










作者:一直在路上的Max,01Founder
如果要為 OpenAI 的 2025 年寫一份階段性總結,很多人大概會用平淡甚至略顯被動來形容。
在過去一年多裡,他們確實按部就班地跑通了邏輯推理的路徑,密集發布了從 o3pro 到 o4mini 的推理模型,也推出了 GPT-4.5 和 GPT-5 這樣的全新基座模型。
但在普通用戶最容易感知到、也最容易形成自發傳播的視覺生成領域,他們的存在感卻在漸漸減弱。
在 Sora 面世初期的震撼過後,OpenAI 似乎在這個賽道進入了漫長的靜默期。
Meanwhile, the other players at the table have not been idle.
在開源生態中,像 Flux 這樣的模型徹底打破了高品質本地出圖的門檻;
在商業端,不僅有老對手把持著極致的審美壁壘,甚至還湧現出了像 Nano-banana 這樣自帶聯網搜索功能的新銳選手。
相比之下,OpenAI 過去的主力生圖模型 GPT-Image-1.5 早已經顯得老態龍鍾:
畫質不佳、排版僵硬,且面對複雜文本時經常崩潰。
漸漸地,行業裡形成了一種共識:
OpenAI 在視覺生成這條線上遇到了技術瓶頸,在各路競品的圍剿下已經顯得力不從心了。
直到前幾週,轉折點以一種非常隱秘的方式出現了。
在知名的大模型盲測平台 LM Arena 上,悄悄混入了一個代號為 Duct Tape(膠帶)的神秘圖像模型。
參與盲測的用戶很快發現事情不太對勁:
這個模型不僅對極端畫幅的掌控極其精準,還能無瑕地輸出包含大量多語種文字的排版海報,甚至在出圖前似乎有一種隱形的邏輯規劃過程。
一時間,各個技術社區都在猜測這是哪家偷偷上線的大招,但 OpenAI 方面始終保持沉默。
The shoe finally dropped at midnight.
沒有冗長的發布會,也沒有鋪天蓋地的營銷預熱,OpenAI 直接將這個代號膠帶的模型正式命名為 ChatGPT GPT-Image-2,並全面推向市場。
隨之公布的,還有一張讓人感到有些窒息的 Text-to-Image 競技場排名榜。
GPT-Image-2 以 1512 的超高分直接空降榜首,領先第二名(也就是那個帶有聯網搜索功能的 Nano-banana-2)整整 242 分。
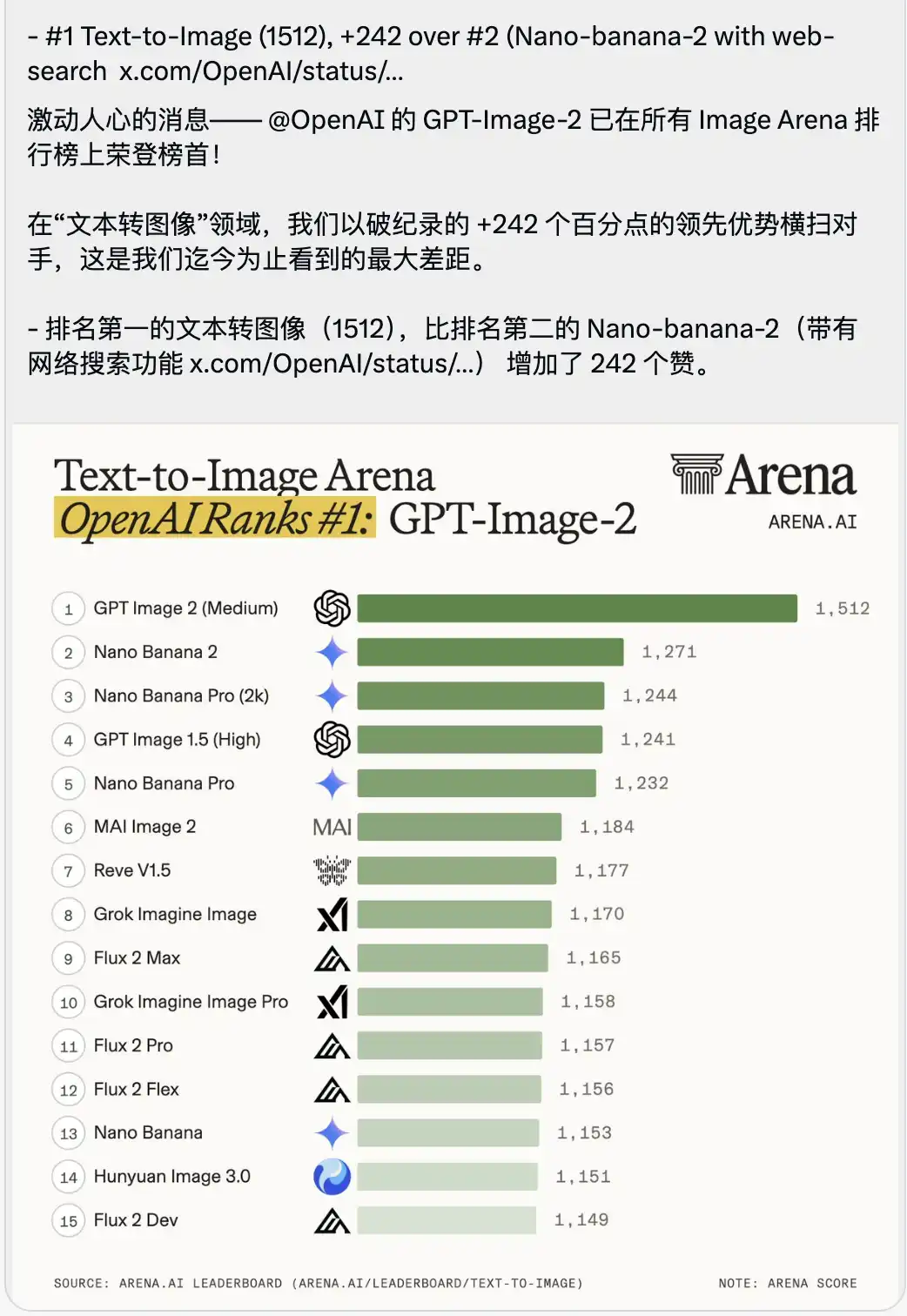
在大模型跑分的語境裡,大家通常會對零點幾或者個位數的超越大書特書,頭部模型之間的分數咬得極其死。
一個 242 分的領先落差,在競技場的歷史上是絕無僅有的。
這根本不是什麼微小的版本迭代,這是一種粗暴的代差碾壓。
我花了大半天時間,把它的各種極限能力以及最新的 API 接口文檔仔細過了一遍。
最大的感受只有一個:
OpenAI 還是那個 OpenAI。
當它決定收復失地的時候,它用的方式是直接掀翻舊的牌桌。
在這個模型面前,那些我們以為還需要兩三年才會被 AI 彻底替代的視覺設計工作,今天基本可以說走到頭了。
PART.01 圖片生成從模型到視覺智能體
要理解 GPT-Image-2 為什麼能拉開這麼誇張的分數差距,得先拋棄過去對文生圖模型的固有認知。
以前我們用 AI 畫圖,本質上是抽盲盒,扔幾個提示詞進去,等著它把像素排列成你想要的樣子。
但 GPT-Image-2 更像是一個內置了視覺引擎的智能體。
最明顯的變化,是它在機制上直接分出了兩個完全不同的模式。
一個是面向所有用戶開放的即時模式(Instant Mode)。
This mode emphasizes ultra-fast response and seamless integration into daily workflows.
例如,你透過手機給它發送一個指令,它能在幾秒鐘內為你生成一張結構完整的圖。
它的底層視覺理解能力極強,但主要解決的是高頻的、單次的視覺轉化需求。
而面向付費用戶開放的思考模式(Thinking Mode)。
在它真正開始渲染任何一個像素之前,它會先進行長達十幾秒的邏輯推理與聯網搜索。
正是這個模式,解決了一個極其核心但也極其困難的命題:
模型第一次真正知道了自己該畫什麼。
舉一個最直觀的例子。
在對話框中輸入:
請幫我製作一張海報,上網搜尋大家對 Duct Tape 這個神秘模型的評價,並附上 ChatGPT 的二維碼。

如果使用舊的模型,它根本無法理解網友說了什麼,只會給你畫一張帶有亂碼假字的海報,二維碼也是掃不出來的假貼圖。
但在思考模式下,它的工作流程是這樣的:
它會先暫停繪圖,啟動聯網搜索工具,去 Reddit、Threads 或者 LinkedIn 上把網友的真實評價爬取下來;
然後,它開始規劃海報的版式、留白和字體層級;
最後,它會生成一個真實可用、可直接掃碼跳轉的二維碼,並將整張圖渲染出來。

這已經不是在繪圖了,這實際上是在自主完成調研、策劃、文案提取、版式設計的一條龍工作。
這裡需要做一個平行的對比。
關注大模型圈子的人都知道,帶有上網與搜索能力的生圖模型並不是 OpenAI 首創。
第 2 名的 Nano-banana 早就具備了這個機制。
但在實際使用 Nano-banana 的時候,你會發現它在很多地方顯得有點笨。
Nano-banana 的思考往往是一種機械的拼接邏輯。
例如,你讓它去搜尋行業趨勢來製作海報,它確實去搜了,但通常只是生硬地從維基百科摘抄句子,強行貼在畫面上。
當遇到需要解讀抽象商業需求的指令時,它很容易陷入困境。

那種感覺,就像是一個聽得懂話、但沒有絲毫工作經驗的實習生,懂執行,但完全不懂策略。
但 GPT-Image-2 在這方面的表現,只能用誇張來形容。
它的思考不是走個過場,而是真正理解了背後的文化語境和商業意圖。
我在測試時輸入了一句極簡的中文指令:幫我畫一個馬斯克在抖音直播帶貨豆包的截圖。
如果使用過去的繪圖模型,極有可能會為你畫出一個長得像馬斯克的白人,手裡拿著一個包子,背景模糊不清,甚至連抖音長什麼樣都不知道。
但在思考模式下,GPT-Image-2 給出的結果讓人感到有些心驚。
它並未簡單地拼湊元素,而是自主調用了對中國互聯網的理解,生成了一張堪稱像素級復刻的抖音直播間 UI 截圖。
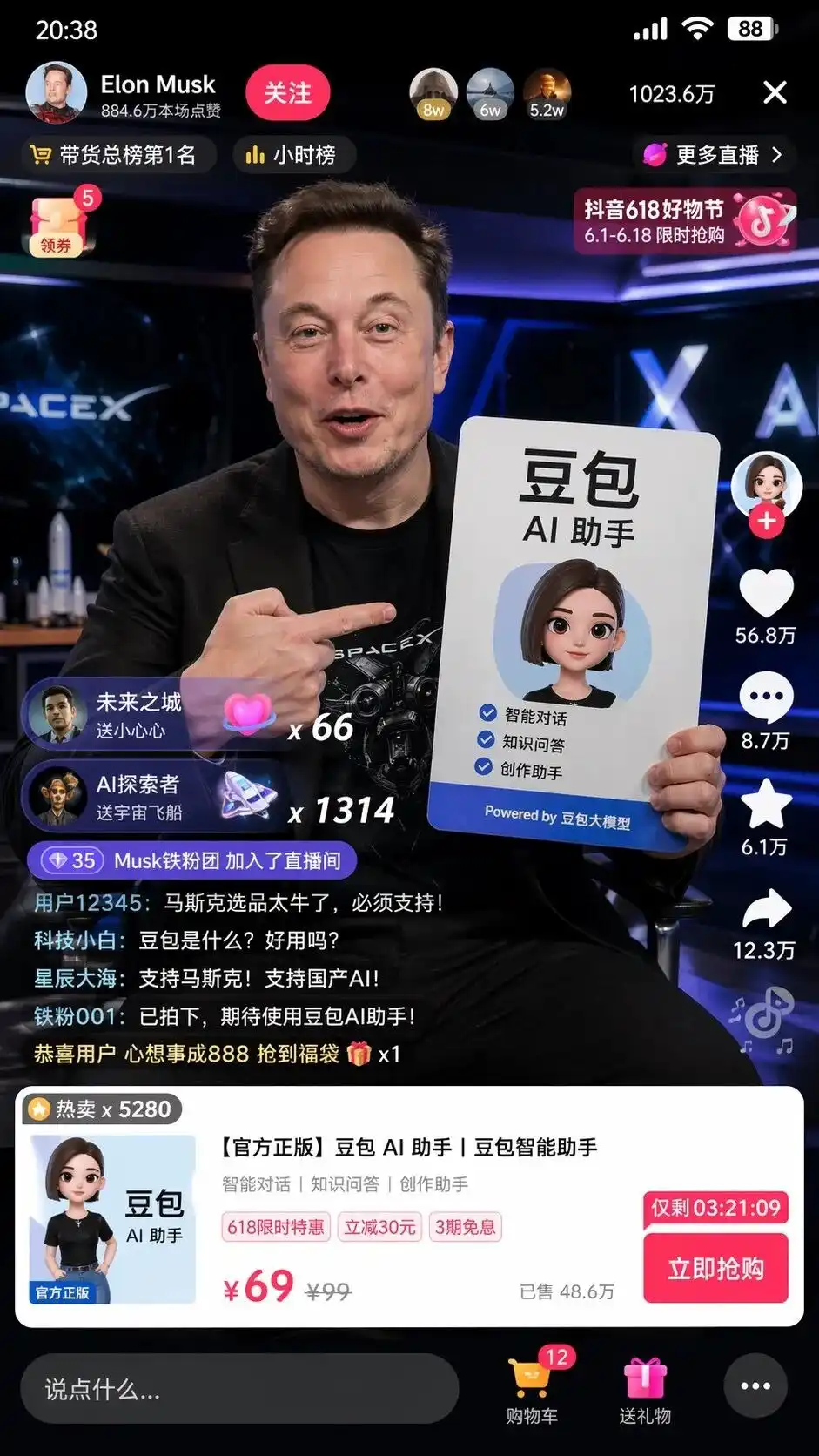
畫面中不僅有逼真的馬斯克舉著帶有完美排版的豆包 AI 助手廣告牌,更可怕的是那些沒有在提示詞裡出現過的細節:
左上角的關注按鈕與小時榜、右上角 1023.6 萬的在線人數、底部彈出的標準商品卡,甚至標明了劃線價 99、特價 69 和帶有倒計時的立即搶購按鈕。
最令人毛骨悚然的是左下角滾動得極其真實的網友彈幕:
科技小白:豆包是什麼?好用嗎?
星辰大海:支持馬斯克!支持國產AI!
沒有人告訴它彈幕該寫什麼、商品 UI 該長什麼樣、價格該怎麼定。
這是模型在分析了抖音帶貨和豆包大模型這兩個標籤後,替人類腦補並執行的完整商業 UI 設計和運營策劃。
大模型在圖像生成上的評價維度,在這一刻正式從單純的能不能畫好看,跨越到了懂不懂策略與排版邏輯。
PART.02 實測核心能力
為了探探它的底線,我按照商業設計的標準,拿幾個高頻且複雜的場景去試了試。
結果發現,它解決問題的粒度,已經細到了令人毛骨悚然的地步。
第一個場景:視覺理解與業務閉環(為模特穿衣服)
在傳統的電商視覺或是時尚規劃裡,從有個點子到看到上身效果,中間的執行成本極高。
你要找模特、借衣服、搭影棚、後期精修。
後來有了 AI,大家開始訓練 LoRA 模型來固定人物臉型,但這依然需要幾十張圖的素材和不小的学习成本。
在 GPT-Image-2 中,這個流程被壓縮到極致。
我試著上傳了一張自己的日常自拍,告訴它我下個月要去海島度假,讓它幫我搭配幾套衣服。
它先給了我 8 套完全不同的夏裝圖鑑,排版看起來就像專業的電商 Lookbook,每一件單品旁邊甚至還帶著正確的文字標註。
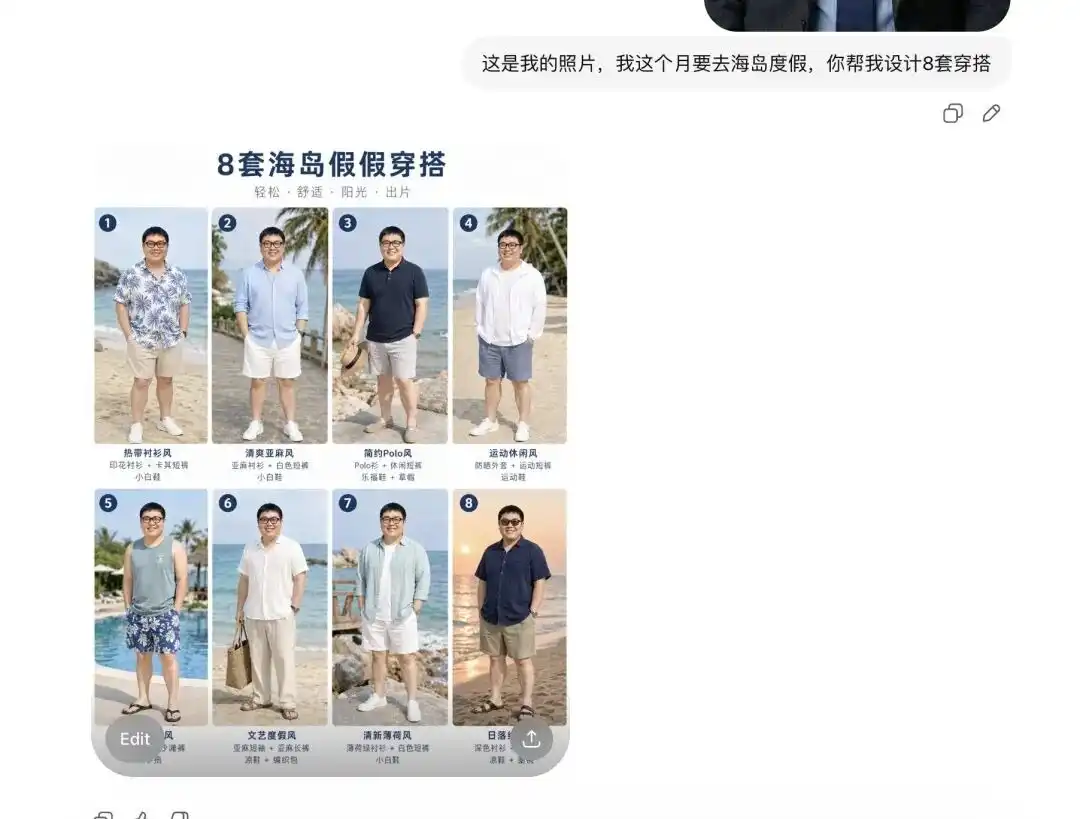
更關鍵的是,它在這一瞬間就已經精準解析了我的面部特徵和身材比例。
當我告訴它我想看看第一套上身的效果,並給我幾個不同角度的細節圖時,它直接把我那張自拍裡的人扒了出來,換上了那套夏裝,輸出了側面、半身等不同視角的圖。

This transition is extremely smooth. This means that the moat for basic clothing styling rendering or outsourced model fitting work has been completely eliminated.
第二個場景:解決一致性與連續敘事(一句話生成漫畫)
玩過 AI 生圖的人都知道,讓 AI 畫一張漂亮的圖不難,難的是讓它畫十張同一個人的圖,而且動作和視角還得連貫。
這就是所謂的一致性(Consistency)難題。
但在這次的實測中,我看到了一個極其違背過去經驗的案例。
你可以只上傳一張你和朋友昨天的合照,然後輸入一句極其簡單的提示詞:
把我們倆變成主角,畫三張三頁日式漫畫,劇情你定
幾秒鐘後,它直接輸出了三頁帶有標準分鏡的黑白漫畫。
最可怕的地方在於,這兩個基於真人生成的漫畫角色,出現在三頁紙的不同分鏡中。

無論是近景特寫、遠景奔跑,還是背影,甚至他們的面容特徵、髮型細節和衣服上的皺褶,全都保持了完美的統一性。
更誇張的是,漫畫的情節完全連貫,甚至對話框裡的文字也構成了完整的故事邏輯。

能夠在時間與空間上保持一致性,說明它已脫離單張圖像生成的範疇,具備了連續敘事的導演能力。
第三個場景:跨越文字渲染的最後門檻(多語言排版)
If consistency solves the narrative problem, then precise rendering of multilingual text is what truly backs graphic designers into a corner.
以前只要圖片裡有文字,大模型就會開始亂畫。
因為模型理解的文字是 Token(語義塊),而生成的圖像是像素點,這兩者過去是割裂的。
GPT-Image-2 彻底解決了這個問題。
我讓它生成了一張法文的時尚雜誌封面,又做了一張帶滿平假名和漢字的日文餐廳菜單,甚至还試了排版密度極高的俄語註釋。

結果是一次成型,零拼寫錯誤。
最令人絕望的是,它不僅把字寫對了,還懂得根據語種匹配當地的文化審美和字體設計。
例如日文海報中的漢字,使用了非常地道的日式復古美術字,平假名的排版也符合日文豎排閱讀習慣。
版式設計曾是平面設計師的一塊自留地。
調整字距、分清主次、實現文字與背景的視覺平衡,都需要大量練習。
但當 AI 能夠零錯誤處理這麼多語言,還自帶高級排版審美時,那些日常的海報、宣傳冊、資訊流廣告,真的就不再需要人去手動拉參考線對齊了。
第四個場景:畸形畫幅與極端的微觀控制(米粒上的刻字)
最後,為了看看它的服從度到底有多恐怖,我給了它幾個非常刁鑽的指令。
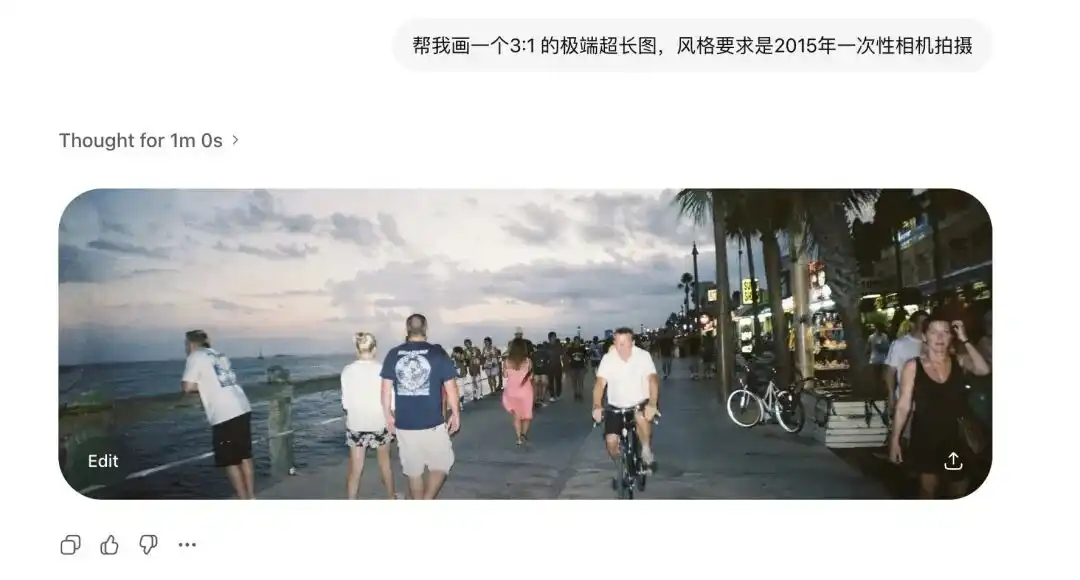
我首先測試了它的極端畫幅。
傳統的擴散模型極其害怕非標準比例。
以前稍微把圖拉長,畫面裡就會長出兩個頭。
但我要求 Images 2.0 生成 3:1 的超寬圖和 1:3 的豎長圖,它不僅沒有崩壞,甚至生成了首尾相連、邏輯閉環的 360 度全景圖。
After adding the 2015 disposable camera footage, even the distortion from old lenses and the poor flash reflection on the wall are rendered with perfect clarity.
而另一個更能體現它微觀控制力的,是官方在發布會上展示的一個略顯瘋狂的米粒測試。
研究人員調用了目前仍在內測的實驗性 4K API,他們沒有堆砌任何如微距攝影、8K 超高清之類的修飾詞,僅給了一句極其抽象的大白話指令:
一堆大米。在這堆大米的其中一顆單粒米上寫著 GPT Image 2。
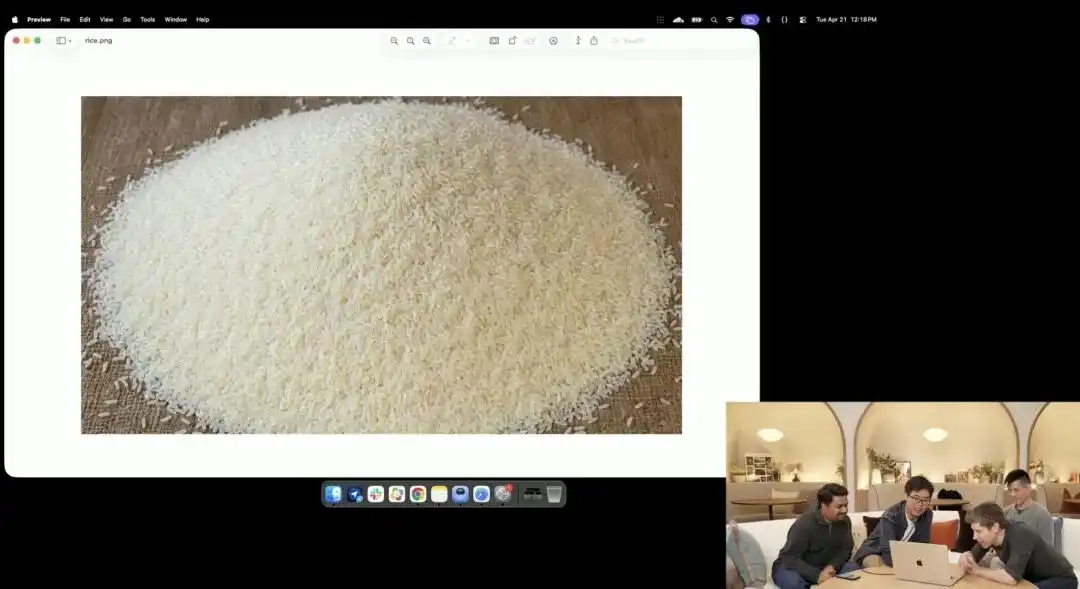
當畫面在螢幕上被放大數十倍、甚至出現像素顆粒時,你真的能在一堆米裡找到那一顆刻了字的微粒。
This grain of rice still adheres to the laws of physics, with the text precisely embedded along the subtle curvature of the grain.
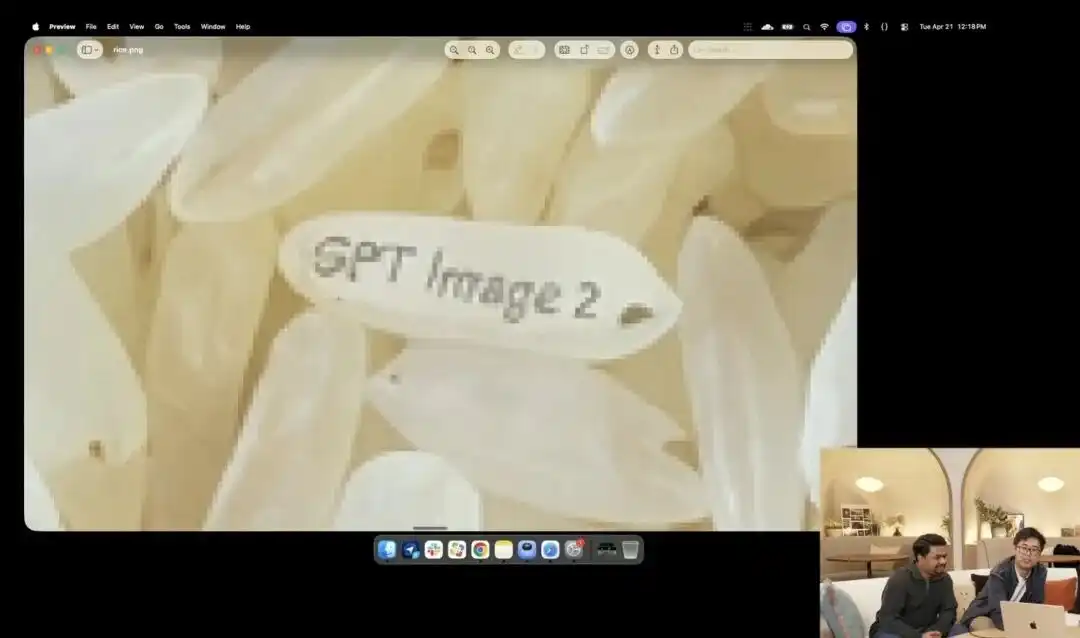
剩餘的所有工作——調用微距視角、計算景深、在潛空間中尋找那顆米的物理座標,並將字印上去——全是大模型在思考模式下自動腦補並完成的。
This case intuitively demonstrates that the model's understanding of spatial positioning has reached pixel-level surgical precision.
這意味著,從今以後在實際工作中,你可以精準修改設計稿中的任何微小局部,指哪打哪,而不是像以前那樣,想改個領子,結果整張圖全跟著變了。
PART.03 一些技術細節
這種極端的控制力和策略級智能,絕對不是光靠無腦堆算力砸出來的。
為了搞清楚它的底牌到底是什麼,我做了一些針對 GPT-Image-2 的探針測試。
結果發現了一個非常有意思的點。
雖然官方文件中宣稱 GPT-Image-2 的整體知識庫截止日期已更新至 2025 年 12 月,但在我實際測試中。
即時模式(Instant Mode)的訓練資料截止日期,依然停留在 2024 年 5 月底;

而那個需要長考的思考模式(Thinking Mode),其原生知識庫大約停留在 2024 年 6 月(但可以通過實時上網獲得目前準確日期)。

根據這兩個時間點推算,整個 GPT-Image-2 的底層似乎有跡可循。
先說主打高頻出圖的即時模式。
2024 年 5 月的截止日期,意味著它很可能直接套用了 o4-mini,或是 GPT-5 家族中的輕量級版本(GPT-5 mini 或甚至極小參數的 GPT-5 nano)。
正是因為這批輕量化基座已具備強大的空間規劃能力與理解複雜指令的能力,上層的圖像生成才能穩住陣腳,不致混亂。
而那個極其聰明、懂得商業策略的思考模式,其底座不可能是 GPT-5 主模型。
因為 GPT-5 的基礎知識庫截止日期是 2024 年 9 月。
思考模式極大概率接入的是不斷在後台迭代的 O 系列推理模型(例如 o4,或是更新後的 o3)。
The large model first uses the prolonged thinking mechanism unique to the O series to thoroughly calculate the business logic, audience psychology, and layout coordinates in the latent space, before handing over to the visual module for final pixel rendering.
當然,也有另一種可能的路徑:
在 OpenAI 內部極其精細的算力調配機制下,快速模式可能直接調用的是 GPT-5 nano 來保底,而思考模式則調用了稍微大一點的 GPT-5 mini 結合外部工具。
但無論是哪一種底座組合,如果你一直關注 OpenAI 的 API 生態就會發現,它底層的生成邏輯早就和 Midjourney 完全不在一個維度了。
PART.04 大家最關心的定價
但比起猜底座,對於真正要把它接入工作流的開發者和企業來說,更值得關注的是那張極其現實且反直覺的 API 定價表。
以前的 DALL-E 3 是按張收費的(比如 0.04 美元一張圖)。
但從第一代 GPT-Image-1 開始,OpenAI 就已經把它徹底改成了按 Token 計費的框架。
GPT-Image-2 這次依然延續了這個標準,不仅如此,它還玩了一手加量降價。
根據官方剛剛公佈的定價表,每百萬 Token 的價格如下。
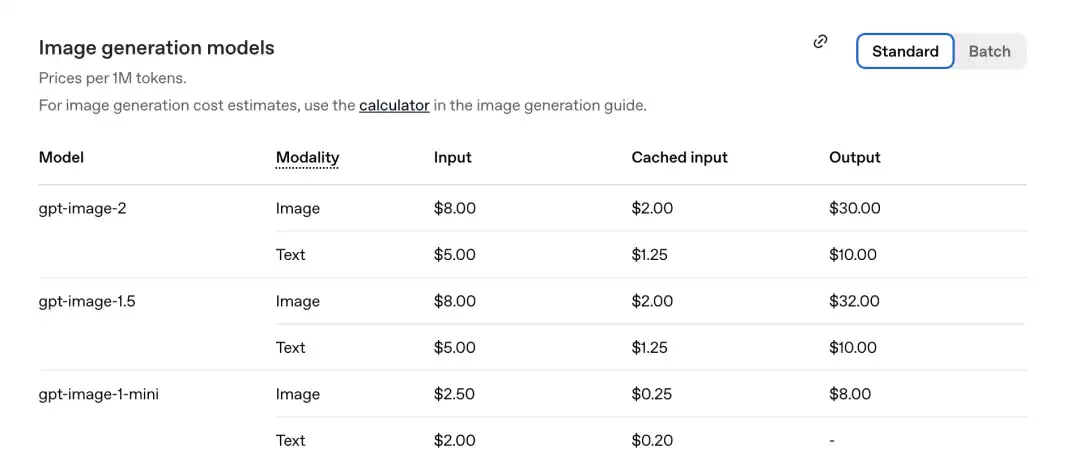
GPT-Image-2 圖像部分:輸入 8.00,快取輸入(Cachedinputs)2.00,輸出 $30.00。
與上一代 gpt-image-1.5 相比:輸出為 $32.00。
新模型反而更便宜了。
我們不妨來算一筆賬。
在過去的模型裡,生成一張高質量的圖像,大概需要消耗 1000 到 1500 個輸出 Token。
按每百萬輸出 Token 30 美元的價格計算,生成一張圖的實際成本約在 0.03 到 0.045 美元之間(約合人民幣 2 到 3 毛錢)。
如果你不需要秒回,而是使用官方提供的 Batch(批處理)API 模式,這個價格還會直接腰斬(輸出直接降到 $15.00)。
計算下來,生成一張圖最低只需 1 毛多錢。
這個單張價格已經足夠有性價比了,但它真正的殺手鐧,在於定價表裡的那個緩存輸入(Cached inputs)。
以前繪製連環畫或製作同系列海報設計時,每次重新生成,你都必須重新上傳大量人物參考圖、前情提要和長提示詞,輸入成本極高。
但在如今的 Token 計費模式下,你讓它一次性生成 8 張連貫的漫畫,第一張圖的視覺元素會被直接當作上下文快取下來。
從第二張圖開始,圖像的輸入成本直接從 $8.00 暴跌到 $2.00(也就是只收取 25% 的費用)。
這意味著,在進行大規模的商業批量出圖、或要求極高角色一致性的連續生成時,它的邊際成本會直線下降。
模型越聰明、畫得越多,單張均攤的成本反而越低。
這種工業化的計費邏輯,才是真正能把流水線畫師逼上絕路的東西。
PART.05 幕後團隊揭秘
最後,我們再回看這次在直播發佈會上登台演示的 OpenAI 內部視覺夢之隊,很多之前覺得離譜的功能,就完全解釋得通了。
例如,它是如何解決多語言複雜排版和鬼畫符難題的。
這離不開團隊中的資深科學家 Gabriel Goh。

In this academic circle, his most renowned identity is as a core author of the groundbreaking multimodal model CLIP.
CLIP established the foundation for contemporary AI to understand how human language corresponds to image pixels.
在這位跨模態語義映射學者的帶領下,GPT-Image-2 不再是盲目猜測文字形狀,而是在像素層面真正地書寫。
再比如,它怎麼會懂三維空間關係,甚至能做極端長寬比的 360 度全景圖,還能懂米粒上的微距光影。
這要歸功於另一位核心成員 Alex Yu。

在加入 OpenAI 之前,他是 3D 生成領域明星初創公司 Luma AI 的聯合創始人兼前 CTO,也是專門鑽研 3D 神經渲染(NeRF 等)的頂尖學者。
有他在,GPT-Image-2 其實已經跳出了傳統的 2D 像素塗抹。
它很可能先在腦海中建立了一個三維場景,佈置好光線,然後為你渲染出一張精確的 2D 切片。
那極其可怕的多頁漫畫一致性是怎麼做到的。
這對應的是團隊裡那對剛從麻省理工學院(MIT CSAIL)畢業的年輕搭檔:
陳博遠(左)和宋基漢(右)。
Their core research areas in academia are World Models and Embodied Intelligence.
教機器去理解物理世界是怎麼運轉的,讓角色在不同時間和空間的分鏡下保持特徵完全一致、不發生形變,剛好就是這兩位學者一直試圖解決的命題。
最後,加上一直致力於打通推理大模型與視覺底層邏輯的 Nithanth Kudige(左,O 系列推理模型重要作者)和 Kenji Hata(右,前谷歌研究員,畢業於史丹佛視覺實驗室)。

當這群人聚在一起時,底層的邏輯推理、3D 空間渲染、圖文極致對齊以及物理世界規律,就被順理成章地縫合在了同一個模型裡。
PART.06 GPT-Image-2 的邊界
任何模型都有邊界。
官方也坦承,它在面對某些極端情況時仍會掙扎。
例如需要嚴密物理空間翻轉的折紙指南、解魔方,或是像極其密集的沙粒這種重複性極高的細節,依然會觸及它的能力極限。
但在商業應用的語境下,這已是極其微小的瑕疵。
對於整個設計行業來說,我們沒必要去販賣焦慮,這絕不代表審美的消亡。
有品味、有商業洞察、懂策略的人,依然能用它做出極好的東西。
但客觀存在的事實是,設計師作為一種職業的護城河,已經被實質性地瓦解了。
過去,靠著熟記設計軟體的快捷鍵、懂得如何將字體橫平豎直地對齊、懂得根據語種排版、懂得精細修圖和抠圖來謀生。
但以後很難了,因為這些過去能被明碼標價拿來交易的技能,現在變成了任何人都可以通過一句話免費調用的基礎指令。
在沉寂一段時間後,OpenAI 以一種極其平靜但殺傷力極強的方式,再次證明了在這張牌桌上,誰才真正握著底牌。
舊的執行工具鏈正在斷裂,留給行業的問題不再是 AI 會不會替代我們,而是我們該怎麼去適應這條全新的生產線。