









當普通人還在研究「最強提示詞咒語」時,矽谷頂級實驗室已將 AI 基礎設施運轉成生產線
文章作者、來源:新智元
你還在 ChatGPT 的聊天框裡反覆調 prompt?
最近,一位 X 用戶發了一條推文,開頭就是一聲驚呼:頭部大廠偷偷在用的 Claude Code 項目模板外洩!
這已經不是寫提示詞了。這是 AI 工程基礎設施。

整個打法圍繞一個文件「CLAUDE.md」展開,而它的核心原則只有三條:
每次 Claude 犯錯 → 你新增一條規則;每次你重複自己 → 你新增一個工作流程;每次出現 bug → 你新增一道防護措施。

This is done to solidify project experience into long-term context and automated constraints that are read each time the system starts.
整個架構,就像一家 AI 公司的崗位編制:CLAUDE.md 是入職手冊,skills/ 是工作 SOP,hooks/ 是合規部,docs/ 是公司章程,tools/ 是後勤組,src/ 才是真正出活的業務部門。

你不再是在和 AI 聊天,而是在建構一個了解你程式碼倉庫的 AI。
最瘋狂的部分是,你只需設定一次,Claude 就會自動審查程式碼,並根據指令重構、強制執行架構規則、撰寫發行說明、從技能中執行工作流程、記住過去的錯誤等。
而且它會越用越聰明。
大多數人都是打開 ChatGPT,撰寫提示詞,複製貼上,反覆進行;但在這套方法下,你只需打開終端,運行一個已交付的 skill 代碼即可。
這就像在自己的代碼庫中養了一隊 AI 同事。
這條推文背後,傳遞的是這個時代正在悄悄翻篇的一個小信號,大多數人可能還沒有反應過來。
一張不算洩露的「洩露截圖」撕開一個真相
@ai_rohitt 晾出的這張截圖,是 Anthropic 官方文件中公開推薦的 Claude Code 標準範式。
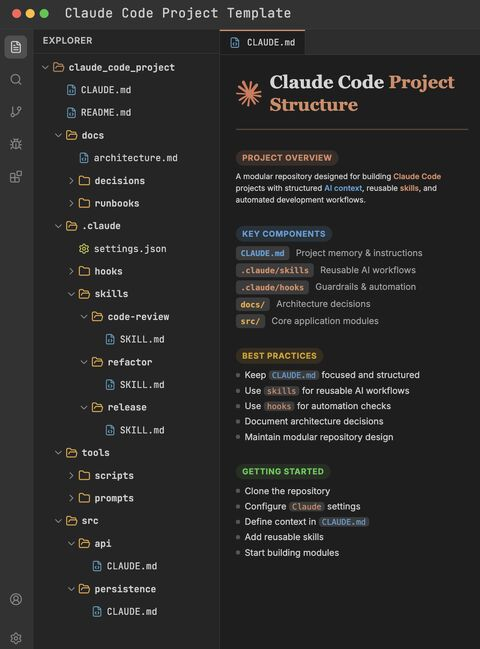
CLAUDE.md 是 Claude Code 在每次會話開始時自動讀取的專案記憶檔案。
.claude/skills/ 和 .claude/hooks/ 是官方支援的擴展機制。
這些都是社區已經討論了幾個月的公開做法,並不是什麼人偷出來的「內部模板」。
但它之所以能讓一些資深開發者主動轉發,說明它得到了一些天天使用 Claude 的開發者的認同。
當中相當一部分人,可能這兩天才意識到原來它還能這樣用。
而硅谷的頂尖團隊,已將這件事打造成一條生產線。
第一個例子,是 OpenAI Frontier 團隊。
在 OpenAI 官方披露的 Frontier 團隊實驗中,一個從空 repo 開始的內部 beta,在約 5 個月內由 Codex 生成了約 100 萬行程式碼和約 1500 個 PR;團隊從 3 人擴展至 7 人,人工不直接撰寫程式碼。
帶隊的 Ryan Lopopolo 在後續訪談中進一步提到,這套工作流程已接近「0 人工代碼、0 人工審核」的極限形態。
他認為,與其節省 token,不如利用模型極高的併發能力和極低的成本,來取代人類有限且昂貴的同步注意力。
第二個例子是 Stripe 內部的自動化代碼代理系統 Minions。
Stripe 內部的 Minions 每週生成並推動超過 1300 個 PR 合併,這些代碼完全由 AI 生成,但仍經過人工審查。
這裡還有一組數據:1.6% vs 98.4%,它來自 Mohamed bin Zayed AI 大學 VILA-Lab 發表的一篇論文。

https://arxiv.org/pdf/2604.14228
研究者系統性分析了 Claude Code v2.1.88 版本的 51.2 萬行程式碼,得出的結論是:僅有 1.6% 是 AI 決策邏輯,其餘 98.4% 為確定性的工程基礎設施。
具體來說,包括權限網關、上下文管理、工具路由和錯誤恢復這四類。
這組數字並非表示模型僅貢獻了 1.6% 的能力,而是說明作為產品的 Claude Code,其大量複雜性不在模型本身,而在權限、上下文、工具路由、恢復機制等確定性工程基礎設施上。
@ai_rohitt 圖中的 CLAUDE.md/skills/hooks 結構,普通開發者也能搭建一套「入門版基建」,它與 OpenAI、Stripe 的生產級架構屬於同一種範式,只是規模小得多。
CLAUDE.md 暴露的秘密
過去三年,所有人都在問「GPT 什麼時候能更聰明」「Claude 什麼時候出新版本」。
但真正能在生產環境中運行 AI 編程的團隊,他們更關心的可能根本不是這個,而是如何讓 AI 記住自己上次踩過的坑,怎麼讓 AI 在動手前先看一下項目的架構約束,怎麼讓 AI 犯錯的時候自己被工具擋住。
CLAUDE.md 正是這一切的承載體。
Anthropic 官方對它的定義只有一句:
一個 markdown 檔案,放在專案根目錄,Claude Code 會在每次會話開始時自動讀取。

https://code.claude.com/docs/en/memory
Sounds simple, but it's the several layers built around it that make it truly impressive.
CLAUDE.md 是項目大腦。
架構決策、命名約定、測試要求、那些反覆踩過的坑,都堆在這裡。它是 AI 每次啟動時第一眼看到的「員工手冊」。
.claude/skills/ 是可重複使用的工作流程。
Claude Code 的創建者 Boris Cherny 在社區中反覆強調一句話:「如果你每天做某件事超過一次,把它變成 skill 或 command。」
一個 skill 就是一段可執行的方法論。Code review、生成 commit message、寫發布說明,這些都不該是每天手動輸入提示詞的工作,而應該是調用一下 skill 就能出結果。
.claude/hooks/ 是自動護欄。
這是最重要的部分。它不依賴 AI 自行判斷,而是由確定性代碼在 AI 出錯前就將其擋下。這就是為何敢讓 AI「無人監督」地運行,因為出錯的邊界已被 hooks 把控住。
docs/decisions/ 是架構決策記錄。
讓 AI 不僅知道代碼「是什麼」,還知道代碼「為什麼是這樣」。
這項最易被忽略,卻也是 AI 協作最大的槓桿點。
tools/ 和 src/ 是執行層。
這套架構真正值得注意的地方,不在於某個開發者弄出了一個漂亮的目錄,而在於越來越多獨立團隊正逐漸趨向同一個方向:將模型放入一套由上下文、工具、權限、評估和反饋迴圈組成的 harness 中。
在 GitHub 上已經可以看到不少類似項目:
rohitg00 的 awesome-claude-code-toolkit、diet103 的 claude-code-infrastructure-showcase、affaan-m 的 everything-claude-code,均圍繞 agents、skills、hooks、rules、MCP configs 等組件搭建 Claude Code 的工程化工作環境。
This shows that a truly mature AI programming workflow is not just about relying on a more powerful model or a longer prompt, but about embedding the model into a reusable, controllable, recoverable, and auditable engineering system.
至於具體的目錄結構,各家實現並不完全相同。
OpenAI 實驗室的極限實驗
2026 年 2 月 11 日,OpenAI 官方博客發佈了一篇文章:《Harness engineering: leveraging Codex in an agent-first world》。

https://openai.com/index/harness-engineering/
Anthropic 重新調整了 Claude Code 的架構理念;Martin Fowler 的網站將其濃縮為一個公式:「Agent=Model+Harness。」
Harness 一詞源自馬術,指的是馬的全套挽具,包括繮繩、馬嚼子、馬鞍和籠頭。
一匹馬可以跑得很快很有力,但它自己不知道往哪兒走:整套挽具決定了它的方向。
類比到 AI 編程:模型本身能力很強,但它不知道在你的程式碼庫中該往哪兒走。Harness 就是你為它打造的方向盤 + 刹車 + 導航。
OpenAI Frontier 團隊那個「100 萬行 0 人工」的實驗,本質就是把 Harness 做到極致。
他們的關鍵工程實踐包括以下幾條。
層級架構強制約束。
從 Types 到 Config 到 Repo 到 Service 到 Runtime 到 UI,依賴關係單向流動,並由 linter 在 CI 層強制執行。Agent 寫出違反層級關係的代碼?直接構建失敗。
Linter 錯誤訊息本身即是修復指令,這也是最反直覺的細節。
一般項目的 lint 錯誤是「violation detected」,供人類查看;OpenAI Frontier 的 lint 錯誤是「use logger.info({event: 'name', …data}) instead of console.log」,供 Agent 查看,可直接理解並修復的指令。
文件作為單一事實來源。所有架構圖、execution plans、設計規範均位於倉庫內的 docs/ 目錄中。Agent 不需要任何外部知識庫,一切皆在 repo 內。
這套東西的效果有多強?
模型未更換,但 LangChain 調整了 harness,包括系統提示、工具、中間件和推理模式,最終將 Terminal Bench 2.0 分數從 52.8 提升至 66.5。
你今天就能做的事
為 AI 創建一個項目大腦
問題回到普通開發者這裡:如果範式已經轉移,作為一個普通工程師,今天就能做點什麼。
第一件事,在你最重要的項目根目錄建一個 CLAUDE.md。
不需要完美,也不需要很長。寫下你團隊的架構規則、命名約定、測試要求,那些反覆踩過的坑,10分鐘能寫完一個能用的版本。
下次 AI 犯錯的時候,先不要手動修,而是問自己一句:CLAUDE.md 裡缺了什麼?
第二件事,把每天重複做的事轉化為技能。
這裡要注意 Boris Cherny 的金句:「如果你每天做某件事超過一次,把它變成 skill 或 command。」
代碼審查、生成 commit message、撰寫發佈說明、修復一類重複的 bug,這些都應是技能,不該每天手動輸入提示詞。
第三件事,在容易踩坑的地方加上一個 hook。
Hook 是 98.4% 中最具槓桿的那部分。它不依賴 AI 變聰明,而是依賴確定性代碼進行強制檢查。這是將人類工程師的判斷力翻譯成機器可讀約束的過程。
這件事的核心不在於寫代碼,而在於寫規則。
Karpathy 今年 1 月在推特上那句被廣泛轉發的話:「我已經從 80% 手動寫代碼變成了 80% 交給 Agent 寫。」
未來五年,工程師的能力曲線正從「我能寫多少行程式碼」轉向「我能為AI設計多嚴格的工作環境」。
寫代碼的工作正被 Agent 接管。
但設計那個讓 Agent 能寫出好代碼的世界,還是人的工作。而且比以前更難、更重要、也更有意思。