









Ang pagbabago ng presyo ng DeepSeek ay nagdulot ng di-linearing pagsabog na pagbaba, na pilit na dinala ang industriya sa isang bagong kapanahunan ng gastos.
May-akda ng artikulo, pinagkukunan: 0x9999in1, ME News
TL;DR
- Bumagsak ang presyo sa paa: Noong huling bahagi ng Abril 2026, binalik ng DeepSeek ang presyo ng output ng kanyang V4-Pro model sa $0.878/milyong Token sa pamamagitan ng pagpapalipat ng limitadong panahon na diskwento at pagbawas sa cache, at ang input na cache hit ay bumaba pa sa $0.0037 (kabuuang halos 0.025 na Chinese yuan), na lubos na binasag ang talaan ng presyo sa industriya ng malalaking modelo.
- May “discontinuity” sa pagpapresyo sa China at US: Sa paghahambing sa mga pangunahing manufacturer sa buong mundo, ang kabuuang gastos sa pagtawag sa API ng DeepSeek-V4-Pro ay lamang ang isang-tatlumpu-kalahati ng gastos ng OpenAI GPT-5.5 at Anthropic Claude Opus 4.7, na bumubuo ng napakalaking pagkakaiba sa kahusayan sa gastos.
- Nagdadasal ang kompetisyon sa loob ng bansa: Sa ilalim ng agresibong pagtatakda ng presyo ni DeepSeek, hinaharap ng mga pangunahing modelong tulad ng Zhipu GLM 5.1 at Moonshot Kimi K2.6 malaking presyong pangkomersyal, at maaaring masikat na sumunod sa pagbaba ng presyo, na magdudulot ng mabilis na paglinis ng industriya.
- Ang “cache hit” ay naging sentro ng ekonomiks: Ipinababa ni DeepSeek ang presyo ng cache hit sa isang-sampu ng orihinal na presyo, isang estratehiya na lubos na nakakatulong sa mga escenario ng patuloy na maraming round ng interaksyon para sa pagproseso ng mahabang teksto, RAG (retrieval-augmented generation), at Agent.
- Mga konklusyon ng think tank: Ang mga pangunahing malalaking modelo ay mabilis na nagsisigaw bilang “infrastraktura tulad ng tubig at kuryente,” at ang hinaharap na pakikidigma ay magsisilbi sa pagbabago mula sa pagtataya ng laki ng parameter ng modelo patungo sa kakayahan sa pag-optimize ng gastos sa pagpapaliwanag at pagkamit ng bahagi sa ekosistema ng mga developer.
Panimula: Ang "singularity" sa gastos ng computing power ng malalaking modelo
Ang pag-unlad ng teknolohiya ay karaniwang kasama ng eksponensyal na pagbaba ng gastos, na isang kailangang hakbang para sa anumang disruptive na teknolohiya upang makamit ang kompletong pagkalat. Noong Abril 25-26, 2026, dumating ang AI industry sa isang napakalaking sandali: ang pangunahing malaking model vendor, DeepSeek, ay naglabas ng dalawang “malalim na pana” nang magkakasunod. Una, inihayag nila ang panahon-limited na 2.5% discount para sa API ng DeepSeek-V4-Pro model; agad pagkatapos, inihayag nila na ang presyo para sa input cache hit sa buong serye ng API ay bawasan nang direkta sa 1/10 ng orihinal na presyo.
Sa pamamagitan ng dalawang pagsasama-samang pagbabawas ng presyo, bago ang Mayo 5, 2026, ang presyo ng input cache hit para sa DeepSeek-V4-Flash ay bumaba sa nakakagulat na $0.0029 bawat milyong Tokens, habang ang presyo ng input cache hit para sa DeepSeek-V4-Pro, na nakakahambing sa pinakamataas na antas sa buong mundo, ay nasa $0.0037 lamang (katumbas ng halos ¥0.025).
Bago pa, karaniwang inaasahan ng industriya na bababa ang gastos sa pagpapatakbo ng malalaking modelo ng humigit-kumulang 50% bawat taon, ngunit ang pagbabago ng presyo ng DeepSeek ay nagdulot ng di-linearyong malaking pagbaba, na pilit na isinilid ang industriya sa isang bagong kapanahunan ng gastos. Naniniwala kami na ito ay hindi isang simpleng marketing aktibidad o pansamantalang “labanan sa presyo,” kundi isang natural na resulta ng pagpapabuti sa ilalim na arkitektura ng algoritmo (tulad ng sparse attention mechanism at ekstremong pag-unlad ng MoE architecture) at pagpapabuti sa kakayahan sa pagpapatakbo ng compute clusters. Ang ulat na ito ay batay sa pinakabagong data sa presyo ng buong industriya, at magpapaliwanag nang malalim tungkol sa epekto ng pagbaba ng presyo ng DeepSeek, at maghahambing nang横向 sa komersyal na kakayahan ng mga pangunahing malalaking modelo sa buong mundo, upang magbigay ng malinaw na landas para sa pag-unlad ng industriya para sa mga tagapagdesisyon.
Pangunahing pangyayari: Pagbubukas ng limitasyon sa presyo ng serye ng DeepSeek-V4
Upang maunawaan ang kalalabasan ng pagbaba ng presyo na ito, kailangan nating pagsuriin ang tatlong pangunahing dimensyon ng pagkalkula ng API para sa malalaking modelo: presyo ng input (hindi nakakasali sa cache), presyo ng input (nakakasali sa cache), at presyo ng output. Ang dating sistema ng pagkalkula ay karaniwang naghihiwalay lamang sa input at output, ngunit kasabay ng pag-unlad ng teknolohiya ng mahabang konteksto (Long-Context), ang “rate ng pagkakasali sa cache (Cache Hit)” ay nagsisimulang maging mahalagang salik sa pagbabago ng ekonomiya ng API.
Paglilinaw sa Patakaran sa Pagtatakda ng Presyo: Pagkakasunod-sunod ng Diskwento at Cache na Leverage
Batay sa pinakabagong ipinahayag na datos, ginamit ng DeepSeek ang tatlong pagsalakay na “base price reduction + limited-time discount + cached leverage”.
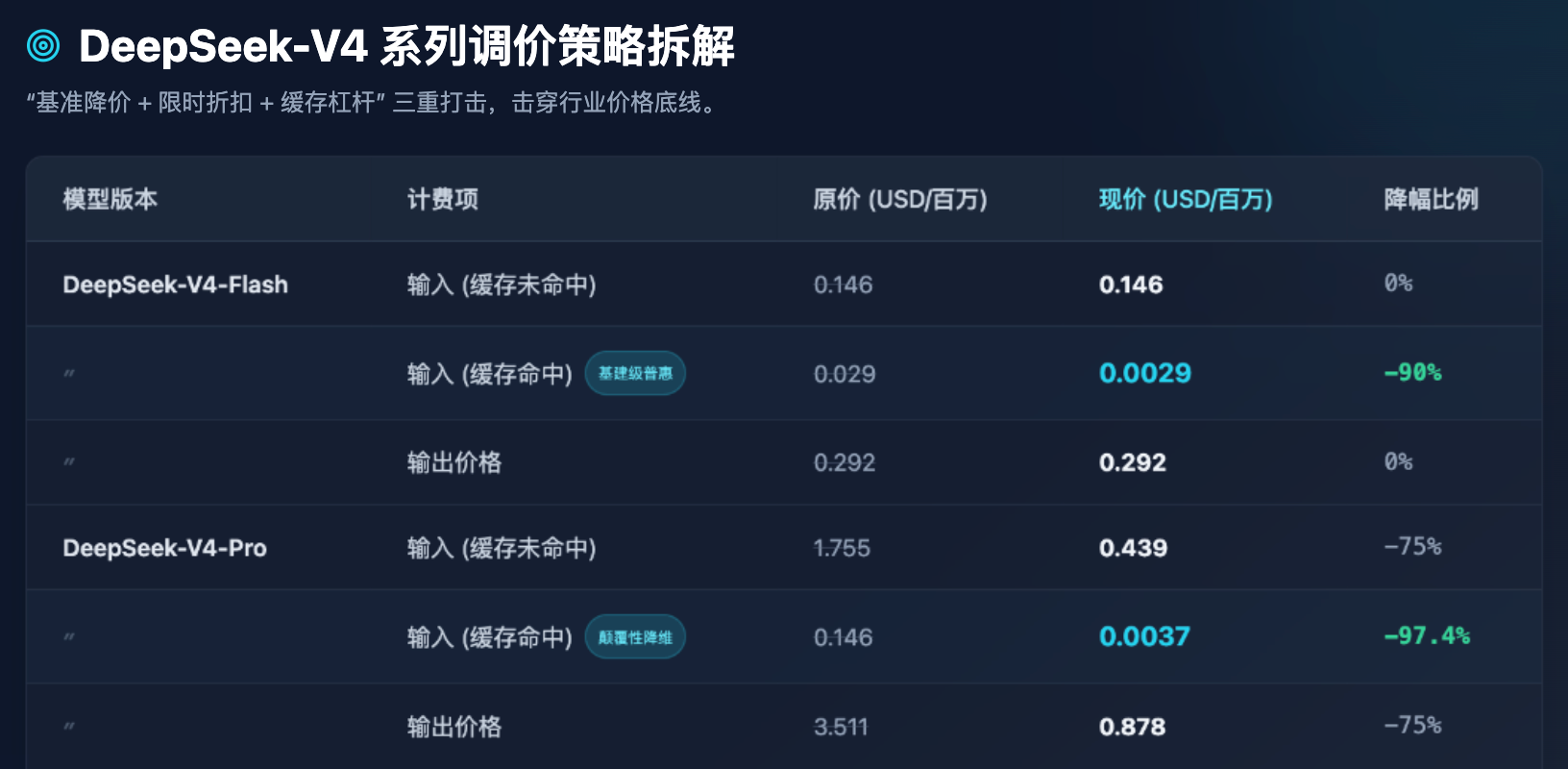
Tala 1: Pagkukumpara ng mga bagong presyo ng API sa DeepSeek-V4 series bago at pagkatapos ng pagbabago (yunit: dolyar/milyong Token)
Mula sa Talahanayan 1, maaari nating makita ang ilang napakalinaw na obserbasyon sa industriya:
Una, ang pagpapalawak ng Flash model ay nasa pinakamababang antas na. Para sa Flash model na nakatuon sa mataas na concurrency at mababang latency, ang presyo ng output ay nananatili sa $0.292 bawat milyong Token, na nasa pinakamababang antas na malapit sa direktang gastos ng server computing power. Hindi sinunod ni DeepSeek ang pagpapababa ng pangunahing presyo ng Flash, kundi sinikap nito na bawasan ang presyo ng “cache hit” ng 90%. Ibig sabihin nito, sa pagproseso ng malaking dami ng paulit-ulit na system prompts o fixed document QA, ang gastos ng Flash model ay halos walang halaga.
Pangalawa, ang pagbaba ng presyo ng Pro model. Bilang flagship model na nakakatugon sa mga unang grupo sa buong mundo (tulad ng GPT-5), bumaba ang presyo ng output mula sa $3.511 patungo sa $0.878. Mas kahanga-hanga pa, ang orihinal na presyo ng input na may cache hit na $0.146, pagkatapos ng 2.5% discount at 1/10 price reduction, bumaba nang direkta sa $0.0037. Ito ay isang napakakatakot na numero—nangangahulugan ito na ang gastos para sa paggamit ng pinakamataas na antas ng global na intelehensya ay na-compress na hanggang sa maaaring gamitin nang walang pag-aalala ng mga maliliit at katamtamang negosyo at mga indibidwal na developer.
Ikatlo, ipinipilit nito ang mga developer na mapabuti ang Prompt engineering. Ang pagtatakda ng presyo na binigyang-kabuluhan bilang isang maliit na bahagi ng presyo na hindi binigyang-kabuluhan (halimbawa, sa Pro model: $0.0037 kumpara sa $0.439, nagkakaiba ng halos 118 beses) ay hindi lamang isang estratehiya sa pagtatakda ng presyo, kundi isang paraan upang gabayan ang teknikal na ekosistema sa pamamagitan ng mga komersyal na paraan. Sinasabi nang malinaw ng DeepSeek sa mga developer: kung ang inyong arkitektura ay maayos na disenyo (halimbawa, ang fixed long context ay nasa harap, at ang variable short question ay nasa likod), kayo ay makakapag-enjoy ng halos libreng input computing power.
Horizontal comparison: Ang malaking pagkakaiba sa presyo ng mga malalaking modelo sa global at lokal
Hindi sapat ang pagsusuri lamang sa pagbaba ng presyo ng DeepSeek mismo upang makita ang buong larawan; kapag isinasaayos natin ito sa grid ng global market para sa malalaking modelo noong 2026, ang pagkakaiba na nilikha ng estratehiyang ito sa pagtatakda ng presyo ay tunay na nakakatakot.
Batay sa OpenRouter at mga pampublikong impormasyon ng iba’t ibang kompanya, isinama namin ang pinakamakabuluhang 9 na API na presyo ng mga malalaking modelo sa lokal at internasyonal na merkado.

Tala 2: Pagkukumpara ng mga presyo ng API ng mga pangunahing malalaking modelo sa buong mundo noong 2026 (yunit: dolyar / milyong Token)
Laban sa mga global na pangunahan: Pagpapabagsak ng mito ng “mataas na intelektuwal at mataas na premium”
Sa loob ng dalawang taon na pagsasalaysay ng AI, nanatili ang OpenAI at Anthropic sa isang pagkakasundo: ang pinakamatalinong mga modelo ay dapat magkaroon ng pinakamataas na margin ng gastos. Sa kasalukuyan, ang presyo ng output ng GPT-5.5 at Claude Opus 4.7 ay umabot sa $30 at $25 bawat milyong Token. Sinusubukan ng dalawang malalaking kumpanya sa Silicon Valley na panatilihin ang kanilang mataas na bayad sa computing sa pamamagitan ng monopoliyo sa pinakamataas na kakayahan sa pag-iisip.
Gayunpaman, ang pagkakaroon ng DeepSeek-V4-Pro at ang pagkakalagay nito sa presyo ng $0.878 para sa output ay diretso nang tinanggal ang kahoy na pabalat. Kung ang V4-Pro ay makakamit o malapit sa antas ng GPT-5.5 sa lahat ng pangunahing benchmark at praktikal na karanasan, ang 34 beses na pagkakaiba sa presyo ng output ay bubuksan nang buong-tuluyan ang logic ng premium ng mga malalaking kompanya sa panlabas na merkado para sa B2B.
Ipinagkalkula ng "ME News Think Tank" na para sa isang kumpanyang malakas na nakasalalay sa AI-generated na nilalaman, kung ang monthly consumption ay 1 bilyon na token, ang direkta na gastos gamit ang GPT-5.5 ay $30,000; samantalang ang paglipat sa DeepSeek-V4-Pro ay bababa nang husto sa $878. Ang ganitong kalaking pagkakaiba sa gastos ay maaaring magdulot ng pagkabigo o tagumpay sa isang startup. Ito ay nagpapakita na ang mga Chinese AI company ay nagsagawa ng isang iba’t ibang landas na nagtataglay ng parehong "brutal aesthetics at extreme engineering" sa pagtratrabaho sa efficiency ng pag-train ng base model at pag-optimize ng inference cluster, na iba sa Silicon Valley.
Pagsisikap sa mga lokal na katulad: Pagpapabilis ng malaking pagbabago sa industriya
Kung ang DeepSeek ay isang downgrading strike sa mga foreign giants, mas isang mapagkukunang zero-sum game ito sa mga lokal na kalaban.
Mula sa Talahanayan 2, makikita na ang mga pangunahing lokal na tagapag-provide tulad ng Zhipu (GLM 5.1, ₱4.40) at Moonshot (Kimi K2.6, ₱4.00) ay nasa isang komplikadong posisyon sa pagtatakda ng presyo. Ang mga presyong ito ay noong ilang buwan ang nakalipas ay itinuturing na “mabisa at may halaga,” ngunit sa harap ng DeepSeek-V4-Pro (₱0.878), agad na nawala ang kanilang lahat ng proteksyon sa presyo. Kahit ang Alibaba Cloud, na kilala sa pagiging open-source at mura (Qwen3.6 Plus, ₱1.96), ay hindi na itinuturing na “mura.”
Sa larangan ng mga lightweight Flash model, ang pakikidigma ay patuloy na mainit. Ang Step 3.5 Flash ng Jiepao Xingchen ay may input na pababa sa $0.028 at output na tanging $0.299, na malapit sa DeepSeek-V4-Flash (output na $0.292). Ito ay nagpapakita na sa larangan ng lightweight models, ang pagpapababa ng gastos sa computing ay nasa antas ng nanometer, at lahat ng kompanya ay lumalabas sa malapit sa cost line.
Sa kabuuan, ang DeepSeek ay gumagamit ng kakayahan na Pro para tumama sa presyo ng mga lokal na kalaban na Plus o Standard version; at gumagamit ng presyo na Flash para suportahan ang lahat ng malaking dami at mababang densidad ng long-tail traffic. Ang taktikang “double-sided pincer” na ito ay malaki ang pagbaba sa espasyo para sa iba pang mga kumpanya ng malalaking modelo, at ang pagtatanggal sa paligsahan ng mga malalaking modelo sa AI sa bansa ay mabilis na maaaring magkaroon pagkatapos ng pagbaba ng presyong ito.
Deep Dive: Ang Teknolohiya at Negosyong Lohika sa Likod ng Ekstremong Mababang Presyo
Hindi mapanatili ang mababang presyo na walang pundasyon. Ang dahilan kung bakit masigla ni DeepSeek na ipatupad ang ganitong matinding pagsabay sa presyo hanggang 2026 ay ang malalim na teknikal na suporta at napakalaking pangangarap sa negosyo.
Teknikal na lohika: Mula sa “malakas na puwersa, malayo ang supot” patungo sa “pagtatayo ng arkitektura ang nagtatagumpay”
Ang biglang pagbaba ng presyo ay sa kanyang pinakamainam na anyo ay ang paglabas ng benepisyo mula sa pag-unlad ng teknikal na arkitektura.
- Malalim na benepisyo ng MoE (Mixture of Experts) architecture: Sa pagkakaiba sa mga malaking dense model ng OpenAI sa kanilang mga una, ang mga modernong advanced model ay karaniwang gumagamit ng napakadisenyong MoE architecture. Malaki ang posibilidad na pinababa ni DeepSeek ang proporsyon ng activated parameters sa V4 architecture. Ibig sabihin, kahit malaki ang kabuuang bilang ng parameters, sa bawat inference, ang kaunting bahagi lamang ng “experts” ang na-activate, kaya napakadali ang computation load (FLOPs) at presyur sa memory bandwidth sa bawat pagtawag.
- Revolutionary breakthrough in KV Cache management: Ang pinakamalaking tagumpay sa pagbabago na ito ay ang “pagbaba ng input cache hit rate sa 1/10”. Sa arkitekturang Transformer, ang pinakamalaking hadlang sa pag-iisip ng mahabang teksto ay hindi ang pagkalkula, kundi ang paggamit ng malaking GPU memory ng KV Cache para sa pag-iimbak ng konteksto. Malinaw na natutupad ng DeepSeek ang teknolohiyang pagpapangkat ng KV Cache na global at跨请求 (hal. upgraded bersyon ng RadixAttention). Kapag mayroong maraming parehong system settings o background knowledge base sa mga parehong kahilingan ng maraming user, hindi na kailangang kalkulahin muli ang mga Token na ito—kundi direktang binabasa mula sa memorya o kahit sa distributed GPU memory pool. Dahil dito, ang marginal cost ng “mahabang input na teksto” ay malapit na sa sero.
Business logic: Palitan ang kita para sa espasyo, muling ilarawan ang mga parapet ng ekosistema
Sa palagay ng «ME News智库», malinaw at matatag ang layunin sa negosyo ng panahong diskwento at pagsasabay na presyo ni DeepSeek:
Una, burahin ang ekosistema ng “fine-tuning na may pabalat” upang pilitin ang paglago ng mga AI-native na aplikasyon. Kapag ang gastos sa paggamit ng pinakamalakas na base model ay malapit na sa libre, ang pagpapalaki o pagfine-tune ng sariling maliit na model sa isang industriya ay magiging walang ekonomikong kahulugan para sa mga entrepreneur. Ang DeepSeek, sa pamamagitan ng mababang presyo, ay nagsusumikap na hikayatin ang lahat ng mga developer ng AI sa buong lipunan na pumasok sa kanilang API ecosystem, gawing tulad ng Amazon AWS o Microsoft Azure ang kanilang “pangunahing tubig, kuryente, at gas sa panahon ng AI”.
Sa ikalawa, ang pag-usbong ng agente ng posisyon. Ang totoong agentic application ay nangangailangan ng malaking dami ng pagsasalaysay, pagsusuri, pagpaplano, at maraming pag-uulit ng pagtawag (loop). Sa prosesong ito, magkakaroon ng malaking halaga ng implicit token consumption. Ang mahal na API ay ang pinakamalaking hadlang sa pagkakaroon ng agent. Sa pamamagitan ng pagbaba ng presyo ng cache hit sa $0.0037, ang DeepSeek ay nagbibigay ng ekonomikong kakayahang magpapatakbo ng isang AI sa libo-libong beses. Sino ang nagbibigay ng pinakamababang gastos sa pagsubok at pagkakamali, siya ang makakapag-usbong ng pinakamalaking AI-native super application.
Epekto at Pagtataya sa Trend ng Industriya: Mula sa “Pakikidigma ng Modelo” patungo sa “Pakikidigma ng Ekosistema”
Upang mas maipakita nang mas malinaw ang epekto ng pagbabago sa presyo sa desisyon ng negosyo, isinagawa namin ang isang simulation ng gastos para sa enterprise-level application.
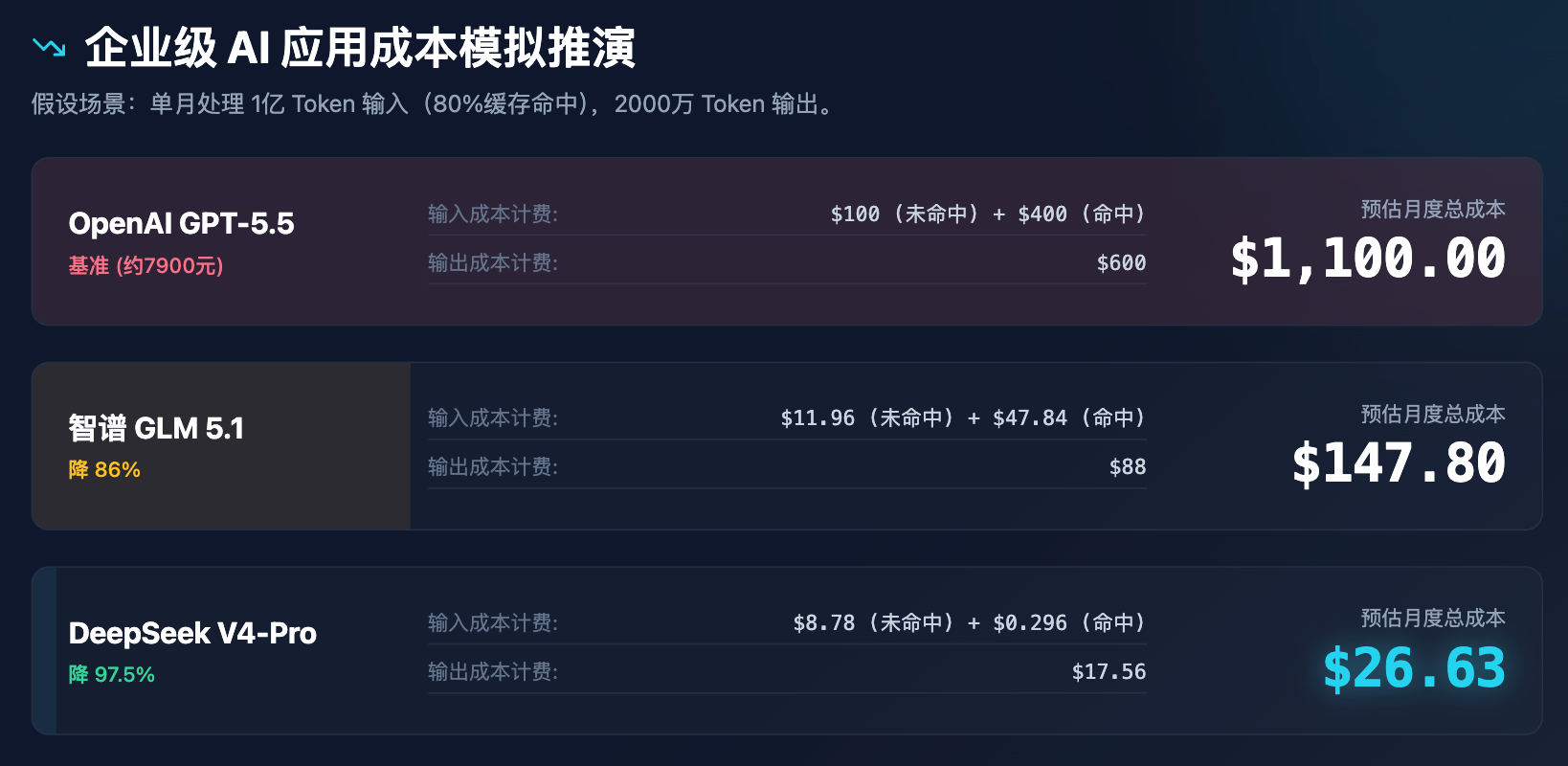
Tala 3: Pagsusuri ng Simulasyon ng Gastos para sa Enterprise AI Applications (nagmumula sa isang buwan na pagproseso ng 100 milyong input Token, 20 milyong output Token)
Maaaring malinaw na makita sa simulation na ito na ang pagtatakda ng presyo ng DeepSeek ay hindi lamang isang diskwento, kundi isang pagbabago sa modelo ng gastos. Sa halagang mas mababa sa $30 bawat buwan, maaaring suportahan ang lahat ng pangangailangan sa pagtutulungan sa customer service, pagpapaliwanag ng dokumento, at pagsusuri ng code para sa isang katamtamang negosyo, at ito ay magdudulot ng isang serye ng mga epekto:
- Pangunahing pagbabago sa lohika ng pag-invest sa AI: Ang kapital ay magkakaroon ng ganap na pagkawala ng interes sa “pagbuo ng isang pangkalahatang malaking modelo.” Bukas na pader na ang pinto para sa pangkalahatang pangunahing malaking modelo, maliban sa ilang kaunting pambansang puwersa o mga malalaking internet na kumpanya. Ang hinaharap na pag-invest ay magkakaroon ng buong pagtutok sa application layer at infrastructure middleware (mga router ng infrastructure, AI gateway, atbp.).
- Ang multi-model routing strategy (LLM Routing) ay naging standard: hindi na magpapasya ang mga kumpanya na mag-focus sa isang modelo lamang. Awtomatikong i-distribute ng sistema ang mga gawain batay sa kahirapan nito. Halimbawa, ang 90% ng pang-araw-araw na paghahanda ng data at simpleng paghahati ay iniiwan sa DeepSeek-V4-Flash o Step 3.5 Flash upang matapos nang napakababang gastos; samantala, ang 10% ng mas kumplikadong lohikal na pag-iisip at paggawa ng mga ulat para sa mga tagapagpaganap ay tinatawag ang DeepSeek-V4-Pro o GPT-5.5 ayon sa pangangailangan.
- Ang mga aplikasyon para sa mahabang teksto ay dumating sa tunay na punto ng komersyalisasyon: Bago ito, ang “pag-upload ng mga财报 na may milyon-milyong salita para i-summarize ng AI” ay tila isang magandang ideya, ngunit ang bawat paggamit ng API na nagsasagawa ng ilang dolyar ay nagpapahintulot sa mga kumpanya sa B-side na maging mapagbantay. Kasabay ng pagbaba ng presyo ng input cache hit sa antas ng 0.02 yuan Tsino bawat milyong Token, ang “pagbabasa ng buong librerya ng dokumento at real-time na interaksyon” ay magiging standard na tampok ng lahat ng software ng OA at ERP ng mga kumpanya.
Kongklusyon at Mga Pahinga sa Estratehiya
Ang pagbaba ng presyo noong Abril 2026 ay nagmarka ng pormal na pagtatapos ng klasikong romantisismo sa industriya ng malalaking modelo, kung saan ang pagpapalakas ng mga parameter at pagpapakita ng mga score ay naging sentro, at pumapasok sa mapanirang panahon ng industriyalisasyon kung saan ang pagpapalakas ng gastos, paghahanap ng computing power, at pagtatayo ng ekosistema ang nangunguna. Sa pamamagitan ng kanyang agresibong pricing strategy, ipinakita ng DeepSeek hindi lamang ang malalim na kagalingan ng mga Chinese AI company sa model engineering, kundi pati na rin ang aktibong pagpapabagsak sa bubble ng sobrang presyo sa AI computing power.
Sa ganitong kaso, may tatlong rekomendasyon ang «ME News Think Tank»:
- Para sa mga developer ng application layer: Alisin ang takot sa gastos ng pagtawag sa malalaking modelo. Tumigil agad sa pagbuo at pag-microwave ng mga base model na may mas mababa sa 10 bilyong parameter, at ilagay ang lahat ng mga yunit sa pagpapabuti ng user experience, pag-adapt sa endpoint, pagbuo ng mga hadlang sa proprietary data, at pagpapahusay ng mga workflow ng Agent. Gamitin ang benepisyo ng “mura at malakas na computing power” na ito upang mabilis na makakuha ng mga scenario.
- Para sa mga CIO/CTO ng tradisyonal na mga negosyo: Mag-re-evaluate ng inyong AI strategy. Ang mga proyekto na dating inisip na iwasan dahil sa gastos tulad ng knowledge base Q&A, automated customer service, at code Copilot, ay may mataas na ROI (return on investment) na ngayon sa kasalukuyang presyo ng API. Maaaring isama ang mga matatag na LLMOps platform upang bumuo ng enterprise-grade AI gateway upang maging flexible sa pag-connect sa mga modelo na may pinakamataas na value-for-money.
- Para sa mga kaibigan na gumagamit ng base model: kailangan nating tanggalin ang pagsubaybay sa mga estratehiya. Sa harap ng pakikidigma sa presyo, o kaya ay pahabain ang gastos sa pamamagitan ng mas ekstremong pagpapagana ng chip at framework, o lumikha ng hindi maaaring palitan na teknikal na hadlang sa mga natatanging larangan tulad ng embodied intelligence, native multimodal (video/3D generation), at malalim na lohikal na pag-iisip sa mga espesipikong industriya. Ang simpleng malaking language model ay naging karaniwan na at wala nang daan.
Hindi na ang malalaking modelo ang isang diyos na naka-iray sa laboratorio; ito ay bumababa mula sa kanyang thrones sa isang walang katulad na bilis, naging isang malaking alon na nagpapagalaw sa lahat ng智能化. At ang lahat ng ito, ay nagsisimula lang.
Source:
- OpenRouter. (2026). API Pricing Comparison Database.
- DeepSeek Opisyal na Pagpapahayag. (2026, Abril 25). DeepSeek-V4-Pro API na Panahon-limited na Promosyon.
- DeepSeek Opisyal na Pagpapahayag. (2026, Abril 26.) Demokratikong Computing Power sa Panahon ng Malalaking Model: Mga Pagbabago sa Presyo ng API Global Cache Hit.