









Makakadream ba ang mga android? Kung makakadream sila, babalikan ba nila ang mga electronic sheep?

Screenshot mula sa pelikulang Blade Runner
Noong 1968, nang isulat ni Philip K. Dick, ang may-akda ng nobelang base sa pelikulang sci-fi na Blade Runner, ang abstrak at maagang tanong na ito sa kanyang typewriter, hindi niya inaasahan na higit sa isang kalahating siglo pagkatapos, ang mga malalaking teknolohiya sa Silicon Valley ay magbibigay ng sagot nang seryoso.
Oo, hindi lang sila nakakadambala ng mga elektronikong tupa, kundi kaya rin nilang mapapakita ang kanilang mga pangarap.
Kahapon, ipinakilala ng Anthropic sa developer conference sa San Francisco ang isang serye ng mga bagong tampok para sa kanilang agent building platform na Managed Agents: pagpapalawak ng memorya, paglabas ng resulta, multi-agent collaboration, at ang “Dreaming”.
Ayon sa sarili nilang pahayag, ang "memory (memory) at dreaming (pag-iisip) ay bumubuo ng isang matatag at makapagpapabuti sa sarili na sistema ng memory ng isang agent."

Mulî ulit ang pangarap, mulî ulit ang alaala, sa mga kaibigan na hindi masyadong nakikinig sa larangan ng AI, malamang ay puno ng tanong ang kanilang ulo—kailan ba nagsimula ang mga salitang ito na kabilang sa tao na maaaring gamitin nang ganito nang magaan sa AI?
Noong 2024, nang ipakilala ni OpenAI ang serye ng o1, ang “isang hanay ng mga AI model na disenyo upang magpass ng higit pang oras sa pag-iisip bago magbigay ng sagot,” ang salitang “pag-iisip” ay ginamit nang napakalikas, hanggang sa walang tumigil upang tanungin: paano isang programa na nagtataya ng susunod na token ay maaaring tawaging pag-iisip?
Susunod ay ang reasoning (pagsusuri), memory (memorya), reflection (pagsusuri), Imagining (pag-iisip), isang-isa ang mga gawain na makakagawa lang ng tao, isinasaad sa bawat pagpapakilala ng produkto.

Mga screenshot mula sa pelikula ng Miyazaki na “Paprika”
Ang "pag-iisip" ay maaaring maipaliwanag bilang metapora, ang "pagtanda" ay maaaring maikliw bilang pagpapalawig ng teknikal na terminolohiya, ngunit ang "pagdudumi" ay talagang sobra. Hindi pa nalalaman ng libu-libong taon ng panitikan, kasaysayan, at pilosopiya, ngunit ang mga kumpanya ng AI ay direktang sinasabi: Ginawa namin hindi lang ang mga makina na nakakapag-iisip, kundi ang mga makina na nakakadumi.
Ano ang pag-iisip, kaya ba ay walang anumang teknikal na termino sa engineering na maaaring ilarawan nang tumpak ang bagay na ito kundi ang pag-iisip?
Kailangan mong magbayad para sa pag-iisip ng AI
Sa panahon ng Claude Code data leak, nakita ng mga netizen na handa na si Anthropic sa isang tampok na tinatawag na Auto Dreaming. Noong panahong iyon, isipin ng lahat: ba't hindi ba kailangan ng AI tulad natin mga tao ang pagtulog at sapat na pagpapahinga upang maging mas nakatuon at mas matalino?
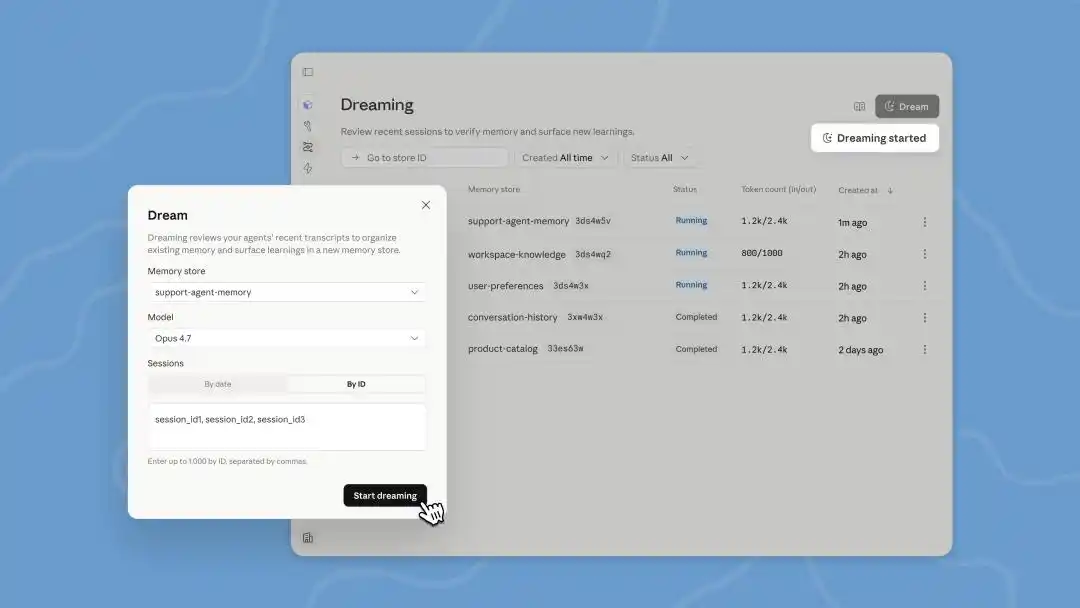
Ngunit sa pag-unawa sa kasalukuyang paraan ng paggana ng AI Agent, makikita na ang tinatawag na “pag-iisip” ay sa katotohanan ay isang awtomatikong batch processing ng offline log.
Ang AI Agent ay ngayon mas mahusay sa pagkumpleto ng mga kumplikadong gawain na may mahabang proseso. Halimbawa, “Tulongan mo akong suriin ang pinakabagong pagsasalaysay ng pananalapi ng limang kompetitor at i-organize ito sa isang talahanayan.” Sa prosesong ito, kailangan ng Agent na maglakbay sa iba’t ibang webpage, basahin ang maraming dokumento, gamitin ang iba’t ibang kasangkapan, at maaaring makaharap sa mga mekanismo ng pagtutol sa pag-scrapping at kailangang subukang muli.
Pagkatapos ng mahabang serye ng mga online na gawain, ang back-end ng Agent ay iiwan ng malaking dami ng mga log ng pagpapatakbo.
Ang larawan ay ginawa ng AI
Ang "pagmumuni-muni" na tampok ng Anthropic ay nagpapahintulot sa Agent na muli pang ayusin ang mga nakaraang rekord habang nasa idle state. Ito ay naghahanap ng mga pattern, tulad ng pagkakakilanlan na "kapag nakakasalubong ng ganitong popup, i-click ang itaas na kanan upang isara," upang mapabuti ang susunod na path ng aksyon.
Ang "memory" ay responsable sa pagkuha ng natutunan habang nagtatrabaho, habang ang "dreaming" ay nagpapalinaw sa mga alaala sa pagitan ng mga usapan at nagbabahagi nito sa iba't ibang Agent.
Sa madaling salita, ito ay isang reinforcement learning at self-correction mechanism na batay sa historical data.

Ang pagkakilala sa Dream: https://platform.claude.com/docs/en/managed-agents/dreams
Sa konhentong ito, ang mga update sa Dreams sa Managed Agents ay isang pagsasagawa sa likod, kailangan nating i-trigger nang manu-manu. Kay Claude ang kakayahang basahin ng pinakamaraming 100 session ng kasaysayan ng usapan, at pagkatapos ay lumikha ng isang bagong memory na maaari naming suriin bago magdesisyon kung gagamitin o hindi.
Ang AutoDream, na nagsimula nang tahimik sa Claude Code, ay susuriin sa background ng Claude Code kung dapat bang magdream pagkatapos ng bawat round ng pag-uusap sa Agent, at ang default ay isang beses sa loob ng 24 na oras.
Mayroon din ang Hermes Agent ng katulad na tampok na “pangarap.” Ang pangunahing pagkakakilanlan ng Hermes Agent ay ang kakayahang mag-aral at mag-evolve nang sarili, at ito ay sumusuporta sa awtomatikong pagbuo ng mga aral mula sa mga nakaraang gawain at pag-iimbak nito sa mga file ng memorya.

Ang isang tampok na tinatawag na Curator ay maaari ring awtomatikong i-organisa ang mga pinag-isang gabay sa paggawa bilang Skill.
Ang mga Skill na ito ay iskore, pinagsasama ang mga duplicated, at awtomatikong arkebuhin ang mga hindi nagagamit nang matagal, kahit mayroon pang buhay na siklo tulad ng active, stale, at archived. Maaari naming i-Pin ang mga mahalagang Skill upang hindi ito alisin ng sistema.
Idinagdag din ng OpenClaw ang mga kaugnay na mekanismo sa mga pinakabagong pag-update, tulad ng patuloy na memorya sa pagitan ng mga pag-uusap, jadwal ng mga gawain, pagpapagana ng mga sub-Agent nang hiwalay, at direkta ang pagtawag sa pagkakaroon ng pangarap.
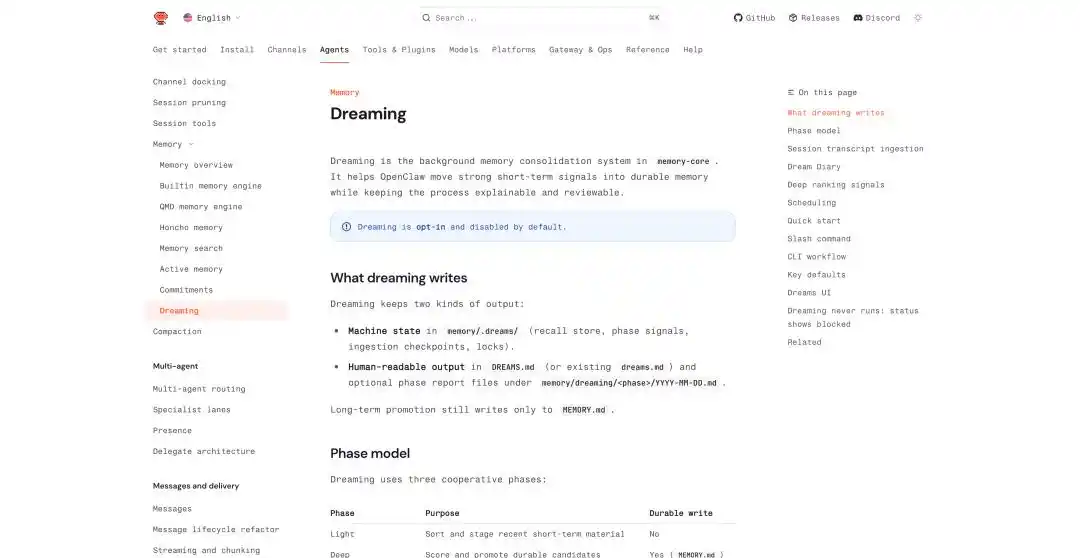
Ang pag-iisip ng OpenClaw: https://docs.openclaw.ai/concepts/dreaming
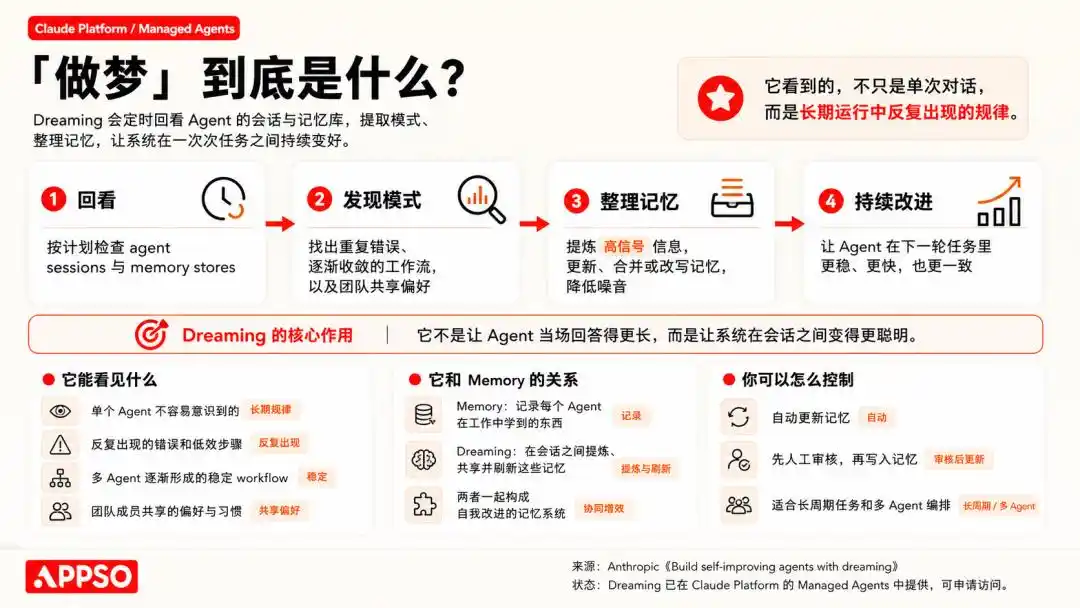
Sa mekanismo ng pangarap ng OpenClaw, isinasaayos nito ang paglalakbay ng pangarap sa tatlong yugto: light, REM, at deep. Ang dalawang unang yugto ay nagtatrabaho para sa pagpapaliwanag, pag-iisip, at pagpupuno ng tema, habang ang deep ang tunay na sumusulat ng nilalaman sa matagalang memorya na MEMORY.md.
Ang pagpapalakas sa yugto ng malalim na tidal ay tatayain ng 6 na may timbang na signal kung kailangan bang isulat sa matagalang pag-iingat. Ang anim na signal ay kasama ang frequency, kaukulian, diversity ng query, kahalagahan sa oras, pagsasaulo sa iba’t ibang araw, at kalaliman ng konsepto.

Ang larawan ay ginawa ng AI
Isusulat sa matagal na memorya, magkakaroon ng dalawang file: isang file ng estado para sa machine, na nakalagay sa memory/.dreams/; at isang readable na rekord para sa user, na isusulat sa DREAMS.md at sa mga ulat na nabubuo ayon sa yugto.
Dagdag pa, maaaring awtomatikong isakay ang Dreaming, at default ay tumatakbo ng isang buong proseso araw-araw sa 3:00 AM, sa pagkakasunod-sunod na light → REM → deep.
Bukod sa output ng pangarap, nagpapanatili ang OpenClaw ng isang dokumento na tinatawag na Dream Diary, kung saan ang sistema ay awtomatikong lumilikha ng isang “Dream Diary” na nag-uulat ng proseso ng pagpapalitan ng memorya sa pamamagitan ng pagsasalaysay, na nagbibigay-diin sa pagiging maipapaliwanag at maipapasiya, hindi sa isang black-box na database.
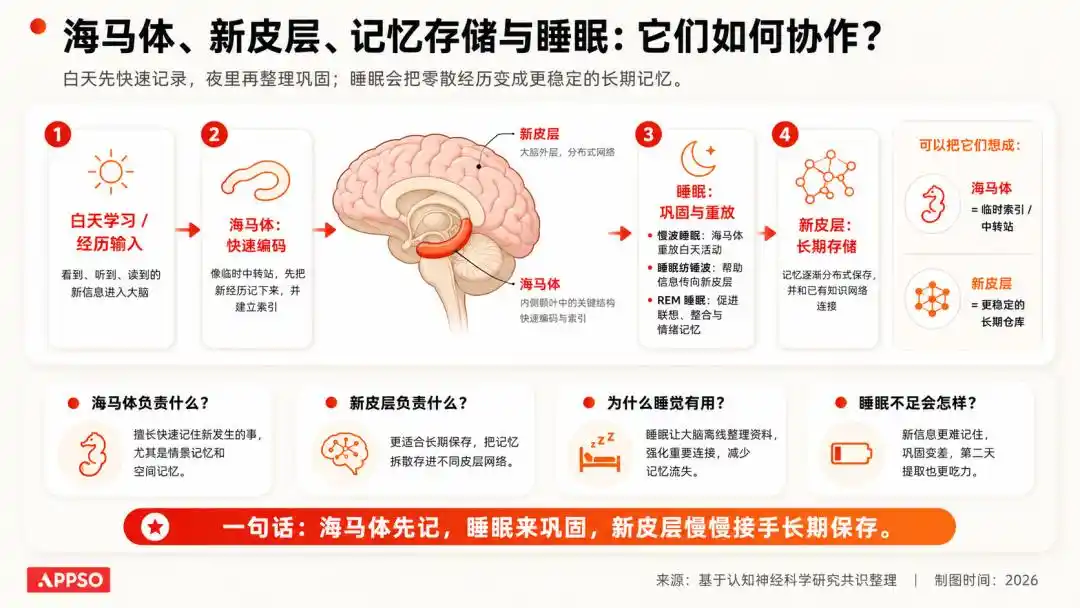
May isang klasikong pag-unawa sa neurosiyensya: ang impormasyon na kinukuha ng tao sa araw, unang papasok sa isang sistema na mas nakatuon sa pansamantalang pag-iimbak; habang sa panahon ng tulog, ang utak ay muling ipinapakita, pinapalakas, at inaayos ang mga impormasyong ito, upang panatilihin ang mahalaga at tanggalin ang walang kwenta.
Ang larawan ay ginawa ng AI
Hindi namin tatalingga sa kulay ng bawat kotse sa biyahe namin papunta sa trabaho kahapon, ngunit tatalingga sa paraan upang pumunta sa kompanya.
Ang mga pangarap na ito, tila pareho sa mga pangarap ng tao, kung may gagawin pang pagkakaiba, siguro ay habang nagdudream si Claude, patuloy pa rin siyang gumagamit ng ating Token.
Ngunit hindi pumili ang Anthropic at OpenAI ng mga pangalan na tulad ng “session-based optimization” o “post-task tuning,” na mas teknikal o inhenyerong termino.
Pagkatapos, kapag ang mga kumplikadong pangalan ay direkting isasalin sa «pangarap», ang ating nadarama ay hindi na isang software function, kundi parang isang «digital na buhay na may loob».
Ang memorya ng AI ay mga detalyeng pana-panahon
Kasabay ng pagbanggit sa “pagdudurog,” kailangang banggitin ang kanyang nakaraang kondisyon, ang memorya (Memory).
Sa nakaraang panahon, ang pinakapopular na salita sa mundo ng AI ay mula sa prompt engineering, nagbago sa context engineering, skill engineering, at harness engineering, ngunit anuman ang pagbabago, ang pinakamahalagang bagay sa kasalukuyan ay ang context engineering.
Ang sistemang pagpapahiwatig, user input, maikling talakayan, matagalang memorya, mga dokumentong nakuha, at ang output ng mga tool at pagtawag sa Skill, kasama ang kasalukuyang estado ng user—ang lahat ng ito ay nagkakasama upang mabuo ang “konteksto” na talagang ginagamit ng agent.
Ang pagpapalawak ng kakayahan ng Agent na tandaan ang higit pa at mag-record ng mas kapaki-pakinabang na impormasyon ay patuloy na isang hamon sa nakalipas na mahabang panahon.
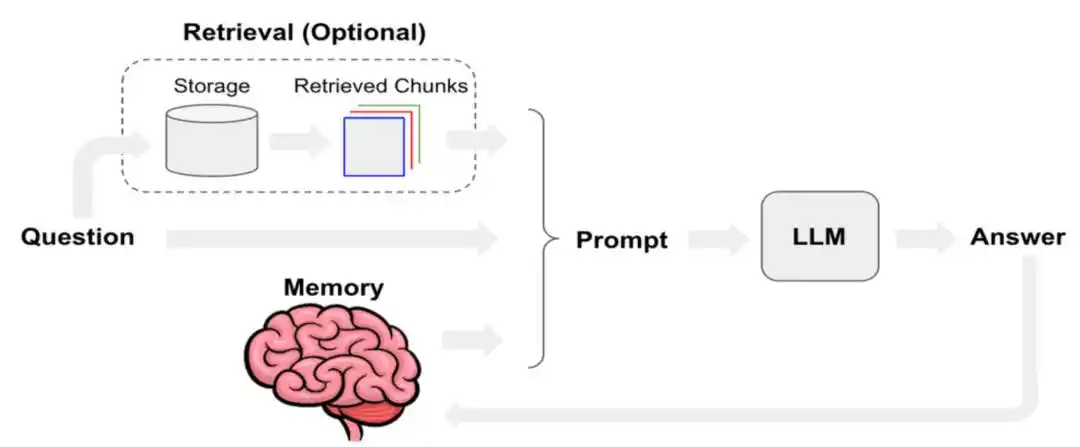
Noong nakaraang taon, ang Manus ay nag-post ng isang teknikal na blog post na nakatuon sa kung paano nila pinabuti ang context engineering. Binanggit dito ang pagtukoy sa KV-Cache hit rate bilang isa sa pinakamahalagang hiwalay na indikador para sa AI Agent sa production environment. Samantala, sa antas ng tool invocation, pinipili ang "masking" kaysa sa "removal"; at ang paggamit ng file system bilang huling context.
Upang maunawaan ang so-called KV Cache (key-value cache), isipin natin ang malaking modelo bilang isang sobrang obsesibong tao na kaya lang basahin ang isang titik nang isang beses.
Kapag ito ay nagpaproseso ng isang pangungusap, ito ay nagkakalkula ng isang Key (pamagat) at isang Value (halaga) na vektor para sa bawat nabuong Token. Upang hindi muling kalkulahin ang bawat beses, ito ay nag-iimbak ng mga (K, V) key-value pair, at ito ang tinatawag na KV Cache.
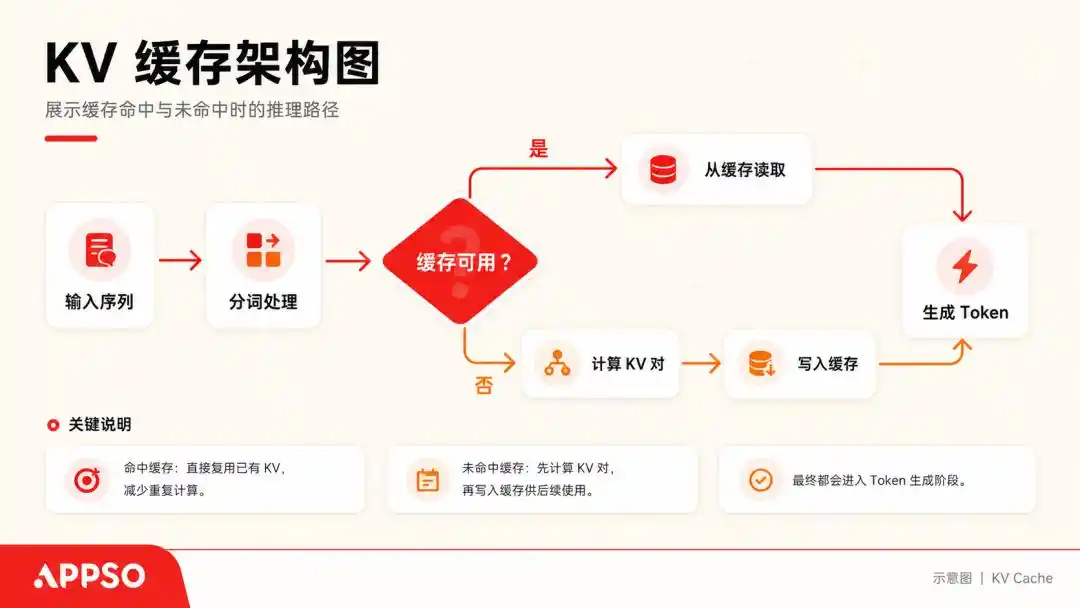
Ang KV Cache (key-value cache) ay isang pang-ilalim na teknik ng pagpapabilis na ginagamit ng malalaking modelo habang nagpapagawa ng teksto, upang “palitan ang espasyo para sa oras.” Ang pag-cache ay nagpapahintulot sa modelo na hindi kailangang muling kalkulahin ang lahat ng mga nakaraang salita habang hinuhulaan ang susunod na salita. Larawan ay nilikha ng AI.
Patuloy na itinutugma ang KV Cache habang patuloy ang usapan. Sa karaniwang pagkakataon, sa pagharap sa mga malalaking modelo na may 128k na konteksto, ang isang modelo na may 70B na parameter na nagpapatakbo ng buong 128k na konteksto ay maaaring magamit ng 64 GB ng VRAM lamang para sa KV Cache.
Ito ang dahilan kung bakit ang kontekstong window ng karamihan sa mga modelo ay kasalukuyang pinakamataas ay sa mga milyon.
Kahapon, ang bagong kumpanya na Subquadratic, na nakakuha ng $29 milyon sa seed funding, ay nag-post sa X ng bagong modelo na SubQ na nagtatampok ng mas mahabang konteksto.

Sinasabing suportahan ng SubQ ang pinakamalaking window ng konteksto na 12 milyon na token, na ang pinakamalaki sa lahat ng malalaking modelo ngayon.
Bagaman wala pa ng teknikal na papel o dokumentasyon ng modelo, sinabi sa video na ipinakilala na ang pangunahing teknikal na direksyon ng SubQ ay mula sa «densen attention» ng tradisyonal na Transformer patungo sa arkitekturang «subquadratic / linear scaling» na may sparse attention. Inaasahan na lutasin ng bagong arkitekturang ito ang problema kung saan ang mas mahabang konteksto ay nagdudulot ng mas malaking gastos sa computing power.

Ang mga resulta ng pagsubok ay pati na rin ang napakalakas: sa 1 milyong token, ang pagtaas ng bilis ay higit sa 50 beses at ang pagbaba ng gastos ay higit sa 50 beses; sa 12 milyong token, ang pangangailangan sa computing power ay maaaring bawasan ng halos 1,000 beses kumpara sa mga pinaka-advance na modelo.
Sa RULER 128K long-context benchmark, sinabi ng Subquadratic na ang SubQ ay nakamit ang 95% na akurasyon sa gastos ng $8, kumpara sa 94% na akurasyon at halos $2,600 na gastos ng Claude Opus, na nagresulta sa pagbaba ng gastos ng humigit-kumulang 300 beses.
O kaya ay palawakin ang window ng konteksto, o kaya ay turuan ang modelo na magdaming, at mag-alis ng ilang bagay nito.
Ito ang dahilan kung bakit kailangan ng mga Agent product tulad ng Anthropic na ilunsad ang Dreaming. Sa ilalim ng limitadong context window, hindi sapat na i-push ang higit pang kontenido ng mas matalinong AI—kailangan nito ng may layunin.
Mas mahirap pangisipin na ang mga makina ay tanging mga makina lamang
Naiintindihan ang mekanismo ng pagdudumi at pagtatala ng AI, maaari nating malaman ang ugnayan nito sa mga gawain ng tao.
Ngunit kapag isasama ang lahat ng mga salitang ito na ginawa ng mga AI company para sa mga machine—ang thinking ng OpenAI, ang memory at hallucination na pangkalahatang ginagamit sa industriya, ang dreaming ng Anthropic sa pagkakataong ito, at ang mga katangian at karunungan sa konstitusyon ng Anthropic.
Nakikita natin na ang mga AI company ay higit pa sa pagbebenta ng mga produkto; sila ay nagrererol ng pagmamay-ari sa mga salita sa loob ng konsepto ng “tao.” Bawat pagkuha ng isang salita, mas nagkakalat ang hangganan sa pagitan ng makina at tao.

Ang wika ay nagpapabuo ng mga inaasahan, ang mga inaasahan ay nagpapabuo ng pagtitiis, at ang pagtitiis ang nagpapasya kung gaano karaming bagay ang handa nating ipagkatiwala sa iyo. Ito ay mahabang serye, ngunit ang simula ay ang mga walang panganib na salita sa pagpapahayag.
Mas nakatagong epekto ay ang pagkakabahagi ng responsibilidad. Kapag inilarawan ang mga kasangkapan bilang mga entidad na may “pag-iisip,” “memorya,” at “mga halaga,” nang magkaron ng problema, natural nating itinuturing ito bilang isang independiyenteng “aktor” na dapat ihold accountable—kailangan ng AI na “matuto,” “i-debug,” at “i-calibrate.”
Ang tunay na dapat tanungin ay ang kumpanya na nag-deploy ng programa sa aming workflow at ang product team na sumulat ng salitang “dreaming”. Kapag nagbago ang salita, nagbago rin ang taong nakaupo sa upuan ng akusado.
At habang tinitingnan natin ang isang makina na "nag-iisip," "nag-iingat," at ngayon ay "nagdudream," nagsisimula na tayong maniwala nang walang kamalay-malay na mayroon pang isang bagay sa loob nito. Dahil ang pagtanggap na ito ay isang makina lamang ay nagpapalabas sa karanasan na "nag-uusap ako sa isang nag-iisip na pagkakataon," at bumabalik sa malamig at mapagkukunan na ugnayan.

Pagpapakilala sa Function ng Daydream | Larawan na ginawa ng AI
Naisip ko na, ang Dreaming ay para sa paghahandle ng nakaraang mga nilalaman, at susunod ay maglalabas ang AI company ang Daydreaming, o white daydream, para sa pagpapakita ng hinaharap.
Ang pagpapaliwanag ay, ang pag-iisip ng mga pangarap o pagkawala ng pansin, ay nagpapahintulot sa Agent na, sa aktibong estado, gamitin ang kaunting kalayang computing power, kasama ang kasalukuyang proyekto, upang magawa ang eksploratoryong pagbuo para sa mga hinaharap na gawain.
Ang artikulong ito ay mula sa WeChat public account na “APPSO”, may-akda: APPSO na nagtataguyod ng mga produkto ng kinabukasan