










原文作者:KarenZ,Foresight News
2026 年 3 月 20 日,在 All-In 創投播客中有一段不尋常的對話。
風投大佬 Chamath Palihapitiya 將話題交給了英偉達 CEO 黃仁勳,表示 Bittensor 上有一個項目「完成了一項相當瘋狂的技術成就」,利用分散式算力在互聯網上訓練了一個大型語言模型,整個過程完全去中心化,未有任何中心化數據中心參與。
黃仁勳沒有迴避。他將此事比作「Folding@home 的現代版本」,那個在 2000 年代讓普通用戶貢獻閒置算力、共同對抗蛋白質折疊難題的分散式項目。
在這之前的 4 天前,3 月 16 日,Anthropic 联合創始人 Jack Clark 在發布一期 AI 研究進展報告中,也用大量篇幅重點介紹和引用這項突破:Bittensor 生態子網 Templar(SN3)完成 720 億參數大模型(Covenant 72B)的分散式訓練,模型性能與 Meta 2023 年發布的 LLaMA-2 相當。
Jack Clark 將本章命名為「Challenging the Political Economy of AI Through Distributed Training」,並在分析中強調,這是一項值得持續追蹤的技術——他能想像一個未來:裝置端 AI 大量採用去中心化訓練產生的模型,而雲端 AI 則繼續運行專有大模型。
市場的反應稍有滯後但極為劇烈:SN3 過去一個月上漲超過 440%,過去兩週上漲超過 340%,市值達 1.3 億美元。子網的敘事爆發,將直接轉化為對 TAO 的購買壓力。因此,TAO 快速上漲,一度達到 377 美元,過去一個月翻倍,FDV 達到約 75 億美元。
問題來了:SN3 到底做了什麼?為何會被推至聚光燈下?分散式訓練和去中心化 AI 的價值敘事又將如何演變?
那個 72B 的模型
要回答這個問題,得先看清楚 SN3 交出的成績單。
2026 年 3 月 10 日,Covenant AI 團隊在 arXiv 上發布了一篇技術報告,正式宣告 Covenant-72B 完成訓練。這是一個 720 億參數的大型語言模型,在約 1.1 兆 tokens 的語料上完成了預訓練,跨越 70 個獨立節點 peers(每輪約 20 個節點同步,每個節點配備 8 張 B200)。
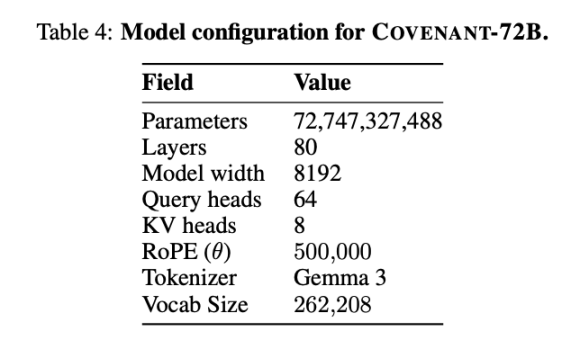
Templar 提供了一些基準測試的數據,當然,對比的 LLaMA-2-70B 是 Meta 於 2023 年發布的大模型。正如 Anthropic 聯合創始人 Jack Clark 所說,Covenant-72B 放在 2026 年可能有些過時了。Covenant-72B 在 MMLU 上的 67.1 分,大致對標的是 Meta 2023 年發布的 LLaMA-2-70B(65.6 分)。
而 2026 年的前沿模型——無論是 GPT 系列、Claude 還是 Gemini——早已在數十萬塊 GPU 上完成了參數量遠超 1000 億的訓練,推理、代碼、數學能力的差距是數量級而非百分比的問題。這個現實差距不應該被市場情緒淹沒。
但換算到「使用開放互聯網上的分散式算力訓練出來」這個前提下,意義就完全不同了。
做個比較:同樣採用去中心化訓練的 INTELLECT-1(由 Prime Intellect 團隊開發,100 億參數)MMLU 得分為 32.7;另一個在白名單參與者中進行的分散式訓練項目 Psyche Consilience(400 億參數)得分为 24.2。Covenant-72B 以 72B 的規模、67.1 的 MMLU 分數,在去中心化訓練賽道中是一個顯眼的數字。
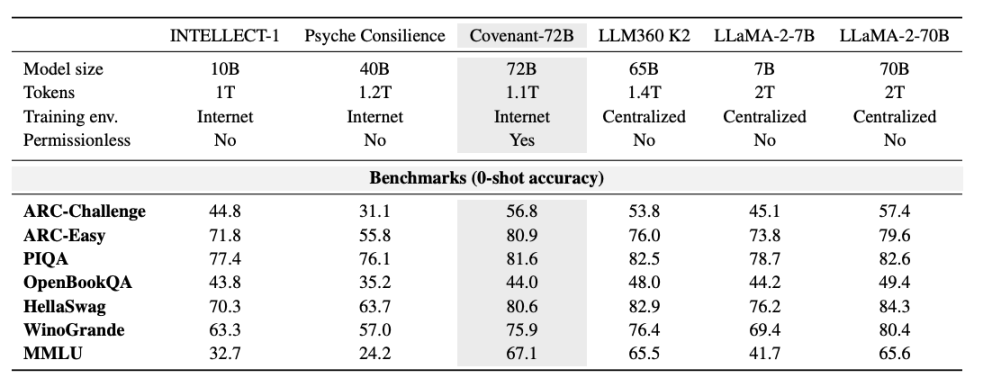
更重要的是,這次訓練是「無需許可」的。任何人都可以接入並成為參與節點,無需事先審核或列入白名單。超過 70 個獨立節點參與了模型更新,從全球各地連接並貢獻算力。
黃仁勳說了什麼,沒說什麼
還原那場播客對話的細節,有助於校正外界對這次「背書」的解讀。
Chamath Palihapitiya 在對話中向黃仁勳展示 Bittensor 的技術成就,並描述為使用分散式算力訓練了一個 Llama 模型,過程「完全分散,同時保持狀態」。黃仁勳回應將此比作「現代版的 Folding@home」,並深入討論了開源與專有模型並行共存的必要性。
值得注意的是,黃仁勳並未直接提及 Bittensor 的代幣或任何投資含義,也未進一步討論去中心化 AI 訓練。
了解 Bittensor 子網和 SN3
要理解 SN3 的突破,首先需明確 Bittensor 及其子網的運作邏輯。簡單來說,Bittensor 可看作是一條 AI 公鏈和平台,而每個子網就相當於一條獨立的「AI 生產流水線」,各自明確核心任務、設計激勵機制,協同構成去中心化 AI 生態。
其運作流程清晰且去中心化:子網所有者定義子網目標並編寫激勵模型;礦工在子網中提供算力、完成 AI 相關任務(如推理、訓練、存儲等);驗證者對礦工的貢獻進行打分,並將評分上傳至 Bittensor 共識層;最終,Bittensor 的 Yuma 共識算法會根據各子網累積的獎勵,向子網參與者分配相應收益。
目前 Bittensor 上有 128 個子網,覆蓋推理、無伺服器 AI 雲服務、圖像、數據標註、強化學習、存儲、計算等各類 AI 任務。
而 SN3 正是其中一個子網。它不進行應用層封裝,也不租用現成的大模型 API,而是直接針對 AI 產業鏈中最昂貴、最封閉的核心環節之一:大模型預訓練本身。
SN3 希望利用 Bittensor 網絡協調異構計算資源的分佈式訓練,透過激勵式分佈式大模型訓練,證明無需昂貴的中心化超級電腦叢集,同樣可以訓練出強大的基礎模型。核心吸引力在於「平權」——打破中心化訓練的資源壟斷,讓普通個體或中小機構也能參與大模型訓練,同時藉助分佈式算力降低訓練成本。
推動 SN3 發展的核心力量是 Templar,其背後的研究團隊為 Covenant Labs。該團隊同時運營另外兩個子網:Basilica(SN39,專注計算服務)和 Grail(SN81,專注 RL 後訓練與模型評估)。三個子網形成垂直整合,完整覆蓋大模型從預訓練到對齊優化的全流程,構建起去中心化大模型訓練的完整生態。
具體而言,礦工貢獻計算資源,將梯度更新(模型參數的調整方向和力度)上傳至網絡;驗證者評估每位礦工的貢獻質量,根據誤差改善幅度給予鏈上評分。結果決定獎勵權重,自動分配,無需信任任何第三方。
激勵機制設計的關鍵在於,獎勵直接與「你的貢獻讓模型變好多少」掛鉤,而非單純的算力出勤。這從根本上解決了去中心化場景中最難的問題:如何防止礦工摸魚。
那 Covenant-72B 如何解決通信效率和激勵相容問題?
讓數十個彼此不信任、硬體各異、網路品質參差不齊的節點協同訓練同一個模型,面臨兩個挑戰:一是通信效率,標準的分散式訓練方案要求節點之間具備高頻寬、低延遲的連接;二是激勵相容,如何防止惡意節點提交錯誤的梯度?如何確保每位參與者都在誠實訓練,而非抄襲他人的成果?
SN3 使用兩個核心組件解決了這兩個問題:SparseLoCo 和 Gauntlet。
SparseLoCo 解決通信效率問題。傳統的分散式訓練每一步都需要同步完整梯度,數據量龐大。SparseLoCo 採用的方案是:每個節點在本地完成 30 步內部優化(AdamW),然後將產生的「偽梯度」壓縮後上傳給其他節點。壓縮方式包括 Top-k 稀疏化(僅保留最關鍵的梯度分量)、誤差反饋(將被丟棄的部分儲存並累積至下一輪),以及 2 位量化。最終壓縮比超過 146 倍。
In other words, what previously required transmitting 100 MB now requires less than 1 MB.
這使得系統在普通互聯網(上行 110 Mbps,下行 500 Mbps)的頻寬限制下,將計算利用率維持在約 94.5%——20 個節點、每個節點 8 塊 B200、每輪通信僅耗時 70 秒。
Gauntlet 解決激勵相容問題。它運行在 Bittensor 區塊鏈(Subnet 3)上,負責驗證每個節點提交的偽梯度質量。具體方式是:用一小批數據測試「使用該節點的梯度後,模型損失降低了多多少」,結果稱為 LossScore。同時,系統還檢查節點是否使用其分配到的數據進行訓練——如果一個節點在隨機數據上的損失改善比在其分配數據上更好,將被扣分。
最終,每輪訓練僅選取評分最高的節點的梯度參與聚合,其餘節點被淘汰出該輪。超出的參與者會隨時補位,以保持系統穩健。整個訓練過程中,平均每輪有 16.9 個節點的梯度被納入聚合,累計參與過的唯一節點 ID 超過 70 個。
去中心化 AI 的價值敘事,正在發生根本性轉變
從技術和行業視角看這件事,Covenant-72B 代表的方向有幾個真實的意義。
First, it breaks the assumption that "distributed training is only suitable for small models." Although it still lags far behind state-of-the-art models, it demonstrates the scalability of this approach.
第二,無許可參與是真實可行的。這一點被低估了。此前的分散式訓練項目依賴白名單——只有經過審核的參與者才能貢獻算力。SN3 這次訓練中,任何擁有足夠算力的人都可以接入,驗證機制負責過濾惡意貢獻。這是向「真正去中心化」邁出的具體一步。
第三,Bittensor 的 dTAO 機制讓子網價值的市場發現成為可能。dTAO 允許每個子網發行自己的 Alpha 代幣,透過 AMM 機制讓市場來決定哪些子網獲得更多的 TAO 排放。這為像 SN3 這樣產出了具體成果的子網提供了一套粗糙但有效的價值捕獲機制。當然,這套機制同樣容易被敘事和情緒干擾,LLM 訓練成果的質量很難被普通市場參與者獨立評估。
第四,去中心化 AI 訓練的政治經濟含義。Jack Clark 在 Import AI 中將此問題提升至「誰擁有 AI 的未來」這一層面。當前前沿模型的訓練被少數擁有大規模數據中心的機構壟斷,這不僅是商業問題,更是權力結構問題。若分布式訓練能持續取得技術進展,有可能在某些模型類型(如特定領域的小規模前沿模型)上形成真正去中心化的開發生態。當然,這一前景目前仍很遙遠。
小結:一個真實的里程碑,以及一堆真實的問題
黃仁勳表示,這就像「現代版的 Folding@home」。Folding@home 在分子模擬領域做出了實際貢獻,但並未威脅到大型製藥公司的核心研發地位。這個類比非常準確。
SN3 已成功運行協議,驗證了分佈式訓練的可行方向。但從技術和行業的視角來看,這份成績單背後,仍存在一堆鮮少有人願意認真討論的問題:
MMLU 本身在學界也是一個充滿爭議的指標,公開基準的題目與答案存在洩露至訓練集的風險。更值得關注的是比較基線的選擇:論文所對標的 LLaMA-2-70B 與 LLM360 K2 均為 2023 至 2024 年的舊模型,而同一區間的 65 至 70 分,在問及 Grok、豆包時均被歸為中下游與入門級水平,在 Claude 看來則屬嚴重落後。若將其置於動態更新的榜單或具備抗污染設計的新一代基準之上,結論或許會更加誠實。
更重要的是,決定模型能力上限的高品質數據——對話數據、代碼、數學推導、科學文獻——極有可能掌握在各大公司、出版機構和學術數據庫手中。算力已民主化,但數據端仍維持寡頭結構,這一矛盾從未被討論過。
關於安全性,無許可參與意味著你不知道那 70 多個節點背後是誰,也不知道他們使用什麼數據進行訓練。Gauntlet 能過濾明顯異常的梯度,但無法防範微妙的數據投毒——如果一個節點系統性地在某類有害內容方向多訓練幾輪,產生的梯度變化足夠細微,能通過損失評分篩查,但對模型行為產生累積偏移。最終的問題是:在金融、醫療、法律這類高合規、安全要求的場景,使用一個由少數匿名節點參與訓練、數據來源追溯不完整的模型,會帶來怎樣的隱患?
還有一個結構性問題值得直言:Covenant-72B 本身以 Apache 2.0 許可證開源,不使用 SN3 代幣。持有 SN3 代幣,分享的是這個子網未來持續產出新模型所帶來的排放收益,而非模型被使用時的任何直接收益。這個價值鏈,依賴於持續的訓練產出,以及 Bittensor 整體網絡排放機制的健康運轉。如果未來訓練停滯,或新的訓練成果質量未達預期,代幣的估值邏輯就會動搖。
列出這些問題,並非為了否定 Covenant-72B 的意義。它證明了以前被認為不可能的事情是可以做到的,這個事實不會消失。但做到了,和它意味著什麼,是兩件不同的事情。
SN3 代幣過去一個月上漲 440%。這中間的距離,可能並非單純的炒作,而是敘事的速度總是快於現實的速度。至於這段距離最終會被現實填補,還是被市場修正消化,取決於 Covenant AI 團隊接下來真正交出什麼。
值得注意的是,Grayscale 已於 2026 年 1 月提交 TAO ETF 申請,顯示機構資本對此賽道的進場信號。此外,2025 年 12 月 Bittensor 將 TAO 日發行量減半,供給端的結構性收緊仍在持續。
參考連結:
https://arxiv.org/pdf/2603.08163
https://importai.substack.com/p/importai-449-llms-training-other
https://docs.tplr.ai/
https://systems-analysis.ru/int/MMLU_Benchmark_%E2%80%94_MMLU_%E5%9F%BA%E5%87%86%E6%B5%8B%E8%AF%95