









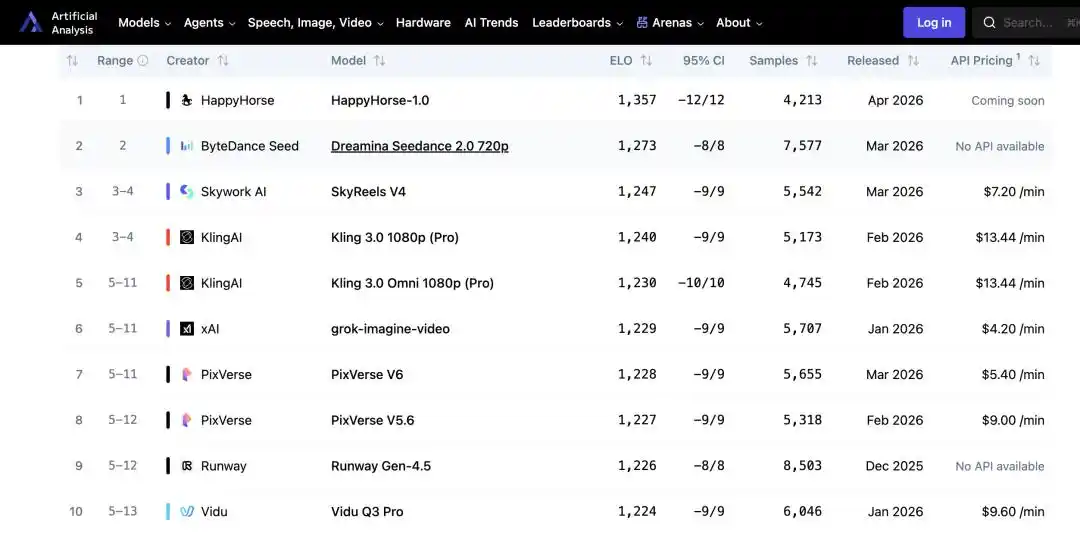
沒有發布會,沒有技術部落格,也沒有任何公司背書——一款名為 HappyHorse-1.0 的文字轉影片模型,悄然登頂權威 AI 評測平台 Artificial Analysis 的 AI Video Arena 排行榜,以更高的 Elo 分數壓過 Seedance 2.0,更將可靈、天工等一眾主流玩家甩在身後,一時之間引發了技術圈的「解密競賽」。
Artificial Analysis 的排名並非技術參數評測,而是基於真實用戶盲測結果彙總出的 Elo 分數,反映的是普通人觀看後的真實感知。這使得該排名比常見的跑分榜更難被輕易質疑,也讓「這東西究竟是誰做的」成為一個無法忽視的問題。
“快樂馬”悄然登頂,引發科技圈猜謎競賽
X 上的猜測來得很快。最先被人注意到的,是官網的語言排序:普通話和粵語排在英語前面。對於一個面向全球用戶的產品,這個順序有點反常——如果是美國團隊主導,英語幾乎不可能不是第一位。背後團隊來自中國,基本可以確認。
名字本身也是線索。2026年是農曆馬年,“HappyHorse”這個命名藏著不太含蓄的馬年梗,今年早些時候“Pony Alpha”也玩過類似套路。於是嫌疑名單迅速拉長:騰訊和阿里的創始人都姓馬,天然在列;有人押注小米,覺得雷軍一貫低調,喜歡突然亮牌;也有人覺得氣質更像DeepSeek,畢竟DS此前曾悄悄上線過視覺模型,後來又悄悄下線了。各路猜測熱鬧非凡,但沒一個拿得出實錘。
真正鎖定目標的,是技術層面的逐條比對。X 用戶 Vigo Zhao 將 HappyHorse-1.0 的公開基準數據與已知模型一一核對,結果找到了一個高度吻合的對象:daVinci-MagiHuman,也就是 3 月上線 Github 的開源模型「達芬奇魔法人類」。
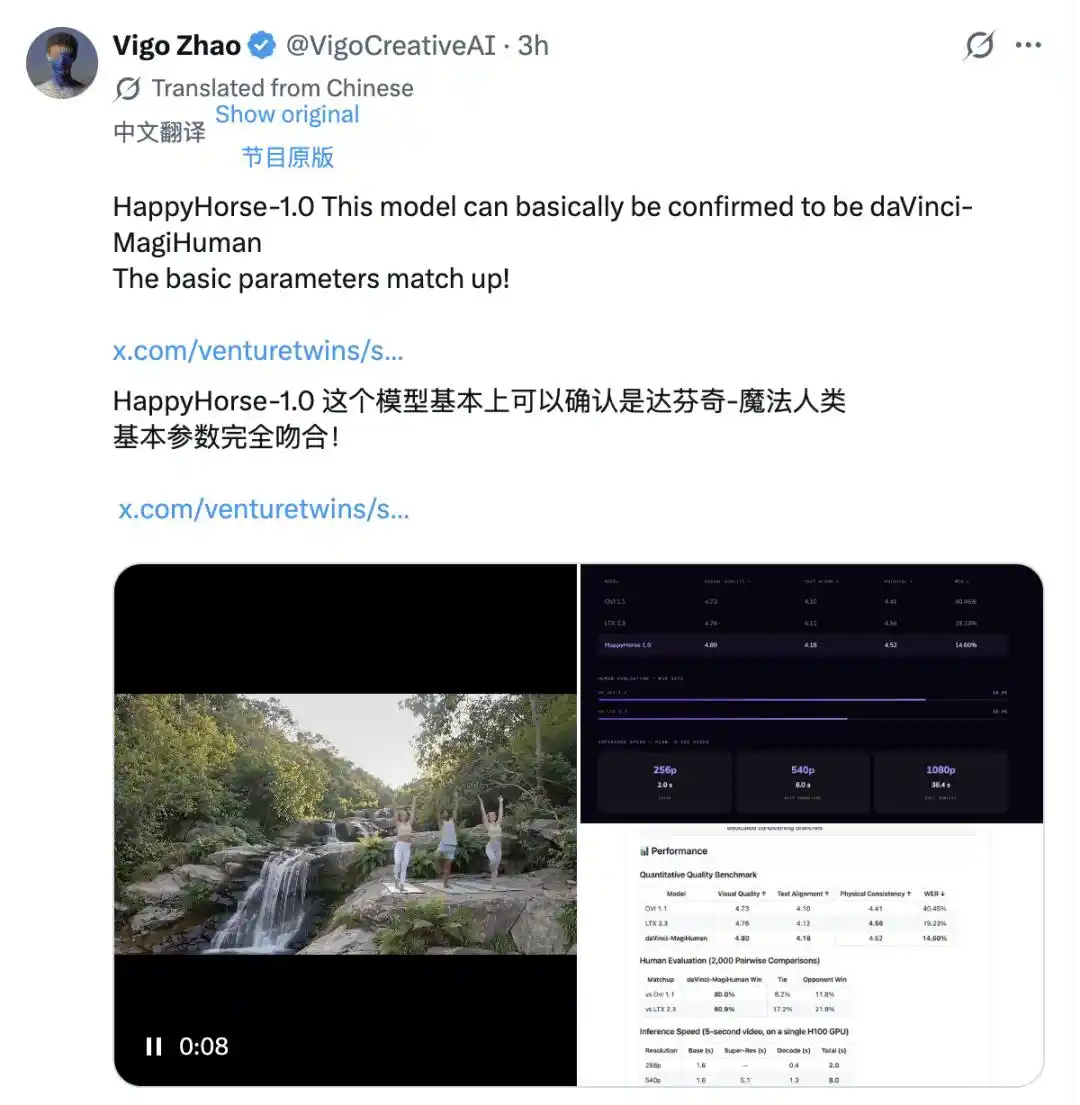
視覺品質 4.80、文本對齊 4.18、物理一致性 4.52、語音字元錯誤率 14.60%——兩份數據逐項吻合。官網結構也幾乎相同:架構描述、性能表格、示範影片的呈現風格,都像是出自同一套模板。兩者同為單流 Transformer 架構,同為音視訊聯合生成,支援的語言列表也完全一致。這種程度的重合,很難用巧合解釋。
目前技術圈認可度最高的結論是,HappyHorse 是 daVinci-MagiHuman 聯合開發方之一的 Sand.ai 基於開源模型優化的迭代版本,核心目的是驗證模型在用戶真實偏好下的表現上限,為後續的商業化落地做鋪墊。
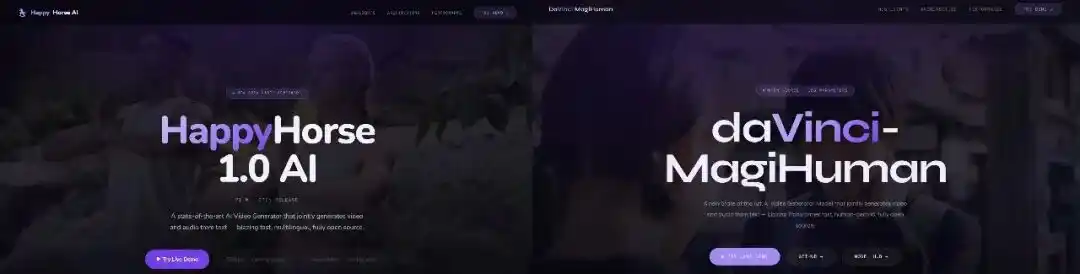
daVinci-MagiHuman 於 2026 年 3 月 23 日正式開源,是兩支年輕團隊合作的成果。一支來自上海創智學院(SII)生成式人工智慧研究實驗室(GAIR),負責人為學者劉鵬飛;另一支是北京的 Sand.ai(三呆科技),創始人曹越同樣具有學術背景,公司方向為自迴歸世界模型。
模型採用150億參數的純自注意力單流Transformer,將文本、視頻、音頻三種模態的token全部塞入同一序列中進行聯合建模——開源界此前從未有人從零開始實現真正的音視頻聯合預訓練,大多數方法僅在單模態基礎上進行拼接。
一款開源視頻模型,何以實現兩週逆襲?
身份釐清後,另一個問題反而更難回答:daVinci-MagiHuman 三月底才開源,HappyHorse-1.0 為何能在短短兩週內取得比 Seedance 2.0 更高的 Elo 分數?
根據官網披露的資訊,HappyHorse 並未對底層架構進行任何修改,較合理的猜測是,它在預設生成策略上針對評測場景做了專項調整。
Elo 系統本質上是用戶偏好的累積,在人物表情是否穩定、音畫是否同步、畫面是否賞心悅目等感知敏感項上稍作優化,就更容易在盲測中被選中。模型的能力上限未變,但「評測表現」可以被打磨出來。
事實上,在 Artificial Analysis 的盲測樣本中,人像生成與口播類內容占比超過 60%,而 daVinci-MagiHuman 從訓練階段就專注於人像演繹,在此類場景中天然具備優勢,這也是其盲測勝率領先的核心原因;若盲測樣本以人像特寫為主,擅長人像的模型就會系統性地佔優勢,這與其在多人物、複雜運鏡、長時序敘事等複雜場景下的實際表現並無直接關係。
結果是,排行榜上的數字與實際體驗之間出現了明顯的落差,X 上的討論者也分成了兩派。懷疑派在測試後認為,HappyHorse-1.0 與 Seedance 2.0 在人物細節、動態連貫性上仍有可見差距,並由此質疑 Elo 評分本身的代表性。
而支持者則對 HappyHorse 的潛力寄予厚望,希望它能夠解決「多鏡頭序列中的畫質一致性」這一行業痛點,因為這是當前主流視頻模型都沒解決好的問題,如果 daVinci-MagiHuman 真的在這裡有所突破,可能要比一個榜單排名重要得多。
模型本身的局限也不該被數字掩蓋。小紅書博主@JACK的AI視界 曾第一時間部署、實測了 daVinci-MagiHuman。發現它運行需要 H100,普通消費級顯卡基本沒戲,雖然社區在研究量化方案,但短期內個人用戶想本地部署還是有難度。
在場景上,它目前主要擅長單一人像,一旦出現多人或場景變複雜,效果就會下降——這不是靠調參能解決的問題,與其專注人像的設計導向直接相關。生成時長一般約為 10 秒,再長就容易混亂,高清輸出仍需依賴超分插件補強。
@JACK的AI視界得出的結論是:daVinci-MagiHuman 的綜合易用性不如 LTX 2.3,需等待社區完成量化後才適合日常使用。
視頻生成賽道,等來了真正的「鯰魚」?
當然,一次榜單領先並不能說明太多。接下來,HappyHorse 還需要在穩定性、高併發訪問速度、跨場景一致性、角色控制精度,以及評測集之外的泛化能力上接受更充分的檢驗。這些,才是決定一個模型能否真正進入創作者工作流的核心指標。
但如果把視野放到更大的行業格局,這件事傳遞的信號其實已經足夠清晰。
開源視頻模型本身並非新鮮事。但始終橫亙在開源與閉源之間的,是一道效果層面的可見差距——在需要向客戶交付的場景中,開源模型的生成質量長期未能跨越「可用」到「可交付」的門檻。可靈、Seedance 等閉源產品的定價權,在相當程度上正是建立在這一差距之上。
這次的意義在於,一個基於開源模型的產品,首次在以真實用戶感知為基準的盲測排行榜上,正面與當前主流閉源競爭對手齊驅並駕。不論其中包含多少針對評測場景的優化成分,對於依賴這一差距建立定價權的閉源廠商而言,至少這是一個值得認真對待的信號。
對於開發者而言,這個轉折點的含義更為具體。在人像、數字人、虛擬主播等垂直場景中,一旦開源基座的生成質量達到「可交付」的門檻,自主部署的成本結構將發生實質性變化——不僅是 API 調用成本的壓縮,更重要的是將數據、模型與推理鏈路完整地納入自身掌控,在定制化深度與隱私合規層面獲得閉源方案難以提供的靈活性。
HappyHorse-1.0 在短期內不會動搖 Seedance 2.0 或 可靈 的市場地位,但一旦確立開源模型的表現可與閉源模型相媲美的認知,後續的量化優化、垂直微調與推理加速將由社區以遠超閉源產品的迭代速度持續推進。
在這個馬年,真正值得關注的,或許不是哪匹馬跑得最快,而是賽道本身正在變寬。
本文來自微信公眾號「AI價值官」,作者:星野,編輯:美圻