
Paano nagkakaiba ang mga self-learning AI agent mula sa tradisyonal na mga machine learning model at kasalukuyang mga agent batay sa LLM?
2026/05/02 15:21:02
Pagsisimula
Nagsisilbi ang larangan ng artificial intelligence sa isang malalim na pagbabago. Habang ang mga tradisyonal na machine learning model ang namamahala sa nakaraang dekada at ang mga malalaking language model ang nakakuha ng atensyon ng buong mundo simula 2022, isang bagong paradigma ang lumalabas na nagbabago nang fundamental kung paano gumagana ang mga AI system. Ang self-learning AI agents ay kumakatawan sa susunod na hakbang ng evolusyon, na nagkakaisa ng autonomy, adaptive reasoning, at continuous improvement sa paraan na nagpapakita ng malaking pagkakaiba sa kanilang mga nakaraan at kasalukuyang LLM-based na mga sistema. Ang pag-unawa sa mga pagkakaiba na ito ay mahalaga para sa sinumang naghahanap na mag-navigate sa mabilis na umuunlad na AI ecosystem.
Ano ang mga Self-Learning AI Agents?
Ang mga self-learning AI agent ay mga autonomong kompyutasyonal na entidad na may kakayahang makita ang kanilang kaligiran, analisahin ang impormasyon, bumuo ng desisyon, at isagawa ang mga aksyon upang makamit ang mga partikular na layunin. Sa pagkakaiba sa mga karaniwang AI system na nangangailangan ng tulong ng tao sa bawat hakbang, ang mga self-learning agent ay maaaring bigyan ng isang mataas na antas na layunin at mag-iisip nang mag-isa kung paano ito matutupad. Ang mga agent na ito ay nagkakaisa ng kakayahang makita, mag-isip, matuto, at gumawa upang makapag-simula ng isang matalinong pag-uugali na dati lamang nakikita sa mga biyolohikal na sistema.
Ang mga natatanging katangian ng mga self-learning AI agent ay ang autonomiya, reaktibidad, pro-aktibidad, at kakayahang sosyal. Ang autonomiya ay nagpapahintulot sa mga agent na magtrabaho nang hiwalay nang walang patuloy na tulong mula sa tao. Ang reaktibidad ay nagpapahintulot sa kanila na makamit ang mga pagbabago sa kalikasan at tumugon nang angkop. Ang pro-aktibidad ay nangangahulugan na hindi lamang sila tumutugon sa mga stimulus kundi aktibong hinahanap ang mga layunin sa pamamagitan ng pagpaplano. Ang kakayahang sosyal ay nagpapahintulot sa pagkakasundo sa iba pang mga agent sa mga multi-agent system upang matapos ang mga kumplikadong gawain.
Ayon sa mga pagbibilang ni Microsoft para sa 2025, ang mga AI-driven agent ay nagkakaroon ng mas mataas na awtonomiya upang maisagawa ang higit pang mga gawain, kaya't mapapabuti ang kalidad ng buhay sa maraming larangan. Ang pangunahing pagkakaiba ay nasa paraan kung paano ang mga agent na ito ay nagdadala ng mga layunin: habang kailangan ng detalyadong, maayos na nilikhang prompt ang isang malaking language model upang makapagbigay ng mataas na kalidad na output, ang isang AI agent ay kailangan lang ng isang layunin, at ito ay mag-iisip at magpapatupad nang sarili ng mga kinakailangang aksyon.
Mga Tradisyonal na Mga Modelong Machine Learning: Istruktura at Mga Limitasyon
Ang mga tradisyonal na modelo ng machine learning ay nagtataglay ng isang pangunahing iba’t ibang pagkakaroon sa artificial intelligence. Karaniwan ay tinuturuan ang mga ito sa mga partikular na dataset upang gawin ang mga makitid, malinaw na gawain tulad ng pagklasipikasyon, regression, o clustering. Pagkatapos ilunsad, gumagana sila sa mga fixed na parameter at hindi makakapagbabago ng kanilang pag-uugali batay sa mga bagong karanasan nang walang eksplisitong pagtuturo muli.
Ang arkitektura ng tradisyonal na mga modelo ng ML ay nakatuon sa statistical learning mula sa historical data. Natututo ang isang modelo sa mga pattern habang nagtatrabaho at ginagamit ang mga natutunang pattern sa mga bagong input sa panahon ng inference. Gumagana nang lubos na mabuti ang pamamaraang ito sa mga gawain na may malinaw na mga pattern at magkakasunod-sunod na input, tulad ng spam detection, image classification, o recommendation systems. Gayunpaman, ang static na kalikasan ng mga modelo na ito ay naglalikha ng malalaking limitasyon sa dynamic at hindi maipapalagay na mga kaligiran.
Kailangan ng tradisyonal na ML models na ang mga inhinyero ay magtukoy ng mga tampok, pumili ng mga algoritmo, at ayusin ang mga hyperparameter. Kapag nagbabago ang distribusyon ng data o ang mga kinakailangan ng gawain, maaaring bumaba ang performance ng mga model at kailangan ng pagrere-train. Ang proseso ng pag-aaral ay praktikal na nakaputol pagkatapos ng deployment, ibig sabihin ay hindi kayang magpabuti ang mga sistema mula sa karanasan o mag-adapt sa mga bagong sitwasyon nang walang eksplisitong pagtutulong.
Karaniwang ginagamit ng mga koponan sa seguridad at pagkakasunod-ayos ang tradisyonal na ML para sa pagkilala sa mga pattern sa structured data, ngunit nahihirapan ang mga sistemang ito kapag nakakatok sa mga gawain na nangangailangan ng pag-unawa sa konteksto o multi-step na pag-iisip. Kulang sila sa kakayahang magplano, mag-isip tungkol sa kaukulan, o hatiin ang mga kumplikadong problema sa mas maliit at mas maipapamahala mga sub-task.
Mga Agente batay sa LLM: Kasalukuyang Kakayahan at Mga Limitasyon
Kasalukuyang LLM-based agents ay isang malaking pag-unlad kumpara sa tradisyonal na machine learning. Batay sa malalaking language models na may milyon-milyong parameter, ang mga sistema na ito ay nakakaintindi ng natural na wika, nakagagawa ng teksto na katulad ng tao, at nakakagawa ng mga gawain sa pag-iisip na dati ay imposible para sa AI. Ang mga kumpanya tulad ng OpenAI, Anthropic, at Google ay nagbuo ng mga palaging mas kaya mong models na nagsisilbing pundasyon para sa maraming AI application sa kasalukuyan.
Ang mga agent batay sa LLM ay mahusay sa pag-unawa at pagbuo ng natural na wika. Maaari silang makipag-usap nang may kahulugan, i-summarize ang mga dokumento, isulat ang code, at ipaliwanag ang mga kumplikadong konsepto. Ang OpenAI's o1 model, halimbawa, ay nagpapakita ng advanced na kakayahan sa pag-iisip na nagpapahintulot sa iyo na lutasin ang mga kumplikadong problema gamit ang mga lohikal na hakbang na katulad ng tao bago sagutin ang mga mahirap na tanong.
Gayunpaman, ang karamihan sa kasalukuyang mga agent batay sa LLM ay mga puro reaktibong sistema. Sila ay tumutugon sa mga prompt ng user ngunit hindi aktibong hinahabol ang mga layunin o nagpapatupad ng mga aksyon sa mundo. Kapag nag-iinteraktyon ka sa isang chatbot, ang sistema ay naglalikha ng tugon batay sa iyong input at sa mga datos ng pagtuturo nito, ngunit hindi ito tumatanggap ng sariling hakbang upang makamit ang isang mas malawak na layunin nang walang patuloy na gabay mula sa tao.
Naging malinaw ang mga limitasyon ng mga agent batay sa LLM kapag nangangailangan ang mga gawain ng patuloy na pagsisikap sa maraming hakbang, integrasyon sa mga panlabas na kasangkapan, o pag-adapt batay sa feedback. Habang ang mga modelo na ito ay makakapag-isip sa mga problema sa isang exchange, kadalasan ay kulang sila sa kakayahan na panatilihin ang estado sa pagitan ng mga interaksyon, i-execute ang mga aksyon sa panlabas na sistema, o matuto mula sa mga resulta ng kanilang mga desisyon.
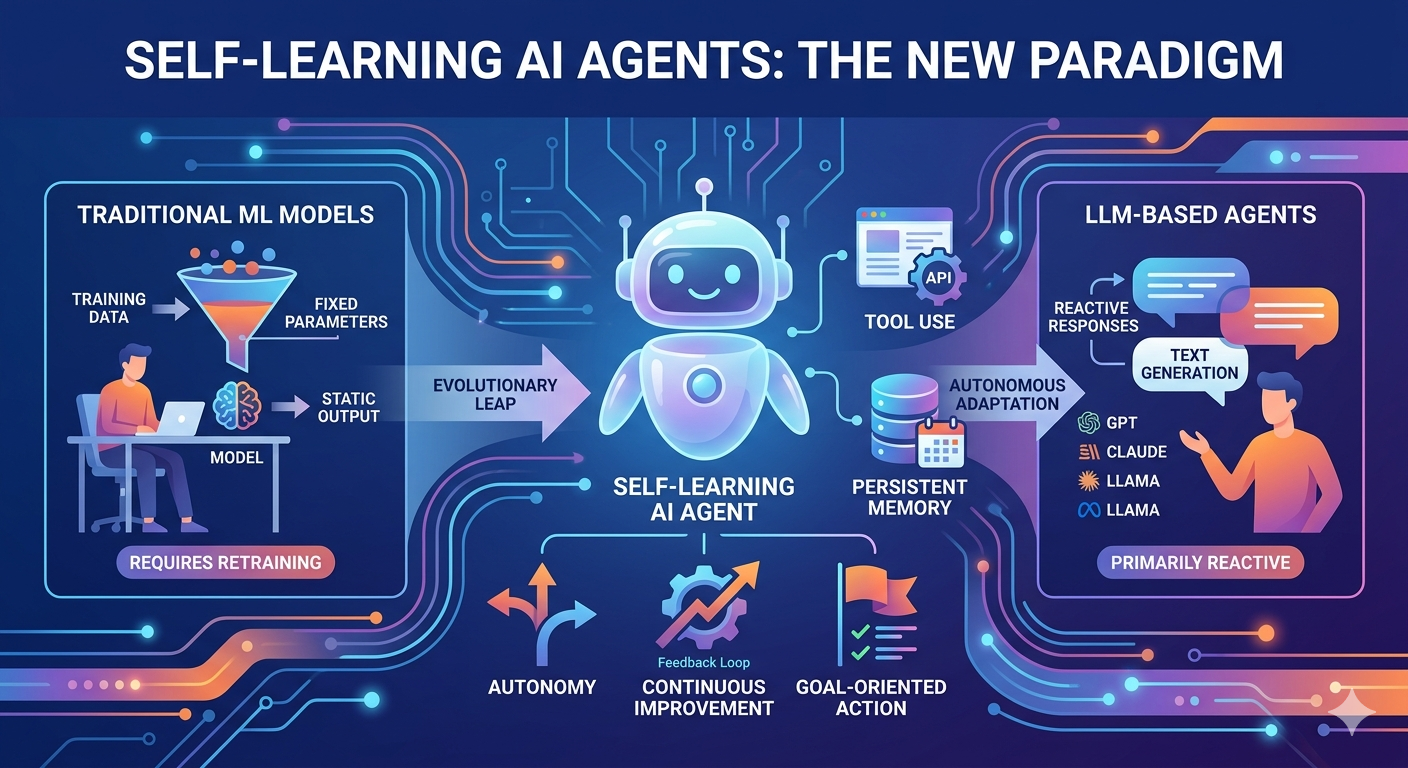
Mga Pangunahing Pagkakaiba: Self-Learning AI Agents kumpara sa Traditional ML
Ang mga pagkakaiba sa pagitan ng mga self-learning AI agent at mga tradisyonal na machine learning model ay sumasaklaw sa arkitektura, kakayahan, at operasyonal na pilosopiya. Ang pag-unawa sa mga pagkakaibang ito ay naglilinaw kung bakit maraming eksperto ang tumitingin sa mga agent bilang ang susunod na hangganan sa pag-unlad ng AI.
-
Pagsusuri at Pag-adapt
Ang mga tradisyonal na ML model ay natututo sa isang fixed na training phase at pagkatapos ay gumagana nang static. Ang isang fraud detection model na tinuruan sa historical transaction data ay gagamitin ang mga parehong pattern nang walang katapusan maliban kung ito ay muling tinuruan. Sa kabilang banda, ang mga self-learning agents ay maaaring mag-aral nang tuloy-tuloy mula sa kanilang interaksyon sa kalikasan. Sila ay nakakakita ng mga resulta ng kanilang mga aksyon, binabasa kung ano ang nagtrabaho at ano ang hindi, at binabago ang kanilang mga estratehiya ayon dito.
-
Autonomiya at Pag-uugali na May Layunin
Ang mga tradisyonal na ML model ay mga kasangkapan na ginagamit ng mga tao upang matupad ang mga partikular na gawain. Hindi sila nagtataglay ng sariling mga layunin; simpleng sinusuri nila ang mga input at naglalabas ng mga output batay sa mga natutunang pattern. Ang mga self-learning agent ay mga sistemang may layunin na makakatanggap ng mataas na antas ng mga obhektibo at makakapagpasya ng pinakamabuting paraan upang matupad ito. Ipinaparito nila ang mga kumplikadong layunin sa mga sub-task, isinasagawa nila ang mga sub-task na iyon, at binabago nila ang kanilang paraan batay sa progreso.
-
Paggamit ng Kasangkapan at Interaksyon sa Kalikasan
Ang mga self-learning agents ay maaaring mag-interface sa mga panlabas na kasangkapan, API, at mga sistema ng software. Maaari silang mag-browse sa internet, manipulahin ang mga file, i-execute ang code, at makipag-ugnayan sa mga database. Karaniwan ay hindi kayang gawin ng mga tradisyonal na ML model; limitado sila sa mga input na tinatanggap at output na nililikha sa loob ng kanilang sariling computation graph.
-
Pagsusuri at Paghahanda sa Konteksto
Samantalang ang tradisyonal na ML ay mahusay sa pagkilala sa mga pattern sa structured data, ang mga sariling nag-aaral na agente ay nagpapakita ng mas mataas na kakayahan sa pag-unawa sa konteksto at pagpaplano ng mga multi-step na solusyon. Ang isang agente na binigyan ng layunin na magplano ng biyahe ay mag-aaral ng mga destinasyon, ihihambing ang mga presyo, i-check ang availability, at i-book ang mga pag-aayos—mga pag-uugali na imposible para sa isang static na classification model.
Mga Pangunahing Pagkakaiba: Mga Self-Learning AI Agent kumpara sa Mga Base sa LLM
Ang pagkakaiba sa pagitan ng mga self-learning AI agent at mga kasalukuyang agent batay sa LLM ay subtil ngunit may malaking epekto. Maaaring gamitin ng pareho ang malalaking language models bilang pangunahing komponente, ngunit iba ang kanilang arkitektura at paraan ng paggana.
-
Reactive vs Proactive na Operasyon
Ang mga pinakabagong agent batay sa LLM ay mga reaktibong sistema na naglalabas ng mga tugon sa mga prompt. Humihingi ang isang user ng tanong, at ibinibigay ng modelo ang sagot. Gayunpaman, ang mga self-learning agent ay maaaring gumana nang proaktibo. Sa pagbibigay ng isang layunin, sila ay magkakaroon ng initiatiba na magtipon ng impormasyon, gumawa ng mga plano, at isagawa ang mga aksyon nang hindi naghihintay ng tulong mula sa tao sa bawat hakbang.
-
Pamamahala ng Estado at Memorya
Ang mga tradisyonal na LLM ay nagtratato ng bawat usapan bilang stateless, bagaman may ilang implementasyon na nagdaragdag ng mga window ng konteksto. Ang mga self-learning agent ay naglalaman ng mga mas komplikadong sistema ng memorya na nagpapanatili ng impormasyon sa pagitan ng sesyon, tinutugunan ang progreso patungo sa mga layunin, at nagpapahintulot sa pagkatuto mula sa nakaraang karanasan. Ang patuloy na memorya na ito ay nagpapahintulot sa mga agent na magpatuloy sa kanilang nakaraang gawain kaysa magsimula muli sa bawat interaksyon.
-
Integrasyon ng Tool at Pagganap ng Aksyon
Ang mga agent batay sa LLM ay pangunahing naglalikha ng teksto, kahit na ang teksto ay kumakatawan sa code o mga utos. Ang mga self-learning agent ay disenyo upang talagang pagsisimulan ang mga utos na iyon at makipag-ugnayan sa mga panlabas na sistema. Ang OpenAI's Operator at Claude's Computer Use ay mga maagap na hakbang sa direksyong ito, na nagpapahintulot sa AI na kontrolin ang mga browser, command-line interfaces, at mga software application.
-
Dinamikong Pagpapasya sa Workflow
Kapag nakakasalungat ang isang agent batay sa LLM, karaniwang nabubuo ito o naglalabas ng mensahe ng error. Ang isang self-learning agent ay makakakilala kung ang kanyang unang pagkakataon ay hindi gumagana, maaaring analisahin kung bakit, at dinamikong i-adjust ang kanyang estratehiya. Mahalaga ang kakayahang mag-iterate at mag-adapt para sa paghahandle ng mga kumplikadong, totoong mundo na gawain na rare lang na lumalabas nang eksaktong ganun ang plano.
Ang Arkitektura ng Mga Self-Learning Agent
Ang pag-unawa sa ano ang nagpapakilala sa mga self-learning agent ay nangangailangan ng pagsusuri sa kanilang pangunahing arkitektura. Ang mga sistemang ito ay nagpapagsasama ng maraming komponente na nagtatrabaho nang sama-sama upang magbigay-daan sa autonomous at adaptive na pag-uugali.
-
Pangunahing Paggawa at Pag-iisip
Sa puso ng isang self-learning agent ay isang reasoning engine, karaniwang pinapagana ng isang malaking language model, na makakadecompose ng mga kumplikadong layunin sa mga actionable na hakbang. Nagpapagana ng engine na ito ang agent upang magplano, mag-isip tungkol sa kausalidad, at mag-evaluate ng mga resulta ng posibleng aksyon. Ipakikita ng pananaliksik ng Microsoft na ang mga paraan ng pagtuturo at mga kakayahan ng agent ay maaaring lumikha ng mga synergistic effects, kung saan ang mas mahusay na mga model ay nagpapahintulot sa mas epektibong mga agent.
-
Mga Sistema ng Memorya
Ang mga sariling natututong agente ay nagpapanatili ng maraming uri ng memorya: maikling panahon na working memory para sa kasalukuyang mga gawain, mahabang panahon na memorya para sa patuloy na kaalaman, at episodikong memorya para sa nakaraang karanasan. Ang mga sistema ng memorya na ito ay nagpapahintulot sa mga agente na matuto mula sa feedback, tandaan ang mga matagumpay na estratehiya, at iwasan ang pag-uulit ng mga pagkakamali. Ang kahalintulad ng mga sistema ng memorya na ito ang nagkakaibang tunay na sariling natututong mga agente mula sa mas simpleng reactive systems.
-
Paggamit ng Tool at Integrasyon ng API
Ang mga agent ay may kakayahang tumawag ng panlabas na kasangkapan, makapag-access sa mga database, mag-browse sa web, at makipag-ugnayan sa mga software application. Ang kakayahang gamitin ang mga kasangkapan na ito ay nagpapalawak sa sakop ng agent mula sa paggawa ng teksto lamang patungo sa mga aktwal na aksyon. Maaari ng agent piliin ang angkop na mga kasangkapan batay sa gawain, isagawa ang pagtawag sa mga kasangkapan, at isama ang mga resulta sa kanyang pag-iisip.
-
Mga Tugon at Mekanismo para sa Pagkatuto
Maaaring ang pinakakilala na tampok ng mga sariling nag-aaral na agente ay ang kanilang kakayahang matuto mula sa karanasan. Kapag sinubukan ng isang agente ang isang gawain, maaari itong suriin ang resulta, tukuyin kung ano ang nangyaring mali, at baguhin ang kanilang paraan para sa mga susunod na pagsubok. Maaaring mangyari ang pag-aaral sa pamamagitan ng iba’t ibang mekanismo, kabilang ang reinforcement learning, self-reflection, at iterative refinement.
Mga Tunay na Paggamit at Epekto
Ang mga natatanging kakayahan ng mga self-learning AI agent ay nagpapahintulot sa mga bagong aplikasyon sa iba’t ibang industriya. Ibinabahagi ng Microsoft na halos 70% ng mga empleyado sa Fortune 500 ay gumagamit na ng mga AI agent na Microsoft 365 Copilot upang harapin ang paulit-ulit na araw-araw na gawain tulad ng pag-filter ng email at pagkuha ng mga tala sa mga pagpupulong habang nasa Teams.
Sa supply chain management, ang mga agent ay makakapaghula ng pagbabago sa pangangailangan ng inventory batay sa historical data at real-time information, at makakapag-adjust ng mga plano sa procurement at production upang maiwasan ang kakulangan o sobrang imbakan. Sa healthcare, ang mga agent ay makakapag-analyze ng mga kaso ng pasyente, magbigay ng mga sugestyon sa diagnosis, at makakatulong sa pagpaplano ng paggamot sa pamamagitan ng pagproseso ng malalaking dami ng medical literature at patient records.
Ang mga epekto ay umabot sa labas ng mga pagpapabuti sa efisensiya. Ang mga sariling natututong agente ay nagpapalit ng paraan kung paano ginagawa ang mga gawain na nauugnay sa kaalaman. Sa halip na matututo ang mga tao na gamitin ang mga tool ng AI, ang paradigma ay umuunlad patungo sa mga agente ng AI na natututong tumulong sa mga tao nang mas epektibo. Ito ay isang pangunahing pagbabago sa ugnayan ng tao at AI, mula sa pagpapatakbo ng mga tool ng mga tao patungo sa pagmamalay at pakikipagtulungan ng mga tao sa mga autonomous na agente.
Paano Maaaring Maghanda ang mga Organisasyon para sa Panahon ng Agent?
Ang mga organisasyon na naghahanap na gamitin ang self-learning AI agents ay dapat magsimula sa pagkilala sa mga mataas na halaga na paggamit kung saan ang mga kakayahan ng agent ay maaaring magbigay ng malaking kalamangan kumpara sa tradisyonal na mga paraan. Ang mga gawain na may multi-step na proseso, integrasyon ng panlabas na sistema, o dinamikong mga kapaligiran ay mga pangunahing kandidato para sa pag-deploy ng agent.
Dapat umunlad ang teknikal na imprastruktura upang suportahan ang pagpapatakbo ng agent. Kasama rito ang mga matibay na integrasyon ng API, ligtas na pag-access sa mga kasangkapan, at mga sistema ng pagmamanman na makakatulong sa pagsubaybay sa performance ng agent at pagkakakilanlan ng mga isyu. Dapat din ng magtatag ang mga organisasyon ng mga framework ng pamamahala na tumutukoy sa mga angkop na hangganan para sa awtonomiya ng agent habang sinusiguro ang pagtutugma sa mga kaugnay na regulasyon.
Mahalaga ang pag-invest sa pagkakaroon ng kaalaman tungkol sa mga agent sa buong organisasyon habang mas karaniwan na ang mga sistema na ito. Kailangan ng mga empleyado na maintindihan kung paano gumagana ang mga agent, kung paano magbigay ng epektibong gabay, at kung paano masusi at i-refine ang mga output ng mga agent. Ang pagbabagong ito ay nangangailangan hindi lamang ng teknikal na pag-invest kundi pati na rin ng pag-adapt sa kultura.
Kongklusyon
Ang mga self-learning AI agent ay nagtataglay ng isang pangunahing pag-unlad sa mga kakayahan ng artificial intelligence. Sa pagkakaiba sa tradisyonal na mga modelo ng machine learning, na static at task-specific, ang mga agent ay maaaring mag-adapt, mag-plano, at mag-execute ng mga kumplikadong workflow nang awtonomo. Kumpara sa kasalukuyang mga sistema batay sa LLM, ang mga agent ay nagdadagdag ng proactive operation, persistent memory, at ang kakayahang gawin ang mga real-world action sa pamamagitan ng tool integration.
Ang paglipat mula sa reactive AI patungo sa autonomous agents ay isang pagbabago ng paradigma na katumbas ng paglipat mula sa narrow AI patungo sa pangkalahatang pag-unawa sa wika. Ang mga organisasyon na nauunawaan ang mga pagkakaiba na ito at naghahanda nang maayos ay magiging pinakamainam na posisyon upang gamitin ang mapapalitan na potensyal ng self-learning agents. Ang panahon ng agent ay hindi lang papasok—ito ay nasa ilalim na, binabago kung paano ginagawa ang trabaho at ano ang kayang abutin ng AI.
Mga Karaniwang Tanong
Ano ang pangunahing pagkakaiba sa pagitan ng AI agents at tradisyonal na mga machine learning model?
Ang mga tradisyonal na ML model ay natututo ng mga pattern habang nagtatrabaho at nag-aapply nito nang static sa mga bagong input, kailangan ng pagrere-train upang makapag-adapt. Ang self-learning AI agents ay maaaring mag-aral nang tuloy-tuloy mula sa karanasan, makapag-adapt sa mga bagong sitwasyon, at magtrabaho nang awtonomo nang walang patuloy na tulong o pagrere-train mula sa tao.
Maaari bang palitan ng self-learning AI agents ang mga chatbot batay sa kasalukuyang LLM?
Ang mga AI agent at LLM ay naglalayon sa iba’t ibang layunin at madalas ay komplementario kaysa kompetitibo. Ang LLM ay nakikilala nang mahusay sa pag-unawa at pagbuo ng wika, habang ang mga agent ay nagdadagdag ng awtonomiya, kakayahang mag-aksiyon, at adaptibong pagkatuto. Marami sa mga agent ay gumagamit ng LLM bilang kanilang engine ng pag-iisip habang nagdadagdag ng mga layer para sa pagpaplano, memorya, at paggamit ng mga kasangkapan.
Kailangan ba ng mas maraming kompyutasyonal na yaman ang mga AI agent na nag-aaral mismo kaysa sa tradisyonal na mga ML model?
Ang mga self-learning agents ay karaniwang nangangailangan ng higit pang mga computasyonal na yaman dahil sa kanilang kumplikado, patuloy na pamamahala ng estado, at madalas na mas malalaking mga pundamental na modelo. Gayunpaman, ang mga pagpapabuti sa kahusayan mula sa autonomous na pagpapatakbo at pagbawas sa pangangailangan para sa tao na pagmamasid ay maaaring kumompensa sa mga gastos na ito sa maraming aplikasyon.
Paano hinahandle ng mga self-learning agent ang mga error at pagkabigo?
Ang mga self-learning agents ay nakakakilala kung ang kanilang paraan ay hindi gumagana, nag-aanalisa ng mga dahilan ng pagkabigo, at dinamikong nag-aadjust ng kanilang estratehiya. Ang kakayahang ito sa iteratibong pagpapabuti ay nagpapahintulot sa kanila na mas mabuting harapin ang hindi inaasahang sitwasyon kaysa sa mga static na sistema, bagaman mahalaga pa rin ang matibay na pag-handle ng error at tao na pagmamasid.
Ligtas ba ang mga self-learning AI agent para sa paggamit sa negosyo?
Kapag tama ang disenyo nito kasama ang mga angkop na pagtitiyak, ang mga sariling natututong agent ay maaaring ligtas na ipasok sa mga negosyo. Dapat maglagay ang mga organisasyon ng malinaw na hangganan para sa awtonomiya ng agent, itatag ang mga sistema ng pagmamasid, at panatilihin ang tao na pangangalaga para sa mga mahahalagang desisyon. Ang susi ay ang pagbalanse sa kakayahan ng agent kasama ang mga angkop na mga kadahilanan sa pamamahala.
Disclaimer: AI technology (powered ng GPT) ang ginamit sa pag-translate ng page na ito para sa convenience mo. Para sa pinaka-accurate na impormasyon, mag-refer sa original na English version.