, at iba’t ibang mga kalahati ay nakikipagkompetensya sa iisang gawain, at ang mga resulta ay pinipili sa pamamagitan ng mekanismo ng pagtataya. Dahil dito, ang performance ng model ay hindi na nakasalalay sa kakayahan ng isang solong sistema, kundi mula sa patuloy na kompetensya at iterasyon mula sa maraming kalahati. Ang AutoML ay naging isang dinamikong proseso na dinudulot ng insentibo, mula sa isang relatibong sarado na teknikal na pagpapabuti, na nagpapahintulot sa pagpapalawak ng kakayahan sa pagpapabuti habang dumadami ang mga kalahati. Ang pagbabagong ito ay nagiging sanhi na ang pagtratrabaho ng AI ay nagsisimula nang magkaroon ng mga katangian ng pag-eevolbuhay na may katulad na mekanismo ng market.
2.4 Papel sa TAO ecosystem: Layer ng Infrastraktura para sa Pagsasanay ng AI
Sa loob ng subnet system ng Bittensor, iba’t ibang Subnet ang nagtataglay ng iba’t ibang tungkulin tulad ng pag-iisip, pagproseso ng data, at pagtatrain, at ang posisyon ng Gradients ay nasa antas ng pagtatrain. Ito ang naglalayong i-convert ang mga natitirang computing power sa tunay na output ng modelo, at sa pamamagitan ng mekanismo ng pagbabahagi at pag-e-evaluate ng mga gawain, pinapahintulutan nito ang mga mapagkukunan na maging patuloy na iskedyul at i-optimize. Samantala, ito ay nag-uugnay sa supply ng computing power at pangangailangan ng modelo, na nagpapalit sa pagtatrain mula sa isang simpleng proseso ng pagkawala ng mapagkukunan patungo sa isang network collaboration na maaaring ma-organisa at i-optimize. Sa loob ng sistema na ito, ang Gradients ay mas tulad ng isang sentral na bahagi na nagpapalit sa distributed resources sa magagamit na AI capability, at sumusuporta sa pag-unlad ng mga aplikasyon sa itaas.
3. Pangunahing arkitektura: Paano natututong ang AI sa network
Sa nakaraang kabanata, sinabi natin na ang Gradients ay nagpalit sa AI training mula sa “pagkumpleto sa loob ng platform” patungo sa “pagkumpleto sa pamamagitan ng network collaboration”. Paano nga ba ito gumagana? Ang pangunahing layunin ng kabanatang ito ay ipaliwanag nang mas malinaw at mas madaling maintindihan ang proseso.
3.1 Distributed Training: Paano isinasagawa ng maraming tao ang isang task
Maaaring isipin ang Gradients bilang isang patuloy na nagpapatakbo na “network ng pagtratrabaho sa pagtuturo”. Kapag isumite ng user ang isang gawain sa pagtuturo, hindi ito ibinibigay sa isang sistema lamang para maisagawa, kundi ipinapamahagi agad sa maraming kalahati sa network. Ang mga kalahati ay gumagamit ng parehong data at layunin, at subukan ang iba’t ibang paraan ng pagtuturo, at isumite ang kanilang resulta sa loob ng itinakdang oras. Pagkatapos, sinusuri ng sistema ang lahat ng resulta at pinipili ang pinakamahusay na solusyon. Ang mga mas mahusay na resulta ay nakakatanggap ng pagsuporta, habang ang iba pang solusyon ay tinanggal. Sa pananaw ng user, ang proseso na ito ay nangangailangan lamang ng isang pagpapatawag ng gawain, na katumbas ng paggamit nang sabay-sabay ng iba’t ibang paraan ng pag-optimize, at awtomatikong pinili ang pinakamahusay na solusyon. Ang pangunahing punto nito ay hindi kung gaano kalakas ang isang node, kundi sa pamamagitan ng maraming tao na nagtatry nang sabay-sabay + awtomatikong pagpili, upang patuloy na malapit sa pinakamahusay na resulta.
Sa network na ito, may tatlong pangunahing bahagi: ang mga user, ang mga miner, at ang mga validator. Ang mga user ang responsable sa paghingi ng mga pangangailangan sa pagtatrain; ang mga miner ang nagbibigay ng computing power at nagsubok ng iba’t ibang paraan ng pagtatrain; at ang mga validator ang responsable sa pag-evaluate ng mga resulta at pagpili ng pinakamahusay na model. Ang pagkakahati-hati ng mga gawain na ito ay nagpapahintulot sa proseso ng pagtatrain na magpatuloy nang tuloy-tuloy at maglinis nang patuloy ng mas mahusay na solusyon. Sa kabuuan, ito ay bumubuo ng isang kolaboratibong network na dinudurog ng “demand, supply, at evaluation.”
3.2 AutoML na idinudulot ng merkado
Sa pagkabuo ng mekanismo sa nakaraang bahagi, makikita na hindi lamang idinadala ng Gradients ang AutoML sa blockchain, kundi binago nito ang pundamental na lohika ng pag-optimize ng modelo sa pamamagitan ng pagpapakilala ng maraming bahagi at mekanismo ng insentibo. Ang tradisyonal na AutoML ay nakasalalay sa isang solong sistema upang hanapin ang pinakamahusay na solusyon sa limitadong mga path, habang sa Gradients, napapalawak ang prosesong ito sa buong network: ang iba’t ibang mga bahagi ay patuloy na sinusubukan ang iba’t ibang paraan para sa parehong gawain, at pinipili at iinomulang muli sa pamamagitan ng isang magkakasunod na pagtataya. Nagiging hindi isang isang beses na proseso ng komputasyon ang pag-optimize ng modelo, kundi isang dinamikong proseso na maaaring umunlad nang paulit-ulit. Sa ilalim ng mekanismong ito, ang mas mahusay na resulta ay makakakuha ng mas mataas na kita, kaya patuloy na tarik ang mga bahagi upang mapabuti ang kanilang estratehiya at palawakin ang pangkabuuang epekto.
4. Mga insentibo at mekanismo ng kompetisyon: Paano nabubuo ang “positive cycle” sa pagtatrain ng AI
4.1 Mekanismo ng Pagsuporta (TAO-driven): Mula sa pagtatrabaho hanggang sa pagkakaroon ng kita
Ang susi sa matagal na pagpapatakbo ng Gradients ay ang pagsuporta sa pagsusugal na mekanismo. Ito ay nakadepende sa orihinal na pagsusugal na sistema na ibinibigay ng Bittensor. Sa loob nito, TAO ay ang orihinal na token ng Bittensor network, na naglalaman ng “value carrier” sa buong network: isa sa mga paraan ay para sa pagbibigay ng pagsuporta sa mga kalahok na nagbibigay ng computing power at kontribusyon sa model, samantalang ang isa pang paraan ay sa pamamagitan ng staking at iba pang paraan upang makilahok sa pagkakabahagi ng weights ng subnet, na nakakaapekto kung paano lumalakad ang mga yaman sa pagitan ng iba’t ibang subnet.
Ang Bittensor mainnet ay patuloy na nagpapalabas ng bagong incentive emission na TAO (kasalukuyang mga 3,600 TAO araw-araw), at ito ay分配 sa iba't ibang subnets ayon sa mga takdang patakaran. Ang dami ng TAO na natatanggap ng bawat subnet ay nakadepende sa kanilang "performa" sa buong network, tulad ng antas ng aktibidad, kalidad ng kontribusyon, at suporta sa pondo. Para sa subnet kung saan nasa Gradients, ang natanggap na TAO ay i-didistribute muli sa loob ng subnet sa mga miyembro. Ang pangunahing batayan ng distribusyon ay kung sino ang nagbigay ng mas mabuting model—siya ang makakakuha ng mas maraming kita.
Sa mas detalyadong pagtingin, ang mga miner ang nagpapadala ng mga resulta ng pagtuturo, habang ang mga validator ang responsable sa pagsubok at pagbibigay ng puntos sa mga resultang ito. Ang sistema ay kalkulahin ang “weight ng kontribusyon” ng bawat participant batay sa kanilang mga puntos, at ibibigay ang mga reward batay sa weight na ito. Ang mas magandang modelo (tulad ng mas malakas na generalization at mas matatag na epekto) ay makakakuha ng mas mataas na kita, habang ang mga validator na mas tama sa pagbibigay ng puntos at mas nakakapagpapakita ng totoong kalidad ay makakakuha rin ng mas maraming insentibo. Ang ganitong disenyo ay direktang nag-uugnay sa “gumawa nang mas mabuti” sa “kita nang mas marami”, na nagpapagalaw sa mga participant na patuloy na mapapabuti ang kanilang mga modelo.
4.2 Kompetisyon sa pagitan ng mga subnet: Hindi lamang panloob na kompetisyon, kundi pati na ang eksternal na pagkakaroon ng ranggo
Bukod sa pakikidigma sa loob ng subnet, kinakaharap ng Gradients ang “horizontal competition” sa buong Bittensor network. Dahil sa dinamikong pagkakabahagi ng TAO, ang iba’t ibang subnet ay nagsisigawan para sa mas mataas na weight. Ang mga subnet na patuloy na nagpapakita ng mataas na kalidad at nakakakuha ng mas maraming mga kalahok ang makakakuha ng mas malaking bahagi ng reward. Kaya, ang incentive ng Gradients ay hindi lamang nakadepende sa loob na performance ng models, kundi pati na rin sa kanyang relatibong kompetisyon sa buong ecosystem. Ang buong sistema ay bumubuo ng maraming antas ng siklo: may pakikidigma sa pagitan ng models sa loob ng subnet; at may pakikidigma sa pagitan ng mga subnet batay sa kanilang pangkabuuang performance. Sa huli, ang pagpapalakas ng computing power, ang epekto ng models, at ang ekonomikong return ay nauugnay nang magkasama, bumubuo ng isang patuloy na gumagalaw na positibong feedback mechanism.
4.3 Gradients 5.0: Mula sa kompetisyon patungo sa “tournament mechanism”
Batay sa patuloy na kompetisyon sa unang yugto, lumikha ang Gradients ng mas structured na mekanismo na tinatawag na “tournament-style training.” Maaaring isipin ito bilang isang periodic na kompetisyon: sa bawat round ng pagtatrabaho, may tiyak na time window, kung saan ang maraming kalahok ay nagkakaroon ng kompetisyon sa parehong gawain, at sa pamamagitan ng maraming pagpapalit, natatanggal ang mga hindi pinakamahusay, hanggang sa makakita ng pinakamahusay na solusyon. Ito ay nagbibigay-diin sa pagkakasunod-sunod na paghahambing at pagsusuri. Mahalagang pagbabago ay ang pagkakaroon ng miner na hindi na direktang sumusubmit ng mga resulta ng pagtatrabaho, kundi ang “training method” (code), na pagkatapos ay isasagawa ng mga verification node nang iisa. Ito ay nagpapabuti sa katarungan, at nag-iwas sa mga epekto ng iba’t ibang computing environment, at mas mainam din ang pagprotekta sa data at privacy ng proseso ng pagtatrabaho. Bukod dito, ang mga panalo ay karaniwang iniiwan bilang maaaring gamitin muli na paraan, tulad ng patuloy na akumulatong “best practices.” Sa mahabang panahon, ang mekanismong ito ay hindi lamang naghahanap ng pinakamahusay na model, kundi nagtatayo rin ng isang patuloy na umuunlad na library ng mga paraan sa pagtatrabaho.
5. Kasalukuyang kalagayan ng ekosistema
5.1 Estruktura ng mga participant: Kolaboratibong network na binubuo ng demand, supply, at pagtataya
Binubuo ng ecosystem ng Gradients ang tatlong uri ng pangunahing papel: mga user (demand side), mga miner (supply side), at mga validator (evaluation side). Ang mga user ay pangunahin ang mga AI developer, mga maliit at katamtamang negosyo, at mga Web3 builder, na karaniwang mayroon ng tiyak na teknikal na kaalaman ngunit kulang sa computing power o kompletong kakayahan sa pag-train ng modelo, kaya mas pumipili sila ng Gradients upang matapos ang pagbuo ng modelo sa mas mababang gastos. Ang mga miner naman ay nagbibigay ng GPU computing power at sumasali sa kompetisyon para sa mga training task, na ang pangunahing motibasyon ay ang pagkuha ng TAO rewards; habang ang mga validator ay responsable sa pag-e-evaluate at pag-ranking ng mga resulta sa pag-train, na ang papel ay mahalaga upang siguraduhin ang kalidad ng modelo at ang epektibong paggalaw ng mekanismo.
Mula sa mas detalyadong user profile, ang aktwal na gumagamit ng Gradients ay may malinaw na “semi-developer” na katangian: hindi katulad ng mga top AI lab, ni hindi rin ganap na walang teknikal na kaalaman na karaniwang gumagamit, kundi pangunahin ang mga developer at Web3 tech users na may tiyak na engineering skills. Ito ay ipinapakita rin sa kanilang komunidad na istruktura, kung saan ang pangunahing wika ay Ingles, at ang pangunahing mga gumagamit ay nasa North America at Europe, habang kasama rin ang ilang Southeast Asian miners at global GPU providers. Sa kabuuan, ito ay malapit sa isang teknikal na developer community.
5.2 Kasalukuyang kalagayan ng ekosistema
Hanggang Mayo 12, ang presyo ng alpha token ng Gradients ay nasa paligid ng 0.0255 TAO, mayroong humigit-kumulang 4,890 na address na may mga token, 243 na minero, at 12 na validator, na may Emission na bahagdan na 1.61%. Samantala, sa kanilang liquidity pool, ang TAO ay nasa 2.19% at ang Alpha ay nasa 97.81%. Batay sa presyo at bilang ng mga nagtataglay ng token, mayroon nang tiyak na base ng mga user at pansin ang Gradients, ngunit patuloy pa itong nasa maagap yugto ng pagkalat. Kumpara sa Chutes, ang pinakamalaking proyekto sa ekosistema ng TAO, ang presyo ng alpha token nito ay 0.0877 TAO at may 13,409 na address na nagtataglay.
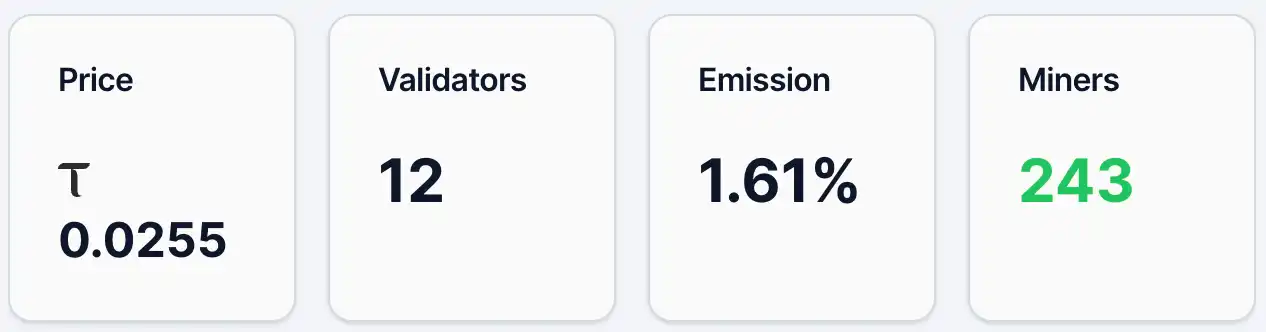
Figure 1. Mga datos ng gradients.
Source:https://bittensormarketcap.com/subnets/56
Susunod ay ang Emission incentive mechanism. Sa loob ng Bittensor system, ang Emission ay tumutukoy sa real-time na weighting ng isang subnetwork sa kabuuang bagong reward ng network. Ang Bittensor network ay patuloy na lumilikha ng bagong TAO at ito ay ibinabahagi batay sa weighting sa bawat subnetwork, at ang kasalukuyang 1.61% ng Gradients ay nangangahulugan na ito ay nakakatanggap lamang ng maliit na bahagi ng kabuuang bagong incentive ng network. Ang indikator na ito ay nagpapakita ng pagsasabay ng pamilihan sa pamamagitan ng flow ng pondo (tulad ng staking) sa iba’t ibang subnetwork. Kaya, ang antas na 1.61% ay karaniwang nangangahulugan na ang kasalukuyang pagkilala at pagdating ng pondo ay limitado, ngunit sa kabilang banda, ito ay nagpapakita rin na mayroon pa ring espasyo para sa pagtaas ng weighting sa hinaharap. Tungkol sa istruktura ng pondo (liquidity pool), ang bahagdan ng TAO ay 2.19% lamang, habang ang Alpha ay 97.81%, na nagpapakita na ang pagdating ng panlabas na pondo ay patuloy na limitado, at ang kasalukuyang supply ay mas dominado ng loob ng subnetwork. Ang presyo ay sensitibo sa bagong pondo; kung may karagdagang pagdaloy ng TAO, maaaring magdulot ito ng mas malakas na epekto.
6. Mga Kompetisyon at mga Kakayahan at Kahinaan
6.1 Pagsasakatuparan ng industriya: Pabrika ng pagtuturo para sa de sentralisadong AutoML
Ang Gradients ay nasa hiwalay na sektor ng “AI training infrastructure + decentralized AutoML.” Itinutukoy nito ang paglalabas ng model training mula sa sentralisadong platform at paggamit ng networked mechanism para sa mas epektibong paggamit ng mga yaman at pag-optimize ng mga model. Sa loob ng Web2 system, ang sektor na ito ay relatibong matatag, na may mga klasikong halimbawa tulad ng Google Vertex AI at AWS SageMaker. Ang mga platform na ito ay nag-aalok ng isang solusyon para sa model training at deployment gamit ang cloud computing, ngunit ang kanilang kalikasan ay nananatiling sentralisadong arkitektura. Sa kabilang banda, ang pagkakaiba ng Gradients ay hindi nasa “higit pang mga tampok,” kundi sa iba’t ibang pundasyonal na lohika: ito ay nagpapalit ng training mula sa “platform service” patungo sa “network collaboration,” at gumagamit ng mekanismo ng kompetisyon upang piliin ang pinakamahusay na resulta, na nagiging mas malapit sa isang market-driven training system.
6.2 Horizontal Comparison: Differences Between Web2 and Web3 AutoML
Sa mas malawak na pananaw, ang pagkakaiba ng Web2 at Web3 sa direksyon ng AutoML ay isang paghahambing ng dalawang iba’t ibang paradigma. Ang Web2 pattern ay nagtataglay ng pagkakaroon ng efisensiya at katatagan, sa pamamagitan ng pagpupuno ng mga mapagkukunan at pagpapabuti ng inhenyeriya upang magbigay ng kontrolado at matatag na karanasan sa serbisyo; samantalang ang Web3 pattern ay mas nagtataglay ng pagkakaroon ng pagkakabukas at mga mekanismo ng insentibo, sa pamamagitan ng pagpapahintulot sa maraming mga kalahati upang gawing patuloy na umunlad ang pagpapabuti ng modelo sa pamamagitan ng kompetisyon. Sa partikular, ang Web2 AutoML ay mas parang “isang makapangyarihang kasangkapan”, kung saan ang user ay ipinapasa ang kanyang gawain sa platform, at ang sistema ang nagtatapos ng paghahanap ng pinakamahusay na solusyon; samantalang ang Web3 AutoML na kinakatawan ni Gradients ay mas parang “isang bukas na merkado”, kung saan ang user ay nagpapahayag ng kanyang pangangailangan, at iba’t ibang mga kalahati ang nag-aalok ng mga solusyon, na pagkatapos ay pinipili sa pamamagitan ng mekanismo ng pagsusuri. Ang direkta epekto ng pagkakaiba na ito ay: ang unang isa ay mas matatag at kontrolado, ngunit may limitadong landas sa pagpapabuti; samantalang ang pangalawa ay may mas malawak na puwang para sa pag-aaral at mas mataas na potensyal na hangganan, ngunit mayroon pa ring espasyo para sa pagpapabuti sa katatagan at kagalingan.
6.3 Ang pagkakaiba-iba ng Gradients sa Web3
Sa kasalukuyang Web3 AI sector, ang karamihan sa mga proyekto ay nakatuon sa inference layer o AI Agent, habang ang mga proyekto na nakatuon sa “training infrastructure” ay relatiwong kaunti. Ang ilang proyekto ay subukan na i-combine ang compute network o data network upang magbigay ng training capability, ngunit sa kabuuan, ang karamihan ay nananatili sa antas ng resource scheduling o compute market. Ang pagkakaiba ng Gradients ay hindi lamang nag-aalok ng compute matching, kundi lumalawak pa sa “model optimization mechanism” mismo, sa pamamagitan ng pagpapakilala ng evaluation at competition system na nagbibigay ng kakayahan sa training process na mag-evolve nang patuloy. Ibig sabihin nito, hindi lamang ito ay naglulutas ng “kung saan galing ang compute,” kundi pati na rin ng “paano gamitin nang mas epektibo ang compute na ito.” Sa pananaw, mas malapit ang Gradients sa isang “training outcome-oriented” network kaysa sa simpleng compute market o tool platform, na ito ang pangunahing pagkakaiba nito mula sa karamihan sa Web3 AI projects.
6.4 Pangunahing kahusayan: Pagpapabuti ng epekto na dinudulot ng mekanismo
Sa kabuuan, ang pangunahing kahusayan ng Gradients ay nakikita sa kanyang disenyo ng mekanismo. Una, ito ay nagbabawas sa pagkakaroon ng mga hadlang sa pamamagitan ng abstraksiyon ng mga gawain, kaya ang mga gumagamit ay hindi kailangang malalim na makilahok sa mga kumplikadong proseso ng pagtatrabaho upang makakuha ng mga resulta ng modelo, na nagpapalawak sa potensyal na base ng mga gumagamit. Pangalawa, sa aspeto ng mga yunit, ang pagpapakilala ng distributed computing ay nagpapalaya sa pagtatrabaho mula sa isang solong cloud provider, at teoretikal na maaaring magkaroon ng mas malakas na istruktura ng gastos sa pamamagitan ng kompetisyon. Mas mahalaga pa ang pagbabago sa paraan ng pagpapabuti. Sa pamamagitan ng paralel na pagpapalawak ng maraming kalahok at pagkombinasyon ng mekanismo ng pagpili, binibigay ng Gradients isang alternatibong solusyon na iba sa tradisyonal na iisang landas ng pagpapabuti, na nagbibigay-daan sa modelo na makamit ang mas mahusay na performance sa mas maikling panahon. Ang modelo na “optimization driven by competition” ay ang pinakamahalagang kahusayan nito.
6.5 Maaaring mga hamon
May posibilidad ng instability sa kalidad ng model. Ang decentralized training ay nakasalalay sa maraming bahagi, na kahit na maaaring pataasin ang limitasyon, maaari rin itong magdulot ng pagkakaiba-iba sa resulta, at mayroong ilang kawalan ng katiyakan kumpara sa sentralisadong sistema. Susunod ay ang isyu ng enterprise-level trust. Para sa mga enterprise user, mahalaga ang data security at ang verifiability ng proseso ng training, at ang pagpapanatili ng pagkakaroon ng pagkakasiguro na hindi masisisihan ang data at ang mga resulta ay auditable sa isang decentralized environment ay patuloy na isang malaking hamon. Huli, ang pagkakabatay sa token economy. Ang paggalaw ng Gradients ay mataas na nakadepende sa incentive mechanism; kung bumaba ang吸引力 ng TAO rewards, maaaring maapektuhan ang antas ng pagkaka-partisipasyon ng miners at ang pangkabuuang aktibidad ng network. Kaya, ang kanilang pangmatagalang sustainability ay bahagya ay nakadepende kung makakabuo ba ang economic model ng isang matatag na positibong siklo.
7. Mga Hinaharap na Pag-asa: Maaari ba ang decentralized AutoML na magtagumpay?
Sa kasalukuyang yugto, nasa maagang bahagi pa ang Gradients, at ang kanyang kakayahang makamit ang tunay na tagumpay sa hinaharap ay nakasalalay sa ilang mahahalagang punto. Ang pinakamahalaga ay kung kakayahan nitong tuloy-tuloy na tarikin ang totoong pangangailangan sa pag-train, at hindi lamang ang pagkakaaliw sa pamamagitan ng insentibo; susunod naman ay ang kalidad ng modelo, kung kakayahan ng decentralized na paraan na magbigay ng matatag, kahit mas mabuting, mga resulta; at kung ang ekonomikong mekanismo ay makakabuo ng positibong siklo, upang mapanatili ang matagalang balanse sa pagitan ng suplay ng computing power at kita.
Sa mas malawak na konteksto ng industriya, ang pag-train ng AI ay naghihiwalay sa dalawang landas. Ang isa ay ang Web2 na modelo, na pinamumunuan ng mga pangunahing tech company, na nagpapalakas ng performance ng model sa pamamagitan ng pagkonsentra ng mga yaman at engineering capability, na may kalamangan sa katatagan at kagalingan; ang isa pang isa ay ang Web3 na landas na kinakatawan ng Gradients, na gumagamit ng bukas na network at incentive mechanism upang higit pang makilahok ang mga participant sa pagpapabuti ng model, at patuloy na pataasin ang kanilang limitasyon sa kompetisyon. Ang una ay “nagbuo ng mas malakas na sistema”, habang ang ikalawa ay parang “nagtatayo ng isang sariling umuunlad na network”.
Mula sa pananaw na ito, ang pag-aaral ng Gradients ay nagtatampok ng isang bagong posibilidad: ang pag-train ng AI ay hindi na lamang isang teknikal na problema, kundi isang pagkakaisa ng “computing power + data + market mechanism”. Kung makakatibay ang modelo na ito, may potensyal itong maging entry point sa pag-train ng decentralized AI at magpanatili ng mahalagang papel bilang infrastruktura sa Bittensor ecosystem. Bagaman kailangan pa ng panahon ang pagpapatotoo sa direksyong ito, ito ay nagsilbi nang magbigay ng isang iba’t ibang landas para sa AutoML.
Refers
1. Dokumentasyon ng Bittensor:https://docs.learnbittensor.org
2. Gradients website:https://www.gradients.io/
3. Gradients:https://bittensormarketcap.com/subnets/56
4. Gradients X: https://x.com/gradients_ai
5. Taostats: https://taostats.io/subnets/56/chart