









Artikulo | Sleepy.txt
Ilang taon na ang nakalipas, ang Zhongxing ay nagkaroon ng cardiac arrest.
Noong Abril 16, 2018, isang pagbabawal mula sa Bureau of Industry and Security ng Kagawaran ng Kalakalan ng Estados Unidos ay nagpapahinto sa ZTE, isang pandaigdigang ikaapat na pinakamalaking kumpanya sa paggawa ng mga kagamitang komunikasyon na may 80,000 empleyado at taunang kita na higit sa isang bilyon dolyar, sa isang gabi. Ang nilalaman ng pagbabawal ay simpleng: sa susunod na pitong taon, bawal ang anumang Amerikanong kumpanya na magbenta ng mga komponente, produkto, software, at teknolohiya sa ZTE.
Walang chip ng Qualcomm, tumigil ang paggawa ng base station. Walang lisensya ng Google sa Android, wala nang gumagana na sistema sa mga cellphone. 23 araw pagkatapos, naglabas ng pahayag ang ZTE na ang pangunahing mga aktibidad ng kompanya ay hindi na maaaring maisagawa.
Ngunit umiiral pa rin ang ZTE, ngunit sa halagang $1.4 bilyon.
P1 bilyon na parusang bayaran nang isang beses; P400 milyon na margin, ipapadala sa isang trust account sa isang American bank. Bukod dito, buong management team ay babaguhin at tatanggap ng pagsusuri mula sa compliance team ng Amerika. Sa buong taon ng 2018, ang net loss ng ZTE ay P7 bilyong Chinese yuan, at bumagsak ang kita nito ng 21.4% kumpara sa nakaraang taon.
Isinulat ni Yin Yimin, ang pangulo ng ZTE, sa isang panloob na liham: “Nasa isang kumplikadong industriya tayo na napakadepende sa pandaigdigang supply chain.” Ang pangungusap na ito, sa panahon nito, ay isang pag-iisip at pagkabigo.
Sa walong taon, Pebrero 26, 2026, ang Chinese AI unicorn na DeepSeek ay inihayag na ang kanilang darating na V4 multimodal na malaking modelo ay magiging unang magkakasama sa mga lokal na tagagawa ng chip, at magiging unang pagkakataon na makamit ang buong proseso mula sa pre-training hanggang sa fine-tuning nang walang NVIDIA.
Hindi na namin gagamitin ang NVIDIA.
Agad na nagdulot ng pag-aalinlangan ang merkado nang maabot ang balita. Higit sa 90% ang bahagi ng NVIDIA sa global na merkado ng AI training chips; ang pagtigil dito, ba ay makatwiran sa negosyo?
Ngunit sa likod ng pagpili ni DeepSeek, nakatago ang isang mas malaking tanong kaysa sa negosyong lohika: Anong uri ng kalayaan sa computing ang kailangan ng Chinese AI?
Ano ba talaga ang nakakapit sa leeg
Marami ang naniniwala na ang pagbabawal sa chip ay tumutok sa hardware. Ngunit ang totoo ay ang isang bagay na tawagin CUDA ang nagdudulot ng pagkakabukod sa mga Chinese AI company.
CUDA, ang pangkabuuang pangalan ay Compute Unified Device Architecture, ay isang paralel na computing platform at programming model na ipinakilala ng NVIDIA noong 2006. Ito ay nagpapahintulot sa mga developer na direktang gamitin ang computing power ng NVIDIA GPU upang pabilisin ang iba't ibang kumplikadong computing tasks.
Bago dumating ang panahon ng AI, ito ay isang kasangkapan lamang para sa ilang mga geek. Ngunit nang dumating ang alon ng deep learning, naging pundasyon ng buong industriya ng AI ang CUDA.
Ang pag-train sa malalaking modelo ng AI ay sa katotohanan ay isang malaking bilang ng matrix operations. At ito ay eksaktong ang pinakamahusay na gawain ng GPU.
Nakabatay ang NVIDIA sa pagpaplano nito nang higit sa sampung taon, at nagtatag ng isang buong chain ng mga kasangkapan mula sa ilalim na hardware hanggang sa itaas na aplikasyon para sa mga developer ng AI sa buong mundo gamit ang CUDA. Ngayon, ang lahat ng pangunahing AI frameworks sa buong mundo, mula sa TensorFlow ng Google hanggang sa PyTorch ng Meta, ay malalim na nakabatay sa CUDA sa kanilang ilalim.
Isang doktoranda sa AI na nagsimula nang mag-aral, magprograma, at gumawa ng mga eksperimento sa CUDA mula sa unang araw ng pagkakaroon. Ang bawat linya ng kanyang code ay nagpapalakas sa parapet ng NVIDIA.

Hanggang 2025, ang CUDA ecosystem ay may higit sa 4.5 milyong developer, na sumasakop sa higit sa 3,000 GPU-accelerated applications, at higit sa 40,000 na kumpanya sa buong mundo ang gumagamit ng CUDA. Ang bilang na ito ay nangangahulugan na higit sa 90% ng mga developer ng AI sa buong mundo, ay nakabatay sa ecosystem ng NVIDIA.
Ang katatakutan ng CUDA ay ang pagiging ito isang flywheel. Mas maraming developer ang gumagamit, mas maraming mga tool, library, at code ang nabubuo, at mas umuunlad ang ecosystem; mas umuunlad ang ecosystem, mas maraming developer ang natutulak na sumali. Ang flywheel na ito ay kapag nagsimula nang umikot, halos hindi na ito matitigil.
Ang resulta ay, ang NVIDIA ang nagbebenta sa iyo ng pinakamahal na pala, at nagtatag ng iisang paraan ng pagmimina. Gusto mo bang palitan ang pala? Oo. Pero kailangan mong isulat muli ang lahat ng karanasan, kasangkapan, at code na naitipon ng mga pinakamatalinong isip sa buong mundo sa loob ng mahigit sa sampung taon sa paraang ito.
Sino ang magbabayad ng gastos na ito?
Kaya, noong Oktubre 7, 2022, nang magsimula ang unang pagpapatupad ng pagsasabwatan ng BIS na nagbabawal sa pag-export ng NVIDIA A100 at H100 patungo sa China, unang maranasan ng mga Chinese AI company ang pagkakasakop na katulad ng Zhongxing. Pagkatapos ay ipinakilala ng NVIDIA ang mga “China-specific version” na A800 at H800, na bumabawas sa bandwidth ng pag-uugnay sa pagitan ng mga chip, upang mapanatili ang suplay nang maikli.
Ngunit isang taon lamang pagkatapos, noong Oktubre 17, 2023, pinigilan muli ang ikalawang yugto ng regulasyon, at pinigilan din ang A800 at H800, at isinama ang 13 na Chinese companies sa Entity List. Kailangan muli ng NVIDIA na ilabas ang mas paunlarin na H20. Hanggang Disyembre 2024, ang huling yugto ng regulasyon sa panahon ng administrasyon ni Biden ay ipinatupad, at pinigilan nang mahigpit ang paglabas ng H20.
Tatlong pagpapalakas ng regulasyon, patuloy na pinalalakas.
Ngunit sa pagkakataong ito, iba ang takbo ng kuwento kaysa sa midyear ng ZTE.
Isang asymmetrical breakout
Sa ilalim ng pagbabawal, naniniwala ang lahat na ang pangarap ng China sa malalaking modelo ng AI ay magtatapos na.
Mali silang lahat. Sa harap ng pagkakasakop, hindi pumili ang mga Chinese company ng direkta at malakas na pagtutol, kundi nagsimula sila ng isang paglalabas. Ang unang battlefield ng paglalabas na ito, hindi sa chip, kundi sa algorithm.
Mula sa huling bahagi ng 2024 hanggang 2025, ang mga Chinese AI company ay nag-convert nang buong pagsasama sa isang teknikal na direksyon: hybrid expert model.
Sa simpleng termino, hinahati ang isang malaking modelo sa maraming maliit na eksperto, at habang inaangkop ang isang gawain, pinapagana lamang ang ilang pinakakaugnay na eksperto, hindi ang buong modelo.
Ang V3 ng DeepSeek ay isang klasikong halimbawa ng ideyang ito. Mayroon itong 671 bilyong parameter, ngunit bawat inference ay nagpapagana lamang ng 37 bilyon, o 5.5% lamang ng kabuuan. Sa kostong pagtatrain, gumamit ito ng 2,048 na NVIDIA H800 GPU, na tinrain sa loob ng 58 araw, na may kabuuang gastos na $5.576 milyon. Bilang komparasyon, ang inaasahang gastos sa pagtatrain ng GPT-4 ay halos $78 milyon. Isang antas ng pagkakaiba.
Ang ekstremong pag-optimize sa algorithm ay direktang nakikita sa presyo. Ang presyo ng API ng DeepSeek, ang input ay tanging $0.028 hanggang $0.28 bawat milyong token, at ang output ay $0.42. Samantala, ang presyo ng input ng GPT-4o ay $5, at ang output ay $15. Mas mahal pa ang Claude Opus, na may presyo ng $15 para sa input at $75 para sa output. Sa pagsasalin, mas mura ang DeepSeek ng 25 hanggang 75 beses kaysa sa Claude.
Ang pagkakaiba sa presyong ito ay nagdulot ng malaking reaksyon sa pandaigdigang merkado ng mga developer. Noong Pebrero 2026, sa OpenRouter, ang pinakamalaking platform para sa pagpagsasama ng AI model API sa buong mundo, ang lingguhang paggamit ng mga Chinese AI model ay tumalon ng 127% sa loob ng tatlong linggo at una naming lampaan ang United States. Isang taon ang nakalipas, ang bahagi ng Chinese models sa OpenRouter ay mas mababa sa 2%. Isang taon pagkatapos, tumataas ito ng 421% at malapit na sa anim na porsyento.
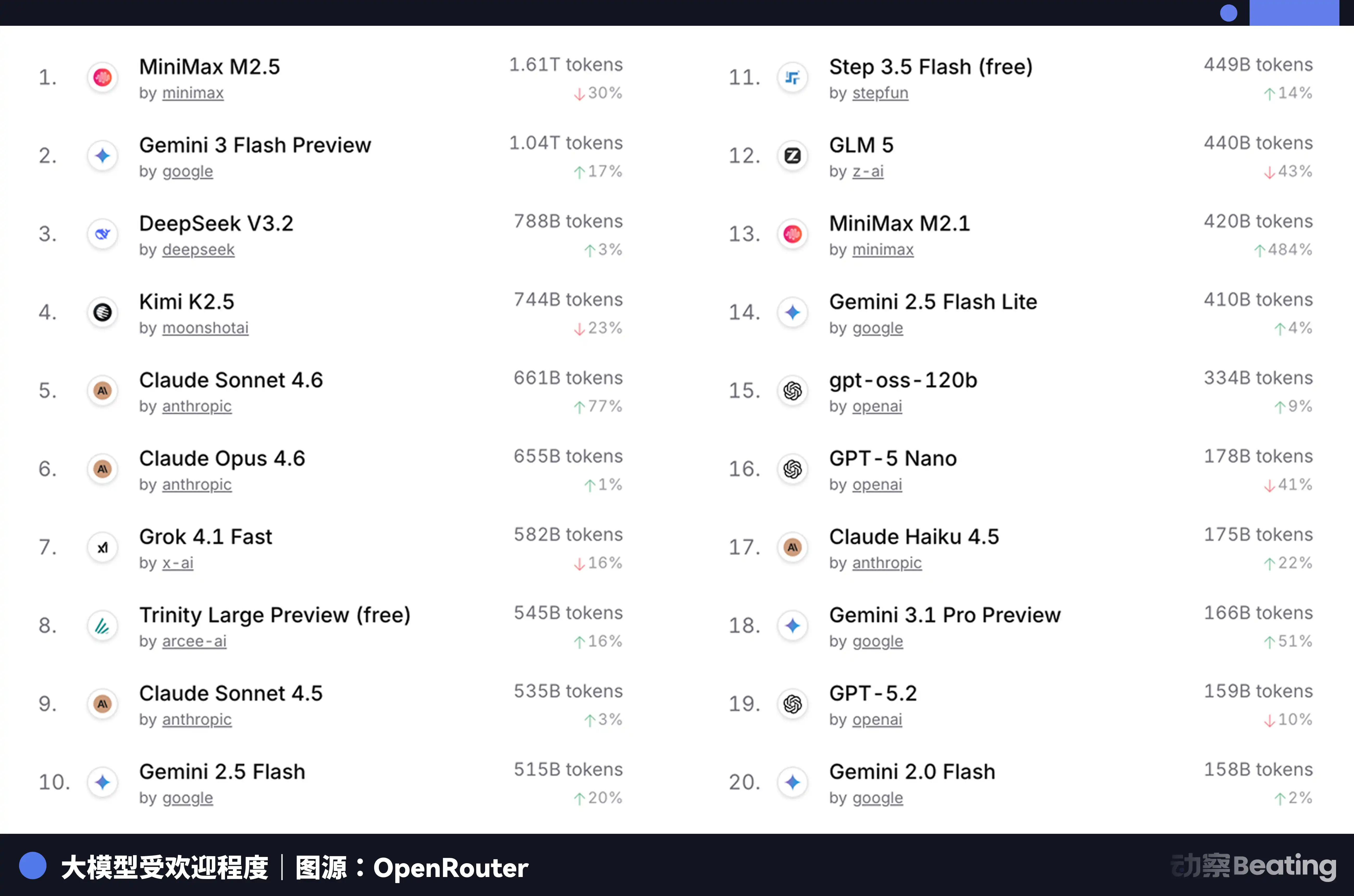
Sa likod ng data na ito, mayroong isang struktural na pagbabago na madalas na nalilimutan. Mula sa ikalawang kalahati ng 2025, ang pangunahing aplikasyon ng AI ay naglipat mula sa pag-uusap patungo sa Agent. Sa mga scenario ng Agent, ang paggamit ng Token sa isang task ay 10 hanggang 100 beses ang dami kaysa sa simpleng pag-uusap. Kapag tumataas nang eksponensyal ang paggamit ng Token, ang presyo ang naging desisyon. Ang ekstrim na halaga ng mga modelong Tsino ay tumpak na sumasakop sa window na ito.
Ngunit ang problema ay, ang pagbaba ng gastos sa pag-iisip ay hindi nalulutas ang pangunahing problema sa pagtatrain. Kung hindi makapag-train at mag-iterate ang isang malaking modelo sa pinakabagong data, mabilis na magiging mas mababa ang kanyang kakayahan. At ang pagtatrain, patuloy pa ring ang hindi maiiwasang black hole ng computing power.
Kung gayon, saan galing ang naitraining na «spade»?
Promotion ng backup
Jiangsu Xinghua, isang maliit na lungsod sa Jiangsu, kilala sa kanyang stainless steel at mga healthy na pagkain, at dati ay walang kinalaman sa AI. Ngunit noong 2025, isang lokal na production line para sa servers ng computing power na 148 metro ang haba ay itinayo at pinagsimulan dito, at mula sa pag-sign ng kasunduan hanggang sa pagpapatakbo, nagtagal lamang ito ng 180 araw.
Ang core ng produksyon na ito ay dalawang buong lokal na chip: ang Loongson 3C6000 processor at ang TaiChu Yuanqi T100 AI accelerator card. Ang Loongson 3C6000 ay may sariling disenyo mula sa instruction set hanggang sa microarchitecture. Ang TaiChu Yuanqi ay nagmula sa National Supercomputing Center sa Wuxi at ang team ng Tsinghua University, at gumagamit ng heterogenous many-core architecture.
Kapag puno ang produksyon na linya, isang server ang nalalabas bawat 5 minuto, ang kabuuang pag-invest sa produksyon na linya ay 1.1 bilyon yuan, at inaasahang makapagproduksyon ng 100,000 unit taun-taon.
Mas mahalaga pa, ang mga cluster na may libo-libo ng mga lokal na chip ay nagsisimula nang tanggapin ang mga tunay na pag-train ng malalaking modelo.
Noong Enero 2026, inilabas ng Zhipu AI ang GLM-Image kasama ang Huawei, ang unang SOTA na image generation model na pinagsanay nang buo gamit ang mga lokal na chip. Noong Pebrero, natapos ng China Telecom ang pagsasanay ng buong proseso ng kanilang千亿-level na "Xingchen" na model sa lokal na compute pool na may libu-libong GPU sa Shanghai Lingang.

Ang kahalagahan ng mga kaso na ito ay nagpapatotoo sa isang bagay: ang mga lokal na chip, ay nagsilbi na mula sa «maaaring gamitin para sa inference» patungo sa «maaaring gamitin para sa training». Ito ay isang qualitative change. Ang inference ay nangangailangan lamang ng pagpapatakbo ng mga naitraining na model, kaya mas mababa ang mga kinakailangan sa chip; samantalang ang training ay nangangailangan ng paghahandle ng malaking dami ng data, kompleks na gradient computation at pag-update ng parameter, kaya mas mataas ng isang antas ang mga kinakailangan sa computing power, interconnect bandwidth, at software ecosystem ng chip.
Ang pangunahang puwersa sa paggawa ng mga gawain na ito ay ang Huawei Ascend series ng chips. Hanggang sa dulo ng 2025, ang bilang ng mga developer sa Ascend ecosystem ay lumampas na sa 4 milyon, habang ang mga kapartner ay higit sa 3,000, at 43 sa mga pangunahing malalaking model sa industriya ay natapos na ang pre-training gamit ang Ascend, kasama ang 200+ open-source models na nagsagawa ng adaptation. Noong Marso 2, 2026, sa MWC, ipinakilala rin ni Huawei ang bagong henerasyon ng compute infrastructure na SuperPoD para sa mga海外市场.
Ang FP16 computing power ng Ascend 910B ay naging katumbas na ng NVIDIA A100. Bagaman mayroon pa ring pagkakaiba, naging maaaring gamitin na ito mula sa hindi maaaring gamitin, at patuloy na nagsisiguro na maging mas mahusay. Ang pagbuo ng ecosystem ay hindi dapat hintayin hanggang sa perpekto na ang chip—dapat itong malawakang ipakilala sa panahon na sapat na ito, gamit ang totoong pangangailangan ng negosyo upang pilitin ang pag-update ng chip at software. Ang mga layunin ng ByteDance, Tencent, at Baidu sa pagpapakilala ng lokal na server para sa computing ay karaniwang magdoble noong 2026 kumpara sa nakaraang taon. Ayon sa data ng Ministry of Industry and Information Technology, ang sukat ng intelligent computing sa China ay umabot na sa 1590 EFLOPS. Ang 2026 ay nagsisimula na bilang taon ng malawakang pag-deploy ng lokal na computing power.
Kulang sa kuryente sa Amerika at paglalabas ng China
Sa simula ng 2026, ang Virginia, na nagdudulot ng malaking bahagi ng traffic ng data center sa buong mundo, ay nagpahinga sa pagpapahintulot sa mga bagong proyekto ng data center. Sumunod ang Georgia, na nagpahinga sa pagpapahintulot hanggang 2027. Sumunod ang Illinois at Michigan sa pagpapalabas ng mga limitasyon.
Ayon sa data ng International Energy Agency, ang pagkakagamit ng kuryente ng mga data center sa Estados Unidos noong 2024 ay umabot na sa 183 terawatt-hours, o humigit-kumulang 4% ng kabuuang pagkakagamit ng kuryente sa bansa. Hanggang 2030, inaasahan na magdoble ang bilang na ito hanggang sa 426 TWh, at maaaring lampasin ang 12%. Higit pa rito, ang CEO ng Arm ay nagsabing hanggang 2030, ang mga data center ng AI ay maaaring mag-consume ng 20% hanggang 25% ng kuryente sa Estados Unidos.
Ang grid ng Estados Unidos ay nasa labas na ng kanyang kakayahan. Ang PJM grid na sumasakop sa 13 na estado sa silangan ng Estados Unidos ay nagtataglay ng kakulangan sa kapasidad na 6GW. Sa pamamagitan ng 2033, ang buong Estados Unidos ay makakaharap sa kakulangan sa kapasidad ng kuryente na 175GW, katumbas ng paggamit ng enerhiya ng 130 milyong pamilya. Ang presyo ng elektrisidad sa pambansang antas sa mga rehiyon kung saan nakokusentra ang mga data center, ay tumataas ng 267% kumpara sa limang taon na ang nakalipas.
Ang hangganan ng computing power ay ang enerhiya. At sa aspeto ng enerhiya, ang pagkakaiba sa pagitan ng China at Estados Unidos ay mas malaki kaysa sa chip, ngunit ang direksyon ay kabaligtaran.
Ang taunang paggawa ng kuryente sa Tsina ay 10.4 trilyon na yunit, habang sa Estados Unidos ay 4.2 trilyon na yunit, kaya ang Tsina ay 2.5 beses ang dami ng Estados Unidos. Mas mahalaga pa, ang paggamit ng kuryente para sa pamilya sa Tsina ay bumubuo lamang ng 15% ng kabuuang paggamit, habang sa Estados Unidos ay 36%. Ibig sabihin nito na mayroong mas malaking kakayahan sa industriyal na paggamit ng kuryente sa Tsina na maaaring i-deploy para sa pagbuo ng computing power.
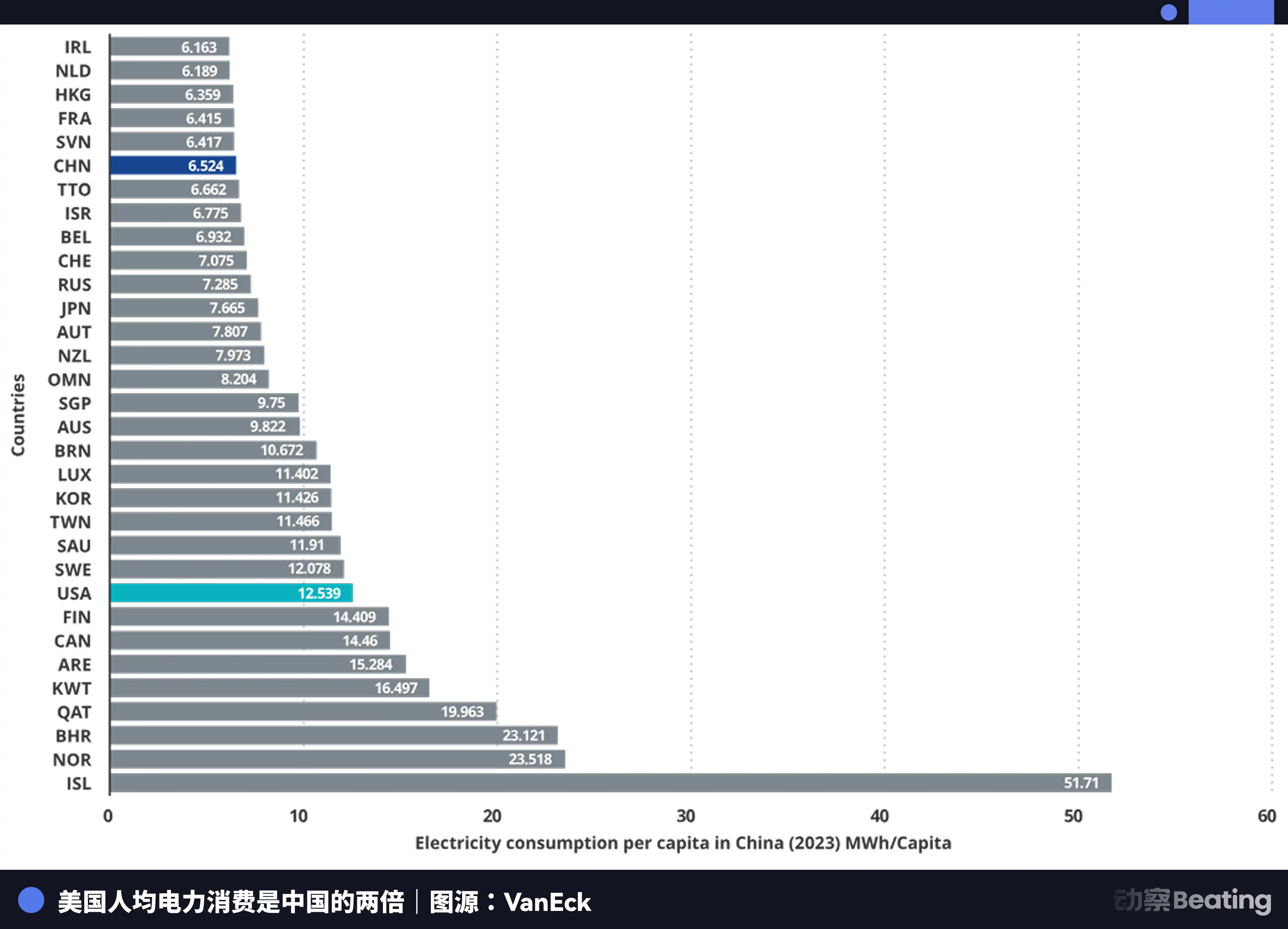
Sa presyo ng kuryente, ang presyo ng kuryente sa mga rehiyon kung saan nakapokus ang mga American AI company ay nasa $0.12 hanggang $0.15 kada kilowatt-hour, habang ang industriyal na presyo ng kuryente sa kanlurang China ay halos $0.03, na lamang ang kalahati o isang-kalimang bahagi ng presyo sa Amerika.
Ang pagdami ng paggawa ng kuryente sa Tsina ay umabot na sa 7 beses ang dami ng Amerika.
Samantalang nag-aalala ang Amerika tungkol sa kuryente, ang AI ng Tsina ay umuunlad nang tahimik sa ibang bansa. Ngunit ang beses na ito, hindi ang produkto o pabrika ang umuunlad, kundi ang Token.
Ang token, ang pinakamaliit na yunit ng impormasyon na kinokonsidera ng AI model, ay nagsisimula nang maging isang bagong digital na komodidad. Ipinaproduko ito sa mga factory ng computing power sa Tsina at ipinapadala sa buong mundo sa pamamagitan ng mga ilalim-angat na kable.
Ang datos sa distribusyon ng mga user ng DeepSeek ay malinaw: 30.7% mula sa China, 13.6% mula sa India, 6.9% mula sa Indonesia, 4.3% mula sa Estados Unidos, at 3.2% mula sa Pransya. Ito ay sumusuporta sa 37 mga wika at malawakang pinapahalagahan sa mga bagong merkado tulad ng Brazil. Mayroon nang 26,000 mga kumpanya sa buong mundo na may account, at 3,200 mga institusyon ang nagsasagawa ng enterprise version.
Sa taon na 2025, 58% ng mga bagong AI startup ay isinama ang DeepSeek sa kanilang tech stack. Sa China, kinuha ng DeepSeek ang 89% ng market share. Samantala, sa iba pang mga bansang pinagsanay, ang market share ay nasa pagitan ng 40% hanggang 60%.
Ang tanawing ito, parang isang digmaan tungkol sa pagkakawala ng kontrol sa industriya na naganap apat na dekada ang nakalipas.
Sa Tokyo no 1986, sa ilalim ng malakas na presyon mula sa Estados Unidos, ang pamahalaan ng Japan ay nilagdaan ang US-Japan Semiconductor Agreement. Ang tatlong pangunahing katangian ng kasunduan ay: ang paghingi na buksan ang merkado ng semiconductor ng Japan, ang antas ng bahagi ng merkado ng mga chip mula sa Estados Unidos ay dapat na higit sa 20%; ang pagbawal sa pag-export ng mga semiconductor ng Japan sa mas mababang presyo kaysa sa gastos; at ang pagpapautang ng 100% na parusa sa 3 bilyong dolyar na mga chip na exportado ng Japan. Samantala, tinanggihan ng Estados Unidos ang pagkakabili ni Fujitsu sa Fairchild Semiconductor.
Noong taong iyon, ang industriya ng semiconductor ng Japan ay nasa apogyo nito. Noong 1988, kinontrol ng Japan ang 51% ng global semiconductor market, samantalang ang Amerika ay may 36.8%. Sa mga top 10 na kumpanya ng semiconductor sa buong mundo, anim ang mula sa Japan: NEC sa pangalawang posisyon, Toshiba sa ikatlo, Hitachi sa ikalima, Fujitsu sa ikapito, Mitsubishi sa ikawalo, at Panasonic sa ikasiyam. Noong 1985, nagkawalan ng $173 milyon ang Intel sa digmaan ng semiconductor sa pagitan ng Amerika at Japan at nasa dulo na ng pagkabigo.
Ngunit pagkatapos ng pagkakasign ng kasunduan, nagbago lahat.
Ginamit ng Amerika ang mga paraan tulad ng pagsisiyasat sa ilalim ng Section 301 upang magbigay ng buong pagpapigil sa mga Japanese semiconductor company. Samantala, sinuportahan nila ang Samsung at SK Hynix ng Korea upang ipaglaban ang merkado ng Japan sa mas mababang presyo. Bumaba ang bahagi ng Japan sa DRAM mula sa 80% patungo sa 10%. Hanggang 2017, natira na lang ang 7% ng bahagi ng Japan sa IC market. Ang mga dating malakas na kompanya, o nahati, o binili, o umalis nang mapapalabas sa walang katapusang pagkawala.
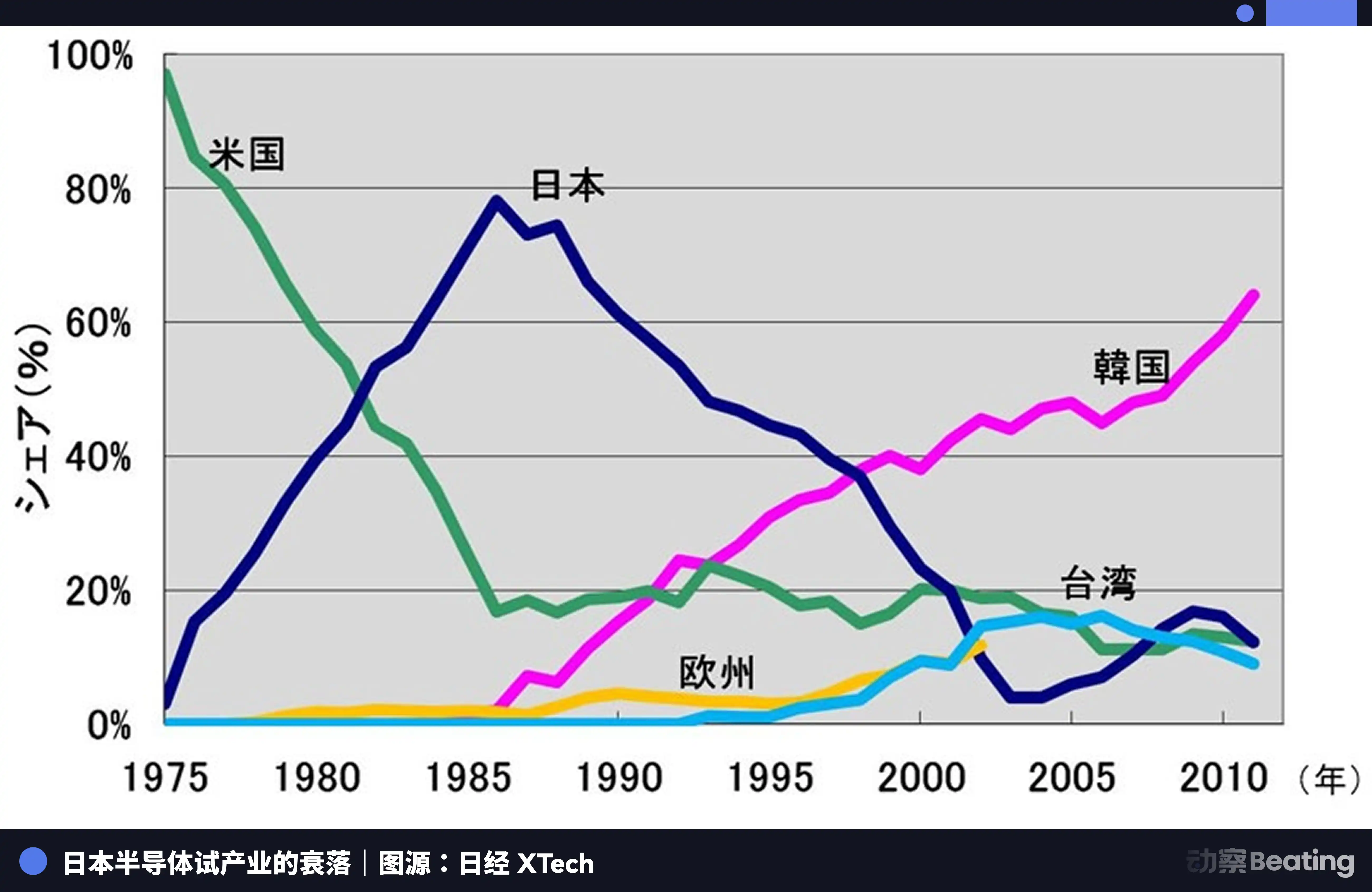
Ang trahedya ng mga Japanese semiconductor ay nasa pagiging masaya sila sa isang pandaigdigang paghahati ng trabaho na pinamumunuan ng isang panlabas na puwersa, bilang pinakamahusay na tagapagprodyus, ngunit hindi nag-isip na bumuo ng isang sariling, independiyenteng ekosistema. Nang bumaba ang alon, nalaman nila na wala silang iba kundi ang paggawa mismo.
Ang kasalukuyang industriya ng AI sa Tsina ay nasa isang katulad ngunit ganap na iba't ibang krusada.
Kaugnay nito, kami ay nagtatagpo rin ng malaking presyon mula sa labas. Tatlong pagkakataon ng pagpapahigpit sa chip, patuloy na pinalalakas, at ang hadlang sa CUDA ecosystem ay patuloy na mataas.
Sa pagkakaiba, sa pagkakataong ito, pinili namin ang mas mahirap na daan—mula sa ekstrim na pag-optimize sa antas ng algorithm, sa paglalakbay ng lokal na chip mula sa inference hanggang sa training, sa pagkolekta ng 4 milyong developer sa Ascend ecosystem, hanggang sa pagpapalaganap ng Token sa global na merkado. Bawat hakbang sa daang ito ay nagtatayo ng isang independiyenteng industriyal na ecosystem na hindi pernah mayroon ang Japan.
Wakas
Ipinaglaban noong Pebrero 27, 2026, ang tatlong mga ulat sa pagganap mula sa mga lokal na kumpanya ng AI chip.
Cambrian, tumataas ang kita ng 453%, unang nakamit ang pagsasagawa ng kikitain sa buong taon. Moore Threads, tumataas ang kita ng 243%, ngunit may net loss na 1 bilyon. Muxi, tumataas ang kita ng 121%, net loss na halos 8 bilyon.
Kalahati ay apoy, kalahati ay tubig.
Ang apoy ay ang kawalan ng pagkain ng merkado. Ang 95% na puwang na inilabas ni Huang Renxun ay tinatapos ng mga numero ng kita ng mga lokal na kumpanya, isa-isang pagsasakatuparan. Anuman ang performance, anuman ang ecosystem, kailangan ng merkado ang pangalawang pagpipilian kung saan wala si NVIDIA. Ito ay isang hindi karaniwang struktural na pagkakataon na tinuklas ng geopolitika.
Ang dagat ay isang malaking gastos sa pagbuo ng ekosistema. Bawat pagkawala ay isang tunay na pera na ginugol para makasunod sa ekosistema ng CUDA. Ito ay mga gastos sa pag-aaral, mga subsidy sa software, at mga gastos sa pagpapadala ng mga inhinyero sa lugar ng kliyente upang solusyunan ang bawat isyu sa compilation. Ang mga pagkawalang ito ay hindi dahil sa mahinang pagpapatakbo, kundi isang kinakailangang buwis ng digmaan para sa pagbuo ng isang independiyenteng ekosistema.
Ang tatlong talaan ng pagsusuri na ito ay mas tapat na isinulat ang totoong kalagayan ng digmaan sa hash power kaysa sa anumang report sa industriya. Hindi ito isang tagumpay na puno ng pagdiriwang, kundi isang malupit na labanan sa posisyon, kung saan ang mga sundalo ay tumataas habang nagdudugo.
Ngunit ang anyo ng digmaan ay talagang nagbago. Walong taon ang nakalipas, tinatalakay natin ang tanong na “kaya ba nating mabuhay.” Ngayon, tinatalakay natin ang tanong na “ano ang gastos na kailangang ibayad upang mabuhay.”
Ang gastos mismo ay ang pag-unlad.
I-click para malaman ang mga posisyon na hinahanap ni BlockBeats
Maligayang pagdating sa opisyal na komunidad ng BlockBeats:
Telegram subscription group: https://t.me/theblockbeats
Telegram group: https://t.me/BlockBeats_App
Twitter official account: https://twitter.com/BlockBeatsAsia