









May-akda: Deep潮 TechFlow
Isang papel na sinasabing "naiiwasan ang paggamit ng memorya ng AI sa 1/6" ay nagdulot ng pagbaba ng halos $90 bilyon sa halaga ng mga kumpanya ng chip na imbakan tulad ng Micron at SanDisk noong nakaraan linggo.
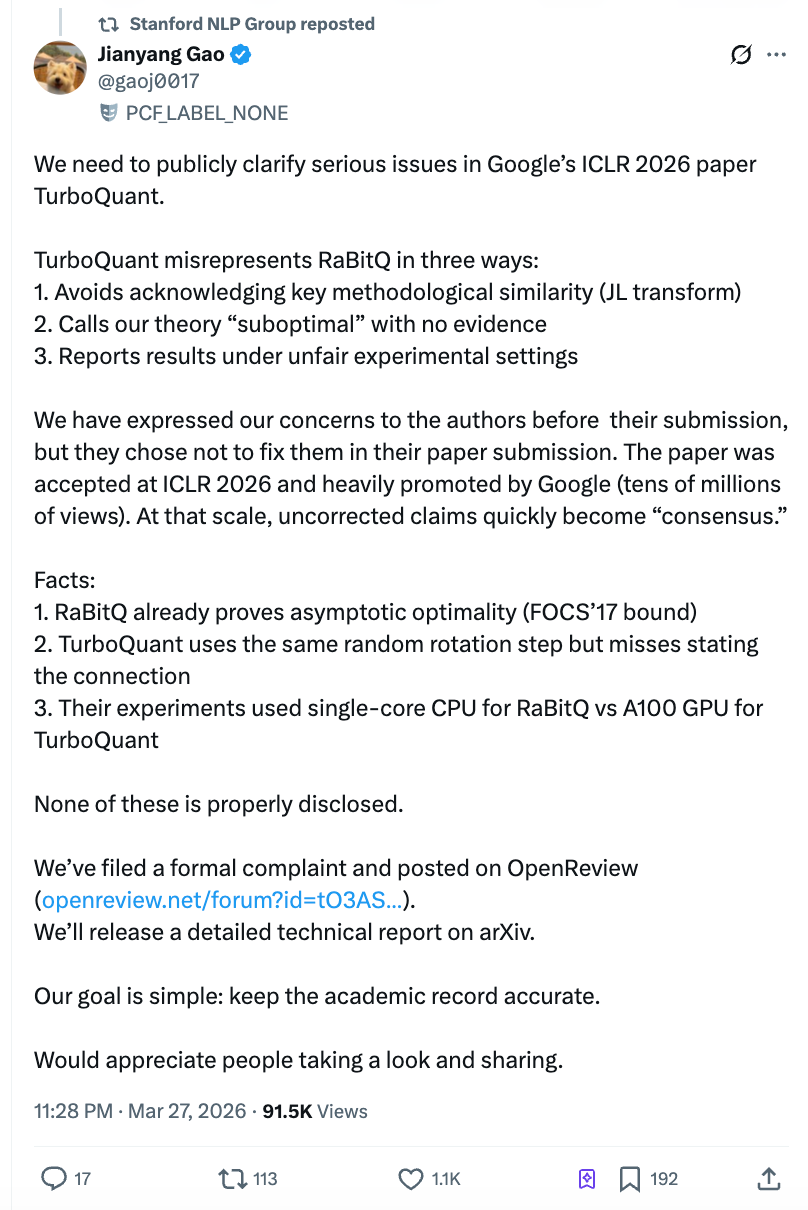
Ngunit dalawang araw lamang pagkatapos ng pagpapalabas ng papel, ang nagkakaroon ng "pagsabog" sa algoritmo—si Gao Jianyang, postdoctoral researcher sa Swiss Federal Institute of Technology Zurich—ay naglabas ng isang 10,000-salitang pampublikong liham na nag-akusang gumamit ang tim ng Google ng isang Python script na naka-run sa single-core CPU para sa pagsubok sa kanilang kalaban, samantalang gumamit sila ng A100 GPU para sa kanilang sariling pagsubok, at tinanggihan ang pagkakaroon ng pagbabago kahit na naalalahanan sila bago ang pagpapadala. Ang bilang ng mga pagbasa sa Zhihu ay agad na lumampas sa 4 milyon, at ang opisyal na account ng Stanford NLP ay nag-repost, na nagdulot ng pagkabigla sa akademya at sa merkado.
(Talaan ng pagbabasa: isang papel na nagbaba sa presyo ng mga deposito sa mga aktibo)
Hindi komplikado ang pangunahing isyu sa gera na ito: Kung ang isang AI conference paper na malawak na pinromosyon ng Google at direktang nagdulot ng panic selling sa sector ng mga chip, ay sistematikong nagmali sa isang nai-publish na nakaraang pag-aaral, at sa pamamagitan ng mga di-makatarungang eksperimento, ay naglikha ng isang maling kuwento tungkol sa isang imahinasyon na pagiging mas mabuting performa?
Ano ang ginawa ng TurboQuant: Pinatipid ang "scratch paper" ng AI hanggang sa anim na beses na mas maliit
Ang mga malalaking modelo sa wika ay kailangang sumulat habang binabale-wala ang mga naunang kalkulasyon. Ang mga intermediate result na ito ay pansamantalang naka-store sa GPU memory, at kilala sa industriya bilang «KV Cache». Mas mahaba ang usapan, mas makapal ang «scratching paper» na ito, mas malaki ang paggamit ng GPU memory, at mas mataas ang gastos.
Ang TurboQuant algorithm na nilikha ng Google research team ay nagtatampok ng pagpapaliit ng isang scrap paper sa 1/6 ng orihinal na laki, habang sinasabing walang pagkawala ng precision at pagtaas ng inference speed ng hanggang 8 beses. Ang papel ay unang inilabas sa akademikong preprint platform na arXiv noong Abril 2025, tinanggap noong Enero 2026 ng ICLR 2026, isang pinakamataas na antas na konperensya sa larangan ng AI, at muling pinakilala noong Marso 24 sa opisyal na blog ng Google.
Sa teknikal na aspeto, ang ideya ng TurboQuant ay maaaring maunawaan nang simpleng paraan: una, gamitin ang isang matematikal na pagpapalit upang i-"wash" ang mga kaguluhan na data sa isang magkakaparehong anyo, pagkatapos ay i-compress ang bawat isa gamit ang naka-una nang isinukat na pinakamahusay na tabla ng compression, at huling- huli, gamitin ang isang 1-bit na mekanismo ng pagkorekta upang ayusin ang mga pagkakamali sa kalkulasyon na dulot ng compression. Ang komunidad ay nag-implementa nang independiyente at na-verify na ang epekto ng compression ay totoo, at ang matematikal na kontribusyon sa algoritmo ay totoo.
Ang debate ay hindi kung maaari bang gamitin ang TurboQuant, kundi kung ano ang ginawa ng Google upang patunayan na ito ay “malayo sa mga kalaban.”
Open Letter ni Gao Jianyang: Tatlong akusasyon, bawat isa ay tumutok sa pusod
Sa 10:00 PM ng Marso 27, inilabas ni Gao Jianyang ang matagal na artikulo sa Zhihu at isinumite ang opisyal na komento sa ICLR Official Review Platform na OpenReview. Si Gao Jianyang ay ang pangunahing may-akda ng RaBitQ algorithm, na ipinakilala noong 2024 sa pinakamataas na konperensya sa larangan ng database, SIGMOD, at nagsosolusyon sa iisang uri ng problema—efisyenteng kompresyon ng mataas-dimensyonal na vektor.
Ang kanyang mga akusasyon ay may tatlong punto, at bawat isa ay may e-mel na rekord at timeline bilang suporta.
Akusasyon 1: Ginamit ang pangunahang paraan ng iba, walang pagbanggit sa buong artikulo.
Ang isang mahalagang karaniwang hakbang sa teknikal na core ng TurboQuant at RaBitQ ay ang paggawa ng "random rotation" sa data bago ito i-compress. Ang layunin ng hakbang na ito ay gawing maipagpalagay at uniform ang distribution ng data na orihinal na hindi regular, na nagpapababa nang malaki sa kahirapan sa pag-compress. Ito ang pinakamahalaga at pinakamalapit na bahagi ng dalawang algorithm.
Kin承认 nito ng may-akda ng TurboQuant sa kanyang pagtugon sa pagsusuri, ngunit hindi ito direktang ipinahayag sa buong papel. Mas mahalagang konteksto: noong Enero 2025, ang ikalawang may-akda ng TurboQuant, si Majid Daliri, ay aktibong nag-contact sa team ni Gao Jianyang upang humingi ng tulong sa pag-debug ng kanyang Python version na binago mula sa source code ng RaBitQ. Detalyado ang email sa mga hakbang ng pagpapakita at mga error message—ibig sabihin, malalim ang kaalaman ng team ng TurboQuant sa teknikal na detalye ng RaBitQ.
Isang anonymous na reviewer ng ICLR ay nagturo rin na pareho ang ginamit na teknolohiya, at hiningi ang sapat na pagtalakay. Ngunit sa final na bersyon ng papel, hindi lamang hindi idinagdag ng team ng TurboQuant ang pagtalakay, kundi isinilip din nila ang dating (na hindi kompletong) paglalarawan ng RaBitQ mula sa pangunahing teksto patungo sa appendix.
Ikalawang akusasyon: Walang batayan ang pagtukoy sa teorya ng kalaban bilang «pangalawang pinakamahusay».
Ang paper ni TurboQuant ay diretso ring isinama ang label na "suboptimal" sa RaBitQ dahil sa pagsasabing ang matematikal na pagsusuri ng RaBitQ ay "hindi gaanong saksak." Ngunit sinabi ni Gao Jianyang na ang extended paper ni RaBitQ ay napatunayan nang mahigpit na ang error sa compression nito ay nakamit ang mathematical optimum—ang resultang ito ay nailathala sa isang pinakamataas na antas na konperensya sa teoretikal na computer science.
Noong Mayo 2025, ang koponan ni Gao Jianyang ay nagpaliwanag nang detalyado sa pamamagitan ng maraming e-mail tungkol sa optimalidad ng teorya ng RaBitQ. Tiniyak ni Daliri, ang ikalawang may-akda ng TurboQuant, na ipinabatid na ito sa lahat ng mga may-akda. Gayunpaman, nanatili pa rin ang pahayag na “suboptimal” sa pinal na bersyon ng papel, na walang anumang pagtutol o argumento.
Kasong 3: Sa paghahambing ng eksperimento, “nakabindang kaliwang kamay, nakatutok na kutsilyo sa kanan.”
Ito ang pinakamakapagpapawi sa buong artikulo. Sinabi ni Gao Jianyang na ang papel ng TurboQuant ay nagdagdag ng dalawang hindi patas na kondisyon sa mga eksperimento ng paghahambing ng bilis:
Una, binigay ng opisyal na RaBitQ ang pinabuting C++ code (na suporta sa multi-threading ng default), ngunit hindi ito ginamit ng team ng TurboQuant; ginamit nila ang kanilang sariling isinalin na Python version upang subukan ang RaBitQ. Ikalawa, sinubukan ang RaBitQ gamit ang single-core CPU at isinara ang multi-threading, habang ginamit ng TurboQuant ang NVIDIA A100 GPU.
Ang epekto ng pagkakasunod-sunod ng dalawang kondisyon ay: ang nagresultang konklusyon na nakikita ng mambabasa ay "mas mabagal ng ilang ordeng-palakas ang RaBitQ kaysa sa TurboQuant", ngunit walang paraan para malaman na ang premisang ito ay batay sa pagkakabind ng team ng Google sa kanilang kalaban bago sila magkasya. Hindi sapat na inilahad ng papel ang mga pagkakaiba sa mga kondisyon ng eksperimento.
Sagot ng Google: "Ang random rotation ay isang pangkalahatang teknolohiya, imposible na i-cite ang bawat artikulo."
Ayon sa Gao Jianyang, sinabi ng team ng TurboQuant sa kanilang e-mail response noong Marso 2026: "Ang paggamit ng random rotation at Johnson-Lindenstrauss transform ay naging standard na teknik sa larangan na ito, at hindi namin kayang i-cite ang bawat papel na gumagamit ng mga paraan na ito."
Ang grupo ni Gao Jianyang ay naniniwala na ito ay isang pagbabago ng konsepto: ang tanong ay hindi kung kailangan mong citahin ang lahat ng mga papel na gumamit ng random rotation, kundi na ang RaBitQ ang unang pag-aaral na nag-combine ng paraan na ito sa vector compression at ipinatotohan ang optimalidad nito sa ganitong parehong problema, kaya dapat nang maayos na ilarawan ng papel ng TurboQuant ang ugnayan ng dalawa.
Ang opisyal na X account ng Stanford NLP Group ay nag-repost ng pahayag ni Gao Jianyang. Ang koponan ni Gao Jianyang ay nagsalita sa pampublikong komento sa platform ng ICLR OpenReview at nagsumite ng opisyal na reklamo sa pangulo at komite ng etika ng ICLR, at magpapalabas ng detalyadong teknikal na ulat sa arXiv sa susunod.
Ang independiyenteng tech blogger na si Dario Salvati ay nagbigay ng isang relatibong neutral na pagsusuri: may totoong kontribusyon ang TurboQuant sa matematikal na paraan, ngunit ang ugnayan nito sa RaBitQ ay mas malapit kaysa sa ipinakita sa papel.
90 bilyong dolyar ang halaga ng market na nawala: Pagkakaroon ng kontrobersya sa papel at takot sa merkado
Ang panahon ng akademikong pagtatalo ay napakasining. Pagkatapos ng Google na ipahayag ang TurboQuant sa opisyal na blog noong Marso 24, ang mga pangkat ng chip sa pag-iimbak ay nakaranas ng malakas na pagbebenta. Ayon sa mga ulat mula sa CNBC at iba pang media, bumaba ang Micron Technology nang anim na araw ng pagtutuloy-tuloy, na may kabuuang pagbaba ng higit sa 20%; bumaba ang SanDisk nang 11% sa isang araw; bumaba ang SK Hynix ng halos 6%, ang Samsung Electronics ng halos 5%, at ang Japan's Kioxia nang halos 6%. Ang lohika ng panikong merkado ay simpleng at walang komplikasyon: ang software compression ay maaaring bawasan ang pangangailangan sa memorya para sa AI inference ng 6 beses, kaya ang hinaharap na pangangailangan sa mga chip sa pag-iimbak ay maaaring mabawasan nang struktural.
Ipinaglaban ni Joseph Moore, isang analyst ng Morgan Stanley, ang lohikang ito sa isang report noong Marso 26, at nanatili sa 'buy' rating para sa Micron at SanDisk. Sinabi ni Moore na ang TurboQuant ay nag-compress lamang ng isang partikular na uri ng cache, ang KV Cache, at hindi ang kabuuang paggamit ng memorya, at isinuri ito bilang 'normal na pagpapabuti sa produktibidad'. Parehong ginamit ni Andrew Rocha, isang analyst ng Wells Fargo, ang Jevons Paradox upang ipaliwanag na ang pagpapabuti sa efficiency na nagbaba ng gastos ay maaaring magpalakas ng mas malaking pag-deploy ng AI, na sa huli ay magpapataas ng pangangailangan sa memorya.
Mga lumang papel, bagong pakete: Panganib sa chain ng transmisyong mula sa pag-aaral ng AI patungo sa kuwentong pamilihan
Ayon sa analisis ng tech blogger na si Ben Pouladian, ang papel ng TurboQuant ay ipinakalabas na noong Abril 2025 at hindi ito bagong pag-aaral. Noong Marso 24, ginawa ng Google ang pagpapakilala nito muli sa kanilang opisyal na blog, ngunit inakala ng merkado na ito ay isang bagong pagbubukas. Ang ganitong estratehiya ng “papel na lumang, bagong pagpapakilala,” kasama ang posibleng bias sa eksperimento sa papel, ay nagpapakita ng sistemikong panganib sa chain ng pagpapadala mula sa akademikong papel patungo sa kuwentong pang-merkado sa AI.
Para sa mga investor sa AI infrastructure, kapag isang papel ay nag-uugnay ng isang pagpapabuti sa performance na “mga hanay ng pagsukat,” ang unang tanong ay kung ang mga kondisyon ng benchmark ay patas.
Ang koponan ni Gao Jianyang ay nagpahayag na patuloy na magtataguyod ng pormal na paglutas ng problema. Hindi pa nagbigay ng pormal na tugon ang Google sa mga partikular na akusasyon sa bukas na liham.