









文 | Sleepy.txt
八年前,中興心臟驟停。
2018 年 4 月 16 日,美國商務部工業與安全局的一紙禁令,讓中興通訊這家擁有 8 萬名員工、年營收超千億的全球第四大通信設備商,在一夜之間停擺。禁令內容很簡單,未來七年,禁止任何美國公司向中興出售零部件、商品、軟體和技術。
沒有高通的晶片,基站停產。沒有谷歌的安卓授權,手機也沒有了可用的系統。23 天後,中興發佈公告,稱公司主要經營活動已無法進行。
不過中興最終活了下來,但代價是 14 億美元。
10 億美元罰款,一次性付清;4 億美元保證金,存入美國銀行的託管賬戶。此外,全部高層換血,接受美方合規監督團隊進駐。2018 年全年,中興淨虧損 70 億元人民幣,營收同比暴跌 21.4%。
當時擔任中興董事長的殷一民在內部信中寫道:「我們身處在一個複雜的、高度依賴全球供應鏈的產業中。」這句話,在當時聽來,是反思,也是無奈。
八年后,2026 年 2 月 26 日,中國 AI 獨角獸 DeepSeek 宣布,其即將發布的 V4 多模態大模型,將優先與國產晶片廠商深度合作,首次實現從預訓練到精調的全流程非英偉達方案。
我們不再使用英偉達。
消息一出,市場的第一反應是質疑。英偉達在全球 AI 訓練晶片市場的份額超過 90%,放棄它,這在商業上合理嗎?
但 DeepSeek 的選擇背後,藏著一個比商業邏輯更大的問題:中國 AI,到底需要一場怎樣的算力獨立?
被卡脖子的到底是什么
很多人以為,晶片禁令卡住的是硬體。但真正讓中國 AI 公司感到窒息的,是一個叫 CUDA 的東西。
CUDA,全稱 Compute Unified Device Architecture,是英偉達在 2006 年推出的一套平行計算平台和程式設計模型。它允許開發者直接調用英偉達 GPU 的算力,來加速各種複雜的計算任務。
在 AI 時代到來之前,這只是一個屬於少數極客的工具。但當深度學習的浪潮襲來,CUDA 變成了整個 AI 產業的地基。
Training AI large models is essentially massive matrix operations, which is precisely what GPUs excel at.
英偉達憑藉提前十幾年的佈局,用 CUDA 為全球的 AI 開發者搭建了一整套從底層硬體到上層應用的完整工具鏈。今天,全球所有主流的 AI 框架,從谷歌的 TensorFlow 到 Meta 的 PyTorch,底層都與 CUDA 深度綁定。
一位 AI 專業的博士生,從入學第一天起,就在 CUDA 的環境中學習、編程、做實驗。他寫的每一行代碼,都在加固英偉達的護城河。

截至 2025 年,CUDA 生態已擁有超過 450 萬開發者,涵蓋 3000 多個 GPU 加速應用,全球超過 4 萬家公司在使用 CUDA。這個數字意味著全球 90% 以上的 AI 開發者,都被綁定在英偉達的生態裡。
CUDA 的可怕之處在於,它是一個飛輪。越多開發者使用,就會產生越多工具、庫和代碼,生態就越繁榮;生態越繁榮,就越能吸引更多的開發者加入。這個飛輪一旦轉起來,就幾乎無法被撼動。
結果就是,英偉達賣給你最貴的鏟子,還定義了唯一的挖礦姿勢。你想換一把鏟子?可以。但你得先把過去十幾年裡,全球幾十萬最聰明的大腦在這個姿勢下累積的所有經驗、工具和代碼,全部重寫一遍。
這個成本,誰來付?
因此,當 2022 年 10 月 7 日,BIS 第一輪管制落地,限制英偉達 A100 和 H100 對華出口時,中國的 AI 公司們,第一次集體感受到了中興式的窒息感。英偉達隨後推出了「中國特供版」A800 和 H800,降低了晶片間的互聯頻寬,勉強維持供應。
但僅僅一年後,2023 年 10 月 17 日,第二輪管制再次收緊,A800 和 H800 也被禁,13 家中國公司被列入實體清單。英偉達不得不再推出進一步阉割的 H20。到 2024 年 12 月,拜登政府任期内的最後一輪管制落地,連 H20 的出口都被嚴格限制。
三輪管制,層層加碼。
But this time, the story's direction is completely different from Zhongxing back then.
一場非對稱的突圍
在禁令之下,所有人都以為,中國 AI 的大模型之夢會就此終結。
他們都錯了。面對封鎖,中國公司並沒有選擇正面硬剛,而是開始了一場突圍。這場突圍的第一個戰場,不在晶片,而在算法。
從 2024 年底到 2025 年,中國的 AI 公司們集體轉向了一個技術方向:混合專家模型。
Simply put, it involves splitting a large model into many smaller experts, and only activating the most relevant ones when processing tasks, rather than activating the entire model.
DeepSeek 的 V3 就是這個思路的典型代表。它擁有 6710 億個參數,但每次推理只激活其中的 370 億個,僅佔總量的 5.5%。在訓練成本方面,它使用了 2048 塊英偉達 H800 GPU,訓練 58 天,總花費 557.6 萬美元。作為對比,外界對 GPT-4 訓練成本的估算,大約在 7800 萬美元。一個量級的差距。
算法上的極致優化,直接反映到了價格上。DeepSeek 的 API 價格,輸入每百萬 Token 僅 0.028 到 0.28 美元,輸出 0.42 美元。而 GPT-4o 的輸入價格是 5 美元,輸出 15 美元。Claude Opus 更貴,輸入 15 美元,輸出 75 美元。換算下來,DeepSeek 比 Claude 便宜了 25 到 75 倍。
這個價格差,在全球開發者市場上反應巨大。2026 年 2 月,全球最大的 AI 模型 API 聚合平台 OpenRouter 上,中國 AI 模型的週調用量在三週內暴漲 127%,首次超越美國。一年前,中國模型在 OpenRouter 上的份額不足 2%。一年後,增長了 421%,逼近六成。
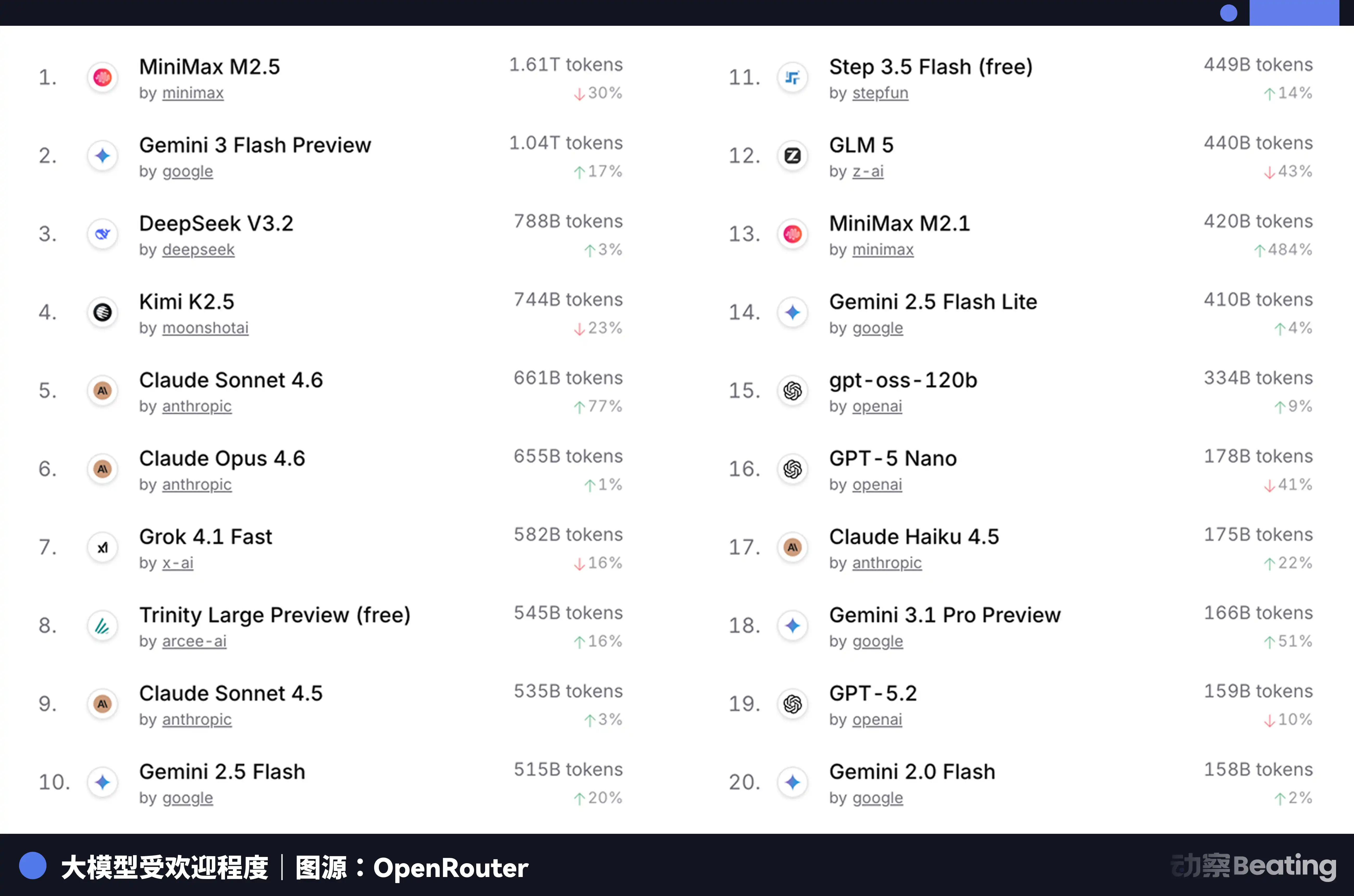
這組數據背後,有一個容易被忽視的結構性變化。從 2025 年下半年開始,AI 應用的主流場景從聊天轉向了 Agent。在 Agent 場景下,一次任務的 Token 消耗量是簡單聊天的 10 到 100 倍。當 Token 的消耗量指數級增長時,價格就成了決定性因素。中國模型的極致性價比,恰好踩中了這個窗口。
但問題是,推理成本的降低,並沒有解決訓練的根本問題。一個大模型如果不能在最新的數據上持續訓練、迭代,它的能力就會迅速退化。而訓練,依然是那個繞不開的算力黑洞。
那麼,訓練的「鏟子」,從哪裡來?
備胎的轉正
江蘇興化,蘇中小城,以不鏽鋼和健康食品聞名,此前和 AI 沒有任何關係。但 2025 年,一條 148 米長的國產算力伺服器產線在這裡建成投產,從簽約到投產,只用了 180 天。
這條產線的核心,是兩顆完全國產的晶片:龍芯 3C6000 處理器和太初元碁 T100 AI 加速卡。龍芯 3C6000,從指令集到微架構全部自主研發。太初元碁脫胎於國家超級計算無錫中心和清華大學團隊,採用異構眾核架構。
當這條生產線滿產時,每 5 分鐘下線一台伺服器,這條生產線總投資 11 億元,預計年產 10 萬台。
更重要的是,由這些國產晶片組成的萬卡叢集,已開始承擔真正的大型模型訓練任務。
2026 年 1 月,智譜 AI 聯合華為發布了 GLM-Image,這是首個完全依託國產晶片實現全程訓練的 SOTA 圖像生成模型。2 月,中國電信的千億級「星辰」大模型,在上海瀘港的國產萬卡算力池上完成了全流程訓練。

這些案例的意義在於,它們證明了一件事:國產晶片,已經從「能用於推理」跨越到了「能用於訓練」。這是質變。推理只需要運行已訓練好的模型,對晶片的要求相對較低;而訓練需要處理海量數據、進行複雜的梯度計算和參數更新,對晶片的算力、互聯頻寬和軟體生態的要求,高出一個數量級。
承擔這些任務的核心力量,是華為的昇騰系列晶片。截至 2025 年底,昇騰生態的開發者數量已突破 400 萬,合作夥伴超過 3000 家,43 個業界主流大模型基於昇騰完成了預訓練,200 多個開源模型完成了適配。2026 年 3 月 2 日的 MWC 大會上,華為還面向海內外市場首發了新一代算力底座 SuperPoD。
昇騰 910B 的 FP16 計算能力已與英偉達 A100 對標。雖然差距依然存在,但已從不可用變為可用,並正從可用走向好用。生態的建設,不能等到晶片完美了再開始,必須在夠用的階段就大規模鋪開,用真實的業務需求去倒逼晶片和軟體的迭代。字節跳動、騰訊、百度對國產算力伺服器的導入目標,2026 年普遍較上一年翻倍增長。工信部的數據顯示,中國智算規模已達 1590 EFLOPS。2026 年,正在成為國產算力規模部署的元年。
美國電荒與中國出海
在 2026 年初,承載全球大量數據中心流量的維吉尼亞州,暫停批准新的數據中心建設項目。喬治亞州跟進,審批暫停延續至 2027 年。伊利諾伊州、密歇根州也相繼出台限制措施。
根據國際能源署的數據,2024 年美國數據中心耗電量已達 183 太瓦時,約佔全國總用電量的 4%。到 2030 年,這個數字預計翻倍至 426TWh,佔比可能突破 12%。Arm 公司 CEO 更是預測,到 2030 年,AI 數據中心將消耗美國 20% 到 25% 的電力。
美國的電網已經不堪重負。覆蓋美國東部 13 個州的 PJM 電網面臨 6GW 的容量短缺。到 2033 年,美國整體面臨 175GW 的電力容量缺口,相當於 1.3 億戶家庭的用電量。數據中心集中區域的批發電力成本,比五年前高出 267%。
算力的盡頭,是能源。而在能源這個維度上,中美之間的差距,比晶片還要大,只不過方向反了過來。
中國的年發電量是 10.4 萬億度,美國是 4.2 萬億度,中國是美國的 2.5 倍。更關鍵的是,中國的居民生活用電僅佔總用電量的 15%,而美國這個比例是 36%。這意味著中國有遠比美國更大的工業用電餘量可以投入算力建設。
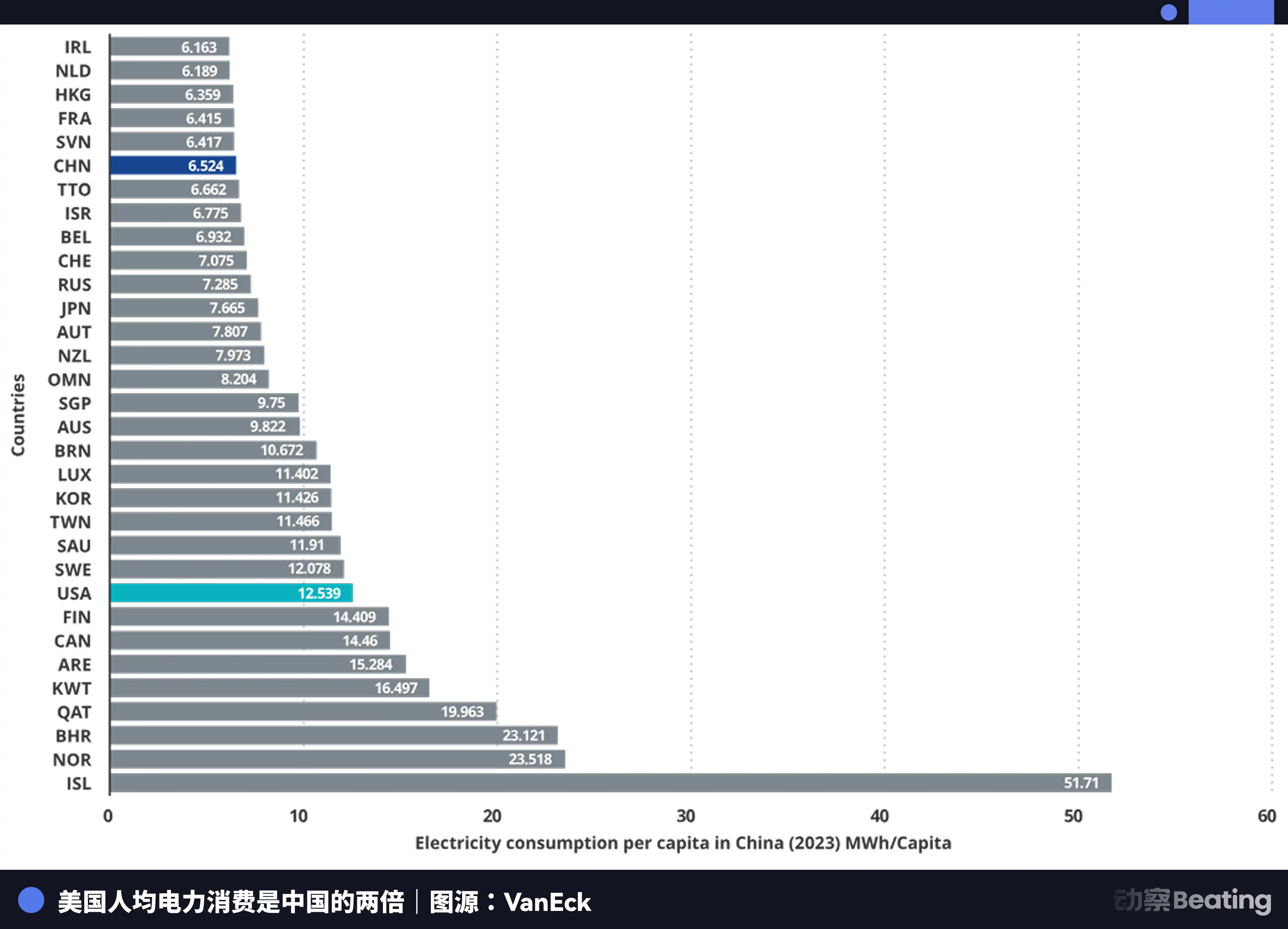
在電價上,美國 AI 公司聚集區的電價為 0.12 到 0.15 美元每千瓦時,而中國西部的工業電價約為 0.03 美元,僅為美國的四分之一到五分之一。
中國的發電增量,已達到美國的 7 倍。
就在美國為電發愁的時候,中國的 AI 正在悄悄出海。但这一次出海的,不是產品,不是工廠,而是 Token。
Token,AI 模型處理資訊的最小單位,正在成為一種新的數位商品。它從中國的算力工廠裡被生產出來,通過海底光纜輸送到全球。
DeepSeek 的用戶分佈數據頗具說明性:中國本土佔 30.7%,印度 13.6%,印尼 6.9%,美國 4.3%,法國 3.2%。它支援 37 種語言,在巴西等新興市場廣受歡迎。全球有 26,000 家企業開通了帳戶,3,200 家機構部署了企業版。
2025 年,58% 的新 AI 創業公司將 DeepSeek 納入了技術棧。在中國,DeepSeek 拿下了 89% 的市場份額。而在其他受制裁國家,市場份額則在 40%~60% 不等。
This scene resembles another war over industrial autonomy forty years ago.
1986 年的東京,在美國的強大壓力下,日本政府簽訂了《美日半導體協議》。協議的核心條款有三條:要求日本開放半導體市場,美國晶片在日本的市場份額須達到 20% 以上;嚴禁日本半導體以低於成本價格出口;對日本出口的 3 億美元晶片徵收 100% 懲罰性關稅。同時,美國否決了富士通對仙童半導體的收購。
那一年,日本半導體產業正處在巔峰。1988 年,日本控制了全球半導體市場 51% 的份額,美國只有 36.8%。全球十大半導體公司,日本獨占六席:NEC 排名第二,東芝第三,日立第五,富士通第七,三菱第八,松下第九。1985 年,Intel 在美日半導體爭奪戰中虧損 1.73 億美元,瀕臨破產。
但協議簽訂後,一切都變了。
美國透過 301 調查等手段,對日本半導體企業發起了全方位的壓制。同時扶持韓國的三星、海力士,以更低的價格衝擊日本的市場。日本的 DRAM 市場份額從 80% 跌至 10%。到 2017 年,日本 IC 市場份額僅剩 7%。曾經不可一世的巨頭們,或被拆分,或被收購,或在無休止的虧損中黯然離場。
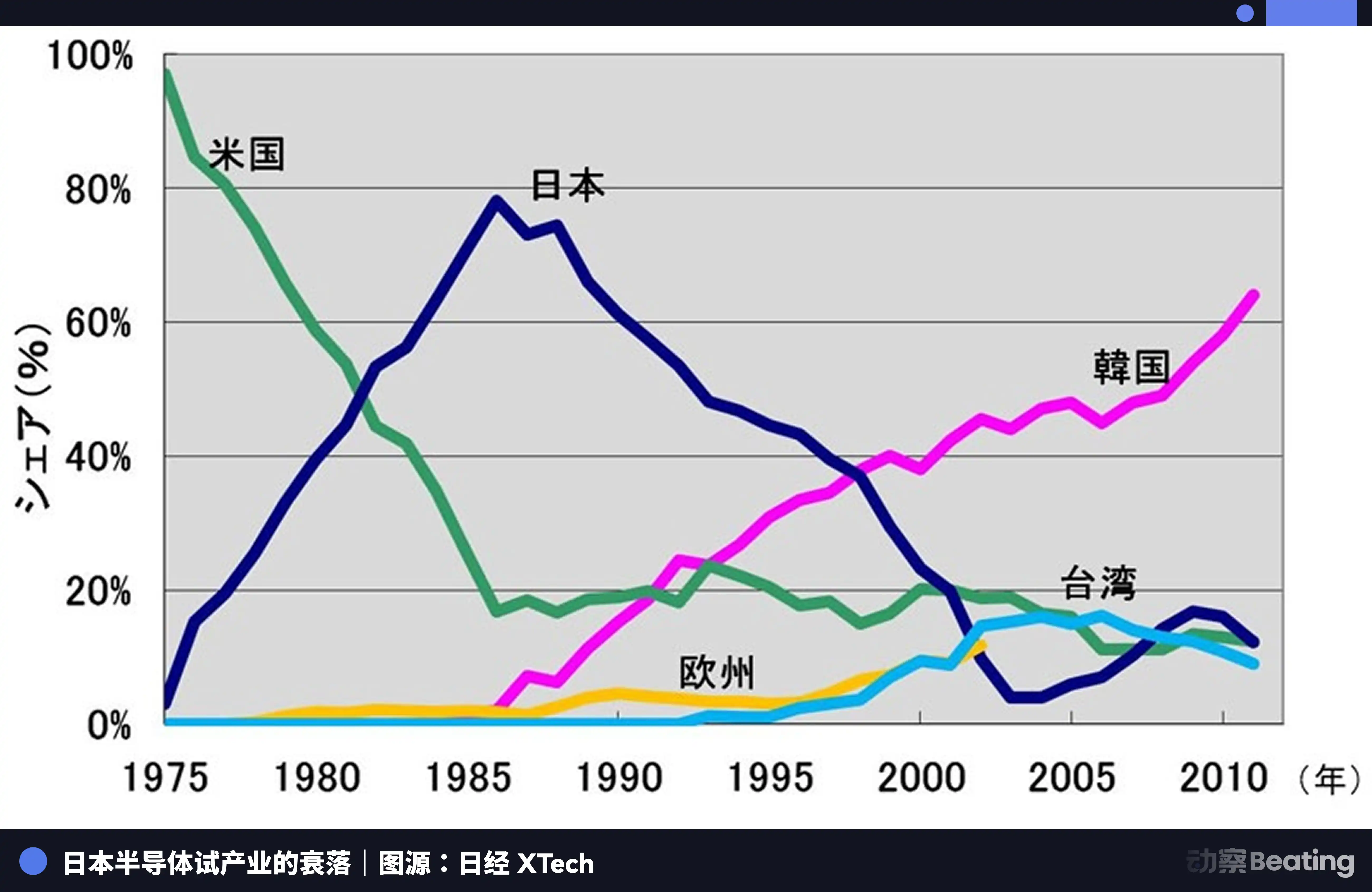
日本半導體的悲劇在於,它滿足於在一個由單一外部力量主導的全球分工體系中,做那個最優秀的生產者,卻從未想過去構建一個屬於自己的、獨立的生態。當潮水退去,它才發現,自己除了生產本身,一無所有。
今天的中國 AI 產業,正站在一個相似卻又完全不同的路口。
相似的是,我們同樣面臨著來自外部的巨大壓力。三輪晶片管制,層層加碼,CUDA 生態的壁壘依然高聳。
不同的是,这一次,我們選擇了一條更難的路。從算法層面的極致優化,到國產晶片從推理到訓練的跨越,再到昇騰生態 400 萬開發者的積累,再到 Token 出海對全球市場的滲透。這條路上的每一步,都在構建一種日本當年從未擁有過的獨立產業生態。
尾聲
2026 年 2 月 27 日,三份來自本土 AI 芯片公司的業績快報,在同一天發布。
寒武紀,營收暴增 453%,首次實現全年盈利。摩爾線程,營收增長 243%,但淨虧損 10 億。沐曦,營收增長 121%,淨虧損近 8 億。
一半是火焰,一半是海水。
火焰,是市場的極度饑渴。黃仁勳讓出的那 95% 的空白,正在被這些本土公司的營收數字,一寸一寸地填滿。無論性能如何,無論生態怎樣,市場需要英偉達之外的第二個選擇。這是地緣政治撕開的、一個千載難逢的結構性機會。
海水,是生態建設的巨大成本。每一分虧損,都是為追趕 CUDA 生態而付出的真金白銀。是研發的投入,是軟體的補貼,是派駐到客戶現場、一個一個解決編譯問題的工程師的人力成本。這些虧損,不是經營不善,而是構建一個獨立生態所必須支付的戰爭稅。
這三份財報,比任何一份行業報告都更誠實地記錄了這場算力戰爭的真實面貌。它不是一場高歌猛進的勝利,而是一場慘烈的、一邊流血一邊衝鋒的陣地戰。
但戰爭的形態,確實已經變了。八年前,我們討論的是「能不能活下來」的問題。今天,我們討論的是「活下來要付出多大代價」的問題。
The cost itself is progress.
歡迎加入律動 BlockBeats 官方社群:
Telegram 訂閱群:https://t.me/theblockbeats
Telegram 交流群:https://t.me/BlockBeats_App
Twitter 官方帳號:https://twitter.com/BlockBeatsAsia