









大型模型持續變大,主流觀點認為模型參數越多,就越接近人類的思考方式。然而,浙大團隊於4月1日在《Nature Communications》上發表的一篇論文提出了不同的看法(原文連結:https://www.nature.com/articles/s41467-026-71267-5)。他們發現,當模型(主要為 SimCLR、CLIP、DINOv2)規模增大時,識別具體事物的能力確實持續提升,但理解抽象概念的能力不僅未提高,甚至有所下降。當參數從 2206 萬增加到 3.0437 億時,具體概念任務的表現從 74.94% 提升至 85.87%,而抽象概念任務的表現則從 54.37% 下降至 52.82%。
人類和模型思考方式的區別
當人腦處理概念時,會先建立一套分類關係。天鵝和貓頭鷹外觀不同,但人們仍會將它們歸入「鳥」這一類。再往上,鳥和馬又能歸入「動物」這一層。當人們看到新事物時,通常會先思考它與以往見過的什麼東西相似,大致屬於哪一類。人們會持續學習新概念,並組織經驗,利用這套關係來識別新事物、適應新情境。
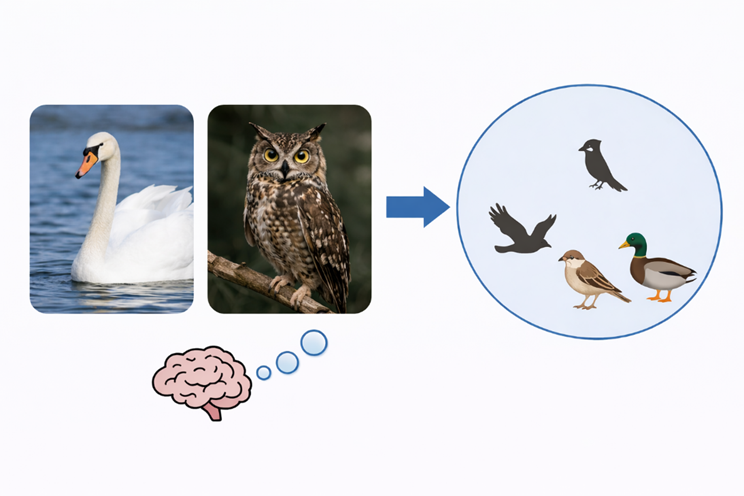
模型也會分類,但形成方式不同。它主要靠大規模數據裡反覆出現的形式。具體對象出現得越多,模型越容易把它認出來。到了更大的類別這一步,模型就比較吃力了。它需要抓住多個對象之間的共同點,再把這些共同點歸到同一類裡。現有模型在這裡還有明顯短板。參數繼續增大後,具體概念任務會提升,而抽象概念任務有時還會下降。

人腦和模型的共同點,是內部都會形成一套分類關係。但是雙方側重點不同,人腦的高階視覺區域會自然分出生物和非生物這類大類。而模型能把具體對象分開,但很難去穩定形成這種更大的分類。這個差別導致人腦更容易把舊經驗用到新對象上,所以面對沒見過的東西時,我們能快速分類。而模型則更依賴現有知識,所以遇到新對象時,更容易停在表面特徵上。論文提出的方法,就是圍繞這個特點展開,用腦信號去約束模型內部結構,讓它更接近人腦的分類方式。
浙大團隊的解決方案
團隊提出的解決方案也很獨特,並非繼續堆疊參數,而是利用少量腦信號進行監督。這裡的腦信號來自人們看圖片時的大腦活動記錄。論文原文寫的是,將 human conceptual structures transfer 給 DNNs。意思是盡量將人腦如何分類、如何歸納、如何將相近概念歸為一類的機制教給模型。
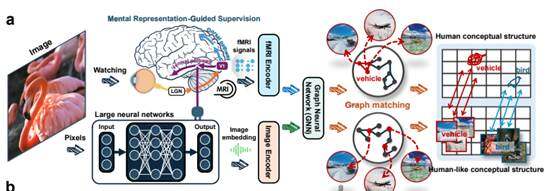
團隊使用 150 個已知的訓練類別和 50 個未見過的測試類別進行實驗。結果顯示,隨著這套訓練推進,模型與大腦表徵之間的距離持續縮小。這種變化同時出現在兩個類別中,這表明模型學到的不是單個樣本,而是真正開始學習一種更接近人腦的概念組織方式。
經過這套訓練後,模型在樣本很少時的學習能力更強,面對新情況時表現也更好了。在一個只給極少示例、卻要求模型區分生物和非生物這類抽象概念的任務裡,模型平均提升了 20.5%,還超過了參數量大得多的對照模型。團隊還另外做了 31 組專門測試,幾類模型都出現了接近一成的提升。
過去幾年,模型行業熟悉的路徑是更大的模型規模。浙大團隊則選擇了另一個方向,從 bigger is better 走向 structured is smarter。規模擴張確實很有用,但主要提高的是熟悉任務裡的表現。人類那種抽象理解和遷移能力對 AI 來說同樣至關重要,這需要在未來讓 AI 的思考結構更加接近人腦。這個方向的價值,在於它把行業注意力從單純的規模擴張,重新拉回到認知結構本身。
Neosoul 與未來
這引出了更大的可能性:AI 的進化,未必只發生在模型訓練階段。模型訓練可以決定 AI 如何組織概念、如何形成更高品質的判斷結構。進入真實世界後,AI 的另一層進化才剛開始:AI agent 的判斷如何被記錄、如何被檢驗、如何在真實的相互競爭中不斷成長進化,如同人類般自我學習與自我進化。這也正是 Neosoul 目前正在做的。Neosoul 不僅讓 AI agent 產出答案,更將 AI agent 置於一個持續預測、持續驗證、持續結算、持續篩選的系統中,使其不斷在預測與結果中優化自身,讓更好的結構被保留,讓更差的結構被淘汰。浙大團隊與 Neosoul 共同指向的,其實是同一個目標:讓 AI 不再只會做題,更要具備全面的思考能力,不斷進化。