









DeepSeek 的此次調價,以一種非線性的斷崖式下跌,強行將行業拉入了一個全新的成本紀元。
文章作者、來源:0x9999in1,ME News
簡而言之
- 價格擊穿底線:2026年4月底,DeepSeek 透過疊加限時折扣與快取降價,將其 V4-Pro 模型的輸出價格降至 0.878 美元/百萬 Token,快取命中輸入更降至 0.0037 美元(約合 0.025 元人民幣),徹底打破了大模型行業的定價錨點。
- 中美定價現「斷層」:與全球頭部廠商相比,DeepSeek-V4-Pro 的 API 調用綜合成本僅為 OpenAI GPT-5.5 及 Anthropic Claude Opus 4.7 的約三十分之一,形成極其顯著的成本優勢剪刀差。
- 國內競爭格局承壓:在 DeepSeek 的激進定價下,國內如 智譜 GLM 5.1、月之暗面 Kimi K2.6 等主力模型面臨巨大的商業化壓力,或將被迫跟進降價,行業出清速度將大幅加快。
- 「快取命中」成為核心經濟學:DeepSeek 將快取命中價格降至原價的 1/10,這一策略從底層邏輯上極大地利好長文本處理、RAG(檢索增強生成)及 Agent(智能體)的持續多輪互動場景。
- 智庫研判結論:基礎大模型正在加速「電水等基礎設施化」,未來的競爭焦點將從單一的模型參數規模之爭,全面轉向推理成本優化能力與開發者生態的佔有率之爭。
引言:大模型算力成本的「奇點」時刻
技術的發展往往伴隨著成本的指數級下降,這是任何一項顛覆性技術走向全面普及的必經之路。2026年4月25日至26日,AI行業迎來了一個極具標誌性的時刻:頭部大模型廠商DeepSeek連續投下兩枚「深水炸彈」。首先是宣布對DeepSeek-V4-Pro模型API開啟限時2.5折的極速優惠;緊接著宣布全系列API服務中,輸入快取命中的價格直接降至原有價格的1/10。
經過這兩輪疊加的調價策略,在2026年5月5日之前,DeepSeek-V4-Flash每百萬Tokens的輸入快取命中價格已跌至驚人的0.0029美元(約合0.02元人民幣),而對標全球頂尖水平的DeepSeek-V4-Pro,其輸入快取命中價格也僅為0.0037美元(約合0.025元人民幣)。
在此之前,業界普遍預測大模型的推理成本將以每年約50%的速度下降,但DeepSeek此次定價調整,以非線性的斷崖式下跌,強行將行業拉入一個全新的成本紀元。我們認為,這絕非一次簡單的市場營銷活動或短期的「價格戰」,而是由底層算法架構優化(如稀疏注意力機制、極致的MoE架構演進)以及算力集群工程化能力提升所帶來的必然結果。本報告將基於最新的全行業價格數據,深度解析DeepSeek降價所帶來的行業震盪,並橫向對比全球主流大模型的商業競爭力,試圖為決策層提供一份清晰的產業演進路線圖。
核心現象:DeepSeek-V4 系列價格體系的極限擊穿
要理解此次降價的震撼程度,我們必須深入剖析大模型 API 計費的三個核心維度:輸入價格(未命中快取)、輸入價格(命中快取)以及輸出價格。過去的計費模式往往只區分輸入和輸出,但隨著長上下文(Long-Context)技術的成熟,「快取命中率(Cache Hit)」正在成為重塑 API 經濟學的關鍵變數。
定價策略拆解:折扣疊加與緩存槓桿
根據最新公佈的數據,DeepSeek 採取了「基準降價 + 試時折扣 + 緩存槓桿」的三重打擊策略。
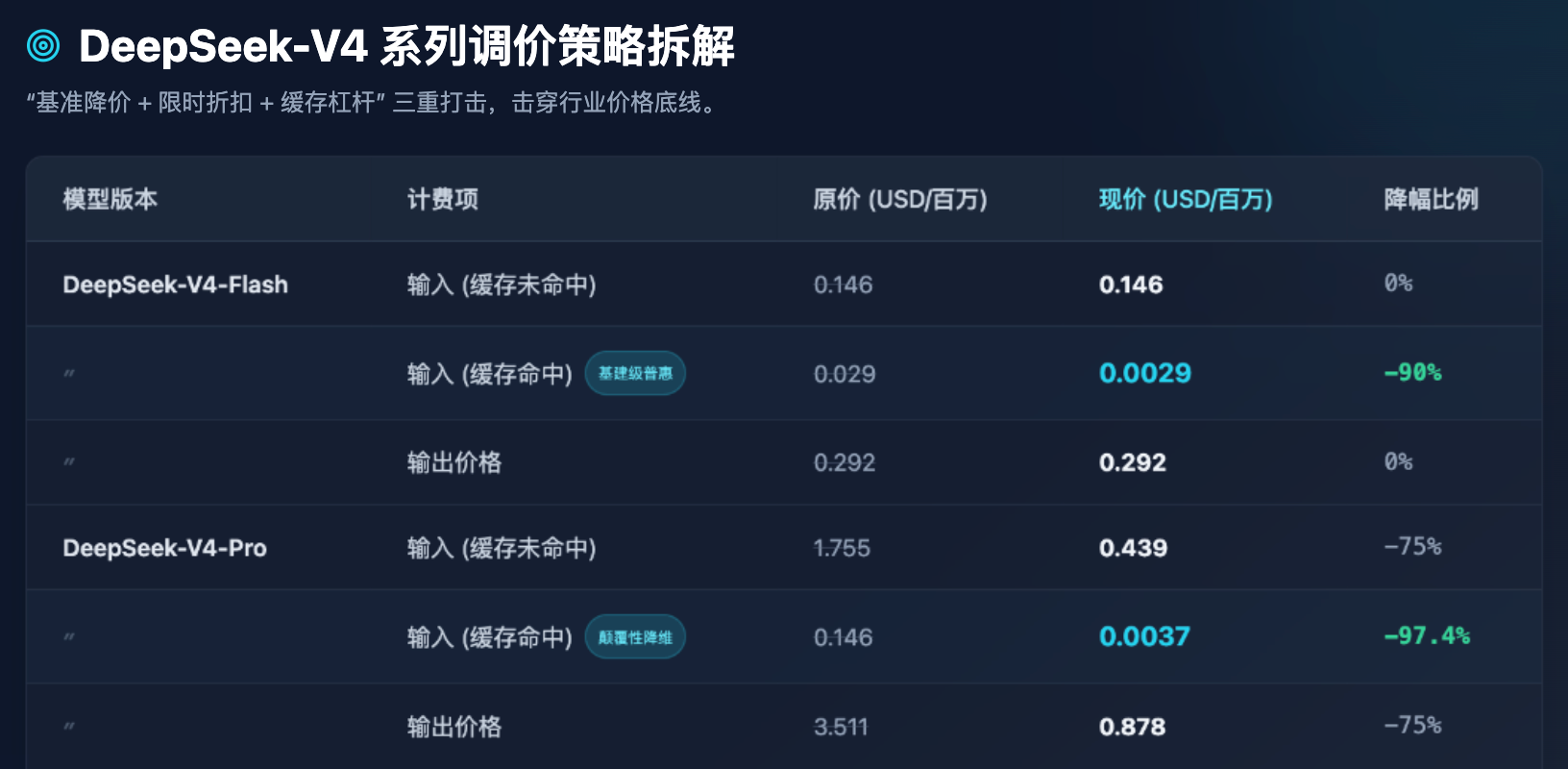
表1:DeepSeek-V4 系列最新 API 調價前後對比(單位:美元/百萬 Token)
從表1中我們可以得出幾個極其明確的產業觀察:
第一,Flash 模型的普惠化已見底。對於主打高併發、低延遲的 Flash 模型,其輸出價格維持在 0.292 美元/百萬 Token,這已是極度貼近伺服器算力硬成本的底線。DeepSeek 並未在 Flash 的基準價格上繼續做文章,而是巧妙地將「快取命中」價格下調了 90%。這意味著,在處理大量重複性系統提示詞(System Prompt)或固定文檔問答時,Flash 模型的成本幾乎可以忽略不計。
第二,Pro 模型的降維打擊。V4-Pro 作為對標全球第一梯隊(如 GPT-5 級別)的旗艦模型,其輸出價格從 3.511 美元暴降至 0.878 美元。更為誇張的是,原本 0.146 美元的快取命中輸入價格,在疊加了限時 2.5 折和 1/10 降價後,直接來到了 0.0037 美元。這是一個極其恐怖的數字——這意味著調用全球頂尖智力的成本,已經被壓縮到了連中小企業甚至個人開發者都可以毫無顧忌進行高頻調用的程度。
第三,倒逼開發者優化 Prompt 工程。將快取命中的價格設定為未命中價格的幾十分之一(例如 Pro 模型中,0.0037 美元 vs 0.439 美元,相差約 118 倍),這不僅是定價策略,更是在透過商業手段引導技術生態。DeepSeek 在明確告訴開發者:只要你們的架構設計得當(例如固定長上下文在前,變動短問題在後),你們就能享受到近乎免費的輸入算力。
橫向比較:全球與本土大模型定價的「斷層」反差
僅僅將 DeepSeek 自身的降價進行縱向對比,不足以看清全貌;當我們將其置於 2026 年全球大模型市場的坐標系中時,這種定價策略所製造的「斷層」對比才真正令人脊背發涼。
基於 OpenRouter 及各家公開資訊,我們整理了目前市場上最具代表性的 9 款國內外大模型最新 API 定價資料。

表2:2026 年全球主流大模型 API 定價對比(單位:美元/百萬 Token)
對抗全球巨頭:粉碎「高智商高溢價」神話
在過去兩年的AI敘事中,OpenAI 和 Anthropic 一直維持著一種默契:最聰明的模型理應享受最高的毛利率。目前,GPT-5.5 和 Claude Opus 4.7 的輸出價格分別高達 30 美元和 25 美元/百萬 Token。這兩家矽谷巨頭試圖通過壟斷最頂尖的推理能力,來維持其高昂的算力稅。
然而,DeepSeek-V4-Pro 的出現及其 0.878 美元的輸出定價,直接將這層窗戶紙捅破。假設 V4-Pro 在各項核心基準測試(Benchmarks)及實際體驗中能夠達到或接近 GPT-5.5 的水平,那麼這兩者之間高達 34 倍的輸出價格差,將徹底摧毀海外巨頭在 B 端市場的溢價邏輯。
「ME News 智庫」估算,對於一家重度依賴 AI 生成內容的出海企業,若每月消耗 10 億 Token 的輸出,使用 GPT-5.5 的硬性成本為 3 萬美元;而切換至 DeepSeek-V4-Pro,這一成本將驟降至 878 美元。這種量級的成本差異,足以影響一家初創企業的生死存亡。這表明中國 AI 企業在底層模型訓練效率和推理集群優化上,已經走出了與矽谷完全不同的「暴力美學與極致工程」並重的路線。
圍剿國內同儕:加速行業大洗牌
如果說 DeepSeek 對海外巨頭是降維打擊,那麼對國內友商而言,則是一場殘酷的零和博弈。
從表2可以看出,國內頭部廠商如智譜(GLM 5.1,輸出4.4美元)、月之暗面(Kimi K2.6,輸出4美元)在定價上處於一種尷尬的境地。這些價格在幾個月前還被認為是「合理且具有性價比」的,但在DeepSeek-V4-Pro(輸出0.878美元)面前,瞬間失去了所有的價格防線。連一直以開源和低價著稱的阿里雲(Qwen3.6 Plus,輸出1.96美元)也顯得不再「便宜」。
而在輕量級 Flash 模型的戰場上,戰鬥同樣白熱化。階躍星辰的 Step 3.5 Flash 輸入低至 0.028 美元,輸出僅 0.299 美元,與 DeepSeek-V4-Flash(輸出 0.292 美元)咬得極緊。這說明在輕量模型領域,算力成本的壓榨已經到了納米級,各家都在貼著成本線飛行。
綜合來看,DeepSeek 實際上是用 Pro 級別的能力,去打國內友商 Plus 甚至標準版的定價;用 Flash 級別的定價,去承接所有海量、低價值密度的長尾流量。這種「雙端鉗制」的戰術,極大地壓縮了其他大模型公司的生存空間,國內 AI 大模型的淘汰賽將在這輪降價後被按下快進鍵。
深度透視:極致低價背後的技術與商業邏輯
脫離基本面的低價不可持續。DeepSeek 之所以敢於在 2026 年祭出如此決絕的降價策略,其背後有著深厚的技术支援與極具野心的商業圖謀。
技術邏輯:從「力大磚飛」到「架構制勝」
價格的斷崖式下降,本質上是技術架構演進的紅利釋放。
- 深度學習中 MoE(混合專家)架構的紅利:與 OpenAI 早期龐大的稠密模型不同,目前的先進模型普遍採用高度優化的 MoE 架構。DeepSeek 極有可能在 V4 架構中進一步降低激活參數的比例。這意味著,即使總參數量龐大,但在每次推理時,僅有極少部分「專家」被喚醒,從而大幅降低單次調用的計算量(FLOPs)和顯存頻寬壓力。
- 革命性突破 KV Cache 管理:本次調價最大的亮點在於「輸入快取命中率降至 1/10」。在 Transformer 架構中,長文本推理最大的瓶頸並非計算,而是儲存上下文資訊的 KV Cache 占用大量顯存。DeepSeek 明顯已在系統層面實現了跨請求、全局共享的 KV Cache 池化技術(例如 RadixAttention 技術的升級版)。當無數用戶的併發請求中包含相同的系統設定或背景知識庫時,模型不再需要重新計算這些 Token,而是直接從記憶體甚至分散式顯存池中讀取。這使得「長文本輸入」的邊際成本趨近於零。
商業邏輯:以利潤換取空間,重塑生態護城河
「ME News 智庫」認為,DeepSeek 的限時折扣與底價策略,其商業目的清晰且果決:
首先,徹底摧毀「套殼微調」生態,逼迫AI原生應用爆發。當最強大的基礎模型調用成本無限趨近於免費時,創業者再花費巨資去訓練或微調自己的行業小模型將變得毫無經濟學意義。DeepSeek透過低價,試圖將全社會所有的AI開發者吸納進自己的API生態中,使其成為像亞馬遜AWS、微軟Azure一樣的「AI時代底層水電煤」。
其次,Agent(智能體)爆發的黎明。真正的 Agentic 應用需要模型進行大量的自我思考、反思、規劃與多輪迴圈調用(Loop)。在這個過程中,會產生海量的隱性 Token 消耗。昂貴的 API 是 Agent 普及的最大絆腳石。DeepSeek 透過將快取命中價格降至 0.0037 美元,實際上是在為「讓 AI 自己跑一萬圈」提供經濟上的可行性。誰提供了最便宜的試錯成本,誰就能孕育出最偉大的 AI 原生超級應用。
行業影響與趨勢研判:從「模型戰」到「生態戰」
為了更直觀地展現這種價格變化對企業決策的影響,我們進行了一次企業級應用的成本模擬推演。
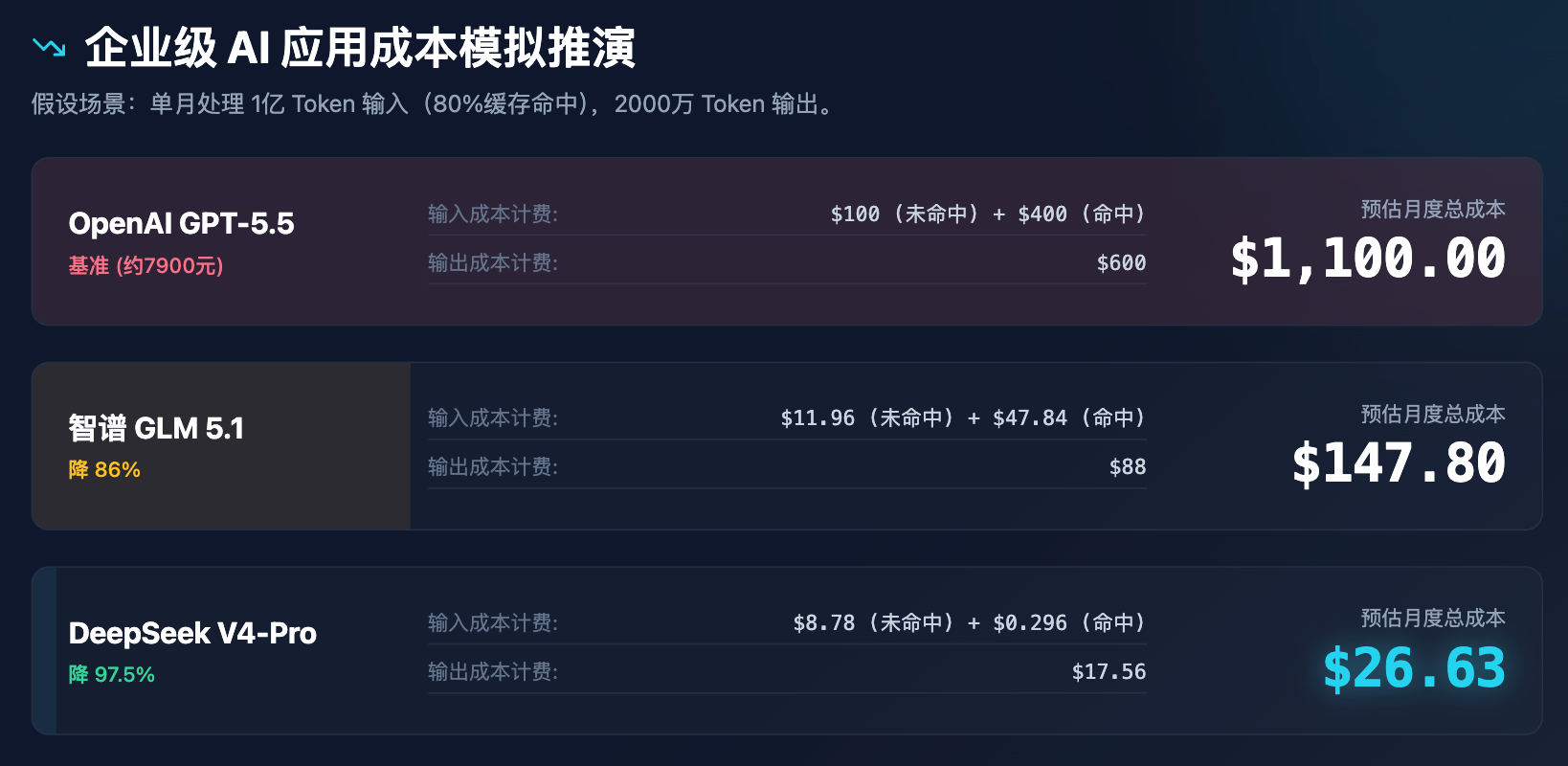
表3:企業級AI應用成本模擬分析(假設單月處理1億輸入Token,2000萬輸出Token)
通過上述模擬可以清晰地看出,DeepSeek 的定價不僅是在打折,更是在重構成本模型。每月不到 30 美元的成本,就能驅動一個中型企業所有的客服輔助、文檔解析和代碼檢查需求,這必將引發一系列連鎖反應:
- AI 投資邏輯的根本轉向:資本將徹底失去對「再造一個通用大模型」的興趣。除極少數國家隊或互聯網巨頭外,通用基礎大模型的門已經焊死。未來投資將全方位湧向應用層(Application Layer)和基礎設施中間件(基礎設施路由器、AI 網關等)。
- 多模型路由策略(LLM Routing)成為標準配置:企業不再會死磕單一模型。系統將自動根據任務複雜度進行分發。例如,90%的日常資料清洗、簡單分類交由 DeepSeek-V4-Flash 或 Step 3.5 Flash 以極低成本完成;10%的複雜邏輯推理、高管報告生成則調用 DeepSeek-V4-Pro 或按需調用 GPT-5.5。
- 長文本應用迎來真正的商業化拐點:在此之前,「上傳百萬字財報讓AI總結」雖然聽上去美好,但每次動輒幾美元的API成本讓B端企業望而卻步。伴隨著輸入快取命中價格降至0.02元人民幣/百萬Token的級別,「閱讀全庫文檔並實時互動」將成為所有企業OA軟體、ERP系統的標配功能。
結論與戰略建議
2026年4月的這場降價風暴,標誌著大模型行業正式告別了「拼參數、秀跑分」的古典浪漫主義時期,進入了「拼成本、搶算力、佔生態」的殘酷工業化時代。DeepSeek通過極限施壓的定價策略,不僅向全球展現了中國AI企業在模型工程學上的深厚造詣,更是在主動刺破AI算力的高溢價泡沫。
針對此,「ME News 智庫」有三點建議:
- 對於應用層開發者:拋棄對大模型調用成本的恐懼。立即停止自建和微調百億參數以下的基礎模型,將所有研發資源投入到產品體驗、端側適配、專有數據壁壘的構建以及 Agent 工作流的打磨中。利用這一輪「廉價高智算力」紅利,快速佔領場景。
- 對於傳統企業的CIO/CTO:重新評估企業的AI化戰略。以往基於成本考量而擱置的知識庫問答、自動化客服、代碼Copilot項目,在目前的API價格下已具備極高的ROI(投資回報率)。建議引入成熟的LLMOps平台,建立企業級AI閘道,以便靈活接入當前最具性價比的模型。
- 對於基礎模型同行:必須拋棄跟隨策略。面對價格戰,要麼通過更極致的晶片-框架協同優化將成本壓得更低,要麼在具身智能、多模態原生(視頻/3D生成)、垂直行業強邏輯推理等差異化領域建立不可替代的技術壁壘。純粹的語言大模型已趨平庸,再無出路。
大模型不再是供奉在實驗室中的神明,它正以前所未有的速度跌落神壇,化作驅動萬物智能的滾滾洪流。而這一切,才剛剛開始。
引用來源:
- OpenRouter. (2026). API 定價比較資料庫.
- DeepSeek 官方公告。 (2026, April 25). DeepSeek-V4-Pro API 限時優惠計劃.
- DeepSeek 官方公告。 (2026, April 26). 大模型時代普惠算力:API 全局快取命中價格調整方案.