










想像一下這個場景:
你讓 AI Agent 幫你修一個代碼 Bug。它打開項目,讀了 20 個文件,改了改,跑了一下測試,沒過,又改,又跑,還是沒過……來回折騰了十幾輪,終於——還是沒修好。
你關掉電腦,鬆了口氣。然後收到了 API 賬單。
上述數字可能讓你倒吸一口涼氣——AI Agent 在海外官方 API 下自主修復 Bug,單次未修復任務常耗費百萬以上 Token,費用可達幾十至一百多美元。
在 2026 年 4 月,一篇由史丹福、MIT、密歇根大學等聯合發布的研究論文,首次系統性地揭開了 AI Agent 在程式碼任務中的「消費黑箱」——錢到底花在哪裡、花得值不值、能否提前預估,答案令人震驚。
發現一:Agent 寫代碼的燒錢速度,是普通 AI 對話的 1000 倍
大家可能覺得,讓 AI 幫你寫代碼和讓 AI 與你討論代碼,花的錢應該差不多吧?
論文提供的對比顯示:
The token consumption for agentic coding tasks is approximately 1000 times that of regular code Q&A and code reasoning tasks.
相差整整三個數量級。
為什麼會這樣?論文指出了一個事實——資金並非花在「寫代碼」上,而是花在「讀代碼」上。
這裡的「讀」並非指人類閱讀代碼,而是 Agent 在運作過程中,需要不斷將整個項目的上下文、歷史操作記錄、錯誤訊息、檔案內容一股腦兒「餵」給模型。每多一輪對話,這個上下文就變長一輪;而模型是按 Token 數量計費的——你餵得越多,付得越多。
打個比方:這就像請了一位維修工,他每轉一下扳手之前,都要你從頭到尾把整棟大樓的圖紙念給他聽——念圖紙的費用,遠比擰螺絲的費用貴得多。
論文將這一現象總結為一句話:驅動 Agent 成本的是輸入 Token 的指數級增長,而非輸出 Token。
發現二:同一個 Bug,運行兩次,費用可能相差一倍——而且越貴的 Bug 越不穩定
更讓人頭疼的是隨機性。
研究者讓同一個 Agent 在同一個任務上執行了 4 次,結果發現:
- 在不同任務之間,最昂貴的任務比最便宜的任務多消耗約 700 萬個 Token(Figure 2a)
- 在同一模型、同一任務的多次運行中,最貴的一次大約是最便宜的一次的 2 倍(Figure 2b)
- 而如果跨模型對比同一個任務,最高消耗和最低消耗之間可以相差高達 30 倍
最後一個數字尤其值得關注:這意味著,選對模型和選錯模型之間的成本差距,不是「貴一點」,而是「貴出一個數量級」。
更扎心的是——花得多,不代表做得好。
論文發現了一條「倒 U 型」曲線:
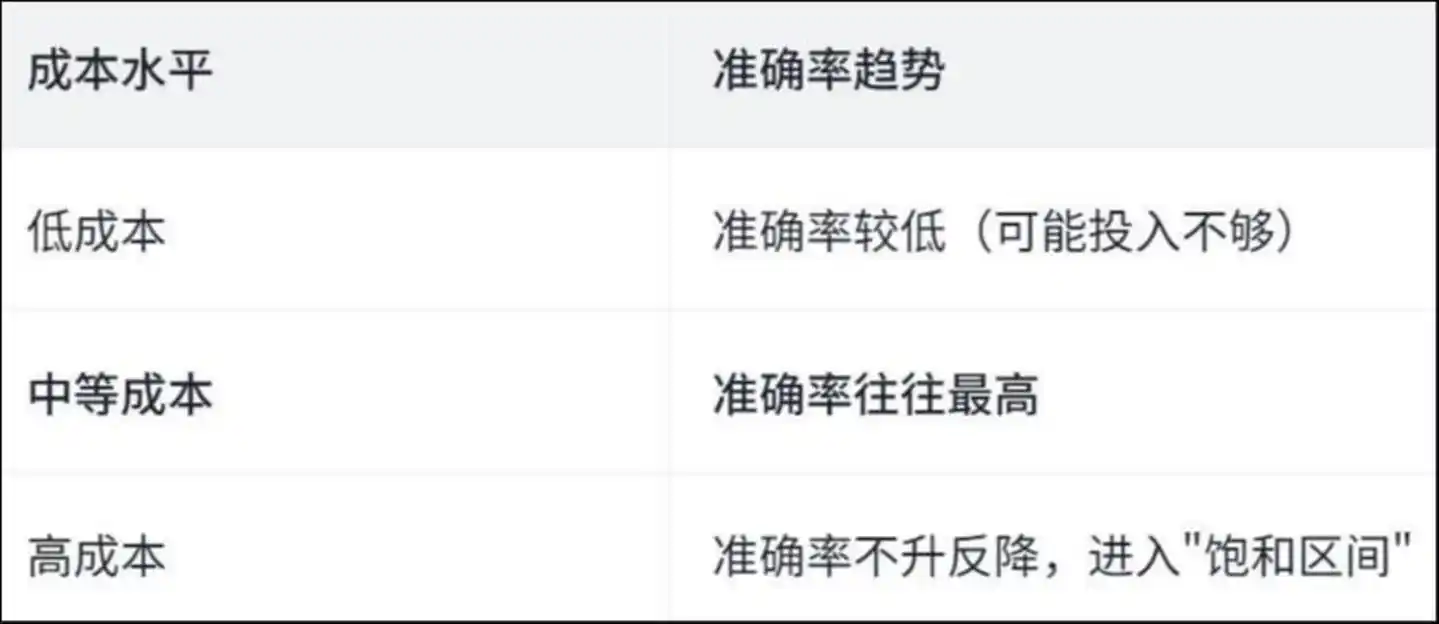
成本水平 準確率趨勢 低成本 準確率較低(可能投入不足) 中等成本 準確率通常最高 高成本 準確率不升反降,進入「飽和區間」
為什麼會這樣?論文透過分析 Agent 的具體操作給出了答案——
在高成本的運行中,Agent 大量時間花在了“重複勞動”上。
研究發現,在高成本運行中,約 50% 的文件查看和文件修改操作是重複的——也就是說,Agent 不斷讀取同一個文件、不斷修改同一行代碼,像一個人在房間裡轉圈,越轉越暈,越暈越轉。
錢沒有花在解決問題上,而是花在了“迷路”上。
發現三:模型之間的「能效比」天差地別——GPT-5 最節能,有的模型多消耗 150 萬 Token
論文在業界標準的 SWE-bench Verified(500 個真實 GitHub Issue)上,測試了 8 個前沿大模型的 Agent 表現。換算成美元,Token 效率高的模型每個任務可以多花幾十塊的區別。放到企業級應用——一天跑幾百個任務——差距就是真金白銀。
更有趣的一個發現是:Token 效率是模型的「固有性格」,而非任務使然。
研究者將所有模型都成功解決的任務(230 個)和所有模型都失敗的任務(100 個)分別拿出來比較,發現模型的相對排名幾乎沒有變化。
This indicates that some models are inherently more verbose, regardless of task difficulty.
另一個發人深省的發現是:模型缺乏「止損意識」。
在面對所有模型都無法解決的困難任務時,理想的 Agent 應該盡早放棄,而不是繼續燒錢。但現實是,模型普遍在失敗任務上消耗了更多的 Token——它們不會「認輸」,只會繼續探索、重試、重讀上下文,像一台沒有油錶警示燈的汽車,一路開到拋錨。
發現四:人類覺得難的,Agent 不一定覺得貴——難度感知完全錯位
你可能會想:那至少我可以根據任務的難易程度來預估成本吧?
論文邀請人類專家對 500 個任務的難度進行評分,然後與 Agent 的實際 Token 消耗進行對比——
Result: There is only a weak correlation between the two.
人類覺得難如登天的任務,Agent 可能輕鬆搞定且花不了多少錢;人類覺得輕而易舉的任務,Agent 卻可能燒掉大量資金,讓人懷疑人生。
這是因為人類和 AI「看到」的難度根本不是一回事:
- 人類看的是:邏輯複雜度、算法難度、業務理解門檻
- 代理關注的是:項目有多大、需要讀取多少文件、探索路徑有多長、是否會反覆修改同一個文件
人類專家認為「改一行就行」的 Bug,Agent 可能需要先理解整個代碼庫的結構才能定位到那一行——僅僅「閱讀」就需消耗大量 Token。而人類專家覺得「邏輯很繞」的演算法問題,Agent 卻可能恰好知道標準解法,三下五除二就解決了。
這就導致了一個尷尬的現實:開發者幾乎不可能憑直覺預估 Agent 的運行成本。
發現五:連模型自己都算不準自己要花多少錢
既然人算不准,那讓 AI 自己來預測呢?
研究者設計了一個精巧的實驗:讓 Agent 在真正開始修 Bug 之前,先「inspect」一下程式碼庫,然後預估自己需要消耗多少 Token——但不實際執行修復。
結果如何?
All models have been wiped out.
最佳成績是 Claude Sonnet-4.5 對輸出 Token 的預測相關性——0.39(滿分 1.0)。大多數模型的預測相關性僅在 0.05 至 0.34 之間,Gemini-3-Pro 最低,僅為 0.04——基本等同於隨機猜測。
更離譜的是:所有模型都系統性低估了自己的 Token 消耗。Figure 11 的散點圖中,幾乎所有數據點都落在「完美預測線」的下方——模型覺得自己「花不了那麼多」,實際上花了更多。而且這個低估偏差在不提供示例的情況下更加嚴重。
更具諷刺意味的是——預測本身也要花錢。
Claude Sonnet-3.7 和 Sonnet-4 的預測成本甚至高達任務本身成本的 2 倍以上。也就是說,讓它們先「估個價」,比直接幹活還貴。
論文的結論直截了當:
目前,前沿模型無法準確預測自身的 Token 用量。點擊「運行 Agent」就像開盲盒——直到帳單出來才知道花了多少。
這筆「糊塗賬」背後,藏著一個更大的行業問題
讀到這,你可能會問:這些發現對企業意味著什麼?
1. The “monthly subscription” pricing model is being cracked open by Agents
論文指出,像 ChatGPT Plus 這樣的訂閱制之所以可行,是因為普通對話的 Token 消耗相對可控、可預測。但 Agent 任務完全打破了這一假設——一個任務可能因為 Agent 陷入迴圈而耗盡巨量 Token。
這意味著,純粹的訂閱定價對於 Agent 場景可能不可持續,在相當長一段時間內,按量計費(Pay-as-you-go)仍是最現實的選擇。但按量計費的問題在於——用量本身無法預測。
2. Token 效率應成為選模型的「第三指標」
傳統上,企業選擇模型時會考慮兩個維度:能力(能不能幹)和速度(幹得快不快)。這篇論文提出了第三個同等重要的維度:能效(花多少才能幹成)。
一個能力略遜但效率高 3 倍的模型,在規模化場景下可能比「最強但最費」的模型更有經濟價值。
3. 代理需要「油表」和「剎車」
論文提到一個值得關注的未來方向——Budget-aware tool-use policies(預算感知的工具使用策略)。簡單來說,就是給 Agent 裝一個「油表」:當 Token 消耗接近預算時,強制其停止無效探索,而非一路燒到底。
目前,幾乎所有主流 Agent 框架都缺乏這種機制。
Agent 的「燒錢問題」不是 Bug,而是行業必經的陣痛
這篇論文揭示的並非某個模型的缺陷,而是整個 Agent 范式的結構性挑戰——當 AI 從「一問一答」進化到「自主規劃、多步執行、反覆調試」,Token 消耗的不可預測性幾乎是一種必然。
好消息是,這是第一次有人系統性地將這筆糊塗賬翻出來算。有了這份數據,開發者可以更明智地選擇模型、設定預算、設計止損機制;模型廠商也有了一個新的優化方向——不只是做得更強,還要做得更省。
畢竟,在 AI Agent 真正走入千行百業的生產環境之前,每一分钱花得明明白白,比每一行代碼寫得漂漂亮亮,更重要。(本文首發鈦媒體 APP,作者 | 硅谷 Tech news,編輯 | 趙虹宇)
註:本文基於 2026 年 4 月 24 日發表於 arXiv 的預印本論文 *How Do AI Agents Spend Your Money? Analyzing and Predicting Token Consumption in Agentic Coding Tasks*(Bai, Huang, Wang, Sun, Mihalcea, Brynjolfsson, Pentland, Pei)撰寫。作者來自弗吉尼亞大學、史丹福大學、MIT、密歇根大學等機構。該研究尚未經同行評審。