









仿生人會做夢嗎?如果他們做夢的話,會夢見電子羊嗎?

電影《銀翼殺手》截圖
1968 年,科幻電影《銀翼殺手》的原著小說作者菲利普·K·迪克,在打字機前敲下這個抽象又超前的問題時,他大概不會想到,半個多世紀後,矽谷的科技巨頭們會一臉嚴肅地給出答案。
Yes, they can not only dream of electronic sheep, but also visualize their dreams.
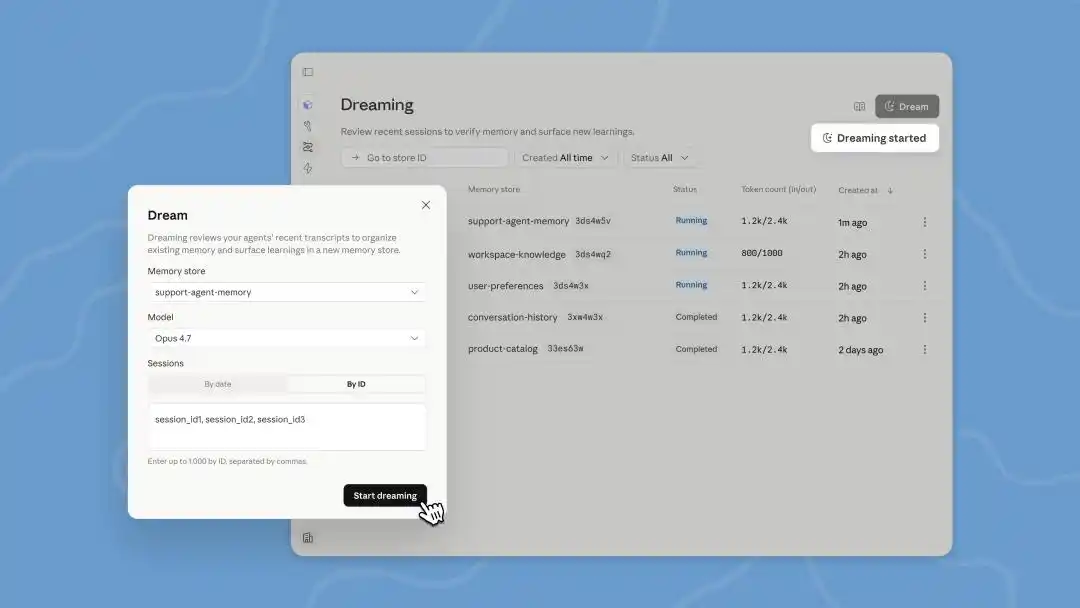
昨天,Anthropic 在舊金山的開發者大會上,發布了智能體構建平台 Managed Agents 的一系列新功能,包括記憶擴展、結果輸出、多智能體協作,以及「夢想 Dreaming」。
按 Anthropic 自己的說法,「memory(記憶)和 dreaming(做夢)共同構成了一個穩健的、能夠自我改進的 agent 記憶系統」。

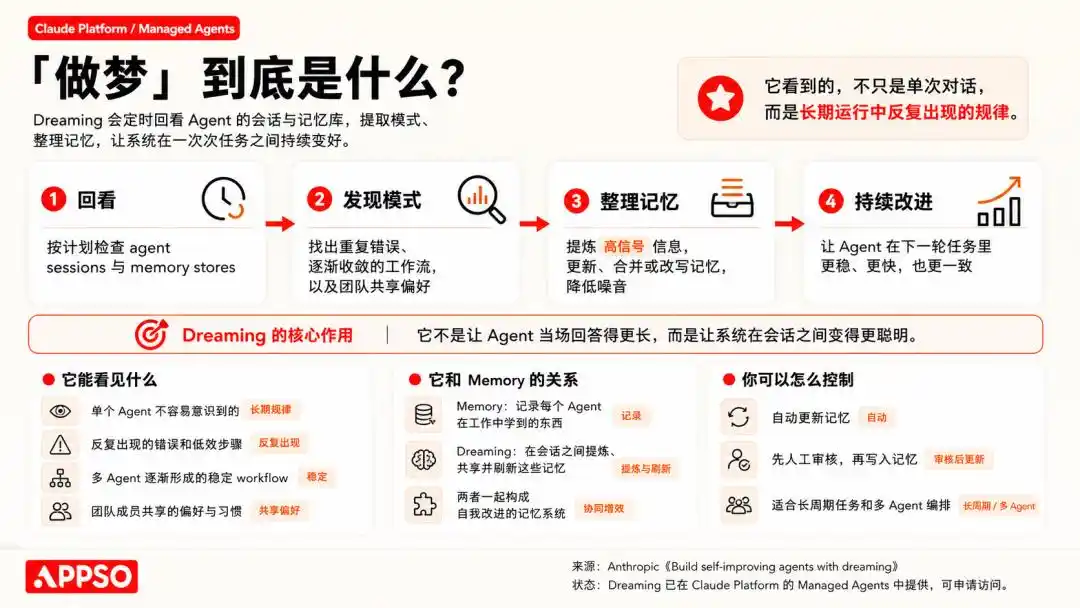
又是夢境,又是記憶,對 AI 領域不太關注的朋友,大概都會滿頭問號,這些屬於人類的詞語,什麼時候開始可以如此絲滑地套用在 AI 身上了。
早在 2024 年 OpenAI 推出 o1 系列時,「一系列被設計成在回應前花更多時間思考的 AI 模型」,「思考」二字用得極其自然,自然到沒人停下來追問一句,一個統計預測下一個 token 的程序,憑什麼叫思考?
接著是 reasoning(推理)、memory(記憶)、reflection(反思)、Imagining(想像),一個一個把只有人類才會做的事情,搬到產品發布會上。

探討夢的電影《紅辣椒》截圖
「思考」還能被解釋為隱喻,「記憶」也勉強算技術行話的延伸,但「做夢」就真的有點過了。文史哲幾千年都沒研究清楚,AI 公司卻能直接說:我們不僅做出了能思考的機器,我們還做出了會做夢的機器。
什麼是做夢,除了做夢,還找不到任何一個能精確描述這件事的工程術語嗎?
AI 做夢也要花錢
在 Claude Code 代碼洩露事件中,就有網友發現 Anthropic 正在準備一項名為 Auto Dreaming 的功能。當時,大家都在想,難道 AI 也和我們人類一樣,需要睡覺,得到足夠的休息,才能變得注意力更集中、更聰明嗎?
但只要了解目前 AI Agent 的工作原理,就會發現所謂的「做夢」,本質上只是一次自動化的離線日誌批處理。
AI Agent 現在擅長完成一些長鏈路的複雜任務,例如「幫我調研一下這五家競爭對手的最新財報,並整理成表格」。在這個過程中,Agent 需要在不同網頁間切換,讀取多個文件,調用多種工具,甚至可能因遇到反爬蟲機制而受阻並重試。
當這一長串繁雜的在線任務結束後,Agent 的後台會留下海量的運行日誌。
圖片由 AI 生成
Anthropic 的「做夢」功能,讓 Agent 在閒置時間重新梳理這些歷史記錄,從中尋找模式,例如發現「每次遇到這種彈窗,點擊右上角即可關閉」,從而優化下一次的操作路徑。
「記憶」負責在工作時捕獲學到的東西,而「做夢」則在會話之間提煉這些記憶,並在不同的 Agent 之間共享。
簡而言之,這是一種基於歷史數據的強化學習和自我糾錯機制。

夢的介紹:https://platform.claude.com/docs/en/managed-agents/dreams
在這次開發者大會上,更新了 Managed Agents 中的 Dreams,這是一個後台處理任務,我們需要手動觸發。Claude 一次最多可讀取 100 個 session 的對話歷史,然後生成一份全新的 memory,供我們審查後決定是否使用。
而之前在 Claude Code 中已悄悄上線的 AutoDream,是在每次與 Agent 聊完一輪後,Claude Code 會在後台檢查「是否該做夢」,預設每 24 小時運行一次。
類似夢境的功能,Hermes Agent 也有。Hermes Agent 的核心在於能夠自我學習與進化,它不僅支援自動從過往任務中總結經驗,並存入記憶檔案中。

其中一項稱為 Curator 的功能,還能將這些提煉出來的操作指南自動整理成 Skill。
這些 Skill 會被評分、重複的會被合併、長期未使用的會自動歸檔,甚至還有 active、stale、archived 這樣的生命周期。我們還可以將重要的 Skill 固定,防止系統自動清除。
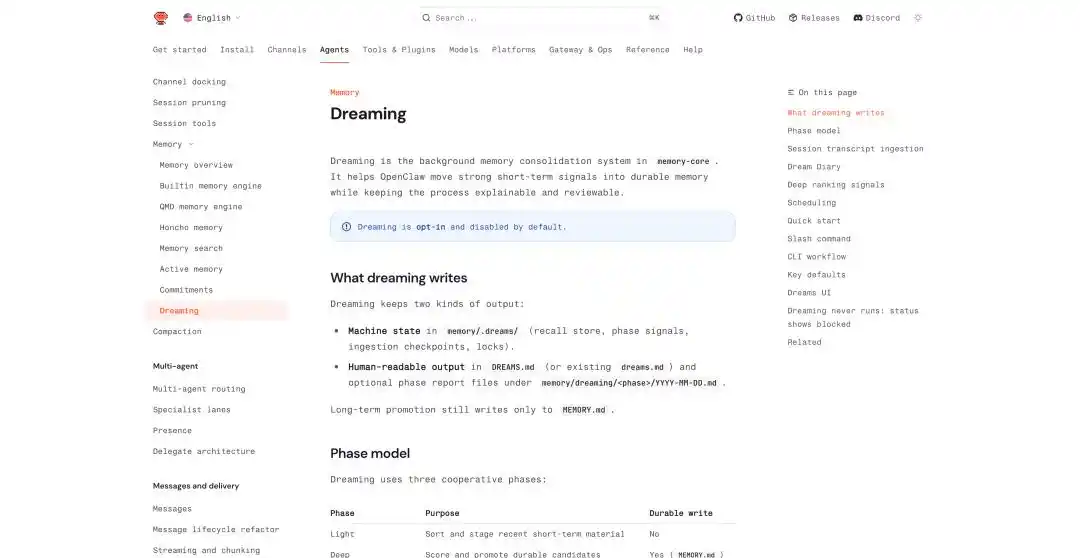
OpenClaw 在最近的幾次更新裡,也添加了相關的機制,像是跨對話的持久記憶、定時的任務調度、子 Agent 隔離執行,以及直接叫 Dreaming 的做夢功能。
OpenClaw 的夢想:https://docs.openclaw.ai/concepts/dreaming
在 OpenClaw 的夢境機制中,它將夢境的過程概括為三個階段:light、REM、deep。前兩個階段負責整理、反思與主題歸納,而 deep 才真正將內容寫入長期記憶 MEMORY.md。
而深度睡眠階段的鞏固,會由 6 個加權信號決定是否需要寫入長期記憶。這六個信號包括頻率、相關性、查詢多樣性、時效性、跨天重複度、概念豐富度。

圖片由 AI 生成
寫入長期記憶會生成兩份文件:一份為機器用的狀態文件,存放於 memory/.dreams/;另一份為用戶可讀的記錄,寫入 DREAMS.md 及按階段生成的報告。
此外,Dreaming 可自動定時運行,預設每天凌晨 3 點執行一次完整流程,順序為 light → REM → deep。
除了夢境輸出外,OpenClaw 還維護一份名為 Dream Diary 的文件,系統會自動生成一份「夢境日記」,以敘事方式記錄記憶整理過程,強調可解釋性與可審查性,而非黑箱式資料庫。
在神經科學中,有一個非常經典的理解:人類白天獲取的資訊,會先進入偏向臨時存儲的系統;而在睡眠過程中,大腦會對這些資訊進行重放、鞏固和清理,將重要的留下,將無意義的丟棄。
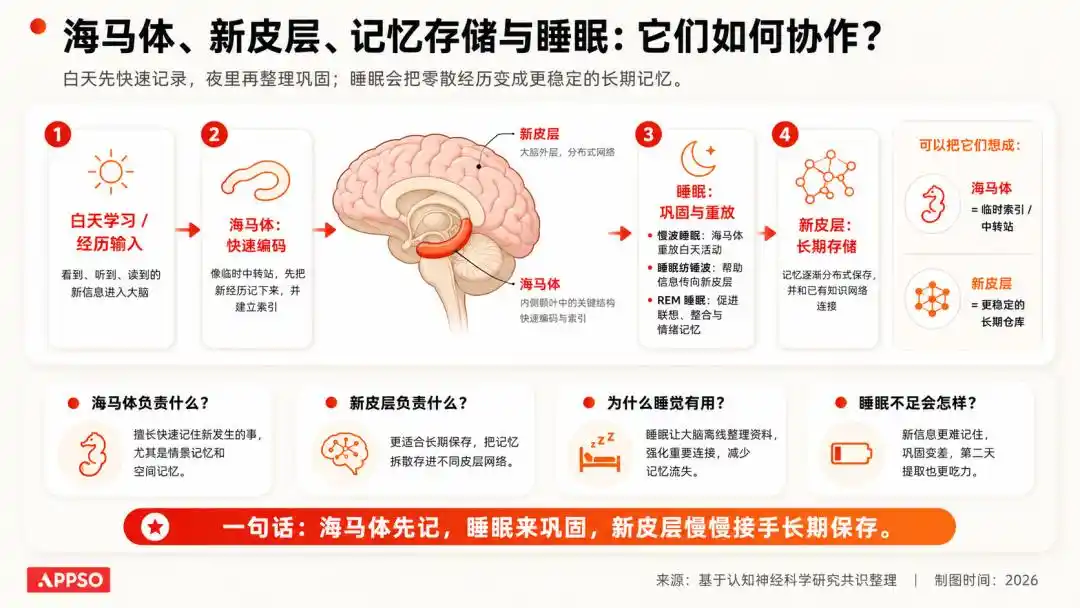
圖片由 AI 生成
我們不會記得昨天上班路上每一輛車的顏色,但會記得怎麼去公司。
這些夢,聽起來確實和我們人做夢一樣,若非要找點不同,大概就是 Claude 做夢的時候,仍在消耗我們的 Token。
但 Anthropic 和 OpenClaw 都沒有選擇稱之為「基於會話的優化(session-based optimization)」或「任務後調優(post-task tuning)」等偏向工程方面的名稱。
畢竟,當把那些複雜的名字直接變成「做夢」,我們感受到的就不再是軟體功能,而像一個「有內心活動的數字生命」。
AI 的記憶,是瑣碎的上下文
既然提到「做夢」,就不得不提它的前置條件,記憶(Memory)。
過去一段時間,AI 圈最熱門的詞從提示詞工程,轉變為上下文工程、Skill 工程、Harness 工程,但無論如何變化,目前最有價值的仍是上下文工程。
系統提示、用戶輸入、短期對話、長期記憶、檢索回來的文檔、工具和 Skill 調用的輸出、當前用戶狀態,這些層疊加起來,就是 agent 真正在用的「上下文」。
讓 Agent 能記得更多,記下更有用的內容,一直是過去很長一段時間以來的難題。
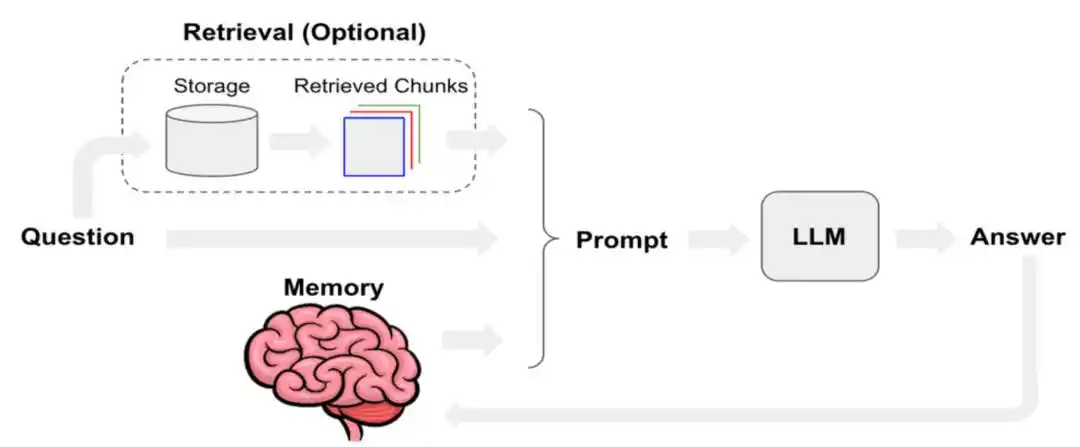
Manus 去年發表了一篇技術部落格,專門講述 Manus 如何優化上下文工程。文中提到,將 KV-Cache 缓存命中率定義為生產環境中 AI Agent 最重要的單一指標之一;同時在工具調用層面,優先採用「遮蔽」而非「移除」;以及將檔案系統作為最終上下文等方法。
要理解所謂的 KV Cache(鍵值緩存),我們可以把大模型想像成一個每次只能讀一個字的極度強迫症患者。
當它處理一句話時,會為每個生成的 Token 計算出一個 Key(鍵)和一個 Value(值)向量。為了避免每次都從頭重新計算,它會將這些 (K, V) 鍵值對儲存起來,這就是 KV Cache。
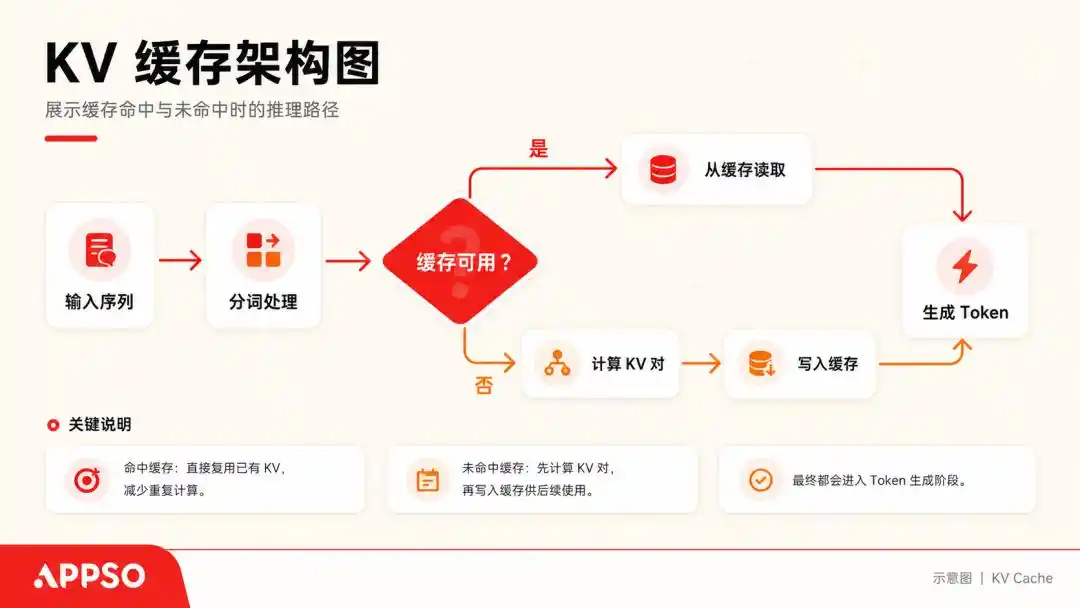
KV Cache(鍵值緩存)是大模型在生成文本時,用來「用空間換時間」的底層加速技術。緩存使得模型在預測下一個詞時,不需要把前面的所有詞重新計算一遍。圖片由 AI 生成。
只要對話持續進行,KV Cache 就會不斷儲存。一般情況下,當面對上下文長達 128k 的大型模型時,一個 70B 參數的模型在跑滿 128k 上下文時,僅 KV Cache 就能佔用 64 GB 的顯存。
這也是為什麼大多數模型的上下文視窗,目前最多都僅為百萬級別。
昨天,獲得 2900 萬美元種子輪融資的新公司 Subquadratic 在 X 發布 SubQ 新模型,主打更長上下文。

SubQ 宣稱可支援最高 1200 萬 token 上下文視窗,這是目前所有大模型中最大的上下文視窗。
雖然尚未有技術論文或模型說明文件,但介紹影片中提到,SubQ 的核心技術路線是從傳統 Transformer 的「稠密注意力」,轉向具有稀疏注意力的「次二次/線性擴展」架構。新架構有望解決上下文越長、算力成本越爆炸的問題。

所給的測試結果也相當激進,在 100 萬 token 下,速度提升超過 50 倍、成本降低超過 50 倍;在 1200 萬 token 時,算力需求較前沿模型可降低近 1000 倍。
而在 RULER 128K 長上下文基準上,Subquadratic 表示 SubQ 以 95% 準確率、8 美元成本,對比 Claude Opus 的 94% 準確率、約 2600 美元成本,成本降低約 300 倍。
要麼擴大上下文視窗,要麼讓模型學會做夢,自行丟棄一些內容。
這也是為什麼 Anthropic 等 Agent 產品現在必須推出 Dreaming。在上下文窗口受限的情況下,更聰明的 AI 不能只靠塞進更多內容,還需要有的放矢。
承認機器只是機器,比想像中難
Understanding the dreaming and memory mechanisms of AI may help us discern its relationship with human activities.
但把所有這些 AI 公司造出來用在機器上的詞放在一起,OpenAI 的 thinking 思考、行業通用的 memory 記憶和 hallucination 幻覺、Anthropic 這次的 dreaming 做夢,以及 Anthropic 那本憲法裡的美德和智慧。
我們可以看到,AI 公司遠不只是在銷售產品,它們正在重新分配「人」這個概念中的詞彙所有權。每挪用一個詞,機器與人的邊界就模糊一分。

語言會塑造預期,預期塑造容忍度,容忍度決定我們願意交給它多少東西。這是一條很長的鏈條,但起點就是發布會上那些無害的詞。
更隱蔽的一層影響是責任分配。當工具被描述為具有「思考」、「記憶」、「價值觀」的實體時,一旦出現問題,我們會自然地將其視為一個獨立的「行为主体」來追責,認為這個 AI 需要被「教育」、「調試」、「校準」。
真正應該被追問的,是將這個程序部署到我們工作流程中的那家公司,以及寫出「dreaming」這個詞的產品團隊。詞一換,坐在「被告席」上的人也換了。
而我們看著一台會「思考」、會「記憶」、現在還會「做夢」的機器,也開始下意識地相信裡面有什麼東西。因為承認這只是一台機器,那種「我正在跟一個會思考的存在對話」的體驗感就消散了,回歸到冷冰冰的工具關係。

白日夢功能介紹|圖片由 AI 生成
我已經想到了,Dreaming 做夢是處理過去的內容,接下來 AI 公司還會推出 Daydreaming,白日夢,用來預演未來。
所謂的白日夢或走神,是指 Agent 在活躍狀態下,利用一小部分閒置算力,結合當前進行的項目,同時進行探索性生成,為未來可能的任務做準備。
本文來自微信公眾號「APPSO」,作者:發現明日產品的 APPSO