










Awtor: KarenZ, Foresight News
Noong Marso 20, 2026, may isang hindi karaniwang talakayan sa podcast ng All-In Ventures.
Inihulog ni Chamath Palihapitiya, isang malaking venture capitalist, ang salita kay Jensen Huang, CEO ng NVIDIA, na may isang proyekto sa Bittensor na "nakamit ang isang lubos na kamangha-manghang teknikal na tagumpay" sa pamamagitan ng pag-train ng isang malaking language model sa internet gamit ang distributed computing, na ganap na decentralizado at walang anumang sentralisadong data center na nakikilahok.
Hindi sinarhan ni Huang Renxun ang isyu. Ipinaghambing niya ito sa "modern version ng Folding@home," ang distributed project na nagbigay-daan sa karaniwang gumagamit na mag-contribute ng kanilang walang ginagawang computing power upang tulungan lutasin ang problema ng protein folding noong mga taon na 2000.
Sa 4 na araw bago ito, noong Marso 16, ginamit ni Jack Clark, co-founder ng Anthropic, ang malaking bahagi ng kanyang ulat tungkol sa pag-unlad sa AI upang bigyang-diin at i-cite ang pagbuo na ito: Nakumpleto ng Bittensor ecosystem subnet na Templar (SN3) ang distributed training ng malaking modelo na may 72 bilyong parameter (Covenant 72B), na may performance na katumbas ng LLaMA-2 na inilabas ni Meta noong 2023.
Inilah ang pamagat na ibinigay ni Jack Clark sa kabanata: “Challenging the Political Economy of AI through Distributed Training,” at tekad na pinahalagahan niya ito bilang isang teknolohiya na dapat patuloy na suportahan—nakikita niya ang isang hinaharap kung saan ang device-side AI ay malawakang gagamit ng mga modelo na galing sa decentralized training, habang ang cloud-based AI ay patuloy na pagsasagawa ng proprietary large models.
Ang reaksyon ng merkado ay kaunting pagkakalate ngunit napakalakas: tumaas ang SN3 ng higit sa 440% sa nakaraang buwan at ng higit sa 340% sa nakaraang dalawang linggo, na nagresulta sa market cap na $130 milyon. Ang pag-usbong ng kuwento ng subnet ay direktang magdudulot ng presyur sa pagbili ng TAO. Dahil dito, tumaas nang mabilis ang TAO, nakamit ang $377 sa isang punto, na nagdoble sa nakaraang buwan, at ang FDV ay umabot sa halos $7.5 bilyon.
May tanong: Ano nga ba ang ginawa ng SN3? Bakit itinangi sa ilaw ng kamera? Paano magiging pag-unlad ang kuwento ng halaga ng distributed training at decentralized AI?
Yun ang 72B na model
Upang sagutin ang tanong na ito, kailangan mong tingnan nang mabuti ang resulta ng SN3.
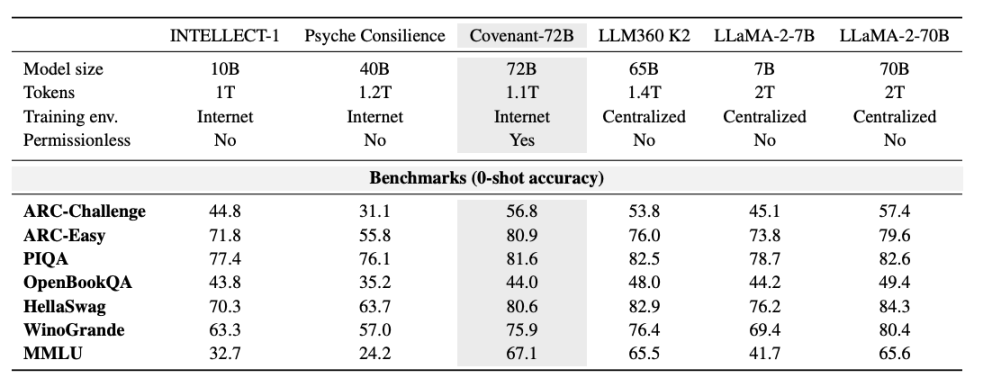
Noong Marso 10, 2026, ang koponan ng Covenant AI ay nag-post ng isang teknikal na ulat sa arXiv, na opisyal na nagpahayag na natapos na ang pagtatrain ng Covenant-72B. Ito ay isang malaking modelo ng wika na may 72 bilyong parameter, na natutunan sa higit sa 70 hiwalay na node peers (tungkol sa 20 node ang synchronous bawat round, bawat node ay may 8 B200 GPUs), sa isang corpus na may halos 1.1 trilyon na tokens.
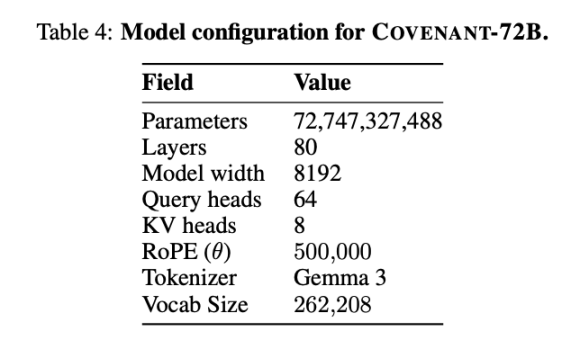
Binigay ng Templar ang ilang data sa pagpapahalaga, kung saan ang LLaMA-2-70B na ginamit bilang komparasyon ay ang malaking modelo na inilabas ni Meta noong 2023. Ayon kay Jack Clark, co-founder ng Anthropic, maaaring maging obsolete na ang Covenant-72B noong 2026. Ang marka ng 67.1 ng Covenant-72B sa MMLU ay halos katumbas ng LLaMA-2-70B na inilabas ni Meta noong 2023 (65.6).
Ang mga modelo ng 2026—kung ito ay ang serye ng GPT, Claude, o Gemini—ay nagsagawa na ng pagtuturo na may higit sa 100 bilyon na parameter sa mga libo-libong GPU, at ang pagkakaiba sa kakayahan sa pagpapaliwanag, code, at matematika ay isang hanay ng pagkakaiba, hindi isang porsyento. Dapat hindi mabawasan ang realyeng pagkakaiba na ito sa pamamagitan ng emosyon ng merkado.
Ngunit kapag isinasaalang-alang ang pamamaraan na "pinatutunaw gamit ang distributed computing sa open internet," iba ang kahulugan.
Gawin ang paghahambing: Parehong decentralized training, ang INTELLECT-1 (gawa ng Prime Intellect team, 10 bilyong parameter) ay may MMLU score na 32.7; samantalang ang iba pang distributed training project na Psyche Consilience (40 bilyong parameter) na ginanap sa loob ng whitelist participants ay may score na 24.2. Ang Covenant-72B ay may 72B na sukat at MMLU score na 67.1, isang nakakatangi na numero sa larangan ng decentralized training.
Mas mahalaga pa, ang pagtatrain na ito ay “walang pahintulot.” Maaaring makakonekta ang sinuman bilang participating node, walang kailangang pagsusuri o whitelist bago. Higit sa 70 na independiyenteng node ang nakikilahok sa pag-update ng model, na nagmumula sa iba’t ibang bahagi ng mundo at nag-aambag ng computing power.
Ano ang sinabi ni Huang Renxun, at ano ang hindi sinabi
Iwasan ang pagkakamali sa pag-unawa sa pagsuportang ito sa pamamagitan ng pagpapalit ng mga detalye ng talakayan sa podcast.
Ipinakita ni Chamath Palihapitiya sa usapan ang teknikal na tagumpay ng Bittensor kay Huang Renxun, at ilarawan ito bilang pag-train ng isang Llama model gamit ang distributed computing, na "kumpletong distributed habang pinapanatili ang estado." Ang tugon ni Huang Renxun ay ang paghahambing nito sa "modern-day Folding@home," at pinag-usapan niya ang kahalagahan ng paralel na pagkakaroon ng open-source at proprietary models.
Mahalagang tandaan na hindi direktang nabanggit ni Huang Renxun ang token ng Bittensor o anumang implikasyon sa pag-invest, at hindi rin itinuloy ang pagtalakay sa decentralized AI training.
Unawain ang Bittensor subnets at SN3
Upang maunawaan ang pagtemo ng SN3, kailangan muna mong maunawaan ang paggana ng Bittensor at mga subnetwork nito. Sa simpleng salita, ang Bittensor ay maaaring ituring na isang AI blockchain at platform, at bawat subnetwork ay katulad ng isang hiwalay na “production line ng AI,” na may sariling malinaw na pangunahing gawain at disenyo ng incentive mechanism, na nagtatagpo upang bumuo ng isang decentralized AI ecosystem.
Ang proseso nito ay malinaw at decentralizado: ang mga owner ng subnet ay tumukoy ng mga layunin ng subnet at sumulat ng modelo ng insentibo; ang mga miner ay nagbibigay ng computing power sa subnet at natatapos ang mga AI-related na gawain (tulad ng inference, training, storage, atbp.); ang mga validator ay nagbibigay ng puntos sa kontribusyon ng mga miner at nag-uupload ng kanilang skor sa Bittensor consensus layer; sa huli, ang Yuma consensus algorithm ng Bittensor ay nag-aalok ng tamang kita sa mga participant ng subnet batay sa kumulatibong reward ng bawat subnet.
Kasalukuyang may 128 na subnet sa Bittensor, na kumakapal ng iba’t ibang AI task tulad ng inference, serverless AI cloud services, imahe, data labeling, reinforcement learning, storage, at computation.
Ang SN3 ay isa sa mga subnetwork nito. Hindi ito gumagamit ng application-layer abstraction o nagpapautang ng mga umiiral na API ng malalaking modelo; kundi direktang tumutok sa isa sa pinakamahal at pinakasarado na mga bahagi ng buong chain ng AI: ang sariling pre-training ng malalaking modelo.
Gusto ng SN3 na gamitin ang Bittensor network para sa distributed training ng heterogenous computing resources, at patunayan na sa pamamagitan ng incentive-based distributed large model training, maaaring makapag-train ng malakas na base model nang walang kailangan ng mahal na centralized supercomputer clusters. Ang pangunahing atraksyon ay ang “pagkakapantay-pantay” — pagbubukas ng monopoliyo sa mga yaman ng centralized training, upang bigyan ng pagkakataon ang karaniwang indibidwal o mga maliit at katamtamang institusyon na makilahok sa pag-train ng malalaking model, habang ginagamit ang distributed computing power upang bawasan ang gastos sa pag-train.
Ang pangunahang puwersa sa pagpapalago ng SN3 ay ang Templar, na may likod na research team na Covenant Labs. Parehong pinapatakbo ng team ang dalawang iba pang subnets: Basilica (SN39, nakatuon sa computing services) at Grail (SN81, nakatuon sa RL post-training at model evaluation). Ang tatlong subnets ay bumubuo ng vertical integration na nakakapag-iskedyul ng buong proseso mula sa pre-training hanggang sa alignment optimization ng malalaking modelo, at nagtatayo ng isang buong ecosystem para sa decentralized large model training.
Sa partikular, ang mga miner ay nag-aambag ng computing resources at nag-uupload ng gradient updates (direksyon at lakas ng pag-adjust ng mga parameter ng model) sa network; ang mga validator ay nag-evaluate ng kalidad ng bawat kontribusyon ng miner at nagbibigay ng on-chain score batay sa antas ng pagpapabuti ng error. Ang resulta ay tumutukoy sa weights ng reward, na awtomatikong ikinakabuot nang walang kailangang maniwala sa anumang third party.
Ang susi sa pagdidisenyo ng incentive system ay ang pagkakapag-ugnay ng mga reward direktang sa "kung gaano ka-kalakas ang iyong kontribusyon sa pagpapabuti ng modelo", hindi lamang sa pagpapagana ng computing power. Ito ang nakakasolusyon sa pinakamahirap na problema sa decentralized scenario: paano maiiwasan ang pagmamaliit ng mga miner.
Paano nilulutas ng Covenant-72B ang mga problema sa efisiyensiya ng komunikasyon at incentive compatibility?
Ang pagpapagana ng isang parehong modelo ng mga node na hindi nagkakatiwalaan, may iba’t ibang hardware, at iba’t ibang kalidad ng network, ay may dalawang hamon: una, ang efisiyensiya ng komunikasyon—ang mga tradisyonal na solusyon sa distributed training ay nangangailangan ng mataas na bandwidth at mababang latency sa pagitan ng mga node; at pangalawa, ang incentive compatibility—paano maiiwasan ang mga masasamang node na magsumite ng maling gradient? Paano masisiguro na bawat participant ay talagang nagtatrabaho nang maayos, at hindi lang nagpapakopya sa mga resulta ng iba?
Nilutas ng SN3 ang dalawang problema gamit ang dalawang pangunahing komponente: SparseLoCo at Gauntlet.
Nilulutas ng SparseLoCo ang mga problema sa efisiyensiya ng komunikasyon. Sa tradisyonal na distributed training, sinusync ang buong gradient sa bawat hakbang, na nagdudulot ng malaking dami ng data. Ang solusyon na ginagamit ng SparseLoCo ay: bawat node ay nagpapatakbo ng 30 hakbang ng lokal na optimisasyon (AdamW), at pagkatapos ay ina-compress ang mga "pseudogradient" na nabuo bago ito i-upload sa ibang mga node. Ang mga paraan ng kompresyon ay kasama ang Top-k sparsification (pagpapanatili lamang ng pinakamahalagang mga gradient component), error feedback (pag-iimbak ng mga inalis na bahagi para sa akumulasyon sa susunod na round), at 2-bit quantization. Ang huling compression ratio ay hihigit sa 146 beses.
Sa ibang salita, kung dating kailangan ng 100MB na pagpapadala, ngayon ay sapat na ang mas maliit sa 1MB.
Nakakapagpapanatili ng paggamit ng compute sa halos 94.5% sa ilalim ng limitasyon sa bandwidth ng karaniwang internet (110 Mbps upload, 500 Mbps download)—20 nodes, 8 B200s bawat node, at tanging 70 segundo ang tagal ng bawat round ng komunikasyon.
Ang Gauntlet ay naglulutas ng problema sa incentive compatibility. Ito ay tumatakbo sa Bittensor blockchain (Subnet 3) at responsable sa pag-verify ng kalidad ng pseudo-gradients na isumite ng bawat node. Ang paraan nito: sinusubok ang isang maliit na batch ng data upang matukoy "kung gaano karaming bumaba ang model loss pagkatapos gamitin ang gradient ng node na ito", at ang resulta ay tinatawag na LossScore. Samantala, sinusuri ng sistema kung ang node ay nagtuturo gamit ang sarili nitong nakalaan na data—kung ang isang node ay mas mabuting pagbuti ang loss sa random na data kaysa sa sarili nitong nakalaan na data, makakatanggap ito ng negative score.
Sa huling bahagi, sa bawat round ng pagtatrabaho, ang gradient ng node na may pinakamataas na skor lamang ang kinukuha para sa aggregation, at ang iba ay inalis sa round na iyon. Ang mga karagdagang kalahati ay maaaring magpapalit nang anumang oras upang mapanatili ang katatagan ng sistema. Sa buong proseso ng pagtatrabaho, ang average na bilang ng nodes na gradient ay kinabibilangan sa bawat round ay 16.9, at higit sa 70 ang natatanging node ID na nakilahok.
Ang value narrative ng decentralized AI ay nagsisimula ng fundamental na pagbabago
Mula sa pananaw ng teknikal at industriya, may ilang tunay na kahulugan ang direksyon na kinakatawan ng Covenant-72B.
Una, na-break ang palagay na ang distributed training ay only suitable para sa mga maliit na model. Kahit pa hindi pa kasalungat sa mga pinakabagong model, ipinakita nito ang scalability ng direksyong ito.
Ikalawa, ang walang pahintulot na pagkakaroon ng pagkakataon ay totoo at maaari. Ito ay nababawasan ang kahalagahan. Ang mga nakaraang proyekto ng distributed training ay nakadepende sa whitelist—kung saan ang mga nakakatulong ay maaaring mag-ambag ng computing power lamang kung sila ay na-approve. Sa pagtratrabaho na ito ng SN3, anumang may sapat na computing power ay maaaring makikilala, at ang mekanismo ng pag-verify ang responsable sa pag-filter ng masasamang ambag. Ito ay isang konkretong hakbang patungo sa “totoong de sentralisado”.
Ikatlo, ang dTAO mechanism ng Bittensor ay nagpapahintulot sa paghahanap ng halaga ng subnet. Ang dTAO ay nagpapahintulot sa bawat subnet na maglabas ng sariling Alpha token, at sa pamamagitan ng AMM mechanism, pinapasyahan ng merkado kung aling subnet ang makakatanggap ng mas maraming TAO distribution. Ito ay nagbibigay ng isang simpleng ngunit epektibong mekanismo para sa pagkuha ng halaga para sa mga subnet tulad ng SN3 na nakapagbigay ng konkretong resulta. Bagaman, ang mekanismong ito ay madaling maapektuhan ng mga kuwento at emosyon, at mahirap masuri nang independiyente ng karaniwang mga tagapag-ugnay sa merkado ang kalidad ng LLM training results.
Ikaapat, ang pulitikal at ekonomikong kahulugan ng decentralizadong pag-train ng AI. Ipinataas ni Jack Clark sa Import AI ang tanong na ito sa antas ng “Sino ang may-ari ng kinabukasan ng AI?” Ang kasalukuyang pag-train ng mga advanced na modelo ay monopoliyo ng ilang institusyon na may malalaking data center, at ito ay hindi lamang isang problema sa negosyo kundi isang isyu sa istruktura ng kapangyarihan. Kung magtatagumpay ang distributed training sa patuloy na teknikal na pag-unlad, maaari itong magbuo ng totoong decentralizadong ecosystem sa pag-unlad para sa ilang uri ng modelo (tulad ng mga maliit na advanced na modelo sa partikular na larangan). Gayunpaman, ang pag-asa na ito ay kasalukuyang malayo pa.
Buod: Isang totoong hakbang at maraming totoong problema
Sinabi ni Huang Renxun na ito ay parang "modern-day Folding@home". Ang Folding@home ay nagbigay ng tunay na kontribusyon sa larangan ng molecular simulation, ngunit hindi ito nagbanta sa pangunahing posisyon ng malalaking kumpanya ng gamot sa pag-aaral at pag-unlad. Ang pagkukumpara na ito ay napakatumpak.
Nakapag-isip na ang SN3 ng protokolo at na-verify ang mga posibleng direksyon ng distributed training. Ngunit mula sa pananaw ng teknolohiya at industriya, mayroon pa ring maraming isyu na rare na pinag-uusapan nang serio sa likod ng resultang ito:
Ang MMLU ay isang indikador na may kontrobersiya sa akademya, at may panganib na mabawasan ang mga tanong at sagot sa pampublikong benchmark sa training set. Mas mahalaga ang pagpili ng baseline para sa paghahambing: ang LLaMA-2-70B at LLM360 K2 na ginamit bilang baseline sa papel ay mga lumang modelo mula sa 2023 hanggang 2024, habang ang parehong antas ng 65 hanggang 70 puntos ay itinuturing na mid to low at entry-level kapag tinanong ang Grok at DouBao, at itinuturing na malalim na nakalipas sa pananaw ng Claude. Kung isasama ito sa isang dinamikong updated na listahan o sa mga bagong benchmark na may disenyo laban sa kontaminasyon, ang konklusyon ay maaaring maging mas tapat.
Mas mahalaga pa, ang mataas na kalidad na data na nagpapasya sa hangganan ng kakayahan ng modelo—ang mga data sa diyalogo, code, matematikal na pagdeduksyon, at agham na pagsusulat—ay malamang nasa kamay ng mga malalaking kumpanya, mga ahensya sa pagpapalabas, at mga akademikong database. Ang compute power ay naging demokratiko, ngunit ang data ay nananatiling oligopolistikong istruktura, at ang kontradiksyong ito ay hindi pa binanggit.
Tungkol sa kaligtasan, ang pagkakaroon ng walang pahintulot na pagkakasali ay nangangahulugan na hindi mo alam sino ang nasa likod ng higit sa 70 na mga node at ano ang mga data na ginagamit nila para sa pagtuturo. Ang Gauntlet ay makakafilter ng mga malinaw na anomali sa gradient, ngunit hindi ito makakaprotektang laban sa mga subtil na pagpapahid ng data—kung ang isang node ay sistematikong nagtuturo ng ilang karagdagang round sa isang uri ng mapanganib na nilalaman, ang pagbabago sa gradient ay sapat na maliit upang makapasok sa pagsusuri ng loss score, ngunit magdudulot ng akumulatibong paglihis sa pag-uugali ng modelo. Ang huling tanong ay: Sa mga sitwasyon tulad ng finansyal, pangkalusugan, at batas na may mataas na pagpapatupad at mga kinakailangang pangkaligtasan, ano ang mga panganib na dulot ng paggamit ng isang modelo na itinuturo ng ilang anonymous na node at kung saan ang pinagmulan ng data ay hindi lubos na ma-track?
Mayroon pa isang struktural na problema na dapat sabihin nang direkta: ang Covenant-72B ay open source sa ilalim ng Apache 2.0 license at hindi gumagamit ng SN3 token. Ang paghawak ng SN3 token ay nagbibigay ng bahagi sa mga kita mula sa pag-output ng mga bagong modelo sa hinaharap, hindi sa anumang direkta na kita mula sa paggamit ng modelo. Ang value chain na ito ay nakadepende sa patuloy na pag-train at sa malusog na paggana ng buong Bittensor network emission mechanism. Kung ang pag-train ay mag-stagnate sa hinaharap, o kung ang mga bagong output ay hindi makakamit ang inaasahang kalidad, magiging mahina ang lohika sa pagbabahagi ng halaga ng token.
Ipinapakita ang mga tanong na ito, hindi upang sirain ang kahalagahan ng Covenant-72B. Ipinapatotohan nito na ang isang bagay na dating itinuturing na imposible ay maaaring gawin, at ang katotohanang ito ay hindi mawawala. Ngunit ang paggawa nito at ang kahulugan nito ay dalawang magkaibang bagay.
Ang SN3 token ay tumataas ng 440% sa nakaraang buwan. Ang distansyang ito ay maaaring hindi lamang isang pagpapalaganap, kundi ang bilis ng kuwento ay laging mas mabilis kaysa sa bilis ng katotohanan. Ang pagkakapuno ng distansyang ito sa pamamagitan ng katotohanan o pagkakasundo ng merkado ay naka-ugnay sa tunay na ipinapakita ng koponan ng Covenant AI sa susunod.
Mahalagang tandaan na ang Grayscale ay nagsumite ng aplikasyon para sa TAO ETF noong Enero 2026, na nagpapahiwatig ng pagpasok ng kapital mula sa mga institusyon sa larangan na ito. Bukod dito, binawasan ng Bittensor ang araw-araw na paglabas ng TAO sa kalagitnaan ng Disyembre 2025, at ang structural na pagkakabawas sa suplay ay patuloy na umuunlad.
Mga link na pang-referensya:
https://arxiv.org/pdf/2603.08163
https://importai.substack.com/p/importai-449-llms-training-other
https://docs.tplr.ai/
https://systems-analysis.ru/int/MMLU_Benchmark_%E2%80%94_MMLU_%E5%9F%BA%E5%87%86%E6%B5%8B%E8%AF%95