









Lumabas na ang DeepSeek V4. Ito ay isang sandaling inaasam na halos limang buwan. Ang pangunahing modelo na MoE na may 1T na parameter + ang Flash version na may 285B na parameter, kasunod ng buong Pro version na 1.6T, bukas na nang buo sa GitHub sa ilalim ng Apache 2.0 license, kasama ang weights at deployment code.
Agad na ibinigay ng mga kapital na merkado ang kanilang sagot sa pamamagitan ng tatlong paraan na magkakaroon ng sariling pagkakakilanlan ngunit magkakaugnay.
Mga iba't ibang reaksyon sa kapital na merkado
Halos ng A-share computing power chain ay umabot sa malawakang pagtaas. Kumilos ang Cambricon sa 11 araw na pagtaas, tumataas ng 3.7% sa isang araw, at ang kabuuang pagtaas sa loob ng isang buwan ay lumampas sa 60%. Tumama ang Hua Guang Information sa 10%涨停 sa loob ng trading session, at nagtapos ng +8.4%. Ang SMIC A-share ay +4.91%, habang ang港股 nito ay +8.81%. Ang Hua Hong sa港股 ay nangunguna sa +18%, at nagtapos ng +12%. Ang ETF na ikinabubuhay ng chip sa science and technology board ay nakakuha ng 2.4 bilyong yuan sa isang araw, at umabot sa pinakamataas na antas sa kasaysayan.
Ang isang kahon ng mga kompanya ng malalaking modelo sa Hong Kong stock market ay may ibang kulay. Bumaba ang Zhipu (02513.HK) ng 8.07%, na may halagang 9.9% sa short selling ratio. Bumaba ang MiniMax (00100.HK) ng 7.40%, at tumaas ang short selling ratio hanggang 22.87%. Ito ay ang pinakamataas na araw-araw na short selling data sa Hong Kong AI sector sa nakalipas na tatlong buwan. Ang dalawang kompanyang ito ay mga representante ng paglulunsad ng AI sa Hong Kong stock market noong ikalawang kalahati ng 2025, at ang kanilang pangunahing kakayahan na nakasulat sa kanilang IPO prospectus ay iisang pangungusap: “self-developed foundational large model.”
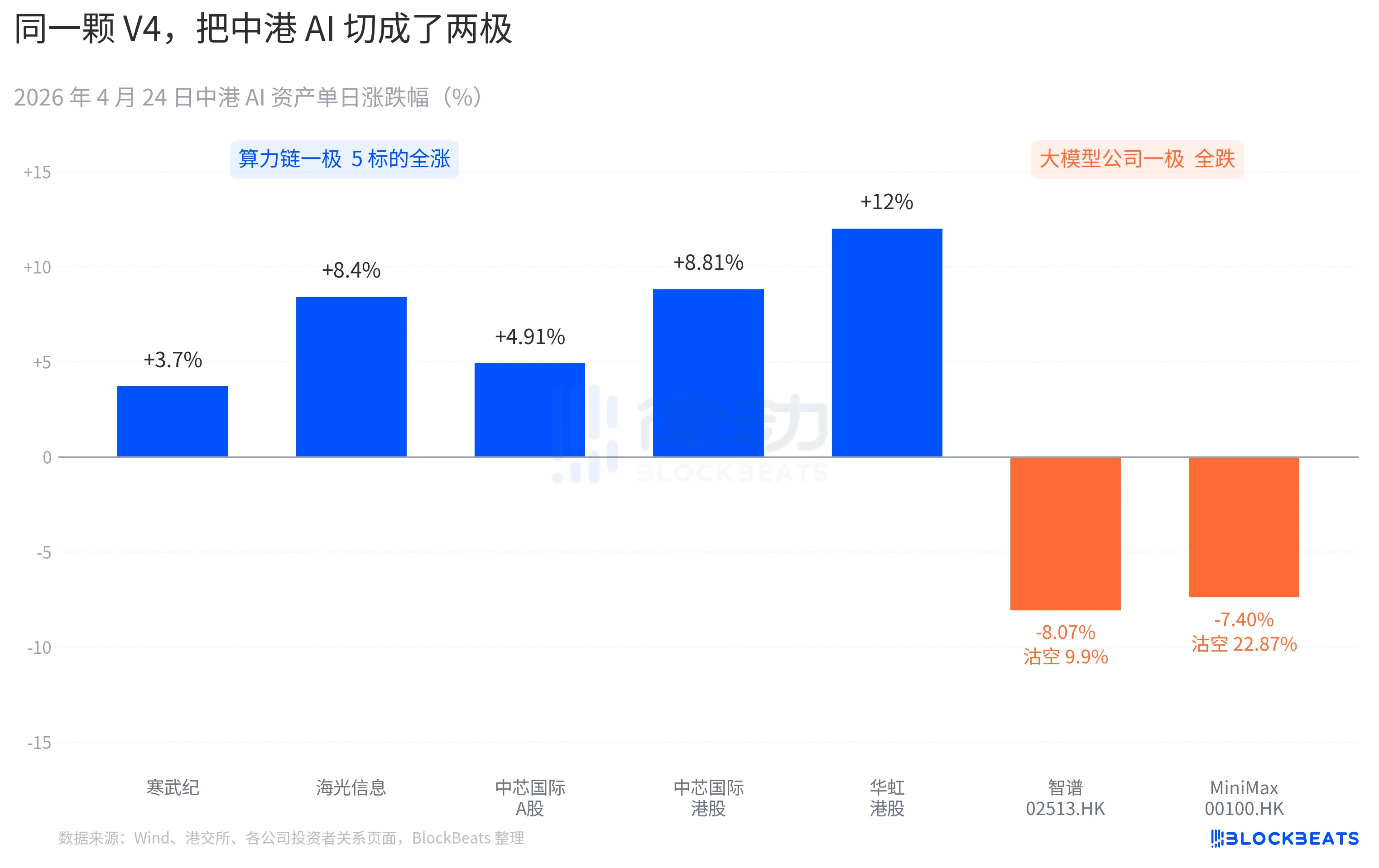
Sa kabilang panig ng Pasipiko, ang reaksyon ay parehong espesipiko. Bumaba ang NVIDIA ng 1.8% nang buksan noong Abril 24, bumaba hanggang -2.6% sa loob ng araw, at nagtapos nang walang pagbabago. Isinakop ng Bloomberg Market Snapshot ang pagpapahinga na ito sa V3 na “DeepSeek Moment” noong Enero 27. Ang pagkakaiba ay, noong Enero, isang panic selling na nag-iiwan ng $600 bilyon sa halaga sa isang araw. Ang besyon na ito ay mas katulad ng isang re-pricing—moderado sa sukat ngunit malinaw sa direksyon. Sa mga研究报告 ng mga institutional buyer, lumabas ang isang bagong pahayag: “Ang demand para sa AI inference sa China ay nagsisimulang magkahiwalay mula sa AI inference demand sa North America.”
Ipinagkakasama ang tatlong mga disk na ito, at ito ang unang hatol na isinulat ng merkado sa loob ng 24 oras pagkatapos ng paglunsad ng V4. Pagkatapos manalo ang open source, ang pera ay nagsimulang muling pumili ng panig; ang hindi na maaaring magbigay ng presyo ay ang modelo mismo, kundi kung saan nagpapatakbo ang modelo, at kung saan ito nakapaloob sa chain ng industriya.
30 araw, 11 bagong modelo, ang V4 ay nagdadagdag ng liwanag sa komunidad ng open source
Ang time window ng paglabas ng V4 ay bahagi rin ng dahilan kung bakit ang reaksyon ay na-enhance.
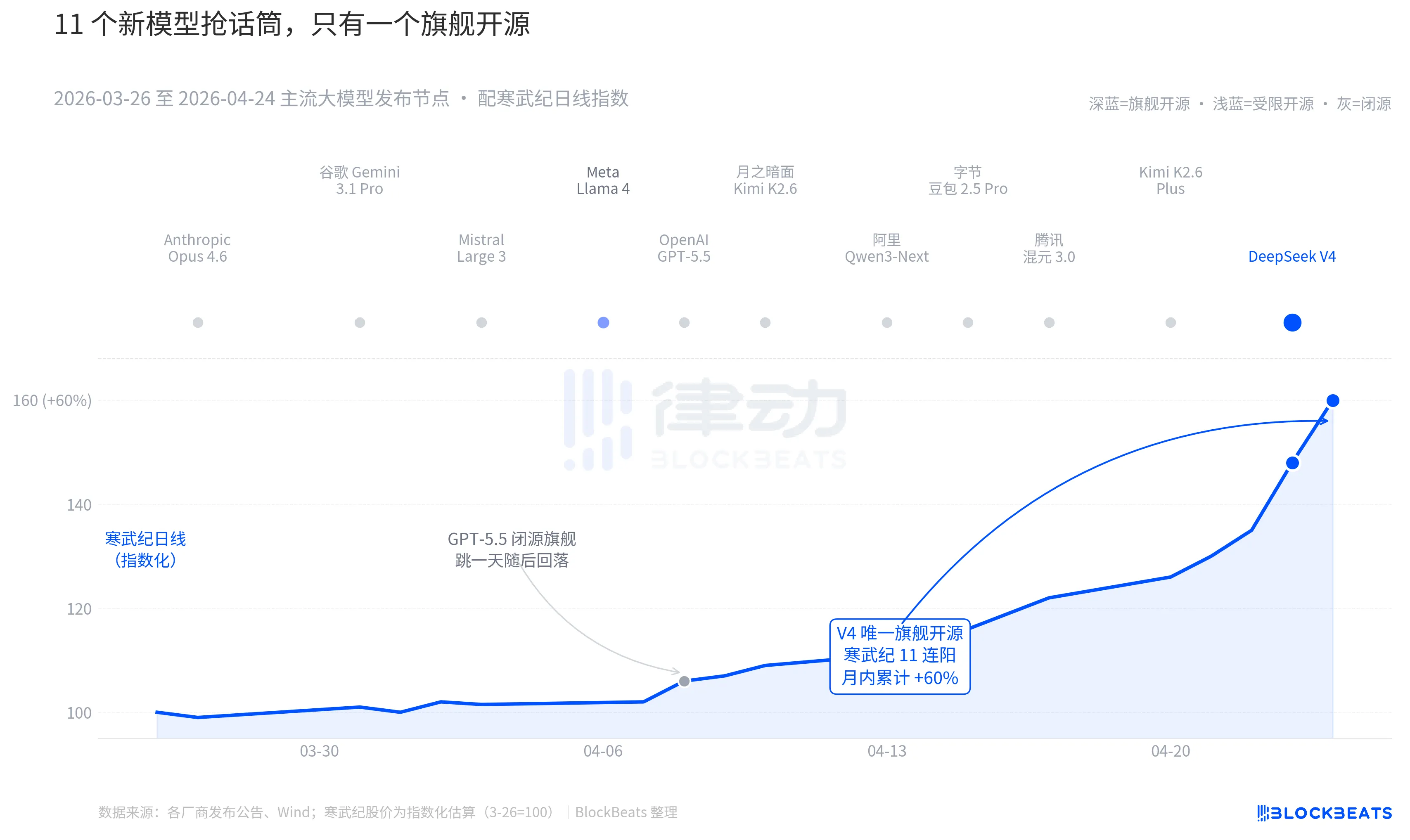
Iwasan ang kamera pabalik sa nakaraang 30 araw. Mula Marso 26 hanggang Abril 24, mayroong hindi bababa sa 11 malaking model na ipinakilala o napag-update sa buong mundo na may malaking epekto, at kasama sa listahan ang lahat ng pangunahing player. Anthropic Opus 4.6, Google Gemini 3.1 Pro, OpenAI GPT-5.5, Mistral Large 3, Meta Llama 4, Moonshot Kimi K2.6, Alibaba Qwen3-Next, ByteDance DouBao 2.5 Pro, Tencent HunYuan 3.0, Kimi K2.6 Plus, at huli ang DeepSeek V4 na ipinakilala noong Abril 23 sa gabi.
Sa pagkakatambal, may isang bagong modelo na lumalabas bawat 2.7 araw. Ito ay mas mabilis kaysa sa pagbabasa ng mga press release ng mga fund manager. Ngunit pagkatapos mong suriin ang 30-araw na K-line ng AI assets sa China at Hong Kong, ang iisang pangalan lang ang nakapag-iwan ng matatag na trace sa chart: Ang GPT-5.5 noong Abril 8 ay nagdulot ng 4.2% na pagtaas sa isang araw ng NVIDIA, at doon ito nakarating sa peak. Pagkatapos ay ang DeepSeek V4 noong Abril 23-24, na nagdulot ng patuloy na pagtaas sa chain ng computing power sa China at Hong Kong.
Hindi sa kakayahan ng modelo ang pagkakaiba. Ang pagkakaiba sa pagitan ng 11 na modelo sa leaderboard ng LMArena ay karaniwang hindi hihigit sa 50 puntos, at nasa maliit na saklaw ng “parehong antas.” Ang pagkakaiba ay nasa pagkakasundo ng dalawang bagay.
Ang unang bagay ay ang open source. Sa mga unang 10 na modelo, ang Llama 4 ay ang tanging open source, ngunit ang lisensya ng weights nito ay may mahabang lista ng mga pagkakabawas para sa komersyal na paggamit, kaya ang komunidad ng mga developer sa Europa at Amerika ay may maliit na reaksyon, at bumaba ito mula sa top 10 sa ikatlong araw ng paglalabas sa OpenRouter. Ang lisensya ng V4 ay Apache 2.0, walang hadlang sa weights, walang limitasyon sa komersyal na paggamit, at sinama ang code para sa inference. Ito ang unang pangunahing open source model sa nakalipas na anim na buwan na nagdulot ng presyon sa mga closed-source camp sa tatlong aspeto: performance, presyo, at pagkakabukas.
Ang pangalawang bagay ay ang tamang panahon. Sa ilalim ng patuloy na pagpapalakas ng mga hakbang mula sa closed-source camp, ang open-source narrative ay paulit-ulit na pinipigil. Ang Opus 4.6 ay nagpataas ng SWE-Bench para sa code tasks sa bagong antas, habang ang GPT-5.5 ay itinakda ang presyo sa $1.25 bawat milyong token bilang lower anchor. Ang debate kung kaya ba ng open-source na makahabol sa closed-source ay patuloy na nangyayari sa Silicon Valley nang dalawang taon. Ang V4, na nakamit ang 90 milyon na aktibong user sa isang buwan, ay nag-aresto sa debate na ito.
Ayon sa isang malaking domestic fund manager sa kanilang roadshow, “Bago ang V4, nagbigay kami ng discount sa pagpapahalaga sa open-source large models, ngunit pagkatapos ng V4, ang discount na iyon ay nagsimulang maging premium.”
Nilikha ng DeepSeek ang isang bagong presyo para sa supply chain ng computing power.
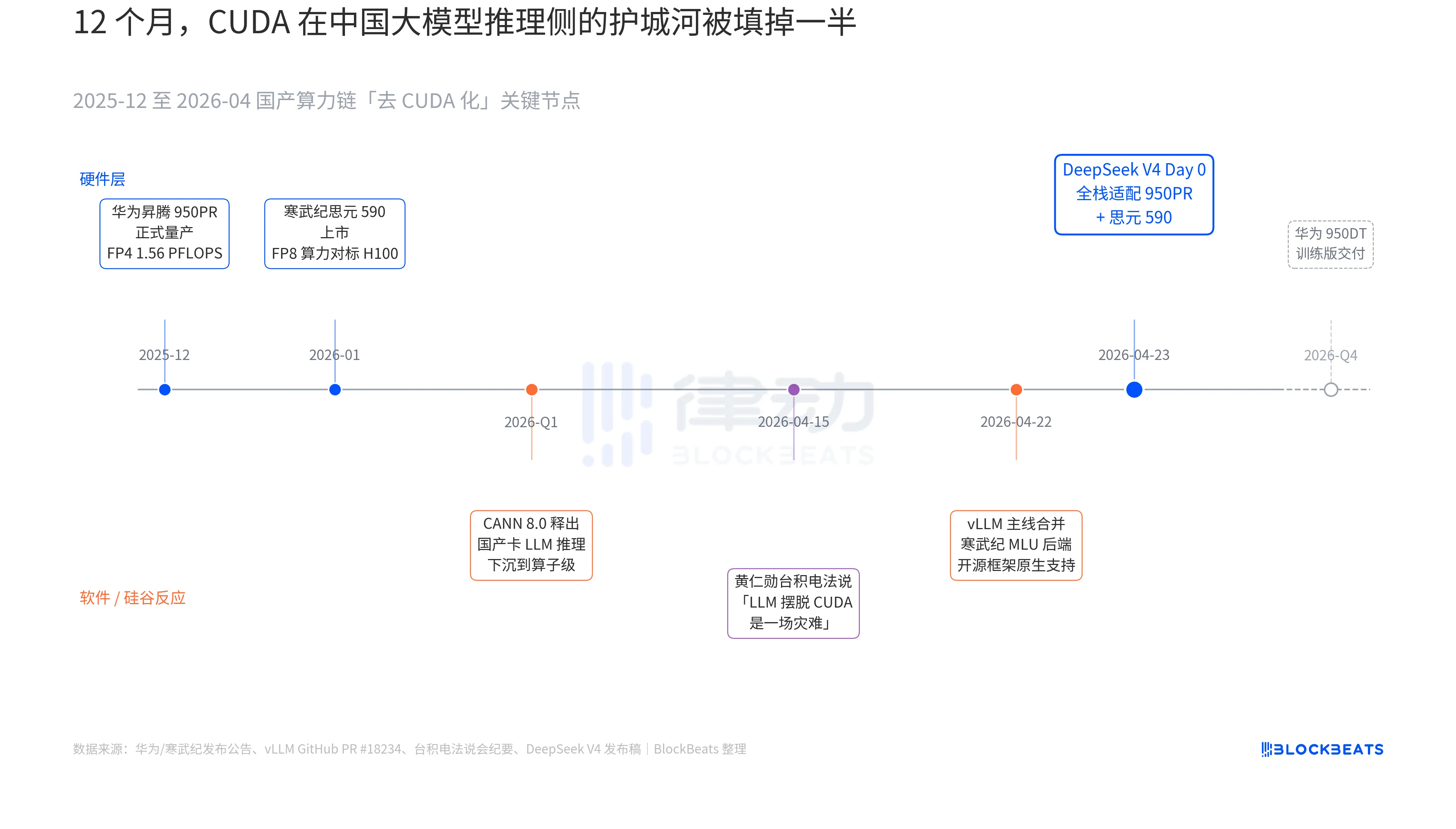
Sa V4 release note, may isang pahayag na dating hindi nagkakaroon sa anumang opisyal na dokumentasyon ng anumang malaking model sa China: "Day 0: Full-stack compatibility with Cambricon MLU590 at Huawei Ascend 950PR, deployment code na sinama sa open source." Ang bigat ng pahayag na ito ay maaaring maunawaan lamang kung isasama ang tatlong paralel na lihim na kuwento sa loob ng nakaraang 12 buwan. Ang tatlong lihim na kuwento ay tumutukoy sa hardware, software, at reaksyon ng Silicon Valley.
Ang unang lihim ay nasa gilid ng chip. Ang Huawei Ascend 950PR ay magsisimula sa mass production noong Disyembre 2025, na may FP4 computing power na 1.56 PFLOPS at HBM capacity na 112GB, na ang unang pagkakataon na isang lokal na AI chip ay direktang ihahambing sa NVIDIA B-series sa mga pambansang sukat. Sa V4, isang MoE inference task na may 1T parameters, ang single-card throughput ay tumataas ng 2.87 beses kumpara sa H20. Ang kasamang CANN 8.0 software stack ay nagpapalalim ng optimization ng LLM inference framework hanggang sa antas ng operator; ang DeepSeek na pinalabas na benchmark ay ipinapakita na ang V4 sa Ascend super-node (8 na kartang 950PR) ay may end-to-end inference latency na 35% mas mababa kaysa sa isang magkaparehong sukat na H100 cluster. Mas malakas pa ang data ng Cambricon思元590: ang single-chip FP8 computing power ay ihahambing sa H100, ngunit ang presyo ay mas mababa kaysa sa kalahati.
Ang pangalawang lihim na linya ay nasa gawang software. Noong Abril 22, ang vLLM ay nag-merge ng PR para sa MLU backend ng Cambricon, kung saan unang beses na native na suportado ng open-source inference framework ang lokal na GPU na hindi mula sa NVIDIA. Ang DCU ng Hygon Information ay gumagamit ng isang iba’t ibang daan sa pamamagitan ng ROCm ecosystem, ngunit kayang i-run nang buo ang MoE routing layer ng V4. Ibig sabihin, ang deployment ng V4 ay hindi na “kakayahan lamang sa isang lokal na GPU” kundi “may pagpili sa pagitan ng maraming lokal na GPU”. Ang pagkakasalalay sa isang solong supplier ay nasira, at ito ang mahalagang punto ng pagbabago para sa production.
Ang ikatlong lihim na linya ay galing sa Silicon Valley. Noong Abril 15, hinamon ni黄仁勋 ang mga analista sa investor call ng TSMC tungkol sa pag-unlad ng lokal na computing power ng China; ang kanyang orihinal na pahayag ay malamig at tiyak: “Kung talagang makakapagpalaya sila ng LLM mula sa CUDA, ito ay isang kalamangan para sa amin (a disaster).” Siyam na araw pagkatapos, ibinigay ng DeepSeek ang sagot sa pamamagitan ng isang Day 0 announcement.
Ang apat na salitang “pagsisikap na palitan ang lokal” ay nadamay na sa loob ng nakaraang tatlong taon hanggang sa mawala ang kahulugan nito. Ngunit pagkatapos ng umaga ng Abril 24, unang beses na mayroong konkretong data na maaaring ma-prisyo ng mga kapital na merkado: ang throughput ng isang GPU, ang end-to-end latency sa inference, ang gastos sa inference, at ang mga code para sa komersyal na deployment—nagpalakas nang tahimik ang mahabang labanan ng mga salita at isinilid ito sa hangganan ng production.
Ang lohika sa 11 araw na pagtaas ng presyo ng CMC ay naka-sembli rito. Hindi na ito isang “stock na may konsepto ng lokal na GPU,” kundi isang “tagapagbigay ng imprastruktura para sa pagpapatakbo ng DeepSeek V4.” Parehong lohika ang nagpapaliwanag sa 12% pagtaas ng presyo ng Hong Hua sa港股: ito ang nagpapagawa ng 7nm equivalent process para sa 950PR. Bawat token ng V4 na tinatakbo sa lokal na Ascend, ay nangangahulugan na ang ilang kapasidad na dati ay papunta sa NVIDIA at TSMC ay pinigil na bahagya sa Pearl River Delta.
Ang susunod na hakbang ay nakaayos na. Sa roadmap ng Huawei, ang 950DT (training version) ay plano na ipagkaloob sa ikalawang kuartal ng 2026, na may layunin na “full-stack training ng V5 o katumbas na model sa cluster ng 10,000 GPUs.” Kung matutupad ang landas na ito, ang CUDA ay mababawasan mula sa “kailangan” hanggang sa “pagsasamantala” sa aspeto ng pag-train ng malalaking model sa China.
Pinagmulan: BlockBeats